42 - 数据库-orm-SQLAlchemy
1 ORM
Object-Relational Mapping,把关系数据库的表结构映射到对象上。使用面向对象的方式来操作数据库。
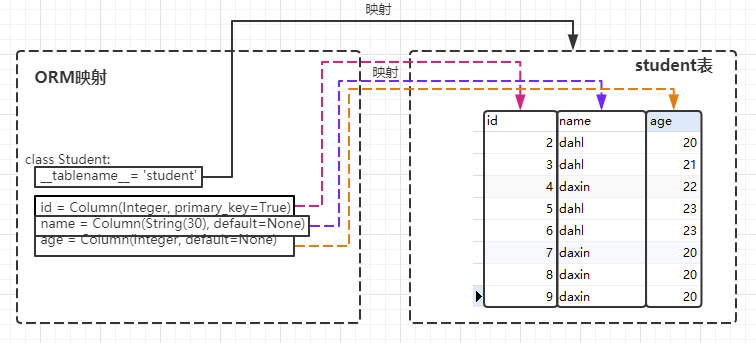
下面是一个关系模型与Python对象之间的映射关系:
- table --> class : 表映射为类
- row --> object : 行映射为实例
- column --> property : 字段映射为属性
2 sqlalchemy
SQLAlchemy是一个ORM框架。内部是使用了连接池来管理数据库连接。其本身只是做了关系映射,不能连接数据库,也不能执行sql语句,它在底层需要使用pymysql等模块来连接并执行sql语句,要使用sqlalchemy,那么需要先进行安装:
pip3 install sqlalchemy
查看版本
In [1]: import sqlalchemy
In [2]: print(sqlalchemy.__version__)
1.3.1
3 基本使用
先来总结一下使用sqlalchemy框架操作数据库的一般流程:
创建引擎(不同类型数据库使用不同的连接方式)创建基类(类对象要继承,因为基类会利用元编程为我们的子类绑定关于表的其他属性信息)创建实体类(用来对应数据库中的表)编写实体类属性(用来对应表中的字段/属性)创建表(如果表不存在,则需要执行语句在数据库中创建出对应的表)实例化(具体的一条record记录)创建会话session(用于执行sql语句的连接)使用会话执行SQL语句关闭会话
3.1 创建连接
sqlalchemy 使用引擎管理数据库连接(DATABASE URLS),连接的一般格式为:
dialect+driver://username:password@host:port/database
dialect:表示什么数据库(比如,mysql,sqlite,oracle等)driver:用于连接数据库的模块(比如pymysql,mysqldb等)username:连接数据库的用户名password:连接数据库的密码host: 数据库的主机地址port: 数据库的端口database: 要连接的数据库名称
pymysql模块是较长用于连接mysql的模块,使用pymysql的连接的语句为:
mysql+pymysql://dahl:123456@10.0.0.13:3306/test
创建引擎用于进行数据库的连接:create_engine(urls)
import sqlalchemy
db_url = 'mysql+pymysql://dahl:123456@10.0.0.13:3306/test'
engine = sqlalchemy.create_engine(db_url,echo=True)
- echo:引擎是否打印执行的sql语句,等于True时,表示打印,便于调试
- max_overflow=5: 超过连接池大小外最多创建的连接
- pool_size=1: 连接池大小
- pool_timeout=30: 池中没有线程最多等待的时间(否则会报错)
- pool_recycle=-1: 多久之后对线程池中的线程进行一次连接的回收(重置)
特别注意:创建引擎并不会马上连接数据库,直到让数据库执行任务是才连接。
3.1.1 利用连接池执行sql
sqlalchemy内部是原生支持连接池的,我们可以仅仅利用它的连接池功能。通过engie的raw_connection方法就可以获取到一个连接,然后就可以执行sql语句了(基本上就是Pymysql+DBUtils的实现)
import threading
import time
import sqlalchemy
import pymysql
engine = sqlalchemy.create_engine(
'mysql+pymysql://dahl:123456@10.0.0.13:3306/test',
max_overflow=5,
pool_size=1,
pool_timeout=30,
pool_recycle=-1
)
def func():
conn = engine.raw_connection()
cursor = conn.cursor(pymysql.cursors.DictCursor)
time.sleep(2)
cursor.execute('select * from employees;')
res = cursor.fetchall()
print(res)
cursor.close()
conn.close()
if __name__ == '__main__':
for i in range(10):
threading.Thread(target=func).start()
3.1.2 利用session来执行sql
上面是通过链接池来执行sql的,其实也可以通过session来执行。
import threading
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = sqlalchemy.create_engine(
'mysql+pymysql://dahl:123456@10.0.0.13:3306/test',
max_overflow=5,
pool_size=1,
pool_timeout=30,
pool_recycle=-1
)
DBsession = sessionmaker(bind=engine)
def func():
session = DBsession()
cursor = session.execute('select * from employees;')
res = cursor.fetchall()
print(res)
cursor.close()
session.close()
if __name__ == '__main__':
for i in range(10):
threading.Thread(target=func).start()
3.2 创建基类
使用: sqlalchemy.ext.declarative.declarative_base 来构造声明性类定义的基类。因为sqlalchemy内部大量使用了元编程,为实例化的子类注入映射所需的属性,所以我们定义的映射要继承自它(必须继承)
一般只需要一个这样的基类
Base = sqlalchemy.ext.declarative.declarative_base()
# 或者
from sqlalchemy.ext import declarative
Base = declarative.declarative_base()
3.3 创建实体类
现数据库存在如下表
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(30) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4;
创建对应的实体类:
import sqlalchemy
from sqlalchemy.ext import declarative
from sqlalchemy import Column, String, Integer
db_url = 'mysql+pymysql://dahl:123456@10.0.0.13:3306/test'
engine = sqlalchemy.create_engine(db_url, echo=True)
Base = declarative.declarative_base()
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True, nullable=False, autoincrement=True)
name = Column(String, default='Null')
age = Column(Integer, default='Null')
print(Student.__dict__)
# Table('student', MetaData(bind=None), 这里没有绑定engine,所以是None
# Column('id', Integer(), table=<student>, primary_key=True, nullable=False),
# Column('name', String(), table=<student>, default=ColumnDefault('Null')),
# Column('age', Integer(), table=<student>, default=ColumnDefault('Null')), schema=None),
# Column('data',DateTime,default=datetime.datetime.now) # 这里不能加括号
- __tablename__: 表明,如果表已存在,则必须指定正确的表名
- Column: 用于构建一个列对象,它的参数一般都和数据库中的列属性是对应的,主要有:
- name: 数据库中表示的此列的名称
type:字段类型(比如String、Integer,这里是sqlalchemy包装的类型,对应的是数据库的varchar、int等),来自TypeEngine的子类autoincrement:是否自增- default:默认值,可以是值,可调用对象或者类,当写入数据该字段没有指定时,调用。当是可调用对象的时候,建议不要加括号
- doc:字段说明信息
