Bilateral Multi-Perspective Matching for Natural Language Sentences---读书笔记
- 自然语言句子的双向、多角度匹配,是来自IBM 2017 年的一篇文章。代码github地址:https://github.com/zhiguowang/BiMPM
- 摘要
- 自然语言句子匹配(Natural language sentence matching ,NLSM)是比较两个句子并且识别它们的关系的任务。
- NLSM 一般有两种架构来解决:
- BiMPM 属于 匹配聚合框架。
- 之前的 匹配聚合框架的局限性:
- BiMPM 对以上的两个局限性进行了改进。
- 任务的定义:
- BiMPM 架构图

- word representstion layer(词表达层):
- context representation layer(上下文表达层):
- matching layer(匹配层)
- aggregation layer(聚合层):
- prediction layer(预测层):
- Multi-perspective Matching Operation(多角度匹配操作):
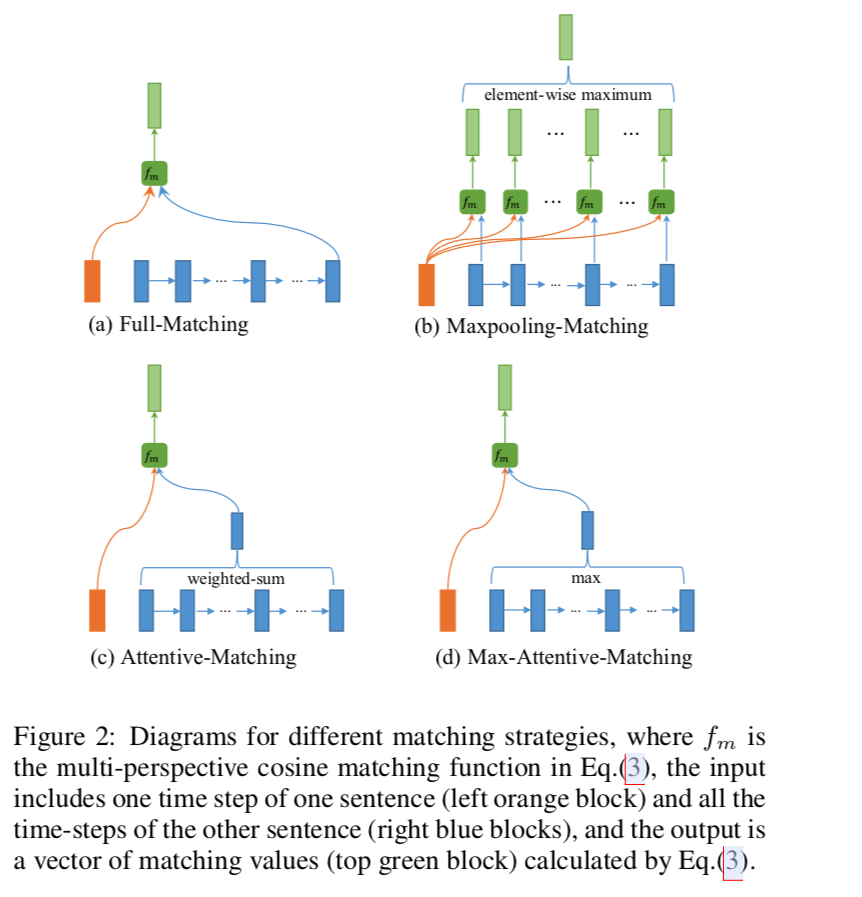
- 实验参数设置:
- Quora Question Pairs(https://www.kaggle.com/quora/question-pairs-dataset)
- quora dataset 训练/验证/测试集的选取
Bilateral Multi-Perspective Matching for Natural Language Sentences---读书笔记的更多相关文章
- 《Bilateral Multi-Perspective Matching for Natural Language Sentences》(句子匹配)
问题: Natural language sentence matching (NLSM),自然语言句子匹配,是指比较两个句子并判断句子间关系,是许多任务的一项基本技术.针对NLSM任务,目前有两种流 ...
- BiMPM:Bilateral Multi-Perspctive Matching for Natural Language Sentences
导言 本论文的工作主要是在 'matching-aggregation'的sentence matching的框架下,通过增加模型的特征(实现P与Q的双向匹配和多视角匹配),来增加NLSM(Natur ...
