京东全链路压测军演系统(ForceBot)架构解密

ForceBot愿景
1、诞生背景
伴随着京东业务的不断扩张,研发体系的系统也随之增加,各核心系统环环相扣,尤其是强依赖系统,上下游关系等紧密结合,其中一个系统出现瓶颈问题,会影响整个系统链路的处理性能,直接影响用户购物体验。
往年的 618、双 11 大促备战至少提前 3 个月时间准备,投入大量的人力物力去做独立系统的线上压力评测,带来的问题就是各个性能压测团队工作量非常大,导致压测任务排期,压测的数据跟线上对比不够准确,各个强依赖系统上下游需要在压测中紧密配合,一不小心就会影响线上。有的在线下测试环境压测,压测出的数据更是跟线上差距太大,只能作为参考。
更重要的一个问题是系统容量规划,每次大促前备战会必不可少的讨论话题就是服务器资源申请扩容问题,各团队基本都是依据往年经验和线上资源使用率给出评估量,提出一个扩容量需求,导致各个业务系统每次促销扩容量非常大。
为了解决以上各种苦恼,2016 年基础平台部整体牵头启动了 ForceBot 全链路压测(备战常态化)这个项目,此项目牵扯到所有京东研发体系团队,各系统必须改造,压测过来的流量和线上正式流量进行区分标记特殊处理,不能因为压测流量影响正常用户体验和污染线上数据等工作。由于跨团队协作之多、跨系统协调改造等工作量非常大,挑战性可想而知!
2、能做什么
2016年主要实现了订单前的所有黄金链路流程高并发压测用户行为模拟,包括模拟用户操作:首页、登陆、搜索、列表、频道、产品详情、购物车、结算页、京东支付等。在黄金链路中有各种用户行为场景,比如一般用户首先访问首页,在首页搜索想要产品,翻页浏览,加入购物车、凑单、修改收货地址、选择自提等等。
各系统压测量依据往年双 11 峰值作为基础量,在此基础上动态增加并发压力;同时要区分对待两个大的场景,日常流量和大促流量。大促场景下抢购活动集中,交易中心写库压力最大,另外用户行为和日常有很大的反差,比如用户会提前加入购物车,选择满减凑单,集中下单等等场景。
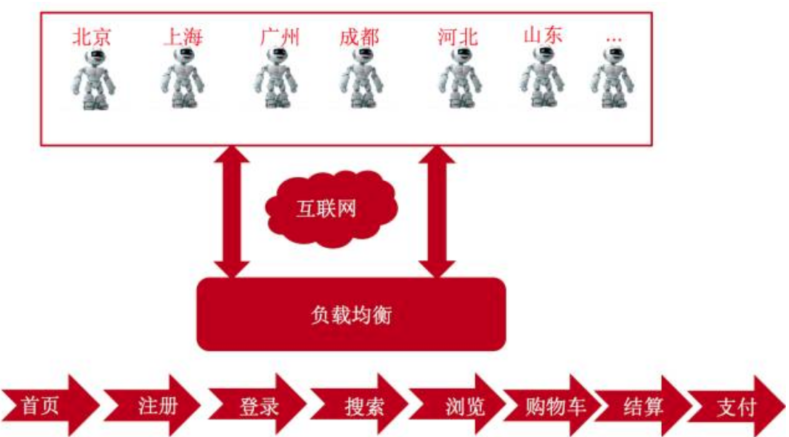
