Windows平台字符的存储和输出分析
1. 引言
(写于2011-07-30)
在Windows NT系列的操作系统中最常用的两种字符集是ANSI和Unicode。ANSI是一种泛称,每一个国家或地区的ANSI编码都不一样,比如在Windows XP简体中文版中,ANSI的编码为GBK,而在Windows XP日文版中ANSI的编码是JIS。Unicode的全称是Universal Multiple-Octet Coded Character Set,中文含义是“通用多八位编码字符集”。Unicode的目标是为世界是所有的字符提供一套唯一的、统一的字符编码,所以不管理在作保地方任何操作系统,一个确定字符的编码都是唯一的。由于Unicode采用大于等于2个字节来储存字符编码,所以有可能在不同的操作系统中储存的字节顺序不一样,可分为大端方式和小端方式。
存储方式
以“中文”两个汉字举例说明,在Windows XP简体中文版中,“中文”两个字的ANSI/GBK和Unicode分别为:
|
字符 |
中 |
文 |
|
ANSI/GBK |
0XD6D0 |
0XCEC4 |
|
Unicode |
0X4E2D |
0X6587 |
2. 内存中的储存方式
在VC中,定义字符有两种方式:char类型和wchar_t类型。char类型采用ANSI/GBK编码,而wchar_t采用Unicode编码,wchar_t也是常说的宽字符型。
定义如下两个字符串
char* str = "中文";
wchar_t* wcstr = L"中文";
通过调试我们可以看到这两个字符串在内存中的储存方式。编译后,指针str所指向的地址为0x004188CC,“中文”两个字在内存中的表示方式为:d6 d0 ce c4,刚好是“中文”两个字的GBK码,从而可知,如一个字符串在VC中被定义为char*类型,那么字符将被编为ANSI/GBK码,如图 1所示。
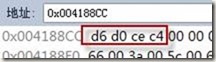
图 1 “中文”在内存中的ANSI编码
wchar_t类型指针wcstr所指向的地址为0x004188C4,如图 2所示。从图可知,在VC中,wchar_t类型的字符串将被编译为Unicode码,并按UTF-16小端方式储存。
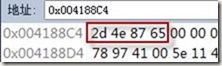
图 2 “中文”在内存中的Unicode编码
Unicode只规定了字符的编码,没有规定如何储存这些编码。储存Unicode码常用三种方式:
1、UTF-16小端方式:用两个字节储存Unicode码,低字节在前,高字节在后;
2、UTF-16大端方式:用两个字节储存Unicode码,高字节在前,低字节在后;
3、UTF-8:用1~4个字节按一定规则存放Unicode码,汉字需要用3个字节。
图 2中的“2d4e8765”正是“中文”两个汉字的Unicode码“4e2d6587”按UTF-16小端方式储存。
3. 磁盘中的储存方式
打开Windows记事本,输入“中文”两个字,在另存为对话框中的编码下拉框中分别选择ANSI、Unicode、Unicode big endian和UTF-8储存为四个文本文件,然后用十六进制文本编辑器打开,内容如下表
表 1
|
编码 |
十六进制内容 |
|
ANSI |
D6 D0 CE C4 |
|
Unicode |
FF FE 2D 4E 87 65 |
|
Unicode big endian |
FE FF 4E 2D 65 87 |
|
UTF-8 |
EF BB BF E4 B8 AD E6 96 87 |
从表中可以看出,对于选择ANSI编码,会采用系统默认编码按大端方式直接储存,对于Windows XP简体中文版,系统默认编码是GBK,所以文件中储存的内容就是“中文”两个字的的GBK编码D6 D0 CE C4。
如果是Unicode编码,按照规定,要在文件的开头加上一个“ZERO WIDTH NO-BREAK SPACE”标识,可直译为“零宽度非换行空格”,目标是标识文件是以哪一种方式来储存Unicode码。“中文”的Unicode码为“4E2D 6587”常用三种方式储存
表 2
|
储存方式 |
字符串编码内容 |
|
UTF-16 Little Endian (小端) |
2D4E 8765 |
|
UTF-16 Big Endian (大端) |
4E2D 6587 |
|
UTF-8 |
E4B8AD E69687 |
注:UTF-8是变长的,储存一个字母要一个字节,一个汉字要三个字节;UTF-16是定长的,不管是储存一个字母还是一个汉字都需要两个字节,所以用UTF-16储存字母时会造成空间浪费。
