spark集群安装并集成到hadoop集群
前言
最近在搞hadoop+spark+python,所以就搭建了一个本地的hadoop环境,基础环境搭建地址hadoop2.7.7 分布式集群安装与配置
本篇博客主要说明,如果搭建spark集群并集成到hadoop
安装流程
安装spark需要先安装scala 注意在安装过程中需要对应spark与scala版本, spark 也要跟hadoop对应版本,具体的可以在spark官网下载页面查看
下载sacla并安装
https://www.scala-lang.org/files/archive/scala-2.11.12.tgz
tar zxf scala-2.11.12.tgz
移动并修改权限
chown hduser:hduser -R scala-2.11.11
mv /root/scala-2.11.11 /usr/local/scala
配置环境变量
vim .bashrc
#scala var
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
安装完成可以通过scala进如交互页面
注意事项
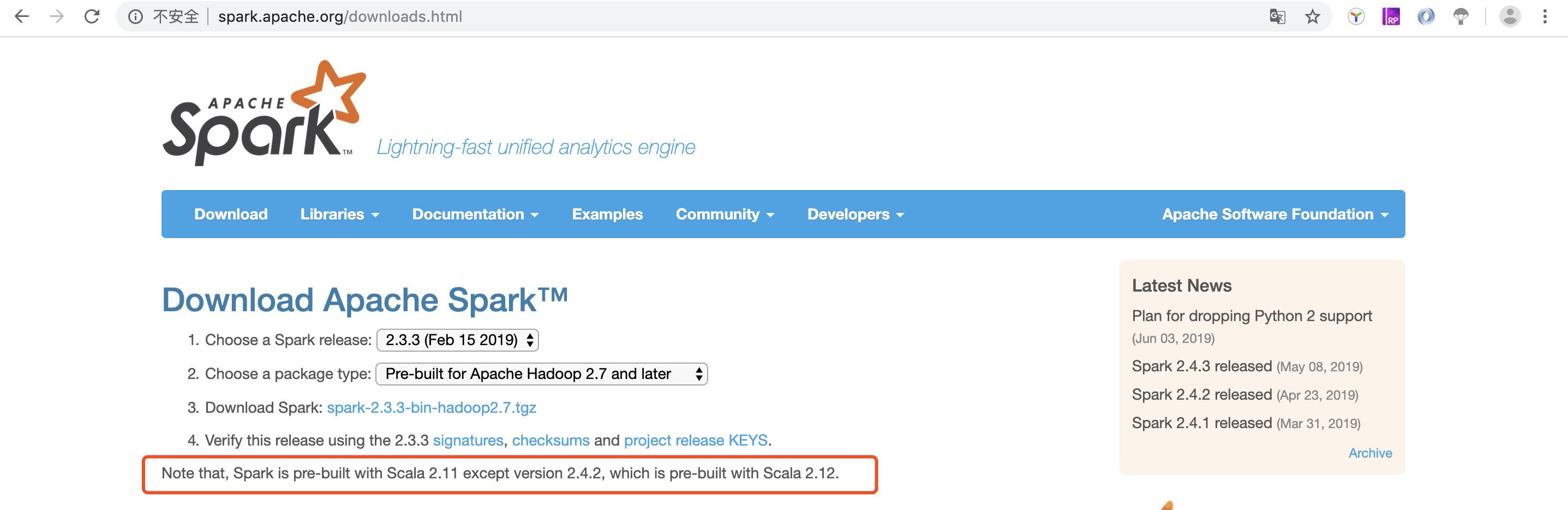
注意:Spark与hadoop版本必须互相匹配,因为Spark会读取Hadoop HDFS 并且必须能在Hadoop YARN执行程序,所以必须要按照我们目前安装的Hadoop版本来选择
笔者这里用的是hadoop2.7.7 所以我选择的是Pre-built for Apache Hadoop 2.7 and later
下载并安装spark
http://mirror.bit.edu.cn/apache/spark/spark-2.3.3/spark-2.3.3-bin-hadoop2.7.tgz
tar zxf spark-2.3.3-bin-hadoop2.7.tgz
移动并修改权限
chown hduser:hduser spark-2.3.3-bin-hadoop2.7
