python学习day3
目录:
1.集合set
2.计数器
3.有序字典
4.默认字典
5.可命名元组
6.队列
7.深浅拷贝
8.函数
9.lambda表达式
10.内置函数
一、集合set
set是一个无序且不重复的元素集合
class set(object):
"""
set() -> new empty set object
set(iterable) -> new set object Build an unordered collection of unique elements.
"""
def add(self, *args, **kwargs): # real signature unknown
""" 添加 """
"""
Add an element to a set. This has no effect if the element is already present.
"""
pass def clear(self, *args, **kwargs): # real signature unknown
""" Remove all elements from this set. """
pass def copy(self, *args, **kwargs): # real signature unknown
""" Return a shallow copy of a set. """
pass def difference(self, *args, **kwargs): # real signature unknown
"""
Return the difference of two or more sets as a new set. (i.e. all elements that are in this set but not the others.)
"""
pass def difference_update(self, *args, **kwargs): # real signature unknown
""" 删除当前set中的所有包含在 new set 里的元素 """
""" Remove all elements of another set from this set. """
pass def discard(self, *args, **kwargs): # real signature unknown
""" 移除元素 """
"""
Remove an element from a set if it is a member. If the element is not a member, do nothing.
"""
pass def intersection(self, *args, **kwargs): # real signature unknown
""" 取交集,新创建一个set """
"""
Return the intersection of two or more sets as a new set. (i.e. elements that are common to all of the sets.)
"""
pass def intersection_update(self, *args, **kwargs): # real signature unknown
""" 取交集,修改原来set """
""" Update a set with the intersection of itself and another. """
pass def isdisjoint(self, *args, **kwargs): # real signature unknown
""" 如果没有交集,返回true """
""" Return True if two sets have a null intersection. """
pass def issubset(self, *args, **kwargs): # real signature unknown
""" 是否是子集 """
""" Report whether another set contains this set. """
pass def issuperset(self, *args, **kwargs): # real signature unknown
""" 是否是父集 """
""" Report whether this set contains another set. """
pass def pop(self, *args, **kwargs): # real signature unknown
""" 移除 """
"""
Remove and return an arbitrary set element.
Raises KeyError if the set is empty.
"""
pass def remove(self, *args, **kwargs): # real signature unknown
""" 移除 """
"""
Remove an element from a set; it must be a member. If the element is not a member, raise a KeyError.
"""
pass def symmetric_difference(self, *args, **kwargs): # real signature unknown
""" 差集,创建新对象"""
"""
Return the symmetric difference of two sets as a new set. (i.e. all elements that are in exactly one of the sets.)
"""
pass def symmetric_difference_update(self, *args, **kwargs): # real signature unknown
""" 差集,改变原来 """
""" Update a set with the symmetric difference of itself and another. """
pass def union(self, *args, **kwargs): # real signature unknown
""" 并集 """
"""
Return the union of sets as a new set. (i.e. all elements that are in either set.)
"""
pass def update(self, *args, **kwargs): # real signature unknown
""" 更新 """
""" Update a set with the union of itself and others. """
pass def __and__(self, y): # real signature unknown; restored from __doc__
""" x.__and__(y) <==> x&y """
pass def __cmp__(self, y): # real signature unknown; restored from __doc__
""" x.__cmp__(y) <==> cmp(x,y) """
pass def __contains__(self, y): # real signature unknown; restored from __doc__
""" x.__contains__(y) <==> y in x. """
pass def __eq__(self, y): # real signature unknown; restored from __doc__
""" x.__eq__(y) <==> x==y """
pass def __getattribute__(self, name): # real signature unknown; restored from __doc__
""" x.__getattribute__('name') <==> x.name """
pass def __ge__(self, y): # real signature unknown; restored from __doc__
""" x.__ge__(y) <==> x>=y """
pass def __gt__(self, y): # real signature unknown; restored from __doc__
""" x.__gt__(y) <==> x>y """
pass def __iand__(self, y): # real signature unknown; restored from __doc__
""" x.__iand__(y) <==> x&=y """
pass def __init__(self, seq=()): # known special case of set.__init__
"""
set() -> new empty set object
set(iterable) -> new set object Build an unordered collection of unique elements.
