Mongodb主从复制 及 副本集+分片集群梳理
转载努力哥原文,原文连接https://www.cnblogs.com/nulige/p/7613721.html
介绍了Mongodb的安装使用,在 MongoDB 中,有两种数据冗余方式,一种 是 Master-Slave 模式(主从复制),一种是 Replica Sets 模式(副本集)。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
Mongodb一共有三种集群搭建的方式:Replica Set(副本集)、Sharding(切片)Master-Slaver(主从)【目前已不推荐使用了!!!】其中,Sharding集群也是三种集群中最复杂的。副本集比起主从可以实现故障转移!!非常使用!mongoDB目前已不推荐使用主从模式,取而代之的是副本集模式。副本集其实一种互为主从的关系,可理解为主主。副本集指将数据复制,多份保存,不同服务器保存同一份数据,在出现故障时自动切换。对应的是数据冗余、备份、镜像、读写分离、高可用性等关键词;而分片则指为处理大量数据,将数据分开存储,不同服务器保存不同的数据,它们的数据总和即为整个数据集。追求的是高性能。在生产环境中,通常是这两种技术结合使用,分片+副本集。 |
一、先说说mongodb主从复制配置
主从复制是MongoDB最常用的复制方式,也是一个简单的数据库同步备份的集群技术,这种方式很灵活.可用于备份,故障恢复,读扩展等.
最基本的设置方式就是建立一个主节点和一个或多个从节点,每个从节点要知道主节点的地址。采用双机备份后主节点挂掉了后从节点可以接替主机继续服务。所以这种模式比单节点的高可用性要好很多。
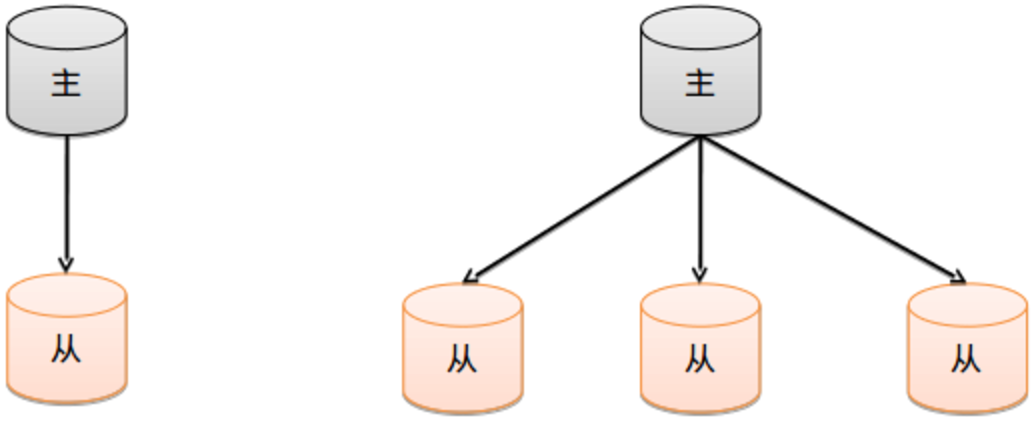
配置主从复制的注意点
|
1
2
3
|
1)在数据库集群中要明确的知道谁是主服务器,主服务器只有一台.2)从服务器要知道自己的数据源也就是对应的主服务是谁.3)--master用来确定主服务器,--slave 和 --source 来控制从服务器 |
可以在mongodb.conf配置文件里指明主从关系,这样启动mongodb的时候只要跟上配置文件就行,就不需要通过--master和--slave来指明主从了。
下面简单记录下Mongodb主从复制的部署过程

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
|
1)机器环境182.48.115.238 master-node182.48.115.236 slave-node两台机器都关闭防火墙和selinuxmongodb的安装参考:http://www.cnblogs.com/kevingrace/p/5752382.html2)主从配置.............master-node节点配置.............[root@master-node ~]# vim /usr/local/mongodb/mongodb.confport=27017bind_ip = 182.48.115.238dbpath=/usr/local/mongodb/datalogpath=/usr/local/mongodb/log/mongo.loglogappend=truejournal = truefork = truemaster = true //确定自己是主服务器[root@master-node ~]# nohup /usr/local/mongodb/bin/mongod --config /usr/local/mongodb/mongodb.conf &[root@master-node ~]# ps -ef|grep mongodbroot 15707 15514 23 16:45 pts/2 00:00:00 /usr/local/mongodb/bin/mongod --config /usr/local/mongodb/mongodb.confroot 15736 15514 0 16:45 pts/2 00:00:00 grep mongodb[root@master-node ~]# lsof -i:27017COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAMEmongod 15707 root 7u IPv4 153114 0t0 TCP 182.48.115.238:27017 (LISTEN)由于mongodb.conf里绑定了本机的ip地址182.48.115.238,所以连接mongodb的时候必须用这个ip地址,不能使用默认的127.0.0.1,也就是说:[root@master-node ~]# mongo 182.48.115.238:27017 //这样才能连接mongodb[root@master-node ~]# mongo 或者 mongodb 127.0.0.1:27017 // 这样不能连接mongodb.............slave-node节点配置.............[root@slave-node ~]# vim /usr/local/mongodb/mongodb.confport=27017dbpath=/usr/local/mongodb/datalogpath=/usr/local/mongodb/log/mongo.loglogappend=truejournal = truefork = truebind_ip = 182.48.115.236 //确定主数据库端口source = 182.48.115.238:27017 //确定主数据库端口slave = true //确定自己是从服务器[root@slave-node ~]# nohup /usr/local/mongodb/bin/mongod --config /usr/local/mongodb/mongodb.conf &[root@slave-node ~]# ps -ef|grep mongoroot 26290 26126 8 16:47 pts/0 00:00:00 /usr/local/mongodb/bin/mongod --config /usr/local/mongodb/mongodb.confroot 26316 26126 0 16:47 pts/0 00:00:00 grep mongo[root@slave-node ~]# lsof -i:27017COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAMEmongod 26290 root 7u IPv4 663904 0t0 TCP slave-node1:27017 (LISTEN)mongod 26290 root 25u IPv4 663917 0t0 TCP slave-node1:51060->slave-node2:27017 (ESTABLISHED)在slave-node测试连接master-node的mongodb数据库是否正常[root@slave-node ~]# mongo 182.48.115.236:27017MongoDB shell version v3.4.4connecting to: 182.48.115.236:27017MongoDB server version: 3.4.4Server has startup warnings:2017-06-03T16:47:31.200+0800 I STORAGE [initandlisten]2017-06-03T16:47:31.200+0800 I STORAGE [initandlisten] ** WARNING: Using the XFS filesystem is strongly recommended with the WiredTiger storage engine2017-06-03T16:47:31.200+0800 I STORAGE [initandlisten] ** See http://dochub.mongodb.org/core/prodnotes-filesystem2017-06-03T16:47:32.472+0800 I CONTROL [initandlisten]2017-06-03T16:47:32.472+0800 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database.2017-06-03T16:47:32.472+0800 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted.2017-06-03T16:47:32.472+0800 I CONTROL [initandlisten] ** WARNING: You are running this process as the root user, which is not recommended.2017-06-03T16:47:32.472+0800 I CONTROL [initandlisten]2017-06-03T16:47:32.473+0800 I CONTROL [initandlisten]2017-06-03T16:47:32.473+0800 I CONTROL [initandlisten] ** WARNING: /sys/kernel/mm/transparent_hugepage/enabled is 'always'.2017-06-03T16:47:32.473+0800 I CONTROL [initandlisten] ** We suggest setting it to 'never'2017-06-03T16:47:32.473+0800 I CONTROL [initandlisten]2017-06-03T16:47:32.473+0800 I CONTROL [initandlisten] ** WARNING: /sys/kernel/mm/transparent_hugepage/defrag is 'always'.2017-06-03T16:47:32.473+0800 I CONTROL [initandlisten] ** We suggest setting it to 'never'2017-06-03T16:47:32.473+0800 I CONTROL [initandlisten]>3)主从数据同步测试在master-node节点数据库里创建master_slave库,并插入20条数据[root@master-node ~]# mongo 182.48.115.238:27017MongoDB shell version v3.4.4connecting to: 182.48.115.238:27017MongoDB server version: 3.4.4Server has startup warnings:2017-06-03T16:45:07.406+0800 I STORAGE [initandlisten]2017-06-03T16:45:07.407+0800 I STORAGE [initandlisten] ** WARNING: Using the XFS filesystem is strongly recommended with the WiredTiger storage engine2017-06-03T16:45:07.407+0800 I STORAGE [initandlisten] ** See http://dochub.mongodb.org/core/prodnotes-filesystem2017-06-03T16:45:08.373+0800 I CONTROL [initandlisten]2017-06-03T16:45:08.373+0800 