【Hadoop学习之十三】MapReduce案例分析五-ItemCF
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
hadoop-3.1.1
推荐系统——协同过滤(Collaborative Filtering)算法
ItemCF:基于item的协同过滤,通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐。简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品。

Co-occurrence Matrix(同现矩阵)和User Preference Vector(用户评分向量)相乘得到的这个Recommended Vector(推荐向量)
基于全量数据的统计,产生同现矩阵
·体现商品间的关联性
·每件商品都有自己对其他全部商品的关联性(每件商品的特征)
用户评分向量体现的是用户对一些商品的评分
任一商品需要:
·用户评分向量乘以基于该商品的其他商品关联值
·求和得出针对该商品的推荐向量
·排序取TopN即可
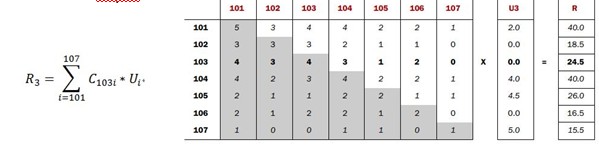
通过历史订单交易记录
计算得出每一件商品相对其他商品同时出现在同一订单的次数
·so:每件商品都有自己相对全部商品的同现列表
用户会对部分商品有过加入购物车,购买等实际操作,经过计算会得到用户对这部分商品的评分向量列表
使用用户评分向量列表中的分值:
·依次乘以每一件商品同现列表中该分值的代表物品的同现值
·求和便是该物品的推荐向量

package test.mr.itemcf; import java.util.HashMap;
import java.util.Map; import org.apache.hadoop.conf.Configuration; public class StartRun { public static void main(String[] args) {
Configuration conf = new Configuration(); conf.set("mapreduce.app-submission.corss-paltform", "true");
conf.set("mapreduce.framework.name", "local"); //所有mr的输入和输出目录定义在map集合中
Map<String, String> paths = new HashMap<String, String>();
paths.put("Step1Input", "/data/itemcf/input/");
paths.put("Step1Output", "/data/itemcf/output/step1");
paths.put("Step2Input", paths.get("Step1Output"));
paths.put("Step2Output", "/data/itemcf/output/step2");
paths.put("Step3Input", paths.get("Step2Output"));
paths.put("Step3Output", "/data/itemcf/output/step3");
paths.put("Step4Input1", paths.get("Step2Output"));
paths.put("Step4Input2", paths.get("Step3Output"));
paths.put("Step4Output", "/data/itemcf/output/step4");
paths.put("Step5Input", paths.get("Step4Output"));
paths.put("Step5Output", "/data/itemcf/output/step5");
paths.put("Step6Input", paths.get("Step5Output"));
paths.put("Step6Output", "/data/itemcf/output/step6"); Step1.run(conf, paths);
Step2.run(conf, paths);
// Step3.run(conf, paths);
// Step4.run(conf, paths);
// Step5.run(conf, paths);
// Step6.run(conf, paths);
} public static Map<String, Integer> R = new HashMap<String, Integer>();
static {
R.put("click", 1);
R.put("collect", 2);
R.put("cart", 3);
R.put("alipay", 4);
}
}
package test.mr.itemcf; import java.io.IOException;
import java.util.Map; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* 去重复
* @author root
*
*/
public class Step1 { public static boolean run(Configuration config,Map<String, String> paths){
try {
FileSystem fs =FileSystem.get(config);
Job job =Job.getInstance(config);
job.setJobName("step1");
job.setJarByClass(Step1.class);
job.setMapperClass(Step1_Mapper.class);
job.setReducerClass(Step1_Reducer.class); job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class); FileInputFormat.addInputPath(job, new Path(paths.get("Step1Input")));
Path outpath=new Path(paths.get("Step1Output"));
if(fs.exists(outpath)){
fs.delete(outpath,true);
}
FileOutputFormat.setOutputPath(job, outpath); boolean f= job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
} static class Step1_Mapper extends Mapper<LongWritable, Text, Text, NullWritable>{ protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
if(key.get()!=0){
context.write(value, NullWritable.get());
}
}
} static class Step1_Reducer extends Reducer<Text, IntWritable, Text, NullWritable>{ protected void reduce(Text key, Iterable<IntWritable> i, Context context)
throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
}
package test.mr.itemcf; import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* 按用户分组,计算所有物品出现的组合列表,得到用户对物品的喜爱度得分矩阵
u13 i160:1,
u14 i25:1,i223:1,
u16 i252:1,
u21 i266:1,
u24 i64:1,i218:1,i185:1,
u26 i276:1,i201:1,i348:1,i321:1,i136:1,
* @author root
*
*/
public class Step2 { public static boolean run(Configuration config,Map<String, String> paths){
try {
FileSystem fs =FileSystem.get(config);
Job job =Job.getInstance(config);
job.setJobName("step2");
job.setJarByClass(StartRun.class);
job.setMapperClass(Step2_Mapper.class);
job.setReducerClass(Step2_Reducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path(paths.get("Step2Input")));
Path outpath=new Path(paths.get("Step2Output"));
