hadoop namenode启动过程详细剖析及瓶颈分析
NameNode中几个关键的数据结构
FSImage
Namenode 会将HDFS的文件和目录元数据存储在一个叫fsimage的二进制文件中,每次保存fsimage之后到下次保存之间的所有hdfs操作,将会记录在 editlog文件中,当editlog达到一定的大小(bytes,由fs.checkpoint.size参数定义)或从上次保存过后一定时间段过后 (sec,由fs.checkpoint.period参数定义),namenode会重新将内存中对整个HDFS的目录树和文件元数据刷到 fsimage文件中。Namenode就是通过这种方式来保证HDFS中元数据信息的安全性。
Fsimage是一个二进制文件,当中记录了HDFS中所有文件和目录的元数据信息,在我的hadoop的HDFS版中,该文件的中保存文件和目录的格式如下:

当namenode重启加载fsimage时,就是按照如下格式协议从文件流中加载元数据信息。从fsimag的存储格式可以看出,fsimage保存有如下信息:
1. 首先是一个image head,其中包含:
a) imgVersion(int):当前image的版本信息
b) namespaceID(int):用来确保别的HDFS instance中的datanode不会误连上当前NN。
c) numFiles(long):整个文件系统中包含有多少文件和目录
d) genStamp(long):生成该image时的时间戳信息。
2. 接下来便是对每个文件或目录的源数据信息,如果是目录,则包含以下信息:
a) path(String):该目录的路径,如”/user/build/build-index”
b) replications(short):副本数(目录虽然没有副本,但这里记录的目录副本数也为3)
c) mtime(long):该目录的修改时间的时间戳信息
d) atime(long):该目录的访问时间的时间戳信息
e) blocksize(long):目录的blocksize都为0
f) numBlocks(int):实际有多少个文件块,目录的该值都为-1,表示该item为目录
g) nsQuota(long):namespace Quota值,若没加Quota限制则为-1
h) dsQuota(long):disk Quota值,若没加限制则也为-1
i) username(String):该目录的所属用户名
j) group(String):该目录的所属组
k) permission(short):该目录的permission信息,如644等,有一个short来记录。
3. 若从fsimage中读到的item是一个文件,则还会额外包含如下信息:
a) blockid(long):属于该文件的block的blockid,
b) numBytes(long):该block的大小
c) genStamp(long):该block的时间戳
当该文件对应的numBlocks数不为1,而是大于1时,表示该文件对应有多个block信息,此时紧接在该fsimage之后的就会有多个blockid,numBytes和genStamp信息。
因此,在namenode启动时,就需要对fsimage按照如下格式进行顺序的加载,以将fsimage中记录的HDFS元数据信息加载到内存中。
BlockMap
从 以上fsimage中加载如namenode内存中的信息中可以很明显的看出,在fsimage中,并没有记录每一个block对应到哪几个 datanodes的对应表信息,而只是存储了所有的关于namespace的相关信息。而真正每个block对应到datanodes列表的信息在 hadoop中并没有进行持久化存储,而是在所有datanode启动时,每个datanode对本地磁盘进行扫描,将本datanode上保存的 block信息汇报给namenode,namenode在接收到每个datanode的块信息汇报后,将接收到的块信息,以及其所在的datanode 信息等保存在内存中。HDFS就是通过这种块信息汇报的方式来完成 block -> datanodes list的对应表构建。Datanode向namenode汇报块信息的过程叫做blockReport,而namenode将block -> datanodes list的对应表信息保存在一个叫BlocksMap的数据结构中。