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database.2017-06-03T16:45:08.373+0800 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted.2017-06-03T16:45:08.373+0800 I CONTROL [initandlisten] ** WARNING: You are running this process as the root user, which is not recommended.2017-06-03T16:45:08.373+0800 I CONTROL [initandlisten]2017-06-03T16:45:08.374+0800 I CONTROL [initandlisten]2017-06-03T16:45:08.374+0800 I CONTROL [initandlisten] ** WARNING: /sys/kernel/mm/transparent_hugepage/enabled is 'always'.2017-06-03T16:45:08.374+0800 I CONTROL [initandlisten] ** We suggest setting it to 'never'2017-06-03T16:45:08.374+0800 I CONTROL [initandlisten]2017-06-03T16:45:08.374+0800 I CONTROL [initandlisten] ** WARNING: /sys/kernel/mm/transparent_hugepage/defrag is 'always'.2017-06-03T16:45:08.374+0800 I CONTROL [initandlisten] ** We suggest setting it to 'never'2017-06-03T16:45:08.374+0800 I CONTROL [initandlisten]> use master_slaveswitched to db master_slave> function add(){var i = 0;for(;i<20;i++){db.persons.insert({"name":"wang"+i})}}> add()> db.persons.find(){ "_id" : ObjectId("593278699a9e2e9f37ac4dbb"), "name" : "wang0" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dbc"), "name" : "wang1" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dbd"), "name" : "wang2" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dbe"), "name" : "wang3" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dbf"), "name" : "wang4" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc0"), "name" : "wang5" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc1"), "name" : "wang6" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc2"), "name" : "wang7" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc3"), "name" : "wang8" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc4"), "name" : "wang9" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc5"), "name" : "wang10" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc6"), "name" : "wang11" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc7"), "name" : "wang12" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc8"), "name" : "wang13" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc9"), "name" : "wang14" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dca"), "name" : "wang15" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dcb"), "name" : "wang16" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dcc"), "name" : "wang17" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dcd"), "name" : "wang18" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dce"), "name" : "wang19" }Type "it" for more然后在slave-node节点数据库里查看,是否将master-node写入的新数据同步过来了[root@slave-node log]# mongo 182.48.115.236:27017MongoDB shell version v3.4.4connecting to: 182.48.115.236:27017MongoDB server version: 3.4.4Server has startup warnings:2017-06-03T16:56:28.928+0800 I STORAGE [initandlisten]2017-06-03T16:56:28.928+0800 I STORAGE [initandlisten] ** WARNING: Using the XFS filesystem is strongly recommended with the WiredTiger storage engine2017-06-03T16:56:28.928+0800 I STORAGE [initandlisten] ** See http://dochub.mongodb.org/core/prodnotes-filesystem2017-06-03T16:56:29.883+0800 I CONTROL [initandlisten]2017-06-03T16:56:29.883+0800 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database.2017-06-03T16:56:29.883+0800 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted.2017-06-03T16:56:29.883+0800 I CONTROL [initandlisten] ** WARNING: You are running this process as the root user, which is not recommended.2017-06-03T16:56:29.883+0800 I CONTROL [initandlisten]2017-06-03T16:56:29.884+0800 I CONTROL [initandlisten]2017-06-03T16:56:29.884+0800 I CONTROL [initandlisten] ** WARNING: /sys/kernel/mm/transparent_hugepage/enabled is 'always'.2017-06-03T16:56:29.884+0800 I CONTROL [initandlisten] ** We suggest setting it to 'never'2017-06-03T16:56:29.884+0800 I CONTROL [initandlisten]2017-06-03T16:56:29.884+0800 I CONTROL [initandlisten] ** WARNING: /sys/kernel/mm/transparent_hugepage/defrag is 'always'.2017-06-03T16:56:29.884+0800 I CONTROL [initandlisten] ** We suggest setting it to 'never'2017-06-03T16:56:29.884+0800 I CONTROL [initandlisten]> show dbs2017-06-03T17:10:32.136+0800 E QUERY [thread1] Error: listDatabases failed:{ "ok" : 0, "errmsg" : "not master and slaveOk=false", "code" : 13435, "codeName" : "NotMasterNoSlaveOk"} :_getErrorWithCode@src/mongo/shell/utils.js:25:13Mongo.prototype.getDBs@src/mongo/shell/mongo.js:62:1shellHelper.show@src/mongo/shell/utils.js:769:19shellHelper@src/mongo/shell/utils.js:659:15@(shellhelp2):1:1> rs.slaveOk();> show dbsadmin 0.000GBlocal 0.000GBmaster_slave 0.000GBwangshibo 0.000GB> use master_slaveswitched to db master_slave> db.persons.find(){ "_id" : ObjectId("593278699a9e2e9f37ac4dbb"), "name" : "wang0" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dbc"), "name" : "wang1" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dbd"), "name" : "wang2" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dbe"), "name" : "wang3" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dbf"), "name" : "wang4" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc0"), "name" : "wang5" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc1"), "name" : "wang6" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc2"), "name" : "wang7" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc3"), "name" : "wang8" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc4"), "name" : "wang9" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc5"), "name" : "wang10" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc6"), "name" : "wang11" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc7"), "name" : "wang12" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc8"), "name" : "wang13" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dc9"), "name" : "wang14" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dca"), "name" : "wang15" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dcb"), "name" : "wang16" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dcc"), "name" : "wang17" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dcd"), "name" : "wang18" }{ "_id" : ObjectId("593278699a9e2e9f37ac4dce"), "name" : "wang19" }Type "it" for more........................................................................................如果在slave-node节点上的数据库中查看,有报错:"errmsg" : "not master and slaveOk=false"!!!首先这是正常的,因为SECONDARY是不允许读写的, 在写多读少的应用中,使用Replica Sets来实现读写分离。通过在连接时指定或者在主库指定slaveOk,由Secondary来分担读的压力,Primary只承担写操作。对于replica set 中的secondary 节点默认是不可读的。解决办法:在slave-node节点数据库中执行"rs.slaveOk();"命令即可........................................................................................在slave-node节点数据库中发现已经同步过来了master_slave库的20条数据,说明mongodb的主从复制环境已经成功了!当配置完主从服务器后,一但主服务器上的数据发生变化,从服务器也会发生变化 |
主从复制的原理
|
1
2
3
4
5
6
7
8
9
|
在主从结构中,主节点的操作记录成为oplog(operation log)。oplog存储在一个系统数据库local的集合oplog.$main中,这个集合的每个文档都代表主节点上执行的一个操作。从服务器会定期从主服务器中获取oplog记录,然后在本机上执行!对于存储oplog的集合,MongoDB采用的是固定集合,也就是说随着操作过多,新的操作会覆盖旧的操作!主从复制的其他设置项--only 从节点指定复制某个数据库,默认是复制全部数据库--slavedelay 从节点设置主数据库同步数据的延迟(单位是秒)--fastsync 从节点以主数据库的节点快照为节点启动从数据库--autoresync 从节点如果不同步则从新同步数据库(即选择当通过热添加了一台从服务器之后,从服务器选择是否更新主服务器之间的数据)--oplogSize 主节点设置oplog的大小(主节点操作记录存储到local的oplog中) |
在上面slave-node从节点的local数据库中,存在一个集合sources。这个集合就保存了这个服务器的主服务器是谁
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
[root@slave-node mongodb]# mongo 182.48.115.236:27017......> show dbsadmin 0.000GBlocal 0.000GBmaster_slave 0.000GBwangshibo 0.000GB> use localswitched to db local> show collectionsmesourcesstartup_log> db.sources.find(){ "_id" : ObjectId("593277a5105051e5648605a3"), "host" : "182.48.115.238:27017", "source" : "main", "syncedTo" : Timestamp(1496481652, 1) }> |
二、Mongodb副本集(Replica Sets) (可以参考:搭建高可用mongodb集群)
mongodb 不推荐主从复制,推荐建立副本集(Replica Set)来保证1个服务挂了,可以有其他服务顶上,程序正常运行,几个服务的数据都是一样的,后台自动同步。主从复制其实就是一个单副本的应用,没有很好的扩展性饿容错性。然而副本集具有多个副本保证了容错性,就算一个副本挂掉了还有很多个副本存在,并且解决了"主节点挂掉后,整个集群内会自动切换"的问题。副本集比传统的Master-Slave主从复制有改进的地方就是它可以进行故障的自动转移,如果我们停掉复制集中的一个成员,那么剩余成员会再自动选举一个成员,作为主库。
Replica Set 使用的是 n 个 mongod 节点,构建具备自动的容错功能(auto-failover),自动恢复的(auto-recovery)的高可用方案。使用 Replica Set 来实现读写分离。通过在连接时指定或者在主库指定 slaveOk,由Secondary 来分担读的压力,Primary 只承担写操作。对于 Replica Set 中的 secondary 节点默认是不可读的。
1)关于副本集的概念
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
副本集是一种在多台机器同步数据的进程,副本集体提供了数据冗余,扩展了数据可用性。在多台服务器保存数据可以避免因为一台服务器导致的数据丢失。也可以从硬件故障或服务中断解脱出来,利用额外的数据副本,可以从一台机器致力于灾难恢复或者备份。在一些场景,可以使用副本集来扩展读性能,客户端有能力发送读写操作给不同的服务器。也可以在不同的数据中心获取不同的副本来扩展分布式应用的能力。mongodb副本集是一组拥有相同数据的mongodb实例,主mongodb接受所有的写操作,所有的其他实例可以接受主实例的操作以保持数据同步。主实例接受客户的写操作,副本集只能有一个主实例,因为为了维持数据一致性,只有一个实例可写,主实例的日志保存在oplog。Client Application Driver Writes Reads | | Primary |Replication|ReplicationSecondary Secondary二级节点复制主节点的oplog然后在自己的数据副本上执行操作,二级节点是主节点数据的反射,如果主节点不可用,会选举一个新的主节点。默认读操作是在主节点进行的,但是可以指定读取首选项参数来指定读操作到副本节点。可以添加一个额外的仲裁节点(不拥有被选举权),使副本集节点保持奇数,确保可以选举出票数不同的直接点。仲裁者并不需要专用的硬件设备。仲裁者节点一直会保存仲裁者身份........异步复制........副本节点同步直接点操作是异步的,然而会导致副本集无法返回最新的数据给客户端程序。........自动故障转移........如果主节点10s以上与其他节点失去通信,其他节点将会选举新的节点作为主节点。拥有大多数选票的副节点会被选举为主节点。副本集提供了一些选项给应用程序,可以做一个成员位于不同数据中心的副本集。也可以指定成员不同的优先级来控制选举。 |
2)副本集的结构及原理
MongoDB 的副本集不同于以往的主从模式。
在集群Master故障的时候,副本集可以自动投票,选举出新的Master,并引导其余的Slave服务器连接新的Master,而这个过程对于应用是透明的。可以说MongoDB的副本集
是自带故障转移功能的主从复制。
相对于传统主从模式的优势
传统的主从模式,需要手工指定集群中的 Master。如果 Master 发生故障,一般都是人工介入,指定新的 Master。 这个过程对于应用一般不是透明的,往往伴随着应用重
新修改配置文件,重启应用服务器等。而 MongoDB 副本集,集群中的任何节点都可能成为 Master 节点。一旦 Master 节点故障,则会在其余节点中选举出一个新的 Master 节点。 并引导剩余节点连接到新的 Master 节点。这个过程对于应用是透明的。
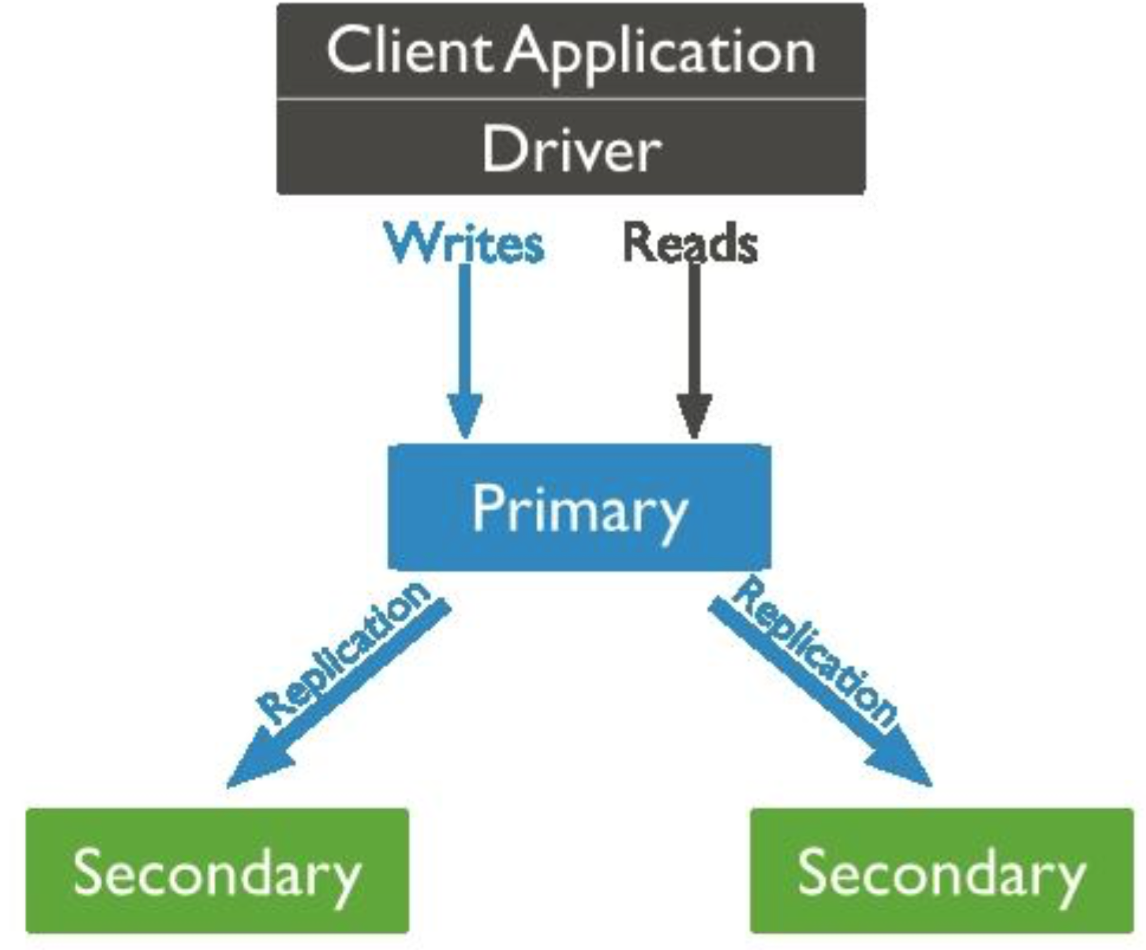
一个副本集即为服务于同一数据集的多个 MongoDB 实例,其中一个为主节点,其余的都为从节点。主节 点上能够完成读写操作,从节点仅能用于读操作。主节点需要记录所有改变数据库状态的操作,这些记录 保存在 oplog 中,这个文件存储在 local 数据库,各个从节点通过此 oplog 来复制数据并应用于本地,保持 本地的数据与主节点的一致。oplog 具有幂等性,即无论执行几次其结果一致,这个比 mysql 的二进制日 志更好用。
集群中的各节点还会通过传递心跳信息来检测各自的健康状况。当主节点故障时,多个从节点会触发一次 新的选举操作,并选举其中的一个成为新的主节点(通常谁的优先级更高,谁就是新的主节点),心跳信 息默认每 2 秒传递一次。

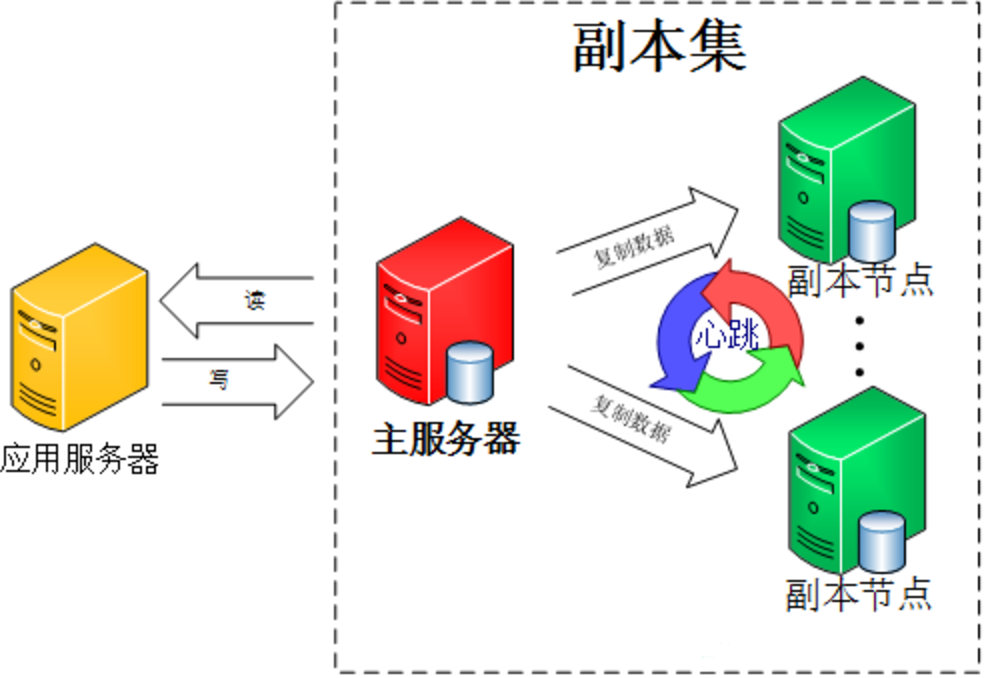
客户端连接到副本集后,不关心具体哪一台机器是否挂掉。主服务器负责整个副本集的读写,副本集定期同步数据备份。一旦主节点挂掉,副本节点就会选举一个新的主服务器。这一切对于应用服务器不需要关心。
|
1
2
3
4
5
6
7
8
9
10
|
心跳检测:整个集群需要保持一定的通信才能知道哪些节点活着哪些节点挂掉。mongodb节点会向副本集中的其他节点每两秒就会发送一次pings包,如果其他节点在10秒钟之内没有返回就标示为不能访问。每个节点内部都会维护一个状态映射表,表明当前每个节点是什么角色、日志时间戳等关键信息。如果是主节点,除了维护映射表外还需要检查自己能否和集群中内大部分节点通讯,如果不能则把自己降级为secondary只读节点。数据同步副本集同步分为初始化同步和keep复制。初始化同步指全量从主节点同步数据,如果主节点数据量比较大同步时间会比较长。而keep复制指初始化同步过后,节点之间的实时同步一般是增量同步。初始化同步不只是在第一次才会被处罚,有以下两种情况会触发:1)secondary第一次加入,这个是肯定的。2)secondary落后的数据量超过了oplog的大小,这样也会被全量复制。 |
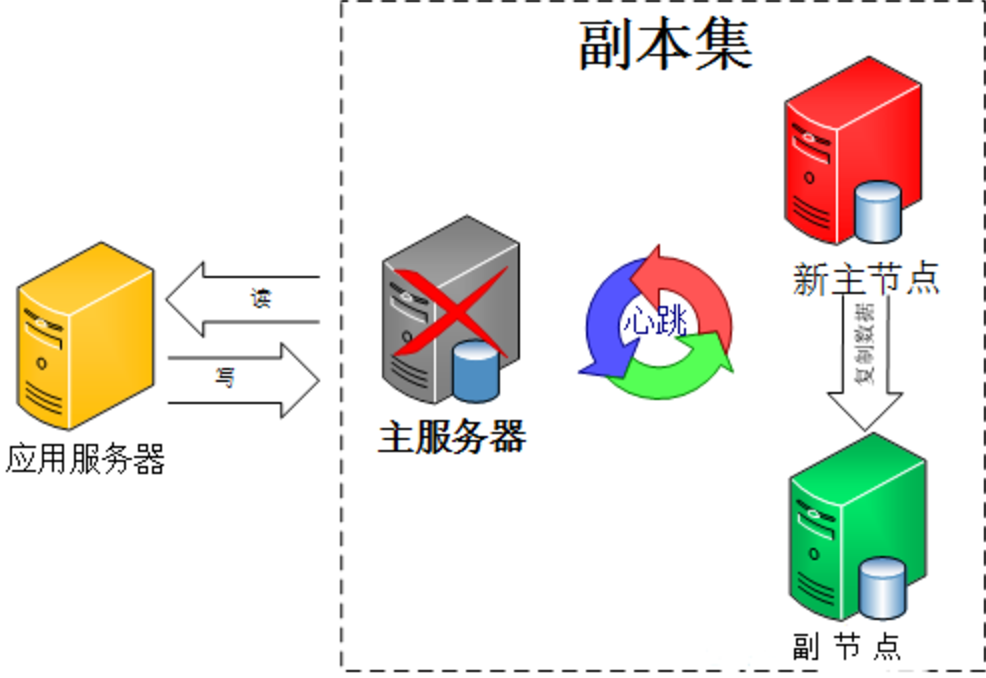
