最基础的分类算法-k近邻算法 kNN简介及Jupyter基础实现及Python实现
k-Nearest Neighbors简介
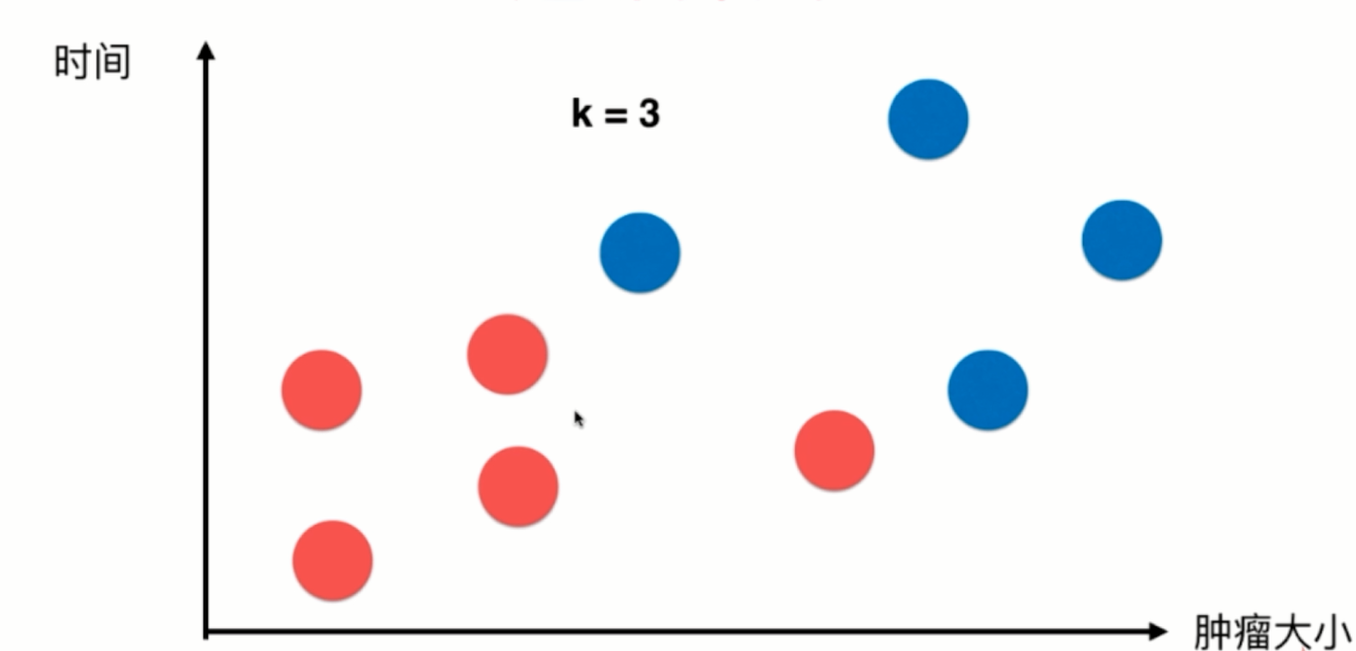
对于该图来说,x轴对应的是肿瘤的大小,y轴对应的是时间,蓝色样本表示恶性肿瘤,红色样本表示良性肿瘤,我们先假设k=3,这个k先不考虑怎么得到,先假设这个k是通过程序员经验得到。
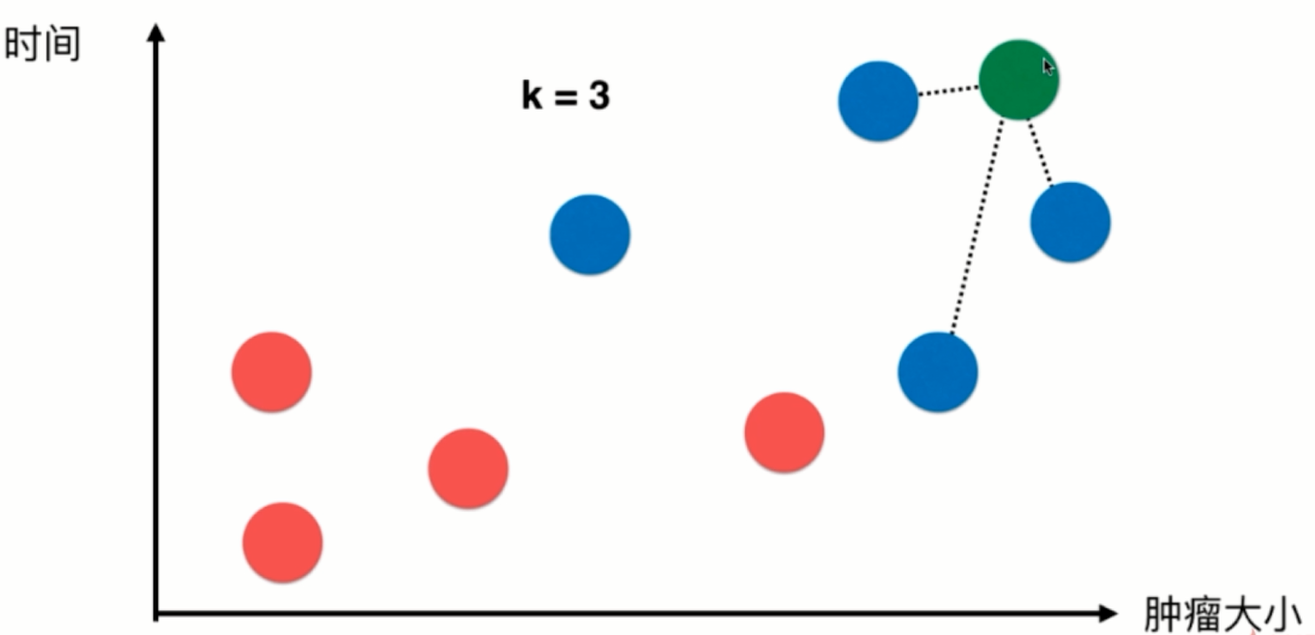
假设此时来了一个新的样本绿色,我们需要预测该样本的数据是良性还是恶性肿瘤。我们从训练样本中选择k=3个离新绿色样本最近的样本,以选取的样本点自己的结果进行投票,如图投票结果为蓝色:红色=3:0,所以预测绿色样本可能也是恶性肿瘤。
再比如
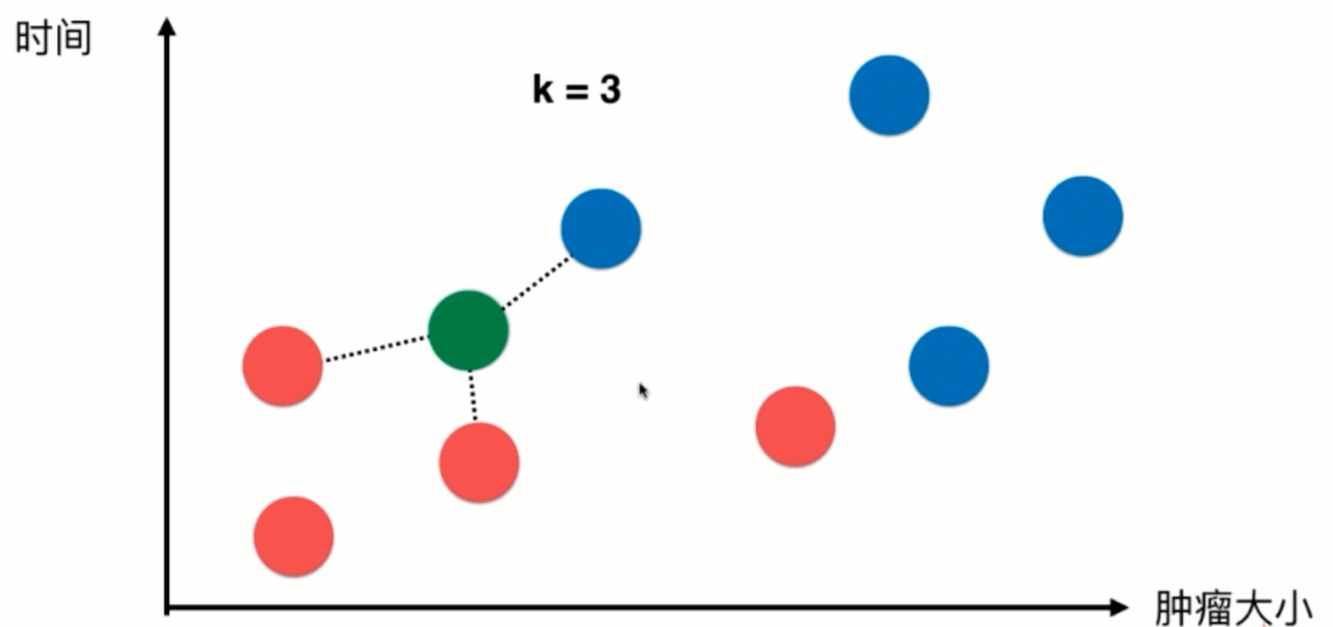
此时来了一个新样本,我们选取离该样本最近的三个样本点,根据他们自身的结果进行投票,如图得到蓝色:红色=1:2,那么我们可以预测该绿色样本可能也是良性肿瘤。
基础代码实现
#首先导入代码需要的package
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
#此处先使用我们模拟的数据进行算法的入门模拟
#特征点的集合
raw_data_X = [[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]
]
#0就代表良性肿瘤,1就代表恶性肿瘤
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
#我们使用raw_data_X和raw_data_y作为我们的训练集
X_train = np.array(raw_data_X) #训练数据集的特征
Y_train = np.array(raw_data_y) #训练数据集的结果(标签)
#此时可以查看两个训练集数据输出显示
In[1]: X_train
'''
Out [1]:array([[3.39353321, 2.33127338],
[3.11007348, 1.78153964],
[1.34380883, 3.36836095],
[3.58229404, 4.67917911],
[2.28036244, 2.86699026],
[7.42343694, 4.69652288],
[5.745052 , 3.5339898 ],
[9.17216862, 2.51110105],
[7.79278348, 3.42408894],
[7.93982082, 0.79163723]])
'''
In[2]: Y_train
'''
Out[2]:array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1])
'''
#我们可以尝试绘制原训练集的散点图
plt.scatter(X_train[Y_train == 0, 0],X_train[Y_train == 0,1], color = "red")
plt.scatter(X_train[Y_train == 1, 0],X_train[Y_train == 1,1], color = "blue")
plt.show() #显示该散点图
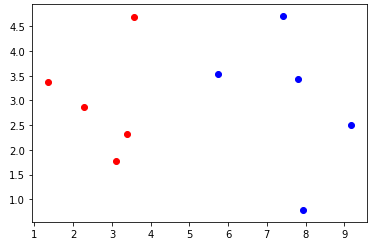
