【Zookeeper】利用zookeeper搭建Hdoop HA高可用
HA概述
所谓HA(high available),即高可用(7*24小时不中断服务)。
实现高可用最关键的策略是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。
NameNode主要在以下两个方面影响HDFS集群
NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启
NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用
HDFS HA功能通过配置Active/Standby两个nameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
HDFS-HA工作机制
通过双namenode消除单点故障
HDFS-HA工作要点
(1)元数据管理方式需要改变:
内存中各自保存一份元数据;
Edits日志只有Active状态的namenode节点可以做写操作;
两个namenode都可以读取edits;
共享的edits放在一个共享存储中管理(qjournal和NFS两个主流实现);
(2)需要一个状态管理功能模块
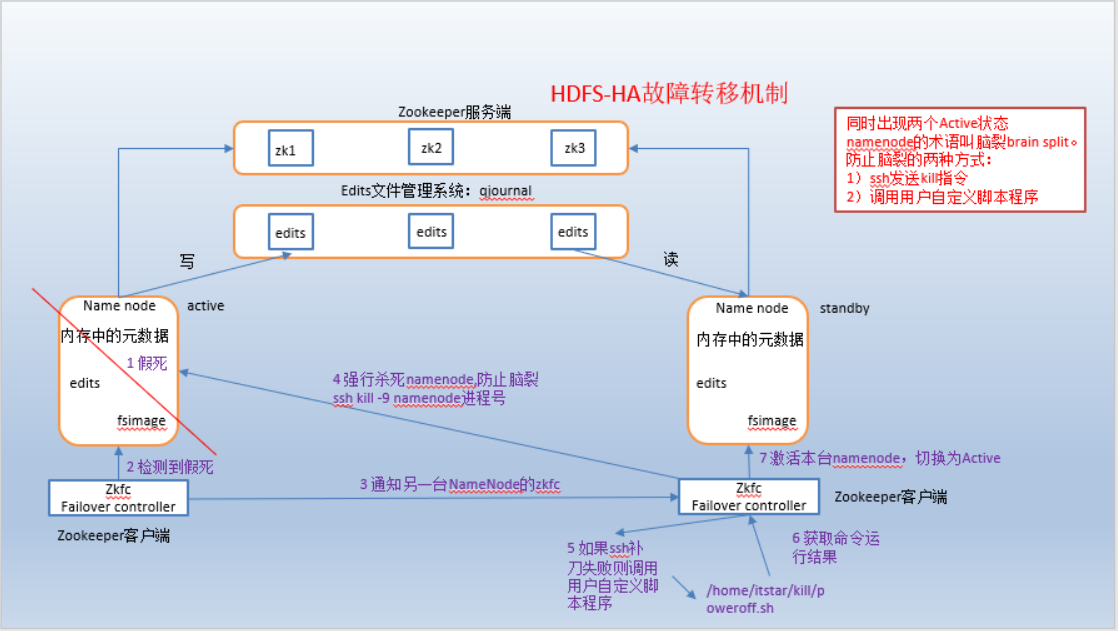
实现了一个zkfailover,常驻在每一个namenode所在的节点,每一个zkfailover负责监控自己所在namenode节点,利用zk进行状态标识,当需要进行状态切换时,由zkfailover来负责切换,切换时需要防止brain split现象的发生。
(3)必须保证两个NameNode之间能够ssh无密码登录。
(4)隔离(Fence),即同一时刻仅仅有一个NameNode对外提供服务
HDFS-HA自动故障转移机制
自动故障转移为HDFS部署增加了两个新组件:ZooKeeper 和 ZKFailoverController(ZKFC)进程。ZooKeeper是维护少量协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。HA的自动故障转移依赖于ZooKeeper的以下功能:
(1)故障检测:集群中的每个NameNode在ZooKeeper中维护了一个持久会话,如果机器崩溃,ZooKeeper中的会话将终止,ZooKeeper通知另一个NameNode需要触发故障转移。
(2)现役NameNode选择:ZooKeeper提供了一个简单的机制用于唯一的选择一个节点为active状态。如果目前现役NameNode崩溃,另一个节点可能从ZooKeeper获得特殊的排外锁以表明它应该成为现役NameNode。
ZKFC是自动故障转移中的另一个新组件,是ZooKeeper的客户端,也监视和管理NameNode的状态。每个运行NameNode的主机也运行了一个ZKFC进程,ZKFC负责:
(1)健康监测:ZKFC使用一个健康检查命令定期地ping与之在相同主机的NameNode,只要该NameNode及时地回复健康状态,ZKFC认为该节点是健康的。如果该节点崩溃,冻结或进入不健康状态,健康监测器标识该节点为非健康的。
(2)ZooKeeper会话管理:当本地NameNode是健康的,ZKFC保持一个在ZooKeeper中打开的会话。如果本地NameNode处于active状态,ZKFC也保持一个特殊的znode锁,该锁使用了ZooKeeper对短暂节点的支持,如果会话终止,锁节点将自动删除。
(3)基于ZooKeeper的选择:如果本地是健康的,且发现没有其它的节点当前持有锁,它将为自己获取该锁。如果成功,则它已经赢得了选择,并负责运行故障转移进程以使它的本地为。故障转移进程与前面描述的手动故障转移相似,首先如果必要保护之前的现役,然后本地转换为状态。
HDFS-HA集群配置
环境准备
1)修改IP
2)修改主机名及主机名和IP地址的映射
3)关闭防火墙
4)ssh免密登录
5)安装JDK,配置环境变量等
以上步骤可参照如下文章:
https://www.cnblogs.com/ShadowFiend/p/11449593.html
https://www.cnblogs.com/ShadowFiend/p/11450457.html
配置好的三台机器名称分别为:bigdata111,bigdata112,bigdata113;
规划集群
三台机器实现目标:
| bigdata111 | bigdata112 | bigdata113 |
|---|---|---|
| NameNode | NameNode | |
| DataNode | DataNode | DataNode |
| JournalNode | JournalNode | JournalNode |
| ZK | ZK | ZK |
| ZKFC | ZKFC |
