精尽MyBatis源码分析 - SQL执行过程(三)之 ResultSetHandler
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址、Mybatis-Spring 源码分析 GitHub 地址、Spring-Boot-Starter 源码分析 GitHub 地址)进行阅读
MyBatis 版本:3.5.2
MyBatis-Spring 版本:2.0.3
MyBatis-Spring-Boot-Starter 版本:2.1.4
MyBatis的SQL执行过程
在前面一系列的文档中,我已经分析了 MyBatis 的基础支持层以及整个的初始化过程,此时 MyBatis 已经处于就绪状态了,等待使用者发号施令了
那么接下来我们来看看它执行SQL的整个过程,该过程比较复杂,涉及到二级缓存,将返回结果转换成 Java 对象以及延迟加载等等处理过程,这里将一步一步地进行分析:
- 《SQL执行过程(一)之Executor》
- 《SQL执行过程(二)之StatementHandler》
- 《SQL执行过程(三)之ResultSetHandler》
- 《SQL执行过程(四)之延迟加载》
MyBatis中SQL执行的整体过程如下图所示:
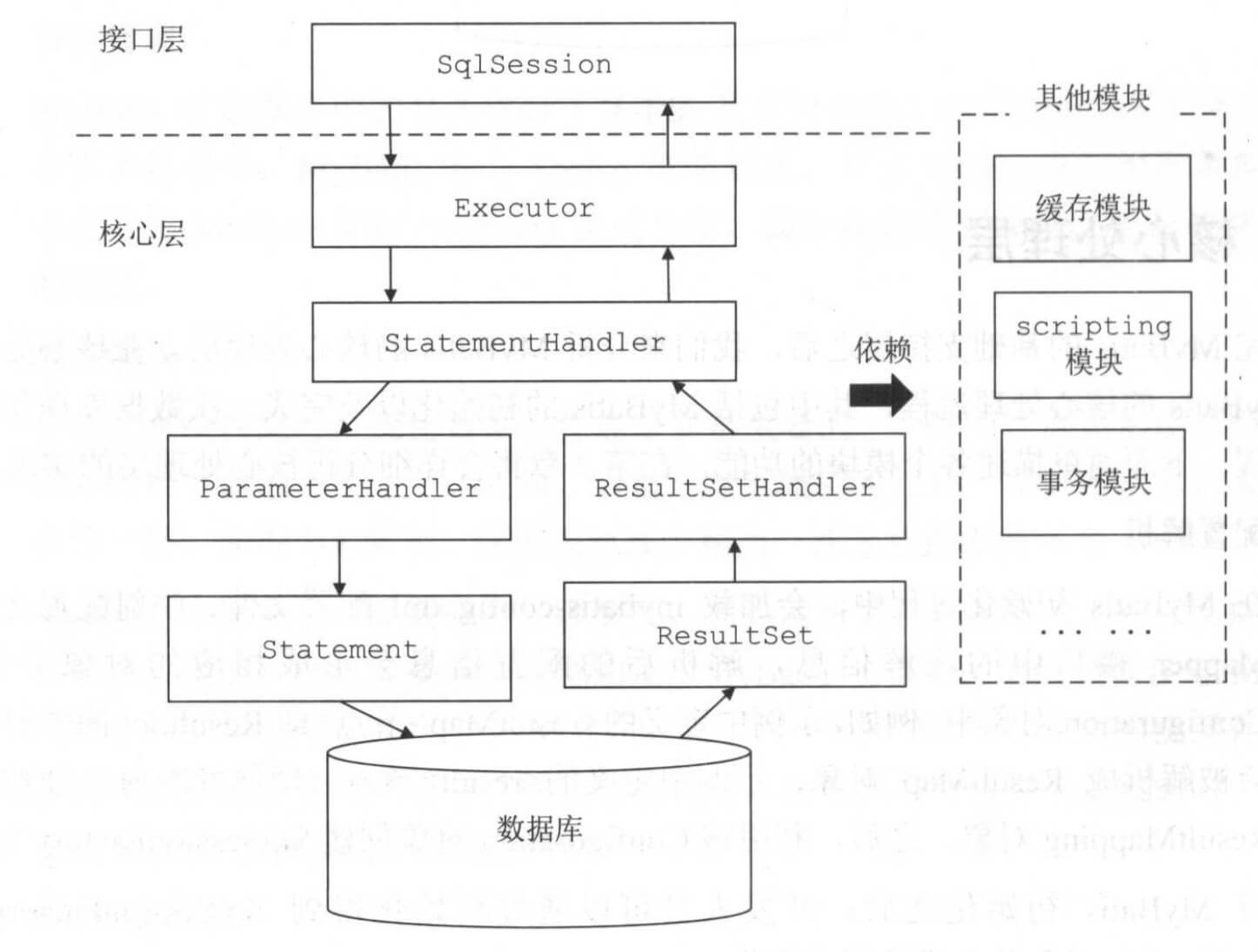
在 SqlSession 中,会将执行 SQL 的过程交由Executor执行器去执行,过程大致如下:
- 通过
DefaultSqlSessionFactory创建与数据库交互的SqlSession“会话”,其内部会创建一个Executor执行器对象 - 然后
Executor执行器通过StatementHandler创建对应的java.sql.Statement对象,并通过ParameterHandler设置参数,然后执行数据库相关操作 - 如果是数据库更新操作,则可能需要通过
KeyGenerator先设置自增键,然后返回受影响的行数 - 如果是数据库查询操作,则需要将数据库返回的
ResultSet结果集对象包装成ResultSetWrapper,然后通过DefaultResultSetHandler对结果集进行映射,最后返回 Java 对象
上面还涉及到一级缓存、二级缓存和延迟加载等其他处理过程
SQL执行过程(三)之ResultSetHandler
高能预警 ️ ️ ️ ️ ️ ️
DefaultResultSetHandler(结果集处理器)将数据库查询结果转换成 Java 对象是一个非常繁琐的过程,需要处理各种场景,如果继续往下看,请做好心理准备
在前面SQL执行过程一系列的文档中,已经详细地分析了在MyBatis的SQL执行过程中,SqlSession会话将数据库操作交由Executor执行器去完成,然后通过StatementHandler去执行数据库相关操作,并获取到数据库的执行结果
如果是数据库查询操作,则需要通过ResultSetHandler对查询返回的结果集进行映射处理,转换成对应的Java对象,算是SQL执行过程的最后一步,那么我们来看看MyBatis是如何完成这个繁杂的解析过程的
ResultSetHandler接口的实现类如下图所示:
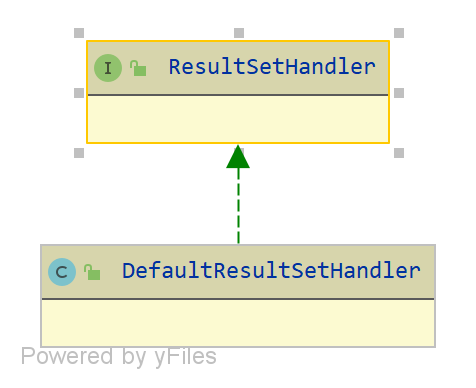
先回顾一下ResultSetHandler在哪被调用,在PreparedStatementHandler的query方法中,代码如下:
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
// 执行
ps.execute();
// 结果处理器并返回结果
return resultSetHandler.handleResultSets(ps);
}
- 属性
resultSetHandler默认为DefaultResultSetHandler对象,可以回到《SQL执行过程(二)之StatementHandler》的BaseStatementHandler小节中的构造方法的第3步可以看到 - 调用
resultSetHandler的handleResultSets(Statement stmt)方法,对结果集进行映射,转换成Java对象并返回
ResultSetWrapper
因为在
DefaultResultSetHandler中,对ResultSet的操作更多的是它的ResultSetWrapper包装类,所以我们先来看看这个类
org.apache.ibatis.executor.resultset.ResultSetWrapper:java.sql.ResultSet的包装类,为DefaultResultSetHandler提供许多便捷的方法,直接来看它的代码
构造方法
public class ResultSetWrapper {
/**
* ResultSet 对象
*/
private final ResultSet resultSet;
/**
* 类型处理器注册表
*/
private final TypeHandlerRegistry typeHandlerRegistry;
/**
* ResultSet 中每列的列名
*/
private final List<String> columnNames = new ArrayList<>();
/**
* ResultSet 中每列对应的 Java Type
*/
private final List<String> classNames = new ArrayList<>();
/**
* ResultSet 中每列对应的 Jdbc Type
*/
private final List<JdbcType> jdbcTypes = new ArrayList<>();
/**
* 记录每列对应的 TypeHandler 对象
* key:列名
* value:TypeHandler 集合
*/
private final Map<String, Map<Class<?>, TypeHandler<?>>> typeHandlerMap = new HashMap<>();
/**
* 记录了被映射的列名
* key:ResultMap 对象的 id {@link #getMapKey(ResultMap, String)}
* value:ResultMap 对象映射的列名集合
