数据可视化之分析篇(一)使用Power BI进行动态帕累托分析
https://zhuanlan.zhihu.com/p/57763423
通过简单的点击交互,就能进行动态分析发现见解,才是我们需要的,恰好这也是 PowerBI 所擅长的。
就帕累托分析来说,能从不同的角度快速发现关键因素、以及可以动态设定关键因素的阈值,就是我们需要的。本文通过一个示例来看看如何生成一个动态的帕累托图,先看看最终效果,
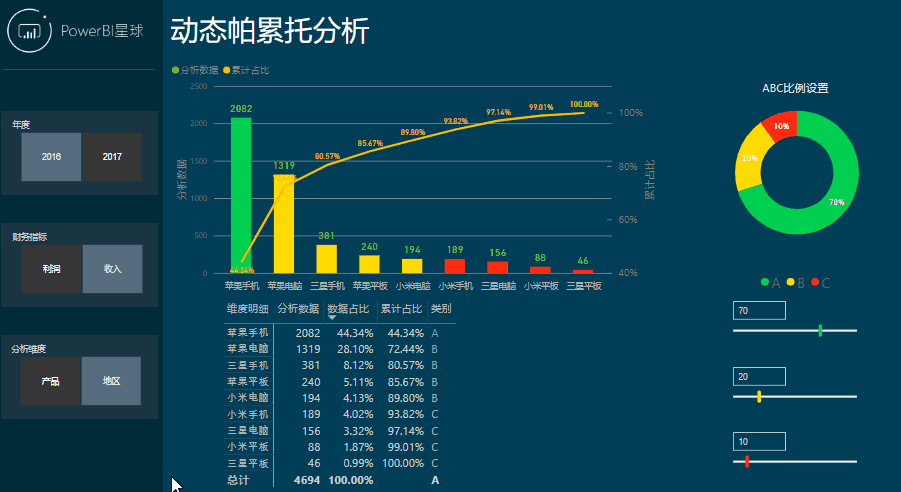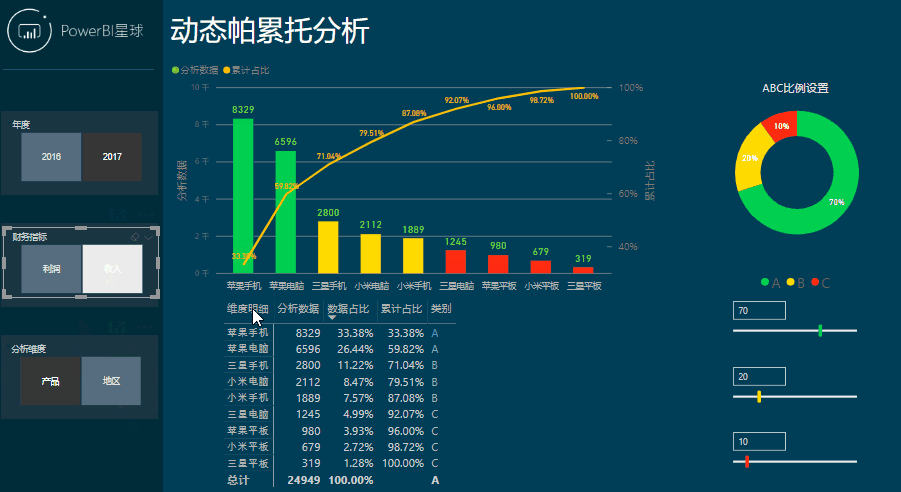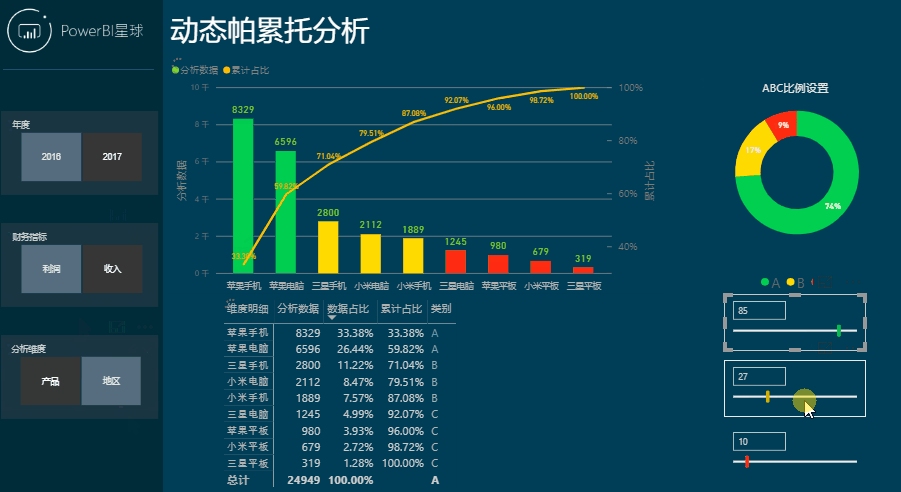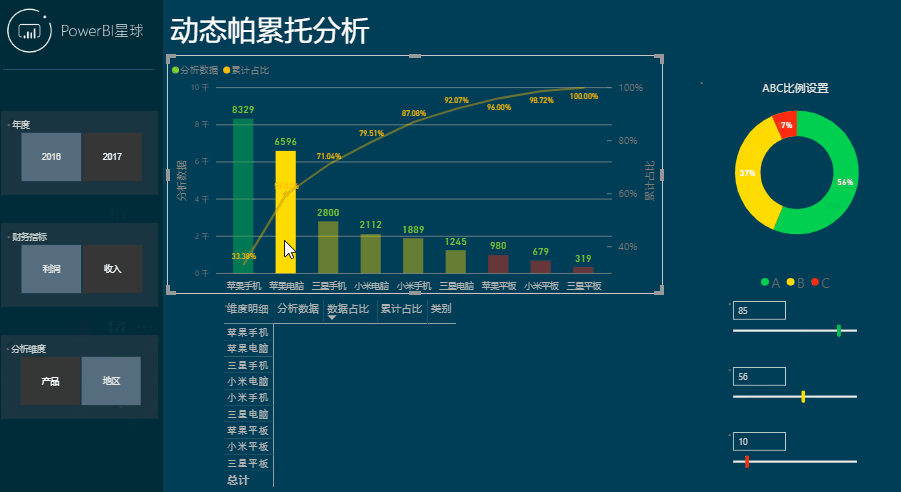
这样分析是不是很简单,下面就来看看是如何制作的。
数据为虚拟的某连锁店的电子产品销售明细,以及与之关联的产品和销售地点维度,和一个对应的日期表,建立关系图如下,
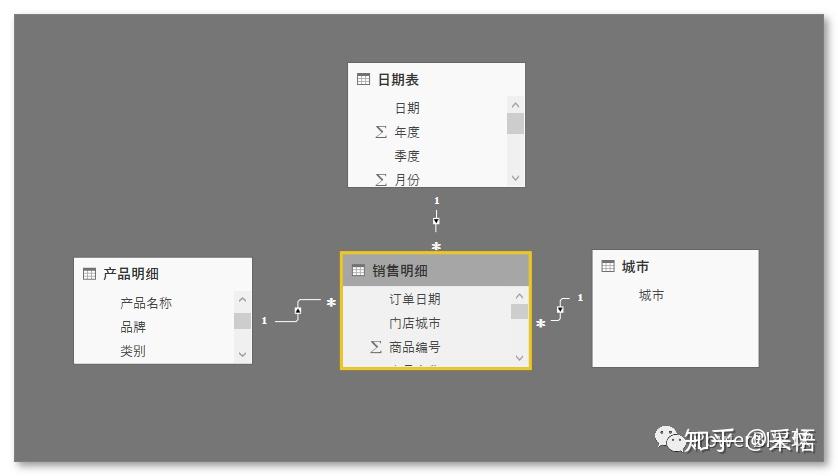
要分析的维度:
1,时间维度:年份
2,财务指标:收入和利润
3,销售细分:按地区和产品明细
时间维度
年度指标比较简单,销售明细表中有日期数据,直接根据日期表中的年度创建一个切片器就行了。
财务指标
先建两个度量值:
收入 = SUM('销售明细'[销售额])
利润贡献 = SUM('销售明细'[毛利])
然后在PowerBI Desktop中新建表,只有一个字段[财务指标],数据为收入和利润,

按字段[财务指标]制作切片器,然后写度量值[指标数据],
指标数据 =
SWITCH(TRUE(),
SELECTEDVALUE('财务指标'[财务指标])="收入",[收入],
SELECTEDVALUE('财务指标'[财务指标])="利润",[利润贡献],
BLANK()
)
该度量值判断切片器的选择,如果选择的是收入,就汇总收入数据;如果选择的是利润,就汇总利润。
产品和地区维度
同上面的思路类似,把产品明细和地区明细整合到一起,如下图,