if(fs.exists(outpath)){
fs.delete(outpath,true);
}
FileOutputFormat.setOutputPath(job, outpath); boolean f= job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
} static class Step2_Mapper extends Mapper<LongWritable, Text, Text, Text>{ //如果使用:用户+物品,同时作为输出key,更优
//i161,u2625,click,2014/9/18 15:03
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
String[] tokens=value.toString().split(",");
String item=tokens[0];
String user=tokens[1];
String action =tokens[2];
Text k= new Text(user);
Integer rv =StartRun.R.get(action);
Text v =new Text(item+":"+ rv.intValue());
context.write(k, v);
//u2625 i161:1
}
} static class Step2_Reducer extends Reducer<Text, Text, Text, Text>{ protected void reduce(Text key, Iterable<Text> i,
Context context)
throws IOException, InterruptedException {
Map<String, Integer> r =new HashMap<String, Integer>();
//u2625
// i161:1
// i161:2
// i161:4
// i162:3
// i161:4
for(Text value :i){
String[] vs =value.toString().split(":");
String item=vs[0];
Integer action=Integer.parseInt(vs[1]);
action = ((Integer) (r.get(item)==null? 0:r.get(item))).intValue() + action;
r.put(item,action);
}
StringBuffer sb =new StringBuffer();
for(Entry<String, Integer> entry :r.entrySet() ){
sb.append(entry.getKey()+":"+entry.getValue().intValue()+",");
} context.write(key,new Text(sb.toString()));
}
}
}
package test.mr.itemcf; import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.MapWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.Logger;
/**
* 对物品组合列表进行计数,建立物品的同现矩阵
i100:i100 3
i100:i105 1
i100:i106 1
i100:i109 1
i100:i114 1
i100:i124 1
* @author root
*
*/
public class Step3 {
private final static Text K = new Text();
private final static IntWritable V = new IntWritable(1); public static boolean run(Configuration config,Map<String, String> paths){
try {
FileSystem fs =FileSystem.get(config);
Job job =Job.getInstance(config);
job.setJobName("step3");
job.setJarByClass(StartRun.class);
job.setMapperClass(Step3_Mapper.class);
job.setReducerClass(Step3_Reducer.class);
job.setCombinerClass(Step3_Reducer.class);
//
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(paths.get("Step3Input")));
Path outpath=new Path(paths.get("Step3Output"));
if(fs.exists(outpath)){
fs.delete(outpath,true);
}
FileOutputFormat.setOutputPath(job, outpath); boolean f= job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
} static class Step3_Mapper extends Mapper<LongWritable, Text, Text, IntWritable>{ protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException { //u3244 i469:1,i498:1,i154:1,i73:1,i162:1,
String[] tokens=value.toString().split("\t");
String[] items =tokens[1].split(",");
for (int i = 0; i < items.length; i++) {
String itemA = items[i].split(":")[0];
for (int j = 0; j < items.length; j++) {
String itemB = items[j].split(":")[0];
K.set(itemA+":"+itemB);
context.write(K, V);
}
} }
} static class Step3_Reducer extends Reducer<Text, IntWritable, Text, IntWritable>{ protected void reduce(Text key, Iterable<IntWritable> i,
Context context)
throws IOException, InterruptedException {
int sum =0;
for(IntWritable v :i ){
sum =sum+v.get();
}
V.set(sum);
context.write(key, V);
}
} }
package test.mr.itemcf; import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.StringTokenizer;
import java.util.regex.Pattern; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.MapWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.log4j.Logger; /**
*
* 把同现矩阵和得分矩阵相乘
* @author root
*
*/
public class Step4 { public static boolean run(Configuration config, Map<String, String> paths) {
try {
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("step4");
job.setJarByClass(StartRun.class);
job.setMapperClass(Step4_Mapper.class);
job.setReducerClass(Step4_Reducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class); // FileInputFormat.addInputPath(job, new
// Path(paths.get("Step4Input")));
FileInputFormat.setInputPaths(job,
new Path[] { new Path(paths.get("Step4Input1")),
new Path(paths.get("Step4Input2")) });
Path outpath = new Path(paths.get("Step4Output"));
if (fs.exists(outpath)) {
