TPS低,CPU高--记一次storm压测问题排查过程
一、业务背景+系统架构
本次场景为kafka+storm+redis+hbase,通过kafka的数据,进入storm的spout组件接收,转由storm的Bolt节点进行业务逻辑处理,最后再推送进kafka。
表数据相关的逻辑为:查询Hbase表数据,首次查询会写入redis和storm cache,再次查询,会直接从redis或cache中取值。
storm应用:

二、性能测试场景
1.数据:json类型的用户偏好数据700万
2.灌入方式:java脚本
3.hbase表:生产全量数据导入
4.storm集群:5台 (Nimbus+sup01+sup02+sup03+sup04)
三、性能过程截图
三分钟时处理数据量:
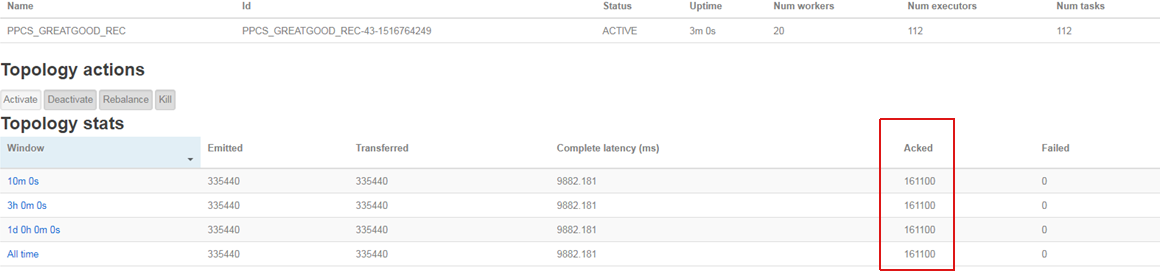
storm响应时间(不包含kafka延时)

十三分钟处理数据量:
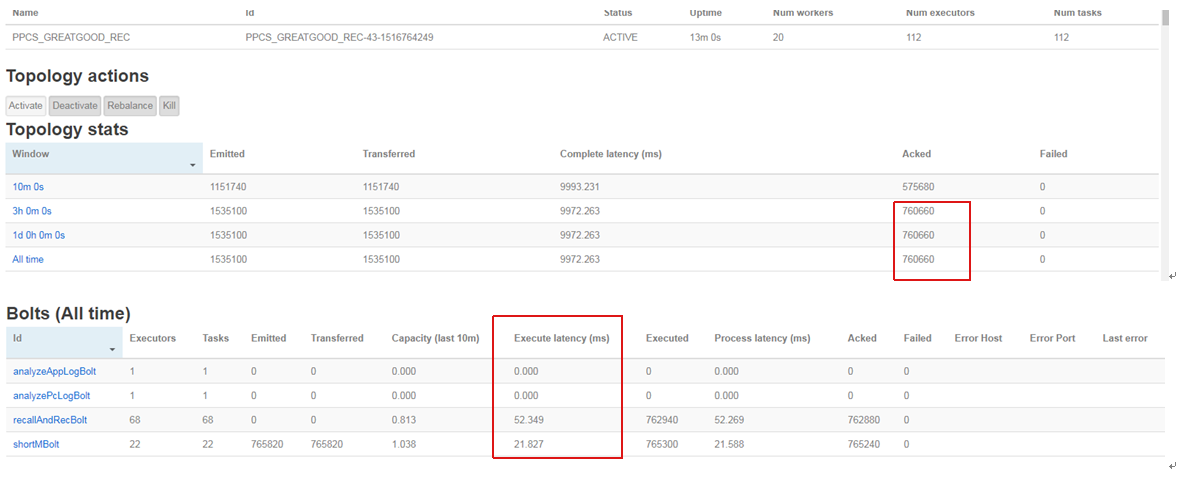
从stormUI接口估算出的TPS大约为970左右,远没有达到我们业务要求。
四、性能瓶颈分析:
1、直接查看storm应用服务器的情况:

发现 cpu从20%直接到80%
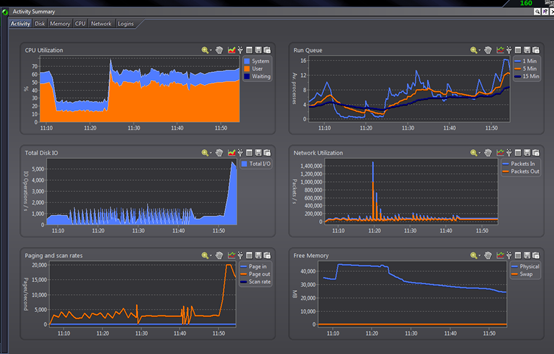
CPU资源显然在user态消耗的更多,判断为用户类进程占用的cpu时间片更多。
2、我们按消耗cpu资源的大小对进程进行排序,抓出最大的进程号16889,然后打印进程下面的线程:
命令:ps -mp pid -o THREAD,tid,time