- key: 一个可选的字符串标识符,用于标识表上的此Column对象。
- index: 是否启用索引
nullable: 是否可以为空- onupdate: 如果在更新语句的SET子句中不存在此列,则将在更新时调用该值
primary_key: 主键- server_default:它的值是 FetchedValue实例、字符串、Unicode 或者 text()实例,用作DDL语句中该列的default值
注意:Column和String、Integer等都来自于sqlalchemy下的方法,要么直接导入,要么就使用sqlalchemy.String来引用。
3.3.1 常用字段
| 类型名 | python中类型 | 说明 |
|---|---|---|
| Integer | int | 普通整数,一般是32位 |
| SmallInteger | int | 取值范围小的整数,一般是16位 |
| BigInteger | int或long | 不限制精度的整数 |
| Float | float | 浮点数 |
| Numeric | decimal.Decimal | 普通整数,一般是32位 |
| String | str | 变长字符串 |
| Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
| Unicode | unicode | 变长Unicode字符串 |
| UnicodeText | unicode | 变长Unicode字符串,对较长或不限长度的字符串做了优化 |
| Boolean | bool | 布尔值 |
| Date | datetime.date | 时间 |
| Time | datetime.datetime | 日期和时间 |
| LargeBinary | str | 二进制文件 |
3.4 实例化
通过我们构建的类,来实例化的对象,在将来就是数据库中的一条条记录。
student = Student()
student.name = 'daxin'
student.id = 1
student.age = 20
print(student) # <1 daxin 20>
3.5 创建表
我们自己写的类都是继承自Base,每继承一次Base类,在Base类的metadata属性中就会记录当前子类,metadata提供了方法用于删除/创建表。如果数据库中已经存在对应的表,那么将不会继续创建
- drop_all(bind=None, tables=None, checkfirst=True):删除metadata中记录的所有表
- create_all(bind=None, tables=None, checkfirst=True):创建metadata中记录的所有表
Base = declarative.declarative_base()
Base.metadata.create_all(bind=engine) # 需要通过引擎去执行
# 下面是engine的echo为true时的输出信息
# 2019-03-16 16:53:45,922 INFO sqlalchemy.engine.base.Engine
# CREATE TABLE hello (
# id INTEGER NOT NULL AUTO_INCREMENT,
# name VARCHAR(24),
# age INTEGER,
# PRIMARY KEY (id)
# )
#
#
# 2019-03-16 16:53:45,922 INFO sqlalchemy.engine.base.Engine {}
# 2019-03-16 16:53:45,926 INFO sqlalchemy.engine.base.Engine COMMIT
# 2019-03-16 16:53:45,927 INFO sqlalchemy.engine.base.Engine
# CREATE TABLE world (
# id INTEGER NOT NULL AUTO_INCREMENT,
# name VARCHAR(24),
# age INTEGER,
# PRIMARY KEY (id)
# )
#
#
# 2019-03-16 16:53:45,927 INFO sqlalchemy.engine.base.Engine {}
# 2019-03-16 16:53:45,928 INFO sqlalchemy.engine.base.Engine COMMIT
- 生产环境很少这样创建表,都是系统上线的时候由脚本生成。
- 生产环境很少删除表,宁可废除都不能删除。
注意:sqlalchemy 只能创建和删除表,不能修改表结构。只能手动的在数据库中修改然后在代码中添加即可。
3.6 创建会话Session
在一个会话中操作数据库,绘画建立在连接上,连接被引擎管理,当第一次使用数据库时,从引擎维护的连接池中取出一个连接使用。
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session() # 实例化一个session对象
- session对象线程不安全。所以不同线程应该使用不同的session对象
- Session类和engine有一个就行了。
scoped_session是sqlalchemy提供的线程安全的session,利用的是ThreadLocal实现的。
3.7 数据操作
3.7.1 增加数据
| 方法 | 含义 |
|---|---|
| add() | 增加一个对象 |
| add_all() | 增加多个对象,类型为可迭代 |
import sqlalchemy
from sqlalchemy.ext import declarative
from sqlalchemy import Column, String, Integer
from sqlalchemy.orm import sessionmaker
db_url = 'mysql+pymysql://dahl:123456@10.0.0.13:3306/test'
engine = sqlalchemy.create_engine(db_url, echo=True)
Base = declarative.declarative_base()
DBSession = sessionmaker(bind=engine)
session = DBSession()
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True, nullable=False, autoincrement=True)
name = Column(String(24), default='Null')
age = Column(Integer, default='Null')
def __repr__(self):
return '<{} {} {}>'.format(
self.id, self.name, self.age
)
daxin = Student(id=12, name='daxin', age=20)
session.add(daxin)
dachenzi = Student(id=13,name='dachenzi', age=21)
xiaobai = Student(id=14,name='xiaobai', age=22)
session.add_all((dachenzi,xiaobai)) # 新增三条数据
session.commit()
需要注意的是下面的情况:
daxin = Student(name='daxin')
daxin.age = 40
session.add(daxin) # 1
session.commit()
daxin.age = 20
session.add(daxin) # 2
session.commit()
daxin.age = 10
session.add_all([daxin, daxin, daxin, daxin]) # 3
session.commit()
# <30 daxin 10>
结果生成个1条数据,<30 daxin 10>,为什么呢?由于id属于自增列,我们在执行#1时,id是没有固定下来的。
- 执行后,commit,则daxin的id就固定下来了。
- 执行时,由于id没变,所以并不会新增数据,而是使用update语句更新了age字段
- 执行时,由于都是daxin的,id,name,age都没有改变,所以只会执行1条语句
当engine的echo等于true时,看到具体的sql语句,一切就很明白了。
3.7.2 简单查询
使用session的query方法进行简单查询,格式为:
session.query(student): 等同于select * from student;session.query(student).get(2): 等同于select * from student where id = 2,这里的get方法只能主键查询
std_list = session.query(Student)
print(std_list) # SELECT student.id AS student_id, student.name AS student_name, student.age AS student_age FROM student
print(type(std_list)) # <class 'sqlalchemy.orm.query.Query'>
这里直接打印并不会结果,因为它太懒了,你不迭代它,它就不会真的去数据库查询。
