ORACLE_笔记_练习题目
一.plsql用法网址及时复习
extract()函数----用于截取年、月、日、时、分、秒
https://www.cnblogs.com/xqzt/p/4477239.html
case when 不同位置用法不同,可用于求显示等级、及格率等
https://www.cnblogs.com/soundcode/p/5549901.html
merge into
https://www.cnblogs.com/kongxc/p/9237941.html
https://www.cnblogs.com/kongxc/p/9237941.html
where 和having 的区别
https://www.cnblogs.com/jameshappy/archive/2012/05/23/2515034.html
constraint约束
https://blog.csdn.net/qqww120102/article/details/79791396
trigger触发器
producers存储过程
consequences序列
index索引
cursor游标
二.写SQL前注意点:
0.查询字段必要的加注释,取名字
1.单表查询不要取别名
2.别名不要用关键字
3.表不多时候用 A B C D E 取别名而不用缩写
4.聚集函数多和分组函数group by 联用求均值
5.分类后求第几个一般用row_num()rank函数 而不用 group by
*6.exists 查询效率一般比in 高 因为in不走索引,in适合外表大内表小 exists 适合外表小内表大。(只要内表和外表有关联ID 就可以使用)
用exists 替换步骤 优化sql如下例:
假如有一个表user,它有两个字段id和name,我们要查询名字中带a的用户信息:
a. 最简单的SQL:select * from user where name like '%a%';
b. 使用IN的SQL:select u.* from user u where u.id in (select uu.id from user uu where uu.name like '%a%');
我们现在将使用IN的SQL修改为使用EXISTS的SQL该怎么写呢?
c. 一开始我直接将u.id in 替换为EXISTS,获得如下语句,发现把结果全部查询出来了 :
select u.* from user u where exists(select uu.id from user uu where uu.name like '%a%');
d.最终末尾加上关联
select u.* from user u where exists (select uu.id from user uu where uu.name like '%a%' and uu.id=u.id);
原因解释:
总结:EXISTS子查询可以看成是一个独立的查询系统,只为了获取真假逻辑值,EXISTS子查询与外查询查询的表是两个完全独立的毫无关系的表(当第二个表中的name中有包含a的姓名存在,那么就执行在第一个表中查询所有用户的操作),当我们在子查询中添加了id关联之后,EXISTS子查询与外查询查询的表就统一了,是二者组合组建的虚表,是同一个表(这样当子查询查询到虚表中当前行的uu.name中包含a时,则将虚表当前行中对应的u.id与u.name查询到了)
所以一切的重点就在这个ID关联之上,添加ID关联,数据库会先将两张表通过ID关联组合成一张虚表,所有的查询操作都在这张虚表上完成,操作的是同一张表,当然就不会出现之前的那种情况了!
例子使用exists语句显示BLAKE所在部门的其他所有雇员,但是不要显示BLAKE
WHERE EXISTS(子查询) ,子查询返回的的是TRUE OR FALSE 即使是
SELECT * FROM DEPR WHERE EXISTS (SELECT NULL)
--正确写法 关键在于内表外表相同组成的同一虚表
SELECT *
FROM EMP B 关键点
WHERE EXISTS
(SELECT *
FROM EMP C --关键点
WHERE C.EMPNO = B.EMPNO
AND C.ENAME <> 'BLAKE'
AND C.DEPTNO =
(SELECT A.DEPTNO FROM EMP A WHERE A.ENAME = 'BLAKE'))
7.lpad( string, padded_length, [ pad_string ] ) 填充在左侧使其左对齐 rpad 填充在右测 一般price习惯lpad对齐,pad_string不指定默认是空格
8. NUMBER 四则运算 要注意 用NVL(EX1,EX2) 因为number+null=null,如果ex1为空返回ex2,如果ex1 不为空返回ex1,作用就是不返回空值
*9.重点掌握 row_number()rank 自主平时多找练习做
10. case when 两种表现形式,3位置不同的用法:10.1 SELECT CASE WHEN 用法 10.2 WHERE CASE WHEN... 10.3 GROUP BY
CASE WHEN salary <= 500 THEN '1' WHEN ....
11.left join 易错点 on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录。
where条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有left join的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
总结:如果想要查询某列所在行所有信息,不要在where 后加过分的限制条件,
12.对时间操作多用round(to_number(to_char(sysdate,'yyyy')),2) ;插入时间字符串 转换成 date类型到数据库中:to_date('2019/1/1','yyyy-mm-dd')
*13.merge into TABLE_A USING TABLE_B 用B表更新A表 一般用法: 有多种模式 1.正常模式先插入再修改 2.只插入 3.只修改
MERGE INTO A_MERGE A USING (select B.AID,B.NAME,B.YEAR from B_MERGE B) C ON (A.id=C.AID)
WHEN MATCHED THEN
UPDATE SET A.YEAR=C.YEAR
WHEN NOT MATCHED THEN
INSERT(A.ID,A.NAME,A.YEAR) VALUES(C.AID,C.NAME,C.YEAR);
commit;
14.where 和 having的区别
它们的相似之处就是定义搜索条件,不同之处是where子句为单个筛选而having子句与组有关,而不是与单个的行有关。
最后:理解having子句和where子句最好的方法就是基础select语句中的那些句子的处理次序:where子句只能接收from子句输出的数据,而having子句则可以接受来自group by,where或者from子句的输入。
15.TABLE_A LEFT JOIN TABLE_B ON A.AID=B.AID 查询数量为A表中每个AID×B表对应的AID的数量和+A表中有而B表中没有的数量=总查询数量,如果加上了where 则会更少
SELECT DEPT.DEPTNO FROM DEPT LEFT JOIN EMP ON EMP.DEPTNO=DEPT.DEPTNO 查询到15条信息
SELECT DEPT.DEPTNO FROM DEPT RIGHT JOIN EMP ON EMP.DEPTNO=DEPT.DEPTNO 查询到14条信息因为是以EMP为基础
SELECT DEPT.DEPTNO FROM DEPT LEFT JOIN EMP ON EMP.DEPTNO=DEPT.DEPTNO WHERE EMP.DEPTNO=DEPT.DEPTNO 查询到14条信息 本来左连接有15条数据,但是where 对结果进行筛选去掉了单独的deptno=40这个数据,因为它没有和EMP表关联
SELECT * FROM EMP LEFT JOIN DEPT ON EMP.DEPTNO=DEPT.DEPTNO 14条数据,因为以EMP为基础
SELECT * FROM EMP RIGHT JOIN DEPT ON EMP.DEPTNO=DEPT.DEPTNO 15条数据,因为以DEPT为基础 但是结果左边会出现空值,所以把两个表交换一下位置再重新用左连接
/*1. 没有使用子查询的理由;
查询老师:谌燕 ,所教授的课程;
*/
SELECT hc.COURSE_NO, hc.COURSE_NAME
FROM HAND_COURSE hc
WHERE TEACHER_NO =
(SELECT TEACHER_NO FROM HAND_TEACHER WHERE TEACHER_NAME = '谌燕');
select h.*,rowid from hzd_table h where h.age between 18 and 28
select HT.* from HZD_TABLE HT where HT.NAME like '%a_%' escape 'a';
select distinct sysdate "aa" ,rowid from dual
select sysdate||sysdate "aa" ,rowid from dual
select to_char(sysdate),to_char(sysdate,'yyyy-MM-dd HH24:mm:ss'), to_date(sysdate),to_date(to_char(sysdate,'yyyy-MM-dd'),'yyyy-MM-dd')from dual
where to_char(sysdate,'yyyy-MM-dd')='2019-11-02'
三.触发器
------------------------------------------触发器trigger 测试----------------------------------------------------
create or replace trigger update_hzd_table_trigger
after
update on hzd_table
for each row
begin dbms_output.put_line('触发器测试') ;
end;
update hzd_table ht set ht.age=19 where ht.age<55
select h.*,length(h.id),length(h.name),length('hzd1') aa,length('Oracle'),rowid from hzd_table h
-------------------------服务器端使用哪种编码 GBK 一个中文16位占用2字节,UTF-8 32位 一个中文占用三个字节-----------
select userenv('language') from dual;
select h.*,length('GBK一个汉字占用两个字节') ,rowid from hzd_table h
select h.*,lengthb('GBK一个汉字占用两个字节') ,rowid from hzd_table h
四.建表 建立CONSTRAINT约束,建立序列SEQUENCE 插入数据自增
DROP TABLE HZD_STUDENT;
CREATE TABLE HZD_STUDENT (
SID NUMBER(10) CONSTRAINT CON_SID_PK PRIMARY KEY ,
SNAME VARCHAR(255),