2016 年启用的链路较短,在 2017 年将实现订单后生产的全链路。
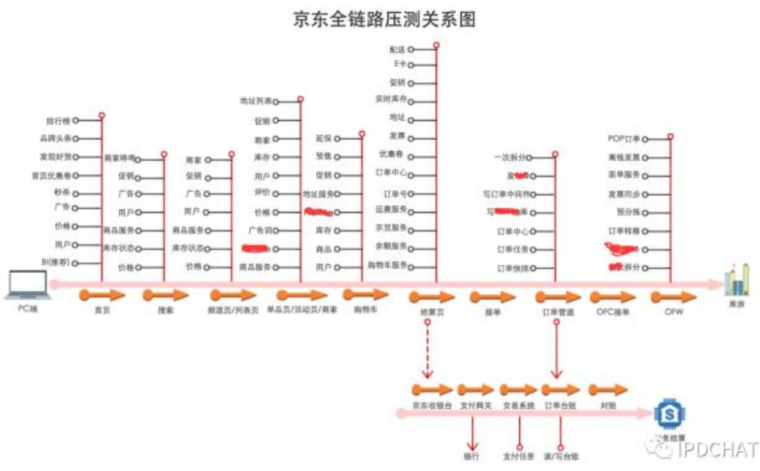
3、价值体现
ForceBot 在 2016 年双 11 替代往年各系统独自优化及性能压测备战状态,目前所有的备战数据和各系统性能承载能力、资源规划等都由 ForceBot 给出直接数据作为依据。
在军演压测过程中,秒级监控到压测源、压测中、京东所有的黄金链路系统、接口响应时间、TPS、TP99 等数据,军演完成后提供丰富的压测报告,准确的找到各系统并发瓶颈。

同时也承担了内网单一系统的日常压测任务,开放给研发和压测团队,支撑京东所有的压测场景统一压测平台,对公司内压测资源的整合和提高利用率。
ForceBot 技术架构
工欲善其事,必先利其器。全链路压测必须要有一套功能强大的军演平台,来实现自动化、全链路、强压力的核心目标。
1、第一代性能测试平台
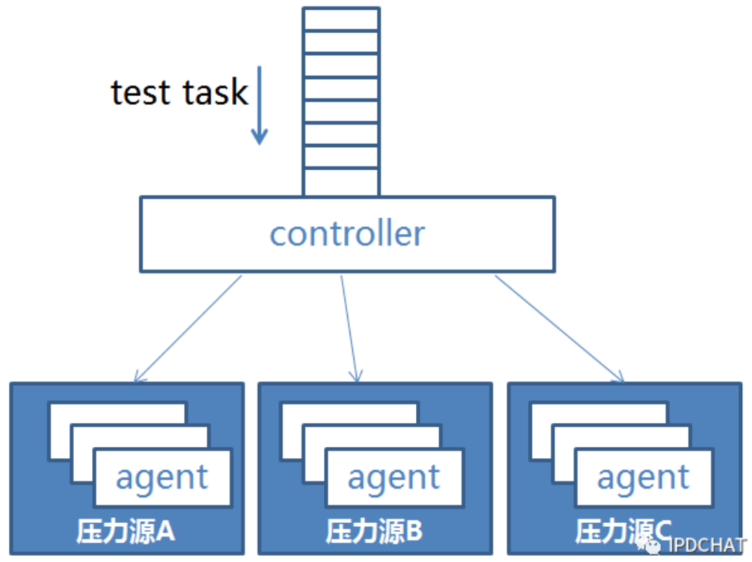
基于 Ngrinder 做定制开发。 Ngrinder 是一个 Java 语言开源的、分布式性能测试平台。它由一个 controller、多个 agent 组成,在 controller 建立测试场景,分发到 agent 进行压力测试,压力源将压测数据上报给 controller。
Ngrinder 基于开源的 Java 负载测试框架 grinder 实现,并对其测试引擎做了功能提升,支持 Python 脚本和 groovy 脚本;同时提供了易用的控制台功能,包括脚本管理、测试计划和压测结果的历史记录、定时执行、递增加压等功能。
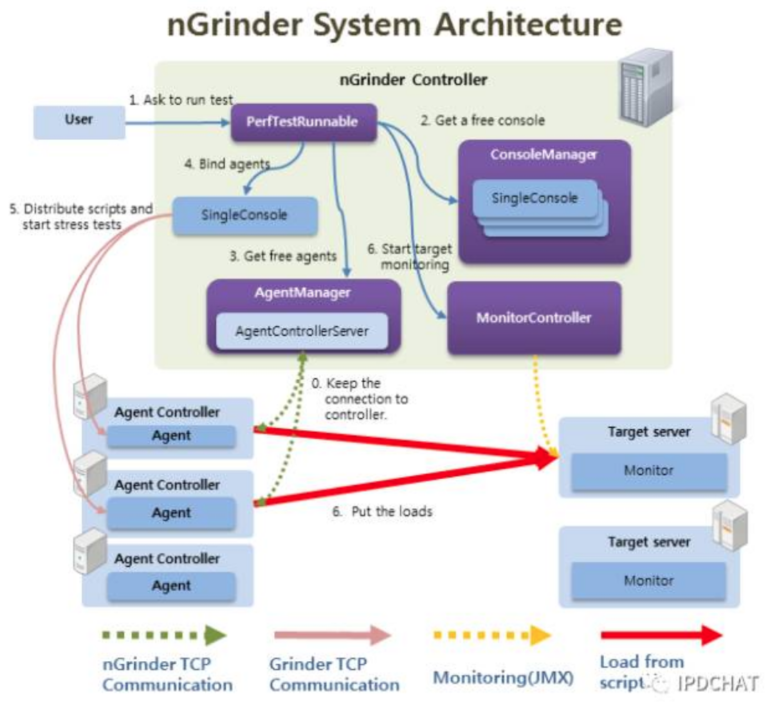
我们根据京东的业务场景对 Ngrinder 进行了优化,以满足我们的功能需求。比如:提升 agent 压力,优化 controller 集群模式,持久化层的改造,管理页面交互提升等。