# (copied from class doc)
"""
pass def __ior__(self, y): # real signature unknown; restored from __doc__
""" x.__ior__(y) <==> x|=y """
pass def __isub__(self, y): # real signature unknown; restored from __doc__
""" x.__isub__(y) <==> x-=y """
pass def __iter__(self): # real signature unknown; restored from __doc__
""" x.__iter__() <==> iter(x) """
pass def __ixor__(self, y): # real signature unknown; restored from __doc__
""" x.__ixor__(y) <==> x^=y """
pass def __len__(self): # real signature unknown; restored from __doc__
""" x.__len__() <==> len(x) """
pass def __le__(self, y): # real signature unknown; restored from __doc__
""" x.__le__(y) <==> x<=y """
pass def __lt__(self, y): # real signature unknown; restored from __doc__
""" x.__lt__(y) <==> x<y """
pass @staticmethod # known case of __new__
def __new__(S, *more): # real signature unknown; restored from __doc__
""" T.__new__(S, ...) -> a new object with type S, a subtype of T """
pass def __ne__(self, y): # real signature unknown; restored from __doc__
""" x.__ne__(y) <==> x!=y """
pass def __or__(self, y): # real signature unknown; restored from __doc__
""" x.__or__(y) <==> x|y """
pass def __rand__(self, y): # real signature unknown; restored from __doc__
""" x.__rand__(y) <==> y&x """
pass def __reduce__(self, *args, **kwargs): # real signature unknown
""" Return state information for pickling. """
pass def __repr__(self): # real signature unknown; restored from __doc__
""" x.__repr__() <==> repr(x) """
pass def __ror__(self, y): # real signature unknown; restored from __doc__
""" x.__ror__(y) <==> y|x """
pass def __rsub__(self, y): # real signature unknown; restored from __doc__
""" x.__rsub__(y) <==> y-x """
pass def __rxor__(self, y): # real signature unknown; restored from __doc__
""" x.__rxor__(y) <==> y^x """
pass def __sizeof__(self): # real signature unknown; restored from __doc__
""" S.__sizeof__() -> size of S in memory, in bytes """
pass def __sub__(self, y): # real signature unknown; restored from __doc__
""" x.__sub__(y) <==> x-y """
pass def __xor__(self, y): # real signature unknown; restored from __doc__
""" x.__xor__(y) <==> x^y """
pass __hash__ = None set
set源码
二、计数器(counter)
Counter是对字典类型的补充,用于追踪值出现的次数
ps:具备字典的所有功能+自己的功能
c = Counter('abcdeabcdabcaba')
print c
输出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
########################################################################
### Counter
######################################################################## class Counter(dict):
'''Dict subclass for counting hashable items. Sometimes called a bag
or multiset. Elements are stored as dictionary keys and their counts
are stored as dictionary values. >>> c = Counter('abcdeabcdabcaba') # count elements from a string >>> c.most_common(3) # three most common elements
[('a', 5), ('b', 4), ('c', 3)]
>>> sorted(c) # list all unique elements
['a', 'b', 'c', 'd', 'e']
>>> ''.join(sorted(c.elements())) # list elements with repetitions
'aaaaabbbbcccdde'
>>> sum(c.values()) # total of all counts >>> c['a'] # count of letter 'a'
>>> for elem in 'shazam': # update counts from an iterable
... c[elem] += 1 # by adding 1 to each element's count
>>> c['a'] # now there are seven 'a'
>>> del c['b'] # remove all 'b'
>>> c['b'] # now there are zero 'b' >>> d = Counter('simsalabim') # make another counter
>>> c.update(d) # add in the second counter
>>> c['a'] # now there are nine 'a' >>> c.clear() # empty the counter
>>> c
Counter() Note: If a count is set to zero or reduced to zero, it will remain
in the counter until the entry is deleted or the counter is cleared: >>> c = Counter('aaabbc')
>>> c['b'] -= 2 # reduce the count of 'b' by two
>>> c.most_common() # 'b' is still in, but its count is zero
[('a', 3), ('c', 1), ('b', 0)] '''
# References:
# http://en.wikipedia.org/wiki/Multiset
# http://www.gnu.org/software/smalltalk/manual-base/html_node/Bag.html
# http://www.demo2s.com/Tutorial/Cpp/0380__set-multiset/Catalog0380__set-multiset.htm
# http://code.activestate.com/recipes/259174/
# Knuth, TAOCP Vol. II section 4.6.3 def __init__(self, iterable=None, **kwds):
'''Create a new, empty Counter object. And if given, count elements
from an input iterable. Or, initialize the count from another mapping
of elements to their counts. >>> c = Counter() # a new, empty counter
>>> c = Counter('gallahad') # a new counter from an iterable
>>> c = Counter({'a': 4, 'b': 2}) # a new counter from a mapping
>>> c = Counter(a=4, b=2) # a new counter from keyword args '''
super(Counter, self).__init__()
self.update(iterable, **kwds) def __missing__(self, key):
""" 对于不存在的元素,返回计数器为0 """
'The count of elements not in the Counter is zero.'