SDESCRIPTION VARCHAR(255)
)
--ALTER 重新、定义、改变命名表字段等
ALTER table hzd_table modify sid not null
CREATE SEQUENCE HZD_STUDENT_SID_SEQ
INCREMENT BY 1
START WITH 1;
insert into HZD_STUDENT(SID,SNAME,SDESCRIPTION)values(HZD_STUDENT_SID_SEQ.Nextval,'张三','测试序列和主键约束');
SELECT ROWID, HZD_TABLE.* FROM HZD_TABLE
SELECT * FROM HZD_STUDENT
--根据 B表信息修改A表信息 这是错误的写法会把所有的数据都修改
UPDATE HZD_TABLE A
SET NAME ='测试修改数据'
WHERE EXISTS
(SELECT *
FROM HZD_STUDENT B
WHERE A.SID = B.SID)
SELECT * FROM HZD_TABLE A WHERE EXISTS (SELECT * FROM HZD_STUDENT B WHERE B.SID=A.SID AND AGE=19)
五.序列例子
-----------------------------------------------序列sequence实现自增长,在插入的时候用-----------------------------------------------
/*步骤:
1.建表某表Student
2.建立序列,名字最后有格式
3.插入数据 用Student_stuId_Seq.Nextval插入 如: insert into Student(stuId,Stuname) values(Student_stuId_Seq.Nextval,'张三');
*/
完整子如下例:
--例创建示例表 --
create table Student(
stuId number(9) not null,
stuName varchar2(20) not null,
stuMsg varchar2(50) null
);
-- 创建序列 Student_stuId_Seq --
create sequence Student_stuId_Seq
increment by 1
start with 1
minvalue 1
maxvalue 999999999;
-- 更改序列 Student_stuId_Seq--
/* alter sequence Student_stuId_Seq
increment by 2
minvalue 1
maxvalue 999999999;*/
--获取序列自增ID --
select Student_stuId_Seq.Nextval 自增序列ID from dual;
-- 删除序列 --
/* drop sequence Student_stuId_Seq;*/
--调用序列,插入Student数据 --
insert into Student(stuId,Stuname) values(Student_stuId_Seq.Nextval,'张三');
insert into Student(stuId,Stuname) values(Student_stuId_Seq.Nextval,'李四');
--查询插入的数据 --
select student.* from Student
六.约束CONSTRAINT
-----------------------------------------------约束constraint-----------------------------------------------
https://blog.csdn.net/qqww120102/article/details/79791396
约束按照创建方式分为:表级约束和列级约束
表级约束:指创建表的时候,定义完全部列后。在最后指定约束对应的列
列级约束:指创建表的时候,定义为列立即定义该列对应的约束
数据库约束有五种:
1.主键约束(PRIMARY KEY) :相当于UNIQUE+NOT NULL 语法:alter table table_name add constraint [constraint_type_name ] [constraint_type](column)
2.唯一性约束(UNIQUE) :alter table table_name add constraint constraint_name unique(column_name);
3.非空约束(NOT NULL) :alter table table_name modify column_name constraint constraint_name not null ;
4.外键约束(FOREIGN KEY) :
5.检查约束(CHECK) :
-- https://blog.csdn.net/qqww120102/article/details/79791396
/*主键约束(primary key)
外键约束(foreign key)
唯一性约束(unique)
非空约束(not null)
检查约束(check)*/
1.主键约束==UNIQUE+NOT NULL
--增加主键约束
alter table table_name add constraint constraint_name primary key(column_name);
--删除主键约束
SQL> alter table table_name drop constraint constraint_name;
或
alter table table_name drop primary key;
2.唯一性约束(UNIQUE)
--增加唯一约束
alter table table_name add constraint constraint_name unique(column_name);
--删除唯一约束
alter table table_name drop constraint constraint_name;
3.非空约束(NOT NULL)
--增加非空约束
alter table table_name modify column_name constraint constraint_name not null ;
--删除非空约束
alter table table_name modify column_name constraint constraint_name null;
4.外键约束(FOREIGN KEY)
第一种方式简单粗暴,删除的时候,级联删除掉子表中的所有匹配行,在创建外键时,通过 on delete cascade 子句指定该外键列可级联删除:
SQL> alter table 外键表名 add constraint constraint_name foreign key(外键表列) references 参照表 (参照表列) on delete cascade;
第二种方式,删除父表中的对应行,会将对应子表中的所有匹配行的外键约束列置为NULL,通过 on delete set null 子句实施:
SQL> alter table 外键表名 add constraint constraint_name foreign key(外键表列) references 参照表 (参照表列) on delete set null;
删除外键约束
SQL> alter table table_name drop constraint constraint_name;
————————————————
版权声明:本文为CSDN博主「大辰」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qqww120102/article/details/79791396
5.检查约束(CHECK)
添加约束
SQL> alter table table_name add constraint constraint_name check(具体约束内容);
删除约束
SQL> alter table table_name drop constraint constraint_name;
添加、修改默认值
alter table table_name modify column_name default 具体内容;
删除默认值
alter table table_name modify column_name default null;
--主键约束 alter table table_name add constraint [constraint_type_name ] [constraint_type](column)
alter table books add constraint books_pk primary key (id);
--唯一约束
alter table table_name add [constraint constraint_name] unique(column_name);
删除约束
删除unique约束
删除列上的unique约束,可以使用alter table...drop语句,形式如下:
alter table table_name drop unique(column_name)
如果约束有名称,也可以使用指定名称的方式删除该约束,语句形式如下:
alter table table drop constraint constraint_name;
SELECT HT.* ,ROWID FROM HZD_TABLE HT
alter table HZD_TABLE add constraint con primary key (id);
七时间转换
-----------------------------------------oracle timestamp和日期 timestamp和字符串互转 ---------------------
Oracle 日期类型timestamp(时间戳)和date类型使用
1、获取系统时间的语句(ssxff6获取小数点后面六位)
select sysdate,systimestamp,to_char(systimestamp, 'yyyymmdd hh24:mi:ssxff6'),
to_char(systimestamp, 'yyyymmdd hh24:mi:ss.ff6') from dual;
2、字符型转成timestamp
select to_timestamp('2011-09-14 12:52:42.123456789', 'syyyy-mm-dd hh24:mi:ss.ff') from dual;
3、timestamp转成date型
select cast(to_timestamp('2011-09-14 12:52:42.123456789', 'syyyy-mm-dd hh24:mi:ss.ff') as date) timestamp_to_date from dual;
4、date型转成timestamp
select cast(sysdate as timestamp) date_to_timestamp from dual;
5、两date的日期相减得出的是天数,而两timestamp的日期相减得出的是完整的年月日时分秒小数秒
select sysdate-sysdate,systimestamp-systimestamp from dual;
select extract(day from inter) * 24 * 60 * 60 +
extract(hour from inter) * 60 * 60 + extract(minute from inter) * 60 +