std_list = session.query(Student)
for std in std_list:
print(std)
# 通过get来过滤主键,是可以直接执行返回结果的。
std_list = session.query(Student).get(30)
print(std_list)
3.7.3 修改数据
修改的数据的流程分为两步:
- 查找匹配的数据
- 修改后,提交
std = session.query(Student).get(30)
print(std) # <30 daxin 200>
std.age = 1000
session.add(std)
session.commit()
std = session.query(Student).get(30)
print(std) # <30 daxin 1000>
# 或者
std = session.query(Student).filter(Student.id > 10).update({'name':'daxin'})
std.commit()
大部分ORM是都是这样,必须先查才能改。
在原有数据的基础上批量修改,比如在所有名称后面添加特定的后缀
session.query(Users).filter(Users.id > 0).update({Users.name: Users.name + "099"}, synchronize_session=False) # 必须为synchronize_session=False
session.query(Users).filter(Users.id > 0).update({"age": Users.age + 1}, synchronize_session="evaluate") # 必须synchronize_session="evaluate",表示要进行计算
3.7.4 删除数据(不建议)
使用session.delete来删除数据
std = session.query(Student).get(30)
session.delete(std)
session.commit() # 提交删除操作
std = session.query(Student).get(30)
print(std) # None
3.7.5 状态
当我们创建一条数据,或是从数据库中获取一条数据时,数据本身是存在一个状态属性的,用来标识当前数据是否持久化,或者其他状态,在sqlalchemy中,inspect(obj)可以用来窥探数据(obj)的状态
daxin = Student(name='daxin')
daxin.age = 10000
state = sqlalchemy.inspect(daxin)
print(state) # <sqlalchemy.orm.state.InstanceState object at 0x00000186EEC38EB8>
std = session.query(Student).get(28)
state = sqlalchemy.inspect(std)
print(state) # <sqlalchemy.orm.state.InstanceState object at 0x00000186EFDCDA20>
我们看到,inspect返回的是一个InstanceState对象。这个对象有以下几个属性:
- session_id:获取数据时的session ID,如果是自建数据未持久化ID为None
- _attached: 是否是附加的(数据已经加载(已add),就差提交的数据库了)
- transient:是否是临时数据(临时创建,还没有提交(还没有add))
- pending: 是否是待定的数据
- persistent: 是否是持久的
- deleted: 是否已删除
- detached:是否被分离
- key:key是多少
InstanceState对象,可以通过sqlalchemy.orm.state导入
具体的状态信息与含义如下:
| 状态 | 说明 |
|---|---|
transient |
实体类尚未加入到session中,同时并没有保存到数据库中 |
pending |
transient的实体被加入到session中,状态切换到pending,但它还没有被flsh到数据库中 |
persistent |
session中的实体对象对应着数据库中的真实记录。pending状态在提交成功后可以变成persistent状态,或者查询成功返回的实体也是persistent状态 |
deleted |
实体被删除且已经flush但未commit完成。事物提交成功了,实体变成detached,事物失败返回persistent状态 |
detached |
删除成功的实体进入这个状态 |
所以数据的状态变化如下:
- 新建一个实体,状态是transient临时的
- add()以后,状态变为pending
- commit()以后,状态变为persistent
- 查询成功返回的实体状态也是persistent状态
- delete()并flush()以后,状态变为deleted
- commit()以后,变为detached,提交失败,回退到persistent状态
flush()方法,主动把改变应用到数据库中去
删除、修改操作,需要对应一个真实存在的数据,也就是说数据的状态是persistent才行。当使用add语句新增信息时,如果这个对象已经添加过数据库了,那么它的状态会变为persistent,如果对persistent的数据进行修改继续提交的话,那么使用的将会是update语句而非insert。这也是前面为啥多次对一个数据进行add,提交了多次只会插入1次的原因。
import sqlalchemy
from sqlalchemy.ext import declarative
from sqlalchemy import Column, String, Integer
from sqlalchemy.orm import sessionmaker
db_url = 'mysql+pymysql://dahl:123456@10.0.0.13:3306/test'
engine = sqlalchemy.create_engine(db_url, echo=True)
Base = declarative.declarative_base()
DBSession = sessionmaker(bind=engine)
session = DBSession()
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True, nullable=False, autoincrement=True)
name = Column(String(24), default='Null')
age = Column(Integer, default='Null')
def __repr__(self):
return '<{} {} {}>'.format(
self.id, self.name, self.age
)
def getstate(state: InstanceState):
print("""
session_id={} transient={} _attached={} pending={} persistent={} deleted={} detached={}
""".format(state.session_id, state.transient, state._attached, state.pending, state.persistent, state.deleted,
state.detached))
daxin = Student(name='daxin')
daxin.age = 10000
state = sqlalchemy.inspect(daxin)
getstate(state) # session_id=None transient=True _attached=False pending=False persistent=False deleted=False detached=False
session.add(daxin)
getstate(state) # session_id=1 transient=False _attached=True pending=True persistent=False deleted=False detached=False
session.commit()
getstate(state) # session_id=1 transient=False _attached=True pending=False persistent=True deleted=False detached=False
std = session.query(Student).get(28)
state = sqlalchemy.inspect(std)
getstate(state) # session_id=1 transient=False _attached=True pending=False persistent=True deleted=False detached=False
std = session.query(Student).get(31)
session.delete(std)
state = sqlalchemy.inspect(std)
