BPTT
RNN 的 BP —— Back Propagation Through Time.

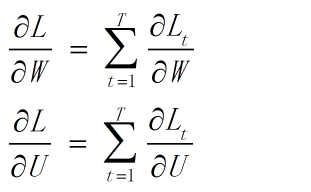
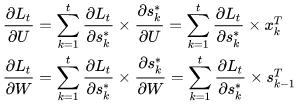
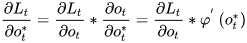

- 1 def backward(self, sensitivity_array,
- activator):
- '''
- 实现BPTT算法
- '''
- self.calc_delta(sensitivity_array, activator)
- self.calc_gradient()
- def calc_delta(self, sensitivity_array, activator):
- self.delta_list = [] # 用来保存各个时刻的误差项
- for i in range(self.times):
- self.delta_list.append(np.zeros(
- (self.state_width, 1)))
- self.delta_list.append(sensitivity_array)
- # 迭代计算每个时刻的误差项
- for k in range(self.times - 1, 0, -1):
- self.calc_delta_k(k, activator)
- def calc_delta_k(self, k, activator):
- '''
- 根据k+1时刻的delta计算k时刻的delta
- '''
- state = self.state_list[k+1].copy()
- element_wise_op(self.state_list[k+1],
- activator.backward)
- self.delta_list[k] = np.dot(
- np.dot(self.delta_list[k+1].T, self.W),
- np.diag(state[:,0])).T
- def calc_gradient(self):
- self.gradient_list = [] # 保存各个时刻的权重梯度
- for t in range(self.times + 1):
- self.gradient_list.append(np.zeros(
- (self.state_width, self.state_width)))
- for t in range(self.times, 0, -1):
- self.calc_gradient_t(t)
- # 实际的梯度是各个时刻梯度之和
- self.gradient = reduce(
- lambda a, b: a + b, self.gradient_list,
- self.gradient_list[0]) # [0]被初始化为0且没有被修改过
- def calc_gradient_t(self, t):
- '''
- 计算每个时刻t权重的梯度
- '''
- gradient = np.dot(self.delta_list[t],
- self.state_list[t-1].T)
- self.gradient_list[t] = gradient
- class RNN2(RNN1):
- # 定义 Sigmoid 激活函数
- def activate(self, x):
- return 1 / (1 + np.exp(-x))
- # 定义 Softmax 变换函数
- def transform(self, x):
- safe_exp = np.exp(x - np.max(x))
- return safe_exp / np.sum(safe_exp)
- def bptt(self, x, y):
- x, y, n = np.asarray(x), np.asarray(y), len(y)
- # 获得各个输出,同时计算好各个 State
- o = self.run(x)
- # 照着公式敲即可 ( σ'ω')σ
- dis = o - y
- dv = dis.T.dot(self._states[:-1])
- du = np.zeros_like(self._u)
- dw = np.zeros_like(self._w)
- for t in range(n-1, -1, -1):
- st = self._states[t]
- ds = self._v.T.dot(dis[t]) * st * (1 - st)
- # 这里额外设定了最多往回看 10 步
- for bptt_step in range(t, max(-1, t-10), -1):
- du += np.outer(ds, x[bptt_step])
- dw += np.outer(ds, self._states[bptt_step-1])
- st = self._states[bptt_step-1]
- ds = self._w.T.dot(ds) * st * (1 - st)
- return du, dv, dw
- def loss(self, x, y):
- o = self.run(x)
- return np.sum(
- -y * np.log(np.maximum(o, 1e-12)) -
- (1 - y) * np.log(np.maximum(1 - o, 1e-12))
- )
BPTT的更多相关文章
- BPTT算法推导
随时间反向传播 (BackPropagation Through Time,BPTT) 符号注解: \(K\):词汇表的大小 \(T\):句子的长度 \(H\):隐藏层单元数 \(E_t\):第t个时 ...
