爬虫(十二):scrapy中spiders的用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页
工作流程分析
- 以初始的URL初始化Request,并设置回调函数,当该request下载完毕并返回时,将生成response,并作为参数传给回调函数. spider中初始的requesst是通过start_requests()来获取的。start_requests()获取 start_urls中的URL,并以parse以回调函数生成Request
- 在回调函数内分析返回的网页内容,可以返回Item对象,或者Dict,或者Request,以及是一个包含三者的可迭代的容器,返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数
- 在回调函数内,可以通过lxml,bs4,xpath,css等方法获取我们想要的内容生成item
- 最后将item传递给Pipeline处理
我们以通过简单的分析源码来理解
我通常在写spiders下写爬虫的时候,我们并没有写start_requests来处理start_urls中的url,这是因为我们在继承的scrapy.Spider中已经写过了,我们可以点开scrapy.Spider查看分析
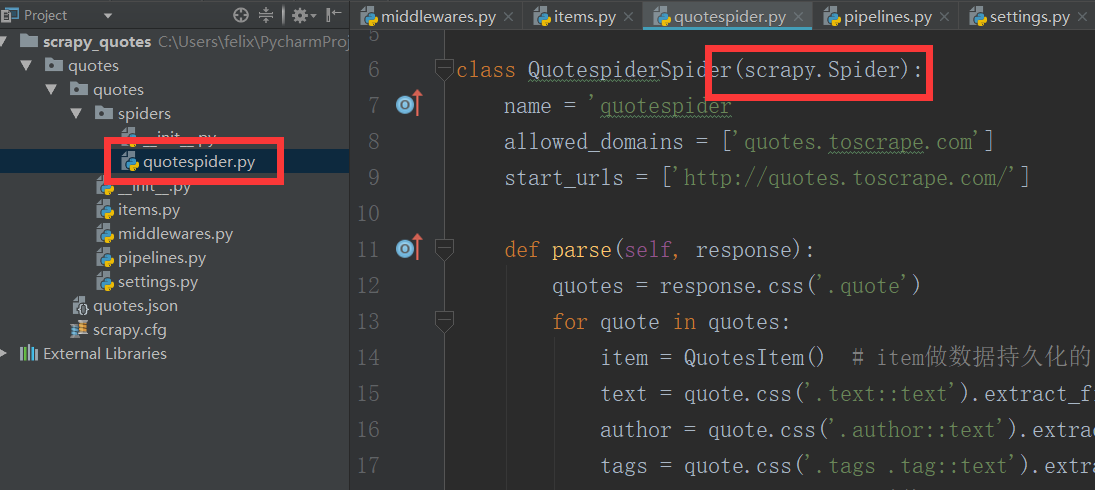
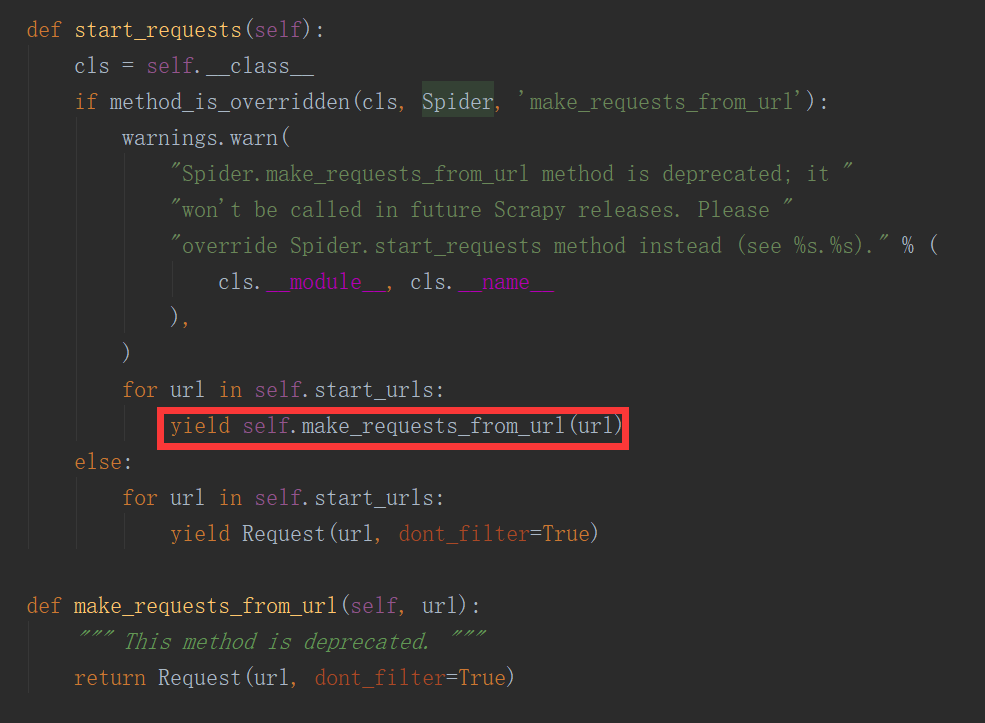
通过上述代码我们可以看到在父类里这里实现了start_requests方法,通过make_requests_from_url做了Request请求
如下图所示的一个例子,parse回调函数中的response就是父类列start_requests方法调用make_requests_from_url返回的结果,并且在parse回调函数中我们可以继续返回Request,如下属代码中yield Request()并设置回调函数。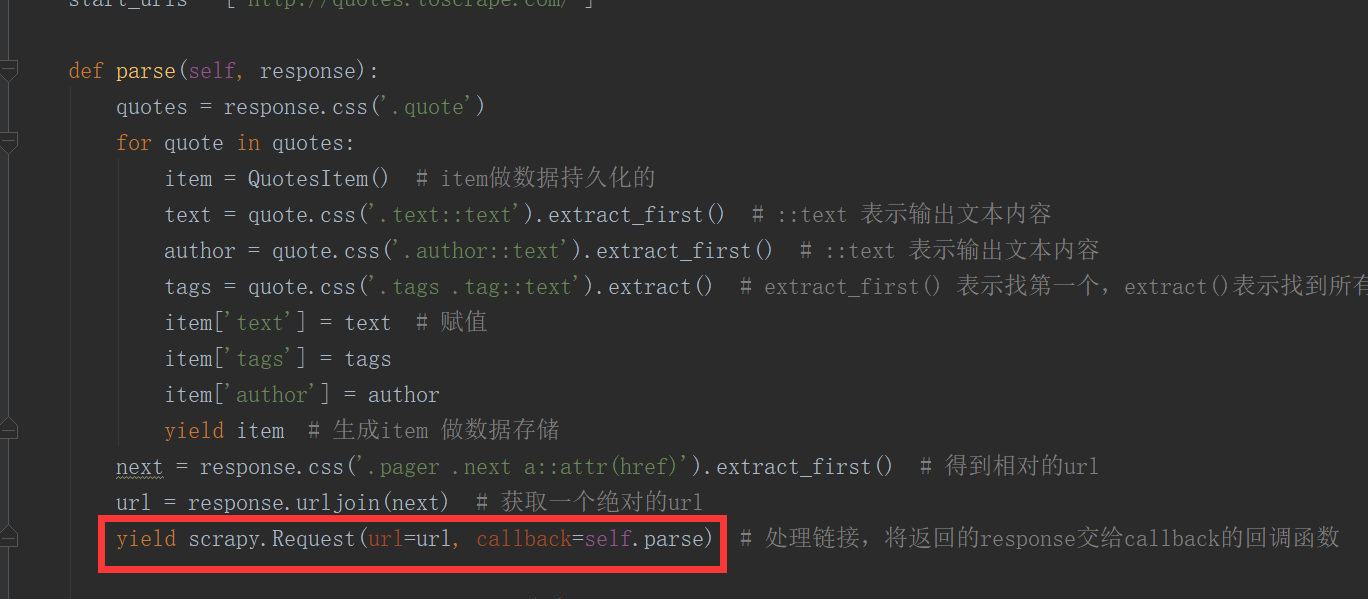
spider内的一些常用属性