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath); boolean f = job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
} static class Step4_Mapper extends Mapper<LongWritable, Text, Text, Text> {
private String flag;// A同现矩阵 or B得分矩阵 //每个maptask,初始化时调用一次
protected void setup(Context context) throws IOException,
InterruptedException {
FileSplit split = (FileSplit) context.getInputSplit();
flag = split.getPath().getParent().getName();// 判断读的数据集 System.out.println(flag + "**********************");
} protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] tokens = Pattern.compile("[\t,]").split(value.toString());
if (flag.equals("step3")) {// 同现矩阵
//i100:i125 1
String[] v1 = tokens[0].split(":");
String itemID1 = v1[0];
String itemID2 = v1[1];
String num = tokens[1];
//A:B 3
//B:A 3
Text k = new Text(itemID1);// 以前一个物品为key 比如i100
Text v = new Text("A:" + itemID2 + "," + num);// A:i109,1 context.write(k, v); } else if (flag.equals("step2")) {// 用户对物品喜爱得分矩阵 //u26 i276:1,i201:1,i348:1,i321:1,i136:1,
String userID = tokens[0];
for (int i = 1; i < tokens.length; i++) {
String[] vector = tokens[i].split(":");
String itemID = vector[0];// 物品id
String pref = vector[1];// 喜爱分数 Text k = new Text(itemID); // 以物品为key 比如:i100
Text v = new Text("B:" + userID + "," + pref); // B:u401,2 context.write(k, v);
}
}
}
} static class Step4_Reducer extends Reducer<Text, Text, Text, Text> {
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// A同现矩阵 or B得分矩阵
//某一个物品,针对它和其他所有物品的同现次数,都在mapA集合中
Map<String, Integer> mapA = new HashMap<String, Integer>();// 和该物品(key中的itemID)同现的其他物品的同现集合// 。其他物品ID为map的key,同现数字为值
Map<String, Integer> mapB = new HashMap<String, Integer>();// 该物品(key中的itemID),所有用户的推荐权重分数。 //A > reduce 相同的KEY为一组
//value:2类:
//物品同现A:b:2 c:4 d:8
//评分数据B:u1:18 u2:33 u3:22
for (Text line : values) {
String val = line.toString();
if (val.startsWith("A:")) {// 表示物品同现数字
// A:i109,1
String[] kv = Pattern.compile("[\t,]").split(
val.substring(2));
try {
mapA.put(kv[0], Integer.parseInt(kv[1]));
//物品同现A:b:2 c:4 d:8
//基于 A,物品同现次数
} catch (Exception e) {
e.printStackTrace();
} } else if (val.startsWith("B:")) {
// B:u401,2
String[] kv = Pattern.compile("[\t,]").split(
val.substring(2));
//评分数据B:u1:18 u2:33 u3:22
try {
mapB.put(kv[0], Integer.parseInt(kv[1]));
} catch (Exception e) {
e.printStackTrace();
}
}
} double result = 0;
Iterator<String> iter = mapA.keySet().iterator();//同现
while (iter.hasNext()) {
String mapk = iter.next();// itemID
int num = mapA.get(mapk).intValue(); //对于A的同现次数
Iterator<String> iterb = mapB.keySet().iterator();//评分
while (iterb.hasNext()) {
String mapkb = iterb.next();// userID
int pref = mapB.get(mapkb).intValue();
result = num * pref;// 矩阵乘法相乘计算 Text k = new Text(mapkb); //用户ID为key
Text v = new Text(mapk + "," + result);//基于A物品,其他物品的同现与评分(所有用户对A物品)乘机
context.write(k, v);
}
}
}
}
}
package test.mr.itemcf; import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.StringTokenizer;
import java.util.regex.Pattern; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.MapWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.log4j.Logger; /**
*
* 把相乘之后的矩阵相加获得结果矩阵
*
* @author root
*
*/
public class Step5 {
private final static Text K = new Text();
private final static Text V = new Text(); public static boolean run(Configuration config, Map<String, String> paths) {
try {
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("step5");
job.setJarByClass(StartRun.class);
job.setMapperClass(Step5_Mapper.class);
job.setReducerClass(Step5_Reducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class); FileInputFormat
.addInputPath(job, new Path(paths.get("Step5Input")));
Path outpath = new Path(paths.get("Step5Output"));
if (fs.exists(outpath)) {
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath); boolean f = job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
} static class Step5_Mapper extends Mapper<LongWritable, Text, Text, Text> { /**
* 原封不动输出
*/
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] tokens = Pattern.compile("[\t,]").split(value.toString());
