操作系统之Linux的内存分页管理
内存是计算机的主存储器。内存为进程开辟出进程空间,让进程在其中保存数据。我将从内存的物理特性出发,深入到内存管理的细节,特别是了解虚拟内存和内存分页的概念。
内存
简单地说,内存就是一个数据货架。内存有一个最小的存储单位,大多数都是一个字节。内存用内存地址(memory address)来为每个字节的数据顺序编号。因此,内存地址说明了数据在内存中的位置。内存地址从0开始,每次增加1。这种线性增加的存储器地址称为线性地址(linear address)。为了方便,我们用十六进制数来表示内存地址,比如0x00000003、0x1A010CB0。这里的“0x”用来表示十六进制。“0x”后面跟着的,就是作为内存地址的十六进制数。
内存地址的编号有上限。地址空间的范围和地址总线(address bus)的位数直接相关。CPU通过地址总线来向内存说明想要存取数据的地址。以英特尔32位的80386型CPU为例,这款CPU有32个针脚可以传输地址信息。每个针脚对应了一位。如果针脚上是高电压,那么这一位是1。如果是低电压,那么这一位是0。32位的电压高低信息通过地址总线传到内存的32个针脚,内存就能把电压高低信息转换成32位的二进制数,从而知道CPU想要的是哪个位置的数据。用十六进制表示,32位地址空间就是从0x00000000 到0xFFFFFFFF。
内存的存储单元采用了随机读取存储器(RAM, Random Access Memory)。所谓的“随机读取”,是指存储器的读取时间和数据所在位置无关。与之相对,很多存储器的读取时间和数据所在位置有关。就拿磁带来说,我们想听其中的一首歌,必须转动带子。如果那首歌是第一首,那么立即就可以播放。如果那首歌恰巧是最后一首,我们快进到可以播放的位置就需要花很长时间。我们已经知道,进程需要调用内存中不同位置的数据。如果数据读取时间和位置相关的话,计算机就很难把控进程的运行时间。因此,随机读取的特性是内存成为主存储器的关键因素。
内存提供的存储空间,除了能满足内核的运行需求,还通常能支持运行中的进程。即使进程所需空间超过内存空间,内存空间也可以通过少量拓展来弥补。换句话说,内存的存储能力,和计算机运行状态的数据总量相当。内存的缺点是不能持久地保存数据。一旦断电,内存中的数据就会消失。因此,计算机即使有了内存这样一个主存储器,还是需要硬盘这样的外部存储器来提供持久的储存空间。
虚拟内存
内存的一项主要任务,就是存储进程的相关数据。我们之前已经看到过进程空间的程序段、全局数据、栈和堆,以及这些这些存储结构在进程运行中所起到的关键作用。有趣的是,尽管进程和内存的关系如此紧密,但进程并不能直接访问内存。在Linux下,进程不能直接读写内存中地址为0x1位置的数据。进程中能访问的地址,只能是虚拟内存地址(virtual memory address)。操作系统会把虚拟内存地址翻译成真实的内存地址。这种内存管理方式,称为虚拟内存(virtual memory)。
每个进程都有自己的一套虚拟内存地址,用来给自己的进程空间编号。进程空间的数据同样以字节为单位,依次增加。从功能上说,虚拟内存地址和物理内存地址类似,都是为数据提供位置索引。进程的虚拟内存地址相互独立。因此,两个进程空间可以有相同的虚拟内存地址,如0x10001000。虚拟内存地址和物理内存地址又有一定的对应关系,如图1所示。对进程某个虚拟内存地址的操作,会被CPU翻译成对某个具体内存地址的操作。

