MDX Step by Step 读书笔记(七) - Performing Aggregation 聚合函数之 Sum, Aggregate, Avg
开篇介绍
SSAS 分析服务中记录了大量的聚合值,这些聚合值在 Cube 中实际上指的就是度量值。一个给定的度量值可能聚合了来自事实表中上千上万甚至百万条数据,因此在设计阶段我们所能看到的度量实际上就已经应用了某些聚合函数来决定这个值怎样被聚合。
当然有可能已有的度量值远远还不够,还需要在查询的时候继续从不同的角度去聚合一些数据以满足实际需求,因此就会使用到各种不同的 MDX 聚合函数。
Sum 聚合
Sum 聚合的应用非常普通和常见,在 MDX 中其语法为: Sum ({SET} [, Expression])
也就是说 Sum 聚合函数操作的对象是一个集合,并且对于集合 SET 中的每一个 Tuple 元组来说可以使用到后面的表达式。 使用起来非常简单,其作用就是把相应的度量值全部加起来,而不需要考虑这些度量值是如何来的。如果这些度量值是基于设计阶段的 sum 或者 count 聚合的话,那么在 MDX 中的 Sum 聚合函数使用没有什么问题。但是如果这些度量值在设计阶段中使用到了 distinct count, max, min 等聚合方式的话,那么在 MDX 中 Sum 聚合有可能会产生一些不太准确的结果。
因此在这种情况下,特别要注意的就是要了解要被聚合的这个度量值在 Cube 设计阶段它本身是如何被聚合的,这个可以通过 MDX 中的 Aggregate 函数来搞定: Aggregate( {Set} [, Expression])
和 MDX Sum 函数一样,MDX Aggregate 函数可以聚合来自特定集合的值。与简单的 Sum 累加值不同的是,MDX 中的 Aggregate 函数还会考虑到它所累加的度量值对象本身是如何被聚合的。如果这个度量值本身是通过 Sum 或者 Count 聚合的话,那么 Aggregate 函数就返回一个 Sum 累加之后的结果。如果度量值本身是取的 max 聚合值,那么 Aggregate 函数就返回一个 max 结果。如果度量值本身取的是 Discint count,那么 Aggregate 函数也返回一个 Distinct count 值。实际上这个过程在分析服务中还是比较复杂的,所以在使用 MDX Aggregate 函数的时候就要注意认真检查一下那些计算值。
定义一个计算成员来聚合前5的 Sub Category 的值
SELECT
{
([Measures].[Reseller Sales Amount]),
([Measures].[Reseller Transaction Count]),
([Measures].[Reseller Order Count])
} ON COLUMNS,
TopCount(
{[Product].[Subcategory].[Subcategory].Members},
5,
([Measures].[Reseller Sales Amount])
)
+
{([Product].[Subcategory].[All Products])} ON ROWS
FROM [Step-by-Step]
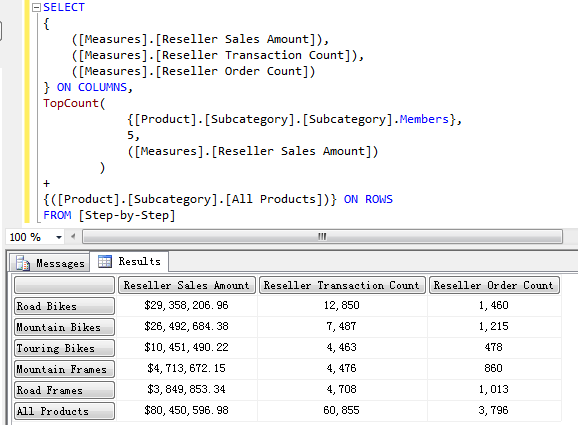
这个查询结果显示了前 5 的产品子目录以及 All 成员的 Reseller Sales Amount, Reseller Transaction Count 以及 Reseller Order Count。
这三个度量值实际上来源于数据仓库中的同一个事实表,但是它们从数据仓库到Cube这一个过程中的计算方式是不同的。
Reseller Sales Amount - 这个度量值是基于表中 Sales Amount 列上的总和。在 Cube 的设计过程中,它是通过 sum 聚合方式来实现的,聚合了 Sales Amount 列上的所有值。
Reseller Transaction Count - 度量值是以订单为基础 Count 了每个订单下的 Line Item 条数。
Reseller Order Count - 度量值记录了订单了条数,并且是通过 Distinct Count 方式来完成聚合的,因为一个订单可能有一条或者多条 Line Item 的记录。
修改这个查询,用 Aggregate函数来添加一个计算前5的成员:
WITH
MEMBER [Product].[Subcategory].[Top 5] AS
Aggregate(
TopCount(
[Product].[Subcategory].[Subcategory].Members,
5,
([Measures].[Reseller Sales Amount])
),
([Measures].CurrentMember)
)
SELECT
{
([Measures].[Reseller Sales Amount]),
([Measures].[Reseller Transaction Count]),
([Measures].[Reseller Order Count])
} ON COLUMNS,
TopCount(
[Product].[Subcategory].[Subcategory].Members,
5,
([Measures].[Reseller Sales Amount])
)
+
{
([Product].[Subcategory].[Top 5]),
([Product].[Subcategory].[All Products])
} ON ROWS
FROM [Step-by-Step]

