深度学习课程笔记(十一)初探 Capsule Network
深度学习课程笔记(十一)初探 Capsule Network
2018-02-01 15:58:52
一、先列出几个不错的 reference:
3. 原始文章:Dynamic Routing Between Capsules Link:https://arxiv.org/pdf/1710.09829.pdf
4. 李宏毅老师的 YouTube 视频教程:https://www.youtube.com/watch?v=UhGWH3hb3Hk
5. Code Pytorch 实现:https://github.com/timomernick/pytorch-capsule
5.1 其他版本:https://mp.weixin.qq.com/s/FZQ3KgW8ZdC4NbramgeNuw
5.2 Hinton胶囊网络代码正式开源,5天GitHub fork超1.4万
6. Jonathan Hui blog :
6.1 、“Understanding Dynamic Routing between Capsules (Capsule Networks)”
6.2、“Understanding Matrix capsules with EM Routing (Based on Hinton's Capsule Networks)”
7. Video Tutorials:
7.1、Capsule networks: overview
7.2、
二、初探 Capsule Networks(胶囊网络):
Hinton 最近提出一种新的神经网络结构,称为“胶囊网络”,作为深度学习的大牛,其影响力可想而知。有可能引起新一波的 follow 和 各种 interesting 的应用。
首先,我们先回顾下传统的 CNNs 有什么缺点:
CNNs 有多吊就不用说了吧,各种 amazing 的事情都可以做,而这些事情是远远超乎人类想象的。但是,它还是有根本性的缺点:

我们可以看到,对于 CNNs 来说,当图像中出现,眼睛,鼻子,嘴巴等部件时,CNNs 会认为这是一张 face,不管这些部件出现在什么位置,都是这样子。CNNs 是怎么工作的呢?我们知道,卷积层是 CNN 的重要组成部分,它会尽可能的去检测出重要的模式,然后逐渐的形成 high level 的 feature,然后将这些 feature 继续编辑成更加 high level 的 feature。然后用 fc layer 输出最终的分类结果。
一个重要的信息是:高层的 feature 是在底层特征基础上 加权求和得到的:activations of a precedings layers are multiplied by the following layer neuron's weights and added, before being passed to acitivation nonlinearity. 在这个过程中,无处不在的是 pose realtionship (translational and rotational),并将底层特征,构建成更加高低的高层特征。CNN 的方法来解决这个问题的方式,是利用 max pooling 或者 连续的卷积层,来降低数据的尺寸,所以增加了高层神经元的“感受野”,所以,允许他们可以在输入图像上的更大的区域内检测到更高层的feature。Max pooling 是使得 CNN 能够工作的非常好的重要原因。但是也别被其良好的结果所欺骗了:while CNNs work better than any model before them, max pooling nonetheless is losing valuable information.
就连老爷子自己都说, max pooling layer 能够如此的 work,这是个大问题:

当然了,你可以继续使用 max pooling,他依然可以得到很好的结果。但是,他依然不能够解决关键的问题(key problems):

在上面的例子当中,仅仅出现face 的各个部件,并不意味着,这张图就是一个 face 的图像,我们也需要知道这些部件之间是如何构建起来的。
Hardcoding 3D world into a neural net: Inverse Graphics Approach
计算机图形学尝试解决的问题是 从一些间隔的几何数据上来构建出一张 visual image。注意到,这样的表示,需要将物体的相对位置考虑进去。而存储在计算机内存中的 中间的表示(internal representation)是作为几何物体的数组,矩阵来表示相对位置以及这些物体的方向。然后,用特殊的软件将其凑成一个图像,这个过程称之为:rendering 。

受到这个idea的启发,Hinton argues that:大脑,也是这样子,做了和 rendering 相反的事情。他称之为:inverse graphics:from visual information received by eyes, they demonstrate a hierarchical representation of the world around us and try to match it with already learned patterns and relationships stored in the brain. 这就是 recognition 发生的过程。And the key idea is that representation of objects in the brain does not depend on view angle.
所以,现在问题变成了:我们如何将这些 hierarchical relationships 建模到 NN 当中呢? 答案来自于 计算机图形学,在 3D图形学当中,3D 物体之间的关系可以表达为所谓的 pose, 就是: translation + rotation。
Hiton 说,为了更好的进行分类和物体的识别,保留物体部件之间的关系是非常重要的。这就是为什么 胶囊理论 如此重要的原因了。他将物体之间的相对关系,表达成了 4D pose matrix。
当这些关系表示到数据的 internal representation 时,这就可以让 NN 理解到:他现在所看到的东西,就是之前看到的东西,只不过就是不同的角度而已。考虑下面的图像,你可以轻易地发现:
自由女神像:无论从那个角度,你都会发现,哦,这都是女神像。
这是因为,internal representation 在你的脑子中,不依赖于 the view angle。你可能从来没有看到过具体角度的图像,但是你可能立刻就知道,哦,这就是那个图。