图1 虚拟内存地址和物理内存地址的对应
应用程序来说对物理内存地址一无所知。它只可能通过虚拟内存地址来进行数据读写。程序中表达的内存地址,也都是虚拟内存地址。进程对虚拟内存地址的操作,会被操作系统翻译成对某个物理内存地址的操作。由于翻译的过程由操作系统全权负责,所以应用程序可以在全过程中对物理内存地址一无所知。因此,C程序中表达的内存地址,都是虚拟内存地址。比如在C语言中,可以用下面指令来打印变量地址:
int v = 0;
printf("%p", (void*)&v);
本质上说,虚拟内存地址剥夺了应用程序自由访问物理内存地址的权利。进程对物理内存的访问,必须经过操作系统的审查。因此,掌握着内存对应关系的操作系统,也掌握了应用程序访问内存的闸门。借助虚拟内存地址,操作系统可以保障进程空间的独立性。只要操作系统把两个进程的进程空间对应到不同的内存区域,就让两个进程空间成为“老死不相往来”的两个小王国。两个进程就不可能相互篡改对方的数据,进程出错的可能性就大为减少。
另一方面,有了虚拟内存地址,内存共享也变得简单。操作系统可以把同一物理内存区域对应到多个进程空间。这样,不需要任何的数据复制,多个进程就可以看到相同的数据。内核和共享库的映射,就是通过这种方式进行的。每个进程空间中,最初一部分的虚拟内存地址,都对应到物理内存中预留给内核的空间。这样,所有的进程就可以共享同一套内核数据。共享库的情况也是类似。对于任何一个共享库,计算机只需要往物理内存中加载一次,就可以通过操纵对应关系,来让多个进程共同使用。IPO中的共享内存,也有赖于虚拟内存地址。
内存分页
虚拟内存地址和物理内存地址的分离,给进程带来便利性和安全性。但虚拟内存地址和物理内存地址的翻译,又会额外耗费计算机资源。在多任务的现代计算机中,虚拟内存地址已经成为必备的设计。那么,操作系统必须要考虑清楚,如何能高效地翻译虚拟内存地址。
记录对应关系最简单的办法,就是把对应关系记录在一张表中。为了让翻译速度足够地快,这个表必须加载在内存中。不过,这种记录方式惊人地浪费。如果树莓派1GB物理内存的每个字节都有一个对应记录的话,那么光是对应关系就要远远超过内存的空间。由于对应关系的条目众多,搜索到一个对应关系所需的时间也很长。这样的话,会让树莓派陷入瘫痪。
因此,Linux采用了分页(paging)的方式来记录对应关系。所谓的分页,就是以更大尺寸的单位页(page)来管理内存。在Linux中,通常每页大小为4KB。如果想要获取当前树莓派的内存页大小,可以使用命令:
$getconf PAGE_SIZE
得到结果,即内存分页的字节数:
4096
返回的4096代表每个内存页可以存放4096个字节,即4KB。Linux把物理内存和进程空间都分割成页。
内存分页,可以极大地减少所要记录的内存对应关系。我们已经看到,以字节为单位的对应记录实在太多。如果把物理内存和进程空间的地址都分成页,内核只需要记录页的对应关系,相关的工作量就会大为减少。由于每页的大小是每个字节的4000倍。因此,内存中的总页数只是总字节数的四千分之一。对应关系也缩减为原始策略的四千分之一。分页让虚拟内存地址的设计有了实现的可能。