BlocksMap的内部数据结构如下:
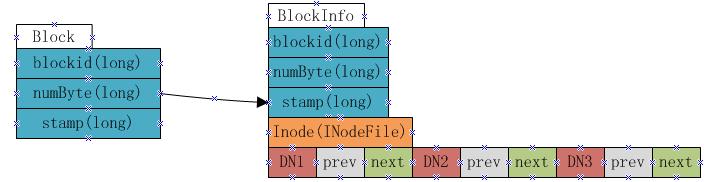
如 上图显示,BlocksMap实际上就是一个Block对象对BlockInfo对象的一个Map表,其中Block对象中只记录了 blockid,block大小以及时间戳信息,这些信息在fsimage中都有记录。而BlockInfo是从Block对象继承而来,因此除了 Block对象中保存的信息外,还包括代表该block所属的HDFS文件的INodeFile对象引用以及该block所属datanodes列表的信 息(即上图中的DN1,DN2,DN3,该数据结构会在下文详述)。
因 此在namenode启动并加载fsimage完成之后,实际上BlocksMap中的key,也就是Block对象都已经加载到BlocksMap中, 每个key对应的value(BlockInfo)中,除了表示其所属的datanodes列表的数组为空外,其他信息也都已经成功加载。所以可以 说:fsimage加载完毕后,BlocksMap中仅缺少每个块对应到其所属的datanodes list的对应关系信息。所缺这些信息,就是通过上文提到的从各datanode接收blockReport来构建。当所有的datanode汇报给namenode的blockReport处理完毕后,BlocksMap整个结构也就构建完成。
BlockMap中datanode列表数据结构
在BlockInfo中,将该block所属的datanodes列表保存在一个Object[]数组中,但该数组不仅仅保存了datanodes列表,还包含了额外的信息。实际上该数组保存了如下信息:

上 图表示一个block包含有三个副本,分别放置在DN1,DN2和DN3三个datanode上,每个datanode对应一个三元组,该三元组中的第二 个元素,即上图中prev block所指的是该block在该datanode上的前一个BlockInfo引用。第三个元素,也就是上图中next Block所指的是该block在该datanode上的下一个BlockInfo引用。每个block有多少个副本,其对应的BlockInfo对象中 就会有多少个这种三元组。
Namenode 采用这种结构来保存block->datanode list的目的在于节约namenode内存。由于namenode将block->datanodes的对应关系保存在了内存当中,随着HDFS 中文件数的增加,block数也会相应的增加,namenode为了保存block->datanodes的信息已经耗费了相当多的内存,如果还像 这种方式一样的保存datanode->block list的对应表,势必耗费更多的内存,而且在实际应用中,要查一个datanode上保存的block list的应用实际上非常的少,大部分情况下是要根据block来查datanode列表,所以namenode中通过上图的方式来保存 block->datanode list的对应关系,当需要查询datanode->block list的对应关系时,只需要沿着该数据结构中next Block的指向关系,就能得出结果,而又无需保存datanode->block list在内存中。
NameNode启动过程
fsimage加载过程
Fsimage加载过程完成的操作主要是为了:
1. 从fsimage中读取该HDFS中保存的每一个目录和每一个文件
2. 初始化每个目录和文件的元数据信息
3. 根据目录和文件的路径,构造出整个namespace在内存中的镜像
4. 如果是文件,则读取出该文件包含的所有blockid,并插入到BlocksMap中。
整个加载流程如下图所示:
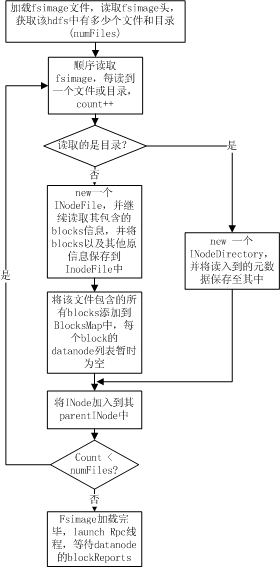
如 上图所示,namenode在加载fsimage过程其实非常简单,就是从fsimage中不停的顺序读取文件和目录的元数据信息,并在内存中构建整个 namespace,同时将每个文件对应的blockid保存入BlocksMap中,此时BlocksMap中每个block对应的datanodes 列表暂时为空。当fsimage加载完毕后,整个HDFS的目录结构在内存中就已经初始化完毕,所缺的就是每个文件对应的block对应的 datanode列表信息。这些信息需要从datanode的blockReport中获取,所以加载fsimage完毕后,namenode进程进入 rpc等待状态,等待所有的datanodes发送blockReports。