配置Zookeeper集群
可参考如下文章:
搭建zookeeper分布式集群 :https://www.cnblogs.com/ShadowFiend/p/11445756.html
配置HDFS-HA集群
下载包
官方网址:http://hadoop.apache.org/ 找到hadoop安装包下载。
上传包
将下载好的hadoop包上传到/opt/soft/文件夹下;
[root@bigdata111 hadoop]# cd /opt/soft[root@bigdata111 soft]# rz
解压包
将上传的tar.gz包解压到/opt/module/HA/目录下,如果HA没有,则新建一个目录HA;
[root@bigdata111 module]# mkdir /opt/module/HA[root@bigdata111 module]# tar -zvxf /opt/soft/hadoop-2.8.4.tar.gz -C /opt/module/HA/
配置hadoop-env.sh
切换目录到/opt/module/HA/hadoop-2.8.4/etc/hadoop目录下,修改hadoop-env.sh;
[root@bigdata111 hadoop]# vi hadoop-env.sh
将JAVA_HOME修改为如下值:
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置core-site.xml
与上面的目录一样,执行vi core-site.xml命令,修改配置;
[root@bigdata111 hadoop]# vi core-site.xml
将Configuration节点修改如下值:
<configuration><!-- 把两个NameNode)的地址组装成一个集群mycluster --><property><name>fs.defaultFS</name><value>hdfs://mycluster</value></property><!-- 指定hadoop运行时产生文件的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/HA/hadoop-2.8.4/data</value></property></configuration>
配置hdfs-site.xml
执行vi hdfs-site.xml命令,修改hdfs配置;
[root@bigdata111 hadoop]# vi hdfs-site.xml
修改Configuration节点:
<configuration><!-- 完全分布式集群名称 --><property><name>dfs.nameservices</name><value>mycluster</value></property><!-- 集群中NameNode节点都有哪些 --><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><!-- nn1的RPC通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>bigdata111:9000</value></property><!-- nn2的RPC通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>bigdata112:9000</value></property><!-- nn1的http通信地址 --><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>bigdata111:50070</value></property><!-- nn2的http通信地址 --><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>bigdata112:50070</value></property><!-- 指定NameNode元数据在JournalNode上的存放位置 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://bigdata111:8485;bigdata112:8485;bigdata113:8485/mycluster</value></property><!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 --><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><!-- 使用隔离机制时需要ssh无秘钥登录--><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- 声明journalnode服务器存储目录--><property><name>dfs.journalnode.edits.dir</name><value>/opt/module/HA/hadoop-2.8.4/data/jn</value></property><!