Hadoop HDFS概念学习系列之HDFS升级和回滚机制(十二)
不多说,直接上干货!
HDFS升级和回滚机制
作为一个大型的分布式系统,Hadoop内部实现了一套升级机制,当在一个集群上升级Hadoop时,像其他的软件升级一样,可能会有新的bug或一些会影响现有应用的非兼容性变更出现。在任何有实际意义的HDFS系统中,丢失数据是不允许的,更不用说重新搭建启动HDFS了。当然,升级可能成功,也可能失败。如果失败了,那就用rollback进行回滚;如果过了一段时间,系统运行正常,那就可以通过finalize正式提交这次升级。
相关升级和回滚命令如下:
bin/hadoop namenode一upgrade //升级
bin/hadoop namenode一rollback //回滚
bin/hadoop namenode一finalize //提交
bin/hadoop namenode一importCheckpoint //从Checkpoint恢复
上述命令的importCheckpoint参数用于NameNode发生故障后,从某个检查点恢复。HDFS允许管理员退回到之前的Hadoop版木,将集群的状态回滚到升级之前。
在升级之前,管理员需要用以下命令删除已存在的备份文件:
bin/hadoop dfsadmin-finalizeUpgrade //升级终结操作
下面简单介绍一下一般的升级过程。
在升级Hadoop软件之前,检查是否已经存在一个备份,如果备份存在,可执行升级终结操作删除这个备份。通过以下命令能够知道是否需要对一个集群执行升级终结操作:
dfsadmin -upgradeProgress status
1) 停止集群并部署Hadoop的新版本。
2) 使用upgrade选项运行新的版本(bin/start-dfs.sh -upgrade)
在大多数情况下,集群都能够正常运行。一旦我们认为新的HDFS运行正常(也许经过几天的操作之后),就可以对其执行升级终结操作。需要注意的是,在对一个集群执行升级终结操作之前,删除那些升级前就已经存在的文件并不会真正地释放DataNode上的磁盘空间。
如果需要退回到老版本,执行步骤如下:
1) 停止集群并部署Hadoop的老版本。
2) 用回滚选项启动集群,命令如下:
bin/start-dfs.h -rolback
上面介绍了HDFS的升级和回滚的基本机制,其实可以从状态转移的角度来理解理解HDFS的升级和回滚机制。整个HDFS的状态有:Normal, Upgraded, Rollbacking, Upgrading,Finalizing五种,HDFS集群的状态转移示意图,如下图所示。
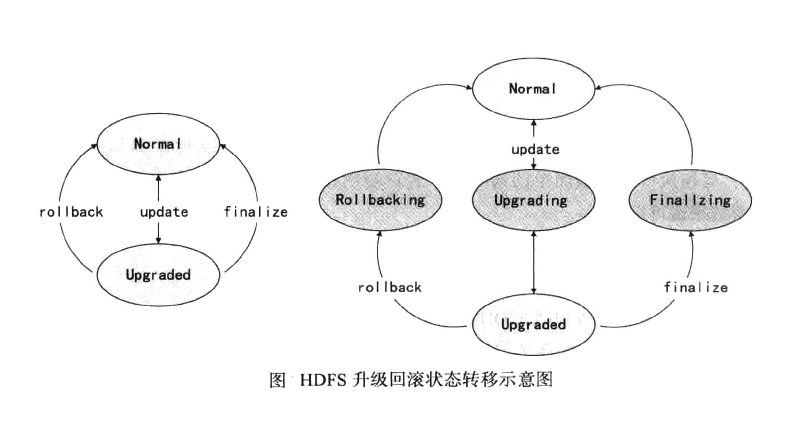
从上图可以看出,升级、回滚、提交都不可能一下完成,这也就是说,在HDFS系统出现故障时,集群可能处于上图右侧图中某一个状态中,特别是在分布式的各个节点上,甚至可能出现有些节点已经升级成功,但有些节点可能处干中间状态的情况,所以Hadoop采用类似于数据库事务的升级机制也就很容易理解了。
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



Hadoop HDFS概念学习系列之HDFS升级和回滚机制(十二)的更多相关文章
- Hadoop Hive概念学习系列之HDFS、Hive、MySQL、Sqoop之间的数据导入导出(强烈建议去看)
Hive总结(七)Hive四种数据导入方式 (强烈建议去看) Hive几种数据导出方式 https://www.iteblog.com/archives/955 (强烈建议去看) 把MySQL里的数据 ...