blockReport阶段
每 个datanode在启动时都会扫描其机器上对应保存hdfs block的目录下(dfs.data.dir)所保存的所有文件块,然后通过namenode的rpc调用将这些block信息以一个long数组的方 式发送给namenode,namenode在接收到一个datanode的blockReport rpc调用后,从rpc中解析出block数组,并将这些接收到的blocks插入到BlocksMap表中,由于此时BlocksMap缺少的仅仅是每 个block对应的datanode信息,而namenoe能从report中获知当前report上来的是哪个datanode的块信息,所 以,blockReport过程实际上就是namenode在接收到块信息汇报后,填充BlocksMap中每个block对应的datanodes列表 的三元组信息的过程。其流程如下图所示:
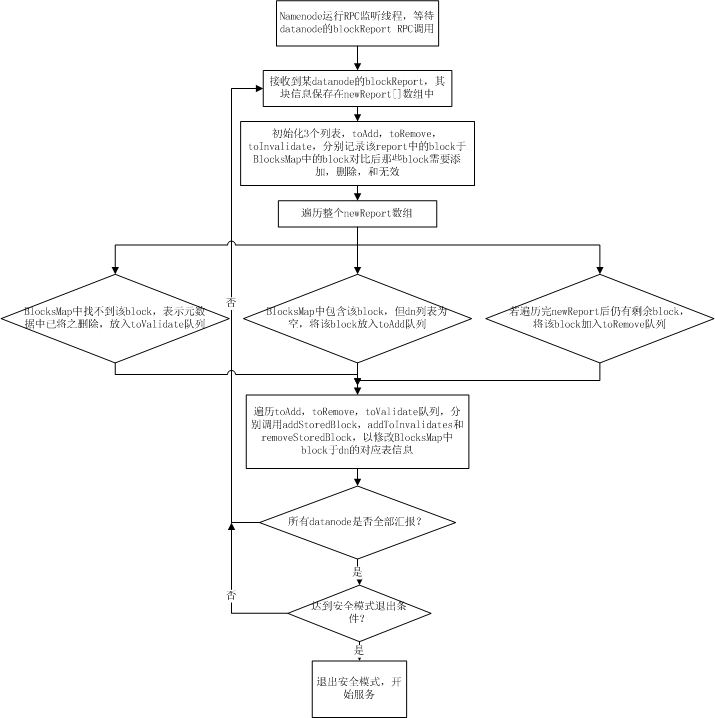
当 所有的datanode汇报完block,namenode针对每个datanode的汇报进行过处理后,namenode的启动过程到此结束。此时 BlocksMap中block->datanodes的对应关系已经初始化完毕。如果此时已经达到安全模式的推出阈值,则hdfs主动退出安全模 式,开始提供服务。
启动过程数据采集和瓶颈分析
对namenode的整个启动过程有了详细了解之后,就可以对其启动过程中各阶段各函数的调用耗时进行profiling的采集,数据的profiling仍然分为两个阶段,即fsimage加载阶段和blockReport阶段。
fsimage加载阶段性能数据采集和瓶颈分析
以下是对建库集群真实的fsimage加载过程的的性能采集数据:

从上图可以看出,fsimage的加载过程那个中,主要耗时的操作分别分布在FSDirectory.addToParent,FSImage.readString,以及PermissionStatus.read三个操作,这三个操作分别占用了加载过程的73%,15%以及8%,加起来总共消耗了整个加载过程的96%。而其中FSImage.readString和PermissionStatus.read操作都是从fsimage的文件流中读取数据(分别是读取String和short)的操作,这种操作优化的空间不大,但是通过调整该文件流的Buffer大小来提高少许性能。而FSDirectory.addToParent的调用却占用了整个加载过程的73%,所以该调用中的优化空间比较大。
以下是addToParent调用中的profiling数据:

从 以上数据可以看出addToParent调用占用的73%的耗时中,有66%都耗在了INode.getPathComponents调用上,而这66% 分别有36%消耗在INode.getPathNames调用,30%消耗在INode.getPathComponents调用。这两个耗时操作的具体 分布如以下数据所示:
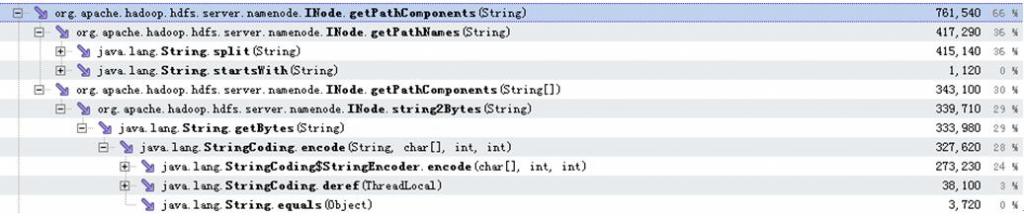
可 以看出,消耗了36%的处理时间的INode.getPathNames操作,全部都是在通过String.split函数调用来对文件或目录路径进行切 分。另外消耗了30%左右的处理时间在INode.getPathComponents中,该函数中最终耗时都耗在获取字符串的byte数组的java原 生操作中。
blockReport阶段性能数据采集和瓶颈分析
由于blockReport的调用是通过datanode调用namenode的rpc调用,所以在namenode进入到等待blockreport阶段后,会分别开启rpc调用的监听线程和rpc调用的处理线程。其中rpc处理和rpc鉴定的调用耗时分布如下图所示:

而其中rpc的监听线程的优化是另外一个话题,在其他的issue中再详细讨论,且由于blockReport的操作实际上是触发的rpc处理线程,所以这里只关心rpc处理线程的性能数据。