- Convolutional Neural Network Architectures for Matching Natural Language Sentences
interaction n. 互动;一起活动;合作;互相影响 capture vt.俘获;夺取;夺得;引起(注意.想像.兴趣)n.捕获;占领;捕获物;[计算机]捕捉 hence adv. 从此;因 ...
- 《Convolutional Neural Network Architectures for Matching Natural Language Sentences》句子匹配
模型结构与原理 1. 基于CNN的句子建模 这篇论文主要针对的是句子匹配(Sentence Matching)的问题,但是基础问题仍然是句子建模.首先,文中提出了一种基于CNN的句子建模网络,如下图: ...
- 《The C Programming Language》读书笔记(一)
1. 对这本书的印象 2011年进入大学本科,C语言入门书籍如果我没记错的话应该是谭浩强的<C程序设计>,而用现在的眼光来看,这本书只能算是一本可用的教材,并不能说是一本好书.在自学操作系 ...
- 《PC Assembly Language》读书笔记
本书下载地址:pcasm-book. 前言 8086处理器只支持实模式(real mode),不能满足安全.多任务等需求. Q:为什么实模式不安全.不支持多任务?为什么虚模式能解决这些问题? A: 以 ...
- Parsing Natural Scenes and Natural Language with Recursive Neural Networks-paper
Parsing Natural Scenes and Natural Language with Recursive Neural Networks作者信息: Richard Socher richa ...
- <Natural Language Processing with Python>学习笔记一
Spoken input (top left) is analyzed, words are recognized, sentences are parsed and interpreted in c ...
- (zhuan) Speech and Natural Language Processing
Speech and Natural Language Processing obtain from this link: https://github.com/edobashira/speech-l ...
随机推荐
- python_模块2
1.sys模块 import sys # 获取一个值的应用计数 a = [11,22,33] b = a print(sys.getrefcount(a)) # python默认支持的递归数量 v1 ...
- SEERC 2018 B. Broken Watch (CDQ分治)
题目链接:http://codeforces.com/gym/101964/problem/B 题意:q 种操作,①在(x,y)处加一个点,②加一个矩阵{(x1,y1),(x2,y2)},问每次操作后 ...
- 第二章 C#语法快速热身
C#语法快速热身 语法 if(条件表达式){ 代码块 } 语法 if(条件表达式){ 代码块 }else{ 代码块2 } 语法 if(条件表达式1){ 代码块1 if(条件表达式1)){ }else{ ...
- 现在有没有一种富文本编辑器能够直接从 word 中复制粘贴公式的?
tinymce是很优秀的一款富文本编辑器,可以去官网下载.https://www.tiny.cloud 这里分享的是它官网的一个收费插件powerpaste的旧版本源码,但也不影响功能使用. http ...
- CF796D Police Stations BFS+染色
题意:给定一棵树,树上有一些点是警察局,要求所有点到最近的警察局的距离不大于 $d$,求最多能删几条边 ? 题解: 考虑什么时候一条边可以被断开:这条边的两个端点被两个不同的警察局覆盖掉. 我们要设计 ...
- pwrite,pread
pwrite,pread,在多线程中读写文件使用,将lseek 和read 或write 合为一个原子操作(在执行的时候不会失去CPU). ssize_t pwrite(intfd, const vo ...
- appium测试android环境搭建(win7)
第一步:安装appium 1. 下载并安装Node.js(地址:https://nodejs.org/download/) 2. 下载git, 并且配置环境变量:(之前没有配置git, 报错找不到gi ...
- php安装扩展的地址
1 查看扩展 phpinfo or extention_loads or php -m 下载扩展地址 http://pecl.php.net or http://windows.php.n ...
- PostMan的详细介绍
无论是接口调试还是接口测试,postman都算的上很优秀的工具,好多接口测试平台.接口测试工具框架的设计也都能看到postman的影子,我们真正了解了这款工具,才可以在这个基础上进行自己的设计和改造. ...
- c#简单的SQLHelp
public abstract class SQLHelper { //只读的静态数据库连接字符串 //需添加引用System.Configuration; public static readonl ...