使用MPI进行分布式内存编程(2)
MPI的英文全称为message passing interface,中文名为消息传递接口,他不是一种新的语言,而是一个可以被C,C++,Fortran程序调用的库。
预备知识
1.编译与执行
使用类似此形式进行编译 mpicc -g -Wall -o mpi_hello mpi_hello.c 进行编译,mpicc为C语言的包装脚本(wrapper script)而非编译器(compilier)。
执行的话,可以使用 mpiexec -n <number of processers> ./mpi_hello 来执行,在一些超算平台,如天河二号上,也可以使用yhrun等命令运行
2.MPI Init and MPI Finalize
MPI_Init是告知MPI系统进行所有必要的初始化设置,如为消息缓冲区分配消息,为进程分配进程号等。
MPI_Finallize告知MPI系统已使用完毕,将MPI占用的资源释放。
一般的MPI程序框架如下:
. . .
#include <mpi.h>
. . .
int main(int argc, char argv[]) f
. . .
/* No MPI calls before this */
MPI Init(&argc, &argv);
. . .
MPI Finalize();
/* No MPI calls after this */
. . .
return ;
}
3.通信子,MPI_Comm_size和MPI_Comm_rank
通信子:一组可以相互发送消息的进程集合。
MPI_Comm_size:可以得到通信子的进程数
MPI_Comm_rank:可以得到通信子的进程号
4.MPI_Send和MPI_Recv
MPI_Send语法结构如下:
int MPI_Send(
void msg_buf_p /* in */,
int msg_size /* in */,
MPI Datatype_msg_type /* in */,
int dest /* in */,
int tag /* in */,
MPI_Comm_communicator /* in */);
msg_buf_p ---->指向包含消息内容的内存块的指针
msg_size ---->发生的数据量
Datatype_msg_type --->由于C语言之中的类型,如int,char等不能作为参数传递给函数。所以要使用这个参数作为媒介。 dest--->指定了需要接收信息的进程号
tag --->一个非负int类型数,用于区分看上去完全一样的信息。 MPI_Comm_communicator ---->通信子。 MPI_Recv语法结构如下:
int MPI_Recv(
void msg_buf_p /* out */,
int buf_size /* in */,
MPI_Datatype buf_type /* in */,
int source /* in */,
int tag /* in */,
MPI_Comm communicator /* in */,
MPI_Status status_p /* out */);
msg_buf_p--->指向内存块
buf_size --->指定了内存块之中要储存对象的数量 buf_type --->说明对象的类型
source ---> 指定接受的信息应该由哪个进程发送而来
tag --->一个非负int类型数,用于区分看上去完全一样的信息,需要与发送消息的参数tag相匹配
communicator --->通信子,需要与发送消息的参数communicator 相匹配
status_p ----> 大部分情况下不进行调用。 实例见https://www.cnblogs.com/caishunzhe/p/12935439.html 为了编写能够使用scanf的MPI程序,我们根据进程号来选取分钟。0号进程复制读取数据,并将数据发送给其他进程。程序如下
pro3.5.c
#include<stdio.h>
#include<string.h>
#include<mpi.h> double f(double x)
{
return x*x+x*x*x+;
}
double Trap(double left_endpt,double right_endpt,int trap_count,double base_len)
{ double estimate,x;
int i;