这三种储存方式所对应的标识为
表 3
|
储存方式 |
对应的标识 |
|
UTF-16 Little Endian (小端) |
FF FE |
|
UTF-16 Big Endian (大端) |
FE FF |
|
UTF-8 |
EF BB BF |
所以从表 1 可知,
1、 如果选择“Unicode”,会将字符串编译为Unicode码,按UTF-16小端方式储存;
2、 如果选择“Unicode big endian”,会将字符串编译为Unicode码,按UTF-16大端方式储存;
3、 如果选择“UTF-8”,会将字符串编译为Unicode码,按UTF-8方式储存。
从上面我们也可知道,如果一个文本文件的前两个字节是“FFFE”,那么这个文件一定是按小端方式储存字符的Unicode码,第三个字节是Unicode码的低字节,第四个字节是Unicode码的高字节,根据这两个高低字节就可以得出一个Unicode字符。第五个字节是第二个字符的Unicode码的低字节,第六个字节是第二个字符的Unicode码的高字节。
UTF-8码是将字符的Unicode码按一定规则存放到1~4个字节中,根据UFT-8码也可以得出字符的Unicode码,请别参考其他文档。
4. 字符的输出方式
知道字符在计算机如何编码,如何储存后,那么如何将这些输出呢?
4.1 Windows控制台的输出方式
Widows在内部维护了一块控制台输出缓冲区,如要要向控制台输出字符串,只要将字符串所对应的内存区域复制到控制台缓冲区,Windows就会以默认的字符编码将控制台缓冲区的内容输出到控制台窗口。对于Windows XP简体中文版,默认的字符编码是GBK,所以Windows会以GBK码的方式输出控制台缓冲区的内容。要想Windows XP简体中文版的控制台窗口能正确输出控制缓冲区的内容,那么必须保证复制到控制台缓冲区的字符编码是GBK码。
4.2 C/C++中将字符串输出到控制台
对于C语言的printf()函数和C++语言中的std::cout对象,其实都是调用系统“kernel32.dll”中的WriteConsole()函数,将字符串所对应的内存区域复制到控制台的缓冲区。
对于char*类型的字符串,C语言提供的输出函数是printf(),对于wchar_t*类型的字符串,C语言提供的输出函数是wprintf()。
在VC中,char*类型的字符被编译为ANSI(GBK)码,正好和输出缓冲区的编码类型一致,所以可以直接输出。对于wchar_t*类型字符串,VC在编译程序时,会将字符串编译为Unicode码,如果程序运行时,直接将字符串对应的内存区域复制到输出缓冲区,由于字符串的编码和控制台的默认编码不至,控制台将Unicode码当作GBK码输出到控制台时就会出现乱情况。
一个可行的办法是先将Unicode码转换成GBK码,然后再复制到控制台的输出缓冲区,这样就不会出现乱码的问题。
在C语言和C++语言中输出char*类型和wchar_t*类型的字符串
//C语言输出char*类型的字符串(ANSI/GBK) void cprintchar(const char* str)
{
printf("%s\n",str);
} //C语言输出wchar_t*类型的字符串(Unicode)
void cprintwchar(const wchar_t* wcstr)
{
//告诉程序控制台缓冲区使用哪种编码
//<locale.h>
setlocale(LC_ALL,"ZHI");
wprintf(L"%ls\n",wcstr);
} //C++语言输出char*类型字符串(ANSI/GBK)
void ccprintchar(const char* str)
{
std::cout << str << std::endl;
} //C++语言输出wchar_t*类型字符串(Unicode)
void ccprintwchar(const wchar_t* wcstr)
{
//告诉程序控制台缓冲区使用哪种编码
//需要<locale>
std::wcout.imbue(std::locale("ZHI"));
std::wcout << wcstr << std::endl;
}
Windows平台字符的存储和输出分析的更多相关文章
- 转:浅析windows下字符集和文件编码存储/utf8/gbk
最近老猿在学习文件操作及网络爬虫相关知识,发现字符集及编码的处理非常重要,而老猿原来对此了解并不多,因此找了几篇文章看了一下,将老猿认为比较的相关文章转载一下.感谢各位原创大神! 1,字符集 这里主要 ...
