菜鸟如何使用hanlp做分词的过程记录
菜鸟如何使用hanlp做分词的过程记录
最近在学习hanlp的内容,准备在节后看看有没有时间整理一波hanlp分享下,应该还是会像之前分享DKHadoop一样的方式吧。把整个学习的过程中截图在配文字的方式搞一下。
这两天也在看一些其他人分享的hanlp学习和使用分享的文章,后面看到的分享也会转载分享给大家。今天分享的这篇也是很早前别人分享的一篇如何用hanlp做分词的文章,新手入门级的可以看看!

boss给了个做分词的任务,最开始想用的是结巴分词and正则表达式。后来发现结果并不好,需要一遍一遍筛选【第一个标准筛选出80%的数据,然后制定第二个标准,继续筛选,然后制定第三个标准筛选,等等等等】
自己用了一下结巴分词,感觉对于人名,地名,机构名,只是泛泛地使用了一下。在实际分开的时候,并不能很好地分开机构名称。于是转而使用hanlp分词。
但是hanlp分词的缺点是只有在java上可以用,但是java一向又是我的弱项。所以在这里写一篇博客从头至尾叙述一下怎么样使用hanlp。
而且,小胖胖把我的电脑锁在北师图书馆柜子里了。我工作没有电脑可用,于是使用小胖的电脑,也就是说,所有的基本变量都需要我自己来配来下,因此也相当于是从一张白纸到使用hanlp的过程。
第一步:下载一个jdk,到openjdk官网去下一个,直接安装即可。
安装过后,要配置三个环境变量,分别是
1、JAVA_HOME:C:\Program Files\Java\jdk1.8.0_73;
2、CLASSPATH: 就是这个jdk打开之后里面的那个lib的目录;
3、PATH:就是jdk后面的bin目录;
配置完成之后,在Windows底下的cmd上面,输入java -version看看有没有反应即可判断是否正确安装jdk。
【我这里出现了个小问题,在胖胖的电脑里,不知道她之前安装过什么东西,自带了一个jre1.6 然而我安装的是jre1.8 在cmd里面报错,说找不到jre1.6 后来我看了网上的说法,说是也许你别的软件也会下载java环境,所以你可能有许多不同的包,系统在寻找路径的时候,默认会根据你上面配置的环境变量里面找。因此,需要把咱们最新下的那个环境变量放在一大堆环境变量的最前面,尝试即可。】
下载了jdk安装成功之后,第二步,下载eclipse
到官网去找,记住,x86是32位,x64是64位,下载之后设定project的位置【比如我设在了D盘的根目录,结果发现不太好,但是已经改不了了。。教训】
安装成功之后,第三步,去下载hanlp的各种东西
方法1.maven方法,下载一个0配置即可。【但是我不会玩儿】
方法2:先下载hanlp-1.2.8.jar这个jar包【备注,目前hanlp版本已经发布到了portable-1.6.8】
http://hanlp.com/
再下载data.zip这个数据包,可以选择,选择下载标准数据or迷你数据or全部数据。大小不同。我下的是标准版的。40M
再下载hanlp.properties这个是一个以properties结尾的一个文件,我之前从来没见过,不过可以用txt打开。
第四步:把下载的这些东西导入到eclipse里面去,构建路径
1、把jar包导入到eclipse的lib目录下
http://jingyan.baidu.com/article/ca41422fc76c4a1eae99ed9f.html
2、自己在src里面创建一个包,在包里面创建一个类。包会在我设置的根目录D:/下面,类名称首字母必须大写?【貌似不大写的话,会被否决】
3、把data包解压,然后放在一个自己喜欢的路径【我的路径是D://py/】然后,在hanlp.properties这个文件里,把root修改为data存放的上一级目录。
4、把hanlp.properties拖动到src这个目录下
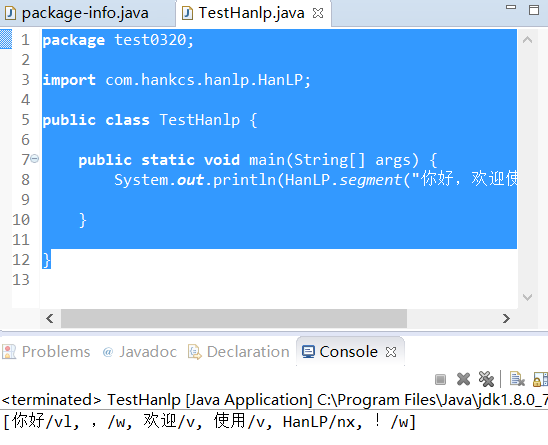
然后试验了一个demo测试,发现报错,然后点击import import com.hankcs.hanlp.HanLP;然后run了一下程序

依然报错,发现是没有把properties那个文件导入到bin目录下,再次打开test0320,在那个bin目录下复制properties文件之后运行,成功了
转载自tianbwin2995 的博客
菜鸟如何使用hanlp做分词的过程记录的更多相关文章
- lucene6+HanLP中文分词
1.前言 前一阵把博客换了个模版,模版提供了一个搜索按钮,这让我想起一直以来都想折腾的全文搜索技术,于是就用lucene6.2.1加上HanLP的分词插件做了这么一个模块CSearch.效果看这里:h ...