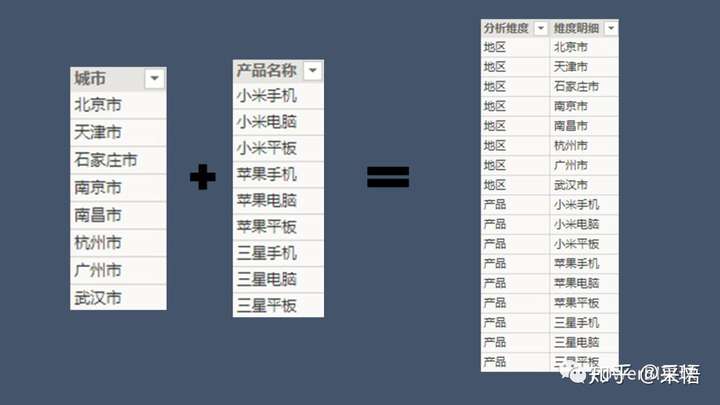
如果数据量很小,手工整理也很快,不过在这里依然可以用DAX实现,在【建模】选项卡下,点击"新表"(参考:PowerBI Desktop中新建表的使用场景),在编辑栏输入:
分析维度 =
VAR item1 = SELECTCOLUMNS( ADDCOLUMNS( DISTINCT( '城市'[城市] ) , "分析维度" , "地区" ) , "分析维度" , [分析维度],"维度明细",[城市] )
VAR item2 = SELECTCOLUMNS( ADDCOLUMNS( DISTINCT( '产品明细'[产品名称]) , "分析维度" , "产品" ) ,"分析维度" , [分析维度], "维度明细" , [产品名称] )
RETURN UNION( item1 , item2 )
然后上图中的表格就生成了,根据该表的字段[分析维度]创建切片器。
至此,三个分析维度已经建立完成,并体现在报表左侧的三个切片器上。
制作帕累托图
步骤和上一篇文章类似,只是由于分析维度更多,需要更细化的处理。各个切片器之间要相互配合,考虑上下文的影响,以下的DAX公式稍微长一点,需要根据每个函数慢慢理解,按照这个实例学习这些函数其实也是个不错的方式。
将【折线和簇状柱形图】拖到画布上,将前面创建的分析维度表中的[维度明细]拖入到共享轴。
创建度量值[分析数据]拖入到列值框中,
分析数据 =
VAR item3=TREATAS( VALUES('分析维度'[维度明细]),'城市'[城市])
VAR item4=TREATAS(VALUES('分析维度'[维度明细]),'产品明细'[产品名称])
RETURN
SWITCH(TRUE(),
SELECTEDVALUE('分析维度'[分析维度])="地区",
CALCULATE([指标数据],item3),
SELECTEDVALUE('分析维度'[分析维度])="产品",
CALCULATE([指标数据],item4),
BLANK()
)
下一步就是获得累计占比的数据,创建度量值如下,