getstate(state) # session_id=1 transient=False _attached=True pending=False persistent=True deleted=False detached=False
session.flush()
getstate(state) # session_id=1 transient=False _attached=True pending=False persistent=False deleted=True detached=False
session.commit()
getstate(state) # session_id=None transient=False _attached=False pending=False persistent=False deleted=False detached=True
3.7.6 枚举字段
在数据库的字段类型中,比如性别字段,我们可能会限制数据来源为M(male),F(Female),这个时候字段类型可以是枚举的,但是在sqlalchemy中,原生的字段类型没有枚举类型,那么就需要借助enum类了。
import sqlalchemy
from sqlalchemy.ext import declarative
from sqlalchemy import Column, String, Integer
from sqlalchemy.orm import sessionmaker
import enum
db_url = 'mysql+pymysql://dahl:123456@10.0.0.13:3306/test'
engine = sqlalchemy.create_engine(db_url, echo=True)
Base = declarative.declarative_base()
DBSession = sessionmaker(bind=engine)
session = DBSession()
class GenderEnum(enum.Enum):
M = 'M'
F = 'F'
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True, nullable=False, autoincrement=True)
name = Column(String(24), default='Null')
age = Column(Integer, default='Null')
gender = Column(sqlalchemy.Enum(GenderEnum),nullable=False)
def __repr__(self):
return '<{} {} {}>'.format(
self.id, self.name, self.age
)
用起来很麻烦,所以建议性别使用1或者0来存储,显示的时候做对于转换即可
3.7.7 复杂查询
3.7.7.1 where条件查询
使用filter方法进行条件过滤查询:
session.query(student).filter(student.id > 10):相当于select * from student where student.id > 10
同时还存在一个filter_by,它的不同之处在于括号中的不是表达式,而是参数。比如:filter(user.id == 10) -> filter_by(user.id = 10)
where条件中的关系:
AND(与) 对应and_OR(或) 对应or_not(非) 对应not_in对应字段的in_not in对应字段的notin_like对应 字段的like方法not like对应 字段的notlike方法
想要使用与或非,需要先行导入
import sqlalchemy
from sqlalchemy.ext import declarative
from sqlalchemy import Column, String, Integer
from sqlalchemy.orm import sessionmaker
from sqlalchemy import and_, or_, not_
db_url = 'mysql+pymysql://dahl:123456@10.0.0.13:3306/test'
engine = sqlalchemy.create_engine(db_url, echo=True)
Base = declarative.declarative_base()
DBSession = sessionmaker(bind=engine)
session = DBSession()
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True, nullable=False, autoincrement=True)
name = Column(String(24), default='Null')
age = Column(Integer, default='Null')
def __repr__(self):
return '<{} {} {}>'.format(
self.id, self.name, self.age
)
def getresulte(stds):
for std in stds:
print(std)
条件判断之AND(&,and_)
# and
std_list = session.query(Student).filter(and_(Student.id < 30, Student.id > 27))
getresulte(std_list)
std_list = session.query(Student).filter(Student.id < 30).filter(Student.id > 27) # filter返回的还是一个结果集,所以还可以继续使用filter进行过滤
getresulte(std_list)
std_list = session.query(Student).filter(Student.id < 30, Student.age > 100) # 多个条件一起写,也是and的关系
getresulte(std_list)
std_list = session.query(Student).filter((Student.name == 'daxin') & (Student.age > 28))
getresulte(std_list)
条件判断之OR(or_,|)
# or
std_list = session.query(Student).filter(or_(Student.id > 27, Student.age < 50))
getresulte(std_list)
std_list = session.query(Student).filter((Student.id > 27) | (Student.age < 50 ))
getresulte(std_list)
条件判断之NOT(not_,~)
# not
std_list = session.query(Student).filter(not_(Student.id == 32))
getresulte(std_list)
std_list = session.query(Student).filter(~(Student.id == 32))
getresulte(std_list)
like和in及not in
# like
std_list = session.query(Student).filter(Student.name.like('da%'))
getresulte(std_list)
# not like
std_list = session.query(Student).filter(Student.name.notlike('da%'))
getresulte(std_list)
# in
std_list = session.query(Student).filter(Student.age.in_([10,30,50]))
getresulte(std_list)
# not in
std_list = session.query(Student).filter(Student.age.notin_([10,30,50]))
getresulte(std_list)
补充:
r6 = session.query(Users).filter(text("id<:value and name=:name")).params(value=224, name='fred').order_by(Users.id).all() # 传参的方式查询
r7 = session.query(Users).from_statement(text("SELECT * FROM users where name=:name")).params(name='ed').all() # 用的不多
3.7.7.2 排序
- order_by:排序
- asc: 升序(默认)
- desc: 降序
# 升序
std_list = session.query(Student).filter(Student.name.like('da%')).order_by(Student.age)
getresulte(std_list)
# 降序
std_list = session.query(Student).filter(Student.name.like('da%')).order_by(Student.age.desc())