-- 关闭权限检查--><property><name>dfs.permissions.enable</name><value>false</value></property><!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式--><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property></configuration>
修改slaves
执行 vi slaves命令,修改配置;
[root@bigdata111 hadoop]# vi slaves
slaves内容如下:
bigdata111bigdata112bigdata113
发送其他机器
通过scp命令将/opt/module/HA/hadoop-2.8.4 目录发送到其他两台机器对应HA目录下;
[root@bigdata111 hadoop-2.8.4]# scp -r /opt/module/HA/hadoop-2.8.4/ root@bigdata112:/opt/module/HA/
[root@bigdata111 hadoop-2.8.4]# scp -r /opt/module/HA/hadoop-2.8.4/ root@bigdata113:/opt/module/HA/
启动HDFS-HA集群
启动journalnode服务
在三台机器上,分别输入以下命令启动journalnode服务,可以利用xshell的发送键到所有命令窗口功能;
[root@bigdata111 hadoop-2.8.4]# sbin/hadoop-daemon.sh start journalnodestarting journalnode, logging to /opt/module/HA/hadoop-2.8.4/logs/hadoop-root-journalnode-bigdata111.out
[root@bigdata112 hadoop-2.8.4]# sbin/hadoop-daemon.sh start journalnodestarting journalnode, logging to /opt/module/HA/hadoop-2.8.4/logs/hadoop-root-journalnode-bigdata112.out
[root@bigdata113 hadoop-2.8.4]# sbin/hadoop-daemon.sh start journalnodestarting journalnode, logging to /opt/module/HA/hadoop-2.8.4/logs/hadoop-root-journalnode-bigdata113.out
格式化nn1节点namenode
在bigdata111(nn1)上格式化namenode;
[root@bigdata111 hadoop-2.8.4]# bin/hdfs namenode -format
执行过程中,如果都是INFO,没有ERROR就代表格式化成功了;
启动格式化完毕的namenode;
[root@bigdata111 hadoop-2.8.4]# sbin/hadoop-daemon.sh start namenodestarting namenode, logging to /opt/module/HA/hadoop-2.8.4/logs/hadoop-root-namenode-bigdata111.out[root@bigdata111 hadoop-2.8.4]# jps5537 Jps5460 NameNode5342 JournalNode
nn2同步nn1的元数据
在bigdata112上同步bigdata111上的namenode元数据;
[root@bigdata112 hadoop-2.8.4]# bin/hdfs namenode -bootstrapStandby
启动nn2
启动bigdata112的namenode
[root@bigdata112 hadoop-2.8.4]# sbin/hadoop-daemon.sh start namenodestarting namenode, logging to /opt/module/HA/hadoop-2.8.4/logs/hadoop-root-namenode-bigdata112.out[root@bigdata112 hadoop-2.8.4]# jps4467 Jps4390 NameNode4285 JournalNode
查看节点web页面