分析数据合计 =
SWITCH(TRUE(),
SELECTEDVALUE('财务指标'[财务指标])="收入",
CALCULATE([收入],ALLSELECTED('销售明细'[销售额])),
SELECTEDVALUE('财务指标'[财务指标])="利润",
CALCULATE([利润贡献],ALLSELECTED('销售明细'[毛利])),
BLANK()
)
数据占比 = DIVIDE([分析数据],[分析数据合计])
累计占比 =
VAR cur_rate=[数据占比]
RETURN
CALCULATE([数据占比],FILTER(ALL('分析维度'[维度明细]),[数据占比]>=cur_rate))
将[累计占比]拖入到列值框中,帕累托图就制作好了,
ABC比例设置
帕累托分析也成为ABC分析,一般按照70%、20%和10%的比例来划分,或者按照二八定律的80%和20%划分,当然这些都是一个概数而已,并不是一定要这样划分,实际分析时还要根据情况自行调整。
在【建模】选项卡下,点击"新建参数"(参考:创建PowerBI「参数」轻松搞定动态分析),建立三个参数如下:
参数a = GENERATESERIES(1, 100, 1)
参数b = GENERATESERIES(0, 100, 1)
参数c = GENERATESERIES(0, 100, 1)
同时生成三个切片器,通过这三个切片器来控制这三个参数的数值大小,然后就可以计算出每一类的相对占比,
A类比例 = DIVIDE([参数a值],[参数a值]+[参数b值]+[参数c值])
B类比例 = DIVIDE([参数b值],[参数a值]+[参数b值]+[参数c值])
C类比例 = DIVIDE([参数c值],[参数a值]+[参数b值]+[参数c值])
利用这三个度量值生成一个环形图,这样动态的ABC比例就设计好了,

判断因素的所属分类
建立度量值,
数据所属分类 =
VAR cur_leji=[累计占比]
RETURN
SWITCH(TRUE(),
cur_leji<=[A类比例],"A",