getresulte(std_list)
3.7.7.3 分页(偏移量)
- limit: 显示结果的条目数
- offset:偏移量
# limit
std_list = session.query(Student).filter(Student.name.like('da%')).order_by(Student.age.desc()).limit(3).offset(2)
getresulte(std_list)
# select * from Student where name like 'da%' order_by age desc limit 3 offset 2
3.7.7.4 消费方法
- count(): 获取总条数(仅仅针对结果集,不能all以后再count)
- all(): 取所有行(默认)(列表)
- first():取首行
- one():有且只有一行,多行则抛出异常
- delete():对查询出来的数据直接进行删除
- scalar(): 第一条记录的第一个元素
# count
std_list = session.query(Student)
print(std_list.count())
# first
std_list = session.query(Student).first()
print(std_list)
first本质上就是limit。
3.7.7.5 分组及聚合方法
sqlalchemy同样提供了聚合方法,使用sqlalchemy.func来调用
- group_by:分组显示
func提供的方法有
- max:求最大值
- min:求最小值
- avg:求平均值
- count:聚合(一般和分组连用)
# max
std_list = session.query(Student.name,sqlalchemy.func.max(Student.age)) # select name,max(age) from Student;
getresulte(std_list)
# count
std_list = session.query(Student.name,sqlalchemy.func.count(Student.id)).group_by(Student.name) # SELECT name, count(id) FROM student GROUP BY name
getresulte(std_list)
3.7.7.6 关联查询
sqlalchemy提供ForeignKey用来进行外键关联,它的格式为:
sqlalchemy.ForeignKey(表名.字段名,ondelete='更新规则')
# 如果填写映射后的class,那么可以直接写:类.字段
# 如果填写数据库中的表,那么需要使用引号:'数据库表名.字段名'
更新规则和删除规则,可选项如下:
CASCADE:级联删除,删除被关联数据时,从表关联的数据全部删除。SET NULL:从父表删除或更新行,会设置子表中的外键列为NULL,但必须保证子表没有指定 NOT NULL,也就是说子表的字段可以为NULL才行。RESTRICT:如果从父表删除主键,如果子表引用了,则拒绝对父表的删除或更新操作。(保护数据)NO ACTION:表中SQL的关键字,在MySQL中与RESTRICT相同。拒绝对父表的删除或更新操作。
现有如下关系表
CREATE TABLE `departments` (
`dept_no` char(4) NOT NULL,
`dept_name` varchar(40) NOT NULL,
PRIMARY KEY (`dept_no`),
UNIQUE KEY `dept_name` (`dept_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` enum('M','F') NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`),
KEY `dept_no` (`dept_no`),
CONSTRAINT `dept_emp_ibfk_1` FOREIGN KEY (`emp_no`) REFERENCES `employees` (`emp_no`) ON DELETE CASCADE,
CONSTRAINT `dept_emp_ibfk_2` FOREIGN KEY (`dept_no`) REFERENCES `departments` (`dept_no`) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
创建对应的映射实体类
import sqlalchemy
from sqlalchemy.ext import declarative
from sqlalchemy import Column, String, Integer, Date
from sqlalchemy.orm import sessionmaker
import enum
db_url = 'mysql+pymysql://dahl:123456@10.0.0.13:3306/test'
engine = sqlalchemy.create_engine(db_url, echo=True)
Base = declarative.declarative_base()
DBSession = sessionmaker(bind=engine)
session = DBSession()
class Departments(Base):
__tablename__ = 'departments'
dept_no = Column(String(4), nullable=False, primary_key=True)
dept_name = Column(String(40), nullable=False, unique=True)
def __repr__(self):
return '<{} {} {}>'.format(self.__class__.__name__, self.dept_no, self.dept_name)
class GenderEnum(enum.Enum):
M = 'M'
F = 'F'
class Employees(Base):
__tablename__ = 'employees'
emp_no = Column(Integer, nullable=False, primary_key=True)
birth_date = Column(Date, nullable=False)
first_name = Column(String(14), nullable=False)
last_name = Column(String(16), nullable=False)
gender = Column(sqlalchemy.Enum(GenderEnum), nullable=False)
hire_date = Column(Date, nullable=False)
def __repr__(self):
return '<{} {} {} {} {} {}>'.format(
self.__class__.__name__, self.emp_no, self.birth_date, self.first_name, self.last_name, self.gender,
self.hire_date
)
class Dept_emp(Base):
__tablename__ = 'dept_emp'
emp_no = Column(Integer, sqlalchemy.ForeignKey(Employees.emp_no, ondelete='CASCADE'), primary_key=True, )
dept_no = Column(String(4), sqlalchemy.ForeignKey(Departments.dept_no, ondelete='CASCADE'), nullable=False)
from_date = Column(Date, nullable=False)
to_date = Column(Date, nullable=False)
def __repr__(self):
return '<{} emp_no={} dept_no={}>'.format(
self.__class__.__name__, self.emp_no, self.dept_no
)
def getres(emps):
for emp in emps:
print(emp)
查询10010员工所在的部门编号及员工信息
隐式连接
emps = session.query(Employees, Dept_emp).filter(and_(Employees.emp_no == Dept_emp.emp_no, Employees.emp_no == '10010')).all()
getres(emps)
emps = session.query(Employees, Dept_emp).filter(Employees.emp_no == Dept_emp.emp_no).filter(Employees.emp_no == '10010').all()
getres(emps)
# 相当于:select * from employees,dept_emp where employees.emp_no = dept_emp.emp_no and employees.emp_no = '10010';
join连接