计算成员 [Product].[Subcategory].[Top 5] 在 Reseller Order Count 这一列上反映出来的度量值就是我们所期望的 non-additive 半累加度量值。因为上面我们提到过 Reseller Order Count 在Cube设计之初它是通过 Distinct Count 来统计出来 Order 的数量的。而对于累加的 Reseller Sales Amount 和 Reseller Transaction Count 度量值来说,它之前怎么设计的,在 Aggregate 中也就怎么如实给反映出来。
如果改用 SUM 函数会发现 Reseller Order Count 的数量增多了,那时因为没有去掉重复的 Order,直接给 SUM 了。

在这里要强调的是这几个例子并不是要说明我们应该在任何时候在MDX中都使用 Aggregate 函数而避免使用 Sum 函数。而应该是,在只需要使用 Sum 函数的时候使用 Sum 函数,如果需要基于度量值在设计之初的定义时那么就可以再使用 Aggregate 函数。
计算平均值的 AVG 函数
Avg( {Set} [, Expression])
语法和 Sum 或者 Aggregate 很类似,指定的 SET 集合中的每一个元组参入平均值的计算,所使用的度量值可以是默认的也可以是表达式中提供的,所有不为空的数值将会被计算并返回一个平均值。
先看 2003年各个月的情况
SELECT
{([Measures].[Reseller Sales Amount])} ON COLUMNS,
{
[Date].[Calendar].[Month].[January 2003]:[Date].[Calendar].[Month].[December 2003]
} ON ROWS
FROM [Step-by-Step]

下面的这个例子根据 Calendar Year 求 Reseller Sales 的平均值:
WITH MEMBER [Date].[Calendar].[CY 2003 Monthly Average]
AS
Avg(
{
[Date].[Calendar].[Month].[January 2003]:[Date].[Calendar].[Month].[December 2003]
},
([Measures].CurrentMember)
)
SELECT
{([Measures].[Reseller Sales Amount])} ON COLUMNS,
{[Date].[Calendar].[CY 2003 Monthly Average]}
+
{
[Date].[Calendar].[Month].[January 2003]:[Date].[Calendar].[Month].[December 2003]
} ON ROWS
FROM [Step-by-Step]

也可以根据季度来求平均值:
WITH
MEMBER [Date].[Calendar].[CY 2003 Quarterly Avg Reseller Sales] AS
Avg(
{
[Date].[Calendar].[Calendar Quarter].[Q1 CY 2003]:
[Date].[Calendar].[Calendar Quarter].[Q4 CY 2003]
},
[Measures].CurrentMember
)
MEMBER [Date].[Calendar].[CY 2003 Monthly Avg Reseller Sales] AS
Avg(
{
[Date].[Calendar].[Month].[January 2003]:
[Date].[Calendar].[Month].[December 2003]
},
[Measures].CurrentMember
)
SELECT
{([Measures].[Reseller Sales Amount])} ON COLUMNS,
{
([Date].[Calendar].[CY 2003 Monthly Avg Reseller Sales]),
([Date].[Calendar].[CY 2003 Quarterly Avg Reseller Sales])
} +
Hierarchize(
{
[Date].[Calendar].[Month].[January 2003]:
[Date].[Calendar].[Month].[December 2003]
} +
{
[Date].[Calendar].[Calendar Quarter].[Q1 CY 2003]:
[Date].[Calendar].[Calendar Quarter].[Q4 CY 2003]
}
) ON ROWS
FROM [Step-by-Step]