extract(second from inter) "seconds" from
(
select to_timestamp('2011-09-14 12:34:23.281000000', 'yyyy-mm-dd hh24:mi:ss.ff') -
to_timestamp('2011-09-14 12:34:22.984000000', 'yyyy-mm-dd hh24:mi:ss.ff') inter from dual
);
select extract(second from to_timestamp('2011-09-14 12:34:23.281000000', 'yyyy-mm-dd hh24:mi:ss.ff'))-
extract(second from to_timestamp('2011-09-14 12:34:22.984000000', 'yyyy-mm-dd hh24:mi:ss.ff')) from dual;
注:所以,timestamp要算出两日期间隔了多少秒,要用函数转换一下。
to_char函数支持date和timestamp,但是trunc却不支持TIMESTAMP数据类型。
select systimestamp-systimestamp from dual
select sysdate,systimestamp,to_char(systimestamp, 'yyyy-mm-dd hh24:mi:ssxff6'),
to_char(systimestamp, 'yyyymmdd hh24:mi:ss.ff6') from dual;
-----------------------------extract (year from sysdate)用于截取时分秒 获取日期间隔---------------------------------------------------------
select extract(second from to_timestamp('2011-09-14 12:34:23.281000000', 'yyyy-mm-dd hh24:mi:ss.ff')),
extract(second from to_timestamp('2011-09-14 12:34:22.984000000', 'yyyy-mm-dd hh24:mi:ss.ff')) from dual;
只可以从一个date类型中截取年月日
select extract (year from sysdate) year, extract (month from sysdate) month, extract (day from sysdate) day from dual;
从timestamp中获取年月日时分秒
select
extract(year from systimestamp) year
,extract(month from systimestamp) month
,extract(day from systimestamp) day
,extract(minute from systimestamp) minute
,extract(second from systimestamp) second
,extract(timezone_hour from systimestamp) th
,extract(timezone_minute from systimestamp) tm
,extract(timezone_region from systimestamp) tr
,extract(timezone_abbr from systimestamp) ta
from dual
获取两个日期之间的具体时间间隔
获取两个日期之间的具体时间间隔,extract函数是最好的选择
select
extract (day from dt2 - dt1) day,
extract (hour from dt2 - dt1) hour,
extract (minute from dt2 - dt1) minute,
extract (second from dt2 - dt1) second
from
(
select
to_timestamp ('2011-02-04 15:07:00','yyyy-mm-dd hh24:mi:ss') dt1,
to_timestamp ('2011-05-17 19:08:46','yyyy-mm-dd hh24:mi:ss') dt2
from
dual
)
例题:
Create Table HAND_STUDENT
(
STUDENT_NO Varchar2(10) Not Null,
STUDENT_NAME Varchar2(20),
STUDENT_AGE Number,
STUDENT_GENDER Varchar2(5),
OBJECT_VERSION_NUMBER Number Default 1 Not Null,
CREATION_DATE DATE Default Sysdate Not Null,
CREATED_BY NUMBER Default -1 Not Null,
LAST_UPDATED_BY NUMBER Default -1 Not Null,
LAST_UPDATE_DATE DATE Default Sysdate Not Null,
LAST_UPDATE_LOGIN NUMBER
);
-- Add comments to the table
comment on table HAND_STUDENT is '学生信息表';
-- Add comments to the columns
comment on column HAND_STUDENT.STUDENT_NO is '学号';
comment on column HAND_STUDENT.STUDENT_NAME is '姓名';
comment on column HAND_STUDENT.STUDENT_AGE is '年龄';
comment on column HAND_STUDENT.STUDENT_GENDER is '性别';
comment on column HAND_STUDENT.OBJECT_VERSION_NUMBER is '行版本号,用来处理锁';
-- Create/Recreate indexes
Create Unique Index HAND_STUDENT_U1 On HAND_STUDENT(STUDENT_NO);
Create Table HAND_TEACHER
(
TEACHER_NO Varchar2(10) Not Null,
TEACHER_NAME Varchar2(20),
MANAGER_NO Varchar2(10),
OBJECT_VERSION_NUMBER Number Default 1 Not Null,
CREATION_DATE DATE Default Sysdate Not Null,
CREATED_BY NUMBER Default -1 Not Null,
LAST_UPDATED_BY NUMBER Default -1 Not Null,
LAST_UPDATE_DATE DATE Default Sysdate Not Null,
LAST_UPDATE_LOGIN NUMBER
);
-- Add comments to the table
comment on table HAND_TEACHER is '教师信息表';
-- Add comments to the columns
comment on column HAND_TEACHER.TEACHER_NO is '教师编号';
comment on column HAND_TEACHER.TEACHER_NAME is '教师名称';
comment on column HAND_TEACHER.MANAGER_NO is '上级编号';
comment on column HAND_TEACHER.OBJECT_VERSION_NUMBER is '行版本号,用来处理锁';
-- Create/Recreate indexes
Create Unique Index HAND_TEACHER_U1 On HAND_TEACHER(TEACHER_NO) ;
Create Table HAND_COURSE
(
COURSE_NO Varchar2(10) Not Null,
COURSE_NAME Varchar2(20),
TEACHER_NO Varchar2(10) Not Null,
OBJECT_VERSION_NUMBER Number Default 1 Not Null,
CREATION_DATE DATE Default Sysdate Not Null,
CREATED_BY NUMBER Default -1 Not Null,
LAST_UPDATED_BY NUMBER Default -1 Not Null,
LAST_UPDATE_DATE DATE Default Sysdate Not Null,
LAST_UPDATE_LOGIN NUMBER
);
-- Add comments to the table
comment on table HAND_COURSE is '课程信息表';
-- Add comments to the columns
comment on column HAND_COURSE.COURSE_NO is '课程号';
comment on column HAND_COURSE.COURSE_NAME is '课程名称';
comment on column HAND_COURSE.TEACHER_NO is '教师编号';
comment on column HAND_COURSE.OBJECT_VERSION_NUMBER is '行版本号,用来处理锁';
-- Create/Recreate indexes
Create Unique Index HAND_COURSE_U1 On HAND_COURSE(COURSE_NO);
Create Table HAND_STUDENT_CORE
(
STUDENT_NO Varchar2(10) Not Null,
COURSE_NO Varchar2(10) Not Null,
CORE Number,
OBJECT_VERSION_NUMBER Number Default 1 Not Null,
CREATION_DATE DATE Default Sysdate Not Null,
CREATED_BY NUMBER Default -1 Not Null,
LAST_UPDATED_BY NUMBER Default -1 Not Null,
LAST_UPDATE_DATE DATE Default Sysdate Not Null,
LAST_UPDATE_LOGIN NUMBER
);
-- Add comments to the table
comment on table HAND_STUDENT_CORE is '学生成绩表';
-- Add comments to the columns
comment on column HAND_STUDENT_CORE.STUDENT_NO is '学号';
comment on column HAND_STUDENT_CORE.COURSE_NO is '课程号';
comment on column HAND_STUDENT_CORE.CORE is '分数';
comment on column HAND_STUDENT_CORE.OBJECT_VERSION_NUMBER is '行版本号,用来处理锁';
