潭州课堂25班:Ph201805201 爬虫高级 第六课 sclapy 框架 中间建 与selenium对接 (课堂笔记)
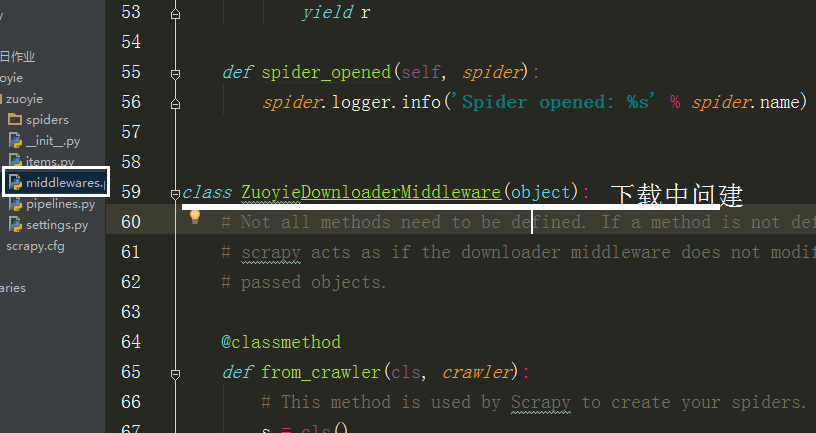


因为每次请求得到的响应不一定是正常的,

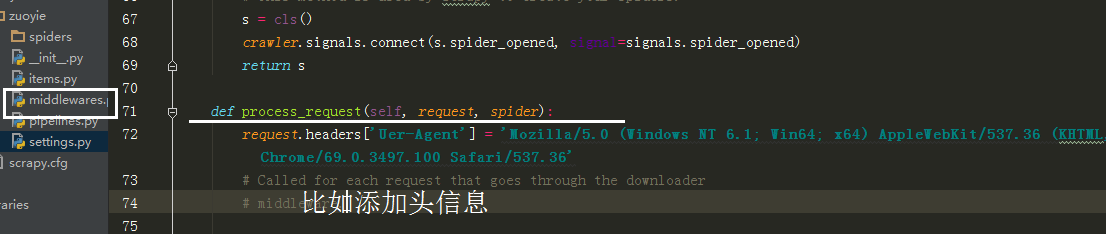
也可以在中间建中与个类的方法,自动更换头自信,代理Ip,
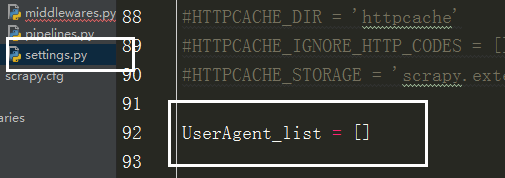
在设置文件中添加头信息列表,
在中间建中导入刚刚的列表,和随机函数
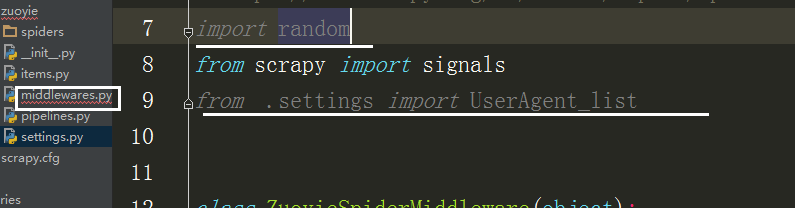
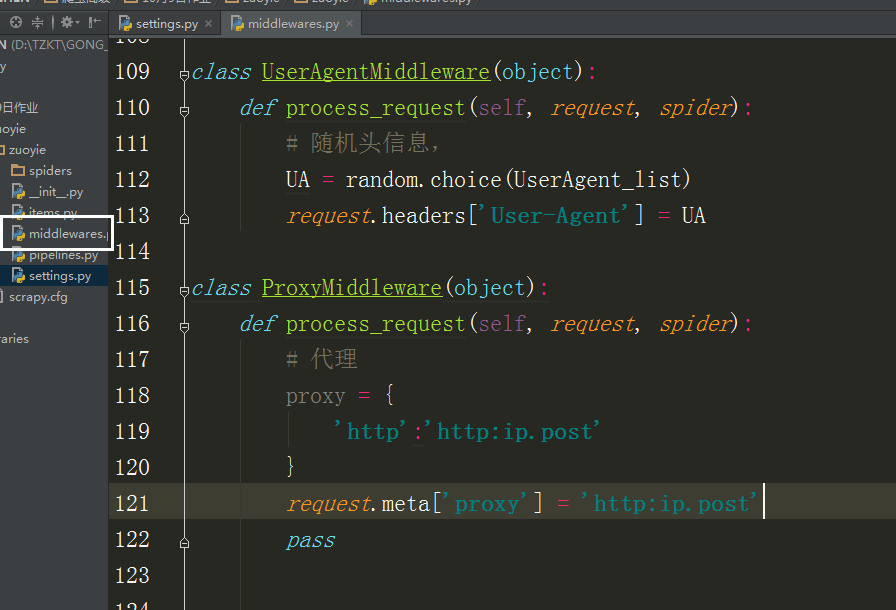
class UserAgentMiddleware(object):
def process_request(self, request, spider):
# 随机头信息,
UA = random.choice(UserAgent_list)
request.headers['User-Agent'] = UA class ProxyMiddleware(object):