estimate=(f(left_endpt)+f(right_endpt))/2.0; //梯形面积
for(i =;i<=trap_count-;++i)
{
x=left_endpt+i*base_len;
estimate+=f(x);
}
estimate=estimate*base_len;
return estimate;
} void Get_input(
int my_rank,
int comm_sz,
double* a_p,
double* b_p,
int* n_p
)
{
int dest;
if(my_rank==)
{
printf("Enter a,b,and n\n");
scanf("%lf %lf %d",a_p,b_p,n_p);
for(dest=;dest<comm_sz;++dest)
{
MPI_Send(a_p,,MPI_DOUBLE,dest,,MPI_COMM_WORLD);
MPI_Send(b_p,,MPI_DOUBLE,dest,,MPI_COMM_WORLD);
MPI_Send(n_p,,MPI_INT,dest,,MPI_COMM_WORLD);
}
}
else //rank!=0;
{
MPI_Recv(a_p,,MPI_DOUBLE,,,MPI_COMM_WORLD,MPI_STATUS_IGNORE);
MPI_Recv(b_p,,MPI_DOUBLE,,,MPI_COMM_WORLD,MPI_STATUS_IGNORE);
MPI_Recv(n_p,,MPI_INT,,,MPI_COMM_WORLD,MPI_STATUS_IGNORE);
}
} int main()
{
/*
int my_rank,comm_sz,n=1024,local_n;
double a=0.0,b=3.0,h,local_a,local_b;
*/
int my_rank,comm_sz,n,local_n;
double a,b,h,local_a,local_b;
double local_int,total_int;
int source; MPI_Init(NULL,NULL); //初始化
MPI_Comm_size(MPI_COMM_WORLD,&comm_sz); //返回进程数
MPI_Comm_rank(MPI_COMM_WORLD,&my_rank); //返回进程号 //新加入的函数,处理输入问题
Get_input(my_rank,comm_sz,&a,&b,&n); h=(b-a)/n;
local_n=n/comm_sz; local_a=a+my_rank*local_n*h;
local_b=local_a+local_n*h;
local_int=Trap(local_a,local_b,local_n,h); if(my_rank!=)
{
MPI_Send(&local_int,,MPI_DOUBLE,,,MPI_COMM_WORLD);
}
else
{
total_int=local_int;
for(source=;source<comm_sz;source++)
{
MPI_Recv(&local_int,,MPI_DOUBLE,source,,MPI_COMM_WORLD,MPI_STATUS_IGNORE); //接受其他节点信息
total_int+=local_int;
}
} if(my_rank==)
{
printf("With n=%d trapezoids,our estimated\n",n);
printf("of the intergral from %f to %f=%.15e\n",a,b,total_int);
} MPI_Finalize();
return ; }
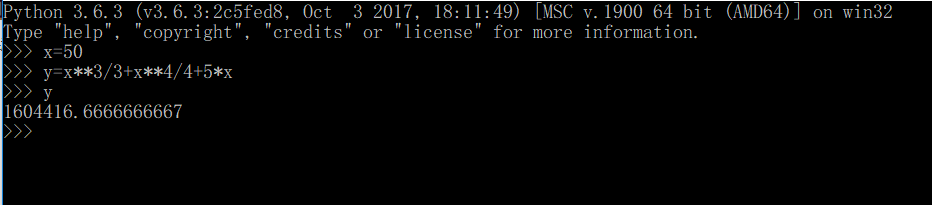
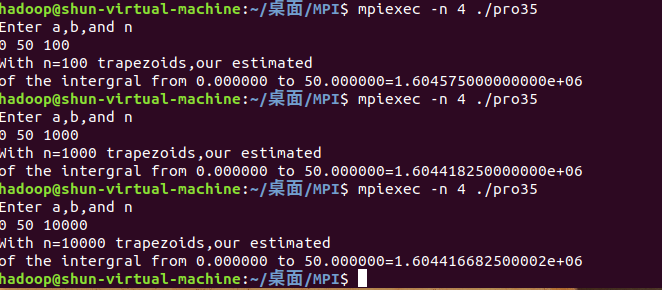
从0积分到50,划分的小间隔为100,1000,10000,理论上原函数为F(x)=1/3*x^3+1/4*x^4+5x ,积分值为F(50)-F(0)=1604416.6667
天河超算平台结果
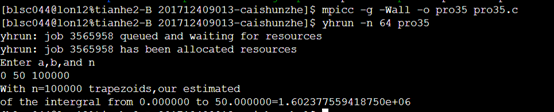
可以看见,随着n的增大,划分的越来越细,结果越接近真实值。
实例上面是比较基本的实现,仔细分析之后发现其通信开销太大,0号进程需要负责所有进程的累加,如果又8个进程,那么就得加7次,随着进程的增长耗时线性增长