-- Create/Recreate indexes
Create Unique Index HAND_STUDENT_CORE_U1 On HAND_STUDENT_CORE(STUDENT_NO,COURSE_NO);
/*******初始化学生表的数据******/
insert into HAND_STUDENT(STUDENT_NO,STUDENT_NAME,STUDENT_AGE,STUDENT_GENDER) values ('s001','张三',23,'男');
insert into HAND_STUDENT(STUDENT_NO,STUDENT_NAME,STUDENT_AGE,STUDENT_GENDER) values ('s002','李四',23,'男');
insert into HAND_STUDENT(STUDENT_NO,STUDENT_NAME,STUDENT_AGE,STUDENT_GENDER) values ('s003','吴鹏',25,'男');
insert into HAND_STUDENT(STUDENT_NO,STUDENT_NAME,STUDENT_AGE,STUDENT_GENDER) values ('s004','琴沁',20,'女');
insert into HAND_STUDENT(STUDENT_NO,STUDENT_NAME,STUDENT_AGE,STUDENT_GENDER) values ('s005','王丽',20,'女');
insert into HAND_STUDENT(STUDENT_NO,STUDENT_NAME,STUDENT_AGE,STUDENT_GENDER) values ('s006','李波',21,'男');
insert into HAND_STUDENT(STUDENT_NO,STUDENT_NAME,STUDENT_AGE,STUDENT_GENDER) values ('s007','刘玉',21,'男');
insert into HAND_STUDENT(STUDENT_NO,STUDENT_NAME,STUDENT_AGE,STUDENT_GENDER) values ('s008','萧蓉',21,'女');
insert into HAND_STUDENT(STUDENT_NO,STUDENT_NAME,STUDENT_AGE,STUDENT_GENDER) values ('s009','陈萧晓',23,'女');
insert into HAND_STUDENT(STUDENT_NO,STUDENT_NAME,STUDENT_AGE,STUDENT_GENDER) values ('s010','陈美',22,'女');
commit;
/******************初始化教师表***********************/
insert into HAND_TEACHER(TEACHER_NO,TEACHER_NAME,MANAGER_NO) values ('t001', '刘阳','');
insert into HAND_TEACHER(TEACHER_NO,TEACHER_NAME,MANAGER_NO) values ('t002', '谌燕','t001');
insert into HAND_TEACHER(TEACHER_NO,TEACHER_NAME,MANAGER_NO) values ('t003', '胡明星','t002');
commit;
/***************初始化课程表****************************/
insert into HAND_COURSE(COURSE_NO,COURSE_NAME,TEACHER_NO) values ('c001','J2SE','t002');
insert into HAND_COURSE(COURSE_NO,COURSE_NAME,TEACHER_NO) values ('c002','Java Web','t002');
insert into HAND_COURSE(COURSE_NO,COURSE_NAME,TEACHER_NO) values ('c003','SSH','t001');
insert into HAND_COURSE(COURSE_NO,COURSE_NAME,TEACHER_NO) values ('c004','Oracle','t001');
insert into HAND_COURSE(COURSE_NO,COURSE_NAME,TEACHER_NO) values ('c005','SQL SERVER 2005','t003');
insert into HAND_COURSE(COURSE_NO,COURSE_NAME,TEACHER_NO) values ('c006','C#','t003');
insert into HAND_COURSE(COURSE_NO,COURSE_NAME,TEACHER_NO) values ('c007','JavaScript','t002');
insert into HAND_COURSE(COURSE_NO,COURSE_NAME,TEACHER_NO) values ('c008','DIV+CSS','t001');
insert into HAND_COURSE(COURSE_NO,COURSE_NAME,TEACHER_NO) values ('c009','PHP','t003');
insert into HAND_COURSE(COURSE_NO,COURSE_NAME,TEACHER_NO) values ('c010','EJB3.0','t002');
commit;
/***************初始化成绩表***********************/
insert into HAND_STUDENT_CORE(STUDENT_NO,COURSE_NO,CORE) values ('s001','c001',58.9);
insert into HAND_STUDENT_CORE(STUDENT_NO,COURSE_NO,CORE) values ('s002','c001',80.9);
insert into HAND_STUDENT_CORE(STUDENT_NO,COURSE_NO,CORE) values ('s003','c001',81.9);
insert into HAND_STUDENT_CORE(STUDENT_NO,COURSE_NO,CORE) values ('s004','c001',60.9);
insert into HAND_STUDENT_CORE(STUDENT_NO,COURSE_NO,CORE) values ('s001','c002',82.9);
insert into HAND_STUDENT_CORE(STUDENT_NO,COURSE_NO,CORE) values ('s002','c002',72.9);
insert into HAND_STUDENT_CORE(STUDENT_NO,COURSE_NO,CORE) values ('s003','c002',81.9);
insert into HAND_STUDENT_CORE(STUDENT_NO,COURSE_NO,CORE) values ('s001','c003','59');
commit;
/**
alter table HAND_STUDENT_CORE add constraint FK_STUDENT_NO foreign key(STUDENT_NO) REFERENCES HAND_STUDENT(STUDENT_NO);
alter table HAND_STUDENT_CORE add constraint FK_COURSE_NO foreign key(COURSE_NO) REFERENCES HAND_COURSE(COURSE_NO);
alter table HAND_COURSE add constraint FK_TEACHER_NO foreign key(TEACHER_NO) REFERENCES HAND_TEACHER(TEACHER_NO);**/
改写:
1. 没有使用子查询的理由;
查询老师:谌燕 ,所教授的课程;
SELECT hc.COURSE_NO, hc.COURSE_NAME
FROM HAND_COURSE hc
WHERE TEACHER_NO =
(SELECT TEACHER_NO FROM HAND_TEACHER WHERE TEACHER_NAME = '谌燕');
2. 自定义更新语句,没有判断版本号,没有更新版本号+who字段
更新学生s001对应的课程 c002 成绩为 82.8
UPDATE HAND_STUDENT_CORE
SET CORE = 82.8
WHERE STUDENT_NO = 'S001'
AND COURSE_NO = 'c002';
--PDATE HAND_STUDENT_CORE
SET CORE = 82.8,
OBJECT_VERSION_NUMBER =OBJECT_VERSION_NUMBER+1,
LAST_UPDATED_BY = &userid,
LAST_UPDATE_DATE = sysdate,
WHERE STUDENT_NO = 'S001'
AND COURSE_NO = 'c002'
and OBJECT_VERSION_NUMBER=1
3. 子查询滥用,重复的子查询请简化;
查询学生s001 对应的成绩+教师编号+课程名称+课程编号
SELECT hsc.COURSE_NO,
(select COURSE_NAME
from HAND_COURSE i
where i.COURSE_NO = hsc.COURSE_NO) COURSE_NAME,
(select TEACHER_NO
from HAND_COURSE j
where j.COURSE_NO = hsc.COURSE_NO) TEACHER_NO,
hsc.CORE
FROM HAND_STUDENT_CORE hsc
where hsc.STUDENT_NO = 's001';
SELECT hsc.COURSE_NO,
(select COURSE_NAME
from HAND_COURSE i
where i.COURSE_NO = hsc.COURSE_NO) COURSE_NAME,
(select TEACHER_NO
from HAND_COURSE j
where j.COURSE_NO = hsc.COURSE_NO) TEACHER_NO,
hsc.CORE
FROM HAND_STUDENT_CORE hsc
where hsc.STUDENT_NO = 's001';
4. 条件语句中直接使用 case when,性能差,建议子查询封装
core 分数等级在 70分以下,差; 70-80分,良; 80分以上,优;
查询出所有成绩等级为"差"的学生及对应课程分数;
SELECT hs.STUDENT_NAME,
hsc.COURSE_NO,
(CASE
WHEN hsc.CORE > 80 THEN
'优'
WHEN hsc.CORE > 70 THEN
'良'
ELSE
'差'
END) type,
hsc.CORE
FROM HAND_STUDENT_CORE hsc, hand_student hs
where hsc.STUDENT_NO = hs.STUDENT_NO
and (CASE
WHEN hsc.CORE > 80 THEN
'优'
WHEN hsc.CORE > 70 THEN
'良'
ELSE
'差'