def process_request(self, request, spider):
# 代理
proxy = {
'http':'http:ip.post'
}
request.meta['proxy'] = 'http:ip.post'
pass
scrapy与 selenium
以 历史空气质量数据 网站为列:
https://www.aqistudy.cn
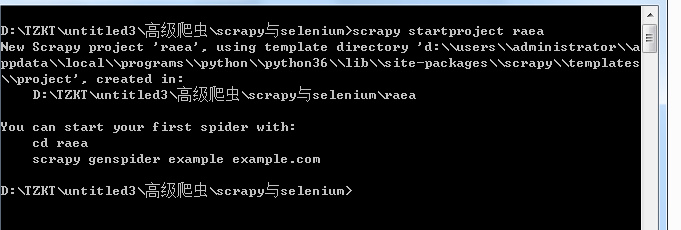
建一项目 scrapy startproject raea
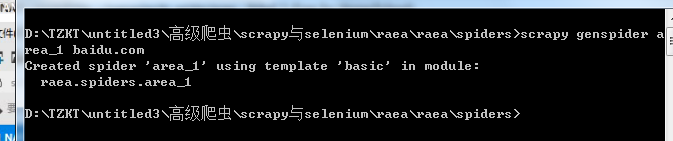
创建运行文件 scrapy genspider area_1 baidu.com

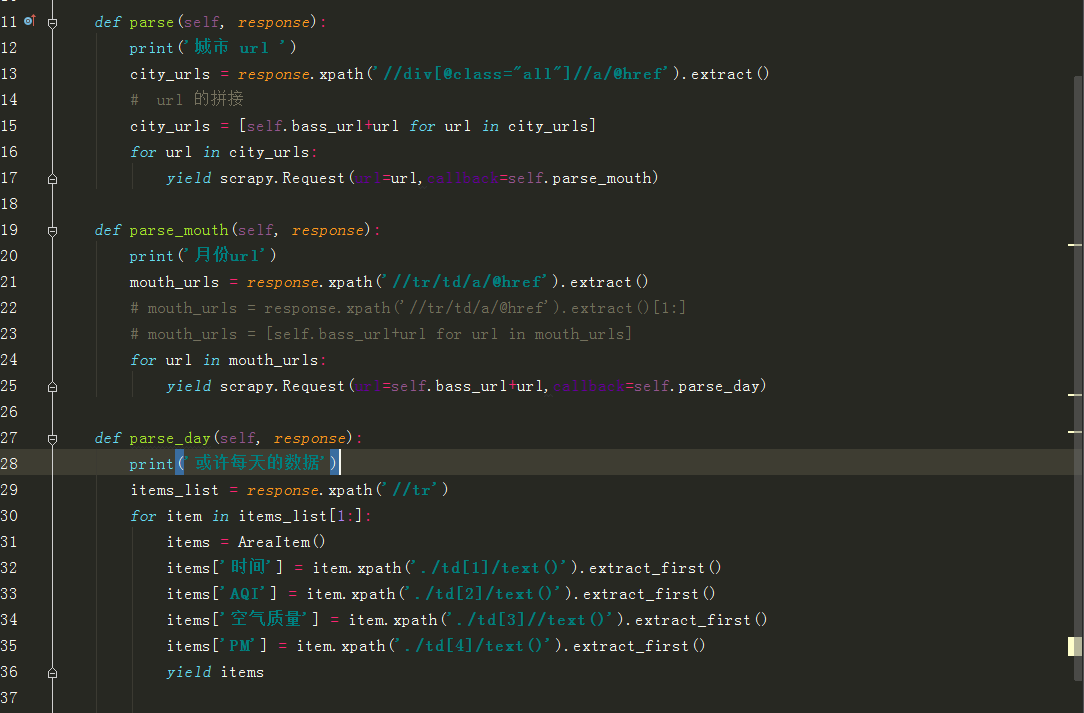
写好后无法获取数据,是因为 scrapy 无法执行 js 获取数据 ,
所以要在中间建 中自己写个类,
在 middlewares 中导入selenium

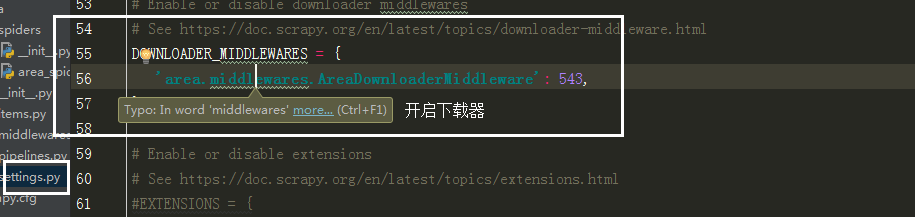
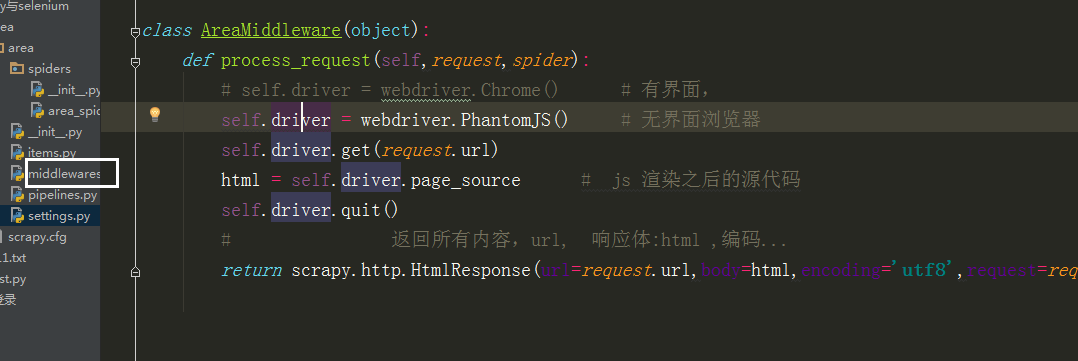
里边的类名改成自己写的那个类方法

潭州课堂25班:Ph201805201 爬虫高级 第六课 sclapy 框架 中间建 与selenium对接 (课堂笔记)的更多相关文章
- 潭州课堂25班:Ph201805201 爬虫高级 第七课 sclapy 框架 爬前程网 (课堂笔)
定时对该网页数据采集,所以每次只爬第一个页面就可以, 创建工程 scrapy startproject qianchen 创建运行文件 cd qianchenscrapy genspider qian ...
- 潭州课堂25班:Ph201805201 爬虫高级 第五课 sclapy 框架 日志和 settings 配置 模拟登录(课堂笔记)
当要对一个页面进行多次请求时, 设 dont_filter = True 忽略去重 在 scrapy 框架中模拟登录 创建项目 创建运行文件 设请求头 # -*- coding: utf-8 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第四课 sclapy 框架 crawispider类 (课堂笔记)
以上内容以 spider 类 获取 start_urls 里面的网页 在这里平时只写一个,是个入口,之后 通过 xpath 生成 url,继续请求, crawispider 中 多了个 rules ...