*/
private final Map<String, List<String>> mappedColumnNamesMap = new HashMap<>();
/**
* 记录了未映射的列名
* key:ResultMap 对象的 id {@link #getMapKey(ResultMap, String)}
* value:ResultMap 对象未被映射的列名集合
*/
private final Map<String, List<String>> unMappedColumnNamesMap = new HashMap<>();
public ResultSetWrapper(ResultSet rs, Configuration configuration) throws SQLException {
super();
this.typeHandlerRegistry = configuration.getTypeHandlerRegistry();
this.resultSet = rs;
// 获取 ResultSet 的元信息
final ResultSetMetaData metaData = rs.getMetaData();
final int columnCount = metaData.getColumnCount();
for (int i = 1; i <= columnCount; i++) {
// 获得列名或者通过 AS 关键字指定列名的别名
columnNames.add(configuration.isUseColumnLabel() ? metaData.getColumnLabel(i) : metaData.getColumnName(i));
// 获得该列对应的 Jdbc Type
jdbcTypes.add(JdbcType.forCode(metaData.getColumnType(i)));
// 获得该列对应的 Java Type
classNames.add(metaData.getColumnClassName(i));
}
}
}
resultSet:被包装的ResultSet结果集对象typeHandlerRegistry:类型处理器注册表,因为需要进行Java Type与Jdbc Type之间的转换columnNames:结果集中的所有列名classNames:结果集中的每列的对应的Java Type的名称jdbcTypes:结果集中的每列对应的Jdbc TypetypeHandlerMap:结果集中每列对应的类型处理器mappedColumnNamesMap:保存每个ResultMap对象中映射的列名集合,也就是我们在<resultMap />标签下的子标签配置的column属性unMappedColumnNamesMap:保存每个ResultMap对象中未映射的列名集合,也就是没有在<resultMap />标签下配置过,但是查询结果返回了
在构造方法中,会初始化上面的columnNames、classNames和jdbcTypes属性
getTypeHandler方法
getTypeHandler(Class<?> propertyType, String columnName):通过列名和Java Type获取对应的TypeHandler类型处理器,方法如下:
public TypeHandler<?> getTypeHandler(Class<?> propertyType, String columnName) {
TypeHandler<?> handler = null;
// 获取列名对应的类型处理器
Map<Class<?>, TypeHandler<?>> columnHandlers = typeHandlerMap.get(columnName);
if (columnHandlers == null) {
columnHandlers = new HashMap<>();
typeHandlerMap.put(columnName, columnHandlers);
} else {
handler = columnHandlers.get(propertyType);
}
if (handler == null) {
// 获取该列对应的 Jdbc Type
JdbcType jdbcType = getJdbcType(columnName);
// 根据 Java Type 和 Jdbc Type 获取对应的 TypeHandler 类型处理器
handler = typeHandlerRegistry.getTypeHandler(propertyType, jdbcType);
// Replicate logic of UnknownTypeHandler#resolveTypeHandler
// See issue #59 comment 10
if (handler == null || handler instanceof UnknownTypeHandler) {
// 从 ResultSet 中获取该列对应的 Java Type 的 Class 对象
final int index = columnNames.indexOf(columnName);
final Class<?> javaType = resolveClass(classNames.get(index));
if (javaType != null && jdbcType != null) {
handler = typeHandlerRegistry.getTypeHandler(javaType, jdbcType);
} else if (javaType != null) {
handler = typeHandlerRegistry.getTypeHandler(javaType);
} else if (jdbcType != null) {
handler = typeHandlerRegistry.getTypeHandler(jdbcType);
}
}
if (handler == null || handler instanceof UnknownTypeHandler) {
// 最差的情况,设置为 ObjectTypeHandler
handler = new ObjectTypeHandler();