# Needed so that self[missing_item] does not raise KeyError
return 0 def most_common(self, n=None):
""" 数量大于等n的所有元素和计数器 """
'''List the n most common elements and their counts from the most
common to the least. If n is None, then list all element counts. >>> Counter('abcdeabcdabcaba').most_common(3)
[('a', 5), ('b', 4), ('c', 3)] '''
# Emulate Bag.sortedByCount from Smalltalk
if n is None:
return sorted(self.iteritems(), key=_itemgetter(1), reverse=True)
return _heapq.nlargest(n, self.iteritems(), key=_itemgetter(1)) def elements(self):
""" 计数器中的所有元素,注:此处非所有元素集合,而是包含所有元素集合的迭代器 """
'''Iterator over elements repeating each as many times as its count. >>> c = Counter('ABCABC')
>>> sorted(c.elements())
['A', 'A', 'B', 'B', 'C', 'C'] # Knuth's example for prime factors of 1836: 2**2 * 3**3 * 17**1
>>> prime_factors = Counter({2: 2, 3: 3, 17: 1})
>>> product = 1
>>> for factor in prime_factors.elements(): # loop over factors
... product *= factor # and multiply them
>>> product Note, if an element's count has been set to zero or is a negative
number, elements() will ignore it. '''
# Emulate Bag.do from Smalltalk and Multiset.begin from C++.
return _chain.from_iterable(_starmap(_repeat, self.iteritems())) # Override dict methods where necessary @classmethod
def fromkeys(cls, iterable, v=None):
# There is no equivalent method for counters because setting v=1
# means that no element can have a count greater than one.
raise NotImplementedError(
'Counter.fromkeys() is undefined. Use Counter(iterable) instead.') def update(self, iterable=None, **kwds):
""" 更新计数器,其实就是增加;如果原来没有,则新建,如果有则加一 """
'''Like dict.update() but add counts instead of replacing them. Source can be an iterable, a dictionary, or another Counter instance. >>> c = Counter('which')
>>> c.update('witch') # add elements from another iterable
>>> d = Counter('watch')
>>> c.update(d) # add elements from another counter
>>> c['h'] # four 'h' in which, witch, and watch '''
# The regular dict.update() operation makes no sense here because the
# replace behavior results in the some of original untouched counts
# being mixed-in with all of the other counts for a mismash that
# doesn't have a straight-forward interpretation in most counting
# contexts. Instead, we implement straight-addition. Both the inputs
# and outputs are allowed to contain zero and negative counts. if iterable is not None:
if isinstance(iterable, Mapping):
if self:
self_get = self.get
for elem, count in iterable.iteritems():
self[elem] = self_get(elem, 0) + count
else:
super(Counter, self).update(iterable) # fast path when counter is empty
else:
self_get = self.get
for elem in iterable:
self[elem] = self_get(elem, 0) + 1
if kwds:
self.update(kwds) def subtract(self, iterable=None, **kwds):
""" 相减,原来的计数器中的每一个元素的数量减去后添加的元素的数量 """
'''Like dict.update() but subtracts counts instead of replacing them.
Counts can be reduced below zero. Both the inputs and outputs are
allowed to contain zero and negative counts. Source can be an iterable, a dictionary, or another Counter instance. >>> c = Counter('which')
>>> c.subtract('witch') # subtract elements from another iterable
>>> c.subtract(Counter('watch')) # subtract elements from another counter
>>> c['h'] # 2 in which, minus 1 in witch, minus 1 in watch
>>> c['w'] # 1 in which, minus 1 in witch, minus 1 in watch
-1 '''
if iterable is not None:
self_get = self.get
if isinstance(iterable, Mapping):
for elem, count in iterable.items():
self[elem] = self_get(elem, 0) - count
else:
for elem in iterable:
self[elem] = self_get(elem, 0) - 1
if kwds:
self.subtract(kwds) def copy(self):
""" 拷贝 """
'Return a shallow copy.'
return self.__class__(self) def __reduce__(self):
""" 返回一个元组(类型,元组) """
return self.__class__, (dict(self),) def __delitem__(self, elem):
""" 删除元素 """
'Like dict.__delitem__() but does not raise KeyError for missing values.'
