数据预处理:规范化(Normalize)和二值化(Binarize)
注:本文是人工智能研究网的学习笔记
规范化(Normalization)
Normalization: scaling individual to have unit norm
规范化是指,将单个的样本特征向量变换成具有单位长度(unit norm)的特征向量的过程。当你要使用二次形式(quadratic from)如点积或核变换运算来度量任意一堆样本的相似性的时候,数据的规范化会非常的有用
假定是基于向量空间模型,经常被用于文本分类和内容的聚类。
函数normalize提供了快速简单的方法使用L1或L2范数(距离)执行规范化操作:
X = [[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]]
X_normalized = preprocessing.normalize(X, norm='l2')
X_normalized

注意:该函数按行操作,把每一行变成单位长度。使用每一个元素去除以欧式距离。
preprocessing模块也提供了一个类Normalizer实现了规范化操作,该类是一个变换器Transformer,具有Transformer API(尽管fit方法在这种时候是没有用的: 该类是一个静态类因为归一化操作是将每一个样本单独进行变换,不存在在所有样本上的统计学习过程。)
规范化操作类Normalizer作为数据预处理步骤,应该用在Pineline管道流的早期阶段。
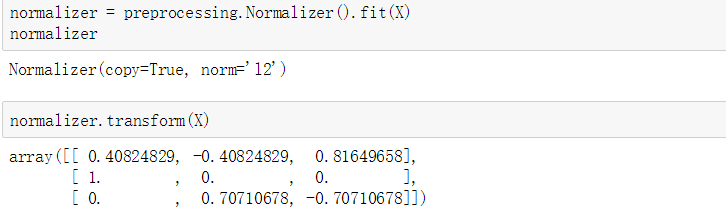
以上的transform过程不依赖于上面的X,也就是说fit是多余的,只是为了整个sklearn的统一。
Sparse input
normalize函数和Normalizer类都接受dense array-like and sparse matrics from scipy.sparse作为输入。
对于稀疏输入,在进入高效的Cython routines处理之前,都会将其转化成CSR(Compressed Sparse Rows)格式(scipy.sparse.csr_matrix),为了避免不必要的数据拷贝,推荐使用CSR格式的稀疏矩阵。
二值化(Binarize)
Binarization: thresholding numerical features to get boolean values
Feature binarization: 将数值型特征取值阈值化转换为布尔型特征取值,这一过程主要是为概率型的学习器(probabilistic estimators)提供数据预处理机制。
概率型学习器(probabilistic estimators)假定输入数据是服从于多变量伯努利分布(multi-variate Bernoulli distribution)的, 概率性学习器的典型的例子是sklearn.neural_network.BrenoulliRBM
在文本处理中,也普遍使用二值特征简化概率推断过程,即使归一化的词频特征或TF-IDF特征的表现比而二值特征稍微好一点。
就像Normalizer,Binarizer也应该用在sklearn.pipeline.Pipeline的早期阶段。fit方法也是什么也不干,有或者没有是一样的。
X = [[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]]
binarizer = preprocessing.Binarizer().fit(X)
print(binarizer)
print('-----')
print(binarizer.transform(X))

binarizer = preprocessing.Binarizer(threshold=1.1)
binarizer.transform(X)