Text k = new Text(tokens[0]);// 用户为key
Text v = new Text(tokens[1] + "," + tokens[2]);
context.write(k, v);
}
} static class Step5_Reducer extends Reducer<Text, Text, Text, Text> {
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
Map<String, Double> map = new HashMap<String, Double>();// 结果 //u3 > reduce
//101, 11
//101, 12
//101, 8
//102, 12
//102, 32 for (Text line : values) {// i9,4.0
String[] tokens = line.toString().split(",");
String itemID = tokens[0];
Double score = Double.parseDouble(tokens[1]); if (map.containsKey(itemID)) {
map.put(itemID, map.get(itemID) + score);// 矩阵乘法求和计算
} else {
map.put(itemID, score);
}
} Iterator<String> iter = map.keySet().iterator();
while (iter.hasNext()) {
String itemID = iter.next();
double score = map.get(itemID);
Text v = new Text(itemID + "," + score);
context.write(key, v);
}
} }
}
package test.mr.itemcf; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
*
* 按照推荐得分降序排序,每个用户列出10个推荐物品
*
* @author root
*
*/
public class Step6 {
private final static Text K = new Text();
private final static Text V = new Text(); public static boolean run(Configuration config, Map<String, String> paths) {
try {
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("step6");
job.setJarByClass(StartRun.class);
job.setMapperClass(Step6_Mapper.class);
job.setReducerClass(Step6_Reducer.class);
job.setSortComparatorClass(NumSort.class);
job.setGroupingComparatorClass(UserGroup.class);
job.setMapOutputKeyClass(PairWritable.class);
job.setMapOutputValueClass(Text.class); FileInputFormat
.addInputPath(job, new Path(paths.get("Step6Input")));
Path outpath = new Path(paths.get("Step6Output"));
if (fs.exists(outpath)) {
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath); boolean f = job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
} static class Step6_Mapper extends Mapper<LongWritable, Text, PairWritable, Text> { protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] tokens = Pattern.compile("[\t,]").split(value.toString());
String u = tokens[0];
String item = tokens[1];
String num = tokens[2];
PairWritable k =new PairWritable();
k.setUid(u);
k.setNum(Double.parseDouble(num));
V.set(item+":"+num);
context.write(k, V); }
} static class Step6_Reducer extends Reducer<PairWritable, Text, Text, Text> {
protected void reduce(PairWritable key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
int i=0;
StringBuffer sb =new StringBuffer();
for(Text v :values){
if(i==10)
break;
sb.append(v.toString()+",");
i++;
}
K.set(key.getUid());
V.set(sb.toString());
context.write(K, V);
} } static class PairWritable implements WritableComparable<PairWritable>{ // private String itemId;
private String uid;
private double num;
public void write(DataOutput out) throws IOException {
out.writeUTF(uid);
// out.writeUTF(itemId);
out.writeDouble(num);
} public void readFields(DataInput in) throws IOException {
this.uid=in.readUTF();
// this.itemId=in.readUTF();
this.num=in.readDouble();
} public int compareTo(PairWritable o) {
int r =this.uid.compareTo(o.getUid());
if(r==0){
return Double.compare(this.num, o.getNum());
}
return r;
} public String getUid() {
return uid;
} public void setUid(String uid) {
this.uid = uid;
} public double getNum() {
return num;
} public void setNum(double num) {
this.num = num;
} } static class NumSort extends WritableComparator{
public NumSort(){
super(PairWritable.class,true);
} public int compare(WritableComparable a, WritableComparable b) {
PairWritable o1 =(PairWritable) a;
PairWritable o2 =(PairWritable) b; int r =o1.getUid().compareTo(o2.getUid());
if(r==0){
return -Double.compare(o1.getNum(), o2.getNum());
}
return r;
}
} static class UserGroup extends WritableComparator{
public UserGroup(){
super(PairWritable.class,true);
} public int compare(WritableComparable a, WritableComparable b) {
PairWritable o1 =(PairWritable) a;
PairWritable o2 =(PairWritable) b;
return o1.getUid().compareTo(o2.getUid());
}
}
}
【Hadoop学习之十三】MapReduce案例分析五-ItemCF的更多相关文章
- 【Hadoop学习之十二】MapReduce案例分析四-TF-IDF
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 概念TF-IDF(term fre ...