mv spark-2.3.3-bin-hadoop2.7 /usr/local/spark
配置环境变量
vim .bashrc
#spark var
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
进入spark交互页面
默认是python2.7.x版本,对于当前来说版本比较老,可以修改pyspark来选择其他版本(前提是当前服务器已安装其他版本python)
修改master下的spark-env.sh #没有这个文件可以cp spark-env.sh.template spark-env.sh
在最后一行添加如下
export PYSPARK_PYTHON=/usr/bin/python3
修改master下的spark bin目录下pyspark
将文本中
PYSPARK_PYTHON=python
改为
PYSPARK_PYTHON=python3 #取消INFO信息打印
复制conf目录下的log4j模本文件到log4j.properties
将文本中
log4j.rootCategory=INFO, console
改为
log4j.rootCategory=WARN, console
测试与效果图
本地运行spark
pyspark --master local[4]
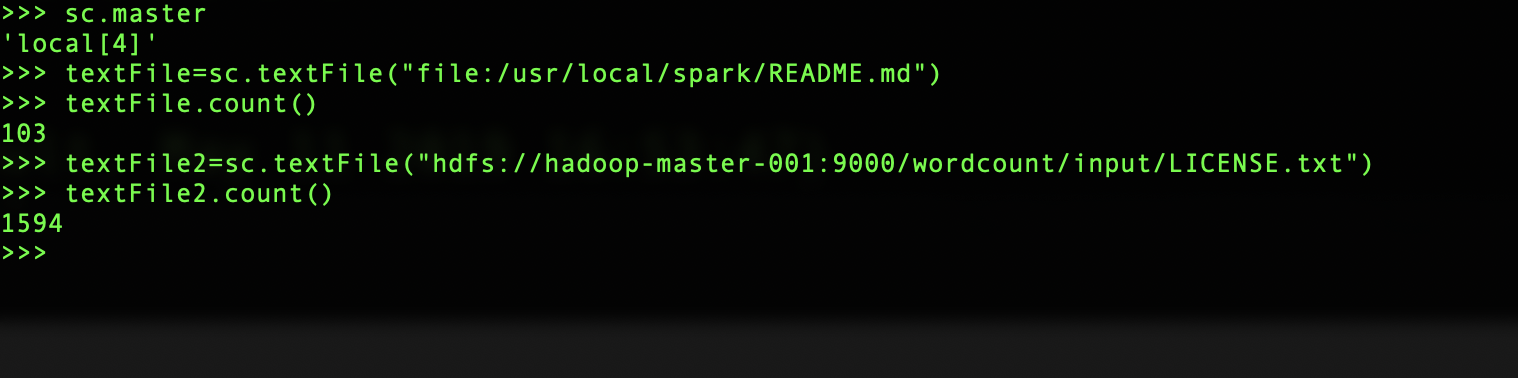
spark 读取本地文件,所有节点都必须存在该文件
textFile=sc.textFile("file:/usr/local/spark/README.md")
spark 读取hdfs文件
textFile2=sc.textFile("hdfs://hadoop-master-001:9000/wordcount/input/LICENSE.txt")
Hadoop YARN运行spark
HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop pyspark --master yarn --deploy-mode client