副本集中的副本节点在主节点挂掉后通过心跳机制检测到后,就会在集群内发起主节点的选举机制,自动选举出一位新的主服务器。
副本集包括三种节点:主节点、从节点、仲裁节点。
|
1
2
3
4
5
6
|
1)主节点负责处理客户端请求,读、写数据, 记录在其上所有操作的 oplog;2)从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。默认情况下,从节点不支持外部读取,但可以设置; 副本集的机制在于主节点出现故障的时候,余下的节点会选举出一个新的主节点,从而保证系统可以正常运行。3)仲裁节点不复制数据,仅参与投票。由于它没有访问的压力,比较空闲,因此不容易出故障。由于副本集出现故障的时候,存活的节点必须大于副本集节点总数的一半, 否则无法选举主节点,或者主节点会自动降级为从节点,整个副本集变为只读。因此,增加一个不容易出故障的仲裁节点,可以增加有效选票,降低整个副本集不可用的 风险。仲裁节点可多于一个。也就是说只参与投票,不接收复制的数据,也不能成为活跃节点。 |
官方推荐MongoDB副本节点最少为3台, 建议副本集成员为奇数,最多12个副本节点,最多7个节点参与选举。限制副本节点的数量,主要是因为一个集群中过多的副本节点,增加了复制的成本,反而拖累了集群
的整体性能。 太多的副本节点参与选举,也会增加选举的时间。而官方建议奇数的节点,是为了避免脑裂 的发生。
3)副本集的工作流程
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
在 MongoDB 副本集中,主节点负责处理客户端的读写请求,备份节点则负责映射主节点的 数据。备份节点的工作原理过程可以大致描述为,备份节点定期轮询主节点上的数据操作,然后对 自己的数据副本进行这些操作,从而保证跟主节点的数据同步。至于主节点上的所有 数据库状态改变 的操作,都会存放在一张特定的系统表中。备份节点则是根据这些数据进行自己的数据更新。oplog上面提到的数据库状态改变的操作,称为 oplog(operation log,主节点操作记录)。oplog 存储在 local 数据库的"oplog.rs"表中。副本集中备份节点异步的从主节点同步 oplog,然后重新 执行它记录的操作,以此达到了数据同步的作用。关于 oplog 有几个注意的地方:1)oplog 只记录改变数据库状态的操作2)存储在 oplog 中的操作并不是和主节点执行的操作完全一样,例如"$inc"操作就会转化为"$set"操作3)oplog 存储在固定集合中(capped collection),当 oplog 的数量超过 oplogSize,新的操作就会覆盖就的操作数据同步在副本集中,有两种数据同步方式:1)initial sync(初始化):这个过程发生在当副本集中创建一个新的数据库或其中某个节点刚从宕机中恢复,或者向副本集中添加新的成员的时候,默认的,副本集中的节点会从离 它最近 的节点复制 oplog 来同步数据,这个最近的节点可以是 primary 也可以是拥有最新 oplog 副本的 secondary 节点。该操作一般会重新初始化备份节点,开销较大。2)replication(复制):在初始化后这个操作会一直持续的进行着,以保持各个 secondary 节点之间的数据同步。initial sync当遇到无法同步的问题时,只能使用以下两种方式进行 initial sync 了1)第一种方式就是停止该节点,然后删除目录中的文件,重新启动该节点。这样,这个节 点就会执行 initial sync 注意:通过这种方式,sync 的时间是根据数据量大小的,如果数据量过大,sync 时间就 会很长 同时会有很多网络传输,可能会影响其他节点的工作2)第二种方式,停止该节点,然后删除目录中的文件,找一个比较新的节点,然后把该节点目 录中的文件拷贝到要 sync 的节点目录中通过上面两种方式中的一种,都可以重新恢复"port=33333"的节点。不在进行截图了。副本集管理1)查看oplog的信息 通过"db.printReplicationInfo()"命令可以查看 oplog 的信息 字段说明: configured oplog size: oplog 文件大小 log length start to end: oplog 日志的启用时间段 oplog first event time: 第一个事务日志的产生时间 oplog last event time: 最后一个事务日志的产生时间 now: 现在的时间2)查看 slave 状态 通过"db.printSlaveReplicationInfo()"可以查看 slave 的同步状态 当插入一条新的数据,然后重新检查 slave 状态时,就会发现 sync 时间更新了 |
4)副本集选举的过程和注意点
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
Mongodb副本集选举采用的是Bully算法,这是一种协调者(主节点)竞选算法,主要思想是集群的每个成员都可以声明它是主节点并通知其他节点。别的节点可以选择接受这个声称或是拒绝并进入主节点竞争,被其他所有节点接受的节点才能成为主节点。节点按照一些属性来判断谁应该胜出,这个属性可以是一个静态 ID,也可以是更新的度量像最近一次事务ID(最新的节点会胜出)副本集的选举过程大致如下:1)得到每个服务器节点的最后操作时间戳。每个 mongodb 都有 oplog 机制会记录本机的操作,方便和主服 务器进行对比数据是否同步还可以用于错误恢复。2)如果集群中大部分服务器 down 机了,保留活着的节点都为 secondary 状态并停止,不选举了。3)如果集群中选举出来的主节点或者所有从节点最后一次同步时间看起来很旧了,停止选举等待人来操作。4)如果上面都没有问题就选择最后操作时间戳最新(保证数据是最新的)的服务器节点作为主节点。副本集选举的特点:选举还有个前提条件,参与选举的节点数量必须大于副本集总节点数量的一半(建议副本集成员为奇数。最多12个副本节点,最多7个节点参与选举)如果已经小于一半了所有节点保持只读状态。集合中的成员一定要有大部分成员(即超过一半数量)是保持正常在线状态,3个成员的副本集,需要至少2个从属节点是正常状态。如果一个从属节点挂掉,那么当主节点down掉 产生故障切换时,由于副本集中只有一个节点是正常的,少于一半,则选举失败。4个成员的副本集,则需要3个成员是正常状态(先关闭一个从属节点,然后再关闭主节点,产生故障切换,此时副本集中只有2个节点正常,则无法成功选举出新主节点)。 |
5)副本集数据过程
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
Primary节点写入数据,Secondary通过读取Primary的oplog得到复制信息,开始复制数据并且将复制信息写入到自己的oplog。如果某个操作失败,则备份节点停止从当前数据源复制数据。如果某个备份节点由于某些原因挂掉了,当重新启动后,就会自动从oplog的最后一个操作开始同步,同步完成后,将信息写入自己的oplog,由于复制操作是先复制数据,复制完成后再写入oplog,有可能相同的操作会同步两份,不过MongoDB在设计之初就考虑到这个问题,将oplog的同一个操作执行多次,与执行一次的效果是一样的。简单的说就是:当Primary节点完成数据操作后,Secondary会做出一系列的动作保证数据的同步:1)检查自己local库的oplog.rs集合找出最近的时间戳。2)检查Primary节点local库oplog.rs集合,找出大于此时间戳的记录。3)将找到的记录插入到自己的oplog.rs集合中,并执行这些操作。副本集的同步和主从同步一样,都是异步同步的过程,不同的是副本集有个自动故障转移的功能。其原理是:slave端从primary端获取日志,然后在自己身上完全顺序的执行日志所记录的各种操作(该日志是不记录查询操作的),这个日志就是local数据 库中的oplog.rs表,默认在64位机器上这个表是比较大的,占磁盘大小的5%,oplog.rs的大小可以在启动参数中设 定:--oplogSize 1000,单位是M。注意:在副本集的环境中,要是所有的Secondary都宕机了,只剩下Primary。最后Primary会变成Secondary,不能提供服务。 |
6)MongoDB 同步延迟问题
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
当你的用户抱怨修改过的信息不改变,删除掉的数据还在显示,你掐指一算,估计是数据库主从不同步。与其他提供数据同步的数据库一样,MongoDB 也会遇到同步延迟的问题,在MongoDB的Replica Sets模式中,同步延迟也经常是困扰使用者的一个大问题。什么是同步延迟?首先,要出现同步延迟,必然是在有数据同步的场合,在 MongoDB 中,有两种数据冗余方式,一种是Master-Slave 模式,一种是Replica Sets模式。这两个模式本质上都是在一个节点上执行写操作, 另外的节点将主节点上的写操作同步到自己这边再进行执行。在MongoDB中,所有写操作都会产生 oplog,oplog 是每修改一条数据都会生成一条,如果你采用一个批量 update 命令更新了 N 多条数据, 那么抱歉,oplog 会有很多条,而不是一条。所以同步延迟就是写操作在主节点上执行完后,从节点还没有把 oplog 拿过来再执行一次。而这个写操作的量越大,主节点与从节点的差别也就越大,同步延迟也就越大了。同步延迟带来的问题首先,同步操作通常有两个效果,一是读写分离,将读操作放到从节点上来执行,从而减少主节点的 压力。对于大多数场景来说,读多写少是基本特性,所以这一点是很有用的。另一个作用是数据备份, 同一个写操作除了在主节点执行之外,在从节点上也同样执行,这样我们就有多份同样的数据,一旦 主节点的数据因为各种天灾人祸无法恢复的时候,我们至少还有从节点可以依赖。但是主从延迟问题 可能会对上面两个效果都产生不好的影响。如果主从延迟过大,主节点上会有很多数据更改没有同步到从节点上。这时候如果主节点故障,就有 两种情况:1)主节点故障并且无法恢复,如果应用上又无法忍受这部分数据的丢失,我们就得想各种办法将这部 数据更改找回来,再写入到从节点中去。可以想象,即使是有可能,那这也绝对是一件非常恶心的活。2)主节点能够恢复,但是需要花的时间比较长,这种情况如果应用能忍受,我们可以直接让从节点提 供服务,只是对用户来说,有一段时间的数据丢失了,而如果应用不能接受数据的不一致,那么就只能下线整个业务,等主节点恢复后再提供服务了。如果你只有一个从节点,当主从延迟过大时,由于主节点只保存最近的一部分 oplog,可能会导致从 节点青黄不接,不得不进行 resync 操作,全量从主节点同步数据。带来的问题是:当从节点全量同步的时候,实际只有主节点保存了完整的数据,这时候如果主节点故障,很可能全 部数据都丢掉了。 |
7)Mongodb副本集环境部署记录
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
|