使用join()关键字来进行连表查询,其isouter参数用于指定join的类型,默认情况下使用的是inner join,当isouter=True时,就表示是left join(right join没有实现,需要自己交换前面表的顺序)
# join连接
std_list = session.query(Employees).join(Dept_emp,Employees.emp_no == Dept_emp.emp_no,isouter=True).filter(Employees.emp_no == '10010')
getres(std_list)
std_list = session.query(Employees).join(Dept_emp).filter((Employees.emp_no == Dept_emp.emp_no) & (Employees.emp_no == '10010'))
getres(std_list)
# 如果query中,仅列出一个表明,相当于
# select employees.* from employees inner join dept_emp on employees.emp_no = dept_emp.emp_no where employees.emp_no = '10010';
4 一对多关系
一对多是一种表与表的关系,在orm中创建和使用方式有一写特点,这里单独描述
4.1 创建关系表
通过ForeignKey来创建一对多关系,需要注意的是它内部需要填写对应的真实的表名和字段(非映射的类对象)
class Deptment(base):
__tablename__ = 'deptment'
id = Column(Integer, autoincrement=True, primary_key=True)
dep_name = Column(String(32), nullable=False)
class User(base):
__tablename__ = 'user'
id = Column(Integer, autoincrement=True, primary_key=True)
name = Column(String(32), nullable=False)
dept_id = Column(Integer, ForeignKey('deptment.id'))
# CREATE TABLE `user` (
# `id` int(11) NOT NULL AUTO_INCREMENT,
# `name` varchar(32) NOT NULL,
# `dept_id` int(11) DEFAULT NULL,
# PRIMARY KEY (`id`),
# KEY `dept_id` (`dept_id`),
# CONSTRAINT `user_ibfk_1` FOREIGN KEY (`dept_id`) REFERENCES `deptment` (`id`)
# ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
# CREATE TABLE `deptment` (
# `id` int(11) NOT NULL AUTO_INCREMENT,
# `dep_name` varchar(32) NOT NULL,
# PRIMARY KEY (`id`)
# ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
4.2 添加数据
添加部门数据时,只能使用id来插入,当插入的dept_id在deptment表中不存在时,会直接爆出异常
# 批量添加部门数据
session.add_all([
Deptment(dep_name='运维部'),
Deptment(dep_name='开发部'),
Deptment(dep_name='产品部'),
Deptment(dep_name='测试部')]
)
# 添加用户数据
session.add_all([
User(name='daxin', dept_id=1),
User(name='dachenzi', dept_id=2),
User(name='dahl', dept_id=3)]
)
session.commit()
4.3 relationship
在表中使用relationship来创建一个关联的对象,便于查询(和django的一对多隐含的对象相同,但在sqlalchemy中必须通过relationship才可以生成),并不会生成新的字段,仅仅是产生一个关联关系。
注意relationship对象不能作为条件直接进行表查询:session.query(User.name,User.deptment.dept_name) 这样是不行的。
relationship(obj,backref='')
- obj:表示要关联的ORM对象
- backref:表示在对方插入一个关键字,用于反向关联relationship所在的表对象的本身。
下面是一个例子:
class Deptment(base):
__tablename__ = 'deptment'
id = Column(Integer, autoincrement=True, primary_key=True)
dep_name = Column(String(32), nullable=False)
class User(base):
__tablename__ = 'user'
id = Column(Integer, autoincrement=True, primary_key=True)
name = Column(String(32), nullable=False)
dept_id = Column(Integer, ForeignKey('deptment.id'))
deptment = relationship(Deptment, backref='user') # 创建relationship关系
# 正向查(通过User查deptment)
std = session.query(User).filter(User.id == 1).first()
print(std.name)
print(std.deptment.dep_name) # 直接通过deptment对象,读取Deptment表中对于的信息
# 反向查(通过depement查User)
dep = session.query(Deptment).filter(Deptment.id == 1).first()
print(dep.user[0].name) # 反向查,通过user获取到的数据是一个列表
relationship,就是通过在一个映射类中增加一个属性,该属性用于表示连接关系,可以在结果中,访问该属性来访问关联的表信息
4.4 通过relationship添加数据
存在relationship的映射关系时,我们添加数据时,就可以通过relationship使用对象来添加关联数据了
dep = session.query(Deptment).filter(Deptment.id == 3).first()
session.add_all([
User(name='hello', deptment=dep),
User(name='world', deptment=dep)]
)
session.commit()
直接创建新的部门对象也是可以的
user = User(name='dahlhin',deptment=Deptment(dep_name='管理员'))
session.add(user)
session.commit()
5 多对多关系
和django不同sqlalchemy的第三张表需要手动创建。
5.1 创建多对多关系
模拟主机与业务线的归属问题。
- 主机可以属于多个业务线
- 一个业务线可以包含多个主机
这是一个典型的多对多关系,需要额外一张关系表来记录。
class Service2host(base):
__tablename__ = 'service_to_host'
id = Column(Integer, primary_key=True, nullable=False, unique=True, autoincrement=True)
s_id = Column(Integer, ForeignKey('service.id'))
h_id = Column(Integer, ForeignKey('host.id'))
__table_args__ = (
# 联合唯一索引
UniqueConstraint('s_id', 'h_id', name='serivce_to_host'),
) # 业务id和主机id不能重复,这里创建唯一索引来约束
class Service(base):
__tablename__ = 'service'
id = Column(Integer, primary_key=True, nullable=False, unique=True, autoincrement=True)
ser_name = Column(String(16), nullable=False)
class Host(base):
__tablename__ = 'host'
id = Column(Integer, primary_key=True, nullable=False, unique=True, autoincrement=True)
hostname = Column(String(16), nullable=False)