而对于 CNN 来说,这个 task 看似很简单,但是他却很难理解。而对于 胶囊网络来说,却非常容易了,因为他们显示的进行建模。这个文章利用这种方法,将识别的错误率降低到了 45%,跟其他方法相比,这已经是一个巨大的提升了。
Capsule 的方法另一个好处就是: 能够仅仅利用 CNN 耗费的少量数据就可以达到顶尖的效果(见 Hinton 的 talk:https://www.youtube.com/watch?v=rTawFwUvnLE&feature=youtu.be)。在这个程度上来说, capsule network 更加接近人类大脑的识别方法。In order to learn to tell digits apart, the human brain needs to see only a couple of dozens of examples, hundreds at most. CNNs, on the other hand, need tens of thousands of examples to achieve very good performance, which seems like a brute force approach that is clearly inferior to what we do with our brains。
这个 idea 看起来很简单,但是为什么花费了那么长时间才搞出来呢???
Hinton 想这个idea将近 10年了。一直未能发表的原因是:之前没有那么好的计算力,能够使他work。另一个原因是:没有好的算法来执行这个事情,并且成功的学习一个 capsule network(直到 1980s 当 BP算法被提出来,并且成功应用于训练神经网络的时候)。
同样的道理, capsule 的想法本身并不是非常的新,Hinton之前也提到过,但是并没有好的算法出现,使其能够很好的 work。这个算法就称为:“dynamic routing between capsules”。这个算法允许 capsule 能够相互交流,并且创造出类似于 计算机图形学中 scene graphs 的表示方法。

小结:
Capsules introduce a new building block that can be used in deep learning to better model hierarchical relationships inside of internal knowledge representation of a neural network. Intuition behind them is very simple and elegant. Nonetheless, there are challenges. Current implementations are much slower than other modern deep learning models. Time will show if capsule networks can be trained quickly and efficiently. In addition, we need to see if they work well on more difficult data sets and in different domains. In any case, the capsule network is a very interesting and already working model which will definitely get more developed over time and contribute to further expansion of deep learning application domain.
三、深入理解 胶囊网络:
1. what is a Capsule ???

太长了,不想看,说人话,简而言之,就是:
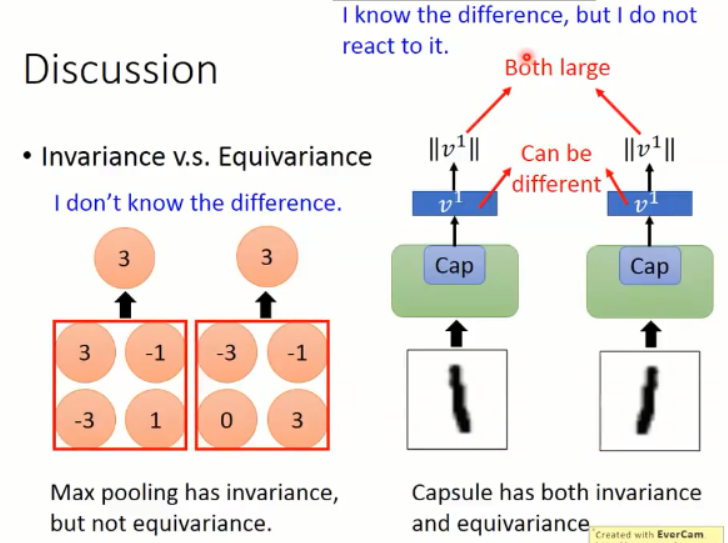
神经元输出的是 a single scalar。另外, CNN 利用 卷积层,对于每一个 kernel 来说,然后复制同一个 kernel 的权重,然后输出一个 2D 的matrix,每一个值的输出是:那个卷积核与局部图像的点乘加和。我们可以将这个 2D matrix 看做是 复制的 feature detector 的输出。然后所有的卷积核的 2D 矩阵依次堆叠起来,来产生一个卷积层的输出。然后,我们利用 max pooling 来达到旋转不变性的目标。
但是上述的机制,并不是非常完美。因为在达到这个目标,而做 max pooling 的同时,我们丢失了非常重要的信息:物体之间的关联。我们应该用 capsule 来替换,因为他们将所有的重要信息,都编码到输出的 vector 当中,而不是传统 CNN 输出的单个 value。