就像StandardScaler和Normalizer类一样,preprocessing模块也为我们提供了一个方便的额binarize进行数值特征的二值化。
Sparse input
normalize函数和Normalizer类都接受dense array-like and sparse matrics from scipy.sparse作为输入。
对于稀疏输入,在进入高效的Cython routines处理之前,都会将其转化成CSR(Compressed Sparse Rows)格式(scipy.sparse.csr_matrix),为了避免不必要的数据拷贝,推荐使用CSR格式的稀疏矩阵。
数据预处理:规范化(Normalize)和二值化(Binarize)的更多相关文章
- [转载+原创]Emgu CV on C# (四) —— Emgu CV on 全局固定阈值二值化
重点介绍了全局二值化原理及数学实现,并利用emgucv方法编程实现. 一.理论概述(转载,如果懂图像处理,可以略过,仅用作科普,或者写文章凑字数) 1.概述 图像二值化是图像处理中的一项基本技术,也 ...
- 机器学习实战基础(十二):sklearn中的数据预处理和特征工程(五) 数据预处理 Preprocessing & Impute 之 处理分类特征:处理连续性特征 二值化与分段
处理连续性特征 二值化与分段 sklearn.preprocessing.Binarizer根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量.大于阈值的值映射为1,而小于或等于阈值的值 ...
- 数据预处理 | 使用 Pandas 进行数值型数据的 标准化 归一化 离散化 二值化
1 标准化 & 归一化 导包和数据 import numpy as np from sklearn import preprocessing data = np.loadtxt('data.t ...
- 机器学习入门-数值特征-进行二值化变化 1.Binarizer(进行数据的二值化操作)
函数说明: 1. Binarizer(threshold=0.9) 将数据进行二值化,threshold表示大于0.9的数据为1,小于0.9的数据为0 对于一些数值型的特征:存在0还有其他的一些数 二 ...
- python的N个小功能(图片预处理:打开图片,滤波器,增强,灰度图转换,去噪,二值化,切割,保存)
############################################################################################# ###### ...
- OpenCV图像的二值化
图像的二值化: 与边缘检测相比,轮廓检测有时能更好的反映图像的内容.而要对图像进行轮廓检测,则必须要先对图像进行二值化,图像的二值化就是将图像上的像素点的灰度值设置为0或255,这样将使整个图像呈现出 ...
- [置顶] c#验证码识别、图片二值化、分割、分类、识别
c# 验证码的识别主要分为预处理.分割.识别三个步骤 首先我从网站上下载验证码 处理结果如下: 1.图片预处理,即二值化图片 *就是将图像上的像素点的灰度值设置为0或255. 原理如下: 代码如下: ...
- 图像处理------基于Otsu阈值二值化
一:基本原理 该方法是图像二值化处理常见方法之一,在Matlab与OpenCV中均有实现. Otsu Threshing方法是一种基于寻找合适阈值实现二值化的方法,其最重 要的部分是寻找图像二值化阈值 ...
- 深度学习实践-强化学习-bird游戏 1.np.stack(表示进行拼接操作) 2.cv2.resize(进行图像的压缩操作) 3.cv2.cvtColor(进行图片颜色的转换) 4.cv2.threshold(进行图片的二值化操作) 5.random.sample(样本的随机抽取)
1. np.stack((x_t, x_t, x_t, x_t), axis=2) 将图片进行串接的操作,使得图片的维度为[80, 80, 4] 参数说明: (x_t, x_t, x_t, x_t) ...
随机推荐
- nginx配置php时fastcgi_pass参数问题
更多内容推荐微信公众号,欢迎关注: 在配置nginx的时候,fastcgi_pass的配置问题,如下所示: location ~ \.php$ { root /home/wwwroot; fastcg ...
- CSS 实现单边阴影
box-shadow: 0px -15px 10px -15px #111; 五个值分别为:x y blur spread color 将 spread 设置成 blur 的负值即可 这种只适用于 o ...
- JavaScript验证注册信息
<script language="javascript"> function check_login(form){ if(form.username.value==& ...
- 延迟注入工具(python)
延迟注入工具(python) #!/usr/bin/env python # -*- coding: utf-8 -*- # 延迟注入工具 import urllib2 import time imp ...
- Spring---七大核心模块
核心容器(Spring Core) 核心容器提供Spring框架的基本功能.Spring以bean的方式组织和管理Java应用中的各个组件及其关系.Spring使用BeanFactory来产生和管理B ...
- tomcat发布html静态页面
一.环境 在Linux系统安装JDK并配置环境变量,安装tomcat(在tomcat官网下载压缩包即可,我使用的是tomcat7 https://tomcat.apache.org/download- ...
- Github授权新的设备ssh接入
为Mac生成公钥 步骤: 检查本机是否已有公钥 ls -la ~/.ssh 将原来的公钥删除 rm -rf ~/.ssh 生成新的公钥(填自己的邮箱),然后除了密码,一路默认 ssh-keygen - ...
- mysql -> 启动&多实例_03
常用的连接方式: 套接字: mysql -uroot -p123 -S /application/mysql/tmp/mysql.sock Tcp/Ip: mysql -uroot -p123 -h ...
- js中的call,apply,bind区别
在JavaScript中,call.apply和bind是Function对象自带的三个方法,这三个方法的主要作用是改变函数中的this指向. call.apply.bind方法的共同点和区别:app ...
- JDBC核心API
JDBC核心API在java.sql.*和javax.sql.* 1.Driver接口:表示Java驱动程序接口,具体的数据库厂商要实现其此接口 connect(url.propertis):连接数据 ...