1)机器环境182.48.115.236 master-node(主节点)182.48.115.237 slave-node1(从节点)182.48.115.238 slave-node2(从节点)MongoDB 安装目录:/usr/local/mongodbMongoDB 数据库目录:/usr/local/mongodb/dataMongoDB 日志目录:/usr/local/mongodb/log/mongo.logMongoDB 配置文件:/usr/local/mongodb/mongodb.confmongodb安装可以参考:http://www.cnblogs.com/kevingrace/p/5752382.html对以上三台服务器部署Mongodb的副本集功能,定义副本集名称为:hqmongodb关闭三台服务器的iptables防火墙和selinux2)确保三台副本集服务器上的配置文件完全相同(即三台机器的mongodb.conf配置一样,除了配置文件中绑定的ip不一样)。下面操作在三台节点机上都要执行:编写配置文件[root@master-node ~]# cat /usr/local/mongodb/mongodb.confport=27017bind_ip = 182.48.115.236 //这个最好配置成本机的ip地址。否则后面进行副本集初始化的时候可能会失败! dbpath=/usr/local/mongodb/datalogpath=/usr/local/mongodb/log/mongo.logpidfilepath=/usr/local/mongodb/mongo.pidfork=truelogappend=trueshardsvr=truedirectoryperdb=true#auth=true#keyFile =/usr/local/mongodb/keyfilereplSet =hqmongodb编写启动脚本(各个节点需要将脚本中的ip改为本机自己的ip地址)[root@master-node ~]# cat /usr/local/mongodb/mongodb.confport=27017dbpath=/usr/local/mongodb/datalogpath=/usr/local/mongodb/log/mongo.logpidfilepath=/usr/local/mongodb/mongo.pidfork=truelogappend=trueshardsvr=truedirectoryperdb=true#auth=true#keyFile =/usr/local/mongodb/keyfilereplSet =hqmongodb[root@master-node ~]# cat /etc/init.d/mongodb#!/bin/sh# chkconfig: - 64 36# description:mongodcase $1 instart)/usr/local/mongodb/bin/mongod --maxConns 20000 --config /usr/local/mongodb/mongodb.conf;;stop)/usr/local/mongodb/bin/mongo 182.48.115.236:27017/admin --eval "db.shutdownServer()"#/usr/local/mongodb/bin/mongo 182.48.115.236:27017/admin --eval "db.auth('system', '123456');db.shutdownServer()";;status)/usr/local/mongodb/bin/mongo 182.48.115.236:27017/admin --eval "db.stats()"#/usr/local/mongodb/bin/mongo 182.48.115.236:27017/admin --eval "db.auth('system', '123456');db.stats()";; esac启动mongodb[root@master-node ~]# ulimit -SHn 655350[root@master-node ~]# /etc/init.d/mongodb startabout to fork child process, waiting until server is ready for connections.forked process: 28211child process started successfully, parent exiting[root@master-node ~]# ps -ef|grep mongodbroot 28211 1 2 00:30 ? 00:00:00 /usr/local/mongodb/bin/mongod --maxConns 20000 --config /usr/local/mongodb/mongodb.confroot 28237 27994 0 00:30 pts/2 00:00:00 grep mongodb[root@master-node ~]# lsof -i:27017COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAMEmongod 28211 root 7u IPv4 684206 0t0 TCP *:27017 (LISTEN)------------------------------------------------------------------如果启动mongodb的时候报错如下:about to fork child process, waiting until server is ready for connections.forked process: 14229ERROR: child process failed, exited with error number 100这算是一个Mongod 启动的一个常见错误,非法关闭的时候,lock 文件没有干掉,第二次启动的时候检查到有lock 文件的时候,就报这个错误了。解决方法:进入mongod启动时指定的data目录下删除lock文件,然后执行"./mongod --repair"就行了。即# rm -rf /usr/local/mongodb/data/mongod.lock //由于我的测试环境下没有数据,我将data数据目录下的文件全部清空,然后--repair# /usr/local/mongodb/bin/mongod --repair然后再启动mongodb就ok了!------------------------------------------------------------------3)对master-node主节点进行配置(182.48.115.236) //其实,刚开始这三个节点中的任何一个都可以用来初始化为开始的主节点。这里选择以master-node为主节点[root@master-node ~]# mongo 182.48.115.236:27017 //登陆到mongodb数据库中执行下面命令操作。由于配置文件中绑定了ip,所以要用这个绑定的ip登陆....3.1)初始化副本集,设置本机为主节点 PRIMARY> rs.initiate(){ "info2" : "no configuration specified. Using a default configuration for the set", "me" : "182.48.115.236:27017", "ok" : 1}hqmongodb:OTHER> rs.conf(){ "_id" : "hqmongodb", "version" : 1, "protocolVersion" : NumberLong(1), "members" : [ { "_id" : 0, "host" : "182.48.115.236:27017", "arbiterOnly" : false, "buildIndexes" : true, "hidden" : false, "priority" : 1, "tags" : { }, "slaveDelay" : NumberLong(0), "votes" : 1 } ], "settings" : { "chainingAllowed" : true, "heartbeatIntervalMillis" : 2000, "heartbeatTimeoutSecs" : 10, "electionTimeoutMillis" : 10000, "catchUpTimeoutMillis" : 2000, "getLastErrorModes" : { }, "getLastErrorDefaults" : { "w" : 1, "wtimeout" : 0 }, "replicaSetId" : ObjectId("5932f142a55dc83eca86ea86") }}3.2)添加副本集从节点。(发现在执行上面的两个命令后,前缀已经改成"hqmongodb:PRIMARY"了,即已经将其自己设置为主节点 PRIMARY了)hqmongodb:PRIMARY> rs.add("182.48.115.237:27017"){ "ok" : 1 }hqmongodb:PRIMARY> rs.add("182.48.115.238:27017"){ "ok" : 1 }3.3)设置节点优先级hqmongodb:PRIMARY> cfg = rs.conf() //查看节点顺序{ "_id" : "hqmongodb", "version" : 3, "protocolVersion" : NumberLong(1), "members" : [ { "_id" : 0, "host" : "182.48.115.236:27017", "arbiterOnly" : false, "buildIndexes" : true, "hidden" : false, "priority" : 1, "tags" : { }, "slaveDelay" : NumberLong(0), "votes" : 1 }, { "_id" : 1, "host" : "182.48.115.237:27017", "arbiterOnly" : false, "buildIndexes" : true, "hidden" : false, "priority" : 1, "tags" : { }, "slaveDelay" : NumberLong(0), "votes" : 1 }, { "_id" : 2, "host" : "182.48.115.238:27017", "arbiterOnly" : false, "buildIndexes" : true, "hidden" : false, "priority" : 1, "tags" : { }, "slaveDelay" : NumberLong(0), "votes" : 1 } ], "settings" : { "chainingAllowed" : true, "heartbeatIntervalMillis" : 2000, "heartbeatTimeoutSecs" : 10, "electionTimeoutMillis" : 10000, "catchUpTimeoutMillis" : 2000, "getLastErrorModes" : { }, "getLastErrorDefaults" : { "w" : 1, "wtimeout" : 0 }, "replicaSetId" : ObjectId("5932f142a55dc83eca86ea86") }}hqmongodb:PRIMARY> cfg.members[0].priority = 11hqmongodb:PRIMARY> cfg.members[1].priority = 11hqmongodb:PRIMARY> cfg.members[2].priority = 2 //设置_ID 为 2 的节点为主节点。即当当前主节点发生故障时,该节点就会转变为主节点接管服务2hqmongodb:PRIMARY> rs.reconfig(cfg) //使配置生效{ "ok" : 1 }说明:MongoDB副本集通过设置priority 决定优先级,默认优先级为1,priority值是0到100之间的数字,数字越大优先级越高,priority=0,则此节点永远不能成为主节点 primay。cfg.members[0].priority =1 参数,中括号里的数字是执行rs.conf()查看到的节点顺序, 第一个节点是0,第二个节点是 1,第三个节点是 2,以此类推。优先级最高的那个被设置为主节点。