训练集绘制的散点图如上图所示,红色的散点表示为良性肿瘤的样本,蓝色表示为恶性肿瘤的样本
#此时,来了一个新样本数据 x
x = np.array([8.093607318,3.365731514])
#将新来的样本点绘入图像中,先绘制原训练集散点图像,再使用绿色表示新样本点进行绘制
plt.plot(X_train[Y_train == 0, 0],X_train[Y_train == 0, 1], color = "red")
plt.plot(X_train[Y_train == 1, 0],X_train[Y_train == 1, 1], color = "blue")
plt.plot(x[0],x[1], color = "green")
plt.show()

带新样本点绘制的散点图如上图所示
#此时我们假设根据程序员经验选取 k = 6
k = 6
#然后我们需要进行在原训练集中选取k个离新样本点最近的6个样本点
#两点之间的距离使用欧拉公式进行计算,

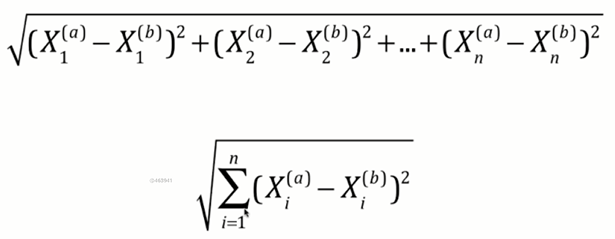
#所以根据上图公式我们可以进行计算所有训练集的样本点与新的绿色样本点的距离
#此处需要使用到开平方根,所以导入相应package
from math import sqrt
#使用distances进行存储所有距离值
distances = []
# 因为所有的训练集的X Y 信息都存储在X_train中,所以我们使用for循环进行遍历所有的样本点信息进行计算
for x_train in X_train:
#使用d暂存距离
d = sqrt(np.sum((x_train - x) ** 2))
#使用append将距离d存到distances
distances.append(d)
#上面for循环部分也能够使用列表推导式进行简化代码
distances = [sqrt(np.sum((X_train - x) ** 2)) for x_train in X_train]
#此时我们能够输出distances的值进行查看一下
In[3]: distances
Out[3]: [4.812566907609877,
5.229270827235305,
6.749798999160064,
4.6986266144110695,
5.83460014556857,
1.4900114024329525,
2.354574897431513,
1.3761132675144652,
0.3064319992975,
2.5786840957478887]
#此时我们的distances里面存储所有的训练样本点与新样本点的距离
#因为我们需要找到距离新样本点最近的k(此处k=6)个样本点,所有我们需要对distances进行排序
#此处我们使用np.argsort对其进行值的索引的排序,就不会对其值逻辑位置进行影响,使用nearest存储排序后的结果
nearest = np.argsort(distances)
#找到前6个索引对应的值对应的Y_train的值
topk_y = [Y_train[i] for i in nearest[:k]]
#此时我们输出topk_y的值
In[4]: topk_y
Out[4]:[1, 1, 1, 1, 1, 0]
#我们能够看到此时对应的topk_y中存储着离新样本点最近的k个训练样本点的结果(0/1 良性肿瘤/恶性肿瘤)
