希尔排序——C语言
希尔排序
希尔排序是插入排序的一种,又称“缩小增量排序”,希尔排序是直接插入排序算法的一种更高效的改进版本,关于插入排序可以看下这篇随笔:插入排序——C语言


(图片来源:https://www.cnblogs.com/fivestudy/p/10212306.html)
1、希尔排序的基本思想:
设待排序元素序列有n个元素,首先取一个整数increment(小于n)作为间隔将全部元素分为n/increment个子序列,所有距离为increment的元素放在同一个子序列中,在每一个子序列中分别实行直接插入排序,然后缩小间隔increment,重复上述子序列划分和排序工作,直到最后取increment=1,将所有元素放在同一个子序列中排序为止,该方法实质上是一种分组插入方法
{1,2,4,8,...}这种序列并不是很好的增量序列,使用这个增量序列的时间复杂度(最坏情形)是O(n^2)
Hibbard提出了另一个增量序列{1,3,7,...,2^k-1},这种序列的时间复杂度(最坏情形)为O(n^1.5)
Sedgewick提出了几种增量序列,其最坏情形运行时间为O(n^1.3),其中最好的一个序列是{1,5,19,41,109,...}
3、代码实现
/* 希尔排序*/
int num[] = {, , , , };
int cur;
int i, j;
int length = sizeof(num)/sizeof(num[]);
int incre; incre = length / ; while (incre >= )
{
for (i = incre; i < length; i++)
{
cur = num[i]; //待排序元素
for (j = i - incre; j >= && num[j] > cur; j = j - incre)
{
num[j + incre] = num[j]; //元素向后移动
}
num[j + incre] = cur; //插入待排序元素
}
incre = incre / ; //增量减半
}
while里面的代码其实和插入排序的代码没多大区别,就是在两个for循环外面套了一个while再修改了一下内部的for循环,可以对照看一下下面列出来的插入排序的for循环
for (i = ; i < length; i++)
{
cur = num[i]; //待排序元素
for (j = i - ; j >= && num[j] > cur; j--)
{
num[j + ] = num[j];
}
num[j + ] = cur;
}
4、排序过程(以5,7,8,3,1,2,4,6为例)


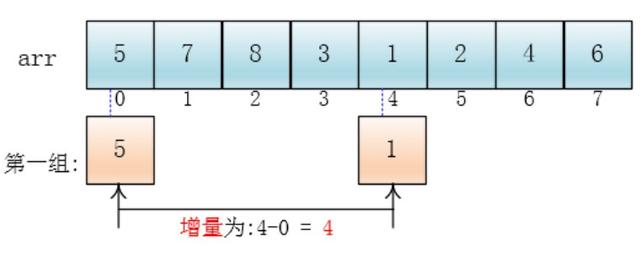
每个分组进行插入排序后,各个分组就变成了有序的了(整体不一定有序)