无论是虚拟页,还是物理页,一页之内的地址都是连续的。这样的话,一个虚拟页和一个物理页对应起来,页内的数据就可以按顺序一一对应。这意味着,虚拟内存地址和物理内存地址的末尾部分应该完全相同。大多数情况下,每一页有4096个字节。由于4096是2的12次方,所以地址最后12位的对应关系天然成立。我们把地址的这一部分称为偏移量(offset)。偏移量实际上表达了该字节在页内的位置。地址的前一部分则是页编号。操作系统只需要记录页编号的对应关系。

图2 地址翻译过程
多级分页表
内存分页制度的关键,在于管理进程空间页和物理页的对应关系。操作系统把对应关系记录在分页表(page table)中。这种对应关系让上层的抽象内存和下层的物理内存分离,从而让Linux能灵活地进行内存管理。由于每个进程会有一套虚拟内存地址,那么每个进程都会有一个分页表。为了保证查询速度,分页表也会保存在内存中。分页表有很多种实现方式,最简单的一种分页表就是把所有的对应关系记录到同一个线性列表中,即如图2中的“对应关系”部分所示。
这种单一的连续分页表,需要给每一个虚拟页预留一条记录的位置。但对于任何一个应用进程,其进程空间真正用到的地址都相当有限。我们还记得,进程空间会有栈和堆。进程空间为栈和堆的增长预留了地址,但栈和堆很少会占满进程空间。这意味着,如果使用连续分页表,很多条目都没有真正用到。因此,Linux中的分页表,采用了多层的数据结构。多层的分页表能够减少所需的空间。
我们来看一个简化的分页设计,用以说明Linux的多层分页表。我们把地址分为了页编号和偏移量两部分,用单层的分页表记录页编号部分的对应关系。对于多层分页表来说,会进一步分割页编号为两个或更多的部分,然后用两层或更多层的分页表来记录其对应关系,如图3所示。

图3 多层分页表
在图3的例子中,页编号分成了两级。第一级对应了前8位页编号,用2个十六进制数字表示。第二级对应了后12位页编号,用3个十六进制编号。二级表记录有对应的物理页,即保存了真正的分页记录。二级表有很多张,每个二级表分页记录对应的虚拟地址前8位都相同。比如二级表0x00,里面记录的前8位都是0x00。翻译地址的过程要跨越两级。我们先取地址的前8位,在一级表中找到对应记录。该记录会告诉我们,目标二级表在内存中的位置。我们再在二级表中,通过虚拟地址的后12位,找到分页记录,从而最终找到物理地址。
多层分页表就好像把完整的电话号码分成区号。我们把同一地区的电话号码以及对应的人名记录同通一个小本子上。再用一个上级本子记录区号和各个小本子的对应关系。如果某个区号没有使用,那么我们只需要在上级本子上把该区号标记为空。同样,一级分页表中0x01记录为空,说明了以0x01开头的虚拟地址段没有使用,相应的二级表就不需要存在。正是通过这一手段,多层分页表占据的空间要比单层分页表少了很多。
多层分页表还有另一个优势。单层分页表必须存在于连续的内存空间。而多层分页表的二级表,可以散步于内存的不同位置。这样的话,操作系统就可以利用零碎空间来存储分页表。还需要注意的是,这里简化了多层分页表的很多细节。最新Linux系统中的分页表多达3层,管理的内存地址也比本章介绍的长很多。不过,多层分页表的基本原理都是相同。
综上,我们了解了内存以页为单位的管理方式。在分页的基础上,虚拟内存和物理内存实现了分离,从而让内核深度参与和监督内存分配。应用进程的安全性和稳定性因此大为提高。
页面置换算法