我们可以对其进行相应的改进,使用树型结构。
如下图的两种方法均可以,随进程数增长,时间为log(N)
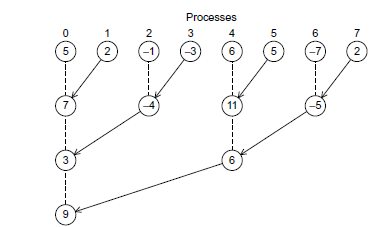
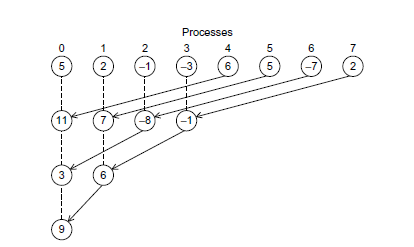
我们选取第一种策略
#include<stdio.h>
#include<string.h>
#include<mpi.h>
/*只考虑最简单的2的幂次方情况*/ double f(double x)
{
return x*x+x*x*x+;
}
double Trap(double left_endpt,double right_endpt,int trap_count,double base_len)
{ double estimate,x;
int i;
estimate=(f(left_endpt)+f(right_endpt))/2.0; //梯形面积
for(i =;i<=trap_count-;++i)
{
x=left_endpt+i*base_len;
estimate+=f(x);
}
estimate=estimate*base_len;
return estimate;
} void Get_input(
int my_rank,
int comm_sz,
double* a_p,
double* b_p,
int* n_p
)
{
int dest;
if(my_rank==)
{
printf("Enter a,b,and n\n");
scanf("%lf %lf %d",a_p,b_p,n_p);
for(dest=;dest<comm_sz;++dest)
{
MPI_Send(a_p,,MPI_DOUBLE,dest,,MPI_COMM_WORLD);
MPI_Send(b_p,,MPI_DOUBLE,dest,,MPI_COMM_WORLD);
MPI_Send(n_p,,MPI_INT,dest,,MPI_COMM_WORLD);
}
}
else //rank!=0;
{
MPI_Recv(a_p,,MPI_DOUBLE,,,MPI_COMM_WORLD,MPI_STATUS_IGNORE);
MPI_Recv(b_p,,MPI_DOUBLE,,,MPI_COMM_WORLD,MPI_STATUS_IGNORE);
MPI_Recv(n_p,,MPI_INT,,,MPI_COMM_WORLD,MPI_STATUS_IGNORE);
}
} int main()
{
/*
int my_rank,comm_sz,n=1024,local_n;
double a=0.0,b=3.0,h,local_a,local_b;
*/
//comm_sz-->进程数 my_rank--->进程号
int my_rank,comm_sz,n,local_n;
double a,b,h,local_a,local_b;
double local_int,total_int;
int source;
int t;
MPI_Init(NULL,NULL); //初始化
MPI_Comm_size(MPI_COMM_WORLD,&comm_sz); //返回进程数
MPI_Comm_rank(MPI_COMM_WORLD,&my_rank); //返回进程号 //新加入的函数,处理输入问题
Get_input(my_rank,comm_sz,&a,&b,&n); h=(b-a)/n;
local_n=n/comm_sz; local_a=a+my_rank*local_n*h;
local_b=local_a+local_n*h;
local_int=Trap(local_a,local_b,local_n,h);
/*
if(my_rank!=0)
{
MPI_Send(&local_int,1,MPI_DOUBLE,0,0,MPI_COMM_WORLD);
}
else //my_rank=0
{
total_int=local_int;
for(source=1;source<comm_sz;source++)
{
MPI_Recv(&local_int,1,MPI_DOUBLE,source,0,MPI_COMM_WORLD,MPI_STATUS_IGNORE); //接受其他节点信息
total_int+=local_int;
}
}
*/ /*