if elem in self:
super(Counter, self).__delitem__(elem) def __repr__(self):
if not self:
return '%s()' % self.__class__.__name__
items = ', '.join(map('%r: %r'.__mod__, self.most_common()))
return '%s({%s})' % (self.__class__.__name__, items) # Multiset-style mathematical operations discussed in:
# Knuth TAOCP Volume II section 4.6.3 exercise 19
# and at http://en.wikipedia.org/wiki/Multiset
#
# Outputs guaranteed to only include positive counts.
#
# To strip negative and zero counts, add-in an empty counter:
# c += Counter() def __add__(self, other):
'''Add counts from two counters. >>> Counter('abbb') + Counter('bcc')
Counter({'b': 4, 'c': 2, 'a': 1}) '''
if not isinstance(other, Counter):
return NotImplemented
result = Counter()
for elem, count in self.items():
newcount = count + other[elem]
if newcount > 0:
result[elem] = newcount
for elem, count in other.items():
if elem not in self and count > 0:
result[elem] = count
return result def __sub__(self, other):
''' Subtract count, but keep only results with positive counts. >>> Counter('abbbc') - Counter('bccd')
Counter({'b': 2, 'a': 1}) '''
if not isinstance(other, Counter):
return NotImplemented
result = Counter()
for elem, count in self.items():
newcount = count - other[elem]
if newcount > 0:
result[elem] = newcount
for elem, count in other.items():
if elem not in self and count < 0:
result[elem] = 0 - count
return result def __or__(self, other):
'''Union is the maximum of value in either of the input counters. >>> Counter('abbb') | Counter('bcc')