bigdata111对应ip:192.168.1.111 则对应的web:192.168.1.111:50070
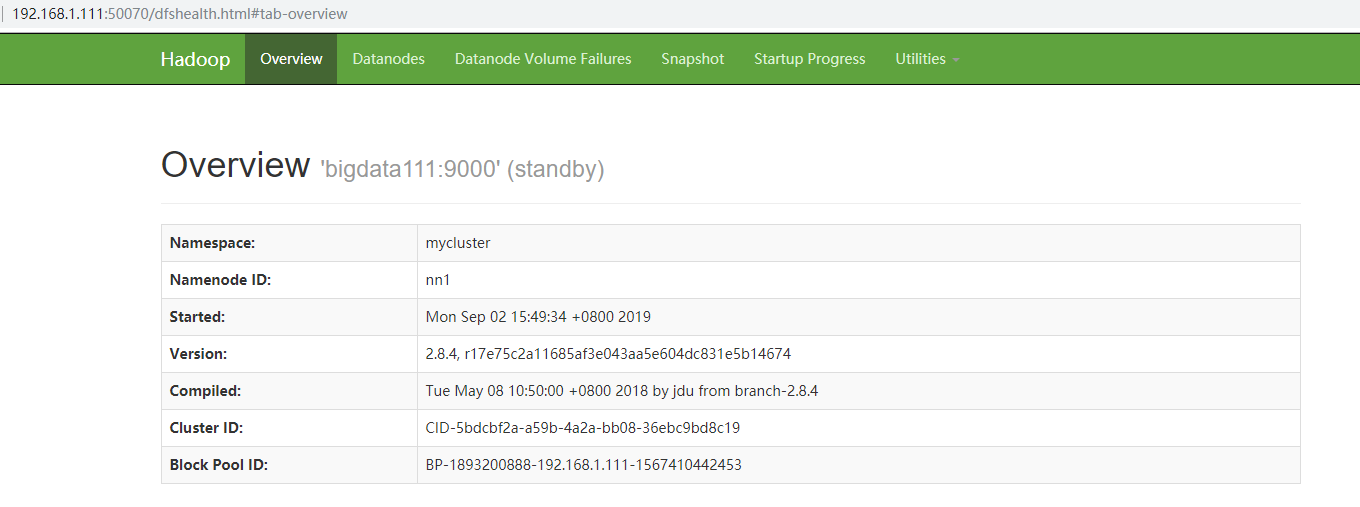
bigdata111对应ip:192.168.1.111 则对应的web:192.168.1.112:50070

启动所有datanode
启动所有的数据节点;(只需在bigdata111上执行即可)
[root@bigdata111 hadoop-2.8.4]# sbin/hadoop-daemons.sh start datanodebigdata113: starting datanode, logging to /opt/module/HA/hadoop-2.8.4/logs/hadoop-root-datanode-bigdata113.outbigdata111: starting datanode, logging to /opt/module/HA/hadoop-2.8.4/logs/hadoop-root-datanode-bigdata111.outbigdata112: starting datanode, logging to /opt/module/HA/hadoop-2.8.4/logs/hadoop-root-datanode-bigdata112.out[root@bigdata111 hadoop-2.8.4]# jps5460 NameNode5741 DataNode5821 Jps5342 JournalNode
将nn1切换为active
将nn1设置为active状态。
[root@bigdata111 hadoop-2.8.4]# bin/hdfs haadmin -transitionToActive nn1
web查看状态

命令查看节点状态
[root@bigdata111 hadoop-2.8.4]# bin/hdfs haadmin -getServiceState nn1active[root@bigdata111 hadoop-2.8.4]# bin/hdfs haadmin -getServiceState nn2standby
模拟故障转移
将nn1的节点进程杀死;看是否nn2会切换为active;
[root@bigdata111 hadoop-2.8.4]# jps5460 NameNode6023 Jps5741 DataNode5342 JournalNode[root@bigdata111 hadoop-2.8.4]# kill -9 5460[root@bigdata111 hadoop-2.8.4]# jps6033 Jps5741 DataNode5342 JournalNode[root@bigdata111 hadoop-2.8.4]# bin/hdfs haadmin -getServiceState nn2standby
通过结果可以看到,nn2并没有切换为active;所以并未达到自动故障转移目的,下面还有一点配置;
配置HDFS-HA自动故障转移
利用xshell的“发送键到所有命令窗口”功能,同时修改三台机器的配置;
切换到/opt/module/HA/hadoop-2.8.4/etc/hadoop目录下,
修改hdfs-site.xml
[root@bigdata111 hadoop]# vi hdfs-site.xml
在该文件Configuration节点下添加如下语句:
<property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property>
修改core-site.xml
同样利用xshell的“发送键到所有命令窗口”功能,同时修改三台机器的配置;目录与上面一样;
[root@bigdata111 hadoop]# vi core-site.xml
在Configuration节点添加如下语句:
<property><name>ha.zookeeper.quorum</name><value>bigdata111:2181,bigdata112:2181,bigdata113:2181</value></property>
安装fuser命令
linux默认不带fuser命令,安装此命令的目的,是避免HA在主备nn切换执行fuser失败的情况;
利用xshell的“发送键到所有命令窗口”功能,在三台机器同时执行以下命令:
[root@bigdata111 hadoop-2.8.4]# yum -y install psmisc
验证自动故障转移
启动服务
(1)关闭所有HDFS服务:
[root@bigdata111 hadoop-2.8.4]# sbin/stop-dfs.sh
(2)启动Zookeeper集群:
[root@bigdata111 hadoop-2.8.4]# zkServer.sh start
(3)初始化HA在Zookeeper中状态:
[root@bigdata111 hadoop-2.8.4]# bin/hdfs zkfc -formatZK
(4)启动HDFS服务:
[root@bigdata111 hadoop-2.8.4]# sbin/start-dfs.sh
(5)在各个NameNode节点上启动DFSZK Failover Controller,先在哪台机器启动,哪个机器的NameNode就是Active NameNode
[root@bigdata111 hadoop-2.8.4]# sbin/hadoop-daemon.sh start zkfc
3)验证
将Active状态的NameNode进程kill
[root@bigdata111 hadoop-2.8.4]# jps16977 DFSZKFailoverController18257 ResourceManager16482 JournalNode16882 QuorumPeerMain16628 NameNode18359 NodeManager19102 Jps16767 DataNode[root@bigdata111 hadoop-2.8.4]# bin/hdfs haadmin -getServiceState nn1active[root@bigdata111 hadoop-2.8.4]# bin/hdfs haadmin -getServiceState nn2standby[root@bigdata111 hadoop-2.8.4]# kill -9 16628[root@bigdata111 hadoop-2.8.4]# jps16977 DFSZKFailoverController18257 ResourceManager19185 Jps16482 JournalNode16882 QuorumPeerMain18359 NodeManager16767 DataNode[root@bigdata111 hadoop-2.8.4]# bin/hdfs haadmin -getServiceState nn2active
通过以上结果可以看出,已经自动切换新的namenode;
至此,HDFS-HA已经配置成功;
YARN-HA集群配置
YARN-HA工作机制
1)官方文档:
http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
2)YARN-HA工作机制
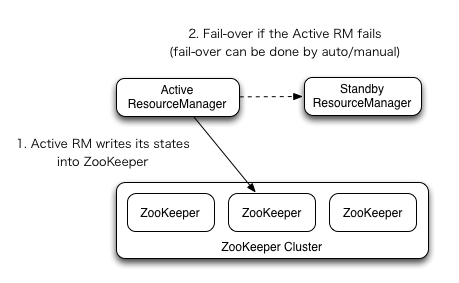
配置YARN-HA集群
环境准备
(1)修改IP
(2)修改主机名及主机名和IP地址的映射
(3)关闭防火墙
(4)ssh免密登录
(5)安装JDK,配置环境变量等
(6)配置Zookeeper集群
规划集群
三台机器实现目标
| bigdata111 | bigdata112 | bigdata113 |
|---|---|---|
| NameNode | NameNode | |
| DataNode | DataNode | DataNode |
| JournalNode | JournalNode | JournalNode |
| ZK | ZK | ZK |
| ZKFC | ZKFC | |
| ResourceManager | ResourceManager | |
| NodeManager | NodeManager | NodeManager |
具体配置
切换到 /opt/module/HA/hadoop-2.8.4/etc/hadoop 目录,修改yarn-site.xml
[root@bigdata111 hadoop]# vi yarn-site.xml
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!--启用resourcemanager ha--><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><!--声明两台resourcemanager的地址--><property><name>yarn.resourcemanager.cluster-id</name><value>cluster-yarn1</value></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>bigdata111</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>bigdata112</value></property><!--指定zookeeper集群的地址--><property><name>yarn.resourcemanager.zk-address</name><value>bigdata111:2181,bigdata112:2181,bigdata113:2181</value></property><!--启用自动恢复--><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><!--指定resourcemanager的状态信息存储在zookeeper集群--><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property>
