python 全栈开发,Day32(知识回顾,网络编程基础)
一、知识回顾
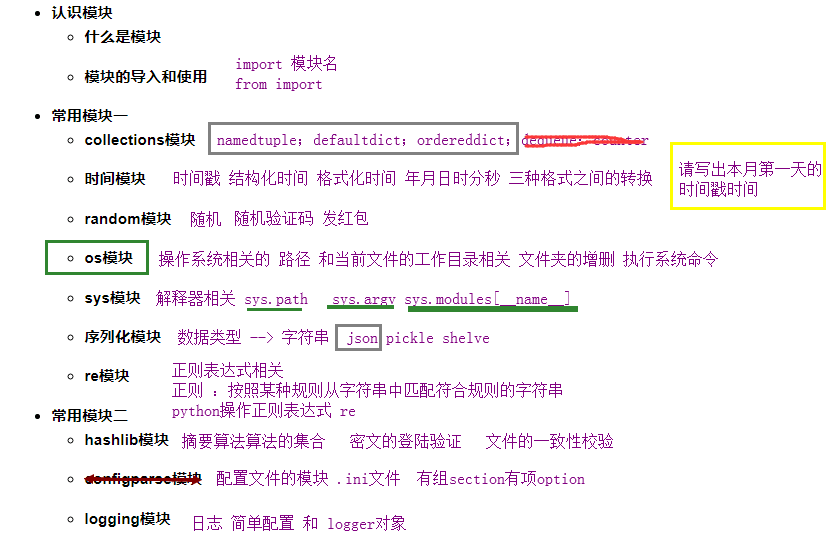
正则模块
正则表达式
元字符 :
. 匹配除了回车以外的所有字符
\w 数字字母下划线
\d 数字
\n \s \t 回车 空格 和 tab
^ 必须出现在一个正则表达式的最开始,匹配开头
$ 必须出现在一个正则表达式的最后,匹配结尾
| 或
a|b 要么取左边的要么取右边的
()|() 分组中的或 一定是长的在前面 短的在后面
[] 在同一个位置上可能出现的所有字符都放在组里
[^] 在同一个位置上不能出现的所有字符都放在组里
() 对于一整个组做量词约束 ; python 分组优先
量词 :
* 0次或多次
+ 1次或多次
? 0次或1次
{} 具体的 {n},{n,m},{n,}
问号的用法
惰性匹配 : 量词+? 表示使用惰性匹配
分组优先 findall split ;取消分组优先 (?:。。。)
分组命名 (?P<name>...)
匹配整数
import re
ret=re.findall(r"\d+","1-2*(60+(-40.35/5)-(-4*3))")
print(ret)
执行输出:
['1', '2', '60', '40', '35', '5', '4', '3']
结果是不对的,因为它把小数也拆分了,得到['40','35']
有的时候 不想要的内容需要被匹配出来
你不想要的东西包含着你想要的东西
匹配小数
import re
ret=re.findall(r"-?\d+\.\d*","1-2*(60+(-40.35/5)-(-4*3))")
print(ret)
执行输出: ['-40.35']
匹配小数或者整数
import re
ret=re.findall(r"-?\d+\.\d*|-?\d+","1-2*(60+(-40.35/5)-(-4*3))")
print(ret)
执行输出:
['1', '-2', '60', '-40.35', '5', '-4', '3']
加括号,优先匹配数字
['1', '-2', '60', '', '5', '-4', '3']
执行输出:
['1', '-2', '60', '', '5', '-4', '3']
删除空格
import re
ret=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))")
ret.remove('')
print(ret)
执行输出:
['1', '-2', '60', '5', '-4', '3']
数字匹配
1、 匹配一段文本中的每行的邮箱
http://blog.csdn.net/make164492212/article/details/51656638 2、 匹配一段文本中的每行的时间字符串,比如:‘1990-07-12’; 分别取出1年的12个月(^(0?[1-9]|1[0-2])$)、
一个月的31天:^((0?[1-9])|((1|2)[0-9])|30|31)$ 3、 匹配qq号。(腾讯QQ号从10000开始) [1,9][0,9]{4,} 4、 匹配一个浮点数。 ^(-?\d+)(\.\d+)?$ 或者 -?\d+\.?\d* 5、 匹配汉字。 ^[\u4e00-\u9fa5]{0,}$ 或者.. 6、 匹配出所有整数
爬虫练习
先看一下,爬虫的过程
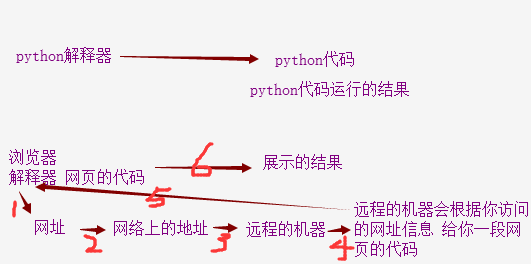
https://movie.douban.com/top250
豆瓣电影 Top 250
import requests import re
import json def getPage(url): response=requests.get(url)
return response.text def parsePage(s): com=re.compile('<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',re.S) ret=com.finditer(s)
for i in ret:
yield {
"id":i.group("id"),
"title":i.group("title"),
"rating_num":i.group("rating_num"),
"comment_num":i.group("comment_num"),