Counter({'b': 3, 'c': 2, 'a': 1}) '''
if not isinstance(other, Counter):
return NotImplemented
result = Counter()
for elem, count in self.items():
other_count = other[elem]
newcount = other_count if count < other_count else count
if newcount > 0:
result[elem] = newcount
for elem, count in other.items():
if elem not in self and count > 0:
result[elem] = count
return result def __and__(self, other):
''' Intersection is the minimum of corresponding counts. >>> Counter('abbb') & Counter('bcc')
Counter({'b': 1}) '''
if not isinstance(other, Counter):
return NotImplemented
result = Counter()
for elem, count in self.items():
other_count = other[elem]
newcount = count if count < other_count else other_count
if newcount > 0:
result[elem] = newcount
return result Counter Counter
counter源码
三、有序字典
orderdDict是对字典类型的补充,他记住了字典元素添加的顺序
例:
dic = collections.OrderedDict()
dic['k1']='v1'
dic['k2']='v2'
dic['k3']='v3'
print(dic)
操作方法与字典操作方法相同
四、默认字典
dic=collections.defaultdict(list)
dic['k1'].append('cat')
print(dic)
操作方法与字典操作方法相同
五、可命名元组(namedtuple)
根据nametuple可以创建一个包含tuple所有功能以及其他功能的类型。
import collections
Mytuple = collections.namedtuple('Mytuple',['x', 'y', 'z'])
六、队列
双向队列(deque):
d = collections.deque()
d.append('') #添加数据到队列
d.appendleft('') #添加数据到队列左边
d.appendleft('')
print(d)
r = d.count('') #查看1在队列里的个数
print(r)
d.extend(['yy','uu','ii']) #添加多个元素到列表
d.extendleft(['y1y','u1u','i1i']) #添加多个元素到列表左边
print(d)
d.rotate(5) #将右边的值按顺序放到左边,括号里的值为要取值的个数
print(d)
单向队列(queue):
import queue q = queue.Queue()
q.put('')
q.put('') #将数据添加到队列