2. How does a capsule work ???
我们首先来对比一下,这个 胶囊网络 和 传统神经元之间的差异:
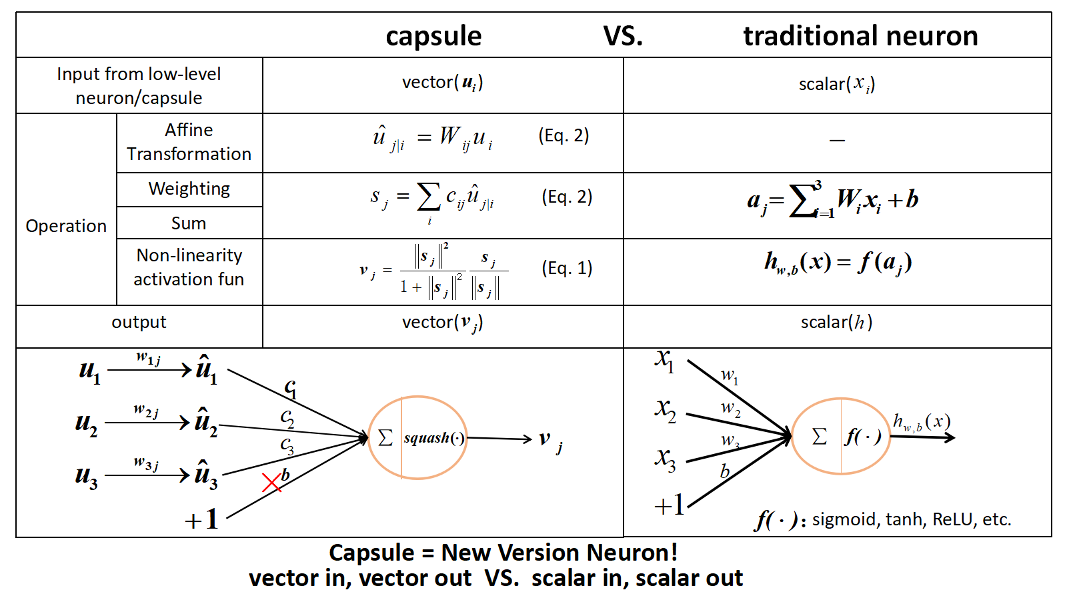
我们知道,传统的 CNN 的计算方式如下:
- scalar weighting of input scalars
- sum of weighted input scalars
- scalar-to-scalar nonlinearity
而新提出的 capsule 则大致是一样的,但是稍有不同:


我们一步步的来看这四个步骤:
1. Matrix Multiplication of Input Vectors :
具体细节这里不在赘述,请看原文 。。。

2. Scalar weighting of input vectors:
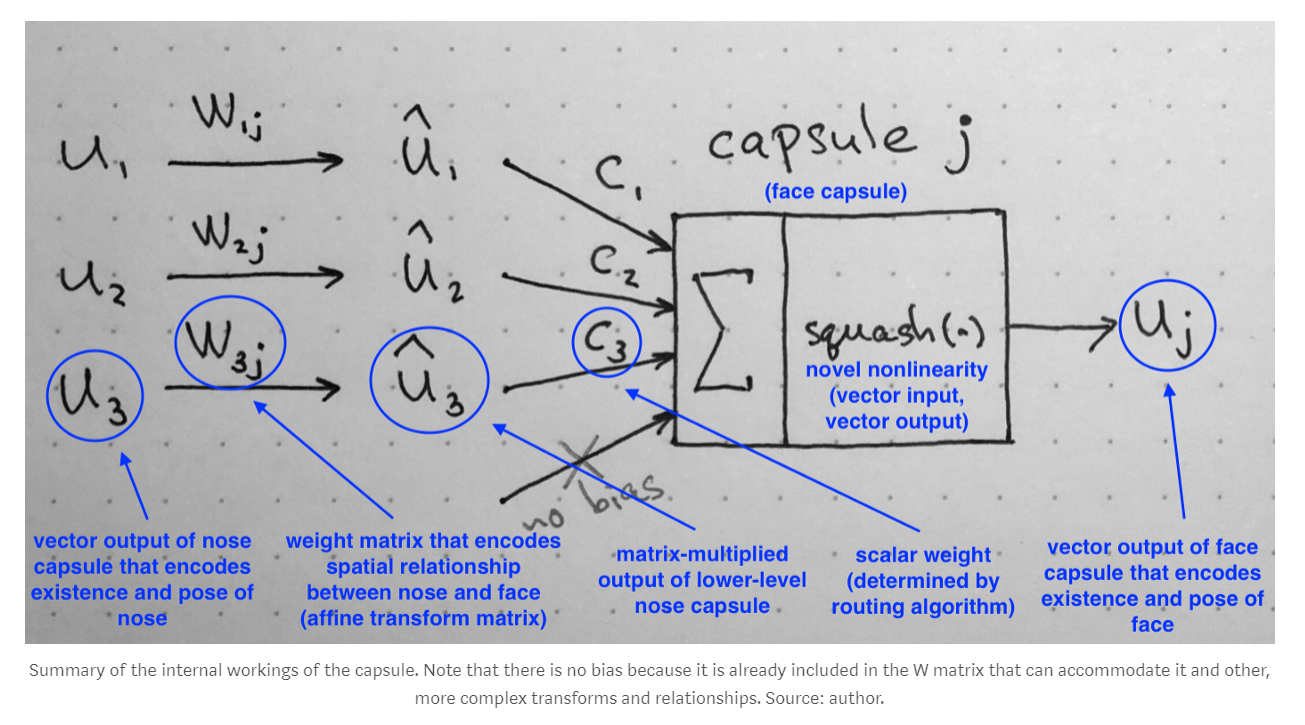
3. 加权输入向量的求和:
并无特殊之处,就是向量的求和。
4. “Squash”:Novel Vector-to-Vector Nonlinearity :
这里引入的一个函数,是 CapsNet 重要的创新之一,即:将一个向量,“Squashes” 成长度不超过 1,但是不改变其方向。