textFile = sc.textFile("hdfs://hadoop-master-001:9000/wordcount/input/LICENSE.txt")
textFile.count()

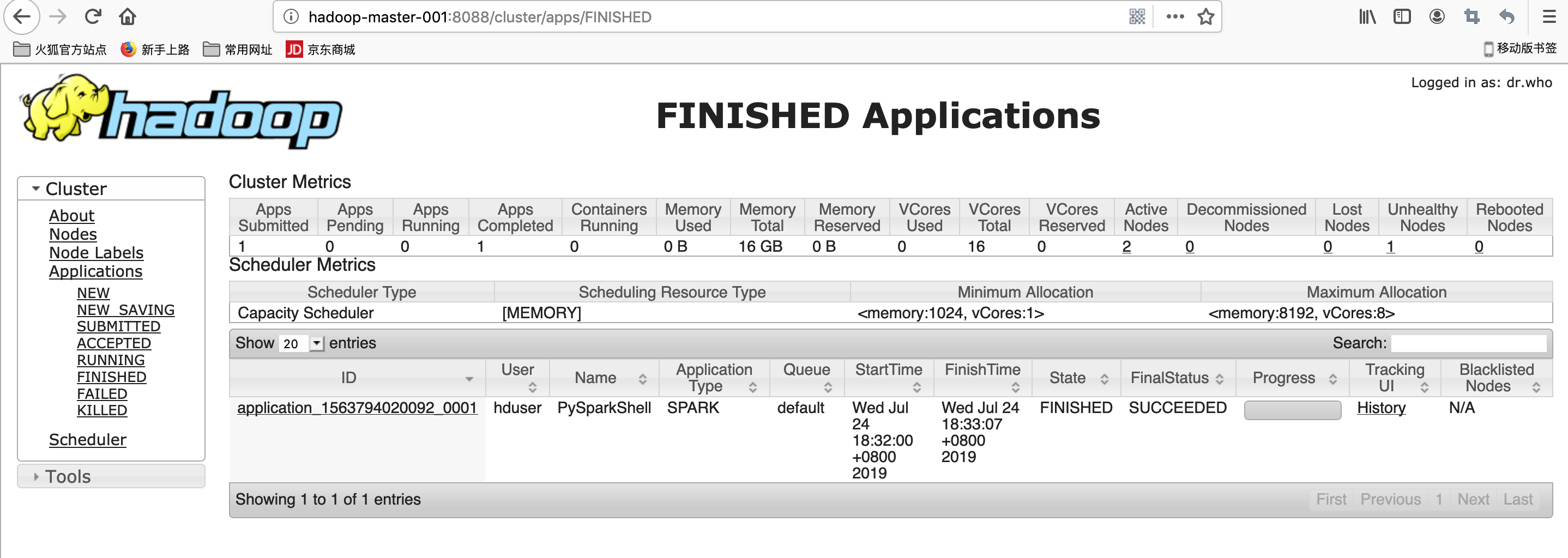
spark Standalone Cluster运行
编辑spark-env.sh #spark_home/conf
export SPARK_MASTER=hadoop-master-001 //设置master的ip或域名
export SPARK_WORKER_CORES=1 //设置每个worker使用的CPU核心
export SPARK_WORKER_MEMORY=512m //设置每个worker使用的内存
export SPARK_WORKER_INSTANCES=4 //设置实例数
将master环境中的spark目录打包并分别远程传输到所有slave节点中.
设置spark Standalone Cluster 服务器(master环境)
vim /usr/local/spark/conf/slaves 添加ip或域名
hadoop-data-001
hadoop-data-002
hadoop-data-003
启动与关闭
/usr/local/spark/sbin/start-all.sh
/usr/local/spark/sbin/stop-all.sh
pyspark --master spark://hadoop-master-001:7077 --num-executors 1 --total-executor-cores 3 --executor-memory 512m
textFile = sc.textFile("file:/usr/local/spark/README.md")
textFile.count()
注意 当在cluster模式下,如yarn-client或spark standalone 读取本地文件时,因为程序是分不到不同的服务器,所以必须确认所有机器都有该文件,否则会发生错误.