} def main(num): url='https://movie.douban.com/top250?start=%s&filter='%num
response_html=getPage(url)
ret=parsePage(response_html)
print(ret)
f=open("move_info7","a",encoding="utf8") for obj in ret:
print(obj)
data=json.dumps(obj,ensure_ascii=False)
f.write(data+"\n") if __name__ == '__main__':
count=0
for i in range(10):
main(count)
count+=25
import re
import json
from urllib.request import urlopen def getPage(url):
response = urlopen(url)
return response.read().decode('utf-8') def parsePage(s):
com = re.compile(
'<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>', re.S) ret = com.finditer(s)
for i in ret:
yield {
"id": i.group("id"),
"title": i.group("title"),
"rating_num": i.group("rating_num"),
"comment_num": i.group("comment_num"),
} def main(num):
url = 'https://movie.douban.com/top250?start=%s&filter=' % num
response_html = getPage(url)
ret = parsePage(response_html)
print(ret)
f = open("move_info7", "a", encoding="utf8") for obj in ret:
print(obj)
data = str(obj)
f.write(data + "\n")
f.close() count = 0
for i in range(10):
main(count)
count += 25
简化版
这一段是为了得到这一段,是为了得到id,title,rating_num,comment_num
('<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>'
https://movie.douban.com/top250?start=25&filter=
一页,有25行。所以start=25时,表示下一页。
总共有10页,调取10次,就取完了。
flags有很多可选值: re.I(IGNORECASE)忽略大小写,括号内是完整的写法
re.M(MULTILINE)多行模式,改变^和$的行为
re.S(DOTALL)点可以匹配任意字符,包括换行符
re.L(LOCALE)做本地化识别的匹配,表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境,不推荐使用
re.U(UNICODE) 使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flag
re.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释
flags
最常用的还是
re.S(DOTALL)点可以匹配任意字符,包括换行符
二、网络编程
1.楔子
你现在已经学会了写python代码,假如你写了两个python文件a.py和b.py,分别去运行,你就会发现,这两个python的文件分别运行的很好。但是如果这两个程序之间想要传递一个数据,你要怎么做呢?
这个问题以你现在的知识就可以解决了,我们可以创建一个文件,把a.py想要传递的内容写到文件中,然后b.py从这个文件中读取内容就可以了。
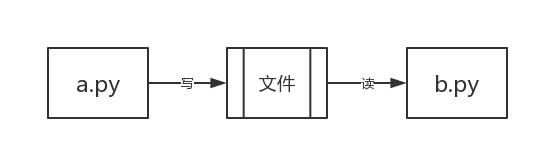
但是当你的a.py和b.py分别在不同电脑上的时候,你要怎么办呢?