Ngrinder能胜任单业务压测,但很难胜任全链路军演压测。分析其原因是 controller 功能耦合过重,能管理的 agent 数目有限,原因如下
controller 与 agent 通讯是 bio 模式,数据传输速度不会很快;
controller 是单点,任务下发和压测结果上报都经过 controller,当 agent 数量很大时,controller 就成为瓶颈。
说得通俗点,controller 干的活又多又慢,整体压力提升不上去。尽管我们优化了 controller 集群模式,可以同时完成多种测试场景。但是集群之间没有协作,每个 controller 只能单独完成一个测试场景。由此我们着手研发全链路军演压测系统(ForceBot)。
2、ForceBot架构
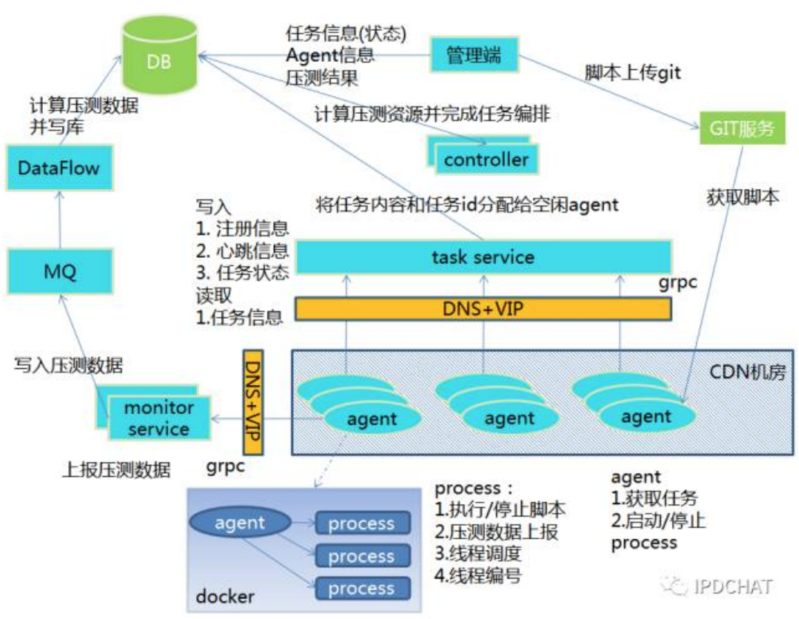
新平台在原有功能的基础上,进行了功能模块的解耦,铲除系统瓶颈,便于支持横向扩展。
对 controller 功能进行了拆解,职责变为单一的任务分配;
由 task service 负责任务下发,支持横向扩展;
由 agent 注册心跳、拉取任务、执行任务;
由 monitor service 接受并转发压测数据给 JMQ;
由 dataflow 对压测数据做流式计算,将计算结果保存在 DB 中;
由 git 来保存压测脚本和类库。 Git 支持分布式,增量更新和压缩
这样极大的减轻了 controller 的负载压力,并且提升了压测数据的计算能力,还可以获取更多维度的性能指标。
在此基础上,还融合进来了集合点测试场景、参数下发、TPS 性能指标等新特性。下面将重点介绍以下几个功能:
容器部署
为了快速的创建测试集群,Agent 采用 Docker 容器通过镜像方式进行自动化部署。这样做好处如下
利用镜像方式,弹性伸缩快捷;
利用 Docker 资源隔离,不影响 CDN 服务;
每个 Agent 的资源标准化,能启动的虚拟用户数固定,应用不需要再做资源调度;
问题:Git 测试脚本如何在各个 Docker 之间共享?