print(q.qsize()) #获取队列中数据的个数
print(q.get()) #拿取队列中的数据(先进先出原则)
七、深浅拷贝
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
import copy
# ######### 数字、字符串 #########
n1 = 123
# n1 = "i am alex age 10"
print(id(n1))
# ## 赋值 ##
n2 = n1
print(id(n2))
# ## 浅拷贝 ##
n2 = copy.copy(n1)
print(id(n2)) # ## 深拷贝 ##
n3 = copy.deepcopy(n1)
print(id(n3))
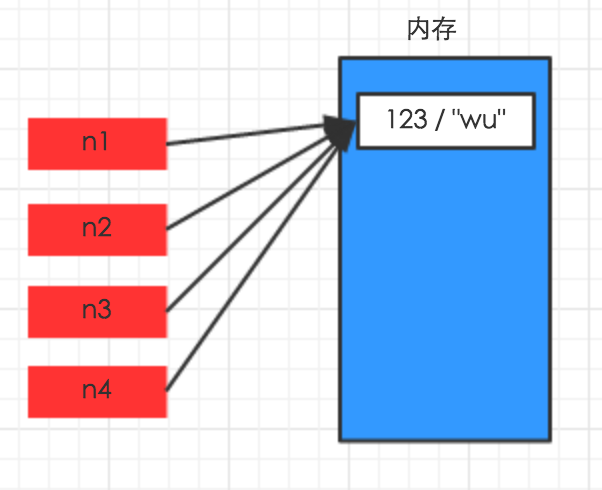
对于字典、元祖、列表 而言,进行赋值、浅拷贝和深拷贝时,其内存地址的变化是不同的。
赋值,只是创建一个变量,该变量指向原来内存地址,如:
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n2 = n1
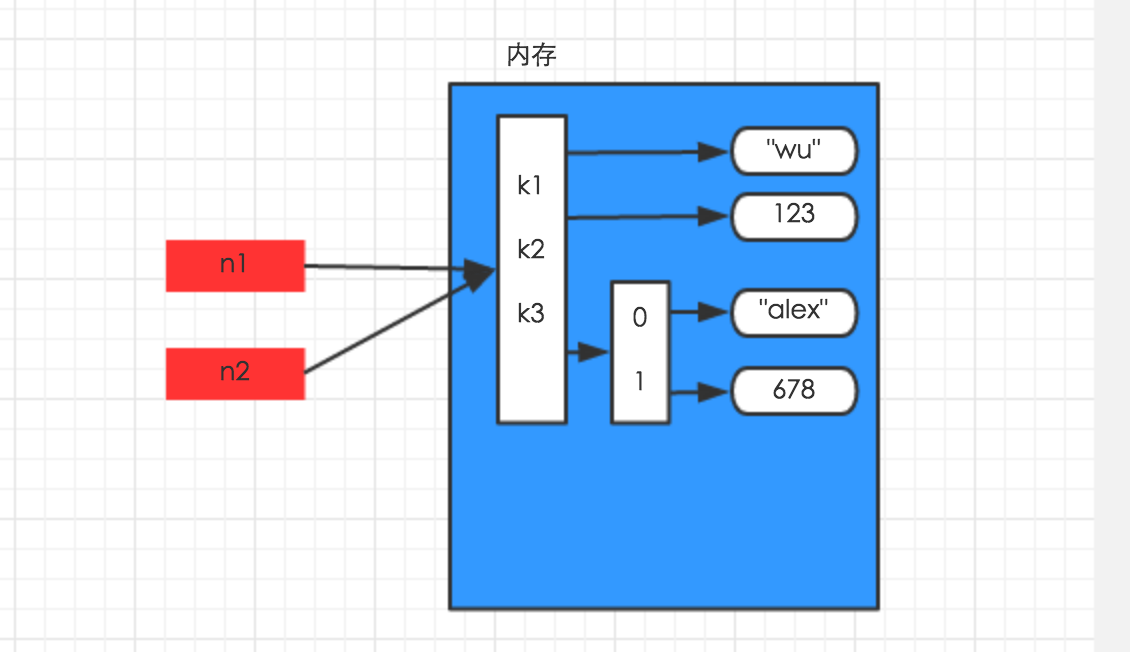
浅拷贝,在内存中只额外创建第一层数据
import copy
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n3 = copy.copy(n1)
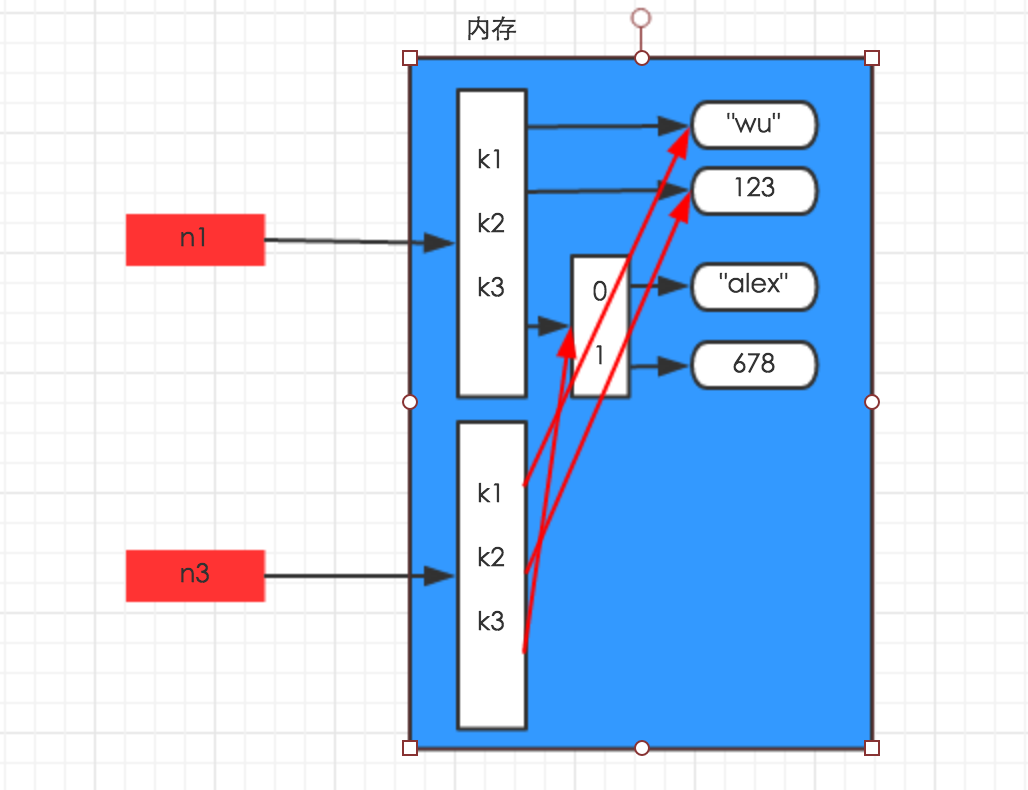
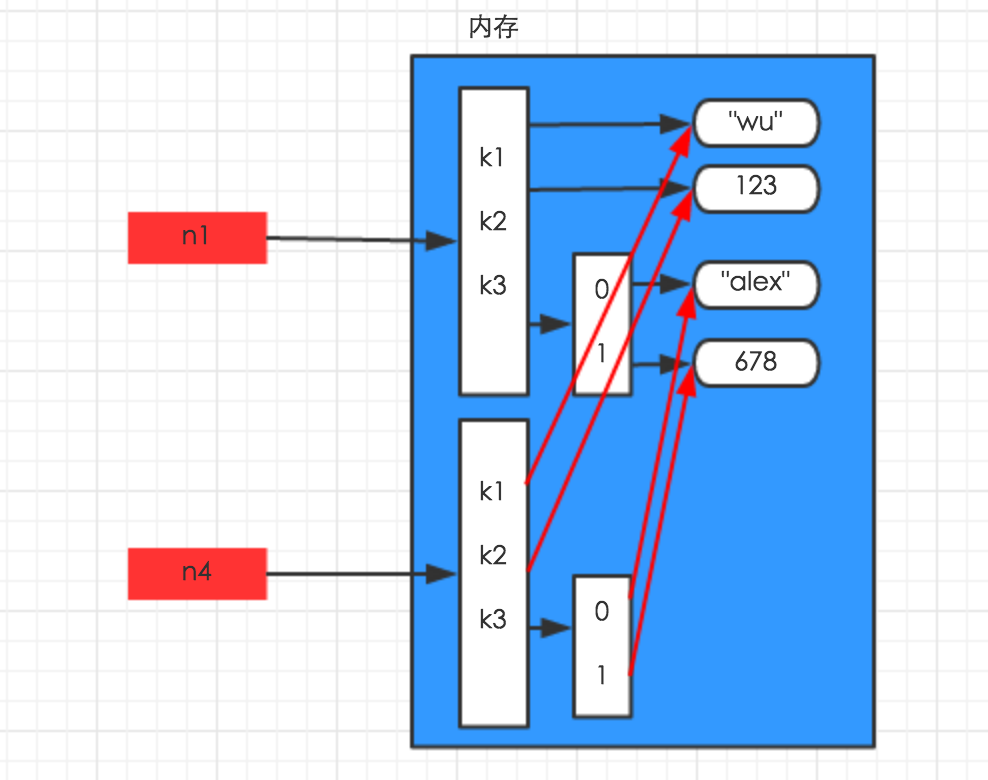
深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
import copy
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n4 = copy.deepcopy(n1)
八、函数
一、背景
在学习函数之前,一直遵循:面向过程编程,即:根据业务逻辑从上到下实现功能,其往往用一长段代码来实现指定功能,开发过程中最常见的操作就是粘贴复制,也就是将之前实现的代码块复制到现需功能处,如下:
while True:
if cpu利用率 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 if 硬盘使用空间 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 if 内存占用 > 80%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
仔细一看上述代码,if条件语句下的内容可以被提取出来公用,如下:
def 发送邮件(内容)
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 while True: if cpu利用率 > 90%:
发送邮件('CPU报警') if 硬盘使用空间 > 90%:
发送邮件('硬盘报警') if 内存占用 > 80%:
对于上述的两种实现方式,第二次必然比第一次的重用性和可读性要好,其实这就是函数式编程和面向过程编程的区别:
- 函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
- 面向对象:对函数进行分类和封装,让开发“更快更好更强...”