4)分别对两台从节点进行配置slave-node1节点操作(182.48.115.237)[root@slave-node1 ~]# mongo 182.48.115.237:27017.....hqmongodb:SECONDARY> db.getMongo().setSlaveOk() //设置从节点为只读.注意从节点的前缀现在是SECONDARY。看清楚才设置slave-node2节点操作(182.48.115.238)[root@slave-node2 ~]# mongo 182.48.115.238:27017......hqmongodb:SECONDARY> db.getMongo().setSlaveOk() //从节点的前缀是SECONDARY,看清楚才设置。执行这个,否则后续从节点同步数据时会报错:"errmsg" : "not master and slaveOk=false",5)设置数据库账号,开启登录验证(这一步可以直接跳过,即不开启登陆验证,只是为了安全着想)5.1)设置数据库账号在master-node主节点服务器182.48.115.236上面操作[root@master-node ]# mongo 182.48.115.236:27017......-------------------------------------------------如果执行命令后出现报错: "errmsg" : "not master and slaveOk=false",这是正常的,因为SECONDARY是不允许读写的,如果非要解决,方法如下:> rs.slaveOk(); //执行这个命令然后,再执行其它命令就不会出现这个报错了-------------------------------------------------hqmongodb:PRIMARY> show dbslocal 0.000GB hqmongodb:PRIMARY> use admin //mongodb3.0没有admin数据库了,需要手动创建。admin库下添加的账号才是管理员账号switched to db admin hqmongodb:PRIMARY> show collections#添加两个管理员账号,一个系统管理员:system 一个数据库管理员:administrator#先添加系统管理员账号,用来管理用户hqmongodb:PRIMARY> db.createUser({user:"system",pwd:"123456",roles:[{role:"root",db:"admin"}]})Successfully added user: { "user" : "system", "roles" : [ { "role" : "root", "db" : "admin" } ]}hqmongodb:PRIMARY> db.auth('system','123456') //添加管理员用户认证,认证之后才能管理所有数据库1#添加数据库管理员,用来管理所有数据库hqmongodb:PRIMARY> db.createUser({user:'administrator', pwd:'123456', roles:[{ role: "userAdminAnyDatabase", db: "admin"}]});Successfully added user: { "user" : "administrator", "roles" : [ { "role" : "userAdminAnyDatabase", "db" : "admin" } ]}hqmongodb:PRIMARY> db.auth('administrator','123456') //添加管理员用户认证,认证之后才能管理所有数据库1hqmongodb:PRIMARY> dbadminhqmongodb:PRIMARY> show collectionssystem.userssystem.versionhqmongodb:PRIMARY> db.system.users.find(){ "_id" : "admin.system", "user" : "system", "db" : "admin", "credentials" : { "SCRAM-SHA-1" : { "iterationCount" : 10000, "salt" : "uTGH9NI6fVUFXd2u7vu3Pw==", "storedKey" : "qJBR7dlqj3IgnWpVbbqBsqo6ECs=", "serverKey" : "pTQhfZohNh760BED7Zn1Vbety4k=" } }, "roles" : [ { "role" : "root", "db" : "admin" } ] }{ "_id" : "admin.administrator", "user" : "administrator", "db" : "admin", "credentials" : { "SCRAM-SHA-1" : { "iterationCount" : 10000, "salt" : "zJ3IIgYCe4IjZm0twWnK2Q==", "storedKey" : "2UCFc7KK1k5e4BgWbkTKGeuOVB4=", "serverKey" : "eYHK/pBpf8ntrER1A8fiI+GikBY=" } }, "roles" : [ { "role" : "userAdminAnyDatabase", "db" : "admin" } ] }退出,用刚才创建的账号进行登录[root@master-node ~]# mongo 182.48.115.236:27017 -u system -p 123456 --authenticationDatabase admin[root@master-node ~]# mongo 182.48.115.236:27017 -u administrator -p 123456 --authenticationDatabase admin5.2)开启登录验证在master-node主节点服务器182.48.115.236上面操作[root@master-node ~]# cd /usr/local/mongodb/ //切换到mongodb主目录[root@master-node mongodb]# openssl rand -base64 21 > keyfile //创建一个 keyfile(使用 openssl 生成 21 位 base64 加密的字符串)[root@master-node mongodb]# chmod 600 /usr/local/mongodb/keyfile[root@master-node mongodb]# cat /usr/local/mongodb/keyfile //查看刚才生成的字符串,做记录,后面要用到RavtXslz/WTDwwW2JiNvK4OBVKxU注意:上面的数字 21,最好是 3 的倍数,否则生成的字符串可能含有非法字符,认证失败。5.3)设置配置文件分别在所有节点上面操作(即三个节点的配置文件上都要修改)[root@master-node ~]# vim /usr/local/mongodb/mongodb.conf //添加下面两行内容......auth=truekeyFile =/usr/local/mongodb/keyfile启动脚本使用下面的代码(注释原来的,启用之前注释掉的)[root@master-node ~]# cat /etc/init.d/mongodb#!/bin/sh# chkconfig: - 64 36# description:mongodcase $1 instart)/usr/local/mongodb/bin/mongod --maxConns 20000 --config /usr/local/mongodb/mongodb.conf;;stop)#/usr/local/mongodb/bin/mongo 182.48.115.236:27017/admin --eval "db.shutdownServer()"/usr/local/mongodb/bin/mongo 182.48.115.236:27017/admin --eval "db.auth('system', '123456');db.shutdownServer()";;status)#/usr/local/mongodb/bin/mongo 182.48.115.236:27017/admin --eval "db.stats()"/usr/local/mongodb/bin/mongo 182.48.115.236:27017/admin --eval "db.auth('system', '123456');db.stats()";; esac5.4)设置权限验证文件先进入master-node主节点服务器182.48.115.236,查看[root@master-node ~]# cat /usr/local/mongodb/keyfileRavtXslz/WTDwwW2JiNvK4OBVKxU //查看刚才生成的字符串,做记录再分别进入两台从节点服务器182.48.115.237/238[root@slave-node1 ~]# vim /usr/local/mongodb/keyfile //将主节点生成的权限验证字符码复制到从节点的权限验证文件里RavtXslz/WTDwwW2JiNvK4OBVKxU[root@slave-node1 ~]# chmod 600 /usr/local/mongodb/keyfile[root@slave-node2 ~]# vim /usr/local/mongodb/keyfile[root@slave-node2 ~]# cat /usr/local/mongodb/keyfileRavtXslz/WTDwwW2JiNvK4OBVKxU[root@slave-node2 ~]# chmod 600 /usr/local/mongodb/keyfile6)验证副本集分别重启三台副本集服务器(三台节点都要重启)[root@master-node ~]# ps -ef|grep mongodbroot 28964 1 1 02:22 ? 00:00:31 /usr/local/mongodb/bin/mongod --maxConns 20000 --config /usr/local/mongodb/mongodb.confroot 29453 28911 0 03:04 pts/0 00:00:00 grep mongodb[root@master-node ~]# kill -9 28964[root@master-node ~]# /etc/init.d/mongodb startabout to fork child process, waiting until server is ready for connections.forked process: 29457child process started successfully, parent exiting[root@master-node ~]# lsof -i:27017COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAMEmongod 29457 root 7u IPv4 701471 0t0 TCP slave-node1:27017 (LISTEN)mongod 29457 root 29u IPv4 701526 0t0 TCP slave-node1:27017->master-node:39819 (ESTABLISHED)mongod 29457 root 30u IPv4 701573 0t0 TCP slave-node1:27017->master-node:39837 (ESTABLISHED)mongod 29457 root 31u IPv4 701530 0t0 TCP slave-node1:36768->master-node:27017 (ESTABLISHED)mongod 29457 root 32u IPv4 701549 0t0 TCP slave-node1:36786->master-node:27017 (ESTABLISHED)mongod 29457 root 33u IPv4 701574 0t0 TCP slave-node1:27017->master-node:39838 (ESTABLISHED)然后登陆mongodb[root@master-node ~]# mongo 182.48.115.236:27017 -u system -p 123456 --authenticationDatabase admin.......hqmongodb:PRIMARY> rs.status() //副本集状态查看.