}
// 将生成的 TypeHandler 存放在 typeHandlerMap 中
columnHandlers.put(propertyType, handler);
}
return handler;
}
大致逻辑如下:
- 先从
Map<String, Map<Class<?>, TypeHandler<?>>> typeHandlerMap属性中获取类型处理器 - 如果从缓存中没有获取到,则尝试根据Jdbc Type和Java Type从
typeHandlerRegistry注册表获取 - 如果还是没有获取到,则根据
classNames中拿到结果集中该列的Java Type,然后在从typeHandlerRegistry注册表获取 - 还是没有获取到,则设置为
ObjectTypeHandler - 最后将其放入
typeHandlerMap缓存中
loadMappedAndUnmappedColumnNames方法
loadMappedAndUnmappedColumnNames(ResultMap resultMap, String columnPrefix)方法,初始化mappedColumnNamesMap和unMappedColumnNamesMap两个属性,分别为映射的列名和未被映射的列名,方法如下:
private void loadMappedAndUnmappedColumnNames(ResultMap resultMap, String columnPrefix) throws SQLException {
List<String> mappedColumnNames = new ArrayList<>();
List<String> unmappedColumnNames = new ArrayList<>();
// <1> 获取配置的列名的前缀,全部大写
final String upperColumnPrefix = columnPrefix == null ? null : columnPrefix.toUpperCase(Locale.ENGLISH);
/*
* <2> 获取 ResultMap 中配置的所有列名,并添加前缀
* 如果在 <select /> 上面配置的是 resultType 属性,则返回的是空集合,因为它生成的 ResultMap 只有 Java Type 属性
*/
final Set<String> mappedColumns = prependPrefixes(resultMap.getMappedColumns(), upperColumnPrefix);
/*
* <3> 遍历数据库查询结果中所有的列名
* 将所有列名分为两类:是否配置了映射
*/
for (String columnName : columnNames) {
final String upperColumnName = columnName.toUpperCase(Locale.ENGLISH);
if (mappedColumns.contains(upperColumnName)) {
mappedColumnNames.add(upperColumnName);
} else {
unmappedColumnNames.add(columnName);
}
}
// <4> 将上面两类的列名保存
mappedColumnNamesMap.put(getMapKey(resultMap, columnPrefix), mappedColumnNames);
unMappedColumnNamesMap.put(getMapKey(resultMap, columnPrefix), unmappedColumnNames);
}
获取配置的列名的前缀,全部大写,通常是没有配置的
获取
ResultMap中配置的所有列名,并添加前缀如果在
<select />上面配置的是resultType属性,则返回的是空集合,因为它创建的ResultMap对象中只有Java Type属性遍历结果集中所有的列名,如果在
<resultMap />标签中的子标签配置的column属性有包含这个列名,则属于映射的列名否则就属于未被映射的列名
ResultSetHandler
org.apache.ibatis.executor.resultset.ResultSetHandler:结果集映射接口,代码如下:
public interface ResultSetHandler {
/**
* 处理 {@link java.sql.ResultSet} 成映射的对应的结果
*
* @param stmt Statement 对象
* @param <E> 泛型
* @return 结果数组
* @throws SQLException SQL异常
*/
<E> List<E> handleResultSets(Statement stmt) throws SQLException;
/**
* 处理 {@link java.sql.ResultSet} 成 Cursor 对象
*
* @param stmt Statement 对象
* @param <E> 泛型
* @return Cursor 对象
* @throws SQLException SQL异常
*/
<E> Cursor<E> handleCursorResultSets(Statement stmt) throws SQLException;
/**
* 暂时忽略,和存储过程相关
*
* @param cs CallableStatement 对象
* @throws SQLException SQL异常
*/
void handleOutputParameters(CallableStatement cs) throws SQLException;
}
DefaultResultSetHandler
org.apache.ibatis.executor.resultset.DefaultResultSetHandler:实现ResultSetHandler接口,处理数据库的查询结果,对结果集进行映射,将结果转换成Java对象
由于该类嵌套的方法太多了,可能一个方法会有十几层的嵌套,所以本分不会进行全面的分析
因为我查看这个类的时候是从下面的方法一层一层往上看的,注释我全部添加了,所以可以参考我的注释一步一步查看