公式的右侧(蓝色框):将输入向量进行归一化,使其包含具有 单元长度;
公式的左侧(红色框): 进行了额外的 scaling。
记住:输出向量的长度,可以表示为:一个给定特征被 capsule 检测到概率。

3. Conclusion:
四、李宏毅老师的教程:
1. 直观的来看待 capsule:
Neuron 的输出是一个 value,而 Capsule 的输出是一个 vector ;
一个神经元负责检测特定的模式(specific pattern),如:Neuron A 负责检测向左的鸟嘴,Neuron B 负责检测向右的鸟嘴。而 capsule 负责检测某一个种类的 pattern,输出 V 的长度代表某一 pattern 是否存在,再用其中的某一些细节来表示是哪一种类的 pattern。如:是否有鸟嘴,以及 该鸟嘴是向左的,还是向右的。

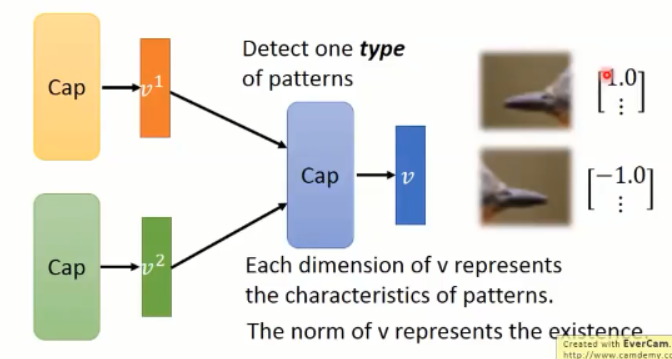
例如:该 capsule 输出的向量,长度都是 1,但是,1.0 用来表示向左的鸟嘴,-1.0 来表示向右的鸟嘴。
2. 更细节的来看待 capsule:

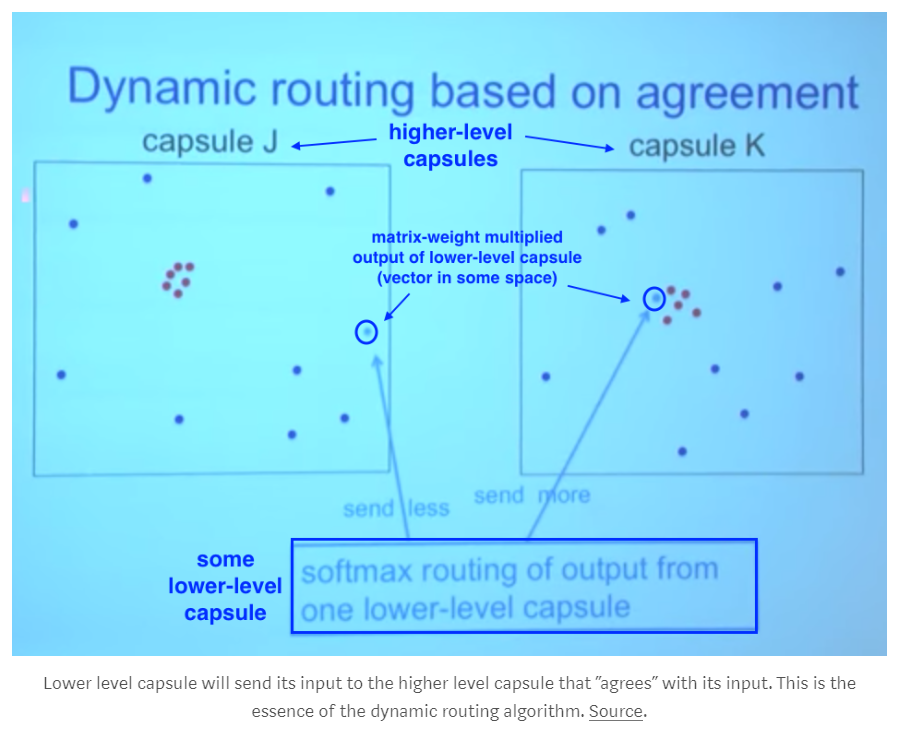
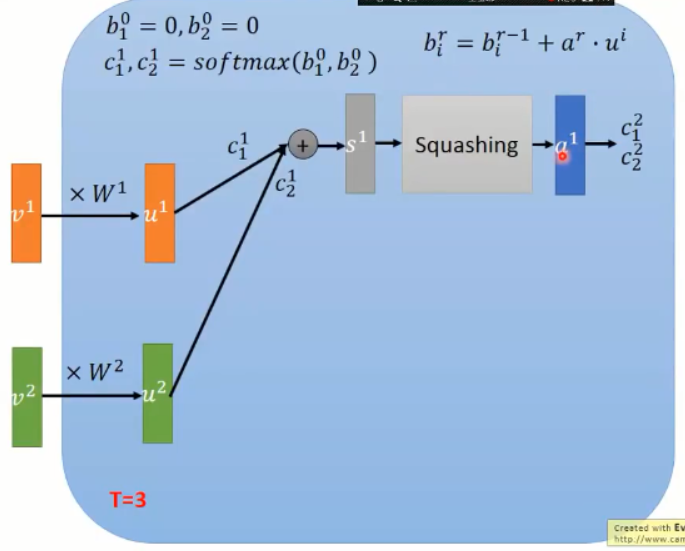
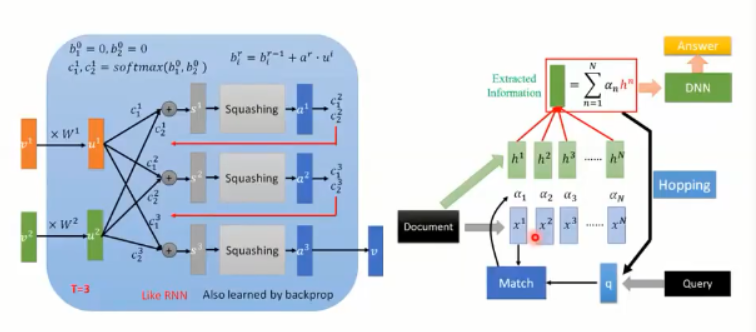
Capsule 的输入是向量 v1,v2,乘以需要利用 BP 算法来更新的权重 w1,w2,再乘以 C1,C2,相加得到 S,然后用一个 Squash 函数来将其进行缩放,当S的长度很长的时候,V 中第一项趋近于1,当S的长度很短的时候,V 中第一项趋近于0。需要注意的是:C1 和 C2 不是用 BP 算法求出来的,而是 testing的时候,动态决定的,这两个系数称为:coupling coefficients,这个决定C1,C2取值的过程,称为:dynamic routing。这里,类似于 pooling 操作,动态决定选择哪一个 Neuron 进行选择,这里也是 online 决定这个参数的。
3. 目标转向 Dynamic Routing:
我们假设有 三个输入,u1, u2, u3:
初始化三组动态的 coupling coefficients,b1, b2, b3 = 0;
然后定义,我们这里确定要跑几个 epoch,假设为 T次;
然后,将 b1, b2, b3 输入到 softmax 函数,这三个 value 的和 为 1,得到 c1, c2, c3;
然后将这三个 value 和输入向量,进行点乘,得到 S,
将 S 进行 squash,得到输出向量 a;
再用 a 更新 b;