也可以省略上面添加登陆验证的步骤,不做验证,直接查看集群状态。集群状态中可以看出哪个节点目前是主节点{ "set" : "hqmongodb", "date" : ISODate("2017-06-03T19:06:59.708Z"), "myState" : 1, "term" : NumberLong(2), "heartbeatIntervalMillis" : NumberLong(2000), "optimes" : { "lastCommittedOpTime" : { "ts" : Timestamp(1496516810, 1), "t" : NumberLong(2) }, "appliedOpTime" : { "ts" : Timestamp(1496516810, 1), "t" : NumberLong(2) }, "durableOpTime" : { "ts" : Timestamp(1496516810, 1), "t" : NumberLong(2) } }, "members" : [ { "_id" : 0, "name" : "182.48.115.236:27017", "health" : 1, "state" : 1, //state的值为1的节点就是主节点 "stateStr" : "PRIMARY", //主节点PRIMARY标记 "uptime" : 138, "optime" : { "ts" : Timestamp(1496516810, 1), "t" : NumberLong(2) }, "optimeDate" : ISODate("2017-06-03T19:06:50Z"), "infoMessage" : "could not find member to sync from", "electionTime" : Timestamp(1496516709, 1), "electionDate" : ISODate("2017-06-03T19:05:09Z"), "configVersion" : 4, "self" : true }, { "_id" : 1, "name" : "182.48.115.237:27017", "health" : 1, "state" : 2, "stateStr" : "SECONDARY", "uptime" : 116, "optime" : { "ts" : Timestamp(1496516810, 1), "t" : NumberLong(2) }, "optimeDurable" : { "ts" : Timestamp(1496516810, 1), "t" : NumberLong(2) }, "optimeDate" : ISODate("2017-06-03T19:06:50Z"), "optimeDurableDate" : ISODate("2017-06-03T19:06:50Z"), "lastHeartbeat" : ISODate("2017-06-03T19:06:59.533Z"), "lastHeartbeatRecv" : ISODate("2017-06-03T19:06:59.013Z"), "pingMs" : NumberLong(0), "syncingTo" : "182.48.115.236:27017", "configVersion" : 4 }, { "_id" : 2, "name" : "182.48.115.238:27017", "health" : 1, "state" : 2, "stateStr" : "SECONDARY", "uptime" : 189, "optime" : { "ts" : Timestamp(1496516810, 1), "t" : NumberLong(2) }, "optimeDurable" : { "ts" : Timestamp(1496516810, 1), "t" : NumberLong(2) }, "optimeDate" : ISODate("2017-06-03T19:06:50Z"), "optimeDurableDate" : ISODate("2017-06-03T19:06:50Z"), "lastHeartbeat" : ISODate("2017-06-03T19:06:59.533Z"), "lastHeartbeatRecv" : ISODate("2017-06-03T19:06:59.013Z"), "pingMs" : NumberLong(0), "syncingTo" : "182.48.115.236:27017", "configVersion" : 4 }, ], "ok" : 1}注意上面命令结果中的state,如果这个值为 1,说明是主控节点(master);如果是2,说明是从属节点slave。在上面显示的当前主节点写入数据,到从节点上查看发现数据会同步。 当主节点出现故障的时候,在两个从节点上会选举出一个新的主节点,故障恢复之后,之前的主节点会变为从节点。从上面集群状态中开看出,当前主节点是master-node,那么关闭它的mongodb,再次查看集群状态,就会发现主节点变为之前设置的slave-node2,即182.48.115.238了!至此,Linux 下 MongoDB 副本集部署完成。-------------------------------------------------------------------------------------------添加数据,来需要验证的--------------------1)主从服务器数据是否同步,从服务器没有读写权限a:向主服务器写入数据 ok 后台自动同步到从服务器,从服务器有数据b:向从服务器写入数据 false 从服务器不能写c:主服务器读取数据 okd:从服务器读取数据 false 从服务器不能读2)关闭主服务器,从服务器是否能顶替 mongo 的命令行执行 rs.status() 发现 PRIMARY 替换了主机了3)关闭的服务器,再恢复,以及主从切换 a:直接启动关闭的服务,rs.status()中会发现,原来挂掉的主服务器重启后变成从服务器了 b:额外删除新的服务器 rs.remove("localhost:9933"); rs.status() c:额外增加新的服务器 rs.add({_id:0,host:"localhost:9933",priority:1}); d:让新增的成为主服务器 rs.stepDown(),注意之前的 priority 投票4)从服务器读写 db.getMongo().setSlaveOk(); db.getMongo().slaveOk();//从库只读,没有写权限,这个方法 java 里面不推荐了 db.setReadPreference(ReadPreference.secondaryPreferred());// 在 复 制 集 中 优 先 读 secondary,如果 secondary 访问不了的时候就从 master 中读 db.setReadPreference(ReadPreference.secondary());// 只 从 secondary 中 读 , 如 果 secondary 访问不了的时候就不能进行查询日志查看--------------------------- MongoDB 的 Replica Set 架构是通过一个日志来存储写操作的,这个日志就叫做”oplog”, 它存在于”local”数据库中,oplog 的大小是可以通过 mongod 的参数”—oplogSize”来改变 oplog 的日志大小。 > use local switched to db local > db.oplog.rs.find() { "ts" : { "t" : 1342511269000, "i" : 1 }, "h" : NumberLong(0), "op" : "n", "ns" : "", "o" : { "msg" : "initiating set" } } 字段说明: ts: 某个操作的时间戳 op: 操作类型,如下: i: insert d: delete u: update ns: 命名空间,也就是操作的 collection name-------------------------------------------------------------------------------------------其它注意细节:rs.remove("ip:port"); //删除副本单服务器,启动时添加--auth 参数开启验证。副本集服务器,开启--auth 参数的同时,必须指定 keyfile 参数,节点之间的通讯基于该 keyfile,key 长度必须在 6 到 1024 个字符之间,最好为 3 的倍数,不能含有非法字符。重新设置副本集rs.stepDown()cfg = rs.conf()cfg.members[n].host= 'new_host_name:prot'rs.reconfig(cfg)副本集所有节点服务器总数必须为奇数,服务器数量为偶数的时候,需要添加一个仲裁节 点,仲裁节点不参与数副本集,只有选举权。rs.addArb("182.48.115.239:27017") #添加仲裁节点 |
三、Mongodb分片集群(Sharding)
Sharding cluster是一种可以水平扩展的模式,在数据量很大时特给力,实际大规模应用一般会采用这种架构去构建。sharding分片很好的解决了单台服务器磁盘空间、内存、cpu等硬件资源的限制问题,把数据水平拆分出去,降低单节点的访问压力。每个分片都是一个独立的数据库,所有的分片组合起来构成一个逻辑上的完整的数据库。因此,分片机制降低了每个分片的数据操作量及需要存储的数据量,达到多台服务器来应对不断增加的负载和数据的效果。
1)Sharding分区概念
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