- Hadoop HDFS概念学习系列之hdfs里的文件下载闲谈(二十六)
hdfs里的文件下载 可以,通过hadoop distributed system来下载,而且速度非常之快.涨知识!!! 或者,通过命令行的方式,也可以! ********************** ...
- Hadoop Hive概念学习系列之hive里的JDBC编程入门(二十二)
Hive与JDBC示例 在使用 JDBC 开发 Hive 程序时, 必须首先开启 Hive 的远程服务接口.在hive安装目录下的bin,使用下面命令进行开启: hive -service hives ...
- Hadoop Hive概念学习系列之hive里的HiveQL——查询语言(十五)
Hive的操作与传统关系型数据库SQL操作十分类似. Hive主要支持以下几类操作: DDL 1.DDL:数据定义语句,包括CREATE.ALTER.SHOW.DESCRIBE.DROP等. 详细点, ...
- Hadoop Hive概念学习系列之hive与依赖环境的交互(二十一)
hive与环境的交互,算是一个小知识点,但掌握不菲! 如何在hive里,也达到这样呢? 不需要这样啦,因为,hive是建立在hadoop之上,启动hive,相当于,就是,hadoop jar ** h ...
- Hadoop HBase概念学习系列之HBase里的存储数据流程(二十三)
这个,很简单,但凡是略懂大数据的,就很清楚,不多说,直接上图.
- 022.掌握Pod-Pod升级和回滚
一 deploymentPod升级和回滚 1.1 deployment升级 若Pod是通过Deployment创建的,可以在运行时修改Deployment的Pod定义(spec.template)或镜 ...
- Hadoop Hive概念学习系列之hive的数据压缩(七)
Hive文件存储格式包括以下几类: 1.TEXTFILE 2.SEQUENCEFILE 3.RCFILE 4.ORCFILE 其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时会直 ...
- Hadoop Hive概念学习系列之hive里的索引(十三)
Hive支持索引,但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键. Hive索引可以建立在表中的某些列上,以提升一些操作的效率,例如减少MapReduce任务中需要 ...
随机推荐
- python编码(七)
本文中,以'哈'来解释作示例解释所有的问题,“哈”的各种编码如下: 1. UNICODE (UTF8-16),C854:2. UTF-8,E59388:3. GBK,B9FE. 一.python中的s ...
- (KMP 最大表示最小表示)String Problem -- hdu-- 3374
http://acm.hdu.edu.cn/showproblem.php?pid=3374 String Problem Time Limit: 2000/1000 MS (Java/Others) ...
- java.util.Date与java.sql.Date的关系和转换方法(转)
在ResultSet中我们经常使用的setDate或getDate的数据类型是java.sql.Date,而在平时java程序中我们一般习惯使用 java.util.Date. 因此在DAO层我们经常 ...
- asp.net—工厂模式
一.什么是工厂模式 定义:定义一个创建对象的接口,让其子类自己决定实例化哪一个工厂类. 二.怎么使用工厂模式 首先模拟一个场景:有一个汽车工厂, 可以日本车.美国车.中国车... 这个场景怎么用工厂 ...
- [ASP.NET]ASP.NET中常用的26个优化性能方法
1. 数据库访问性能优化 数据库的连接和关闭 访问数据库资源需要创建连接.打开连接和关闭连接几个操作.这些过程需要多次与数据库交换信息以通过身份验证,比较耗费服务器资源.ASP.NET中提供了连接池( ...
- C#基础复习(1) 之 Struct与Class的区别
参考资料 [1] 毛星云[<Effective C#>提炼总结] https://zhuanlan.zhihu.com/p/24553860 [2] <C# 捷径教程> [3] ...
- Java开发 小工具累计
array to list Integer[] spam = new Integer[] { 1, 2, 3 }; List<Integer> rlt = Arrays.asList(sp ...
- Redis持久化策略(RDB &AOF)
redis持久化的几种方式 1.前言 Redis是一种高级key-value数据库.它跟memcached类似,不过数据可以持久化,而且支持的数据类型很丰富.有字符串,链表,集 合和有序集合.支持在服 ...
- python web开发——c2 flask框架和flask_script
重定向/error 通过flask中的redirect方法和自定义的newpath函数.redirect_demo函数实现重定向: #coding:utf-8 from flask import Fl ...
- django 视图中执行原生的 sql 查询语句
可以使用objects的raw()方法执行原生的sql语句,进行对数据库的查询操作,raw()方法只能执行查询语句 query_set = your_model.objects.raw("s ...