我们所有自己写的爬虫都是继承与spider.Spider这个类
name
定义爬虫名字,我们通过命令启动的时候用的就是这个名字,这个名字必须是唯一的
allowed_domains
包含了spider允许爬取的域名列表。当offsiteMiddleware启用时,域名不在列表中URL不会被访问
所以在爬虫文件中,每次生成Request请求时都会进行和这里的域名进行判断
start_urls
起始的url列表
这里会通过spider.Spider方法中会调用start_request循环请求这个列表中每个地址。
custom_settings
自定义配置,可以覆盖settings的配置,主要用于当我们对爬虫有特定需求设置的时候
设置的是以字典的方式设置:custom_settings = {}
from_crawler
这是一个类方法,我们定义这样一个类方法,可以通过crawler.settings.get()这种方式获取settings配置文件中的信息,同时这个也可以在pipeline中使用
start_requests()
这个方法必须返回一个可迭代对象,该对象包含了spider用于爬取的第一个Request请求
这个方法是在被继承的父类中spider.Spider中写的,默认是通过get请求,如果我们需要修改最开始的这个请求,可以重写这个方法,如我们想通过post请求
make_requests_from_url(url)
这个也是在父类中start_requests调用的,当然这个方法我们也可以重写
parse(response)
这个其实默认的回调函数
负责处理response并返回处理的数据以及跟进的url
该方法以及其他的Request回调函数必须返回一个包含Request或Item的可迭代对象
爬虫(十二):scrapy中spiders的用法的更多相关文章
- Python爬虫利器二之Beautiful Soup的用法
上一节我们介绍了正则表达式,它的内容其实还是蛮多的,如果一个正则匹配稍有差池,那可能程序就处在永久的循环之中,而且有的小伙伴们也对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Be ...