在namenode处理blockReport过程中的调用耗时性能数据如下:

可以看出,在namenode启动阶段,处理从各个datanode汇报上来的blockReport耗费了整个rpc处理过程中的绝大部分时间(48/49),blockReport处理逻辑中的耗时分布如下图:

从 上图数据中可以发现,blockReport阶段中耗时分布主要耗时在FSNamesystem.addStoredBlock调用以及 DatanodeDescriptor.reportDiff过程中,分别耗时37/48和10/48,其中 FSNamesystem.addStoredBlock所进行的操作时对每一个汇报上来的block,将其于汇报上来的datanode的对应关系初始 化到namenode内存中的BlocksMap表中。所以对于每一个block就会调用一次该方法。所以可以看到该方法在整个过程中调用了774819次, 而另一个耗时的操作,即DatanodeDescriptor.reportDiff,该操作的过程在上文中有详细介绍,主要是为了将该datanode 汇报上来的blocks跟namenode内存中的BlocksMap中进行对比,以决定那个哪些是需要添加到BlocksMap中的block,哪些是 需要添加到toRemove队列中的block,以及哪些是添加到toValidate队列中的block。由于这个操作需要针对每一个汇报上来的 block去查询BlocksMap,以及namenode中的其他几个map,所以该过程也非常的耗时。而且从调用次数上可以看 出,reportDiff调用在启动过程中仅调用了14次(有14个datanode进行块汇报),却耗费了10/48的时间。所以reportDiff 也是整个blockReport过程中非常耗时的瓶颈所在。
同 时可以看到,出了reportDiff,addStoredBlock的调用耗费了37%的时间,也就是耗费了整个blockReport时间的 37/48,该方法的调用目的是为了将从datanode汇报上来的每一个block插入到BlocksMap中的操作。从该方法调用的运行数据如下图所 示:

从 上图可以看出,addStoredBlock中,主要耗时的两个阶段分别是FSNamesystem.countNode和 DatanodeDescriptor.addBlock,后者是java中的插表操作,而FSNamesystem.countNode调用的目的是为 了统计在BlocksMap中,每一个block对应的各副本中,有几个是live状态,几个是decommission状态,几个是Corrupt状 态。而在namenode的启动初始化阶段,用来保存corrput状态和decommission状态的block的map都还是空状态,并且程序逻辑 中要得到的仅仅是出于live状态的block数,所以,这里的countNoes调用在namenode启动初始化阶段并无需统计每个block对应的 副本中的corrrput数和decommission数,而仅仅需要统计live状态的block副本数即可,这样countNodes能够在 namenode启动阶段变得更轻量,以节省启动时间。
瓶颈分析总结
从profiling数据和瓶颈分歧情况来看,fsimage加载阶段的瓶颈除了在分切路径的过程中不够优以外,其他耗时的地方几乎都是在java原生接口的调用中,如从字节流读数据,以及从String对象中获取byte[]数组的操作。
而 blockReport阶段的耗时其实很大的原因是跟当前的namenode设计以及内存结构有关,比较明显的不优之处就是在namenode启动阶段的 countNode和reportDiff的必要性,这两处在namenode初始化时的blockReport阶段有一些不必要的操作浪费了时间。可以 针对namenode启动阶段将必要的操作抽取出来,定制成namenode启动阶段才调用的方式,以优化namenode启动性能。
hadoop namenode启动过程详细剖析及瓶颈分析的更多相关文章
- 【ARM-Linux开发】U-Boot启动过程--详细版的完全分析
---------------------------------------------------------------------------------------------------- ...