迭代结束之后,我们得到这三个 value,分别乘以输入向量即可。
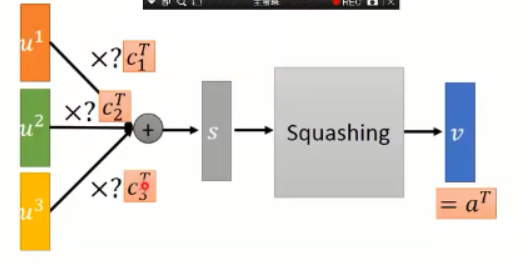
用图示的方法来表达这个过程:
有了得到的 a1, 我们可以用于更新 c1, c2;当 a1 和 哪一个 vector 比较像,就会使得对应的权重,得到增加;
然后,更新后的 c1, c2 再次和 u1, u2 进行相乘,得到新的 s2,然后再得到 a2,再更新 c1, c2;
依次迭代;
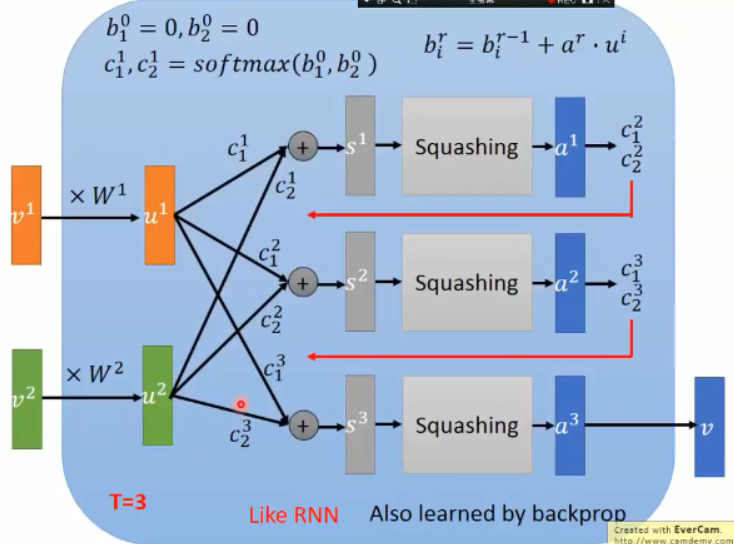
这个东西和 RNN 非常的类似,也是利用 BP 进行训练。
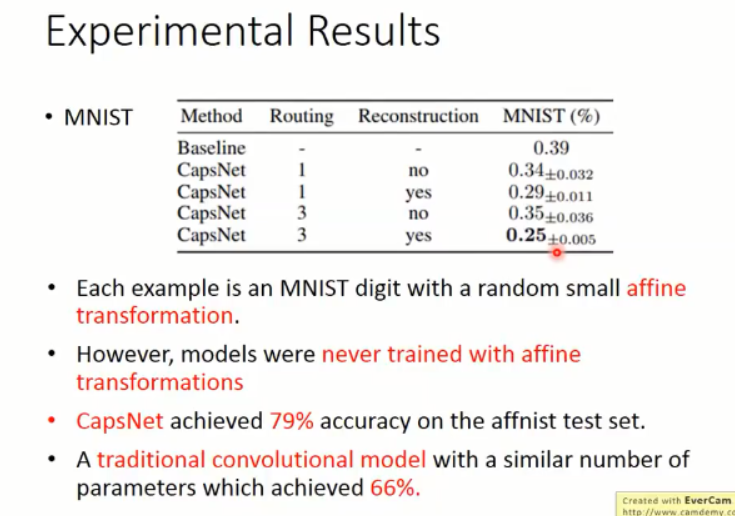