解决方案:采用外挂宿主机的共享磁盘实现。
任务分配
用户在管理端创建一个测试场景,主要包括:压力源(分布在不同机房的压力机)、虚拟用户数、测试脚本、定时执行时间、process JVM 参数,压力源,启动模式,集合点设置,选择测试脚本。
这个测试场景保存到 db 后,controller 按照时间顺序,扫描发现有测试场景了,会根据标签算法寻找当前存活的空闲的 agent 资源,并计算 agent 的每个 worker process 启动的线程数。
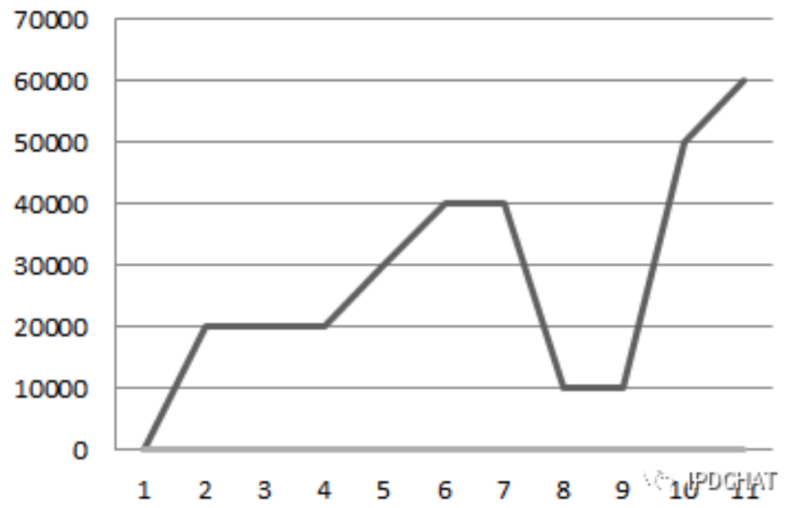
任务分配时,要考虑集合点的计算,就是虚拟用户数在不同的时间点不断变化。目前有两种方式:毛刺型和阶梯型。毛刺型,就是在某个时间点有大量的请求瞬时访问业务系统,这样做可以测试系统的并发能力和吞吐量。阶梯型,就是在相等时间间隔,虚拟用户数等值递增。
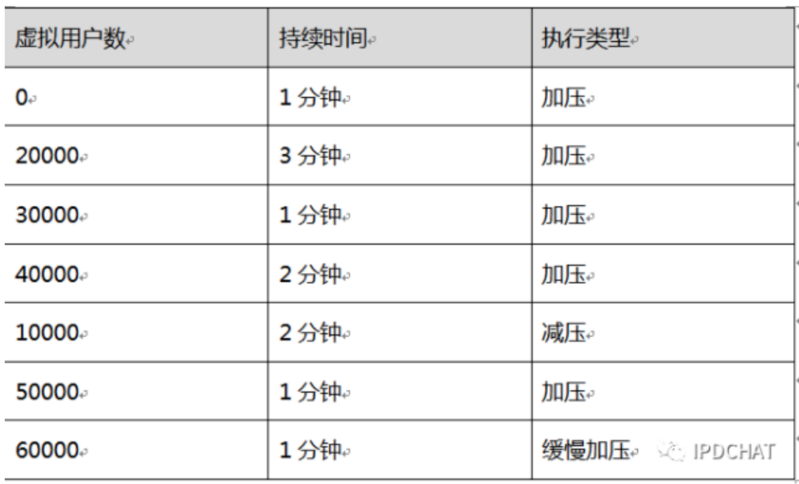
比如:一个测试场景在今天 9 点执行 10000 个虚拟用户数,执行到 9 点 01 分要虚拟用户数变为 20000 个,到 9 点 05 分虚拟用户数又变为 40000 个,到 9 点 07 分虚拟用户数变为 10000 个,虚拟用户数像毛刺一样上下变化。
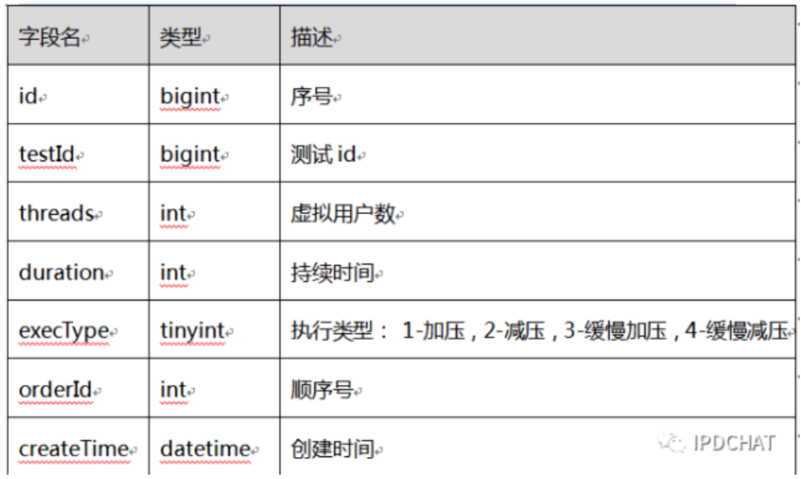
上面的表格就是对应表结构设计,每个压力线会按照顺序保存到 db 中。在这张表中,只记录的持续时间,具体的执行时间是由 controller 根据开始压测时间累加持续时间逐一计算出来。execType 还包含了缓慢加压减压两种类型,覆盖了阶梯型,默认时间间隔为 5 秒。
controller 要计算出每个间隔的执行时间点,递增的虚拟用户数。controller 将计算结果分给每个 agent,保存到 db 中,由 agent 定时来拉取。
动态加压减压目前只支持采用 Agent 的增减方式来实现。
问题:由于购物车是用户共享的,在压测下单过程中,同一个用户并发操作会出现冲突?