函数式编程最重要的是增强代码的重用性和可读性
二、定义和使用
def 函数名(参数):
...
函数体
...
函数的定义主要有如下要点:
- def:表示函数的关键字
- 函数名:函数的名称,日后根据函数名调用函数
- 函数体:函数中进行一系列的逻辑计算,如:发送邮件、计算出 [11,22,38,888,2]中的最大数等...
- 参数:为函数体提供数据
- 返回值:当函数执行完毕后,可以给调用者返回数据。
以上要点中,比较重要有参数和返回值:
1、返回值
函数是一个功能块,该功能到底执行成功与否,需要通过返回值来告知调用者。
def 发送短信():
发送短信的代码...
if 发送成功:
return True
else:
return False
while True:
# 每次执行发送短信函数,都会将返回值自动赋值给result
# 之后,可以根据result来写日志,或重发等操作
result = 发送短信()
if result == False:
记录日志,短信发送失败...
2、参数
为什么要有参数?
def 发送邮件(邮件内容)
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
while True:
if cpu利用率 > 90%:
发送邮件("CPU报警了。")
if 硬盘使用空间 > 90%:
发送邮件("硬盘报警了。")
if 内存占用 > 80%:
发送邮件("内存报警了。")
有参数实现
def CPU报警邮件()
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 def 硬盘报警邮件()
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 def 内存报警邮件()
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 while True: if cpu利用率 > 90%:
CPU报警邮件() if 硬盘使用空间 > 90%:
硬盘报警邮件() if 内存占用 > 80%:
内存报警邮件()
无参数实现
函数的有三中不同的参数:
- 普通参数
- 默认参数
- 动态参数
# ######### 定义函数 ######### # name 叫做函数func的形式参数,简称:形参
def func(name):
print name # ######### 执行函数 #########
# 'spykdis' 叫做函数func的实际参数,简称:实参
func('spykdis')
普通参数
def func(name, age = 18):
print "%s:%s" %(name,age)
# 指定参数
func('cat', 19)
# 使用默认参数
func('tom')
注:默认参数需要放在参数列表最后
默认参数
def func(*args):
print args
# 执行方式一
func(11,33,4,4454,5)
# 执行方式二
li = [11,2,2,3,3,4,54]
func(*li)
动态参数-序列
def func(**kwargs):
print args
# 执行方式一
func(name='tom',age=18)
# 执行方式二
li = {'name':'tom', age:18, 'gender':'male'}
func(**li)
动态参数-字典
def func(*args, **kwargs):
print args
print kwargs
动态参数-序列和字典
九、lambda表达式
学习条件运算时,对于简单的 if else 语句,可以使用三元运算来表示,即:
# 普通条件语句
if 1 == 1:
name = 'wupeiqi'
else:
name = 'alex' # 三元运算
name = 'wupeiqi' if 1 == 1 else 'alex'
对于简单的函数,也存在一种简便的表示方式,即:lambda表达式
# ###################### 普通函数 ######################
# 定义函数(普通方式)
def func(arg):
return arg + 1 # 执行函数
result = func(123) # ###################### lambda ###################### # 定义函数(lambda表达式)
my_lambda = lambda arg : arg + 1 # 执行函数
result = my_lambda(123)
lambda存在意义就是对简单函数的简洁表示
十、内置函数

详细见python文档,猛击这里
map
遍历序列,对序列中每个元素进行操作,最终获取新的序列。

li = [11, 22, 33] new_list = map(lambda a: a + 100, li)
每个元素增加100
li = [11, 22, 33]
sl = [1, 2, 3]
new_list = map(lambda a, b: a + b, li, sl)
两个列表相同元素相加
filter
对于序列中的元素进行筛选,最终获取符合条件的序列

li = [11, 22, 33] new_list = filter(lambda arg: arg > 22, li) #filter第一个参数为空,将获取原来序列
获取列表中大于12的所有元素集合
reduce
对于序列内所有元素进行累计操作


li = [11, 22, 33] result = reduce(lambda arg1, arg2: arg1 + arg2, li) # reduce的第一个参数,函数必须要有两个参数
# reduce的第二个参数,要循环的序列
# reduce的第三个参数,初始值
获取序列中所有元素的和
python学习day3的更多相关文章
- python学习-day3
今天是第三天学习,加油! 第一部分 集合 一.集合 1.什么是集合以及特性? 特性:无序的,不重复的序列,可嵌套. 2.创建集合 方法一:创建空集合 s1 = set() print(type(s1) ...