类似的机制有计算机网盘,qq等等。我们可以在我们的电脑上和别人聊天,可以在自己的电脑上向网盘中上传、下载内容。这些都是两个程序在通信。
2.软件开发的架构
我们了解的涉及到两个程序之间通讯的应用大致可以分为两种:
第一种是应用类:qq、微信、网盘、优酷这一类是属于需要安装的桌面应用
第二种是web类:比如百度、知乎、博客园等使用浏览器访问就可以直接使用的应用
这些应用的本质其实都是两个程序之间的通讯。而这两个分类又对应了两个软件开发的架构~
1.C/S架构
C/S即:Client与Server ,中文意思:客户端与服务器端架构,这种架构也是从用户层面(也可以是物理层面)来划分的。
这里的客户端一般泛指客户端应用程序EXE,程序需要先安装后,才能运行在用户的电脑上,对用户的电脑操作系统环境依赖较大。
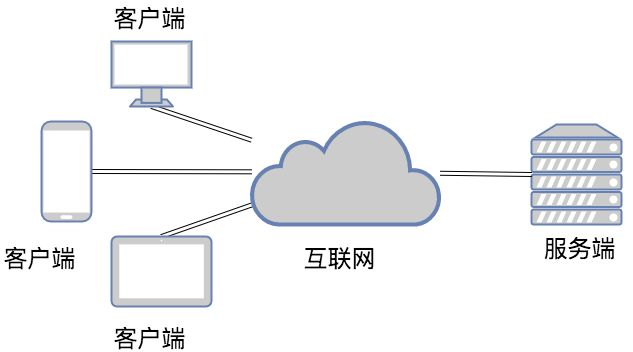
2.B/S架构
B/S即:Browser与Server,中文意思:浏览器端与服务器端架构,这种架构是从用户层面来划分的。
Browser浏览器,其实也是一种Client客户端,只是这个客户端不需要大家去安装什么应用程序,只需在浏览器上通过HTTP请求服务器端相关的资源(网页资源),客户端Browser浏览器就能进行增删改查。
3.网络基础
计算机网络的发展及基础网络概念
问题:网络到底是什么?计算机之间是如何通信的?
早期 : 联机

以太网 : 局域网与交换机

广播
主机之间“一对所有”的通讯模式,网络对其中每一台主机发出的信号都进行无条件复制并转发,所有主机都可以接收到所有信息(不管你是否需要),由于其不用路径选择,所以其网络成本可以很低廉。有线电视网就是典型的广播型网络,我们的电视机实际上是接受到所有频道的信号,但只将一个频道的信号还原成画面。在数据网络中也允许广播的存在,但其被限制在二层交换机的局域网范围内,禁止广播数据穿过路由器,防止广播数据影响大面积的主机。
ip地址与ip协议
- 规定网络地址的协议叫ip协议,它定义的地址称之为ip地址,广泛采用的v4版本即ipv4,它规定网络地址由32位2进制表示
- 范围0.0.0.0-255.255.255.255
- 一个ip地址通常写成四段十进制数,例:172.16.10.1
mac地址
head中包含的源和目标地址由来:ethernet规定接入internet的设备都必须具备网卡,发送端和接收端的地址便是指网卡的地址,即mac地址。
mac地址:每块网卡出厂时都被烧制上一个世界唯一的mac地址,长度为48位2进制,通常由12位16进制数表示(前六位是厂商编号,后六位是流水线号)
arp协议 ——查询IP地址和MAC地址的对应关系
广域网与路由器

路由器
局域网
局域网(Local Area Network,LAN)是指在某一区域内由多台计算机互联成的计算机组。一般是方圆几千米以内。局域网可以实现文件管理、应用软件共享、打印机共享、工作组内的日程安排、电子邮件和传真通信服务等功能。局域网是封闭型的,可以由办公室内的两台计算机组成,也可以由一个公司内的上千台计算机组成。
子网掩码
所谓”子网掩码”,就是表示子网络特征的一个参数。它在形式上等同于IP地址,也是一个32位二进制数字,它的网络部分全部为1,主机部分全部为0。比如,IP地址172.16.10.1,如果已知网络部分是前24位,主机部分是后8位,那么子网络掩码就是11111111.11111111.11111111.00000000,写成十进制就是255.255.255.0。
知道”子网掩码”,我们就能判断,任意两个IP地址是否处在同一个子网络。方法是将两个IP地址与子网掩码分别进行AND运算(两个数位都为1,运算结果为1,否则为0),然后比较结果是否相同,如果是的话,就表明它们在同一个子网络中,否则就不是。