datetime = Column(DateTime, default=datetime.datetime.now, nullable=False)
# CREATE TABLE `host` (
# `id` int(11) NOT NULL AUTO_INCREMENT,
# `hostname` varchar(16) NOT NULL,
# `datetime` date NOT NULL,
# PRIMARY KEY (`id`),
# UNIQUE KEY `id` (`id`)
# ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
# CREATE TABLE `service` (
# `id` int(11) NOT NULL AUTO_INCREMENT,
# `ser_name` varchar(16) NOT NULL,
# PRIMARY KEY (`id`),
# UNIQUE KEY `id` (`id`)
# ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
# CREATE TABLE `service_to_host` (
# `id` int(11) NOT NULL AUTO_INCREMENT,
# `s_id` int(11) DEFAULT NULL,
# `h_id` int(11) DEFAULT NULL,
# PRIMARY KEY (`id`),
# UNIQUE KEY `id` (`id`),
# UNIQUE KEY `serivce_to_host` (`s_id`,`h_id`),
# KEY `h_id` (`h_id`),
# CONSTRAINT `service_to_host_ibfk_1` FOREIGN KEY (`s_id`) REFERENCES `service` (`id`),
# CONSTRAINT `service_to_host_ibfk_2` FOREIGN KEY (`h_id`) REFERENCES `host` (`id`)
# ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
5.2 通过relationship操作数据
如果没有relationship关联对象,那么我们将需要分别操作三张表,使用relationship将会大大简化这个过程,那么在Service中创建关系:
hosts = relationship('host', secondary='service_to_host', backref='services')
创建后:
- 在Service中存在一个hosts属性,对应host表
- 在Host中被动注入一个services属性,对应service表
- secondary='service_to_host' 表示通过第三张表来关联关系
# 添加一个业务,并创建几台主机
session.add(
Service(ser_name='运营', hosts=[
Host(hostname='openstack'),
Host(hostname='nginx')
])
)
# 添加一个主机,并关联几个业务线
service = session.query(Service).filter(or_(Service.ser_name == '运营', Service.ser_name == '运维')).all()
session.add(
Host(hostname='Tomcat', services=service)
)
# 查询一个业务线下都有哪些主机
service = session.query(Service).filter(Service.ser_name == '运营').first()
for host in service.hosts:
print(host.id, host.hostname)
# 查询一台主机都归属哪些业务线
host = session.query(Host).filter(Host.hostname == 'openstack').first()
for servcie in host.services:
print(service.id, service.ser_name)
6 scoped_session(推荐)
当我们启动多线程来执行数据库操作时,每个线程都会用到session来执行sql语句,一般情况下,我们会在线程内不创建新的session来执行sql语句,下面是一个利用session完成原生sql的执行。
import threading
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = create_engine(
'mysql+pymysql://dahl:123456@10.0.0.10:3306/test',
max_overflow=5,
pool_size=1,
pool_timeout=30,
pool_recycle=-1
)
DBsession = sessionmaker(bind=engine)
def func():
session = DBsession()
cursor = session.execute('show tables')
res = cursor.fetchall()
print(res)
cursor.close()
session.close()
if __name__ == '__main__':
for i in range(10):
threading.Thread(target=func).start()
这里会产生一个问题,每个线程启动时都会创建一个session,用完又会关闭,这样太麻烦了,这里可以使用scoped_session对象来完成,它类似与threading.Local的实现方式。作用是,当线程调用scoped_session对象的功能时,比如各种sql查询,在其内部会为每个线程创建一个新的session对象,让它来使用。
# 1 引入scoped_session
from sqlalchemy.orm import scoped_session
# 2 全局创建session对象
session = scoped_session(DBsession)
# 3 多进程内直接使用
def func():
cursor = session.execute('show tables')
res = cursor.fetchall()
print(res)
cursor.close()
session.remove() # 使用完毕需要remove
不需要关闭,直接使用scoped_session对象的remove方法即可。
实现过程:
- scoped_session是一个类
- 它内部并没有实现所有的Session类的方法
- 它只是在内部,把传入的session对象的属性,进行反射获取,并绑定在自己身上。
- self.registry() 就是为每个线程创建的Session对象,其内部使用的就是threading.local实现的。
源码如下:
# scoping
def instrument(name):
def do(self, *args, **kwargs):
return getattr(self.registry(), name)(*args, **kwargs)
return do
for meth in Session.public_methods:
setattr(scoped_session, meth, instrument(meth))
# registry是ThreadLocalRegistry对象
self.registry = ThreadLocalRegistry(session_factory)
# ThreadLocalRegistry对象内部通过threading.local实现的
def __init__(self, createfunc):
self.createfunc = createfunc # Session对象
self.registry = threading.local()
# registry()其实调用的就是__call__方法
def __call__(self):
try:
return self.registry.value
except AttributeError:
val = self.registry.value = self.createfunc() # 第一次执行,就会实例化一个Session对象
return val
7 别名
当使用join语句连表查询时,难免会碰到两个表重名的字段,这里就可以使用label来对字段进行别名显示。
stds = session.query(User.name.label('username'), User.id, Deptment.dep_name).join(Deptment).all()
for std in stds:
print(std.username, std.id, std.dep_name)
42 - 数据库-orm-SQLAlchemy的更多相关文章
- tornado 06 数据库—ORM—SQLAlchemy——基本内容及操作
tornado 06 数据库—ORM—SQLAlchemy——基本内容及操作 一. ORM #在服务器后台,数据是要储存在数据库的,但是如果项目在开发和部署的时候,是使用的不同的数据库,该怎么办?是不 ...