- Windows平台下源码分析工具
最近这段时间在阅读 RTKLIB的源代码,目前是将 pntpos.c文件的部分看完了,准备写一份文档记录下这些代码的用处.处理过程.理论公式来源.注意事项,自己还没有弄明白的地方.目前的想法是把每一个 ...
- 认识二进制安全与漏洞攻防技术 (Windows平台)
二进制漏洞是指程序存在安全缺陷,导致攻击者恶意构造的数据(如Shellcode)进入程序相关处理代码时,改变程序原定的执行流程,从而实现破坏或获取超出原有的权限. 0Day漏洞 在计算机领域中,0da ...
- cocos2d-x 开头配置(Windows 平台)
工欲善其事,必先利其器. 要使用 cocos2d-x 引擎,就要配置(或者安装)引擎,到 cocos2d-x 官网下载页下载引擎,官网给了2.x和3.x两个版本,我使用的是3.6的版本,3.x的版本类 ...
- Windows平台配置Appium+Java环境
1) 安装JDK 下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 安装 ...
- Windbg是windows平台上强大的调试器
基础调试命令 - .dump/.dumpcap/.writemem/!runaway Windbg是windows平台上强大的调试器,它相对于其他常见的IDE集成的调试器有几个重要的优势, Windb ...
- 转:Windows平台配置Appium+Java环境
1) 安装JDK 下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 安装 ...
- 不同WINDOWS平台下磁盘逻辑扇区的直接读写
不同WINDOWS平台下磁盘逻辑扇区的直接读写 关键字:VWIN32.中断.DeviceIoControl 一.概述 在DOS操作系统下,通过BIOS的INT13.DOS的INT25(绝对读).INT ...
- MySQL 在Windows平台上的安装及实例多开
MySQL在Windows平台上的安装及实例多开 by:授客 QQ:1033553122 测试环境 Win7 64 mysql-5.7.20-winx64.zip 下载地址: https://cd ...
随机推荐
- VC:CString用法整理(转载)
1.CString::IsEmpty BOOL IsEmpty( ) const; 返回值:如果CString 对象的长度为0,则返回非零值:否则返回0. 说明:此成员函数用来测试一个CString ...
- dwz笔记之tree权限扩展
碰到的问题:tree选择子节点时,父级节点的值没有选择 解决方法如下(红色部分): 原代码: _checkParent:function(){ if($(this).parent().hasClass ...
- 让footer在底部(测试它人方法)
要求:网页布局中,页脚在底部.内容不够一页时,在底部.内容超过一页时,出现卷动条,页脚也在被挤到底部 1.测试的这个文章介绍的办法 链接: http://www.cnblogs.com/cheny ...
- php解析json数组(循环输出数据)的实例
以快递100接口为例 返回的JSON数据 {"message":"ok","nu":"350116805826",&qu ...
- 使用注解@Transient使表中没有此字段
注意,实体类中要使用org.springframework.data.annotation.Transient 在写实体类时发现有加@Transient注解的 加在属性声明上,但网上有加到get方法上 ...
- python导入matplotlib模块出错
我的系统是linux mint.用新立得软件包安装了numpy和matplotlib.在导入matplotlib.pyplot时出错.说是没有python3-tk包. 于是就在shell中装了一下. ...
- Android Development Tools 发生checkAndLoadTargetData错误
之前使用时没有出现任何问题的,我把D:\IDE\ADT\adt-bundle-windows-x86_64-20140321\eclipse目录下面的 eclipse.exe重名名为adt.exe并设 ...
- key转成pvf
https://www.godaddy.com/help/converting-an-exported-pfx-code-signing-file-to-pvk-and-spc-files-using ...
- 关于Microsoft app下同义词的整理
Windows os 以下词表达的是同一个概念 windows store app windows metro app windows modern app windows runtime app w ...
- 2014.11.12模拟赛【最小公倍数】| vijos1047最小公倍数
最小公倍数(lcm.c/.cpp/.pas) 题目描述 给定两个正整数,求他们的最小公倍数. 样例输入 28 12 样例输出 84 数据范围 对于40%数据:1<=a,b<=10^9 对于 ...