接下来的描述可能有点混乱,请按照我在方法前面表明的顺序进行查看,参考:DefaultResultSetHandler.java
先来看下DefaultResultSetHandler处理结果集的方法的流程图:
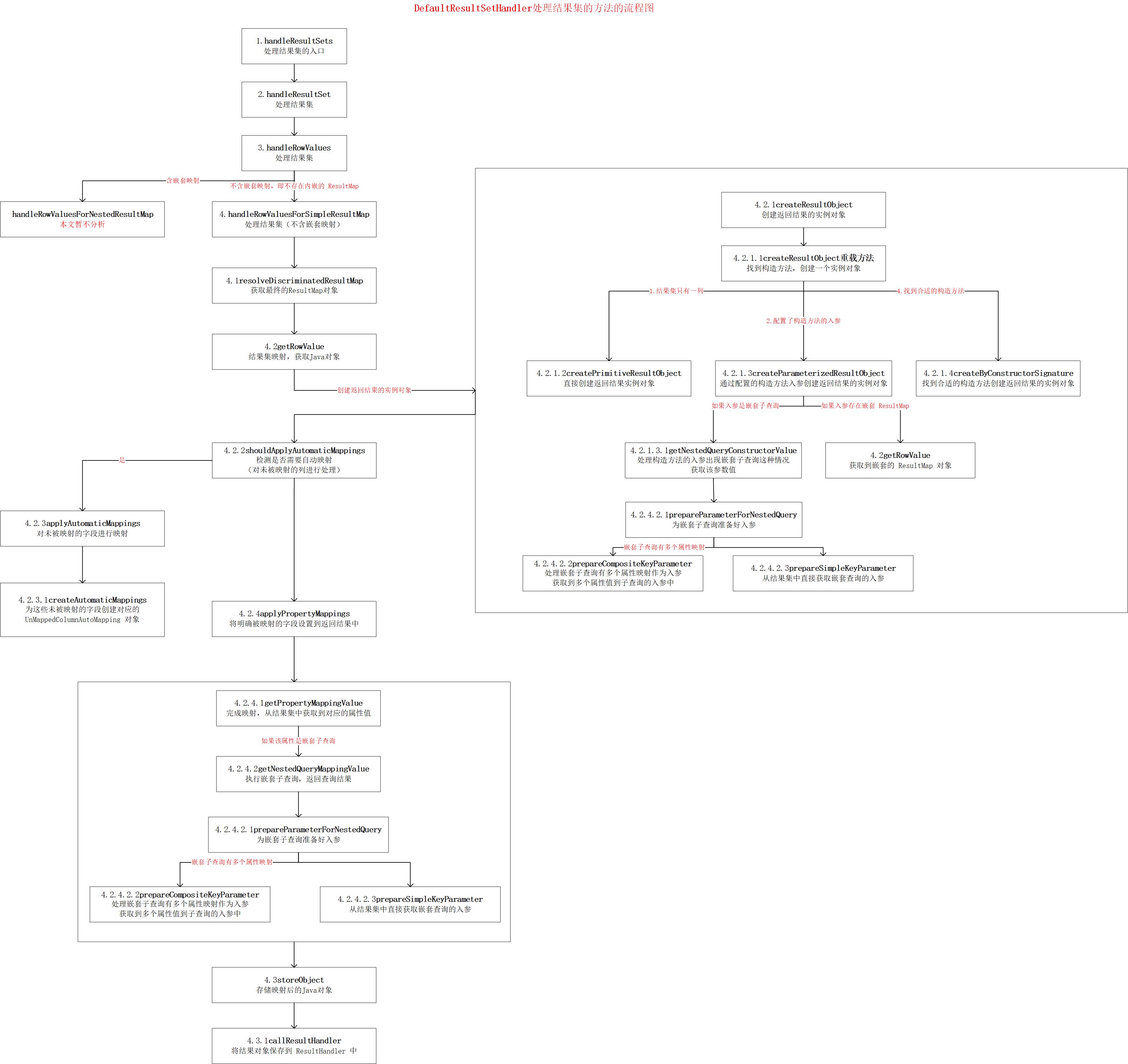
构造方法
public class DefaultResultSetHandler implements ResultSetHandler {
/**
* 延迟加载默认对象
*/
private static final Object DEFERRED = new Object();
/**
* 执行器
*/
private final Executor executor;
/**
* 全局配置对象
*/
private final Configuration configuration;
/**
* 本次查询操作对应的 MappedStatement 对象
*/
private final MappedStatement mappedStatement;
/**
* 分页对象
*/
private final RowBounds rowBounds;
/**
* 参数处理器,默认为 DefaultParameterHandler
*/
private final ParameterHandler parameterHandler;
/**
* 结果处理器,默认为 DefaultResultHandler
*/
private final ResultHandler<?> resultHandler;
/**
* SQL 相关信息
*/
private final BoundSql boundSql;
/**
* 类型处理器注册表
*/
private final TypeHandlerRegistry typeHandlerRegistry;
/**
* 对象实例工厂
*/
private final ObjectFactory objectFactory;
/**
* Reflector 工厂
*/
private final ReflectorFactory reflectorFactory;
// nested resultmaps
private final Map<CacheKey, Object> nestedResultObjects = new HashMap<>();
private final Map<String, Object> ancestorObjects = new HashMap<>();
private Object previousRowValue;
// multiple resultsets
private final Map<String, ResultMapping> nextResultMaps = new HashMap<>();
private final Map<CacheKey, List<PendingRelation>> pendingRelations = new HashMap<>();
// Cached Automappings
private final Map<String, List<UnMappedColumnAutoMapping>> autoMappingsCache = new HashMap<>();
// temporary marking flag that indicate using constructor mapping (use field to reduce memory usage)
private boolean useConstructorMappings;
public DefaultResultSetHandler(Executor executor, MappedStatement mappedStatement,
ParameterHandler parameterHandler, ResultHandler<?> resultHandler, BoundSql boundSql, RowBounds rowBounds) {
this.executor = executor;
this.configuration = mappedStatement.getConfiguration();
this.mappedStatement = mappedStatement;
this.rowBounds = rowBounds;
this.parameterHandler = parameterHandler;
this.boundSql = boundSql;
this.typeHandlerRegistry = configuration.getTypeHandlerRegistry();
this.objectFactory = configuration.getObjectFactory();
this.reflectorFactory = configuration.getReflectorFactory();
this.resultHandler = resultHandler;
}
}
- 上面的属性有点多,可以先根据注释进行理解,也可以在接下来的方法中逐步理解
1.handleResultSets方法
handleResultSets(Statement stmt)方法,处理结果集的入口
/**
* 1.处理结果集
*/
@Override
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
/*
* <1> 用于保存映射结果集得到的结果队形
* 多 ResultSet 的结果集合,每个 ResultSet 对应一个 Object 对象,而实际上,每个 Object 是 List<Object> 对象
*/
final List<Object> multipleResults = new ArrayList<>();
int resultSetCount = 0;
// <2> 获取 ResultSet 对象,并封装成 ResultSetWrapper
ResultSetWrapper rsw = getFirstResultSet(stmt);
/*