- 潭州课堂25班:Ph201805201 爬虫高级 第三课 sclapy 框架 腾讯 招聘案例 (课堂笔记)
到指定目录下,创建个项目 进到 spiders 目录 创建执行文件,并命名 运行调试 执行代码,: # -*- coding: utf-8 -*- import scrapy from ..items ...
- 潭州课堂25班:Ph201805201 爬虫高级 第八课 AP抓包 SCRAPY 的图片处理 (课堂笔记)
装好模拟器设置代理到 Fiddler 中, 代理 IP 是本机 IP, 端口是 8888, 抓包 APP斗鱼 用 format 设置翻页
- 潭州课堂25班:Ph201805201 爬虫高级 第十三 课 代理池爬虫检测部分 (课堂笔记)
1,通过爬虫获取代理 ip ,要从多个网站获取,每个网站的前几页2,获取到代理后,开进程,一个继续解析,一个检测代理是否有用 ,引入队列数据共享3,Queue 中存放的是所有的代理,我们要分离出可用的 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第十一课 Scrapy-redis分布 项目实战 (课堂笔
- 潭州课堂25班:Ph201805201 爬虫高级 第十课 Scrapy-redis分布 (课堂笔记)
利用 redis 数据库,做 request 队列,去重,多台数据共享, scrapy 调度 基于文件每户,默认只能在单机运行, scrapy-redis 默认把数据放到 redis 中,实现数据共享 ...
- 潭州课堂25班:Ph201805201 爬虫基础 第六课 选择器 (课堂笔记)
HTML解析库BeautifulSoup4 BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库,它的使用方式相对于正则来说更加的简单方便,常常能够节省我们大量的时间 ...
随机推荐
- UART中的硬件流控RTS与CTS DTR DSR DTE设备和DCE设备【转】
中低端路由器上使用disp interface 查看相应串口状态信息,其中DCD.DTR.DSR.RTS及CTS等五个状态指示分别代表什么意思? DCD ( Data Carrier Detect 数 ...
- ES系列十二、ES的scroll Api及分页实例
1.官方api 1.Scroll概念 Version:6.1 英文原文地址:Scroll 当一个搜索请求返回单页结果时,可以使用 scroll API 检索体积大量(甚至全部)结果,这和在传统数据库中 ...
- oracle flashback 后主键及索引更改问题
oracle flashback 后 主键会变为bin开头,如果删除可以采用将sql复制出单独窗口,然后加上“”执行
- nodejs服务器读取图片返回给前端(浏览器)显示
1 前言 项目需要用nodejs服务器给前端传递图片,网上找了好多资料,多数都是怎么在前端上传图片的,然后通过看runoob.com菜鸟教程,发现其实是非常简单,用express框架就行了. 2 代码 ...
- 【mysql】MySQLdb返回字典方法
来源:http://blog.csdn.net/zgl_dm/article/details/8710371 默认mysqldb返回的是元组,这样对使用者不太友好,也不利于维护下面是解决方法 impo ...
- system
system("cls"); //清屏 system("color f2") //改变控制台颜色 f2为颜色样式,可以是e2.f3等等 Original:htt ...
- poj3666 线性dp
要把一个序列变成一个不严格的单调序列,求最小费用 /* 首先可以证明最优解序列中的所有值都能在原序列中找到 以不严格单增序列为例, a序列为原序列,b序列为升序排序后的序列 dp[i][j]表示处理到 ...
- HTTP协议特点
1 HTTP协议特点 1)客户端->服务端(请求request)有三部份 a)请求行--请求行用于描述客户端的请求方式.请求的资源名称,以及使用的HTTP协议版本号 请 ...
- CSS - !important声明强制优先
!important声明强制优先 CSS优先级中还有一个最无敌的声明,就是!important. 在CSS样式表中,带有!important声明的样式优先使用,它的优先级会超越任何地方.任何方式的样式 ...
- nodejs模块——网络编程模块
net模块提供了一个异步网络包装器,用于TCP网络编程,它包含了创建服务器和客户端的方法.dgram模块用于UDP网络编程. 参考链接:https://nodejs.org/api/net.html, ...