50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫架构中的HTML下载器、HTML解析器、数据存储器三大模块:
HTML下载器:利用requests模块下载HTML网页;
HTML解析器:利用re正则表达式解析出有效数据
数据存储器:将有效数据通过文件或者数据库的形式存储起来
一、构造HTML下载器
import requests
from requests.exceptions import RequestException
headers = {'User-Agent':'Mozilla/5.0 '}
def get_one_page(url):
try:
res = requests.get(url,headers = headers)
if res.status_code == 200:
return res.text
return None
except RequestException:
return None
二、构造HTML解析器
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
+'.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+'.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',re.S)
items = re.findall(pattern,html)
for item in items:
yield{
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
注意:1.在函数中本来该return的地方用yield,如果用return,在第一轮循环就会跳出,结果文件只会有一部电影。如果用yield,函数返回的就是一个生成器,而生成器作为一种特殊的迭代器,可以用for——in方法,一次一次的把yield拿出来;
2.re.findall(pattern,string[,flags]):搜索整个string,以列表的形式返回能匹配的全部子串,其中参数是匹配模式,如re.S表示点任意匹配模式,改变“.”的行为。
三、构造数据存储器
def write_to_file(content):
with open ('result.txt', 'a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False) + '\n')
f.close()
注意事项:1.为什么ensure_ascii=False?原因是json默认是以ASCII来解析code的,由于中文不在ASCII编码当中,因此就不让默认ASCII生效;
2.要写入特定编码的文本文件,请给open()函数传入encoding参数,将字符串自动转换成指定编码。细心的童鞋会发现,以'w'模式写入文件时,如果文件已存在,会直接覆盖(相当于删掉后新写入一个文件)。如果我们希望追加到文件末尾怎么办?可以传入'a'以追加(append)模式写入。
接下来就是构造主函数,初始化各个模块,传入入口URL,按照运行流程执行上面三大模块:
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
p = Pool()
p.map(main,[i*10 for i in range(10)])注意:为了提高速度,我们引入Pool模块,用多线程并发抓取
执行代码后,结果如下:
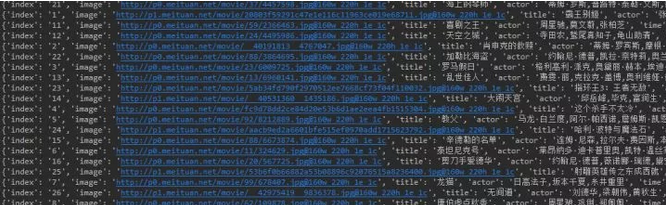
本文中介绍了基础爬虫架构主要的的三个模块(HTML下载器、HTML解析器、数据存储器),无论大型还是小型爬虫都不会脱离这三个模块,也希望大家通过这个小小的练习对整个爬虫有个清晰的认识,欢迎大家一起谈论学习交流。
50 行代码教你爬取猫眼电影 TOP100 榜所有信息的更多相关文章
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- Python爬虫项目--爬取猫眼电影Top100榜
本次抓取猫眼电影Top100榜所用到的知识点: 1. python requests库 2. 正则表达式 3. csv模块 4. 多进程 正文 目标站点分析 通过对目标站点的分析, 来确定网页结构, ...
- Requests+正则表达式爬取猫眼电影(TOP100榜)
猫眼电影网址:www.maoyan.com 前言:网上一些大神已经对猫眼电影进行过爬取,所用的方法也是各有其优,最终目的是把影片排名.图片.名称.主要演员.上映时间与评分提取出来并保存到文件或者数据库 ...
- 使用requests爬取猫眼电影TOP100榜单
Requests是一个很方便的python网络编程库,用官方的话是"非转基因,可以安全食用".里面封装了很多的方法,避免了urllib/urllib2的繁琐. 这一节使用reque ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- # [爬虫Demo] pyquery+csv爬取猫眼电影top100
目录 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 代码君 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 https://maoyan.co ...
- 用requests库爬取猫眼电影Top100
这里需要注意一下,在爬取猫眼电影Top100时,网站设置了反爬虫机制,因此需要在requests库的get方法中添加headers,伪装成浏览器进行爬取 import requests from re ...
随机推荐
- linux每日命令(10):touch命令
linux的touch命令一般用来修改文件时间戳,或者新建一个不存在的文件. 一.命令格式: touch [参数]... 文件... 二.命令参数: 参数 描述 -a 或--time=atime或-- ...
- Error:java: invalid source release 无效的源发行版: 8
原因:这是由于jdk的版本与项目的要求不一致造成的,如果是maven项目,首先查看一下pom.xml,以我的项目为例: 从其中可以看出要求的编译插件为1.8版本,而我本机上安装的jdk为1.7版本,因 ...
- 基于jQuery鼠标滚轮滑动到页面节点部分
基于jQuery鼠标滚轮滑动到页面节点部分.这是一款基于jQuery+CSS3实现的使用鼠标滚轮或者手势滑动到页面节点部分特效.效果图如下: 在线预览 源码下载 实现的代码. html代码: &l ...
- tomcat启动时非常慢,启动时 一直卡在Root WebApplicationContext: initialization completed
每次重启自己的服务tomcat都需要卡住很长时间,每次都是日志停在 Root WebApplicationContext: initialization completed in 744 ms这个地方 ...
- spring mvc中获取请求URL
String baseUrl=request.getScheme()+"://"+request.getServerName()+":"+request.get ...
- 教程:Spagobi开源BI系统 Console报表设计教程
Console Designer 1 Console Designer Console Designer 1.1 Introduction 1.2 Dataset Tab 1.3 Summary Pa ...
- Scala学习笔记(二):object、伴生对象和基本类
object object 是只有一个实例的类.它的定义与Java中的class类似,如: // 单例对象 object AppEntry { def main(args: Array[String] ...
- Ant 学习笔记
1.下载Ant 官方网站http://ant.apache.org/bindownload.cgi 下载最新版本 .zip archive: apache-ant-1.9.4-bin.zip [PG ...
- [JS] ECMAScript 6 - Destructuring
C#里没有这种变态的方法. 虽然变态,但看起来不错的样子. 变量的解构赋值 完全解构:本质上,这种写法属于“模式匹配”,: 不完全解构:同时支持“不完全解构” let [x, y] = [1, 2, ...
- 大杂烩 -- 四种生成和解析XML文档的方法详解
基础大杂烩 -- 目录 众所周知,现在解析XML的方法越来越多,但主流的方法也就四种,即:DOM.SAX.JDOM和DOM4J DOM:在现在的Java JDK里都自带了,在xml-apis.jar包 ...