SSD训练网络参数计算
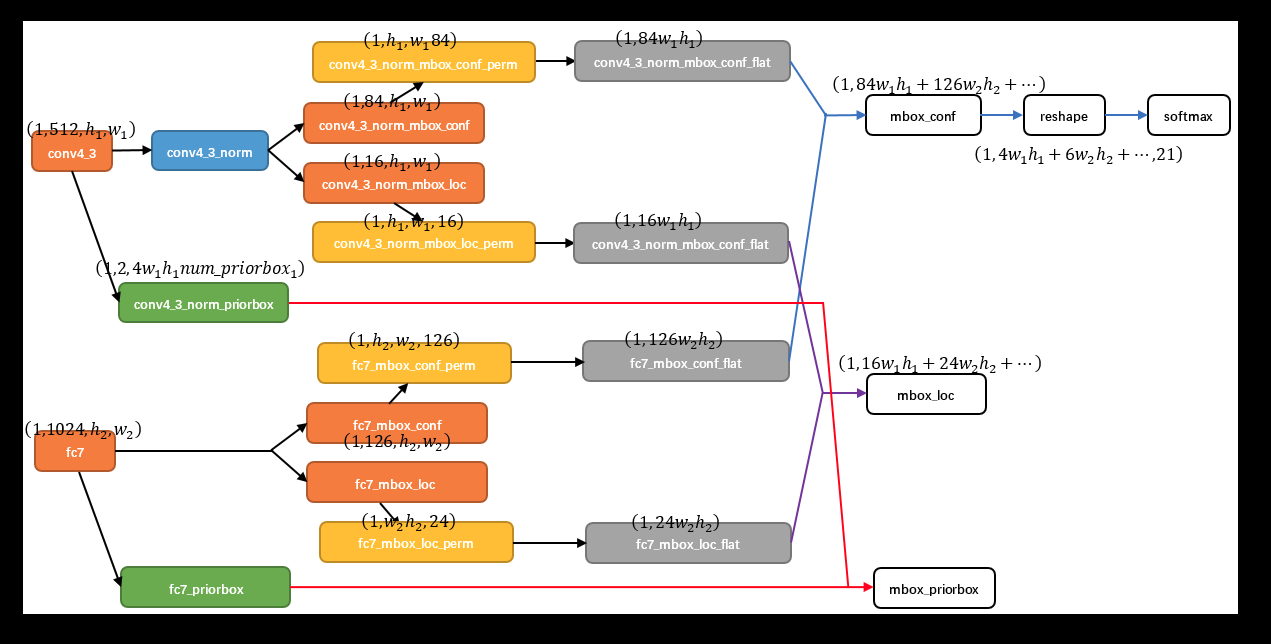
一个预测层的网络结构如下所示:
可以看到,是由三个分支组成的,分别是"PriorBox"层,以及conf、loc的预测层,其中,conf与loc的预测层的参数是由PriorBox的参数计算得到的,具体计算公式如下:
min_size与max_size分别对应一个尺度的预测框(有几个就对应几个预测框),in_size只管自己的预测,而max_size是与aspect_ratio联系在一起的;
filp参数是对应aspect_ratio的预测框*2,以几个max_size,再乘以几;最终得到结果为A
conf、loc的参数是在A的基础上再乘以类别数(加背景),以及4
如下,是需要预测两类的其中一个尺度的网络参数;
如上算出的是,每个格子需要预测的conf以及loc的个数;
每个预测层有H*W个格子,因此,总共预测的loc以及conf的个数是需要乘以H*W的;
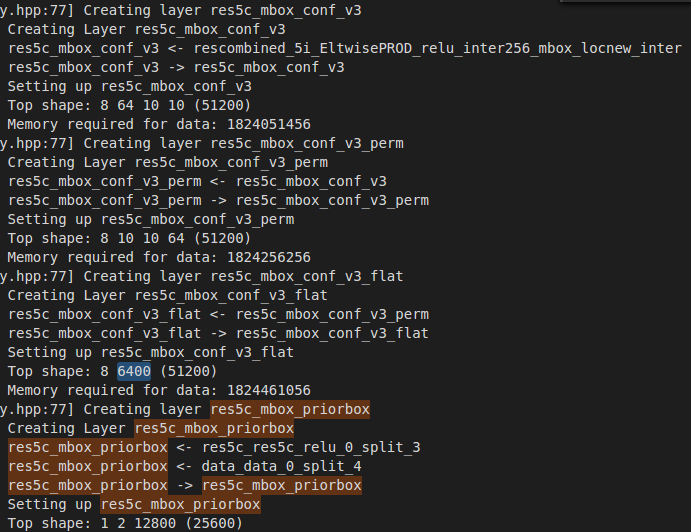
如下是某一个层的例子(转自:http://www.360doc.com/content/17/1013/16/42392246_694639090.shtml)

注意最后这里的num_priorbox的值与前面的并不一样,这里是每个预测层所有的输出框的个数:

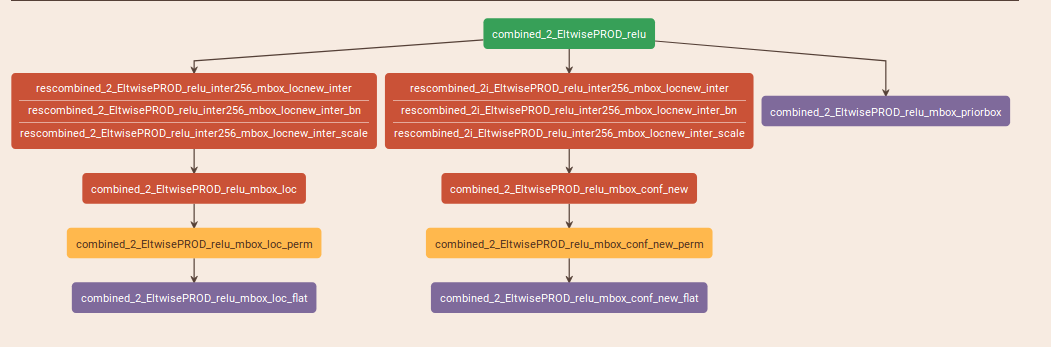
layer {
name: "combined_2_EltwisePROD_relu"
type: "ReLU"
bottom: "combined_2_EltwisePROD"
top: "combined_2_EltwisePROD_relu"
}
###########################################
###################################################################
layer {
name: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter"
type: "Convolution"
bottom: "combined_2_EltwisePROD_relu"
top: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter"
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
stride:
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter_bn"
type: "BatchNorm"
bottom: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter"
top: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
batch_norm_param {
moving_average_fraction: 0.999
eps: 0.001
}
}
layer {
name: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter_scale"
type: "Scale"
bottom: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter"
top: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
scale_param {
filler {
type: "constant"
value: 1.0
}
bias_term: true
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter"
type: "Convolution"
bottom: "combined_2_EltwisePROD_relu"
top: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter"
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
stride:
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter_bn"
type: "BatchNorm"
bottom: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter"
top: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
batch_norm_param {
moving_average_fraction: 0.999
eps: 0.001
}
}
layer {
name: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter_scale"