END) = '差' ;
5. 列名的函数运算,将不走索引
查询出所有加10分后,分数还低于80分的学生成绩;
SELECT hs.STUDENT_NAME, hsc.STUDENT_NO, hsc.COURSE_NO, hsc.CORE
FROM HAND_STUDENT_CORE hsc, hand_student hs
WHERE hsc.STUDENT_NO = hs.STUDENT_NO
and hsc.core + 10 < 80
order by hs.STUDENT_NAME;
6. 重复的SQL建议使用子查询整个进行封装 or 合适的方式进行改写;
查询老师:刘阳,所教授的课程;
SELECT hc.COURSE_NO,
hc.COURSE_NAME,
hc.TEACHER_NO,
(SELECT TEACHER_NAME
FROM HAND_TEACHER ht
where hc.TEACHER_NO = ht.TEACHER_NO) TEACHER_NAME
FROM HAND_COURSE hc
WHERE 1 = 1
and (SELECT TEACHER_NAME
FROM HAND_TEACHER ht
where hc.TEACHER_NO = ht.TEACHER_NO) = '刘阳';
7.Group by 与 distinct 混用
SELECT DISTINCT STUDENT_NO, COURSE_NO
FROM HAND_STUDENT_CORE
GROUP BY STUDENT_NO, COURSE_NO;
8. 内层的Group by 没有任何的限制条件,只能走全表扫描,建议改成子查询
计算学生的成绩总分;
大数据量,比如50万左右的数据可以明显看出执行计划上的差别,小数据量比如10几行可能错误的写法还更快,全表扫描比走索引快;
select hs.STUDENT_NO, hs.STUDENT_NAME, hc.cores
from hand_student hs
left join (SELECT STUDENT_NO, sum(CORE) cores
FROM HAND_STUDENT_CORE
GROUP BY STUDENT_NO) hc
on hs.STUDENT_NO = hc.STUDENT_NO;
9. 内层子查询的Group by 没有限制条件走全表扫描,外层where条件可作为限制,建议移到内层,走索引查询;内层多余的查询字段请去除,只使用有用的字段
select COURSE_NO, sum(core)
from (select STUDENT_NO, COURSE_NO, core
from HAND_STUDENT_CORE
union ALL
select STUDENT_NO, COURSE_NO, core
from HAND_STUDENT_CORE) a
where 1 = 1
and a.student_no = 's001'
group by COURSE_NO;
10. 存在全表扫描,可以如何提速;
SELECT hsc.COURSE_NO, hc.COURSE_NAME, hc.TEACHER_NO, hsc.CORE
FROM HAND_STUDENT_CORE hsc, HAND_COURSE hc
with (index(hsc.COURSE_NO))
where hsc.COURSE_NO = 'c001'
and hc.COURSE_NO = hsc.COURSE_NO;
---------------------------2019/11/4 黄泽东SQL练习 BY PLSQL-----------------------------------------
取合适的别名,字段不要取关键字
表少的时候最好是A B C D E
1.关键字:ROW_NUMBER
题目:请按渠道的首付酬金进行排序,找出排名为第3的渠道编码
CREATE TABLE DD_TABLE1
(
GROUP_ID VARCHAR (10), --渠道编码
PARAM_NAME VARCHAR (10), --酬金类别
VALUE INTEGER, --酬金金额
OP_TIME VARCHAR(100), --操作时间
OP_NOTE VARCHAR(100) --操作说明
);
Insert into DD_TABLE1
(GROUP_ID,PARAM_NAME,VALUE,OP_TIME,OP_NOTE)
Values
('51124', '首付酬金',789,'2008-07-17-09.23.01.000000', '运行状态正常');
Insert into DD_TABLE1
(GROUP_ID,PARAM_NAME,VALUE,OP_TIME,OP_NOTE)
Values
('51124', '按质支付',900,'2008-06-06-14.03.02.000000', '此渠道为三星级,5%分成比例');
Insert into DD_TABLE1
(GROUP_ID,PARAM_NAME,VALUE,OP_TIME,OP_NOTE)
Values
('51124', '分时见效',1000,'2008-08-20-22.05.48.000000', '二返三返发展酬金');
Insert into DD_TABLE1
(GROUP_ID,PARAM_NAME,VALUE,OP_TIME,OP_NOTE)
Values
('51124', '首付酬金',789,'2008-07-17-09.23.01.000000', '运行状态正常');
Insert into DD_TABLE1
(GROUP_ID,PARAM_NAME,VALUE,OP_TIME,OP_NOTE)
Values
('51124', '按质支付',900,'2008-06-06-14.03.02.000000', '此渠道为三星级,5%分成比例');
Insert into DD_TABLE1
(GROUP_ID,PARAM_NAME,VALUE,OP_TIME,OP_NOTE)
Values
('51124', '分时见效',1000,'2008-08-20-22.05.48.000000', '二返三返发展酬金');
--select * from (select rownum r,a.* from DD_TABLE1 a where rownum <=3 order by value) where r >= 3;
--答案:
/*select t.GROUP_ID
from (select rownum r, a.*
from DD_TABLE1 a
where rownum <= 3
order by value) T
where r >= 3;*/
row_number()函数 可排序也可分组
答案:
select * from(
select A.*,row_number()over(partition by PARAM_NAME order by GROUP_ID desc) RN
from DD_TABLE1 A where A.PARAM_NAME='首付酬金') B
WHERE RN=3
2.请写出查询 xjt1 表中存在xjt2表存在用户号码
请写出查询 xjt1 表中不存在xjt2表存在用户号码
CREATE TABLE XJT1
(PHONE_NO INTEGER, --电话号码
NAME VARCHAR(20), --姓名
OPEN_TIME VARCHAR(50) --办理时间
);
INSERT INTO XJT1 VALUES (13909092110, 'a', '20090101');
INSERT INTO XJT1 VALUES (13795923070, 'b', '20100101');
INSERT INTO XJT1 VALUES (13890912880, 'c', '20070912');
INSERT INTO XJT1 VALUES (13778926770, 'd', '20100101');
INSERT INTO XJT1 VALUES (13458825100, 'e', '20060901');
CREATE TABLE XJT2
(PHONE_NO INTEGER , --电话号码
NAME VARCHAR (20), --姓名
OPEN_TIME VARCHAR (50) --办理时间
);
INSERT INTO XJT2 VALUES (13458825100, 'a', '20060901');
INSERT INTO XJT2 VALUES (13778926770, 'b', '20100101');
INSERT INTO XJT2 VALUES (15284182050, 'c', '20070912');
INSERT INTO XJT2 VALUES (15181199330, 'd', '20100102');
INSERT INTO XJT2 VALUES (15196978260, 'e', '20100101');
--答案
select *
from XJT1 A
where exists (select 1 from XJT2 B where A.PHONE_NO = B.PHONE_NO);
select *
from XJT1 A
where not exists (select 1 from XJT2 B where A.PHONE_NO = B.PHONE_NO);
3.关键字:CASE WHEN
题目:添加一列 显示以下信息
第一类:集团成员数<20户的,且集团离网率<=15% 显示为A
第二类:20户≤集团成员数<50户的,且集团离网率<=10% 显示为 B
第三类:50户≤集团成员数<100户的,且集团离网率<=6% 显示为C
第四类:100户≤集团成员数<200户的,且集团离网率<=4% 显示为D
第五类:集团成员数>=200户的,且集团离网率<=2%显示为E
其他显示为X
CREATE TABLE PDJ_GROUP
(
GROUP_DETAIL_ID INTEGER, --集团编号
CNT INTEGER, --集团成员数
RATE DECIMAL(10,2)--集团离网率
);
INSERT INTO PDJ_GROUP VALUES(76451,15,0.01);
INSERT INTO PDJ_GROUP VALUES(76452,45,0.04);
INSERT INTO PDJ_GROUP VALUES(76451,65,0.03);
INSERT INTO PDJ_GROUP VALUES(76452,100,0.08);
INSERT INTO PDJ_GROUP VALUES(76453,120,0.07);
INSERT INTO PDJ_GROUP VALUES(76453,200,0.1);
INSERT INTO PDJ_GROUP VALUES(76451,267,0.15);
INSERT INTO PDJ_GROUP VALUES(76452,35,0.04);
INSERT INTO PDJ_GROUP VALUES(76453,10,0.07);
INSERT INTO PDJ_GROUP VALUES(76454,78,0.08);
--答案:
SELECT A.*,
CASE
WHEN A.CNT < 20 AND A.RATE <= 0.15 THEN
'A'
WHEN A.CNT >= 20 AND A.CNT < 50 AND A.RATE <= 0.1 THEN
'B'
WHEN A.CNT >= 50 AND A.CNT < 100 AND A.RATE <= 0.06 THEN
'C'
WHEN A.CNT >= 100 AND A.CNT < 200 AND A.RATE <= 0.04 THEN
'D'