平均值和表达式
先看下面的这个例子,在这幅图事实表中的 6 条交易数据,有3条是2003年的,另外3条是2004的。

如果基于这个事实表来求 Reseller Sales Amount 的平均值的话,那么计算的结果就应该把所有的值加起来然后除以 6 得到一个 150 的平均值。
如果在 MDX 中来求这个平均值的话,首先需要定义一个集合 SET。我们假设这个集合是由 CY 2003 和 CY 2004 来组成,那么我们 AVG 的函数将取得 CY 2003 的 300 和 CY 2004 的600 然后除以 2 得到一个平均值,结果是 450。
那么这两个平均值的结果就不同了,一个是 150 一个是 450。事实上两者都没有错,因为它们表示的是不同的含义。因为第一种是基于业务领域的问题:“Reseller Sales Amount 的平均值是多少?” 而第二个逻辑则表达的是 “Reseller Sales Amount 的年平均值是多少?”
基于业务领域的平均值在关系型数据库中是一种典型的平均值计算方式,多维数据集数据库中也可以像这样来计算平均值但是需要借用到表达式并 Count 度量值而不是 Avg 函数。
SELECT
{
([Measures].[Reseller Sales Amount]),
([Measures].[Reseller Order Count])
} ON COLUMNS,
{
[Date].[Calendar Year].[CY 2001]:[Date].[Calendar Year].[CY 2004]
} ON ROWS
FROM [Step-by-Step]
先取到 CY 2001 年 到 2004年间的 Reseller Sales Amount 和 Reseller Order Count 的数据。

为了查询在这四年中月份的平均 Reseller Sales Amount 是多少使用到了 AVG 函数。
WITH
MEMBER [Measures].[Monthly Avg Reseller Sales Amount] AS
Avg(
EXISTING [Date].[Calendar].[Month].Members,
[Measures].[Reseller Sales Amount]
)
SELECT
{
([Measures].[Reseller Sales Amount]),
([Measures].[Reseller Order Count]),
([Measures].[Monthly Avg Reseller Sales Amount])
} ON COLUMNS,
{
[Date].[Calendar Year].[CY 2001]:[Date].[Calendar Year].[CY 2004]
} ON ROWS
FROM [Step-by-Step]
可以看到每一年的月平均销售额都不一样 -

在计算成员中,使用到了EXISTING 关键字就可以使得 SET 集合中的月使用了当前上下文环境,即 CY 2001 - CY 2004 的年成员。表达式中的 [Measures].[Reseller Sales Amount] 度量值将由集合中每一个月成员决定并且聚集求得平均值返回。 如果不加上 EXISTING 关键字,那么就没有上下文环境了,即表示的是所有月份的 Reseller Sales Amount 的平均值。
在表达式中使用 SET 集合时 SET 集合不会被当前单元格的上下文所影响,这样一来分析服务中的 Auto Exists 机制就无法应用。因此使用 EXISTING 关键字可以强制在计算成员表达式中的 SET 使用当前上下文环境。
在我的 这一篇笔记 中详细解释了 EXISTING 关键字的作用。
上面的这个查询中 2003 年的平均额度要比 2004年的要高,是不是因为在 2003 年中订单中的平均销售额要更高一些呢,下面是对 Order item level 的平均值计算。
WITH
MEMBER [Measures].[Average Reseller Sales Amount] AS
([Measures].[Reseller Sales Amount]) / ([Measures].[Reseller Transaction Count])
,FORMAT_STRING="Currency"
MEMBER [Measures].[Monthly Avg Reseller Sales Amount] AS
Avg(
EXISTING [Date].[Calendar].[Month].Members,
[Measures].[Reseller Sales Amount]
)
SELECT
{
([Measures].[Reseller Sales Amount]),
([Measures].[Reseller Order Count]),
([Measures].[Reseller Transaction Count]),
([Measures].[Monthly Avg Reseller Sales Amount]),
([Average Reseller Sales Amount])
} ON COLUMNS,
{
[Date].[Calendar Year].[CY 2001]:
[Date].[Calendar Year].[CY 2004]
} ON ROWS
FROM [Step-by-Step]
查询的结果显示了2004年订单中的平均销售额要比 2003 年的要高一些。