解决方案:为每个压测线程绑定使用不同的用户。在任务分配过程中,为每个 process 进程中的线程分配线程编号。不同的线程根据编号,按照映射规则,找到相应的压测用户。

心跳任务和下发
task service 为 agent 提供了任务交互和注册服务,主要包括 agent 注册、获取任务、更新任务状态。
agent 启动后就会到 task service 注册信息,然后每个几秒就会有心跳拉取一次任务信息。controller 会根据注册的信息和最近心跳时间来判断 agent 是否存活。
agent 拉取任务和执行任务过程中,会将任务状态汇报给 task service。controller 会根据任务状态来判断任务是否已经结束。
task service 采用了 gRPC 框架,通过接口描述语言生成接口服务。gRPC 是基于 http2 协议,序列化使用的是 protobuf3,Java 语言版采用 netty4 作为网络 IO 通讯。
使用 gRPC 作为服务框架,主要原因有两点:
服务调用有可能会跨网络,可以提供 http2 协议;
服务端可以认证加密,在外网环境下,可以保证数据安全。
Agent 实现
agent 职责主要是注册,获取任务信息,更新任务状态,执行和停止 worker process 进程,同时上报压测数据。通信协议主要是 gRPC。
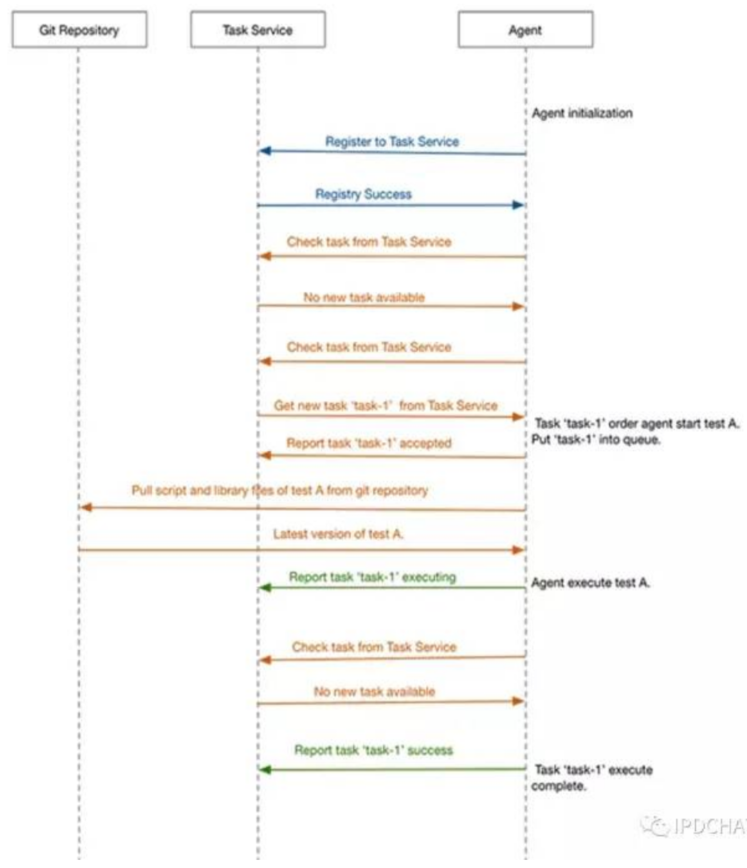
Agent 启动后生成 UUID 作为当前 Agent 的唯一标识,并向 Task Service 进行注册。如果 Agent 进程挂掉重启后,会产生新的 UUID,放弃原来的任务。
Agent 心跳线程每隔 3 秒从 Task Service 拉取任务。获取到任务后,会把任务扔到队列里面,并上报任务接收状态,不阻塞当前拉取线程。
任务执行线程从队列获取任务,如果是启动新的测试任务,则先从 Git 拉取任务所需的脚本文件和用户的自定义类库。然后根据 JVM 参数,设置并启动 worker process 进程,同时将任务的执行时间,虚拟用户数,集合点设置信息,压测脚本信息,以及脚本加载 plugin 所需要的 classpath 传递给 worker process。在这里我们采用使 Agent 通过 stdout 的方式与 Worker process 对 stdin 的监听构成一个数据传输通道,采用 Stream 的方式将任务的所有信息和数据发送给 Worker process,使 Worker process 可以获取到足够且结构化的数据以完成初始化的工作。
问题:一台物理机上多个 Docker 实例,如何减少更新测试脚本造成的 git 压力?