如果发生了缺页中断,就需要从磁盘上将需要的页面调入内存。如果内存没有多余的空间,就需要在现有的页面中选择一个页面进行替换。使用不同的页面置换算法,页面更换的顺序也会各不相同。如果挑选的页面是之后很快又要被访问的页面,那么系统将很开再次产生缺页中断,因为磁盘访问速度远远内存访问速度,缺页中断的代价是非常大的。因此,挑选哪个页面进行置换不是随随便便的事情,而是有要求的。
2.1 页面置换的目标
页面置换时挑选页面的目标主要在于降低随后发生缺页中断的次数或概率。
因此,挑选的页面应当是随后相当长时间内不会被访问的页面,最好是再也不会被访问的页面。BTW,如果可能,最好选择一个没有修改过的页面,这样替换时就无须将被替换页面的内容写回磁盘,从而进一步加快缺页中断的响应速度。
所以,为了达到这个目的,先驱们设计出了各种各样的页面置换算法,下面就来看看这些算法。
2.2 随机更换算法
在需要替换页面的时候,产生一个随机页面号,从而替换与该页面号对应的物理页面。遗憾的是,随机选出的被替换的页面不太可能是随后相当长时间内不会被访问的页面。也就是说,这种算法难以保证最小化随后的缺页中断次数。事实上,这种算法的效果相当差。
2.3 先进先出算法
顾名思义,先进先出(FIFO,First In First Out)算法的核心是更换最早进入内存的页面,其实现机制是使用链表将所有在内存中的页面按照进入时间的早晚链接起来,然后每次置换链表头上的页面就行了,而新加进来的页面则挂在链表的末端,如下图所示:

FIFO的优点是简单且容易实现,缺点是如果最先加载进来的页面是经常被访问的页面,那么就可能造成被访问的页面替换到磁盘上,导致很快就需要再次发生缺页中断,从而降低效率。
2.4 第二次机会算法
由于FIFO只考虑进入内存的时间,不关心一个页面被访问的频率,从而有可能造成替换掉一个被经常访问的页面而造成效率低下。那么,可以对FIFO进行改进:在使用FIFO更换一个页面时,需要看一下该页面是否在最近被访问过,如果没有被访问过,则替换该页面。反之,如果最近被访问过(通过检查其访问位的取值),则不替换该页面,而是将该页面挂到链表末端,并将该页面进入内存的时间设置为当前时间,并将其访问位清零。这样,对于最近被访问过的页面来说,相当于给了它第二次机会。
例如,当A页面最近被访问过,即其访问位R的值为1,则使用第二次机会算法之后,链表的格局如下图所示:
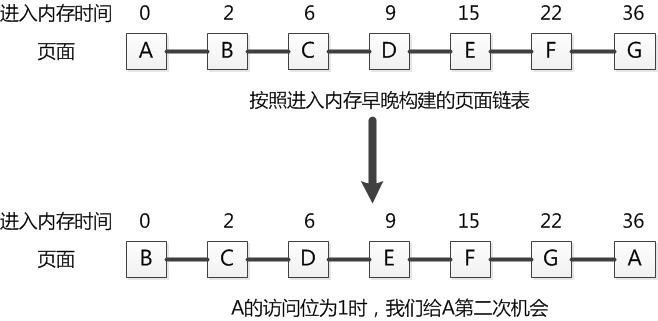
第二次机会算法简单、公平且容易实现。但是,每次给予一个页面第二次机会时,将其移动到链表末端需要耗费时间。此外,页面的访问位只在页面替换进行扫描时才可能清零,所以其时间局域性体现得不好,访问位为1的页面可能是很久以前访问的,时间上的分辨粒度太粗,从而影响页面替换的效果。
2.5 时钟算法
为了改善第二次机会算法的缺点,先驱们提出了时钟算法。时钟算法的核心思想是:将页面排成一个时钟的形状,该时钟有一个针臂,每次需要更换页面时,我们从针臂所指的页面开始检查。如果当前页面的访问位为0,即从上次检查到这次,该页面没有被访问过,将该页面替换。反之,就将其访问位清零,并顺时针移动指针到下一个页面。重复这些步骤,直到找到一个访问位为0的页面。
例如下图所示的一个时钟,指针指向的页面是F,因此第一个被考虑替换的页面是F。如果页面F的访问位为0,F将被替换。如果F的访问位为1,则F的访问位清零,指针移动到页面G。