WHEN A.CNT >= 200 AND A.RATE <= 0.02 THEN
'B'
ELSE 'X'
END "哈哈"
FROM PDJ_GROUP A
4.请写出查询 dm_call_cdr_201005 表中字段 CALL_DURATION_M 通话分钟数最大的前6条记录,同时把 START_DATETIME 字段替换成日期型
相关SQL
CREATE TABLE dm_call_cdr_201005
(
OP_TIME DATE NOT NULL,
OPPOSITE_NUMBER_OFF VARCHAR(24),
CALL_DURATION_M VARCHAR (10),
PHONE_NO VARCHAR (12),
IMEI VARCHAR (20),
START_DATETIME VARCHAR (26)
);
insert into dm_call_cdr_201005 values(to_date('2010-05-05','yyyy-mm-dd'),'15908496676','23','13778900540','353966012877970','2010-05-05-00.05.15.000000');
insert into dm_call_cdr_201005 values(to_date('2010-05-05','yyyy-mm-dd'),'15884113553','9' ,'13795820590','352373020164580','2010-05-05-00.06.08.000000');
insert into dm_call_cdr_201005 values(to_date('2010-05-05','yyyy-mm-dd'),'13980392801','34','13558964110','355573023963220','2010-05-05-00.05.40.000000');
insert into dm_call_cdr_201005 values(to_date('2010-05-05','yyyy-mm-dd'),'13778974438','23','13547714170','351580020086900','2010-05-05-00.03.53.000000');
insert into dm_call_cdr_201005 values(to_date('2010-05-05','yyyy-mm-dd'),'15281445099','65','13629037850','352774014171470','2010-05-05-00.01.07.000000');
insert into dm_call_cdr_201005 values(to_date('2010-05-05','yyyy-mm-dd'),'18784125110','6' ,'15884147720','359337036713310','2010-05-05-00.01.32.000000');
insert into dm_call_cdr_201005 values(to_date('2010-05-05','yyyy-mm-dd'),'15883141643','33','15183129560','359659021720010','2010-05-05-00.00.36.000000');
insert into dm_call_cdr_201005 values(to_date('2010-05-05','yyyy-mm-dd'),'15987035963','5' ,'15281444970','359753006625340','2010-05-05-00.01.37.000000');
insert into dm_call_cdr_201005 values(to_date('2010-05-05','yyyy-mm-dd'),'1008611','13','15281401350','351818030078720','2010-05-05-00.02.47.000000');
insert into dm_call_cdr_201005 values(to_date('2010-05-05','yyyy-mm-dd'),'18783176278','1' ,'13558953850','358380013494970','2010-05-05-00.02.04.000000');
--答案
select B.*
from (select A.* ,cast(to_timestamp(A.START_DATETIME, 'syyyy-mm-dd hh24:mi:ss.ff') as date) timestamp_to_date
from dm_call_cdr_201005 A
order by to_number(CALL_DURATION_M) desc) B
where rownum <= 6;
--select t.* from dm_call_cdr_201005 t where rownum<=6 order by to_number(CALL_DURATION_M) desc;
--select * from table1 where rownum<=10
--select t.* from dm_call_cdr_201005 t
5. 根据用户表、区县归属表,利用用户表里面的区县归属ID,请首先为区县ID创建索引,再以用户表为基础表。请查出用户属于翠屏区的所有工号。
相关sql
--用户表
CREATE TABLE BA_USER
(
ID NUMBER(10),
NAME VARCHAR(80),
LOGIN_NAME VARCHAR(20),
DISTRICT_ID VARCHAR(10),
IS_LOCKED NUMBER(1)
);
insert into BA_USER VALUES(18,'郑宜萍','kaaf49','33',0 );
insert into BA_USER VALUES(19,'马亮', 'kaaf65','1044919',0);
insert into BA_USER VALUES(20,'罗悟', 'kbba01','53',0);
insert into BA_USER VALUES(21,'张贤敏','kbba03','53',0);
insert into BA_USER VALUES(22,'黄雪梅','kbba05','53',0);
--区县归属表
CREATE TABLE BA_DISTRICT
(
ID VARCHAR(10) NOT NULL,
PARENT_ID VARCHAR(10),
NAME VARCHAR(255) NOT NULL,
IN_USE NUMBER(1) NOT NULL
);
insert into BA_DISTRICT values('12',' ','宜宾',1);
insert into BA_DISTRICT values('33','12','翠屏区',1);
insert into BA_DISTRICT values('1044919','33','城郊片区',1);
insert into BA_DISTRICT values('1002968','33','李庄片区',1);
insert into BA_DISTRICT values('53','12','宜宾县',1);
insert into BA_DISTRICT values('1044920','53','宜宾县渠道组',1);
insert into BA_DISTRICT values('121170','53','白花片区',1);
--为区县ID创建索引
--答案
CREATE INDEX IDX_BA_DISTRICT_ID ON BA_DISTRICT (ID)
--SELECT BU.* FROM BA_USER BU LEFT JOIN BA_DISTRICT BD ON BU.DISTRICT_ID=BD.ID WHERE BD.NAME='翠屏区'
--查出用户属于翠屏区的所有工号
--答案
SELECT A.LOGIN_NAME as "翠屏区用户的工号"
FROM BA_USER A
LEFT JOIN BA_DISTRICT B
ON A.DISTRICT_ID = B.ID
WHERE B.NAME = '翠屏区'
---------------------------2019/11/4 黄泽东SQL练习2 BY PLSQL-----------------------------------------
CREATE TABLE EMP(
EMPNO NUMBER(4),
ENAME VARCHAR2(10),
JOB VARCHAR2(9),
MGR NUMBER(4),
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2)
)
INSERT INTO EMP VALUES(7369,'SMITH','CLERK',7902,to_date('1980-12-17','yyyy-mm-dd'),800,'',20);
INSERT INTO EMP VALUES(7499,'ALLEN','SALESMAN',7902,to_date('1981-2-20','yyyy-mm-dd'),1600,'',30);
INSERT INTO EMP VALUES(7521,'WAED','SALESMAN',7902,to_date('1981-2-22','yyyy-mm-dd'),1250,'',30);
INSERT INTO EMP VALUES(7566,'JONES','MANAGER',7902,to_date('1981-4-2','yyyy-mm-dd'),2975,'',20);
INSERT INTO EMP VALUES(7654,'MARTIN','SALESMAN',7902,to_date('1981-9-28','yyyy-mm-dd'),1250,'',30);
INSERT INTO EMP VALUES(7698,'BLAKE','MANAGER',7902,to_date('1981-5-1','yyyy-mm-dd'),2850,'',30);
INSERT INTO EMP VALUES(7782,'CLARK','MANAGER',7902,to_date('1981-6-9','yyyy-mm-dd'),2450,'',10);
INSERT INTO EMP VALUES(7788,'SCOTT','ANALYST',7902,to_date('1987-4-19','yyyy-mm-dd'),3000,'',20);
INSERT INTO EMP VALUES(7839,'KING','PRESIDENT',7902,to_date('1981-11-17','yyyy-mm-dd'),5000,'',10);
INSERT INTO EMP VALUES(7844,'TURNER','SALESMAN',7902,to_date('1981-9-8','yyyy-mm-dd'),1500,'',30);
INSERT INTO EMP VALUES(7876,'ADAMS','CLERK',7902,to_date('1987-5-23','yyyy-mm-dd'),1100,'',20);
INSERT INTO EMP VALUES(7900,'JAMES','CLERK',7902,to_date('1981-12-3','yyyy-mm-dd'),950,'',30);
INSERT INTO EMP VALUES(7902,'FORD','ANALYST',7902,to_date('1981-12-3','yyyy-mm-dd'),3000,'',20);