此时,整个数组变的部分有序了(有序程度可能不是很高)
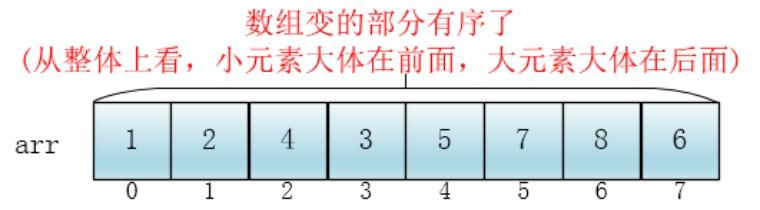
然后缩小增量为上个增量的一半:2,继续划分分组,此时,每个分组元素个数多了,但是,数组变的部分有序了,插入排序效率同样比高
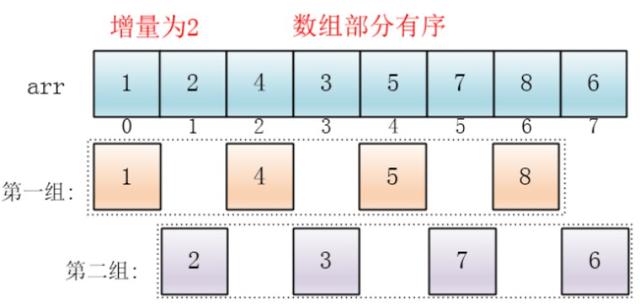
同理对每个分组进行排序(插入排序),使其每个分组各自有序
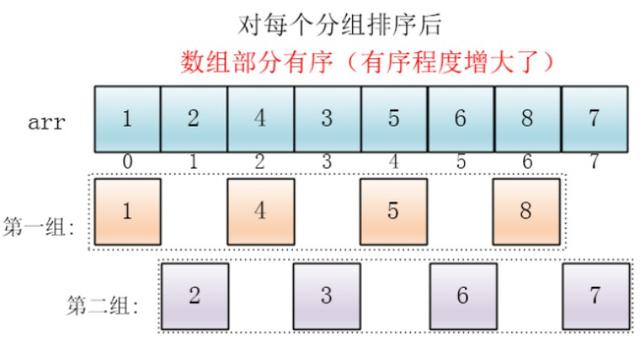
最后设置增量为上一个增量的一半:1,则整个数组被分为一组,此时,整个数组已经接近有序了,插入排序效率高
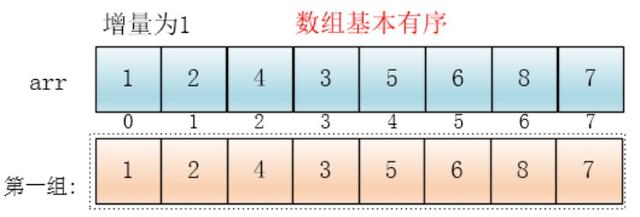
同理,对这仅有的一组数据进行排序,排序完成
(图片来源:https://blog.csdn.net/qq_39207948/article/details/80006224)
参考链接:
希尔排序——C语言的更多相关文章
- [数据结构] 希尔排序 C语言程序
//由小到大 //希尔排序 void shellSort( long int array[], int length) { int i; int j; int k; int gap; //gap是分组 ...
- 希尔排序(Shell's Sort)的C语言实现
原创文章,转载请注明来自钢铁侠Mac博客http://www.cnblogs.com/gangtiexia 希尔排序(Shell's Sort)又称“缩小增量排序”(Diminishing Incre ...
- 排序(4)---------希尔(shell)排序(C语言实现)
由于考试耽搁了几天,不好意思~~~ 前面的介绍的三种排序算法,都属于简单排序,大家能够看下详细算法,时间复杂度基本都在0(n^2),这样呢,非常多计算机界.数学界的牛人就非常不爽了,他们在家里想啊想, ...
- 深入浅出数据结构C语言版(17)——希尔排序
在上一篇博文中我们提到:要令排序算法的时间复杂度低于O(n2),必须令算法执行"远距离的元素交换",使得平均每次交换减少不止1逆序数. 而希尔排序就是"简单地" ...
- c语言希尔排序,并输出结果(不含插入排序)
#include<stdio.h> void shellsort(int* data,int len) { int d=len; int i; ) { d=(d+)/; //增量序列表达方 ...
- 算法分析中最常用的几种排序算法(插入排序、希尔排序、冒泡排序、选择排序、快速排序,归并排序)C 语言版
每次开始动手写算法,都是先把插入排序,冒泡排序写一遍,十次有九次是重复的,所以这次下定决心,将所有常规的排序算法写了一遍,以便日后熟悉. 以下代码总用一个main函数和一个自定义的CommonFunc ...
- C语言实例解析精粹学习笔记——43(希尔排序)
实例说明: 用希尔排序方法对数组进行排序.由于书中更关注的实例,对于原理来说有一定的解释,但是对于第一次接触的人来说可能略微有些简略.自己在草稿纸上画了好久,后来发现网上有好多很漂亮的原理图. 下面将 ...
- C语言中的排序算法--冒泡排序,选择排序,希尔排序
冒泡排序(Bubble Sort,台湾译为:泡沫排序或气泡排序)是一种简单的排序算法.它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.走访数列的工作是重复地进行直到没 ...
- C语言实现 冒泡排序 选择排序 希尔排序
// 冒泡排序 // 选择排序 // 希尔排序 // 快速排序 // 递归排序 // 堆排序 #define _CRT_SECURE_NO_WARNINGS #include <stdio.h& ...
随机推荐
- Hadoop 安装(本地、伪分布、分布式模式)
本地模式 环境介绍 一共三台测试机 master 192.168.4.91 slave1 192.168.4.45 slave2 192.168.4.96 操作系统配置 1.Centos7 ...
- linux 安装nginx -查看 linux的环境变量
我发现在linux上面安装linux很简单 在CentOS release 6.5 上面先看一下操作系统的版本: lsb_release -a 直接执行 yum install nginx 系统自动的 ...
- [游戏开发]LÖVE2D(1):引擎介绍
什么是LÖVE引擎 Love引擎是一个非常棒的框架,你可以用来在Lua制作2D游戏.它是免费的,开源的,适用于Windows,Mac OS X,Linux,Android和iOS. 怎么安装 在官网下 ...
- 为什么要装Tomcat?
来说一说C/S架构和B/S架构 先来说说为什么C/S框架不用对tomcat之类的部署? 其中主要的原因在与这种结构本身就是有服务器来提供服务的,客户端来使用服务. 再者说为什么B/S架构要 ...
- new HttpClient().PostAsync封装参数
var data = Encoding.UTF8.GetBytes("{ \"y\": 5, \"x\": 3}"); var conten ...
- Error: unable to load xmlsec-openssl library
yum install libxml2-devel xmlsec1-devel xmlsec1-openssl-devel libtool-ltdl-devel
- Keil MDK 5代码补全功能设置
这段时间在用Keil5编程,经常会遇到在程序文件头部定义一个全局变量.在后面的编程过程中,经常会要用到这个变量,如果每次再打这个变量名会特别麻烦和浪费时间,我就想着Keil5有没有像vs软件一样的代码 ...
- pytorch常用损失函数
损失函数的基本用法: criterion = LossCriterion() #构造函数有自己的参数 loss = criterion(x, y) #调用标准时也有参数 得到的loss结果已经对min ...
- ideal配置使用Git
1.git简介 git是目前流行的分布式版本管理系统.它拥有两套版本库,本地库和远程库,在不进行合并和删除之类的操作时这两套版本库互不影响.也因此其近乎所有的操作都是本地执行,所以在断网的情况下任然可 ...
- 第六章 Realm及相关对象——《跟我学Shiro》
转发地址:https://www.iteye.com/blog/jinnianshilongnian-2022468 目录贴:跟我学Shiro目录贴 6.1 Realm [2.5 Realm]及[3. ...