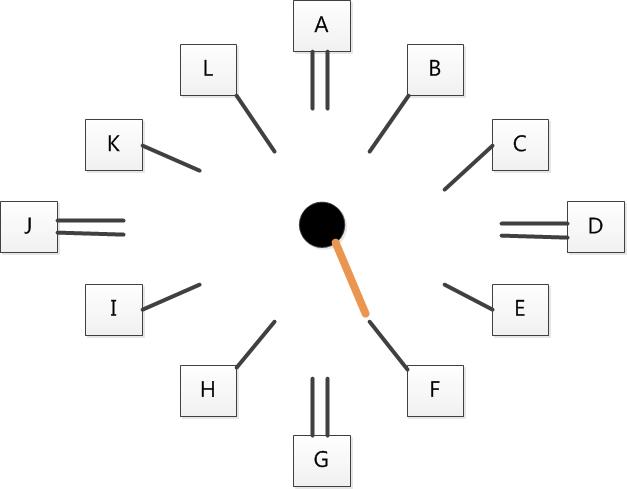
从表面上看,它和第二次机会算法类似,都是访问位为0就更换,反之则再给一次机会。但是,它和第二次机会算法还是有几点不同:
(1)他们的数据结构不一样,第二次机会使用的是链表,时钟算法使用的是索引(整数指针)。这样,其使用的内存空间不一样。
(2)第二次机会需要使用额外的内存,而时钟算法可以直接使用页表。使用页表的好处是无需额外的空间,更大的好处是页面的访问位会定期自动清零,这样将使得时钟算法的时间分辨粒度较第二次机会算法高,从而取得更好的页面替换效果。
时钟算法的精髓是第二次机会,其缺点也就和第二次机会算法一样:过于公平,没有考虑到不同页面调用频率的不同,有可能换出不应该或不能换出的页面,还可能造成无限循环。
PS:至此,随机、FIFO、第二次机会与时钟算法的介绍就到此结束,这四种算法都是属于“公平算法”,即所有的页面都或多或少地给予公平待遇,没有页面获得特殊待遇。但是这种公平实现方式,会使效率受到一定影响,这时因为个体对于整个系统的贡献没有被区别对待,造成贡献大的和贡献小的待遇一样,自然会影响整个系统的效率。
2.6 最优更换算法
我们知道,最理想的页面替换算法是选择一个再也不会被访问的页面进行替换。如果不存在这样的页面,那至少选择一个在随后最长时间内不会被访问的页面进行替换。这样,我们就可以保证在随后发生缺页中断的次数最小或概率最低,这种算法就是最有替换算法。
但是,我们没法知道一个页面随后多长时间不会被访问,因此最优更换算法在实际中没法实现,那么为什么要介绍最有更换算法呢?这是为了定义一个标杆,以此来评判其他算法的优劣。
2.7 NRU(最近未被使用)算法
顾名思义,NRU就是选择一个在最近一段时间内没有被访问过的页面进行替换,这是基于程序访问的时空局域性。因为根据时空局域性原理,一个最近没有被访问的页面,在随后的时间里也不太可能被访问,而NRU的实现方式就是利用页面的访问和修改位。
每个页面都有一个访问位和一个修改位,凡是对页面进行读写操作时,访问位被设置为1。当进程对页面进行读写操作时,修改位设置为1。根据这两个位的状态来对页面进行分类的话,可以分成以下四种页面类型:1、2、3、4。

有了这个分类,NRU算法就按照这四类页面的顺序依次寻找可以替换的页面。如果所有页面皆被访问和修改过,那也只能从中替换掉一个页面,因此NRU算法总是会终结的。
当然,这种分类比较笼统,在同一类页面里,我们没有办法分辨出哪一类被访问的时间更近一些。即在某些情况下,我们替换的可能并不是最近没有被使用的页面。
2.8 LRU(最近最少使用)算法
与NRU算法相比,LRU算法不仅考虑最近是否用过,还要考虑最近使用的频率。这里是基于过去的数据预测未来:如果一个页面被访问的频率低,那么以后很可能也用不到。
LRU算法的实现必须以某种方式记录每个页面被访问的次数,这是个相当大的工作量。最简单的方式就是在页表的记录项里增加一个计数域,一个页面被访问一次,这个计数器的值就增加1。于是,当需要更换页面时,只需要找到计数域值最小的页面替换即可,该页面即是最近最少使用的页面。另一种简单实现方式就是用一个链表将所有页面链接起来,最近被使用的页面在链表头,最近未被使用的放在链表尾。在每次页面访问时对这个链表进行更新,使其保持最近被使用的页面在链表头。