- RNN 入门教程 Part 3 – 介绍 BPTT 算法和梯度消失问题
转载 - Recurrent Neural Networks Tutorial, Part 3 – Backpropagation Through Time and Vanishing Gradien ...
- Recurrent Neural Network系列3--理解RNN的BPTT算法和梯度消失
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 这是RNN教程的第三部分. 在前面的教程中,我们从头实现了一个循环 ...
- 机器学习 —— 基础整理(八)循环神经网络的BPTT算法步骤整理;梯度消失与梯度爆炸
网上有很多Simple RNN的BPTT(Backpropagation through time,随时间反向传播)算法推导.下面用自己的记号整理一下. 我之前有个习惯是用下标表示样本序号,这里不能再 ...
- BPTT for multiple layers
单层rnn的bptt: 每一个时间点的误差进行反向传播,然后将delta求和,更新本层weight. 多层时: 1.时间1:T 分层计算activation. 2.时间T:1 利用本时间点的误差,分层 ...
- 循环神经网络-极其详细的推导BPTT
首先明确一下,本文需要对RNN有一定的了解,而且本文只针对标准的网络结构,旨在彻底搞清楚反向传播和BPTT. 反向传播形象描述 什么是反向传播?传播的是什么?传播的是误差,根据误差进行调整. 举个例子 ...
- LSTM简介以及数学推导(FULL BPTT)
http://blog.csdn.net/a635661820/article/details/45390671 前段时间看了一些关于LSTM方面的论文,一直准备记录一下学习过程的,因为其他事儿,一直 ...
- Deep Learning基础--随时间反向传播 (BackPropagation Through Time,BPTT)推导
1. 随时间反向传播BPTT(BackPropagation Through Time, BPTT) RNN(循环神经网络)是一种具有长时记忆能力的神经网络模型,被广泛用于序列标注问题.一个典型的RN ...
- Backpropagation Through Time (BPTT) 梯度消失与梯度爆炸
Backpropagation Through Time (BPTT) 梯度消失与梯度爆炸 下面的图显示的是RNN的结果以及数据前向流动方向 假设有 \[ \begin{split} h_t & ...
随机推荐
- vue+element ui 重置表单
<el-dialog :title="addForm.title" :visible.sync="dialogFormVisible" width=&qu ...
- 消息中间件RabbitMq的代码使用案例
消费者: ---------------------- 构造初始化: public RabbitMqReceiver(String host, int port, String username, S ...
- tinymce 中我输入的内容 清空问题
<tinymce v-model="formItem.hDtContent" ref="content" @accessory="handlea ...
- Spring4学习回顾之路02—IOC&DI
IOC&DI介绍 ●IOC:(Inversion of Control) :控制反转(反向获取资源) 其思想是反转资源获取的方向.传统的资源上查找方式要求组件向容器发起请求查找资源,作为回应, ...
- 老贾的幸福生活day03 之思维导图
思维导图 层级关系 从大范围到具体 编程语言 编译型 C C++ ...... 解释型 python php ......... python 基础语法 基础数据类 ...
- js,bom,dom(相信我,你看不懂我写的)
js dom bom 2种结合方式: 1.在body中加入script标签,<script type="text/javascript" >alert(" 向 ...
- linux lkm rootkit常用技巧
简介 搜集一下linux lkm rootkit中常用的一些技巧 1.劫持系统调用 遍历地址空间 根据系统调用中的一些导出函数,比如sys_close的地址来寻找 unsigned long ** g ...
- T100-----汇出EXCEL表格
例子:cxmp541 #excel匯出功能 ON ACTION exporttoexcel LET g_action_choice="exporttoexcel" IF cl_au ...
- iview给布局MenuItem标签绑定点击事件
@click.native="menuHandleClick"
- python-open函数
open函数,该函数用于文件处理 操作文件时,一般需要经历如下步骤: 打开文件 操作文件 一.打开文件 1 文件句柄 = open('文件路径', '模式') 打开文件时,需要指定文件路径和以何等方式 ...