那么,在 mnist 手写体识别数据集上,我们利用,
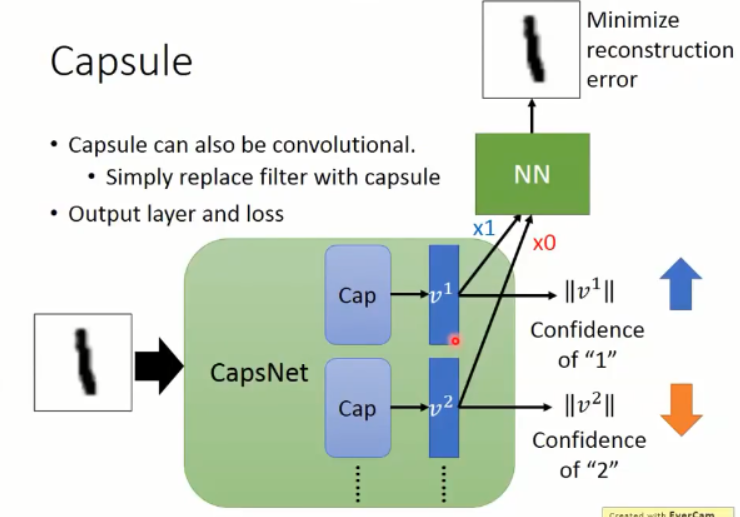
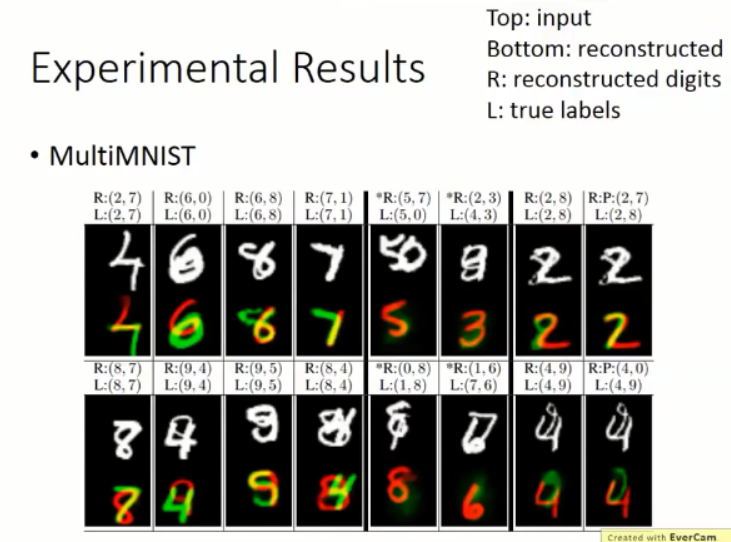
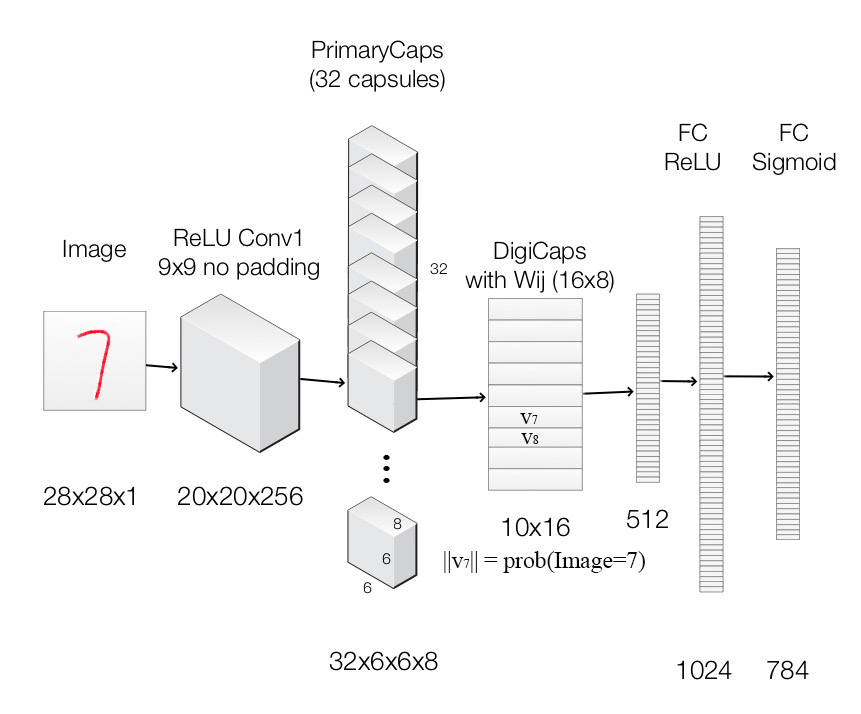
capsule 可以替换掉 filter,以 mnist 手写体识别为例,我们可以用一个 capsule 来表示一类数字,那么,10个数字,就需要10个 capsule 来表达,假设输入的图像是 1,那么,对应 1 的 vector 置信度就要尽可能的高。作者在 paper 中也引入了 reconstruction loss,用这两个损失函数来学习 feature 以及 后续的分类。