解决方案:测试脚本存放到宿主机共享存储,更新前,按照测试任务编号进行文件锁,如果锁成功则调用 git 更新。同一个测试任务就可以减少 git 压力。
问题:如何模拟在某一个瞬间压力达到峰值?
解决方案:通过集合点功能实现,提前开启峰值所需足够数量的线程,通过计算确定各个时间点上不需要执行任务的线程数量,通过条件锁让这些线程阻塞。当压力需要急剧变化时,我们从这些阻塞的线程中唤醒足够数量的线程,使更多的线程在短时间进入对目标服务压测的任务。
数据收集和计算
实现秒级监控。数据的收集工作由 monitor service 完成,也是采用 gRPC 作为服务框架。Agent 每秒上报一次数据,包括性能,JVM 等值。
monitor service 将数据经 JMQ 发送给 dataflow 平台,进行数据的流式计算后,产生 TPS,包括 TP999,TP99,TP90,TP50,MAX,MIN 等指标存储到 ES 中进行查询展示。
问题:为了计算整体的 TPS,需要每个Agent把每次调用的性能数据上报,会产生大量的数据,如果进行有效的传输?
解决方案:对每秒的性能数据进行了必要的合并,组提交到监控服务
业务系统改造
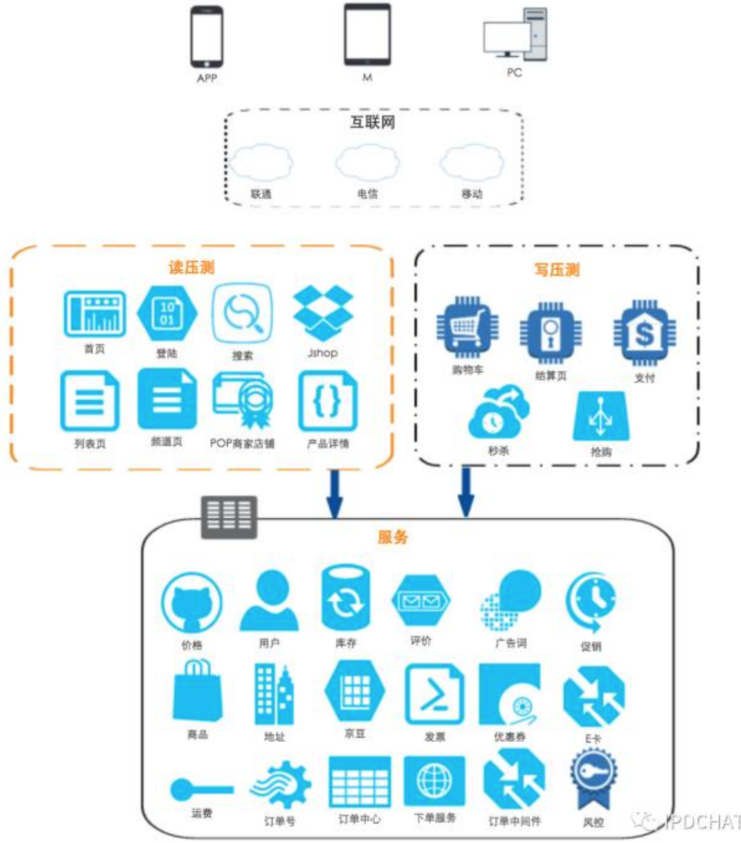
1、黄金流程业务
首期识别从用户浏览到下单成功的黄金流程,其包含的核心业务如下:
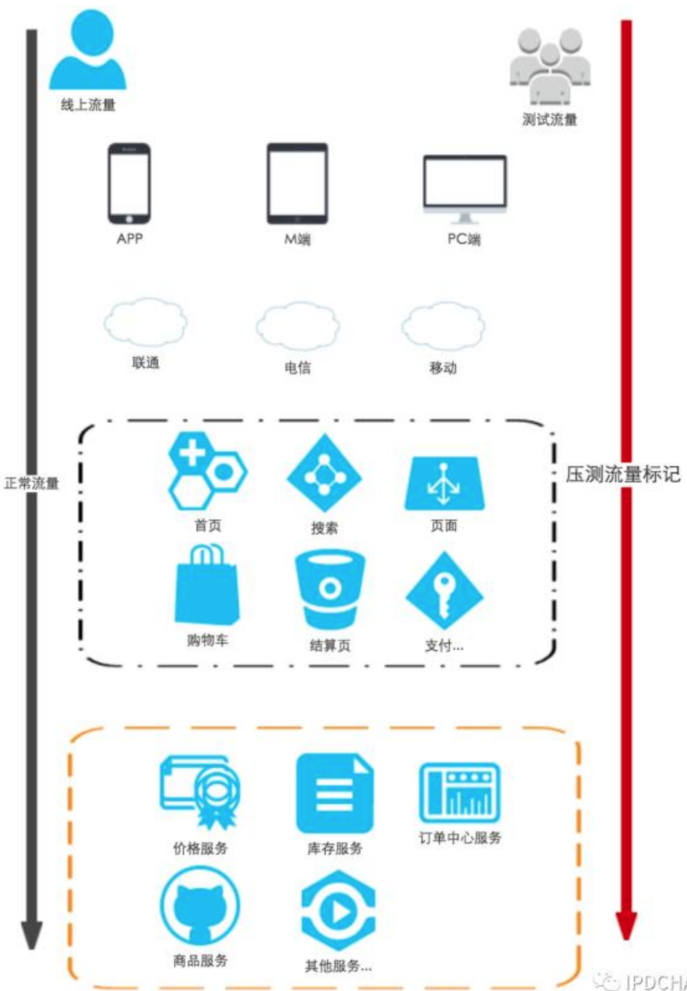
2、压测流量识别
压测流量是模拟真实用户行为,要保障在军演过程中不能污染线上各种统计等数据,比如:PV UV 订单量等,更不能影响正常用户下单购物体验。
首先要对用户、商品进行打标,以便于各个系统进行测试流量识别。
针对下单压测,库存系统需要根据测试用户和商品提前准备好库存量。