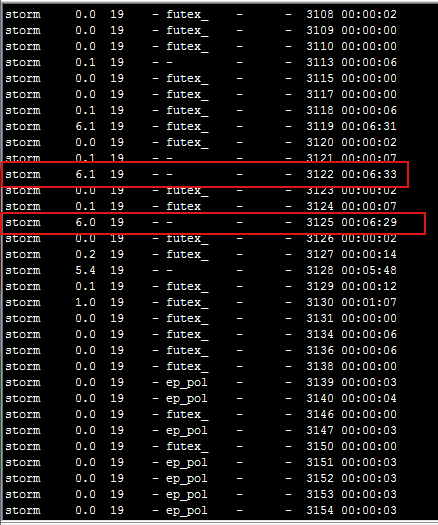
3.挑出占用cpu时间最高的线程,打印线程栈信息,注意线程id(tid)必须转化成16进制
命令:printf "%x\n" tid
jstack pid |grep tid -A 30
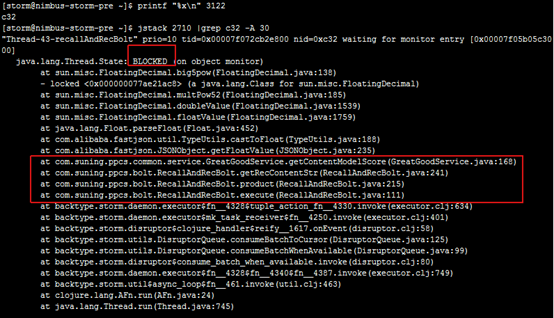
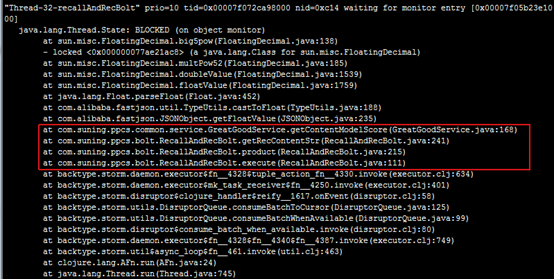
此处不逐一举例线程信息,Niubus主机和其他从机都需选取一些线程进行打印,发现耗时长的线程大部分都处于Blocked状态,线程状态为执行getcontentmodelscore方法。
检查getcontentmodelscore这部分代码:
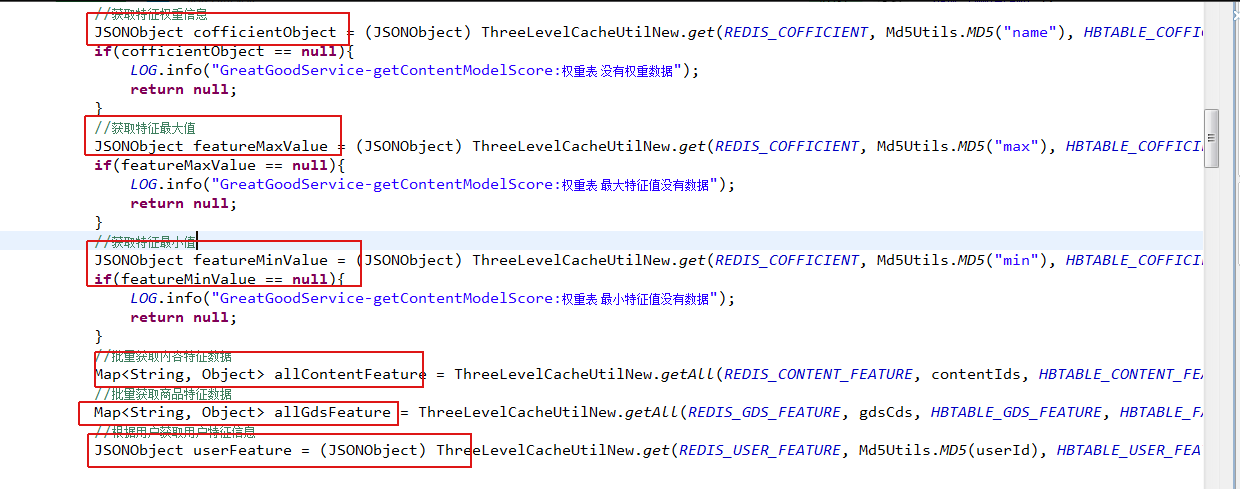
发现这部分代码逻辑为从Hbase中获取得分数据和推荐商品数据,判断为hbase性能不佳引起的性能低下,由于PRE环境HBASE条件有限,没有监听端口,也无权限进行配置优化,此问题暂时没有进一步解决方案。
五、第二种排查方案:
由于stormUI提供了可视化的界面,我们可以点开处理时间长的bolt下找到对应的端口号:

在host一栏查到对应的机器地址,通过Jps -m |grep 命令找到对应的进程号,此方法适用于多个业务系统公用一个集群,需要快速定位Pid的时候。
六、附redis监控:
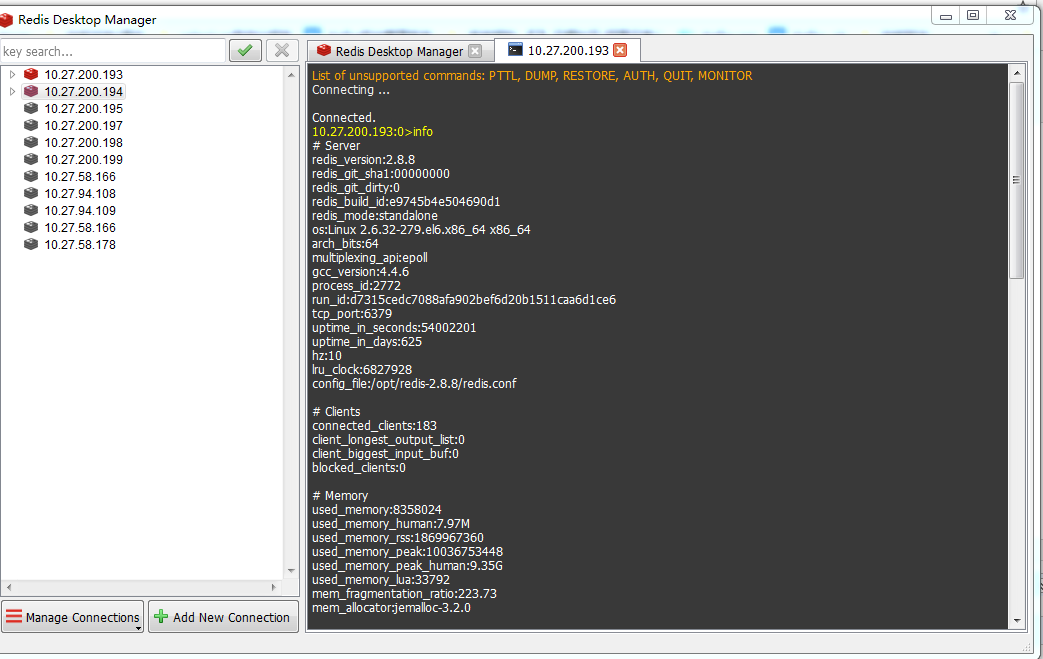
在redis工具中敲入info,查看连接数和使用内存。