启动HDFS
(1)在各个JournalNode节点上,输入以下命令启动journalnode服务:
[root@bigdata111 hadoop-2.8.4]# sbin/hadoop-daemon.sh start journalnode
(2)在[nn1]上,对其进行格式化,并启动:
[root@bigdata111 hadoop-2.8.4]# bin/hdfs namenode -format[root@bigdata111 hadoop-2.8.4]# sbin/hadoop-daemon.sh start namenode
(3)在[nn2]上,同步nn1的元数据信息:
[root@bigdata112 hadoop-2.8.4]# bin/hdfs namenode -bootstrapStandby
(4)启动[nn2]:
[root@bigdata112 hadoop-2.8.4]# sbin/hadoop-daemon.sh start namenode
(5)启动所有datanode
[root@bigdata112 hadoop-2.8.4]# sbin/hadoop-daemons.sh start datanode
(6)将[nn1]切换为Active
[root@bigdata111 hadoop-2.8.4]# bin/hdfs haadmin -transitionToActive nn1
启动YARN
(1)在bigdata111中启动yarn集群:
[root@bigdata111 hadoop-2.8.4]# sbin/start-yarn.sh
(2)在bigdata112中启动yarn的rm节点:
[root@bigdata111 hadoop-2.8.4]# sbin/yarn-daemon.sh start resourcemanager
(3)查看服务状态
[root@bigdata111 hadoop-2.8.4]# bin/yarn rmadmin -getServiceState rm1
验证yarn的自动故障迁移
(1)查看rm1和rm2的服务状态
[root@bigdata111 hadoop-2.8.4]# bin/yarn rmadmin -getServiceState rm1active[root@bigdata111 hadoop-2.8.4]# bin/yarn rmadmin -getServiceState rm2standby
(2)将active状态的rm1的进程杀死
[root@bigdata111 hadoop-2.8.4]# jps16977 DFSZKFailoverController18257 ResourceManager19265 NameNode16482 JournalNode16882 QuorumPeerMain20531 Jps18359 NodeManager16767 DataNode[root@bigdata111 hadoop-2.8.4]# kill -9 18257[root@bigdata111 hadoop-2.8.4]# jps16977 DFSZKFailoverController19265 NameNode16482 JournalNode16882 QuorumPeerMain18359 NodeManager20541 Jps16767 DataNode
(3)查看rm2的服务状态(注意:yarn的故障迁移有时间延迟,大概5秒左右再查看状态)
由下图可见,立即查看rm2时,并未及时更换rourcemanager节点;
5秒后,再运行就可以看到状态发生了改变;
[root@bigdata111 hadoop-2.8.4]# bin/yarn rmadmin -getServiceState rm2standby[root@bigdata111 hadoop-2.8.4]# bin/yarn rmadmin -getServiceState rm2active
至此,YARN-HA 就搭建成功了。
【Zookeeper】利用zookeeper搭建Hdoop HA高可用的更多相关文章
- Zookeeper(四)Hadoop HA高可用集群搭建
一.高可就集群搭建 1.集群规划 2.集群服务器准备 (1) 修改主机名(2) 修改 IP 地址(3) 添加主机名和 IP 映射(4) 同步服务器时间(5) 关闭防火墙(6) 配置免密登录(7) 安装 ...