风控系统需要放行测试用户和商品的操作。
3、压测数据存储
业务系统识别出压测数据后,根据不同的场景,采用两种方式来存放压测数据。
打标数据并存储到生产库中,压测的数据能体现生产环境性能。定期清理测试数据。统计报表要过滤掉测试数据。改方案能利用现有资源,需要系统进行较多改造。
构造压测库环境,根据压测流量,把压测数据存放到压测库中进行隔离。改方案需要较多的资源,但系统改造量小。支付系统最大的改造困难就是银行接口的强依赖,不能用真实的银行卡扣款和支付,ForceBot的目标不是压银行接口,而是压自己本身的支付系统,所以京东这边支付团队目前是自己造了一个假银行,假接口,通过前端传递过来的压测标识,自动路由到假银行进行扣款支付;
ForceBot 未来规划
ForceBot 未来的路还很长,要做的优化、功能也很多,比如有:
无人值守智能压测,通过监控系统监控到各个被压系统的性能问题,如遇到系统瓶颈问题联动 JDOS 系统弹性扩容 docker 资源,扩容到一定量级后发现性能没有提升,停止此压测,由 callgraph 自动找到性能系统位置;
人工智能预言:根据大数据人工智能学习计算,在 ForceBot 中设定订单量目标值(秒级订单量、日订单量等),根据日常的军演数据自动计算出各链路系统将要承载的军演并发量,给出智能评估各系统的瓶颈所在,预测各系统的性能指标和瓶颈问题。
“在线全链路压测,军演备战常态化,将是我们的终极目标。”
京东全链路压测军演系统(ForceBot)架构解密的更多相关文章
- 【转】京东金融App端链路服务端全链路压测策略
京东金融移动端全链路压测历时三个月,测试和服务端同学经过无数日日夜夜,通宵达旦,终于完成了移动端链路的测试任务.整个测试有部分涉及到公司敏感数据,本文只对策略部分进行论述. 1.系统架构与策略 在聊性 ...