建议 最好在cluster读取hdfs文件,这样不会出现文件
text2=sc.textFile("hdfs://hadoop-master-001:9000/wordcount/input/LICENSE.txt")
text2.count()

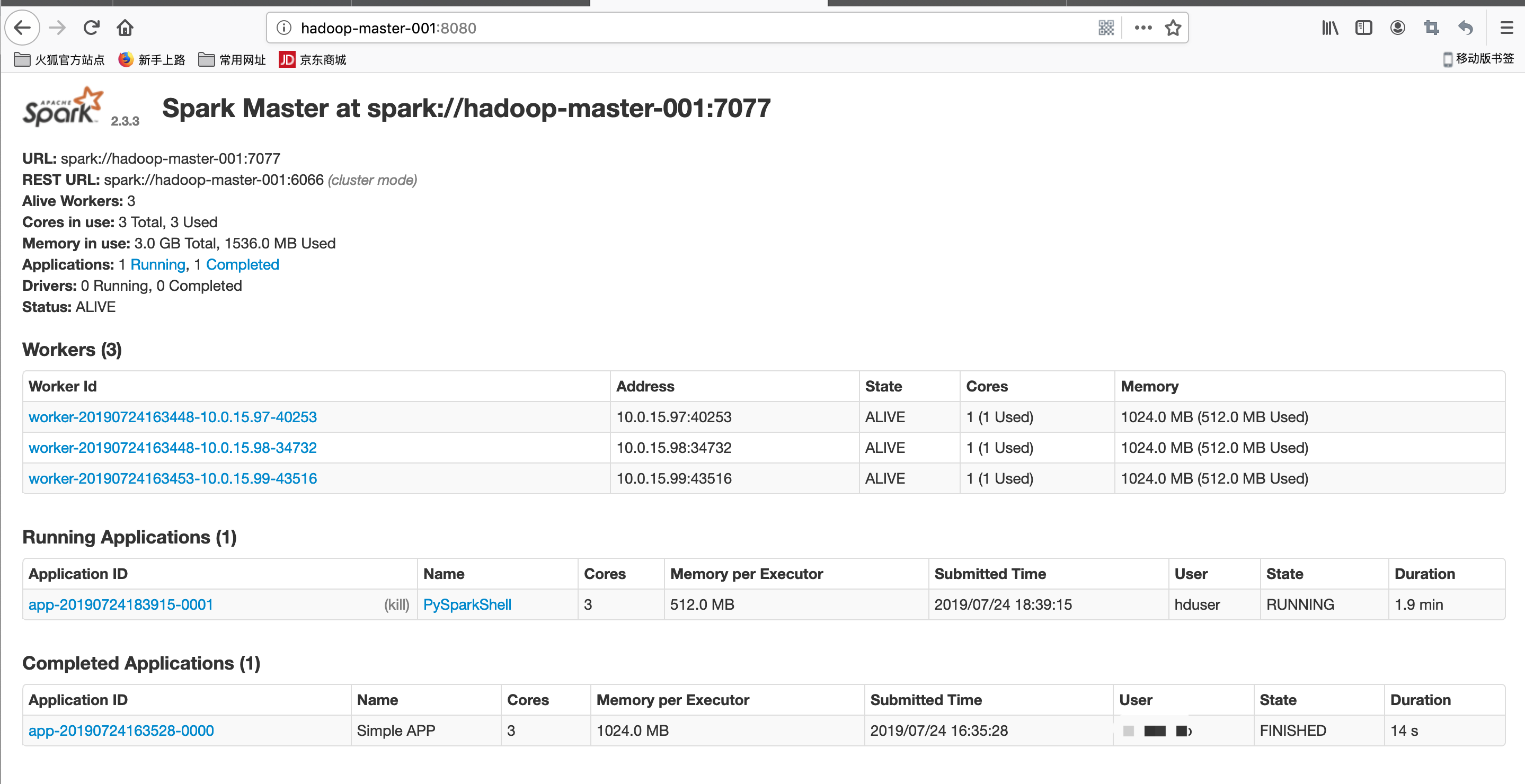
spark web ui
异常处理
hadoop yarn运行pyspark时异常信息:
ERROR SparkContext: Error initializing SparkContext. org.apache.spark.SparkException: Yarn application has already ended! It might have been killed or unable to launch application master 解决方式
查看http://hadoop-master-001:8088/cluster/app/ 最新任务点击history 查看信息
"Diagnostics: Container [pid=29708,containerID=container_1563435447194_0007_02_000001] is running beyond virtual memory limits. Current usage: 55.6 MB of 1 GB physical memory used; 2.2 GB of 2.1 GB virtual memory used. Killing container." 修改所有节点的yarn-site.xml,添加如下
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
主节点执行stop-yarn.sh, start-yarn.sh 重启所有节点yarn
spark集群安装并集成到hadoop集群的更多相关文章
- 最近有安装了一次hadoop集群,NameNode启动失败,及原因
最近有安装了一次hadoop集群,NameNode启动失败,查看日志,找到以下原因: 遇到的异常1: org.apache.hadoop.hdfs.server.common.Inconsistent ...