if(my_rank%2!=0)//奇数向小一位的偶数发送,然后退休
{
MPI_Send(&local_int,1,MPI_DOUBLE,my_rank-1,0,MPI_COMM_WORLD);
}
else //偶数先接受奇数还可能有进一步的行动
{
//接受奇数节点信息
total_int=local_int;
MPI_Recv(&local_int,1,MPI_DOUBLE,my_rank+1,0,MPI_COMM_WORLD,MPI_STATUS_IGNORE); //接受其他节点信息
total_int+=local_int;
local_int=total_int; for(t=2;t<comm_sz;t<<1)
{
for(source=t;source<comm_sz;source+=2*t)
{
if(my_rank==source)
MPI_Send(&local_int,1,MPI_DOUBLE,my_rank-t,0,MPI_COMM_WORLD);
}
for(source=0;source<comm_sz;source+=2*t)
{
if(my_rank==source)
{
total_int=local_int;
MPI_Recv(&local_int,1,MPI_DOUBLE,my_rank+t,0,MPI_COMM_WORLD,MPI_STATUS_IGNORE); //接受其他节点信息
total_int+=local_int;
local_int=total_int;
}
}
} }
*/
for(t=;t<comm_sz;t*=)
{
for(source=t;source<comm_sz;source+=*t)
{
if(my_rank==source)
{
MPI_Send(&local_int,,MPI_DOUBLE,my_rank-t,,MPI_COMM_WORLD);
break;
}
}
for(source=;source<comm_sz;source+=*t)
{
if(my_rank==source)
{
total_int=local_int;
MPI_Recv(&local_int,,MPI_DOUBLE,my_rank+t,,MPI_COMM_WORLD,MPI_STATUS_IGNORE); //接受其他节点信息
total_int+=local_int;
local_int=total_int;
break;
}
}
} if(my_rank==)
{
printf("With n=%d trapezoids,our estimated\n",n);
printf("of the intergral from %f to %f=%.15e\n",a,b,total_int);
//printf("comm_sz=%d",comm_sz);
} MPI_Finalize();
return ; }
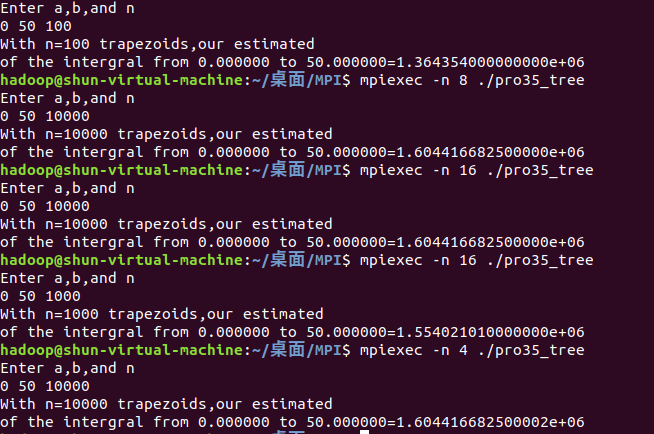
天河超算平台结果

使用MPI进行分布式内存编程(2)的更多相关文章
- 【并行计算】用MPI进行分布式内存编程(一)
通过上一篇关于并行计算准备部分的介绍,我们知道MPI(Message-Passing-Interface 消息传递接口)实现并行是进程级别的,通过通信在进程之间进行消息传递.MPI并不是一种新的开发语 ...
- 【并行计算】用MPI进行分布式内存编程(二)
通过上一篇中,知道了基本的MPI编写并行程序,最后的例子中,让使用0号进程做全局的求和的所有工作,而其他的进程却都不工作,这种方式也许是某种特定情况下的方案,但明显不是最好的方案.举个例子,如果我们让 ...
- 用MPI进行分布式内存编程(1)
<并行程序设计导论>第三章部分程序 程序3.1运行实例 #include<stdio.h> #include<string.h> #include<mpi.h ...
- Python并发编程-Memcached (分布式内存对象缓存系统)
一.Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的 ...
- 基于英特尔® 至强™ 处理器 E5 产品家族的多节点分布式内存系统上的 Caffe* 培训
原文链接 深度神经网络 (DNN) 培训属于计算密集型项目,需要在现代计算平台上花费数日或数周的时间方可完成. 在最近的一篇文章<基于英特尔® 至强™ E5 产品家族的单节点 Caffe 评分和 ...