* <3> 获得当前 MappedStatement 对象中的 ResultMap 集合,XML 映射文件中 <resultMap /> 标签生成的
* 或者 配置 "resultType" 属性也会生成对应的 ResultMap 对象
* 在 <select /> 标签配置 ResultMap 属性时,可以以逗号分隔配置多个,如果返回多个 ResultSet 则会一一映射,通常配置一个
*/
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
// <4> 如果有返回结果,但是没有 ResultMap 接收对象则抛出异常
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
ResultMap resultMap = resultMaps.get(resultSetCount);
/*
* <5> 完成结果集的映射,全部转换的 Java 对象
* 保存至 multipleResults 集合中,或者 this.resultHandler 中
*/
handleResultSet(rsw, resultMap, multipleResults, null);
// 获取下一个结果集
rsw = getNextResultSet(stmt);
// 清空 nestedResultObjects 集合
cleanUpAfterHandlingResultSet();
// 递增 resultSetCount 结果集数量
resultSetCount++;
}
// <6> 获取 resultSets 多结果集属性的配置,存储过程中使用,暂时忽略
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
// 根据 resultSet 的名称,获取未处理的 ResultMapping
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
// 未处理的 ResultMap 对象
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
// 完成结果集的映射,全部转换的 Java 对象
handleResultSet(rsw, resultMap, null, parentMapping);
}
// 获取下一个结果集
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
// <7> 如果是 multipleResults 单元素,则取首元素返回
return collapseSingleResultList(multipleResults);
}
multipleResults用于保存映射结果集得到的结果队形,多 ResultSet 的结果集合,每个 ResultSet 对应一个 Object 对象,而实际上,每个 Object 是List<Object>对象获取
ResultSet对象,并封装成ResultSetWrapper获得当前 MappedStatement 对象中的
ResultMap集合,XML 映射文件中<resultMap />标签生成的,或者 配置 "resultType" 属性也会生成对应的ResultMap对象在
<select />标签配置ResultMap属性时,可以以逗号分隔配置多个,如果返回多个 ResultSet 则会一一映射,通常配置一个如果有返回结果,但是没有
ResultMap接收对象则抛出异常调用
handleResultSet方法,完成结果集的映射,全部转换的 Java 对象,保存至multipleResults集合中,或者this.resultHandler中(用户自定的,通常不会)获取 resultSets 多结果集属性的配置,存储过程中使用,暂时忽略,本文暂不分析
完成结果集映射的任务还是交给了2.handleResultSet方法
2.handleResultSet方法
handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping)方法,处理结果集
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults,
ResultMapping parentMapping) throws SQLException {
try {
if (parentMapping != null) {
// <1> 暂时忽略,因为只有存储过程的情况时 parentMapping 为非空
handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);
} else {
if (resultHandler == null) { // <2>
// <2.1> 创建 DefaultResultHandler 默认结果处理器
DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);
// <2.2> 处理结果集,进行一系列的处理,完成映射,将结果保存至 DefaultResultHandler 中
handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);
// <2.3> 将结果集合添加至 multipleResults 中
multipleResults.add(defaultResultHandler.getResultList());
} else { // 用户自定义了 resultHandler,则结果都会保存在其中
// <3> 处理结果集,进行一系列的处理,完成映射,将结果保存至 DefaultResultHandler 中
handleRowValues(rsw, resultMap, resultHandler, rowBounds, null);
}
}
} finally {
// issue #228 (close resultsets)
// <4> 关闭结果集
closeResultSet(rsw.getResultSet());
}
}
暂时忽略,因为只有存储过程的情况时 parentMapping 为非空,查看上面的1.handleResultSets方法的第
6步用户没有指定
ResultHandler结果处理器- 创建