- 【Hadoop学习之十】MapReduce案例分析二-好友推荐
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 最应该推荐的好友TopN,如何排名 ...
- 【Hadoop学习之九】MapReduce案例分析一-天气
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 找出每个月气温最高的2天 1949 ...
- 【Hadoop学习之十一】MapReduce案例分析三-PageRank
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 什么是pagerank?算法原理- ...
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:当前页面 网站日志分析项目案例 ...
- Hadoop学习笔记—20.网站日志分析项目案例
1.1 项目来源 本次要实践的数据日志来源于国内某技术学习论坛,该论坛由某培训机构主办,汇聚了众多技术学习者,每天都有人发帖.回帖,如图1所示. 图1 项目来源网站-技术学习论坛 本次实践的目的就在于 ...
- Hadoop学习笔记—20.网站日志分析项目案例(一)项目介绍
网站日志分析项目案例(一)项目介绍:当前页面 网站日志分析项目案例(二)数据清洗:http://www.cnblogs.com/edisonchou/p/4458219.html 网站日志分析项目案例 ...
- Hadoop学习笔记—20.网站日志分析项目案例(三)统计分析
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:http://www.cnbl ...
- Hadoop学习之路(二十五)MapReduce的API使用(二)
学生成绩---增强版 数据信息 computer,huangxiaoming,85,86,41,75,93,42,85 computer,xuzheng,54,52,86,91,42 computer ...
随机推荐
- POJ2431 Expedition 贪心
正解:模拟费用流 解题报告: 先放个传送门鸭,题目大意可以点Descriptions的第二个切换成中文翻译 然后为了方便表述,这里强行改一下题意(问题是一样的只是表述不一样辣,,, 就是说现在在高速公 ...
- python脚本获取文件的创建于修改日期并计算时间差
由于在计算一个算法的运行时间的时候,需要将文件的创建日期与修改日期读取到,然后计算两者之差,在网上搜索了相关的程序之后,自己又修改了一下,把代码贴在这里,供以后查阅使用,也希望可以帮到其他人. # - ...
- Linux I/O 调度器
每个块设备或者块设备的分区,都对应有自身的请求队列, 而每个请求队列都可以选择一个I/O调度器来协调所递交的.I/O调度器的基本目的是将请求按照它们对应在块设备上的扇区号进行排列,以减少磁头的移动, ...
- MySQL 5.5 服务器变量详解(一)
autocommit={0|1} 设定MySQL事务是否自动提交,1表示立即提交,0表示需要显式提交.作用范围为全局或会话,可用于配置文件中(但在5.5.8之前的版本中不可用于配置文件),属于动态变量 ...
- 防止SQL注入的6个要点
SQL注入,就是通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令.防止SQL注入,我们可以从以下6个要点来进行: 1.永远不要信任用户的输入 ...
- RN导航栏使用
import PropTypes from 'prop-types'; import React, { Component } from 'react'; import { NavigatorIOS, ...
- 20181220 Oracle程序包基本开发逻辑
做事情,开始也许比较迷茫,也可能工具不会,也可能语言不会,但不要害怕 多去思考而不是盲目的开始工作,盲目的听从,程序开发都是不断训练自己的思维能力. 做每件事情都是有意义的,思考为什么这么做,这么做的 ...
- what's the python之函数及装饰器
what's the 函数? 函数的定义:(return是返回值,可以没有,不过没有的话就返回了None) def wrapper(参数1,参数2,*args,默认参数,**kwargs): '''注 ...
- css实现右侧固定宽度,左侧宽度自适应
https://blog.csdn.net/qq_22889599/article/details/78414040 反过来也可以:左侧宽度固定,右侧自适应.不管是左是右,反正就是一边宽度固定,一边宽 ...
- java.lang.UnsatisfiedLinkError: dlopen failed: library "libsqlite.so" not found
项目在7.0以下系统的手机上运行正常,但在7.0的手机上运行异常. 出现这个问题的原因是:从 Android 7.0 开始,Android系统将阻止应用动态链接非公开 NDK 库. 解决方法有两种 第 ...