type: "Scale"
bottom: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter"
top: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
scale_param {
filler {
type: "constant"
value: 1.0
}
bias_term: true
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "combined_2_EltwisePROD_relu_mbox_loc"
type: "Convolution"
bottom: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter"
top: "combined_2_EltwisePROD_relu_mbox_loc"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
engine: CAFFE
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value:
}
}
}
layer {
name: "combined_2_EltwisePROD_relu_mbox_loc_perm"
type: "Permute"
bottom: "combined_2_EltwisePROD_relu_mbox_loc"
top: "combined_2_EltwisePROD_relu_mbox_loc_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "combined_2_EltwisePROD_relu_mbox_loc_flat"
type: "Flatten"
bottom: "combined_2_EltwisePROD_relu_mbox_loc_perm"
top: "combined_2_EltwisePROD_relu_mbox_loc_flat"
flatten_param {
axis:
}
}
layer {
name: "combined_2_EltwisePROD_relu_mbox_conf_new"
type: "Convolution"
bottom: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter"
top: "combined_2_EltwisePROD_relu_mbox_conf_new"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
engine: CAFFE
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value:
}
}
}
layer {
name: "combined_2_EltwisePROD_relu_mbox_conf_new_perm"
type: "Permute"
bottom: "combined_2_EltwisePROD_relu_mbox_conf_new"
top: "combined_2_EltwisePROD_relu_mbox_conf_new_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "combined_2_EltwisePROD_relu_mbox_conf_new_flat"
type: "Flatten"
bottom: "combined_2_EltwisePROD_relu_mbox_conf_new_perm"
top: "combined_2_EltwisePROD_relu_mbox_conf_new_flat"
flatten_param {
axis:
}
}
layer {
name: "combined_2_EltwisePROD_relu_mbox_priorbox"
type: "PriorBox"
bottom: "combined_2_EltwisePROD_relu"
bottom: "data"
top: "combined_2_EltwisePROD_relu_mbox_priorbox"
prior_box_param {
min_size: 12.0
min_size: 6.0
max_size: 30.0
max_size: 20.0
aspect_ratio:
aspect_ratio: 2.5
aspect_ratio:
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
step:
offset: 0.5
}
}
SSD训练网络参数计算的更多相关文章
- LeNet-5网络结构及训练参数计算
经典神经网络诞生记: 1.LeNet,1998年 2.AlexNet,2012年 3.ZF-net,2013年 4.GoogleNet,2014年 5.VGG,2014年 6.ResNet,201 ...