#然后我们对结果进行“投票”操作,票数最多的结果作为新样本的预测结果(前面已经介绍)
#可以调用Collections包中的Counter方法对topk_y进行唱票统计
from Collections import Counter
votes = Counter(topk_y)
#此时我们能够输出votes的值进行查看
In[4]: votes
Out[4]: Counter({1: 5, 0: 1})
#我们能够使用most_common(vaule)方法进行取最大票数的前value位
In[5]: votes.most_common(1)
Out[5]: [(1, 5)]
#查看该输出我们能够得到
predict_y = votes.most_common(1)[0][0]
In[6]: predict_y
Out[6]: 1
#此时kNN算法结束,根据所得到的预测结果,我们能够预测该新的样本可能是恶性肿瘤
Python实现
import numpy as np
from math import sqrt
from collections import Counter def kNN_classify(k, X_train, Y_train, x):
assert 1<= k <= X_train.shape[0],"k must be valid"
assert X_train.shape[0] == Y_train.shape[0], "the size of X-train must equal to the size of Y_train"
assert X_train.shape[1] == x.shape[0], "the feature number of x must be equal to X_train" distances = [sqrt(np.sum((X_train - x) ** 2)) for x_train in X_train]
nearest = np.argsort(distances) topk_y = [Y_train[i] for i in nearest[:k]]
votes = Counter(topk_y) return votes.most_common(1)[0][0]
最基础的分类算法-k近邻算法 kNN简介及Jupyter基础实现及Python实现的更多相关文章
- 第4章 最基础的分类算法-k近邻算法
思想极度简单 应用数学知识少 效果好(缺点?) 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 distances = [] for x_train in X_train ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 分类算法----k近邻算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
- python 机器学习(二)分类算法-k近邻算法
一.什么是K近邻算法? 定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. 来源: KNN算法最早是由Cover和Hart提 ...
- 【学习笔记】分类算法-k近邻算法
k-近邻算法采用测量不同特征值之间的距离来进行分类. 优点:精度高.对异常值不敏感.无数据输入假定 缺点:计算复杂度高.空间复杂度高 使用数据范围:数值型和标称型 用例子来理解k-近邻算法 电影可以按 ...