DefaultResultHandler默认结果处理器,就是使用一个List集合保存转换后的Java对象 - 调用
handleRowValues方法,处理结果集,进行一系列的处理,完成映射,将结果保存至 DefaultResultHandler 中 - 将结果集合添加至
multipleResults中
- 创建
用户指定了自定义的
ResultHandler结果处理器,和第2步的区别在于,处理后的Java对象不会保存在multipleResults中,仅保存在ResultHandler中,用户可通过它获取关闭 ResultSet 结果集对象
通常我们不会自定义结果处理器的,所以第4步本文暂不分析,我们来看到第2步,最终还是交给了3.handleRowValues方法
3.handleRowValues方法
handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping)方法,处理结果集
public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler,
RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
/*
* <1> ResultMap 存在内嵌的 ResultMap
* 例如 <resultMap /> 标签中 <association /> 或者 <collection /> 都会创建对应的 ResultMap 对象
* 该对象的 id 会设置到 ResultMapping 的 nestedResultMapId 属性中,这就属于内嵌的 ResultMap
*/
if (resultMap.hasNestedResultMaps()) { // 存在
// <1.1> 如果不允许在嵌套语句中使用分页,则对 rowBounds 进行校验,设置了 limit 或者 offset 则抛出异常,默认允许
ensureNoRowBounds();
// <1.2> 校验要不要使用自定义的 ResultHandler,针对内嵌的 ResultMap
checkResultHandler();
// <1.3> 处理结果集,进行映射,生成返回结果,保存至 resultHandler 或者设置到 parentMapping 的对应属性中
// 这里会处理内嵌的 ResultMap
handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
} else {
// <2> 处理结果集,进行映射,生成返回结果,保存至 resultHandler 或者设置到 parentMapping 的对应属性中
handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
}
}
如果当前 ResultMap 存在内嵌的 ResultMap
例如
<resultMap />标签中<association />或者<collection />都会创建对应的 ResultMap 对象,该对象的 id 会设置到ResultMapping的nestedResultMapId属性中,这就属于内嵌的 ResultMap- 如果不允许在嵌套语句中使用分页,则对 rowBounds 进行校验,设置了 limit 或者 offset 则抛出异常,默认允许
- 校验要不要使用自定义的 ResultHandler,针对内嵌的 ResultMap
- 处理结果集,进行映射,生成返回结果,保存至
resultHandler或者设置到parentMapping(存储过程相关,本文暂不分析)的对应属性中,这里会对内嵌的 ResultMap 进行处理,调用handleRowValuesForNestedResultMap方法
处理结果集,进行映射,生成返回结果,保存至
resultHandler或者设置到parentMapping(存储过程相关,本文暂不分析)的对应属性中,调用handleRowValuesForSimpleResultMap方法
这里先来看到第2步中的4.handleRowValuesForSimpleResultMap方法,因为这个处理的情况相比第1步调用的方法简单些
4.handleRowValuesForSimpleResultMap方法
handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping)方法,处理结果集(不含嵌套映射)
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap,
ResultHandler<?> resultHandler, RowBounds rowBounds,
ResultMapping parentMapping) throws SQLException {
// 默认的上下文对象,临时保存每一行的结果且记录返回结果数量
DefaultResultContext<Object> resultContext = new DefaultResultContext<>();
ResultSet resultSet = rsw.getResultSet();
// <1> 根据 RowBounds 中的 offset 跳到到指定的记录
skipRows(resultSet, rowBounds);
// <2> 检测已经处理的行数是否已经达到上限(RowBounds.limit)以及 ResultSet 中是否还有可处理的记录
while (shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next()) {
/*
* <3> 获取最终的 ResultMap
* 因为 ResultMap 可能使用到了 <discriminator /> 标签,需要根据不同的值映射不同的 ResultMap
* 如果存在 Discriminator 鉴别器,则根据当前记录选择对应的 ResultMap,会一直嵌套处理
*/
ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(resultSet, resultMap, null);
// <4> 从结果集中获取到返回结果对象,进行映射,比较复杂,关键方法!!!
