sklearn--模型的评价
sklearn.metrics
1.MSE(均方误差)和RMSE(均方根误差),以及score()
lr.score(test_x,test_y)#越接近1越好,负的很差
from sklearn.metrics import mean_squared_error
mean_squared_error(test_y,lr.predict(test_x))#mse
np.sqrt(mean_squared_error(test_y,lr.predict(test_x)))
from sklearn.metrics import accuracy_score
print(accuracy_score(predict_results, target_test))
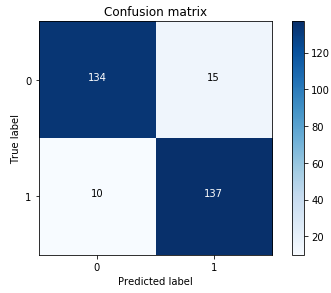
2.混淆矩阵
混淆矩阵的每一列代表了预测类别 ,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。每一列中的数值表示真实数据被预测为该类的数目:如下图,第一行第一列中的43表示有43个实际归属第一类的实例被预测为第一类,同理,第二行第一列的2表示有2个实际归属为第二类的实例被错误预测为第一类。
cnf_matrix = confusion_matrix(y_test_undersample,y_pred_undersample)
import seaborn as sns
sns.heatmap(cnf_matrix,cmap="Blues",annot=True,fmt='d',square=True)
plt.ylabel('True Label')
plt.xlabel('pre Label')
plt.title('Confusion matrix')
学习曲线
通过观察训练集和测试集的得分来看两个曲线的靠近程度,如果是两个曲线的方差太大,测试集差训练集好,则说明是过拟合,如果两个曲线方差不太大,两个的训练的效果都不好,这就说明是欠拟合
from sklearn.model_selection import learning_curve #绘制学习曲线,以确定模型的状况
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
train_sizes=np.linspace(.1, 1.0, 5)):
"""
画出data在某模型上的learning curve.
参数解释
----------
estimator : 你用的分类器。
title : 表格的标题。
X : 输入的feature,numpy类型
y : 输入的target vector
ylim : tuple格式的(ymin, ymax), 设定图像中纵坐标的最低点和最高点
cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份)
"""
plt.figure()
train_sizes, train_scores, test_scores = learning_curve( estimator, X, y, cv=5, n_jobs=1, train_sizes=train_sizes,scoring='neg_mean_squared_error')
train_scores=np.sqrt(-train_scores)
test_scores=np.sqrt(-test_scores)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1, color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score")
plt.xlabel("Training examples")
plt.ylabel("Score")
plt.legend(loc="best")
plt.grid("on")
if ylim:
plt.ylim(ylim)
plt.title(title)
plt.show() #少样本的情况情况下绘出学习曲线

sklearn--模型的评价的更多相关文章
- sklearn 模型选择和评估
一.模型验证方法如下: 通过交叉验证得分:model_sleection.cross_val_score(estimator,X) 对每个输入数据点产生交叉验证估计:model_selection.c ...
- sklearn模型保存与加载
sklearn模型保存与加载 sklearn模型的保存和加载API 线性回归的模型保存加载案例 保存模型 sklearn模型的保存和加载API from sklearn.externals impor ...
- python sklearn模型的保存
使用python的机器学习包sklearn的时候,如果训练集是固定的,我们往往想要将一次训练的模型结果保存起来,以便下一次使用,这样能够避免每次运行时都要重新训练模型时的麻烦. 在python里面,有 ...
- sklearn模型的属性与功能-【老鱼学sklearn】
本节主要讲述模型中的各种属性及其含义. 例如上个博文中,我们有用线性回归模型来拟合房价. # 创建线性回归模型 model = LinearRegression() # 训练模型 model.fit( ...
- sklearn模型保存
使用sklearn训练完模型之后,只有将模型持久化到硬盘上,才能方便下次直接使用. 第一种方式:使用pickle >>> from sklearn import svm >&g ...