由于redis是在内存中运行,不需要考虑命中率;redis单线程运行,如果redis查得慢的话基本可能是一次获取的数据太多了或者程序逻辑不对,不需要考虑慢查询。对于redis,只要不一次获取太多的Key-value,基本不会出现性能问题。
七、strorm worker executor配置问题:
storm中worker代表了进程,比如配置10个worker,5台机器,每个机器会均衡分配2个worker,executor代表线程数,对于每个Bolt,spout节点都可增大减小线程数,达到最佳的处理数据效率。
在本次压测时,10个worker配置了100个线程数,发现性能远不如10个worker配置60个线程,对于kafka,我们知道,一个kafka分区只需对应一个线程,多配置的线程也会处于闲置状态,但并没出现由于多配置线程儿造成的性能降低。而对于storm,对于多配置的线程,反而出现了性能的严重降低。此问题暂时未知道具体原因。
TPS低,CPU高--记一次storm压测问题排查过程的更多相关文章
- 记一次redis读取超时的排查过程(SADD惹的祸)
问题背景 在业务使用redis过程中,出现了read timeout 的异常. 问题排查 直接原因 运维查询redis慢查询日志,发现在异常时间节点,有redis慢查询日志,执行sadd 命令花费了1 ...
- 记一次eclipse无法启动的排查过程
起因是本地为开发工程打包,总是提示 source 1.3 不支持注释.enum等等,但询问开发开发表示自己本地打包正常. 于是排查版本问题.开发的jdk是1.6版本,自己的是1.7,于是想要不降级吧, ...