- k近邻算法
k 近邻算法是一种基本分类与回归方法.我现在只是想讨论分类问题中的k近邻法.k近邻算法的输入为实例的特征向量,对应于特征空间的点,输出的为实例的类别.k邻近法假设给定一个训练数据集,其中实例类别已定. ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- 02-16 k近邻算法
目录 k近邻算法 一.k近邻算法学习目标 二.k近邻算法引入 三.k近邻算法详解 3.1 k近邻算法三要素 3.1.1 k值的选择 3.1.2 最近邻算法 3.1.3 距离度量的方式 3.1.4 分类 ...
随机推荐
- idea中maven项目下载源码的方式的
当我们打开class文件的时候,右上角有个Download Sources的超链接,点击就可以下载源码了. 下载源码后,就变成java文件了.
- 避免复制引用程序集的XML文件
VS在编译时,默认会复制所有引用程序集对应的XML文件到输出目录. 在项目中设置AllowedReferenceRelatedFileExtensions可以避免复制操作. <PropertyG ...
- Appium移动自动化测试-----(十二)appium API 之 TouchAction 操作
Appium的辅助类,主要针对手势操作,比如滑动.长按.拖动等. 1.按压控件 方法: press() 开始按压一个元素或坐标点(x,y).通过手指按压手机屏幕的某个位置. press(WebElem ...
- 带你一步一步搭建TypeScript环境
今天继续来更新,本篇文章我们讲环境搭建,主要分享一些环境搭建的学习资源及安装步骤,解决一些安装时可能会出现的问题.下面就让我们一起进入学习第一步,搭建TypeScript环境:一. 环境搭建1.1. ...
- noVNC使用——访问多台vnc
一.模拟实验环境 1.CentOS6.8系统2.KVM环境3.使用KVM环境的两个系统(Windows,Linux)4.noVNC5.vncserver 二.实验过程1.在kvm的环境下,通过xml创 ...
- 软件素材--c/c++干掉代码的通用方法
while(1) { sleep(200); } #endif
- es原理
一: 一个请求到达es集群,选中一个coordinate节点以后,会通过请求路由到指定primary shard中,如果分发策略选择为round-robin,如果来4个请求,则2个打到primary ...
- python安装OpenCV – 4.1.0
(python3) [jiangshan@localhost ~]$ pip install opencv_python==4.1.0Collecting opencv_python==4.1.0 E ...
- 在 VMware 中安装 MacOS 全记录
在 VMware 15 中安装 MacOS Mojave 安装文件 下载:Unlocker v3.0 for VMware 15地址:https://github.com/DrDonk/unlocke ...
- WxWidgets与其他工具包的比较(15种方案)
一些一般注意事项: wxWidgets不仅适用于C ++,而且具有python,perl,php,java,lua,lisp,erlang,eiffel,C#(.NET),BASIC,ruby甚至ja ...