- sklearn 模型评估
原文链接 http://d0evi1.com/sklearn/model_evaluation/ 预测值:pred 真实值:y_test #### 直接用平均值 ``` mean(pred == y_ ...
- Sklearn,TensorFlow,keras模型保存与读取
一.sklearn模型保存与读取 1.保存 from sklearn.externals import joblib from sklearn import svm X = [[0, 0], [1, ...
- sklearn中模型评估和预测
一.模型验证方法如下: 通过交叉验证得分:model_sleection.cross_val_score(estimator,X) 对每个输入数据点产生交叉验证估计:model_selection.c ...
- Sklearn数据集与机器学习
sklearn数据集与机器学习组成 机器学习组成:模型.策略.优化 <统计机器学习>中指出:机器学习=模型+策略+算法.其实机器学习可以表示为:Learning= Representati ...
- python进行机器学习(四)之模型验证与参数选择
一.模型验证 进行模型验证的一个重要目的是要选出一个最合适的模型,对于监督学习而言,我们希望模型对于未知数据的泛化能力强,所以就需要模型验证这一过程来体现不同的模型对于未知数据的表现效果. 这里我们将 ...
随机推荐
- 安装ELectron失败解决方案
npm安装Electron解决方案 Electron使用npm安装时,因为是国外的镜像源,所以速度会非常慢.而使用cnpm如下命令进行安装时,又会出现安装失败的问题: npm install elec ...
- ECS适合你吗?
实体组件系统处于预览状态.不建议用于生产. 目前有两个很好的理由使用它. 你想试验 这是令人兴奋的新技术,并且大规模性能提升的承诺正在引诱.试试看.给我们您的反馈.我们很乐意在论坛上与您交谈. 您正在 ...
- “但行好事 莫问前程 只问耕耘 不问收获 成功不必在我 而功力必不唐捐” 科技袁人·年终盛典——5G是科技时代非常重要的基础设施
中国的科技实力:用数据对比展示当前中国整体科技实力在国际中的发展水平和未来的发展趋势. 主要分为基础研究和应用研究.其中基础研究通过论文数据进行对比展示,应用研究通过发明专利数据. 又分别结合当今中国 ...
- 洛谷P2604 最大流+最小费用最大流
题目链接:https://www.luogu.org/problem/P2604 题目描述 给定一张有向图,每条边都有一个容量C和一个扩容费用W.这里扩容费用是指将容量扩大1所需的费用.求: 1. 在 ...
- hdu 2871 Memory Control (区间合并 连续段的起始位置 点所属段的左右端点)
链接:http://acm.hdu.edu.cn/showproblem.php?pid=2871 题意: 四种操作: 1.Reset 清空所有内存2.New x 分配一个大小为x的内存块返回,返 ...
- 《你必须知道的495个C语言问题》读书笔记之第1-2章:声明和初始化
1. C标准中并没有精确定义数值类型的大小,但作了以下约束: (1) char类型可以存放小于等于127的值: (2) short int和int可以存放小于等于32767的值: (3) long i ...
- emacs 常用命令
C stands for Ctrl and M stands for Alt REFERENCE FORM EMACS TUTORIAL 表述不一定正确,仅供参考,主要是要多实践,一开始可能会不习惯 ...
- 【计算机网络】-传输层-Internet传输协议-UDP
[计算机网络]-传输层-UDP 简介 Internet协议集支持一个无连接的传输协议,该协议称为用户数据报协议(UDP,UserDatagram Protocol) .UDP为应用程序提供了一-种无需 ...
- gcc命令-更新中....
下载安装MinGW 1.编译c 使用gcc xx.c命令,将文件编译为a.exe.或使用gcc xx.c -o xx.exe命令,将文件编译为xx.exe 2.编译c++ 使用g++ xx.cpp命令 ...
- fiddler笔记:快捷工具栏
WinConfig: Comment 为所有选中的Session添加Comment. Replay Replay+ctrl 重新发送请求,而不包括任何条件请求头. Replay+shift 指定每 ...