cur_leji<=[A类比例]+[B类比例],"B",
"C"
)
至此该模型的技术操作完成,剩下的就是一些可视化方面的修饰、格式调整等,以及按照ABC的分类动态配色。
该帕累托模型在主要的分析维度上都已考虑到,可以在实际分析中进行分解套用。
总结:
进行动态帕累托分析的主要步骤:
1,整理需要分析的维度
2,设置ABC比例参数
3,创建指标数据和累计比例
数据可视化之分析篇(一)使用Power BI进行动态帕累托分析的更多相关文章
- 数据可视化之PowerQuery篇(十一)使用Power BI进行动态帕累托分析
https://zhuanlan.zhihu.com/p/57763423 上篇文章介绍了帕累托图的用处以及如何制作一个简单的帕累托图,在 PowerBI 中可以很方便的生成,但若仅止于此,并不足以体 ...
- 数据特征分析:3.统计分析 & 帕累托分析
1.统计分析 统计指标对定量数据进行统计描述,常从集中趋势和离中趋势两个方面进行分析 集中趋势度量 / 离中趋势度量 One.集中趋势度量 指一组数据向某一中心靠拢的倾向,核心在于寻找数据的代表值或中 ...
- 帕累托分析法(Pareto Analysis)(柏拉图分析)
帕累托分析法(Pareto Analysis)(柏拉图分析) ABC分类法是由意大利经济学家帕雷托首创的.1879年,帕累托研究个人收入的分布状态图是地,发现少数人收入占全部人口收入的大部分,而多数人 ...
- 数据可视化之powerBI技巧(四)使用Power BI制作帕累托图
各种复杂现象的背后,其实都是受关键的少数因素和普通的大多数因素所影响,把主要精力放在关键的少数因素上,就能达到事半功倍的效果. 这就是大家常说的二八原则,也称为帕累托原则,最早是由意大利经济学家 V. ...
- 数据可视化之DAX篇(二十三)ALLEXCEPT应用示例:更灵活的累计求和
https://zhuanlan.zhihu.com/p/67441847 累计求和问题,之前已经介绍过(有了这几个公式,你也可以快速搞定累计求和),主要是基于比较简单的情形,针对所有的数据进行累计求 ...
