python接口自动化测试十七:使用bs4框架进行简单的爬虫
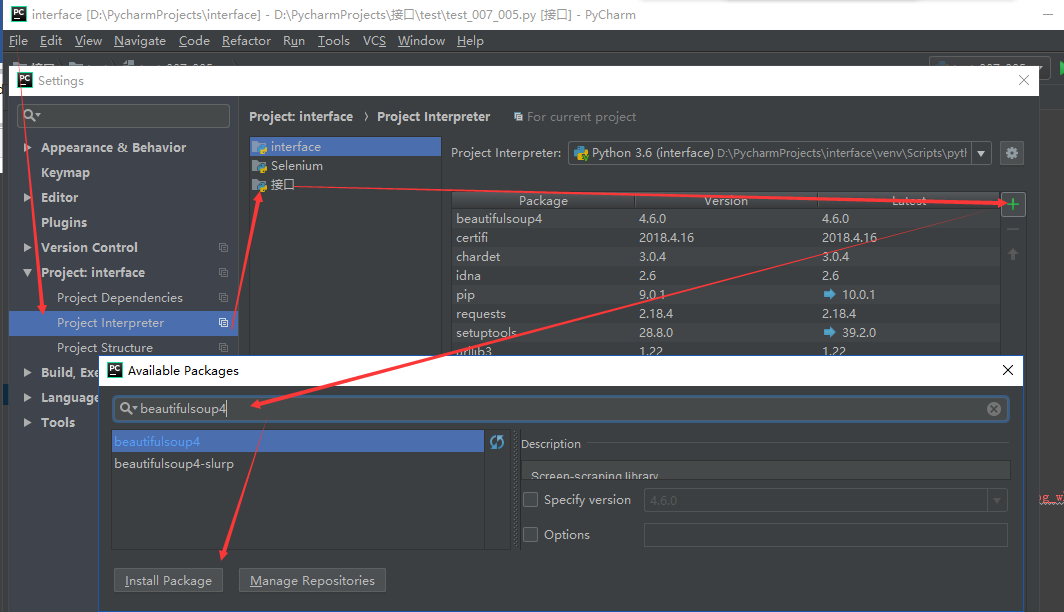
安装:beautifulsoup4
from
bs4 import BeautifulSoup
yoyo = open('yoyo.html', 'r') # 以读的方式打开“yoyo.html”文件
# print(yoyo.read()) # 此方法打开的是一个字符串,内容没有层级结构
# yoyo.close()
soup
= BeautifulSoup(yoyo, 'html.parser') # 此时打印出来的效果与.read的一致
# print(soup.prettify()) # 此时打印出来为有层级的html格式
# 通过soup对象,去找tag标签
head
= soup.head
print(head) # <head><title>yoyo
ketang</title></head>
# 当有多个标签重名的时候,会从上往下找,找到第一个后就结束,不再往下继续找
# 通过soup对象,去找p标签
p = soup.p
print(p) # <p
class="title"><b>yoyoketang</b></p>
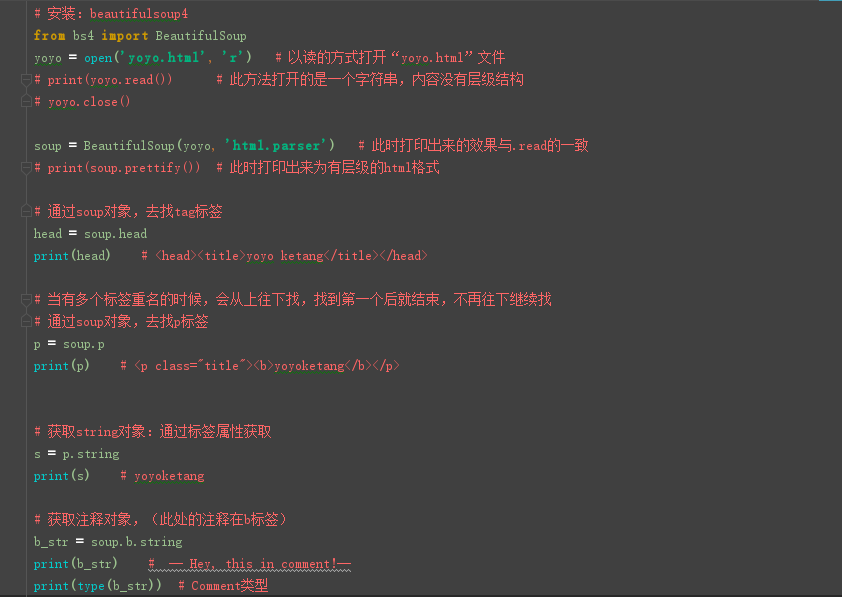
# 获取string对象:通过标签属性获取
s = p.string
print(s) # yoyoketang
# 获取注释对象,(此处的注释在b标签)
b_str
= soup.b.string
print(b_str) #
-- Hey, this in comment!--
print(type(b_str)) # Comment类型
- # 标签属性
from bs4 import BeautifulSoup
yoyo = open('yoyo.html', 'r') # 以读的方式打开“yoyo.html”文件
# print(yoyo.read()) # 此方法打开的是一个字符串,内容没有层级结构
# yoyo.close()- soup = BeautifulSoup(yoyo, 'html.parser')
- p = soup.p # p 标签
print(p) # <p class="title"><b>yoyoketang</b></p>
# 获取标签属性
value = p.attrs['class'] # tag对象,可以当成字典取值
print(value) # ['title'] list属性- # calss属性有多重属性,返回的值是list
# class="clearfix sdk 十分广泛广泛的
# value = p.attrs['class']
# print(value) # ['clearfix', 'sdk', '十分广泛广泛的']

- # 查找所有文本
from bs4 import BeautifulSoup
yoyo = open('yoyo.html', 'r') # 以读的方式打开“yoyo.html”文件
# print(yoyo.read()) # 此方法打开的是一个字符串,内容没有层级结构
# yoyo.close()- soup = BeautifulSoup(yoyo, 'html.parser')
- # 获取body对象内容
body = soup.body
print(body)- # 只获取body里面的文本信息
get_text = body.get_text() # 获取当前标签下的,所有子孙节点的string
print(get_text)

- # 查找所有的标签对象
from bs4 import BeautifulSoup
yoyo = open('yoyo.html', 'r') # 以读的方式打开“yoyo.html”文件