LRU算法虽然很好,但是实现成本高(需要分辨出不同页面中哪个页面时最近最少使用的),并且时间代价大(每次页面访问发生时都需要更新记录)。因此,一般的商业操作系统都没有采纳LRU页面更新算法。
2.9 工作集算法
由于不可能精确地确定那个页面是最近最少使用的,那就干脆不花费这个力气,只维持少量的信息使得我们选出的替换页面不太可能是马上又会使用的页面即可。这种少量的信息就是工作集信息。
工作集概念来源于程序访问的时空局限性,即在一段时间内,程序访问的页面将局限在一组页面集合上。例如,最近k次访问均发生在某m个页面上,那么m就是参数为k时的工作集。我们用w(k,t)来表示在时间t时k次访问所涉及的页面数量。
显然,随着k的增长,w(k,t)的值也随之增长;但是当k增长到某个数值之后,w(k,t)的值将增长极其缓慢甚至接近停滞,并维持一段时间的稳定,如下图所示:

由上图可以看出,如果一个程序在内存里面的页面数与其工作集大小相等或者超过工作集,则该程序可在一段时间内不会发生缺页中断。如果其在内存的页面数小于工作集,则发生缺页中断的频率将增加,甚至发生内存抖动。
因此,工作计算法的目标就是维持当前的工作集的页面在物理内存里面。每次页面更换时,寻找一个不属于当前工作集的页面替换即可。这样,我们再寻找页面时只需要将页面分离为两大类即可:当前工作集内页面和当前工作集外页面。如此,只要找到一个飞当前工作集的页面,将其替换即可。
工作集算法的优点:实现简单,只需要在页表的每个记录增加一个虚拟时间域即可。而且,这个时间域不是每次发生访问时都需要更新,而是在需要更换页面时,页面更换算法对其进行修改,因此时间成本也不大。
工作集算法的缺点:每次扫描页面进行替换时,有可能需要扫描整个页表。然而,并不是所有页面都内存里,因此扫描过程中的一大部分时间将是无用功。另外,由于其数据结构是线性的,会造成每次都按同样的顺序进行扫描,显得不太公平。
2.10 工作集时钟算法
鉴于工作集算法的缺点,先驱们将工作集算法与时钟算法结合起来,设计出了工作集时钟算法,即使用工作集算法的原理,但是将页面的扫描顺序按照时钟的形式组织起来。这样每次需要替换页面时,从指针指向的页面开始扫描,从而达到更加公平的状态。而且,按时钟组织的页面只是在内存里面的页面,在内存外的页面不放在时钟圈里,从而提高实现效率。
鉴于其时间与空间上的优势,工作集时钟算法被大多商业操作系统所采纳。
操作系统之Linux的内存分页管理的更多相关文章
- 【操作系统之十】内存分页管理与swap
一.虚拟内存电脑里内存分内存条(这里我们叫物理内存)和硬盘,内存条保存程序运行时数据,硬盘持久保存数据.那么虚拟内存是什么? 程序运行会启动一个进程,进程里有程序段.全局数据.栈和堆,这些都会加载到内 ...
- [转帖]运维必读:Linux 的内存分页管理
运维必读:Linux 的内存分页管理 https://cloud.tencent.com/developer/article/1356431 内存是计算机的主存储器.内存为进程开辟出进程空间,让进程在 ...
- Linux的内存分页管理
作者:Vamei 出处:http://www.cnblogs.com/vamei 严禁转载 内存是计算机的主存储器.内存为进程开辟出进程空间,让进程在其中保存数据.我将从内存的物理特性出发,深入到内存 ...