- python学习Day3 变量、格式化输出、注释、基本数据类型、运算符
今天复习内容(7项) 1.语言的分类 -- 机器语言:直接编写0,1指令,直接能被硬件执行 -- 汇编语言:编写助记符(与指令的对应关系),找到对应的指令直接交给硬件执行 -- 高级语言:编写人能识别 ...
- python学习 day3 (3月4日)---字符串
字符串: 下标(索引) 切片[起始:终止] 步长[起始:终止:1] 或者-1 从后往前 -1 -2 -3 15个专属方法: 1-6 : 格式:大小写 , 居中(6) s.capitalize() s ...
- Python学习day3作业
days3作业 作业需求 HAproxy配置文件操作 根据用户输入,输出对应的backend下的server信息 可添加backend 和sever信息 可修改backend 和sever信息 可删除 ...
- python学习day3 编程语言分类 变量 格式化输出
1.编程语言分类 机器语言:直接使用二进制指令直接编写程序,直接操作计算机硬件,必须考虑硬件细节 汇编语言:使用英文标签代替二进制指令去编写程序,直接操作计算机硬件,必须考虑硬件细节对,不过相比机器语 ...
- Python学习day3 数据类型Ⅰ(str,int,bool)
day3 数据类型 @上节内容补充 每周一个思维导图-xmind.exe in / not in #示例:(是否包含敏感字符)while True: text = input('请输入你要说的 ...
- Python学习笔记,day3
Python学习第三天 一.集合 集合是一个无序的,不重复的数据组合,它的主要作用如下: 去重,把一个列表变成集合,就自动去重了 关系测试,测试两组数据之前的交集.差集.并集等关系 常用操作: s = ...
- python s12 day3
python s12 day3 深浅拷贝 对于 数字 和 字符串 而言,赋值.浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ...
- python学习博客地址集合。。。
python学习博客地址集合... 老师讲课博客目录 http://www.bootcdn.cn/bootstrap/ bootstrap cdn在线地址 http://www.cnblogs. ...
随机推荐
- class A<T>where T
where表明了对类型变量T的约束关系.where T: A表示类型变量是继承于A的,或者是A本身.where T:new()指明了创建T的实例时应该使用的构造函数.
- JS编码解码详解
今天在整理 js编码解码方法时,在网上搜资料,发现一篇文章讲的不错,讲解的非常简单明了,于是乎就想转载过来,却发现无法转载到博客园,最后只能卑鄙的摘抄过来.js编码解码就是将一些对URL和数据库敏感的 ...
- Effective Java2读书笔记-创建和销毁对象(一)
第1条:考虑用静态工厂方法代替构造器 通常情况下,我们创建一个对象采取new的形式,但是还有一种方法也是经常使用到的,它的名称叫做静态工厂方法. 例如,java中基本类型boolean的包装类Bool ...
- 汇编写函数:关于PUBLIC和EXTRN的区别
PUBLIC伪指令的格式:PUBLIC 标识符,标识符... 该伪指令告诉汇编程序放在PUBLIC之后的标识符(本模块的定义的)可为其他模块使用,这些标识符可以是变量.标号或者过程名.言外之意,它不仅 ...
- 对Qt for Android的评价(很全面,基本已经没有问题了,网易战网客户端就是Qt quick写的),可以重用QT积累20年的RTL是好事,QML效率是HTML5的5倍
现在Qt不要光看跨平台了,Qt也有能力和原生应用进行较量的.可以直接去Qt官网查看他和那些厂商合作.关于和Java的比较,框架和Java进行比较似乎不且实际.如果是C++和Java比较,网上有很多文章 ...
- Unattended Setup Software Components (无人值守安装软件组件)
原文 http://social.technet.microsoft.com/Forums/windows/en-US/d4ad85b4-8342-4401-83ed-45cefa814ec5/una ...
- bootstrap绿色大气后台模板下载[转]
From:http://www.oschina.net/code/snippet_2364127_48176 1. [图片] 2. [文件] 素材火官网后台模板下载.rar ~ 4MB 下载( ...
- C语言中不同类型的循环(Different types of loops in C)
C语言中有三种类型的循环:for,while,do-while. while循环先判断循环条件. while (condition) { //gets executed after condition ...
- hdu 2202 最大三角形_凸包模板
题意:略 思路:直接套用凸包模板 #include <iostream> #include <cstdio> #include <cmath> #include & ...
- UVA 10282 (13.08.18)
Problem C: Babelfish You have just moved from Waterloo to a big city. The people here speakan incomp ...