- <转>二十问全链路压测干货汇总(上)
本文转载自:微信公众号-数列科技<二十问全链路压测干货汇总(上)> 最近几年全链路压测无疑成为了一个热门话题,在各个技术峰会上都可以看到它的身影. 一些大型的互联网公司,比如阿里巴巴.京东 ...
- 全链路压测平台(Quake)在美团中的实践
背景 在美团的价值观中,以“客户为中心”被放在一个非常重要的位置,所以我们对服务出现故障越来越不能容忍.特别是目前公司业务正在高速增长阶段,每一次故障对公司来说都是一笔非常不小的损失.而整个IT基础设 ...
- 高德全链路压测平台TestPG的架构与实践
导读 2018年十一当天,高德DAU突破一个亿,不断增长的日活带来喜悦的同时,也给支撑高德业务的技术人带来了挑战.如何保障系统的稳定性,如何保证系统能持续的为用户提供可靠的服务?是所有高德技术人面临的 ...
- 让全链路压测变得更简单!Takin2.0重磅来袭!
自Takin社区版1.0发布两个多月以来,有很多测试同学陆续在各自的工作中运用了起来,其中包括金融.电商.物流.出行服务等行业.这个过程中我们收到了很多同学的反馈建议,同时也了解到很多同学在落地全链路 ...
- 生产环境全链路压测平台 Takin
什么是Takin? Takin是基于Java的开源系统,可以在无业务代码侵入的情况下,嵌入到各个应用程序节点,实现生产环境的全链路性能测试,适用于复杂的微服务架构系统. Takin核心原理图 Taki ...
- 美团--Quake全链路压测平台
原文:连接: https://tech.meituan.com/2018/09/27/quake-introduction.html 开源分布式监控Cat: https://github.com/di ...
- 性能利器 Takin 来了!首个生产环境全链路压测平台正式开源
6 月 25 日,国内知名的系统高可用专家数列科技宣布开源旗下核心产品能力,对外开放生产全链路压测平台产品的源代码,并正式命名为 Takin. 目前中国人寿.顺丰科技.希音.中通快递.中国移动.永辉超 ...
- Dubbo接口压测
在每年的双十一大促之前,除了全链路压测,还需要各个业务方对自己业务提供的核心接口进行单接口压测,以评判系统的稳定性和承压能力. 一.准备工作 环境准备:确保应用性能环境(perf)正常可用 压测接口梳 ...
随机推荐
- HDU 1015 Jury Compromise 01背包
题目链接: http://poj.org/problem?id=1015 Jury Compromise Time Limit: 1000MSMemory Limit: 65536K 问题描述 In ...
- 四则运算web版
1)在文章开头给出Coding.Net项目地址.(1') https://git.coding.net/meiyoupiqidefan/jieduizuoye.git url测试地址:http://3 ...
- 通用的将Excel导入数据集的方法
http://blog.csdn.net/baronyang/article/details/7048563
- modify headers插件的使用
Modity headers是firefox浏览器的一个插件,作用是改变http请求的IP地址 (一)在firefox中添加该插件 步骤一:打开firefox浏览器,打开地址: https://add ...
- [转帖]windows 2008 Server R2 /Win7启用TLS 1.2
来自新浪博客的 一个文章 自己很早之前曾经看过 iis的加密工具 但是当时没有认识到TLS1.2协议的问题 这里 晚上学习了一下. http://blog.sina.com.cn/s/blog_16 ...
- Everyone is tester
有一本书叫<人人都是产品经理>,作者在书中介绍了在做产品的过程中学到的思维方式和做事方式,受到行业大众的认可 作为一名测试老鸟,我想说,其实Everyone is tester 为 ...
- DAY8-Python学习笔记
老样子课有点多,睡觉有点多,玩手机有点多,总结就是事情有点多.Python项目还没找好所以就没上手. 今天学习内容贴几张图...
- P4867 Gty的二逼妹子序列
题目描述 Autumn和Bakser又在研究Gty的妹子序列了!但他们遇到了一个难题. 对于一段妹子们,他们想让你帮忙求出这之内美丽度∈[a,b]的妹子的美丽度的种类数. 为了方便,我们规定妹子们的美 ...
- view的阴影效果shadowColor
btn.layer.shadowColor = UIColor.blackColor().CGColor btn.layer.shadowOffset = CGSizeMake(5, 5) btn.l ...
- BZOJ 1180: [CROATIAN2009]OTOCI
1180: [CROATIAN2009]OTOCI Time Limit: 50 Sec Memory Limit: 162 MBSubmit: 989 Solved: 611[Submit][S ...