- Linux的内存分页管理【转】
内存是计算机的主存储器.内存为进程开辟出进程空间,让进程在其中保存数据.我将从内存的物理特性出发,深入到内存管理的细节,特别是了解虚拟内存和内存分页的概念. 内存 简单地说,内存就是一个数据货架.内存 ...
- 吴裕雄--天生自然Linux操作系统:Linux 用户和用户组管理
Linux系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统. 用户的账号一方面可以帮助系统管理员对使用系统的用户进行 ...
- 操作系统:x86下内存分页机制 (1)
前置知识: 分段的概念(当然手写过肯定是坠吼的 为什么要分页 当我们写程序的时候,总是倾向于把一个完整的程序分成最基本的数据段,代码段,栈段.并且普通的分段机制就是在进程所属的LDT中把每一个段给标识 ...
- Linux共享内存的管理
在进程通信应用中会用到共享内存,这就涉及到了IPC,与IPC相关的命令包括:ipcs.ipcrm(释放IPC).IPCS命令是Linux下显示进程间通信设施状态的工具.我们知道,系统进行进程间通信(I ...
- 吴裕雄--天生自然Linux操作系统:Linux 文件与目录管理
Linux的目录结构为树状结构,最顶级的目录为根目录 /. 其他目录通过挂载可以将它们添加到树中,通过解除挂载可以移除它们. 绝对路径: 路径的写法,由根目录 / 写起,例如: /usr/share/ ...
- Linux内核内存管理架构
内存管理子系统可能是linux内核中最为复杂的一个子系统,其支持的功能需求众多,如页面映射.页面分配.页面回收.页面交换.冷热页面.紧急页面.页面碎片管理.页面缓存.页面统计等,而且对性能也有很高的要 ...
随机推荐
- Spring----最小化Spring配置
在Spring的配置文件中,我们可以使用<bean>元素定义Bean,以及使用<constructor-arg>或着<property>元素装配bean,这对于包含 ...
- Iframe内联框架
iframe:内联框架标签,用于在网页中任意的位置嵌入另一个网页 <iframe src="url地址"> </iframe> iframe标签的常用属性 ...
- MQ疑难杂症小记
为什么使用消息队列? 什么业务场景,这个业务场景有个什么技术挑战,如果不用MQ可能会很麻烦,但是你现在用了MQ之后带给了你很多的好处.消息队列的常见使用场景,其实场景有很多,但是比较核心的有3个:解耦 ...
- windows 查看端口
windowsnetstat命令查看进程:netstat -ano查看占用端口进程:netstat -ano|findstr “端口号”,例子netstat -ano|findstr “8080”.t ...
- 纯web实现游记类手机端应用
初衷 当初的一个学习框架项目,采用sui框架实现的一套手机端页面.今天清理github的时候重新整理了一下,因为设计的确实不错嘛,拿出来大家一起学习...哈哈 说明 采用sui框架 纯html/css ...
- ASP.Net与JSP如何共享Session值
思路: ASP.NET中序列化Session以二进制数据保存到数据库,然后由JSP读取数据库中的二进制数据反序列化成Session对象,再强制转化成JAVA的Session对象登录的ASPX文件 ...
- Pig UDF 用户自定义函数
注册UDF do.pig的内容如下: register /xx/yy.jar data = load 'data'; result = foreach data generate aa.bb.Uppe ...
- WCF3.5 SP1 参考源码索引
http://www.projky.com/dotnet/WCF3.5SP1/Microsoft/InfoCards/AccessibilityApplicationManager.cs.htmlht ...
- HBase Compaction详解
HBase Compaction策略 RegionServer这种类LSM存储引擎需要不断的进行Compaction来减少磁盘上数据文件的个数和删除无用的数据从而保证读性能. RegionServer ...
- javaweb 读取properties配置文件参数
场景1:在servlet中读取properties配置文件参数 protected void doGet(HttpServletRequest request, HttpServletResponse ...