比如,已知IP地址172.16.10.1和172.16.10.2的子网掩码都是255.255.255.0,请问它们是否在同一个子网络?两者与子网掩码分别进行AND运算, 172.16.10.1:10101100.00010000.00001010.000000001
255255.255.255.0:11111111.11111111.11111111.00000000
AND运算得网络地址结果:10101100.00010000.00001010.000000001->172.16.10.0 172.16.10.2:10101100.00010000.00001010.000000010
255255.255.255.0:11111111.11111111.11111111.00000000
AND运算得网络地址结果:10101100.00010000.00001010.000000001->172.16.10.0
结果都是172.16.10.0,因此它们在同一个子网络。
例如
IP协议的作用主要有两个,一个是为每一台计算机分配IP地址,另一个是确定哪些地址在同一个子网络。
总结:
三.网络基础B/S
B/S 有什么好?
统一了所有应用的入口 手机端 为什么B/S没火起来
统一了所有应用的入口 —— 微信 C/S 架构 几乎包含了所有网络开发的架构形态
B/S 架构 也是C/S架构
B/S 架构中的client都是browser浏览器
统一了所有应用的入口 —— 趋势 django tornado flask B/S 架构软件开发 网络
底层的 网卡 mac地址
局域网
交换机 : 同一个局域网内的机器之间的交流
路由器 : 跨局域网机器之间的交流
网关ip : 跨局域网的机器之间不能直接通信,只能通过网关ip通信
为什幺有局域网:
因为IP地址不够用
全球的IP地址为0.0.0.0-255.255.255.255,它是有限的。
192.168.*.* 内网的保留字段
10.*.*.* 内网的保留字段
172.16.*.*-172.31.*.* 内网的保留字段 8位 2进制
asc码 只有 255 个
00000001 --> 1
ip地址代表了你在一个网络中的位置
是一个四位点分十进制
范围是 0.0.0.0 - 255.255.255.255
11111111.1111111.1111111.1111111
mac地址唯一的,为什么要有ip地址?
192.168.11.***
256台 0-255
192.168.***.***
256^2
192.***.***.***
256^3 子网掩码
网络地址ip和子网掩码ip做按位与运算 如果结果相同 那么说明在同一个网段内
#192.168.12.62
#11000000.10101000.00001011.00111110
#11111111.11111111.11111111.00000000
#11000000.10101000.00001011.00000000 == 192.168.0.0
#255.255.0.0 #192.168.11.94
#255.255.0.0
11000000.10101000.00001011.01011110
11111111.11111111.11111111.00000000 == 192.168.0.0
python 全栈开发,Day32(知识回顾,网络编程基础)的更多相关文章
- Python全栈开发之10、网络编程
网络编程就是如何在程序中实现两台计算机的通信,而两台计算机间的通信其实就是两个进程间的通信,进程间的通信主要通过socket(套接字)来描述ip地址(主机)和端口(进程)来实现的,因此我们学习网络编程 ...
- 巨蟒python全栈开发flask8 MongoDB回顾 前后端分离之H5&pycharm&夜神
1.MongoDB回顾 .启动 mongod - 改变data/db位置: --dbpath D:\data\db mongod --install 安装windows系统服务 mongod --re ...