分片 (sharding)是指将数据库拆分,将其分散在不同的机器上的过程。将数据分散到不同的机器上,不需要功能强大的服务器就可以存储更多的数据和处理更大的负载。分片的基本思想就是:将集合切成小块,这些块分散到若干片里,每个片只负责总数据的一部分。通过一个名为 mongos 的路由进程进行操作,mongos 知道数据和片的对应关系(通过配置服务器)。 大部分使用场景都是解决磁盘空间的问题,对于写入有可能会变差(+++里面的说明+++),查 询则尽量避免跨分片查询。使用分片的时机:使用场景:1)机器的磁盘不够用了。使用分片解决磁盘空间的问题。2)单个mongod已经不能满足写数据的性能要求。通过分片让写压力分散到各个分片上面,使用分片服务器自身的资源。3)想把大量数据放到内存里提高性能。和上面一样,通过分片使用分片服务器自身的资源。要构建一个MongoDB Sharding Cluster(分片集群),需要三种角色:1)分片服务器(Shard Server) mongod 实例,用于存储实际的数据块,实际生产环境中一个 shard server 角色可由几台机器组个一个 relica set 承担,防止主机单点故障 这是一个独立普通的mongod进程,保存数据信息。可以是一个副本集也可以是单独的一台服务器。2)配置服务器(Config Server) mongod 实例,存储了整个 Cluster Metadata,其中包括 chunk 信息。 这是一个独立的mongod进程,保存集群和分片的元数据,即各分片包含了哪些数据的信息。最先开始建立,启用日志功能。像启动普通的 mongod 一样启动 配置服务器,指定configsvr 选项。不需要太多的空间和资源,配置服务器的 1KB 空间相当于真是数据的 200MB。保存的只是数据的分布表。3)路由服务器(Route Server) mongos实例,前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用 起到一个路由的功能,供程序连接。本身不保存数据,在启动时从配置服务器加载集群信息,开启 mongos 进程需要知道配置服务器的地址,指定configdb选项。片键的意义一个好的片键对分片至关重要。 片键必须是一个索引 ,通 过 sh.shardCollection 加会自动创建索引。一个自增的片键对写入和数据均匀分布就不是很好, 因为自增的片键总会在一个分片上写入,后续达到某个阀值可能会写到别的分片。但是按照片键查询会非常高效。随机片键对数据的均匀分布效果很好。注意尽量避免在多个分片上进行查询。在所有分片上查询,mongos 会对结果进行归并排序 |
为何需要水平分片
1)减少单机请求数,将单机负载,提高总负载
2)减少单机的存储空间,提高总存空间
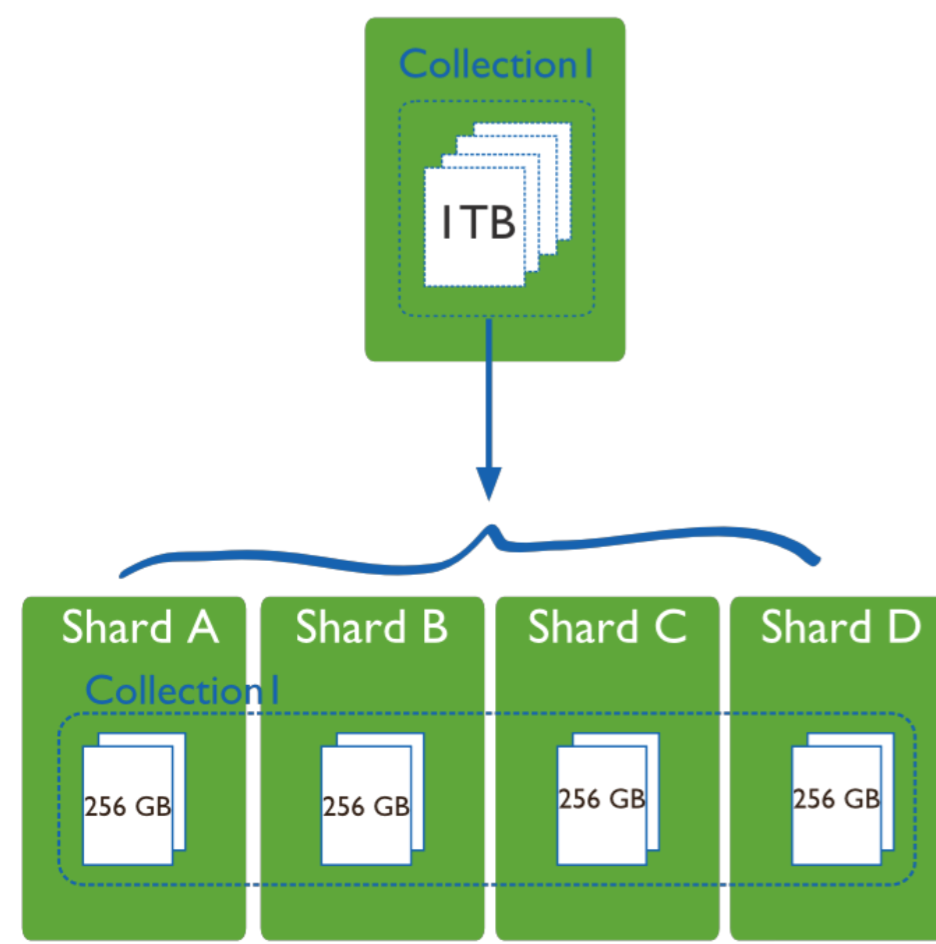
mongodb sharding 服务器架构

简单注解:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
分片集群主要由三种组件组成:mongos,config server,shard1) mongos (路由进程, 应用程序接入 mongos 再查询到具体分片)数据库集群请求的入口,所有的请求都通过 mongos 进行协调,不需要在应用程序添加一个路由选择器,mongos 自己就是一个请求分发中心,它负责把对应的数据请求请求转发到对应的 shard 服务器上。在生产环境通常有多个 mongos 作为请求的入口,防止其中一个挂掉所有的 mongodb 请求都没有办法操作。2) config server (路由表服务。 每一台都具有全部 chunk 的路由信息)顾名思义为配置服务器,存储所有数据库元信息(路由、分片)的配置。mongos 本身没有物理存储分片服务器和数据路由信息,只是缓存在内存里,配置服务器则实际存储这些数据。mongos 第一次启动或者关掉重启就会从 config server 加载配置信息,以后如果配置服务器信息变化会通知到所有的 mongos 更新自己的状态,这样mongos 就能继续准确路由。在生产环境通常有多个 config server 配置服务器,因为它存储了分片路由的元数据,这个可不能丢失!就算挂掉其中一台,只要还有存货,mongodb 集群就不会挂掉。3) shard (为数据存储分片。 每一片都可以是复制集(replica set))这就是传说中的分片了。如图所示,一台机器的一个数据表 Collection1 存储了 1T 数据,压力太大了!在分给 4 个机器后, 每个机器都是 256G,则分摊了集中在一台机器的压力。事实上,上图4个分片如果没有副本集(replica set)是个不完整架构,假设其中的一个分片挂掉那四 分之一的数据就丢失了,所以在高可用性的分片架构还需要对于每一个分片构建 replica set 副本集保 证分片的可靠性。生产环境通常是 2 个副本 + 1 个仲裁。 |
2)Sharding分区的原理
|
1
2
3
|
分片,是指将数据拆分,将其分散到不同的机器上。这样的好处就是,不需要功能强大的大型计算机也可以存储更多的数据,处理更大的负载。mongoDB 的分片,是将collection 的数据进行分割,然后将不同的部分分别存储到不同的机器上。当 collection 所占空间过大时,我们需要增加一台新的机器,分片会自动将 collection 的数据分发到新的机器上。 |
mongoDB sharding分片的原理

|
1
2
3
4
5
6
7
8
9
10
11
12
|
人脸: 代表客户端,客户端肯定说,你数据库分片不分片跟我没关系,我叫你干啥就干啥,没什么好商量的。mongos:首先我们要了解”片键“的概念,也就是说拆分集合的依据是什么?按照什么键值进行拆分集合。mongos就是一个路由服务器,它会根据管理员设置的"片键"将数据分摊到自己管理的mongod集群,数据和片的对应关系以及相应的配置信息保存在"config服务器"上。客户端只需要对 mongos 进行操作就行了,至于如何进行分片,不需要 客户端参与,由 mongos 和 config 来完成。mongod: 一个普通的数据库实例或者副本集,如果不分片的话,我们会直接连上mongod。分片是指将数据拆分,将其分散存在不同机器上的过程.有时也叫分区.将数据分散在不同的机器上MongoDB支持自动分片,可以摆脱手动分片的管理.集群自动切分数据,做负载均衡 |
分片集群的构造如下:
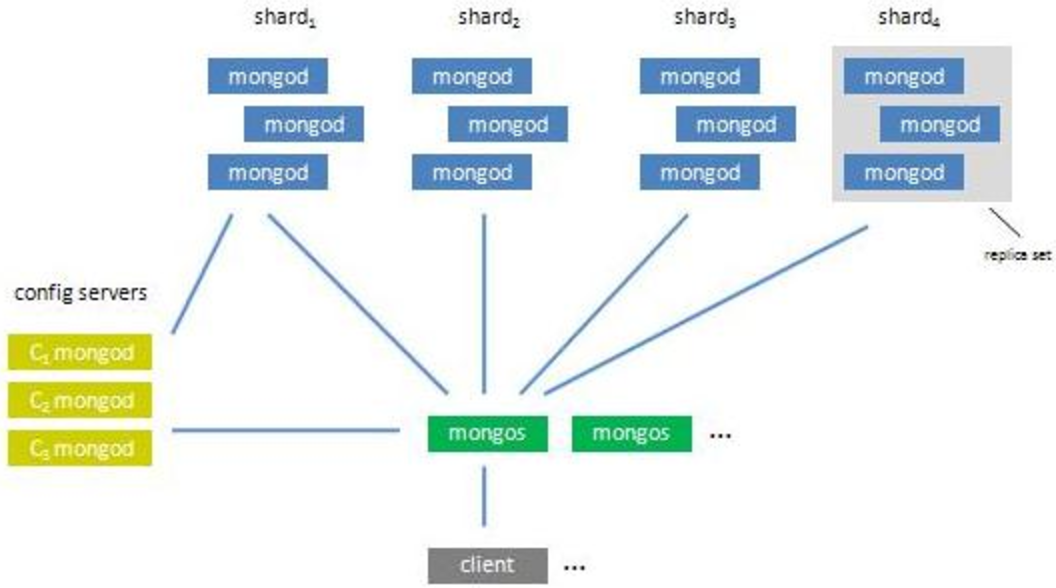
分片集群由以下3个服务组成:
Shards Server: 每个shard由一个或多个mongod进程组成,用于存储数据
Config Server: 用于存储集群的Metadata信息,包括每个Shard的信息和chunks信息
Route Server: 用于提供路由服务,由Client连接,使整个Cluster看起来像单个DB服务器
Mongodb主从复制 及 副本集+分片集群梳理的更多相关文章
- mongoDB副本集+分片集群
首先搭建一个副本集(三台机器) 主,从,仲裁 然后搭建分片shard1,在每台机子上启用shard1(这里就写一个分片吧!!如果写多了怕初学者会混乱,先写一个.然后可以按照同样的方法写第二个,第三个) ...
- Mongodb主从复制/ 副本集/分片集群介绍
前面的文章介绍了Mongodb的安装使用,在 MongoDB 中,有两种数据冗余方式,一种 是 Master-Slave 模式(主从复制),一种是 Replica Sets 模式(副本集). Mong ...
- 关于MongoDB副本集和分片集群有关用户和权限的说明分析
1.MongoDB副本集 可以先创建超管用户,然后再关闭服务,创建密钥文件,修改配置文件,启动服务,使用超管用户登录验证,然后创建普通用户 2.MongoDB分片集群 先关闭服务,创建密钥文件,修改配 ...
- MongoDB DBA 实践6-----MongoDB的分片集群部署
一.分片 MongoDB使用分片技术来支持大数据集和高吞吐量操作. 1.分片目的 对于单台数据库服务器,庞大的数据量及高吞吐量的应用程序对它而言无疑是个巨大的挑战.频繁的CRUD操作能够耗尽服务器的C ...
- MongoDB主从复制和副本集
MongoDB有主从复制和副本集两种主从复制模式,主从复制最大的问题就是无法自动故障转移,MongoDB副本集解决了主从模式无法自动故障转义的特点,因此是复制的首选.对于简单的主从复制无法自动故障转移 ...
- MongoDB DBA 实践7-----MongoDB的分片集群操
一.使用Ranged Sharding对集合进行分片 从mongo连接到的shell中mongos,使用该sh.shardCollection()方法对集合进行分片. 注意: 必须已为集合所在的数据库 ...
- 02 . MongoDB复制集,分片集,备份与恢复
复制集 MongoDB复制集RS(ReplicationSet): 基本构成是1主2从的结构,自带互相监控投票机制(Raft(MongoDB)Paxos(mysql MGR 用的是变种)) 如果发生主 ...
- mongodb 副本集+分片集群搭建
数据分片节点#192.168.114.26mongod --shardsvr --replSet rsguo --port 2011 --dbpath=/data/mongodb/guo --logp ...
- mongodb模拟生产环境的分片集群
分片是指数据拆分 将其分散在不同的机器上的过程,有时候也叫分区来表示这个概念.将数据分散到不同机器上 不需要功能强大的计算机就可以储存更多的数据,处理更大的负载. 几乎所有的数据库 ...
随机推荐
- 【tomcat】启动报错:Failed to initialize end point associated with ProtocolHandler ["http-apr-8080"] java.lang.Exception: Socket bind failed 和java.net.BindException: Address already in use: JVM_Bind错误解决
背景:[新手] 将开发机子上的Tomcat连同其中的项目,一起拷贝到服务器上,启动tomcat的start.bat,然后报错如下: 问题1: Failed to initialize end poin ...
- viewport是左下角开始的
- 增加临时表空间组Oracle11g单实例
#需求,测试库与生产库,临时表空间同步一致 #经过查询生产环境,数据库默认临时表空间,为临时表空间组,有三个成员,三个临时表空间,每个临时表空间一个数据文件,自动扩展 #使用临时表空间组的优点,减少不 ...
- Samsung_tiny4412(驱动笔记06)----list_head,proc file system,GPIO,ioremap
/**************************************************************************** * * list_head,proc fil ...
- Linux系统下curl命令上传文件,文件名包含逗号无法上传
使用curl命令,将备份好的图片全部重新导入到seaweedfs,图片全部以存储在seaweedfs中的fid命令, fid中间有一个逗号,使用curl命令时报错: curl: (26) couldn ...
- go服务运行框架go-svc
go-svc:https://github.com/judwhite/go-svc/svc go-svc支持linux和windows,应用只需实现Service接口即可. 官方例子 package ...
- MyBatis-Plus使用教程
单机版 安装环境 上传压缩包到/usr/local/software/下 解压安装包,进入解压目录的bin目录下,启动命令: ./solr start -force 默认端口是8983,请求虚拟机, ...
- 欧拉函数 已经优化到o(n)
欧拉函数 ψ(x)=x*(1-1/pi) pi为x的质数因子 特殊性质(图片内容就是图片后面的文字) 欧拉函数是积性函数——若m,n互质, ψ(m*n)=ψ(m)*ψ(n): 当n为奇数时, ψ ...
- linux---文件颜色含义
下面是linux系统约定不同类型文件默认的颜色: 白色:表示普通文件 蓝色:表示目录 绿色:表示可执行文件 红色:表示压缩文件 浅蓝色:链接文件 红色闪烁:表示链接的文件有问题 黄色:表示设备文件 灰 ...
- CentOS下如何根据Dump文件分析线上问题
https://blog.csdn.net/lixin03080/article/details/79711296 一.保存现场 1.记录系统整体资源使用情况,进程信息.线程信息 top -b -n ...