- OpenJDK源码研究笔记(十二):JDBC中的元数据,数据库元数据(DatabaseMetaData),参数元数据(ParameterMetaData),结果集元数据(ResultSetMetaDa
元数据最本质.最抽象的定义为:data about data (关于数据的数据).它是一种广泛存在的现象,在许多领域有其具体的定义和应用. JDBC中的元数据,有数据库元数据(DatabaseMeta ...
- (转)SpringMVC学习(十二)——SpringMVC中的拦截器
http://blog.csdn.net/yerenyuan_pku/article/details/72567761 SpringMVC的处理器拦截器类似于Servlet开发中的过滤器Filter, ...
- 十、SQL中EXISTS的用法 十三、sql server not exists
十.SQL中EXISTS的用法 EXISTS用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False EXISTS 指定一个子查询,检测 行 的存在. 语法 ...
- 爬虫(十三):scrapy中pipeline的用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- 爬虫(十二):图形验证码的识别、滑动验证码的识别(B站滑动验证码)
1. 验证码识别 随着爬虫的发展,越来越多的网站开始采用各种各样的措施来反爬虫,其中一个措施便是使用验证码.随着技术的发展,验证码也越来越花里胡哨的了.最开始就是几个数字随机组成的图像验证码,后来加入 ...
- Expo大作战(十二)--expo中的自定义样式Custom font,以及expo中的路由Route&Navigation
简要:本系列文章讲会对expo进行全面的介绍,本人从2017年6月份接触expo以来,对expo的研究断断续续,一路走来将近10个月,废话不多说,接下来你看到内容,讲全部来与官网 我猜去全部机翻+个人 ...
- Python_爬虫伪装_ scrapy中fake_userAgent的使用
scrapy 伪装代理和fake_userAgent的使用 伪装浏览器代理 在爬取网页是有些服务器对请求过滤的不是很高可以不用ip来伪装请求直接将自己的浏览器信息给伪装也是可以的. 第一种方法: 1. ...
- (十二) WebGIS中矢量图层的设计
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/. 1.前言 在前几章中我们已经了解了什么是矢量查询.屏幕坐标与地理坐标之 ...
随机推荐
- java连接腾讯云上的redis
目录 腾讯云上的配置 redis连接单机和集群 依赖 pom.xml redis参数的配置文件 遗留问题 腾讯云上的配置 在安全组上打开相关的端口即可 "来源" 就是你的目标服务器 ...
- 游记-NOI2019
Day -18 被各路julao们轮番吊打-- Day -12 鸽子F发布了笔试题库,然而并没有 "MLE全场记零分" 的操作 Day -8 广二体育馆机器装配完毕,误闯开幕式表演 ...
- myisam和innodb的区别,java事务不起作用原因
myisam:只支持表级锁.不支持事务.方便移植.该类型是mysql默认表存储类型 innodb:支持表级锁和行级锁.支持事务. 如果你的事务不起作用,很可能是用了myisam存储引擎,检查数据表引擎 ...
- iOS - starckView 类似Android线性布局
同iOS以往每个迭代一样,iOS 9带来了很多新特性.UIKit框架每个版本都在改变,而在iOS 9比较特别的是UIStackView,它将从根本上改变开发者在iOS上创建用户界面的方式.本文将带你学 ...
- extjs layout 最灵活的页面布局样式
当你在页面布局的时候,遇到页面元素较多,不知如何完美布局... 可以试试下面这个类型,万能布局类型. var panel = new Ext.Panel({ renderTo:Ext.getBody( ...
- 爬虫request库规则与实例
Request库的7个主要方法: requests.request(method,url,**kwargs) method:请求方式,对应get/put/post等7种: r = reques ...
- pymysql操作mysql数据库
1.建库 import pymysql # 建库 try: conn=pymysql.connect( host='127.0.0.1', port=3306, user='root', passwd ...
- element-ui中使用表单验证的问题
<el-form ref="ruleRules" :inline="true" :model="ruleInfo"> <e ...
- python之约束、加密及logging模块
一.什么是约束? 在生活中的约束大概就是有什么原因,导致你不能做这件事情了,称之为约束.而在python中的约束是在当多个类中,都需要使用某些方法时,需要人为抛出异常或使用基类+异常处理来进行约束 c ...
- linux文件权限命令chmod学习
Linux系统中的每个文件和目录都有访问许可权限,用它来确定谁可以通过何种方式对文件和目录进行访问和操作. 文件或目录的访问权限分为只读,只写和可执行三种.以文件为例,只读权限表示只允许读其内容,而禁 ...