- 巨蟒python全栈开发数据库攻略1:基础攻略
1.什么是数据库? 2.数据库分类 3.数据库简单介绍 4.安装数据库 5.修改root密码 6.修改字符集 7.sql介绍 8.简单sql操作
- 巨蟒python全栈开发数据库攻略2:基础攻略2
1.存储引擎表类型 2.整数类型和sql_mode 3.浮点类&字符串类型&日期类型&集合类型&枚举类型 4.数值类型补充 5.完整性约束
- Python全栈开发之目录
基础篇 Python全栈开发之1.输入输出与流程控制 Python全栈开发之2.运算符与基本数据结构 Python全栈开发之3.数据类型set补充.深浅拷贝与函数 Python全栈开发之4.内置函数. ...
- Python全栈开发【面向对象进阶】
Python全栈开发[面向对象进阶] 本节内容: isinstance(obj,cls)和issubclass(sub,super) 反射 __setattr__,__delattr__,__geta ...
- python 全栈开发,Day99(作业讲解,DRF版本,DRF分页,DRF序列化进阶)
昨日内容回顾 1. 为什么要做前后端分离? - 前后端交给不同的人来编写,职责划分明确. - API (IOS,安卓,PC,微信小程序...) - vue.js等框架编写前端时,会比之前写jQuery ...
- 学习笔记之Python全栈开发/人工智能公开课_腾讯课堂
Python全栈开发/人工智能公开课_腾讯课堂 https://ke.qq.com/course/190378 https://github.com/haoran119/ke.qq.com.pytho ...
- Python全栈开发【模块】
Python全栈开发[模块] 本节内容: 模块介绍 time random os sys json & picle shelve XML hashlib ConfigParser loggin ...
随机推荐
- Cloud9 开发环境部署
安装和部署 cloud9 云端开发环境 简介 Cloud9 是亚马逊发布的一款基于云端的开发环境. AWS Cloud9 是一种基于云的集成开发环境 (IDE),您只需要一个浏览器,即可编写.运行和调 ...
- vue使用element Transfer 穿梭框实现ajax请求数据和自定义查询
vue使用element Transfer 穿梭框实现ajax请求数据和自定义查询 基于element Transfer http://element-cn.eleme.io/#/zh-CN/comp ...
- 第三节:工厂+反射+配置文件(手写IOC)对缓存进行管理。
一. 章前小节 在前面的两个章节,我们运用依赖倒置原则,分别对 System.Web.Caching.Cache和 System.Runtime.Cacheing两类缓存进行了封装,并形成了ICach ...
- 14. Spring Boot的 thymleaf公共页抽取
5).CRUD-员工列表实验要求:1).RestfulCRUD:CRUD满足Rest风格:URI: /资源名称/资源标识 HTTP请求方式区分对资源CRUD操作 普通CRUD(uri来区分操作) ...
- Linux 文件日志筛选操作
统计查看文件以及筛选日志 1.*.log 日志文件中 统计独立ip的个数: awk '{print $1}' test.log | sort | uniq | wc -l 2.#查询访问最多的前10个 ...
- 2017CCPC秦皇岛 L题One-Dimensional Maze&&ZOJ3992【模拟】
链接:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=3992 题意: 走迷宫,一个一维字符串迷宫,由'L'.'R'组成,分别 ...
- C语言文件操作详解
C语言中没有输入输出语句,所有的输入输出功能都用 ANSI C提供的一组标准库函数来实现.文件操作标准库函数有: 文件的打开操作 fopen 打开一个文件 文件的关闭操作 fclose 关闭一个文件 ...
- Database学习 - mysql数据类型
MySQL数据类型 可以被分为3类: 1.整型,数值类型 2.日期和时间类型 3.字符串(字符)类型 整型(INT) 数据类型 大小 M(默认值) 范围(有符号) 范围(无符号) 用途 tinyint ...
- python cookbook 笔记二
去重和排序: #coding=utf-8 def dedupe(items): seen = set() for item in items: if item not in seen: yield i ...
- WinEdt 和 Sumatra 双向关联设置
(1)配置PDF Viewer,在菜单栏选Options -> Execution Modes ->PDF Viewer ->点击右侧的"Browse"按钮,在弹 ...