INSERT INTO EMP VALUES(7934,'MILLER','CLERK',7902,to_date('1982-12-23','yyyy-mm-dd'),1300,'',10);
CREATE TABLE DEPT(
DEPTNO NUMBER(4),
DNAME VARCHAR2(14),
LOC VARCHAR2(13)
);
INSERT INTO DEPT VALUES(10,'ACCOUNTING','NEW YORK');
INSERT INTO DEPT VALUES(20,'RESEARCH','DALLAS');
INSERT INTO DEPT VALUES(30,'SALES','CHICAGO');
INSERT INTO DEPT VALUES(40,'OPERATIONS','BOSTON');
SELECT ROWID, A.* FROM EMP A;
SELECT * FROM DEPT
------------------------------------题目及答案------------------------
1.请查找出雇员名称为ALLEN的部门和地址信息
SELECT B.DEPTNO 部门, B.LOC 地址信息
FROM EMP A
LEFT JOIN DEPT B
ON A.DEPTNO = B.DEPTNO
WHERE A.ENAME = 'ALLEN';
2.请找出出生年月在1985年以后,并且薪水在2000以上的人员信息
--一般不用extra 截取特定的年月日
/*SELECT *
FROM EMP
WHERE EXTRACT(YEAR FROM HIREDATE) > 1985
AND SAL > 2000;*/
SELECT *
FROM EMP
WHERE to_number(to_char(HIREDATE,'yyyy'))> 1985
AND SAL > 2000;
3.在CHICAGO的员工工资提升10%,在DALLAS的员工工资提升20%,请使用case或者decode函数
--方法一case
SELECT B.LOC 地区,
CASE
WHEN B.LOC = 'CHICAGO' THEN
SAL * (1 + 0.1)
WHEN B.LOC = 'DALLAS' THEN
SAL * (1 + 0.2)
ELSE
SAL
END 工资
FROM EMP A
LEFT JOIN DEPT B
ON A.DEPTNO = B.DEPTNO;
-- decode方法
语法:decode(条件,值1,返回值1,值2,返回值2,...值n,返回值n,缺省值)
SELECT B.LOC 地区,
DECODE(B.LOC,'CHICAGO',SAL * (1 + 0.1),'DALLAS',SAL * (1 + 0.2),SAL) 工资
FROM EMP A
LEFT JOIN DEPT B
ON A.DEPTNO = B.DEPTNO;
4.新进员工 张三,1988年3月15号出生,工资1200,经理是CLARK
自己加条件补充
显示所有雇员的平均工资、总计工资、最高工资、最低工资
SELECT ROUND(SUM(SAL) / COUNT(*), 2) 平均工资,
SUM(SAL) 总计工资, MAX(SAL) 最高工资, MIN(SAL) 最低工资
FROM EMP
5.使用exists语句显示BLAKE所在部门的其他所有雇员,但是不要显示BLAKE
WHERE EXISTS(子查询) ,子查询返回的的是TRUE OR FALSE 即使是
SELECT * FROM DEPR WHERE EXISTS (SELECT NULL)
--正确写法
SELECT *
FROM EMP B
WHERE EXISTS
(SELECT *
FROM EMP C
WHERE C.EMPNO = B.EMPNO
AND C.ENAME <> 'BLAKE'
AND C.DEPTNO =
(SELECT A.DEPTNO FROM EMP A WHERE A.ENAME = 'BLAKE'))
;
/*SELECT B.DEPTNO
FROM DEPT B
WHERE NOT exists (SELECT A.DEPTNO
FROM EMP A
WHERE A.DEPTNO = B.DEPTNO
AND A.ENAME = 'BLAKE')
*/
/*思路 1.查询其他所有雇员 又要求用exists 则首先确定外表是 EMP 内表是DEPT 查询结果所示A表在B表上的映射 又因为关联是DEPTID即 结果只能初步筛选出映射的所有DEPTNO,接下来考虑的是进一步筛选
2.进一步筛选条件 根据BLAKE 可以得到确定的DEPTID,从而得到整个部门的雇员,最后筛选去除ENAME='BLAKE'即可*/
/*
错误的写法
SELECT T.ENAME 雇员名称, T.DEPTNO 部门编号
FROM (SELECT B.DEPTNO, B.ENAME
FROM EMP B
WHERE exists
(SELECT A.DEPTNO FROM DEPT A WHERE A.DEPTNO = B.DEPTNO)) T
WHERE T.ENAME <> 'BLAKE'
AND T.DEPTNO = (SELECT DEPTNO FROM EMP WHERE ENAME = 'BLAKE')*/
/*
错误的写法
SELECT T.ENAME 雇员名称, T.DEPTNO 部门编号
FROM (SELECT * FROM EMP) T
WHERE T.ENAME <> 'BLAKE'
AND T.DEPTNO = (SELECT DEPTNO FROM EMP WHERE ENAME = 'BLAKE')
*/
SELECT * FROM EMP
SELECT * FROM EMP A WHERE EXISTS (SELECT * FROM EMP B WHERE B.JOB LIKE '%CLERK%' AND A.EMPNO=B.EMPNO)
6.部门平均工资低于2000的提升20%
--思考 显然查询的是所有部门 使用 右连接
SELECT C.DNAME 部门名称 ,
C.DEPTNO 部门编号,
ROUND(C.SUM_SAL / C.NUMS) 平均工资,
CASE
WHEN ROUND(C.SUM_SAL / C.NUMS) < 2000 THEN
ROUND(C.SUM_SAL / C.NUMS) * (1 + 0.2)
ELSE
ROUND(C.SUM_SAL / C.NUMS)
END "提升20%后的工资"
FROM (SELECT B.DEPTNO DEPTNO,
B.DNAME DNAME,
SUM(SAL) SUM_SAL,
COUNT(*) NUMS
FROM EMP A
RIGHT JOIN DEPT B
ON B.DEPTNO = A.DEPTNO
GROUP BY (B.DEPTNO, B.DNAME)) C
/* SELECT C.DNAME,C.DEPTNO DEPRNO, ROUND(C.SUM_SAL / C.NUMS )AVERAGE_SAL
FROM (SELECT A.DEPTNO DEPTNO,B.DNAME DNAME, SUM(SAL) SUM_SAL, COUNT(*) NUMS
FROM EMP A RIGHT JOIN DEPT B ON B.DEPTNO = A.DEPTNO
GROUP BY(A.DEPTNO,B.DNAME) ) C*/
/*SELECT B.GROUP_ID, B.PARAM_NAME ,ROUND(B.SAL/B.NUM,2) FROM (
SELECT GROUP_ID, PARAM_NAME ,SUM(VALUE) SAL,COUNT(*) NUM FROM DD_TABLE1 A GROUP BY(PARAM_NAME,GROUP_ID)
)B */
7.显示超过部门平均工资的所有雇员信息
--,lpad(T.SAL,5)填充在左侧 使其左对齐
SELECT T.*,
ROUND(C.SUM_SAL / C.NUMS, 2) 平均工资,
CASE
WHEN T.SAL > ROUND(C.SUM_SAL / C.NUMS, 2) THEN
'是'
ELSE '否'
END 是否超过平均工资
FROM EMP T
LEFT JOIN (SELECT B.DEPTNO DEPTNO,
B.DNAME DNAME,
SUM(SAL) SUM_SAL,
COUNT(*) NUMS
FROM EMP A
RIGHT JOIN DEPT B
ON B.DEPTNO = A.DEPTNO
GROUP BY (B.DEPTNO, B.DNAME)) C
ON C.DEPTNO = T.DEPTNO
8. 显示所有雇员的年收入(工资+补助+奖金),奖金是部门的平均工资的2倍
SELECT T.*,
C.SUM_SAL 部门成员薪资总和,
C.NUMS 部门成员数量,
ROUND(C.SUM_SAL / C.NUMS, 2) AS 部门平均工资,
T.SAL + NVL(T.COMM, 0) + ROUND(C.SUM_SAL / C.NUMS, 2) * 2 AS 年收入
FROM EMP T
LEFT JOIN (SELECT B.DEPTNO DEPTNO,
B.DNAME DNAME,
SUM(SAL) SUM_SAL,
COUNT(*) NUMS
FROM EMP A
RIGHT JOIN DEPT B
ON B.DEPTNO = A.DEPTNO
GROUP BY (B.DEPTNO, B.DNAME)) C
ON C.DEPTNO = T.DEPTNO
9. 使用row_number()rank 不使用max() min(),筛选出所有雇员中最大年分、最小年分的雇员信息
SELECT ENAME 入职最小年份员工名称, TO_NUMBER(TO_CHAR(HIREDATE, 'YYYY')) 入职最小年份
FROM EMP
WHERE TO_NUMBER(TO_CHAR(HIREDATE, 'YYYY')) =
(SELECT B.FLAG_YEAR
FROM (SELECT ROWNUM FLAG, A.FLAG_YEAR FLAG_YEAR, A.ENAME ENAME
FROM (SELECT TO_NUMBER(TO_CHAR(HIREDATE, 'YYYY')) FLAG_YEAR,
ENAME,
ROW_NUMBER() OVER(PARTITION BY TO_NUMBER(TO_CHAR(HIREDATE, 'YYYY')) ORDER BY HIREDATE ASC) RN
FROM EMP
ORDER BY HIREDATE ASC) A) B
WHERE B.FLAG = 1
);
SELECT ENAME 入职最大年份员工名称,
TO_NUMBER(TO_CHAR(HIREDATE, 'YYYY')) 入职最大年份
FROM EMP
WHERE TO_NUMBER(TO_CHAR(HIREDATE, 'YYYY')) =
(SELECT B.FLAG_YEAR
FROM (SELECT ROWNUM FLAG, A.FLAG_YEAR FLAG_YEAR, A.ENAME ENAME
FROM (SELECT TO_NUMBER(TO_CHAR(HIREDATE, 'YYYY')) FLAG_YEAR,
ENAME,
ROW_NUMBER() OVER(PARTITION BY TO_NUMBER(TO_CHAR(HIREDATE, 'YYYY')) ORDER BY HIREDATE ASC) RN
FROM EMP
ORDER BY HIREDATE DESC) A) B
WHERE B.FLAG = 1);
/*SELECT ENAME 最小年份雇员名称,TO_NUMBER(TO_CHAR(HIREDATE,'YYYY')) 雇员入职最小年份