- tornado 07 数据库—ORM—SQLAlchemy—查询
tornado 07 数据库—ORM—SQLAlchemy—查询 引言 #上节课使用query从数据库查询到了结果,但是query返回的对象是直接可用的吗 #在query.py内输入一下内容 from ...
- 第二百八十九节,MySQL数据库-ORM之sqlalchemy模块操作数据库
MySQL数据库-ORM之sqlalchemy模块操作数据库 sqlalchemy第三方模块 sqlalchemysqlalchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API ...
- 【tips】ORM - SQLAlchemy操作MySQL数据库
优先(官方文档SQLAlchemy-version1.2): sqlalchemy | 作者:斯芬克斯 推荐一(长篇幅version1.2.0b3):python约会之ORM-sqlalchemy | ...
- python ORM - sqlalchemy 操作使用
python操作数据库 使用 ORM - sqlalchemy,pymsql 安装: pip install pymsq pip install sqlalchemy 一. '''连接数据库''' ...
- 二十九:数据库之SQLAlchemy连接数据库
手写SQL复用性不高,SQL越复杂越容易出bug,而且容易引起SQL注入,所以现在Ibanez使用orm框架将数据库映射为数据模型,这是使用SQLAlchemy 准备工作,安装SQLAlchemy和P ...
- Django学习笔记〇四——数据库ORM的使用(有待修改)
Django框架基本上都是要和数据库结合使用的,我在以前讲过SQLAlchemy框架的使用,Django支持的不是SQLAlchemy,但是也内嵌了ORM框架,可以不需要直接面对数据库编程,而可以通过 ...
- Android 开源项目android-open-project工具库解析之(一) 依赖注入,图片缓存,网络相关,数据库orm工具包,Android公共库
一.依赖注入DI 通过依赖注入降低View.服务.资源简化初始化.事件绑定等反复繁琐工作 AndroidAnnotations(Code Diet) android高速开发框架 项目地址:https: ...
- LitepalNewDemo【开源数据库ORM框架-LitePal2.0.0版本的使用】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 本Demo使用的是LitePal2.0.0版本,对于旧项目如何升级到2.0.0版本,请阅读<赶快使用LitePal 2.0版本 ...
- Flask学习笔记:数据库ORM操作MySQL+pymysql/mysql-python+SQLAlchemy/Flask-SQLAlchemy
Python中使用sqlalchemy插件可以实现ORM(Object Relationship Mapping,模型关系映射)框架,而Flask中的flask-sqlalchemy其实就是在sqla ...
随机推荐
- VUE开发一个图片轮播的组件
完成效果图如下: vue开发的思路主要是数据绑定,代码如下: <template> <div ref="root" style="user-select ...
- 【转】__ATTRIBUTE__ 你知多少
__ATTRIBUTE__ 你知多少? GNU C 的一大特色就是__attribute__ 机制.__attribute__ 可以设置函数属性(Function Attribute ).变量属性(V ...
- Docker跟一般的虚拟机有什么区别
这是StackOverflow上的一个问题及其回答的翻译(原文:Docker.io跟一般的虚拟机有什么区别?).原文主要回答了三个问题: 1. Docker.io的基本原理是什么?2. 为什么在doc ...
- Android Paging库使用详解
Android分页包能够更轻易地在RecyclerView里面缓慢且优雅地加载数据. 许多应用从数据源消耗数据, 数据源里面有大量的数据, 但是一次却只展示一小部分. 分页包帮助应用观测和展示大量数据 ...
- CF600E Lomsat gelral 【线段树合并】
题目链接 CF600E 题解 容易想到就是线段树合并,维护每个权值区间出现的最大值以及最大值位置之和即可 对于每个节点合并一下两个子节点的信息 要注意叶子节点信息的合并和非叶节点信息的合并是不一样的 ...
- BGP的那些安全痛点(转)
0x00 BGP(RFC 1771. RFC 4271)定义 全称是Border Gateway Protocol, 对应中文是边界网关协议,最新版本是BGPv4. BGP是互联网上一个核心的互联网去 ...
- 项目开发中git常用命令、git工作流、git分支模型
#新建代码库git init # 在当前目录新建一个Git代码库git init [project-name] # 新建一个目录,将其初始化为Git代码库git clone [url] # 下载一个项 ...
- 解题:HEOI 2013 SAO
题面 不好讲,直接上式子吧=.= 设$dp[i][j]$表示考虑完$i$的子树后$i$的排名为$j$的方案数,然后转移类似树形背包,具体来说是(这里假设子树在$i$后选,其实反过来还用这个式子答案也是 ...
- 【bzoj2795】【Poi2012】A Horrible Poem
题解: 询问区间的整循环节 设区间长度为$n$ 如果有循环节长为$x$和$y$,那由斐蜀定理得$gcd(x,y)$也一定为一个循环节: 假设最小的循环节长为$mn$,那么对于任何循环节长$x$,一定$ ...
- P4887 第十四分块(前体) 莫队
题意: 给你一个序列,每次询问l,r问多少个a[i]^a[j]有k个1,k固定. 序列长度1e5,a[i]<=2^14 时限1s,空间40M 题解: 个人其实开始没什么思路,看了题解也好久,题解 ...