- CDH集群安装配置(三)- 集群时间同步(主节点)和 免密码登录
集群时间同步(主节点) 1. 查看是否安装ntp服务,如果没有安装 rpm -qa |grep ntpd查看命令 yum install ntp安装命令 2. 修改配置 vi /etc/ntp.con ...
- CDH集群安装配置(一)-集群规划和NAT网络配置
三台物理机或者虚拟机. cdh1,cdh2,cdh3. 内存要求大于8GB,cdh1的物理磁盘要求多余50G. 每台虚拟机安装centos 7 系统.
- hadoop2.7.7 分布式集群安装与配置
环境准备 服务器四台: 系统信息 角色 hostname IP地址 Centos7.4 Mster hadoop-master-001 10.0.15.100 Centos7.4 Slave hado ...
- spark集群安装配置
spark集群安装配置 一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoo ...
- 沉淀,再出发——在Hadoop集群的基础上搭建Spark
在Hadoop集群的基础上搭建Spark 一.环境准备 在搭建Spark环境之前必须搭建Hadoop平台,尽管以前的一些博客上说在单机的环境下使用本地FS不用搭建Hadoop集群,可是在新版spark ...
- Spark应用(app jar)发布到Hadoop集群的过程
记录了Spark,Hadoop集群的开启,关闭,以及Spark应用提交到Hadoop集群的过程,通过web端监控运行状态. 1.绝对路径开启集群 (每次集群重启,默认配置的hadoop集群中tmp文件 ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
随机推荐
- Dubbo的SPI是个什么鬼
原文:https://mp.weixin.qq.com/s/bQc_tASkfsojlcd897kLtA # spi 是啥? spi,简单来说,就是 service provider interfac ...
- CentOS 6.5系统中mysql数据库还原后出现无法读表
图形化工具还原提示如下: 命令行输入 mysql> use netmanage; Database changed mysql> show tables; ERROR 1018 (H ...
- 微信小程序 位置定位position详解,相对定位relative,绝对定位absolute相关问题
一.位置position[定位属性:static,relative,absolute,fixed,inherit,-ms-page,initial,unset] 1.static:元素框正常生成,块级 ...
- MySQL查询获取行号rownum
MySQL中可以使用变量产生行号,下面是2个简单例子: 使用工具:MySQL Workbench 说明:表heyf_10中字段,empid(员工工号).deptid(部门编号).salary(薪资): ...
- maven报错解决
maven-resources-plugin prior to 2.4 is not supported by m2e. Use maven- resources-plugin versio < ...
- Ionic4.x 中的列表UI组件
1.普通列表 <ion-list> <ion-item> <ion-label>Peperoni</ion-label> </ion-item&g ...
- JavaScript的深拷贝
javaScript的拷贝有浅拷贝和深拷贝.拷贝我们一般拷贝对象,获取对象的内容(字段.函数)都给复制一遍 浅拷贝:一般只是简单的赋值 //浅拷贝 var obj1={name:"cat&q ...
- smarty使用小技巧——截取小技巧
smarty截取字符串(末尾没有...)今天发现有个网页出现乱码,检查发现是用truncate()函数截取的字符串,truncate()函数对中文支持不好,随用mb_substr()函数替换trunc ...
- 批量删除Maven 仓库未下载成功.lastupdate 的文件
Windows: @echo off echo 开始... for /f "delims=" %%i in ('dir /b /s "./*lastUpdated&quo ...
- OVS+VXLAN实现两个宿主机上的VM间的通信
一.组网图 说明: 1.使用网络命名空间表示vm1和vm2. 因为我没有两台物理服务器. 2.使用virtualbox 的两条虚机模拟作为host1和host2. 二.配置指导 1.创建网桥 br0 ...