- 共享内存Distributed Memory 与分布式内存Distributed Memory
我们经常说到的多核处理器,是指一个处理器(CPU)上有多个处理核心(CORE),共享内存多核系统我们可以将CPU想象为一个密封的包,在这个包内有多个互相连接的CORES,每个CORE共享一个主存,所有 ...
- Disque:Redis之父新开源的分布式内存作业队列
Disque是Redis之父Salvatore Sanfilippo新开源的一个分布式内存消息代理.它适应于"Redis作为作业队列"的场景,但采用了一种专用.独立.可扩展且具有容 ...
- Spark入门实战系列--10.分布式内存文件系统Tachyon介绍及安装部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Tachyon介绍 1.1 Tachyon简介 随着实时计算的需求日益增多,分布式内存计算 ...
- 高性能分布式内存队列系统beanstalkd(转)
beanstalkd一个高性能.轻量级的分布式内存队列系统,最初设计的目的是想通过后台异步执行耗时的任务来降低高容量Web应用系统的页面访问延迟,支持过有9.5 million用户的Facebook ...
随机推荐
- 面向对象之多态(Java实现)
本文借鉴于csdn,博客园,b站等各大知识分享平台 之前学习了封装与继承,封装就是数据的封装性(大致理解),继承就是一个类继承另一个类的属性,称为父子类 多态 多态是面向对象的第三大特性(共三大特性) ...
- Django开篇 - Web应用
一 Web应用的组成 接下来我们学习的目的是为了开发一个Web应用程序,而Web应用程序是基于B/S架构的,其中B指的是浏览器,负责向S端发送请求信息,而S端会根据接收到的请求信息返回相应的数据给浏览 ...
- 数据可视化基础专题(十五):pyecharts 基础(二)flask 框架整合
Flask 前后端分离 Step 1: 新建一个 Flask 项目 $ mkdir pyecharts-flask-demo $ cd pyecharts-flask-demo $ mkdir tem ...
- JavaScript 基础 学习(三)
JavaScript 基础 学习(三) 事件三要素 1.事件源: 绑定在谁身上的事件(和谁约定好) 2.事件类型: 绑定一个什么事件 3.事件处理函数: 当行为发生的时候,要执行哪一个函数 ...
- 【Nginx】如何为已安装的Nginx动态添加模块?看完我懂了!!
写在前面 很多时候,我们根据当时的项目情况和业务需求安装完Nginx后,后续随着业务的发展,往往会给安装好的Nginx添加其他的功能模块.在为Nginx添加功能模块时,要求Nginx不停机.这就涉及到 ...
- python学习03-使用动态ua
在写爬虫的时候要使用到浏览器ua 分享一下今天学到的如何使用动态ua的进行爬取 1.简单的爬取网页信息 from urllib.request import urlopen #目标地址 url = & ...
- Eclipse点击空格总是自动补全代码怎么办,如何自动补全代码,代码提示
Eclipse点击空格总是自动补全不想要的代码说明大家配置的时候出现了一点错误,下面的步骤将会解决它, 网上部分经验需要大家更改代码非常繁琐,下面是一个简单的步骤方法 步骤一:打开eclipse依次点 ...
- Java Properties集合基础解析
Java Properties集合基础解析 本期学习的properties集合是项目中经常用到的操作 什么是Properties集合? java.util.Properties集合继承于Hashtab ...
- ztree : 增删改功能demo与自定义DOM功能demo的结合
最近有个项目要用ztree,需要用ztree自带的功能(增删改),也需要自定义DOM的功能(置顶). ztree的demo里有增删改的demo,也有自定义DOM的demo,但没有两者结合的. 所以我把 ...
- 你闺女也能看懂的插画版 Kubernetes 指南
Matt Butcher是Deis的平台架构师,热爱哲学,咖啡和精雕细琢的代码.有一天女儿走进书房问他什么是Kubernetes,于是就有了这本插画版的Kubernetes指南,讲述了勇敢的Phipp ...