FROM EMP
WHERE TO_NUMBER(TO_CHAR(HIREDATE, 'YYYY')) =
(SELECT C.FLAG_YEAR 最大年份
FROM (SELECT ROWNUM, B.FLAG_YEAR FLAG_YEAR
FROM (SELECT A.HIREDATE ,TO_NUMBER(TO_CHAR(HIREDATE, 'YYYY')) FLAG_YEAR,
ROW_NUMBER() OVER(PARTITION BY HIREDATE ORDER BY HIREDATE ASC) RN
FROM EMP A ORDER BY HIREDATE ASC
) B
WHERE ROWNUM = 1) C);
*/
10. 使用row_number()rank 不使用max() min(),筛选出【部门】最大生日、最小生日的雇员信息
SELECT D.DEPTNO 部门编号, E.MAX_HIAREDATE 部门最大生日员工信息, E.MIN_HIAREDATE 部门最小生日员工信息
FROM DEPT D
LEFT JOIN (SELECT B.DEPTNO,
B.MIN_HIAREDATE MIN_HIAREDATE,
(SELECT C.MAX_YEAR
FROM (SELECT A.HIREDATE MAX_YEAR, A.DEPTNO DEPTNO
FROM (SELECT EMP.*,
ROW_NUMBER() OVER(PARTITION BY DEPTNO ORDER BY HIREDATE DESC) RN
FROM EMP) A
WHERE A.RN = 1) C
WHERE C.DEPTNO = B.DEPTNO) MAX_HIAREDATE
FROM (SELECT A.DEPTNO DEPTNO,
A.ENAME,
A.HIREDATE MIN_HIAREDATE
FROM (SELECT EMP.*,
ROW_NUMBER() OVER(PARTITION BY DEPTNO ORDER BY HIREDATE ASC) RN
FROM EMP) A
WHERE A.RN = 1) B) E
ON D.DEPTNO = E.DEPTNO
select * from EMP where rownum<=10
SELECT DEPTNO FROM EMP GROUP BY EMP.DEPTNO HAVING
SELECT DEPTNO FROM EMP WHERE DEPTNO >10 GROUP BY EMP.DEPTNO

DDL: 1.建表CREATE TABLE 修改表结构,添加,删,除,修改列长度 ALERT TABLE 删除表DROP TABLE 建立索引 CREATE INDEX 删除索引DROP INDEX
DML: INSERT DELETE UPDATE SELECT
DCL: GRANT 授予访问权限 REVOKE撤销访问权限 COMMIT提交事务处理 ROLLBACK事务处理回退 SAVEPOINT 设置保存点 LOCK 对数据库的特定部分进行锁定
1.常用函数
a.查询时间。指定格式
to_char(creation_date,'yyyy--mm--dd')
to_date('2019/11/2')
select to_char(sysdate),to_char(sysdate,'yyyy-MM-dd HH24:mm:ss'), to_date(sysdate),to_date(to_char(sysdate,'yyyy-MM-dd'),'yyyy-MM-dd')from dual
where to_char(sysdate,'yyyy-MM-dd')='2019-11-02'

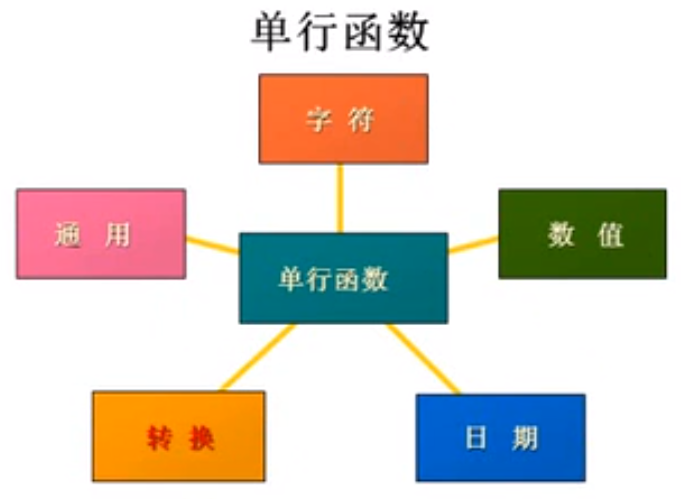
单行函数
字符函数分为
a.大小写控制函数 :小写 lower() 大写upper() 首字母大写 initcap()
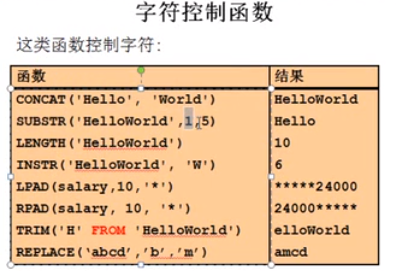
b.字符控制函数: 连接concat 截取函数substr 取得长度length 获取位置instr 左对齐 不足的位置用*替代 lpad 右对齐 rpad trim去掉首尾的指定的字符串 replace
数值函数分为

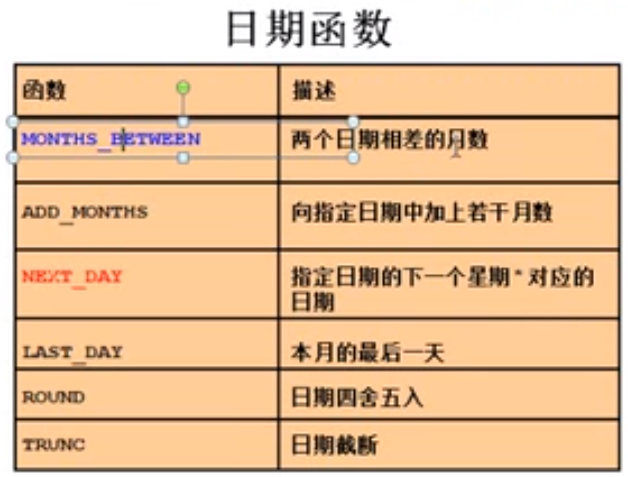
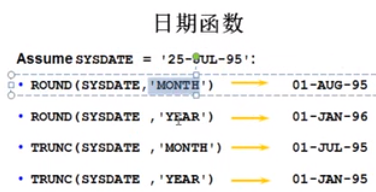
多行函数
赋值 :=
[范围包括边界]: between and
like 'a%' 首位是a
like '%a' 末尾是a
like '_a%' 第二位是a
like '%a%' 含有a的任意
*********** like '%_%'含有空格的的名字 不是表示有下划线
应该这样写 like '%\_%' escape '\' 或者 应该这样写 like '%#_%' escape '#' 多种写法
取别名 1.直接在查询字段后加名字 或者双引号 2。字段后加上as 再加别名或者双引号
|| 连接
distinct 去重
运算优先级
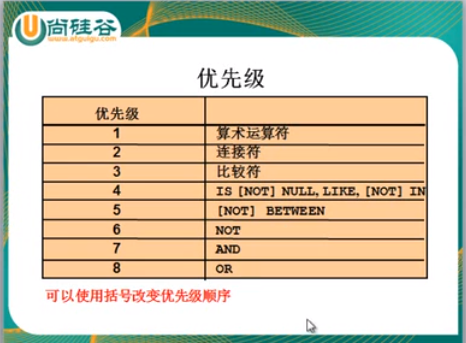
order by在结尾,在where后
oracle备份数据
1. 使用plsql
2.使用wndows 批处理脚本 + windows定时任务
--触发器测试
create or replace trigger update_hzd_table_trigger
after
update on hzd_table
for each row
begin dbms_output.put_line('触发器测试') ;
end;
update hzd_table ht set ht.age=19 where ht.age<55
ORACLE_笔记_练习题目的更多相关文章
- React笔记_(3)_react语法2
React笔记_(3)_react语法2 state和refs props就是在render渲染时,向组件内传递的变量,这个传递是单向的,只能继承下来读取. 如何进行双向传递呢? state (状态机 ...
- oracle_单向函数_数字化功能
oracle_单向函数_数字化功能 1.abs(x) 为了获得x绝对值 2.ceil(x) 用于获得大于或等于x的最小整数. 3.floor(x) 用于获得小于或等于x 4.mod(x,y ...
- 读经典——《CLR via C#》(Jeffrey Richter著) 笔记_发布者策略控制
在 读经典——<CLR via C#>(Jeffrey Richter著) 笔记_高级管理控制(配置)中,是由程序集的发布者将程序集的一个新版本发送给管理员,后者安装程序集,并手动编辑应用 ...
- jQuery源代码学习笔记_工具函数_noop/error/now/trim
jQuery源代码学习笔记_工具函数_noop/error/now/trim jquery提供了一系列的工具函数,用于支持其运行,今天主要分析noop/error/now/trim这4个函数: 1.n ...
- Net基础篇_学习笔记_第九天_数组_冒泡排序(面试常见题目)
冒泡排序: 将一个数组中的元素按照从大到小或从小到大的顺序进行排列. for循环的嵌套---专项课题 int[] nums={9,8,7,6,5,4,3,2,1,0}; 0 1 2 3 4 5 6 7 ...
- 数据结构习题Pop Sequence的理解----小白笔记^_^
Pop Sequence(25 分) Given a stack which can keep M numbers at most. Push N numbers in the order of 1, ...
- 第四期coding_group笔记_用CRF实现分词-词性标注
一.背景知识 1.1 什么是分词? NLP的基础任务分为三个部分,词法分析.句法分析和语义分析,其中词法分析中有一种方法叫Tokenization,对汉字以字为单位进行处理叫做分词. Example ...
- SSM框架学习笔记_第1章_SpringIOC概述
第1章 SpringIOC概述 Spring是一个轻量级的控制反转(IOC)和面向切面(AOP)的容器框架. 1.1 控制反转IOC IOC(inversion of controller)是一种概念 ...
- Python笔记_第一篇_面向过程_第一部分_6.语句的嵌套
学完条件控制语句和循环控制语句后,在这里就会把“语言”的精妙之处进行讲解,也就是语句的嵌套.我们在看别人代码的时候总会对一些算法拍案叫绝,里面包含精妙和精密的逻辑分析.语句的嵌套也就是在循环体内可以嵌 ...
随机推荐
- Windows7下IIS+php配置教程
WINDOWS 7 IIS+php配置教程,具体内容如下 打开 开始 -> 控制面板 -> 程序与功能 -> 打开或关闭windows功能 勾选Internet信息服务,并点击前面的 ...
- 阶段5 3.微服务项目【学成在线】_day02 CMS前端开发_12-webpack研究-webpack安装
npm默认安装配置的路径配置在nodejs的node_modules目录 j加上 -g 就是全局安装 后面只写webpack默认安装的是最新版本 指定版本号 视频中建议指定版本号进行安装
- 解决 Windows启动时要求验证
KB971033 微软检测盗版jar SLMGR -REARM 出现Window启动时要求验证版本, 在cmd窗口输入命令重新配置 重新启动即可 出现错误:解决办法 开始→设置,打开控制面板的“添加和 ...
- LeetCode_9. Palindrome Number
9. Palindrome Number Easy Determine whether an integer is a palindrome. An integer is a palindrome w ...
- iOS实现图片无限轮播之使用第三方库SDCycleScrollView(转)
下载链接:github不断更新地址:https://github.com/gsdios/SDCycleScrollView #import "ViewController.h" # ...
- jmeter性能测试的指标分析和定义
通常情况下,性能测试关注被测对象的时间与资源利用特性及稳定性.时间特性,即被测对象实现业务交易过程中所需的处理时间,从用户角度来说,越短越好.资源利用特性,即被测对象的系统资源占用情况,一般web系统 ...
- EMC DS300B光纤交换机扩展光口license
一.通过EMC指定的网站激活license 激活license,生成激活码需要三个信息: 1.交换机WWN号:可在交换机铭牌上查看:(16位) 2.SN号码:AQA00***9*6(11位) 3.ke ...
- 《精通并发与Netty》学习笔记(15 - 详解NIO中Buffer之position,limit,capacity)
一.前言熟悉NIO的人想必一定不会陌生buffer中position,limit,capacity这三个属性吧,之前在学习的时候遇到一个问题:就是当你先往缓冲区写入一部分数据,然后调用flip()方法 ...
- 在vue项目中获取当前城市
在vue项目中使用百度地图获取当前城市:https://www.jianshu.com/p/0819cfd46712 Vue2 :百度地图bmap:https://www.jianshu.com/p/ ...
- 《PC Assembly Language》读书笔记
本书下载地址:pcasm-book. 前言 8086处理器只支持实模式(real mode),不能满足安全.多任务等需求. Q:为什么实模式不安全.不支持多任务?为什么虚模式能解决这些问题? A: 以 ...