- 『计算机视觉』Mask-RCNN_训练网络其二:train网络结构&损失函数
Github地址:Mask_RCNN 『计算机视觉』Mask-RCNN_论文学习 『计算机视觉』Mask-RCNN_项目文档翻译 『计算机视觉』Mask-RCNN_推断网络其一:总览 『计算机视觉』M ...
- CNN网络参数
卷积神经网络 LeNet-5各层参数详解 LeNet论文阅读:LeNet结构以及参数个数计算 LeNet-5共有7层,不包含输入,每层都包含可训练参数:每个层有多个Feature Map,每个 ...
- pytorch和tensorflow的爱恨情仇之定义可训练的参数
pytorch和tensorflow的爱恨情仇之基本数据类型 pytorch和tensorflow的爱恨情仇之张量 pytorch版本:1.6.0 tensorflow版本:1.15.0 之前我们就已 ...
- 『计算机视觉』Mask-RCNN_训练网络其三:训练Model
Github地址:Mask_RCNN 『计算机视觉』Mask-RCNN_论文学习 『计算机视觉』Mask-RCNN_项目文档翻译 『计算机视觉』Mask-RCNN_推断网络其一:总览 『计算机视觉』M ...
- 『计算机视觉』Mask-RCNN_训练网络其一:数据集与Dataset类
Github地址:Mask_RCNN 『计算机视觉』Mask-RCNN_论文学习 『计算机视觉』Mask-RCNN_项目文档翻译 『计算机视觉』Mask-RCNN_推断网络其一:总览 『计算机视觉』M ...
- 卷积神经网络(CNN)张量(图像)的尺寸和参数计算(深度学习)
分享一些公式计算张量(图像)的尺寸,以及卷积神经网络(CNN)中层参数的计算. 以AlexNet网络为例,以下是该网络的参数结构图. AlexNet网络的层结构如下: 1.Input: 图 ...
- 关于LeNet-5卷积神经网络 S2层与C3层连接的参数计算的思考???
https://blog.csdn.net/saw009/article/details/80590245 关于LeNet-5卷积神经网络 S2层与C3层连接的参数计算的思考??? 首先图1是LeNe ...
- caffe 网络参数设置
weight_decay防止过拟合的参数,使用方式: 样本越多,该值越小 模型参数越多,该值越大 一般建议值: weight_decay: 0.0005 lr_mult, decay_mult 关于偏 ...
随机推荐
- QT中为程序加入超级管理员权限
QT的一些文件操作,注册表的操作等,有些操作会无效,主要是因为没有对C盘的相关权限. 解决方法: 1. mingw编译器 在pro工程文件中加入 RC_FILE=main.rc rc文件,之前一篇博客 ...
- redis 用scan 代替keys,hgetAll
转载自:https://blog.csdn.net/w05980598/article/details/80264568 众所周知,当redis中key数量越大,keys 命令执行越慢,而且最重要的会 ...
- HTTP中GET请求与POST请求的区别
GET和POST是HTTP请求的两种基本方法.最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数.但这只是表象,或者说只是现象,并不是核心.本文将细细谈谈对它们的 ...
- ctf密码学------密文解码python脚本(凯撒解密)
题目来源实验吧 分析题意,说是困在栅栏中,所以将字符栅栏解密看看有什么,利用工具CTFcraktools 得到三条密文 然后说是密码是凯撒,在将四栏依次凯撒解码,寻找可能的key,这里很显然,在尝试第 ...
- 微信小程序:undefined Expecting 'STRING', got INVALID
出现问题: 问题原因:app.json中不能出现注释
- 手写web框架之实现依赖注入功能
我们在Controller中定义了Service成员变量,然后在Controller的Action方法中调用Service成员变量的方法,那么如果实现Service的成员变量? 之前定义了@Injec ...
- elk收集tomcat的日志
logstash收集tomcat的日志 不要修改下tomcat中server.xml的日志格式,否则tomcat无法启动,试过多次,不行,就用自带的日志让logstash去收集 首先给tomcat日志 ...
- flask(1.1)装饰器装饰多个视图函数出现的问题
目录 1.装饰器装饰多个视图函数出现的问题 2.使用装饰器修复技术解决该问题 1.装饰器装饰多个视图函数出现的问题 代码实例: from flask import Flask, request, re ...
- 【笔记】《CNCF × Alibaba云原生技术公开课》知识点
一,课时1:第一堂“云原生”课 二,课时2:容器基本概念 1.已运行 docker run -d -t —name demo ubuntu top 命令, 是否可以在 demo 这个容器内部停止容器? ...
- swagger-注解
常用注解 @Api(value = "xxx"):用于类,表示标识这个类是swagger的资源. tags–表示说明,如果有多个值,会生成多个list value–也是说明,可以使 ...