讨论:
Invariance v.s. Equivariance
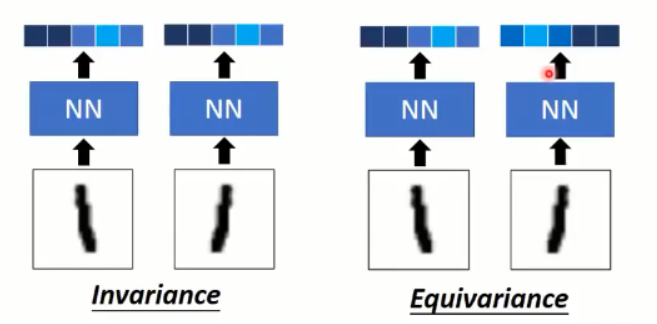
CNN 的 max-pooling 只能做到 invariance,而 capsule 可以做到 invariance 以及 Equivariance。
CapsNet architecture:
我们利用 capsule 结构来构建一个CapsNet 来分类 MNist 数据集。

深度学习课程笔记(十一)初探 Capsule Network的更多相关文章
- 深度学习课程笔记(十二) Matrix Capsule
深度学习课程笔记(十二) Matrix Capsule with EM Routing 2018-02-02 21:21:09 Paper: https://openreview.net/pdf ...
- 深度学习课程笔记(十六)Recursive Neural Network
深度学习课程笔记(十六)Recursive Neural Network 2018-08-07 22:47:14 This video tutorial is adopted from: Youtu ...
- 深度学习课程笔记(十五)Recurrent Neural Network
深度学习课程笔记(十五)Recurrent Neural Network 2018-08-07 18:55:12 This video tutorial can be found from: Yout ...
- 深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE
深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE 201 ...
- 深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning)
深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning) 2018-08-09 12:21:33 The video tutorial can ...
- 深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO)
深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO) 2018-07-17 16:54:51 Reference: https://b ...
- 深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods)
深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods) 2018-07-17 16:50:12 Reference:https://www.you ...
- 深度学习课程笔记(十)Q-learning (Continuous Action)
深度学习课程笔记(十)Q-learning (Continuous Action) 2018-07-10 22:40:28 reference:https://www.youtube.com/watc ...
- 深度学习课程笔记(九)VAE 相关推导和应用
深度学习课程笔记(九)VAE 相关推导和应用 2018-07-10 22:18:03 Reference: 1. TensorFlow code: https://jmetzen.github.io/ ...
随机推荐
- Sitecore CMS中创建模板
如何在Sitecore CMS中创建模板. 在/sitecore/templates选择应创建模板的文件夹中. 注意:在多站点项目中,通常会在模板所属的网站名称的/sitecore/templates ...
- PYQT5学习笔记之各模块介绍
Qtwidgets模块包含创造经典桌面风格的用户界面提供了一套UI元素的类 Qtwidegts下还有以下常用对象,所以一般使用Qtwidegts时会使用面向对象式编程 QApplication: ap ...
- restful的特点
1. 资源(Resources) REST的名称”表现层状态转化”中,省略了主语.”表现层”其实指的是”资源”(Resources)的”表现层”. 所谓”资源”,就是网络 ...
- Linux基础命令---显示路由表route
route route指令用于显示或者修改IP路由表.它的主要用途是在使用ifconfig(8)程序配置接口后,通过接口设置到特定主机或网络的静态路由.当使用add或del选项时,路由将修改路由表.如 ...
- [转载]Cookie与Session的区别与联系及生命周期
前几天面试问了一个问题,当时记不太清了,上网查了下发现这个问题还真的很有讲究而且很重要,自己总结下做下记录. 一.Session与Cookie介绍 这些都是基础知识,不过有必要做深入了解.先简单介绍一 ...
- echarts遇到的问题
X轴无偏移: axisTick: { alignWithLabel: true }, x轴显示所有数据项且避免拥挤在xAxis设置: axisLabel: { interval: 0, rotate: ...
- Com类型
/* VARIANT STRUCTURE * * VARTYPE vt; * WORD wReserved1; * WORD wReserved2; * WORD wReserved3; * unio ...
- log4j2笔记 #03# PatternLayout
该类的目标是格式化LogEvent并返回(字符串)结果.结果的格式取决于具体的模式字符串(pattern string).这里的模式字符串与c语言中printf函数的转换模式非常相似.模式字符串由“转 ...
- Linux学习笔记之Linux运行脚本时 $'\r' 错误
1.Windows上操作 用notepad++编译器打开脚本,编辑->文档格式转换->转换为UNIX格式,然后保存. 重新上传.运行,问题解决 2.Linux上操作 用vi/vim命令打开 ...
- mysql常用的操作命令
在mysql中以半角分号;作为命令的结束符 查看当前系统包含的数据库:mysql> show databases [like ' ']; 从一个数据库切换到另一个:mysql>use ol ...