# print(yoyo.read()) # 此方法打开的是一个字符串,内容没有层级结构
# yoyo.close()- soup = BeautifulSoup(yoyo, 'html.parser')
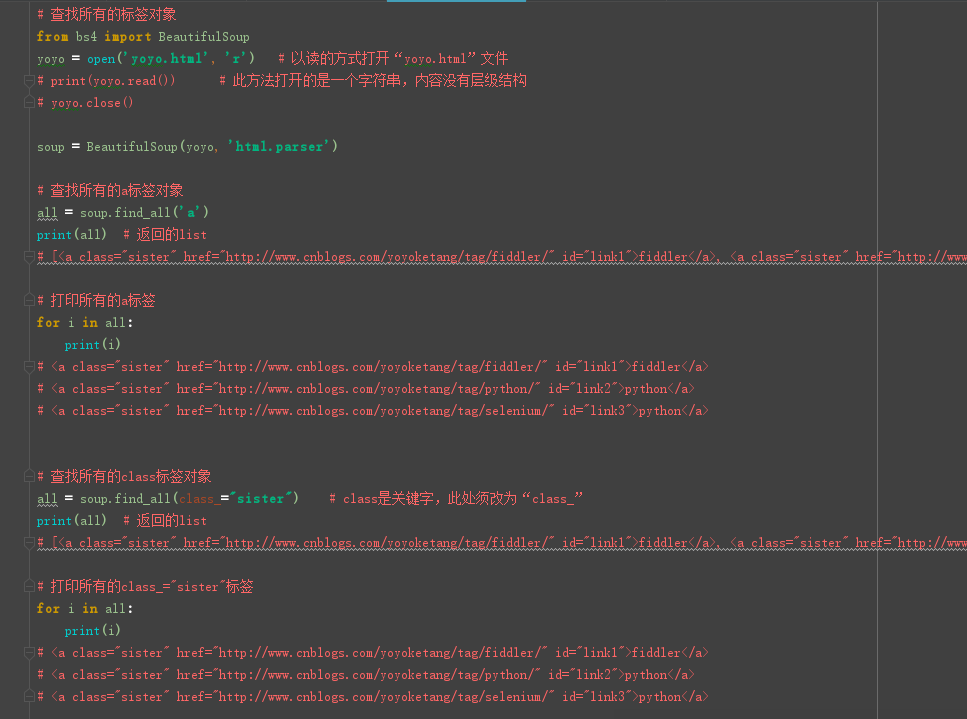
- # 查找所有的a标签对象
all = soup.find_all('a')
print(all) # 返回的list
# [<a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/fiddler/" id="link1">fiddler</a>, <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/python/" id="link2">python</a>, <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/selenium/" id="link3">python</a>]- # 打印所有的a标签
for i in all:
print(i)
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/fiddler/" id="link1">fiddler</a>
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/python/" id="link2">python</a>
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/selenium/" id="link3">python</a>- # 查找所有的class标签对象
all = soup.find_all(class_="sister") # class是关键字,此处须改为“class_”
print(all) # 返回的list
# [<a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/fiddler/" id="link1">fiddler</a>, <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/python/" id="link2">python</a>, <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/selenium/" id="link3">python</a>]- # 打印所有的class_="sister"标签
for i in all:
print(i)
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/fiddler/" id="link1">fiddler</a>
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/python/" id="link2">python</a>
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/selenium/" id="link3">python</a>
python接口自动化测试十七:使用bs4框架进行简单的爬虫的更多相关文章
- python接口自动化测试二十七:密码MD5加密 ''' MD5加密 ''' # 由于MD5模块在python3中被移除 # 在python3中使用hashlib模块进行md5操作 import hashlib # 待加密信息 str = 'asdas89799,.//plrmf' # 创建md5对象 hl = hashlib.md5() # Tips # 此处必须声明encode # 若写法为
python接口自动化测试二十七:密码MD5加密 ''' MD5加密 '''# 由于MD5模块在python3中被移除# 在python3中使用hashlib模块进行md5操作import has ...