Object rowValue = getRowValue(rsw, discriminatedResultMap, null);
// <5> 将返回结果对象保存至 resultHandler,或者设置到父对象 parentMapping 的对应属性中
storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);
}
}
这里创建了一个DefaultResultContext保存结果的上下文对象,点击去你会发现有3个属性:
resultObject:暂存映射后的返回结果,因为结果集中可能有很多条数据resultCount:记录经过DefaultResultContext暂存的对象个数stopped:控制是否还进行映射
根据
RowBounds中的offset跳到到结果集中指定的记录检测已经处理的行数是否已经达到上限(
RowBounds.limit)以及ResultSet中是否还有可处理的记录调用
resolveDiscriminatedResultMap方法,获取最终的 ResultMap因为 ResultMap 可能使用到了
<discriminator />标签,需要根据不同的值映射不同的 ResultMap
如果存在Discriminator鉴别器,则根据当前记录选择对应的 ResultMap,会一直嵌套处理调用
getRowValue(ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix)方法,从结果集中获取到返回结果对象,进行映射,比较复杂,关键方法!!!调用
storeObject方法,将返回结果对象保存至resultHandler,或者设置到父对象parentMapping(存储过程相关,本文暂不分析)的对应属性中
对于第3、4、5步的三个方法,我们一个一个来看
4.1resolveDiscriminatedResultMap方法
4.2getRowValue方法
4.3storeObject方法
4.1resolveDiscriminatedResultMap方法
resolveDiscriminatedResultMap(ResultSet rs, ResultMap resultMap, String columnPrefix)方法,如果存在<discriminator />鉴别器,则进行处理,选择对应的 ResultMap,会一直嵌套处理
public ResultMap resolveDiscriminatedResultMap(ResultSet rs, ResultMap resultMap, String columnPrefix)
throws SQLException {
// 记录已经处理过的 ResultMap 的 id
Set<String> pastDiscriminators = new HashSet<>();
// <1> 获取 ResultMap 中的 Discriminator 鉴别器,<discriminator />标签会被解析成该对象
Discriminator discriminator = resultMap.getDiscriminator();
while (discriminator != null) {
// <2> 获取当前记录中该列的值,通过类型处理器转换成了对应的类型
final Object value = getDiscriminatorValue(rs, discriminator, columnPrefix);
// <3> 鉴别器根据该值获取到对应的 ResultMap 的 id
final String discriminatedMapId = discriminator.getMapIdFor(String.valueOf(value));
if (configuration.hasResultMap(discriminatedMapId)) {
// <3.1> 获取到对应的 ResultMap
resultMap = configuration.getResultMap(discriminatedMapId);
// <3.2> 记录上一次的鉴别器
Discriminator lastDiscriminator = discriminator;
// <3.3> 获取到对应 ResultMap 内的鉴别器,可能鉴别器里面还有鉴别器
discriminator = resultMap.getDiscriminator();
// <3.4> 检测是否出现循环嵌套了
if (discriminator == lastDiscriminator || !pastDiscriminators.add(discriminatedMapId)) {
break;
}
} else {
// <4> 鉴别结果没有对应的 ResultMap,则直接跳过
break;
}
}
// <5> 返回最终使用的 ResultMap 对象
return resultMap;
}
获取 ResultMap 中的
Discriminator鉴别器,<discriminator />标签会被解析成该对象调用
getDiscriminatorValue方法,获取当前记录中该列的值,通过类型处理器转换成了对应的类型,方法如下:private Object getDiscriminatorValue(ResultSet rs, Discriminator discriminator, String columnPrefix) throws SQLException {
// 获取 <discriminator />标签对应的的 ResultMapping 对象
final ResultMapping resultMapping = discriminator.getResultMapping();
// 获取 TypeHandler 类型处理器
final TypeHandler<?> typeHandler = resultMapping.getTypeHandler();
// 通过 TypeHandler 从 ResultSet 中获取该列的值
return typeHandler.getResult(rs, prependPrefix(resultMapping.getColumn(), columnPrefix));
}
Discriminator鉴别器根据该值获取到对应的 ResultMap 的 id- 存在对应的 ResultMap 对象,则获取到
- 记录上一次的鉴别器
- 获取到对应 ResultMap 内的鉴别器,可能鉴别器里面还有鉴别器
- 检测是否出现循环嵌套了
Discriminator鉴别结果没有对应的 ResultMap,则直接跳过返回最终使用的 ResultMap 对象
4.2getRowValue方法
getRowValue(ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix)方法,处理结果集
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix) throws SQLException {
// <1> 保存延迟加载的集合
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
// <2> 创建返回结果的实例对象(如果存在嵌套子查询且是延迟加载则为其创建代理对象,后续的延迟加载保存至 lazyLoader 中即可)
Object rowValue = createResultObject(rsw, resultMap, lazyLoader, columnPrefix);