- 全文检索Solr集成HanLP中文分词
以前发布过HanLP的Lucene插件,后来很多人跟我说其实Solr更流行(反正我是觉得既然Solr是Lucene的子项目,那么稍微改改配置就能支持Solr),于是就抽空做了个Solr插件出来,开源在 ...
- Elasticsearch:hanlp 中文分词器
HanLP 中文分词器是一个开源的分词器,是专为Elasticsearch而设计的.它是基于HanLP,并提供了HanLP中大部分的分词方式.它的源码位于: https://github.com/Ke ...
- IK的整个分词处理过程
首先,介绍一下IK的整个分词处理过程: 1. Lucene的分词基类是Analyzer,所以IK提供了Analyzer的一个实现类IKAnalyzer.首先,我们要实例化一个IKAnalyzer,它有 ...
- 全文检索Solr集成HanLP中文分词【转】
以前发布过HanLP的Lucene插件,后来很多人跟我说其实Solr更流行(反正我是觉得既然Solr是Lucene的子项目,那么稍微改改配置就能支持Solr),于是就抽空做了个Solr插件出来,开源在 ...
- HanLP的分词统计
HanLP的分词效果鄙人研究了HanLP,他的分词效果确实还可以,而且速度也比较快,10的数据是9000毫秒 @SneakyThrows@Overridepublic LinkedHashMap< ...
- 升级Windows 10 正式版过程记录与经验
升级Windows 10 正式版过程记录与经验 [多图预警]共50张,约4.6MB 系统概要: 预装Windows 8.1中文版 64位 C盘Users 文件夹已经挪动到D盘,并在原处建立了符号链接. ...
- 双系统Ubuntu分区扩容过程记录
本人电脑上安装了Win10 + Ubuntu 12.04双系统.前段时间因为在Ubuntu上做项目要安装一个比较大的软件,导致Ubuntu根分区的空间不够了.于是,从硬盘又分出来一部分空间,分给Ubu ...
- 升级到 ExtJS 5的过程记录
升级到 ExtJS 5的过程记录 最近为公司的一个项目创建了一个 ExtJS 5 的分支,顺便记录一下升级到 ExtJS 5 所遇到的问题以及填掉的坑.由于 Sencha Cmd 的 sencha ...
随机推荐
- FGX Native library功能介绍
Hot news from the fields of the cross-platform library "FGX Native" development. New Engli ...
- IOS safari 浏览器 时间乱码(ios时间显示NaN) 问题解决
问题一: 项目中遇到一个关于日期时间在ios中乱码在安卓中安然无恙的问题,焦躁了半天 问题如上图,通过用户选择的时间和当天的天数相加然后在ios上就是乱码 这个界面运用了日期类型的计算,当我们用Jav ...
- JAVA中关于对像的读写
/** * 针对对象的文件读写 */ //导入包 import java.io.File; import java.io.FileInputStream; import java.io.FileNot ...
- 服务器上安装caffe的过程记录
1. 前言 因为新的实验室东西都是新的,所以在服务器上要自己重新配置CAFFE 这里假设所有依赖包学长们都安装好了,我是没有sudo权限的 服务器的配置: CUDA 8.0 Ubuntu 16.04 ...
- [LeetCode&Python] Problem 706. Design HashMap
Design a HashMap without using any built-in hash table libraries. To be specific, your design should ...
- day 017面向对象-反射
主要内容: isinstance, type, issubclass( 内置函数) 区分函数和方法 反射 一 ( isinstance, type, issubclass) isinstance ...
- PDO数据库引擎
PDO概述1.PDO是一种数据库访问抽象层,你不必使用以前的 mysqli_xx 之类只能访问 mysql数据库.使用PDO可以连接mysql.msssql.oracle等等,而不必重写代码.2.PD ...
- 一个简易的drf的项目例子
luffy_city 1.项目介绍 今日内容:(路飞项目) contentType组件: 路飞学成项目,有课程,学位课(不同的课程字段不一样),价格策略 问题, 如何设计表结构,来表示这种规则 为专题 ...
- C++学习(二十九)(C语言部分)之 顺序表
一.数据结构组织 存放数据的方式 精心选择的数据结构可以提升效率 数据结构 1.逻辑结构 一对多关系 父与子 一对一关系 排队中 多对多关系 两地的路线 2.存储结构 数据存放的位置关系 顺序存储数据 ...
- js中数组的去重
第一种方式: var ss=['小红','小花','小兰','小花'] var uu=[] for(var i=0;i<ss.length;i++){ if(uu.indexOf(ss[i])= ...