- 设备数据通过Azure Functions 推送到 Power BI 数据大屏进行展示(2.Azure Functions实战)
本案例适用于开发者入门理解Azure Functions/ IoT Hub / Service Bus / Power BI等几款产品. 主要实战的内容为: 将设备遥测数据上传到物联网中心, 将遥测数 ...
- 数据可视化之PowerQuery篇(十六)使用Power BI进行流失客户分析
https://zhuanlan.zhihu.com/p/73358029 为了提升销量,在不断吸引新客户的同时,还要防止老客户离你而去,但每一个顾客不可能永远是你的客户,不可避免的都会经历新客户.活 ...
- 数据可视化之 图表篇(四) 那些精美的Power BI可视化图表
之前使用自定义图表,每次新打开一个新文件时,都需要重新添加,无法保存,在PowerBI 6月更新中,这个功能得到了很大改善,可以将自定义的图表固定在内置图表面板上了. 添加自定义图表后,右键>固 ...
- 数据可视化之 图表篇(二)如何用Power BI制作疫情地图?
丁香园制作的这个地图可视化,相信大家每天都会看好几遍,这里不讨论具体数据,仅来探讨一下PowerBI地图技术. 这个地图很简洁,主要有三个特征: 1,使用着色地图,根据数据自动配色 2,只显示中国地图 ...
随机推荐
- 深浅拷贝 set集合
数据类型的补充 编码转换 # s1 = '中国' # b1 = s1.encode('utf-8') # # print(b1)-------------->b'\xe4\xb8\xad\xe5 ...
- 修改MSSQL的端口地址_TcpPort_数据库安装工具_连载_2
修改MSSQL的端口地址_TcpPort,可在程序中调用,从而修改TcpPort Use master Go ------------------------------ --1)在注册表中查询 Pi ...
- docker安装,基本使用,实战
[docker概念作用术语] [使用docker的步骤] [docker安装及配置] [环境要求] docker要求centos7 必须要64位,内核3.1及以上 https://docs.docke ...
- jmeter的参数化
[4种参数化] 用户参数 适用于参数取值范围很小的时候使用 CSV数据文件设置 适用于参数取值范围较大的时候使用,该方法具有更大的灵活性 用户定义的变量 一般用于测试计划中不需要随请求迭代的参数设置, ...
- Apache Hudi:云数据湖解决方案
1. 引入 开源Apache Hudi项目为Uber等大型组织提供流处理能力,每天可处理数据湖上的数十亿条记录. 随着世界各地的组织采用该技术,Apache开源数据湖项目已经日渐成熟. Apache ...
- 黎活明8天快速掌握android视频教程--17_创建数据库与完成数据添删改查
1.我们首先来看下整个项目 项目也是采用mvc的框架 package dB; import android.content.Context; import android.database.sqlit ...
- disruptor架构四 多生产者多消费者执行
1.首先介绍下那个时候使用RingBuffer,那个时候使用disruptor ringBuffer比较适合场景比较简单的业务,disruptor比较适合场景较为复杂的业务,很多复杂的结果必须使用di ...
- 入门大数据---Flume 简介及基本使用
一.Flume简介 Apache Flume 是一个分布式,高可用的数据收集系统.它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集.Flume 分为 NG 和 OG ( ...
- 《UNIX环境高级编程》(APUE) 笔记第十章 - 信号
10 - 信号 GitHub 地址 1. 信号 信号是 软中断 ,信号提供了一种处理异步事件的方法. 当造成信号的事件发生时,为进程 产生 一个信号(或向进程 发送 一个信号).事件 可以是硬件异常( ...
- 《UNIX环境高级编程》(APUE) 笔记第七章 - 进程环境
7 - 进程环境 Github 地址 1. main 函数 C 程序总是从 main 函数 开始执行: int main(int argc, char *argv[]); \(argc\) 为命令行参 ...