/*
* <3> 如果上面创建的返回结果的实例对象不为 null,并且没有对应的 TypeHandler 类型处理器,则需要对它进行赋值
* 例如我们返回结果为 java.lang.String 就不用了,因为上面已经处理且赋值了
*/
if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
// <3.1> 将返回结果的实例对象封装成 MetaObject,便于操作
final MetaObject metaObject = configuration.newMetaObject(rowValue);
// <3.2> 标记是否成功映射了任意一个属性,useConstructorMappings 表示是否在构造方法中使用了参数映射
boolean foundValues = this.useConstructorMappings;
// <3.3> 检测是否需要自动映射
if (shouldApplyAutomaticMappings(resultMap, false)) {
/*
* <3.4> 从结果集中将未被映射的列值设置到返回结果 metaObject 中
* 返回是否映射成功,设置了1个或以上的属性值
*/
foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues;
}
/*
* <3.5> 从结果集中将 ResultMap 中需要映射的列值设置到返回结果 metaObject 中
* 返回是否映射成功,设置了1个或以上的属性值
*/
foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues;
foundValues = lazyLoader.size() > 0 || foundValues;
/*
* <3.6> 如果没有成功映射任意一个属性,则根据 returnInstanceForEmptyRow 全局配置(默认为false)返回空对象还是 null
*/
rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null;
}
// <4> 返回该结果对象
return rowValue;
}
创建一个保存延迟加载的集合
ResultLoaderMap对象lazyLoader,如果存在代理对象,创建的代理对象则需要通过它来执行需要延迟加载的方法,在后续会将到精尽MyBatis源码分析 - SQL执行过程(三)之 ResultSetHandler的更多相关文章
- 精尽MyBatis源码分析 - SQL执行过程(四)之延迟加载
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
- 精尽MyBatis源码分析 - SQL执行过程(二)之 StatementHandler
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
- 精尽 MyBatis 源码分析 - SqlSession 会话与 SQL 执行入口
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
- 精尽MyBatis源码分析 - MyBatis初始化(四)之 SQL 初始化(下)
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
- 精尽 MyBatis 源码分析 - 基础支持层
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
- 精尽MyBatis源码分析 - 插件机制
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
- 精尽MyBatis源码分析 - 文章导读
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
- MyBatis 源码篇-SQL 执行的流程
本章通过一个简单的例子,来了解 MyBatis 执行一条 SQL 语句的大致过程是怎样的. 案例代码如下所示: public class MybatisTest { @Test public void ...
- 精尽MyBatis源码分析 - MyBatis-Spring 源码分析
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
随机推荐
- IntelliJ IDEA 2020.2 x64 激活 2020-09-18亲测有效
idea 激活,查阅许多资源和文章,激活码都失效,无意发现该资源(https://macwk.com/article/jetbrains-crack),亲测有效(2020-09-18),在此记录,以备 ...
- nginx负载均衡常见问题配置信息
nginx为后端web服务器(apache,nginx,tomcat,weblogic)等做反向代理 几台后端web服务器需要考虑文件共享,数据库共享,session共享问题.文件共享可以使用nfs, ...
- AWS Lambda 借助 Serverless Framework,迅速起飞
前言 微服务架构有别于传统的单体式应用方案,我们可将单体应用拆分成多个核心功能.每个功能都被称为一项服务,可以单独构建和部署,这意味着各项服务在工作时不会互相影响 这种设计理念被进一步应用,就变成了无 ...
- nacos 作为配置中心使用心得--配置使用
1.页面配置 撇开原理不谈,先来介绍下nacos的基本使用,如下图nacos配置是以data id为单位进行使用的,基本上一个服务的一个配置文件就对应一个data id,支持的格式有xml,yaml, ...
- 深入理解golang:内存分配原理
一.Linux系统内存 在说明golang内存分配之前,先了解下Linux系统内存相关的基础知识,有助于理解golang内存分配原理. 1.1 虚拟内存技术 在早期内存管理中,如果程序太大,超过了空闲 ...
- Java的Arrays.sort()方法到底用的什么排序算法
暂时网上看过很多JDK8中Arrays.sort的底层原理,有些说是插入排序,有些说是归并排序,也有说大于域值用计数排序法,否则就使用插入排序...其实不全对.让我们分析个究竟: 1 // Use Q ...
- (3)ASP.NET Core3.1 Ocelot认证
1.认证 当客户端通过Ocelot访问下游服务的时候,为了保护下游资源服务器会进行认证鉴权,这时候需要在Ocelot添加认证服务.添加认证服务后,随后使用Ocelot基于声明的任何功能,例如授权或使用 ...
- Mongoose Guide(转)
转自:http://www.w3c.com.cn/mongoose-guide Queries 文件可以通过一些静态辅助模型的方法检索. 任何涉及 指定 查询 条件的模型方法,有两种执行的方式: 当一 ...
- layui表单提交
关于layui表单提交 只是简单用一个文本框记录一下提交过程 其他的如下拉框选择框样式可以参考官网 下面直接开始.首 一:前台页面 <!DOCTYPE html><html& ...
- C/C++中内存对齐问题的一些理解(转)
内存对齐指令 一般来说,内存对齐过程对coding者来说是透明的,是由编译器控制完成的 如对内存对齐有明确要求,可用#pragma pack(n)指定,以n和结构体中最长数据成员长度中较小者为有效值 ...
- 精尽MyBatis源码分析 - SQL执行过程(四)之延迟加载