- Atitit. 最佳实践 QA----降低cpu占有率--cpu占用太高怎么办
Atitit. 最佳实践 QA----降低cpu占有率--cpu占用太高怎么办 跟个磁盘队列长度雅十,一到李80%走不行兰.... 1. 寻找线程too 多的.关闭... Taskman>> ...
- 记一次排查CPU高的问题
背景 将log4j.xml的日志级别从error调整为info后,进行压测发现CPU占用很高达到了90%多(之前也就是50%,60%的样子). 问题排查 排查思路: 看进程中的线程到底执行的是什么, ...
- 压测过程中,CPU和内存占用率很高,案例简单分析
Q: 最近公司测试一个接口,数据库采用Mongo 并发策略:并发400个用户,每3秒加载5个用户,持续运行30分钟 数据量:8000条左右 压测结果发现: TPS始终在5左右 ...
- nginx cpu高排查
首先查看nginx的error日志,无异常打印. cpu占用如下图所示: top - 10:05:40 up 233 days, 16:28, 4 users, load average: 25.53 ...
- 查看tomcat项目中,具体占用cpu高的线程。
1.查看主进程占用cpu高: 此处主进程:27823 ~]# top top - :0: up days, :, 3 users, load average: 13.12, 13.31, 13.23 ...
- MySQL SYS CPU高的案例分析(二)
原文:MySQL SYS CPU高的案例分析(二) 后面又做了补充测试,增加了每秒context switch的监控,以及SQL执行时各步骤消耗时间的监控. [测试现象一] 启用1000个并发线程的压 ...
- MySQL SYS CPU高的案例分析(一)
原文:MySQL SYS CPU高的案例分析(一) [现象] 最近关注MySQL CPU告警的问题时,发现有一种场景,有一些服务器最近都较频繁的出现CPU告警,其中的现象是 SYS CPU占比较高. ...
随机推荐
- 高可用集群(crmsh详解)http://www.it165.net/admin/html/201404/2869.html
crmsh是pacemaker的命令行接口工具,执行help命令,可以查看shell接口所有的一级命令和二级命令,使用cd 可以切换到二级子命令的目录中去,可以执行二级子命令 在集群中的资源有四类:p ...
- webpack命令局部运行的几种方法
webpack命令局部运行的几种方法 1. 第一种,先全局安装webpack 命令:npm install -g webpack 然后再在项目内安装 命令:npm install webpack ...
- mysql group by分组查询
分组的SQL语句有2个: group by 和分组聚合函数实现 partition by (oracle和postgreSQL中的语句)功能 group by + having 组合赛选数据 注意:h ...
- C++ 查看预处理后的源文件(查看真实代码)
gcc -E filename.cpp 会生成 filename.cpp 的预处理文件,这样就能看到宏展开后的代码,用于理解和调试宏非常有帮助. http://www.qtdebug.com/cp ...
- ArrayList底层实现
ArrayList 底层是有数组实现,实际上存放的是对象的引用,而不是对象本身.当使用不带参的构造方法生成ArrayList对象时,实际会在底层生成一个长度为10的数组 当添加元素超过10的时候,会进 ...
- MacOS & dock 工具栏 & 外接显示器 & 主屏
MacOS & dock 工具栏 & 外接显示器 & 主屏 macos 如何将 dock工具栏从外接显示器拖回主屏 https://support.apple.com/zh-c ...
- HDU4183_Pahom on Water
题意为给你若干个圆,每个圆的颜色对应一个频率,如果两个圆有公共部分,那么这两个圆之间可以走,你可以从起点开始,从频率小的圆走向频率大的圆并且到达终点后,从频率大的圆走向频率小的圆,最终回到起点,路径中 ...
- BZOJ4553: [Tjoi2016&Heoi2016]序列 树套树优化DP
把pos[i]上出现的平常值定义为nor[i]最大值定义为max[i]最小值定义为min[i],那么我们发现在两个值,i(前),j(后),当且仅当max[i]<=nor[j],nor[i]< ...
- 学习Spring Boot:(九)统一异常处理
前言 开发的时候,每个controller的接口都需要进行捕捉异常的处理,以前有的是用切面做的,但是SpringMVC中就自带了@ControllerAdvice ,用来定义统一异常处理类,在 Spr ...
- 【BZOJ2463】谁能赢呢?(博弈论)
[BZOJ2463]谁能赢呢?(博弈论) 题面 BZOJ 洛谷 题解 洛谷上对于难度的评级我总觉有些问题. 很多人按照代码难度而并非思维难度在评级,导致很多评级很不合理啊... 不说废话了.. 对于一 ...