- 七、Hadoop3.3.1 HA 高可用集群QJM (基于Zookeeper,NameNode高可用+Yarn高可用)
目录 前文 Hadoop3.3.1 HA 高可用集群的搭建 QJM 的 NameNode HA Hadoop HA模式搭建(高可用) 1.集群规划 2.Zookeeper集群搭建: 3.修改Hadoo ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- linux -- 基于zookeeper搭建yarn的HA高可用集群
linux -- 基于zookeeper搭建yarn的HA高可用集群 实现方式:配置yarn-site.xml配置文件 <configuration> <property> & ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
- centos7搭建hadoop2.10高可用(HA)
本篇介绍在centos7中搭建hadoop2.10高可用集群,首先准备6台机器:2台nn(namenode);4台dn(datanode):3台jns(journalnodes) IP hostnam ...
- Flink 集群搭建,Standalone,集群部署,HA高可用部署
基础环境 准备3台虚拟机 配置无密码登录 配置方法:https://ipooli.com/2020/04/linux_host/ 并且做好主机映射. 下载Flink https://www.apach ...
- HA高可用的搭建
HA 即 (high available)高可用,又被叫做双机热备,用于关键性业务. 简单理解就是,有两台机器A和B,正常是A提供服务,B待命闲置,当A宕机或服务宕掉,会切换至B机器继续提供服务.常用 ...
随机推荐
- Python 基础知识 (1) 持续更新
(1)数字和表达式 当进入Python交互式的时候,Python就可以直接当成计算机使用 如 >>> 2 + 2 4 但是 当 1个整数 和 另外一个整数 相除的时候,计算的结果,只 ...
- Java笔记(基础第四篇)
Java集合类 集合类概述 Java 语言的java.util包中提供了一些集合类,这些集合类又被称为容器.常用的集合有List集合.Set集合.Map集合,其中List与Set实现了Collecti ...
- stm32——modbus例程网址收藏
https://blog.csdn.net/baidu_31437863/article/details/82178708 STM32(五) Modbus https://blog.csdn.net/ ...
- BZOJ 4260: Codechef REBXOR (trie树维护异或最大值)
题意 分析 将区间异或和转化为前缀异或和.那么[L,R][L,R][L,R]的异或和就等于presum[R] xor presum[L−1]presum[R]\ xor \ presum[L-1]pr ...
- HDU 6088 - Rikka with Rock-paper-scissors | 2017 Multi-University Training Contest 5
思路和任意模数FFT模板都来自 这里 看了一晚上那篇<再探快速傅里叶变换>还是懵得不行,可能水平还没到- - 只能先存个模板了,这题单模数NTT跑了5.9s,没敢写三模数NTT,可能姿势太 ...
- ...cURL error 60: SSL certificate problem: unable to get local issuer certificate...
问题描述: 在做PHP爬虫的时候, 安装了 guzzle 和 dom-crawler 之后, 调用的时候出现问题, 如下 报错内容: Fatal error: Uncaught GuzzleHttp ...
- UTF-8 无 BOM
[参考] UTF8最好不要带BOM,附许多经典评论 Visual Studio UTF-8 无 BOM 一站式解决办法https://blog.csdn.net/dolphin98629/articl ...
- Android App常用控件
- python--批量修改文件夹名
python代码如下: import os , re import os.path rootdir = r'C:\Users\Administrator\Desktop\222' # rootdir ...
- Python相关分析—一个金融场景的案例实操
哲学告诉我们:世界是一个普遍联系的有机整体,现象之间客观上存在着某种有机联系,一种现象的发展变化,必然受与之关联的其他现象发展变化的制约与影响,在统计学中,这种依存关系可以分为相关关系和回归函数关系两 ...