- (一)U-Boot启动过程--详细版的完全分析
博客地址:http://blog.csdn.net/hare_lee/article/details/6916325
- Hadoop namenode启动瓶颈分析
NameNode启动过程详细剖析 NameNode中几个关键的数据结构 FSImage Namenode会将HDFS的文件和目录元数据存储在一个叫fsimage的二进制文件中,每次保存fsimage之 ...
- HDFS中NameNode启动过程
移动到hadoop文件目录下 NameNode启动命令:sbin/hadoop-daemon.sh start namenode DataNode启动命令:sbin/hadoop-daemon.sh ...
- HDFS Namenode启动过程
文章作者:luxianghao 文章来源:http://www.cnblogs.com/luxianghao/p/6564032.html 转载请注明,谢谢合作. 免责声明:文章内容仅代表个人观点, ...
- 【5】namenode启动过程
1.格式化空间(第一次启动的操作): 命令:bin/hadoop -format //用于格式化HDFS,如果不是首次格式化,需要删除下面配置的tmp目录后再进行core-site.xml的配置: / ...
- hadoop namenode启动失败
hadoop version=3.1.2 生产环境中,一台namenode节点突然挂掉了,,重新启动失败,日志如下: Info=-64%3A1391355681%3A1545175191847%3AC ...
- Symfony启动过程详细学习
想了解symfony的启动过程,必须从启动文件(这里就以开发者模式)开始. <?php /* * web/app_dev.php */ $loader = require_once __DIR_ ...
- 4、NameNode启动过程详解
NameNode 内存 本地磁盘 fsimage edits 第一次启动HDFS 格式化HDFS,目的就是生成fsimage start NameNode,读取fsimage文件 start Data ...
随机推荐
- hibernate初探
1.在MyEclipse Datebase Explorer 页面中新创建一个连接数据库“DB Browser”的XX,如起名“register”2.新建项目->右键Properties-> ...
- 306573704 Char型和string型字符串比较整理(转)
1.赋值 char赋值: char ch1[] = "give me"; char ch2[] = "a cup"; strcpy(ch1,ch2); cout ...
- [Guava官方文档翻译] 6. 用Guava辅助Throwable异常处理 (Throwables Explained)
我的技术博客经常被流氓网站恶意爬取转载.请移步原文:http://www.cnblogs.com/hamhog/p/3537508.html ,享受整齐的排版.有效的链接.正确的代码缩进.更好的阅读体 ...
- 安装FreeMind
Freemind 1.0.0 官方正式版下载地址:http://dl.pconline.com.cn/html_2/1/131/id=46751&pn=0.html 软件介绍: Freemin ...
- Newtonsoft.Json随手记
private static Newtonsoft.Json.JsonSerializerSettings CreateSettings(string dateFormat) { Newtonsoft ...
- 栈(链式存储) C++模板实现
#include <iostream> using namespace std; //栈结点类 template <typename T> class stackNode{ p ...
- RX学习笔记:正则表达式
正则表达式 2016-07-03 正则表达式是以字符串模板的形式匹配查找字符的方式. 正则表达式是字符串模板,所以其本身是一个字符串,首尾以反斜杆 / 开始和结束. 在两反斜杆中间的字符串表示要查找的 ...
- 客户端获取服务器SessionID (Asp.net SessionID)
SessionID是客户端首次访问某个方法或页面, 并且这个方法中设置了Session["xxx"]=xx; 此时服务器返回的响应头(HttpResponse.Headers)中会 ...
- Linux下18b20温度传感器驱动代码及测试实例
驱动代码: #include <linux/module.h> #include <linux/fs.h> #include <linux/kernel.h> #i ...
- osg 基本几何图元
转自:osg 基本几何图元 //osg 基本几何图元 // ogs中所有加入场景中的数据都会加入到一个Group类对象中,几何图元作为一个对象由osg::Geode类来组织管理. // 绘制几何图元对 ...