- Python接口自动化测试框架实战 从设计到开发
第1章 课程介绍(不要错过)本章主要讲解课程的详细安排.课程学习要求.课程面向用户等,让大家很直观的对课程有整体认知! 第2章 接口测试工具Fiddler的运用本章重点讲解如何抓app\web的htt ...
- 基于Python接口自动化测试框架+数据与代码分离(进阶篇)附源码
引言 在上一篇<基于Python接口自动化测试框架(初级篇)附源码>讲过了接口自动化测试框架的搭建,最核心的模块功能就是测试数据库初始化,再来看看之前的框架结构: 可以看出testcase ...
- python接口自动化测试七:获取登录的Cookies
python接口自动化测试七:获取登录的Cookies,并关联到下一个请求 获取登录的cookies:loginCookies = r.cookies 把获取到的cookies传入请求:cooki ...
- Python接口自动化测试框架: pytest+allure+jsonpath+requests+excel实现的接口自动化测试框架(学习成果)
废话 最近在自己学习接口自动化测试,这里也算是完成一个小的成果,欢迎大家交流指出不合适的地方,源码在文末 问题 整体代码结构优化未实现,导致最终测试时间变长,其他工具单接口测试只需要39ms,该框架中 ...
- python接口自动化测试框架实现之字符串插入变量(字符串参数化)
问题: 在做接口自动化测试的时候,请求报文是json串,但是根据项目规则必须转换成字符串,然后在开头拼接“data=” 接口中很多入参值需要进行参数化. 解决方案: 1.Python并没有对在字符串中 ...
- 基于Python接口自动化测试框架(初级篇)附源码
引言 很多人都知道,目前市场上很多自动化测试工具,比如:Jmeter,Postman,TestLink等,还有一些自动化测试平台,那为啥还要开发接口自动化测试框架呢?相同之处就不说了,先说一下工具的局 ...
- 记录python接口自动化测试--简单总结一下学习过程(第十目)
至此,从excel文件中循环读取接口到把测试结果写进excel,一个简易的接口自动化测试框架就完成了.大概花了1周的时间,利用下班和周末的时间来理顺思路.编写调试代码,当然现在也还有很多不足,例如没有 ...
- Python接口自动化测试概念以及意义
接口定义: 接口普遍有两种意思,一种是API(Application Program Interface),应用编程接口,它是一组定义.程序及协议的集合,通过API接口实现计算机软件之间的相互通信.而 ...
随机推荐
- GoLang基础数据类型-切片(slice)详解
GoLang基础数据类型-切片(slice)详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 数组的长度在定义之后无法再次修改:数组是值类型,每次传递都将产生一份副本.显然这种数 ...
- 面向对象【day07】:类的属性(五)
本节内容 概述 公有属性 一.概述 前面我们讲了类的私有属性,现在我们来说说类的公有属性,这边很容易被人弄混淆,有人觉的,在__init__()构造方法中,除了私有属性,其他的都是公有属性了,其实这是 ...
- BootStrap行内编辑
Bootstrap行内编辑,这里下载了一个X-Editable的插件,在Nuget里面就可以搜到. 引用的js和css大致如下: @*.Jquery组件引用*@ <script src=&quo ...
- mysql命令备份和还原
1.导出整个数据库 mysqldump -u用户名 -p密码 数据库名 > 导出的文件名 C:\Users\jack> mysqldump -uroot -pmysql sva_rec ...
- 任意两点间的最短路问题(Floyd-Warshall算法)
#define _CRT_SECURE_NO_WARNINGS /* 7 10 0 1 5 0 2 2 1 2 4 1 3 2 2 3 6 2 4 10 3 5 1 4 5 3 4 6 5 5 6 9 ...
- .Net进阶系列(14)-异步多线程(async和await)(被替换)
1. 方法名前只有async,但是方法中Task实例前没有await关键字,该方法和普通方法没有什么区别,但是会报一个警告. #region 情况一 /// <summary> /// ...
- jQuery 选择城市,显示对应的即时时区时间
因客户需要,我们CRM系统中,jQuery 弄个时区插件 如图: HTML: <div id="cityDate"> <i class="P_arrow ...
- .NET面试题系列(十三)Lucene底层原理
索引原理 全文检索技术由来已久,绝大多数都基于倒排索引来做,曾经也有过一些其他方案如文件指纹.倒排索引,顾名思义,它相反于一篇文章包含了哪些词,它从词出发,记载了这个词在哪些文档中出现过,由两部分组成 ...
- .NET 单点登录开源项目
1. https://www.apereo.org/cas/client-integration 2.源码下载 https://wiki.jasig.org/display/CASC/.Net+Cas ...
- C# print2flash3文件转化
1.下载print2flash3 并且安装print2flash3 2.转换工具类 (1)需要导入using Print2Flash3; 这个程序集 using System; using Syste ...