更多 BI 文章请参看 BI 系列随笔列表 (SSIS, SSRS, SSAS, MDX, SQL Server) 如果觉得这篇文章看了对您有帮助,请帮助推荐,以方便他人在 BIWORK 博客推荐栏中快速看到这些文章。
MDX Step by Step 读书笔记(七) - Performing Aggregation 聚合函数之 Sum, Aggregate, Avg的更多相关文章
- MDX Step by Step 读书笔记(七) - Performing Aggregation 聚合函数之 Max, Min, Count , DistinctCount 以及其它 TopCount, Generate
MDX 中最大值和最小值 MDX 中最大值和最小值函数的语法和之前看到的 Sum 以及 Aggregate 等聚合函数基本上是一样的: Max( {Set} [, Expression]) Min( ...
- 《利用python进行数据分析》读书笔记--第九章 数据聚合与分组运算(一)
http://www.cnblogs.com/batteryhp/p/5046450.html 对数据进行分组并对各组应用一个函数,是数据分析的重要环节.数据准备好之后,通常的任务就是计算分组统计或生 ...
- Machine Learning for hackers读书笔记(七)优化:密码破译
#凯撒密码:将每一个字母替换为字母表中下一位字母,比如a变成b. english.letters <- c('a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i' ...
- 【锋利的Jquery】读书笔记七
第七章 jquery插件 管理cookie的插件--cookie jquery插件太多没什么好讲的,百度太多 说以下 cookie插件 <!DOCTYPE html> <html& ...
- Android驱动开发读书笔记七
第七章 (一)创建设备文件 1.使用cdev_init函数初始化cdec 描述设备文件需要一个cdev结构体,代码如下: struct cdev{ struct kobject kobj; struc ...
- 《CLR.via.C#第三版》第二部分第13章节 接口 读书笔记(七)
这章的书写感觉很普通,是些基础的认知知识. 其中一点的重要认知,泛型接口的好处(其实也是使用泛型的好处之一):编译时类型安全&处理值类型时减少装箱. 再说点书上没有的.本来这些知识我打算另外分 ...
- 深入理解linux网络技术内幕读书笔记(七)--组件初始化的内核基础架构
Table of Contents 1 引导期间的内核选项 2 注册关键字 3 模块初始化代码 引导期间的内核选项 linux运行用户把内核配置选项传给引导记录,然后引导记录再把选项传给内核. 在引导 ...
- Spring揭秘 读书笔记 七 BeanFactory的启动分析
首先,先看我自己画的BeanFactory启动时的时序图. 第一次接触时序图,可能有些地方画的不是很符合时序图的规则,大家只关注调用顺序即可. public static void main(Stri ...
- how tomcat works读书笔记 七 日志记录器
大家可以松一口气了,这个组件比较简单,这一节和前面几节想比,也简单的多. Logger接口 Tomcat中的日志记录器都必须实现org.apache.catalina.Logger接口. packag ...
随机推荐
- 【C语言】字节对齐(内存对齐)
数据对齐 1. 对齐原则: [原则1]数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员的对齐按照#pragma p ...
- android adb命令 抓取系统各种 log
getLog.bat: adb root adb remount adb wait-for-device adb logcat -v time > C:\log.txt 在Android中不同的 ...
- day9--队列queue
queue队列 Queue是python标准库中的线程安全的队列(FIFO)实现,提供了一个适用于多线程编程的先进先出的数据结构,即队列,用来在生产者和消费者线程之间的信息传递.一个线程放入数据,另外 ...
- [转]数据类型和Json格式
作者: 阮一峰 日期: 2009年5月30日 1. 前几天,我才知道有一种简化的数据交换格式,叫做yaml. 我翻了一遍它的文档,看懂的地方不多,但是有一句话令我茅塞顿开. 它说,从结构上看,所有的数 ...
- 6-20 Ideal Path uva1599
第一个bfs很快 但是我第一次做还用了结构体 这题完全不需要 反而导致了代码非常乱 输入: 一开始我是用m二维数组储存颜色 vector path来储存路径 但是二维数组的下标是不够用的 ...
- Scrapy爬虫笔记 - 爬取知乎
cookie是一种本地存储机制,cookie是存储在本地的 session其实就是将用户信息用户名.密码等)加密成一串字符串,返回给浏览器,以后浏览器每次请求都带着这个sessionId 状态码一般是 ...
- Linux 运行Python文件,不因终端关闭而终止运行
在Linux服务器运行py文件时,有时会因为终端窗口的关闭而结束py文件的执行,这时候使用下面的命令运行py文件: $nohup python filename.py & 命令解释: nohu ...
- flask源码剖析
这段时间想重新写个自己的博客系统,又正好在看一些框架源码,然后就想要不顺便写个小框架吧,既然想写框架,要不再顺便写个orm吧,再写个小的异步Server吧..事实证明饭要一口一口吃 先梳理一下flas ...
- 项目冲刺Fifth
Fifth Sprint 1.各个成员今日完成的任务 蔡振翼:编写博客,了解php 谢孟轩:无 林凯:优化登录判断逻辑,熟悉相关php及mysql数据库技术的使用 肖志豪:帮助组员 吴文清:实现管理员 ...
- Codeforces.914D.Bash and a Tough Math Puzzle(线段树)
题目链接 \(Description\) 给定一个序列,两种操作:一是修改一个点的值:二是给一个区间\([l,r]\),问能否只修改一个数使得区间gcd为\(x\). \(Solution\) 想到能 ...