内存管理算法--Buddy伙伴算法【转】
转自:http://blog.csdn.net/orange_os/article/details/7392986
Buddy算法的优缺点:
1)尽管伙伴内存算法在内存碎片问题上已经做的相当出色,但是该算法中,一个很小的块往往会阻碍一个大块的合并,一个系统中,对内存块的分配,大小是随机的,一片内存中仅一个小的内存块没有释放,旁边两个大的就不能合并。
2)算法中有一定的浪费现象,伙伴算法是按2的幂次方大小进行分配内存块,当然这样做是有原因的,即为了避免把大的内存块拆的太碎,更重要的是使分配和释放过程迅速。但是他也带来了不利的一面,如果所需内存大小不是2的幂次方,就会有部分页面浪费。有时还很严重。比如原来是1024个块,申请了16个块,再申请600个块就申请不到了,因为已经被分割了。
3)另外拆分和合并涉及到 较多的链表和位图操作,开销还是比较大的。
Buddy(伙伴的定义):
这里给出伙伴的概念,满足以下三个条件的称为伙伴:
1)两个块大小相同;
2)两个块地址连续;
3)两个块必须是同一个大块中分离出来的;
Buddy算法的分配原理:
假如系统需要4(2*2)个页面大小的内存块,该算法就到free_area[2]中查找,如果链表中有空闲块,就直接从中摘下并分配出去。如果没有,算法将顺着数组向上查找free_area[3],如果free_area[3]中有空闲块,则将其从链表中摘下,分成等大小的两部分,前四个页面作为一个块插入free_area[2],后4个页面分配出去,free_area[3]中也没有,就再向上查找,如果free_area[4]中有,就将这16(2*2*2*2)个页面等分成两份,前一半挂如free_area[3]的链表头部,后一半的8个页等分成两等分,前一半挂free_area[2]
的链表中,后一半分配出去。假如free_area[4]也没有,则重复上面的过程,知道到达free_area数组的最后,如果还没有则放弃分配。
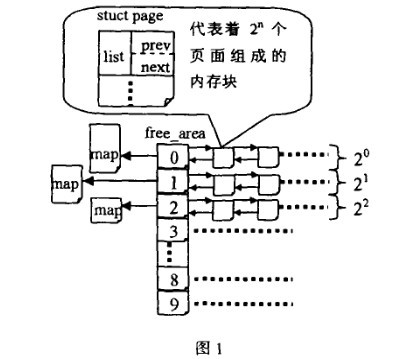
Buddy算法的释放原理:
内存的释放是分配的逆过程,也可以看作是伙伴的合并过程。当释放一个块时,先在其对应的链表中考查是否有伙伴存在,如果没有伙伴块,就直接把要释放的块挂入链表头;如果有,则从链表中摘下伙伴,合并成一个大块,然后继续考察合并后的块在更大一级链表中是否有伙伴存在,直到不能合并或者已经合并到了最大的块(2*2*2*2*2*2*2*2*2个页面)。
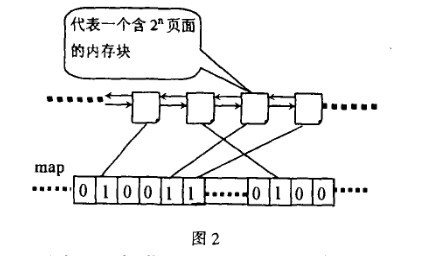
整个过程中,位图扮演了重要的角色,如图2所示,位图的某一位对应两个互为伙伴的块,为1表示其中一块已经分配出去了,为0表示两块都空闲。伙伴中无论是分配还是释放都只是相对的位图进行异或操作。分配内存时对位图的
是为释放过程服务,释放过程根据位图判断伙伴是否存在,如果对相应位的异或操作得1,则没有伙伴可以合并,如果异或操作得0,就进行合并,并且继续按这种方式合并伙伴,直到不能合并为止。
Buddy内存管理的实现:
提到buddy 就会想起linux 下的物理内存的管理 ,这里的memory pool 上实现的 buddy 系统
和linux 上按page 实现的buddy系统有所不同的是,他是按照字节的2的n次方来做block的size
实现的机制中主要的结构如下:
整个buddy 系统的结构:
struct mem_pool_table
{
#define MEM_POOL_TABLE_INIT_COOKIE (0x62756479)
uint32 initialized_cookie;
/* Cookie 指示内存已经被初始化后的魔数, 如果已经初始化设置为0x62756479*/
uint8 *mem_pool_ptr;/* 指向内存池的地址*/
uint32 mem_pool_size;
/* 整个pool 的size,下面是整个max block size 的大小*/
/* 必须是2的n次方,表示池中最大块的大小*/
boolean assert_on_empty;
/* 如果该值被设置成TRUE,内存分配请求没有完成就返回 并输出出错信息*/
uint32 mem_remaining;
/* 当前内存池中剩余内存字节数*/
uint32 max_free_list_index;
/* 最大freelist 的下标,*/
struct mem_free_hdr_type *free_lists[MAX_LEVELS];/* 这个就是伙伴系统的level数组*/
#ifdef FEATURE_MEM_CHECK
uint32 max_block_requested;
uint32 min_free_mem;
/* 放mem_remaining
*/
#endif /* FEATURE_ONCRPC_MEM_CHECK*/
};
这个结构是包含在free node 或alloc node 中的结构:
其中check 和 fill 都被设置为某个pattern
用来检查该node 的合法性
#define MEM_HDR_CHECK_PATTERN ((uint16)0x3CA4)
#define MEM_HDR_FILL_PATTERN ((uint8)0x5C)
typedef struct tagBuddyMemBlockHeadType
{
mem_pool_type pool;
/*回指向内存池*/
uint16 check;
uint8 state; /* bits 0-3 放该node 属于那1级 bit 7 如果置1,表示已经分配(not
free)
uint8 fill;
} BUDDY_MEM_BLOCK_HEAD_TYPE;
这个结构就是包含node 类型结构的 free header 的结构:
typedef struct tagBuddyMemHeadType
{
mem_node_hdr_type hdr;
struct mem_free_hdr_type * pNext; /* next,prev,用于连接free header的双向 list*/
struct mem_free_hdr_type * pPrev;
} mem_free_hdr_type;
这个结构就是包含node 类型结构的 alloc header 的结构:
已分配的mem 的node 在内存中就是这样表示的
- typedef struct mem_alloc_hdr_type
- {
- mem_node_hdr_type hdr;
- #ifdef FEATURE_MEM_CHECK_OVERWRITE
- uint32 in_use_size;
- #endif
- } mem_alloc_hdr_type;
其中用in_use_size 来表示如果请求分配的size 所属的level上实际用了多少
比如申请size=2000bytes, 按size to level 应该是2048,实际in_use_size
为2000,剩下48byte 全部填充为某一数值,然后在以后free 是可以check
是否有overwite 到着48byte 中的数值,一般为了速度,只 检查8到16byte
另外为什么不把这剩下的48byte 放到freelist 中其他level 中呢,这个可能
因为本来buddy 系统的缺点就是容易产生碎片,这样的话就更碎了
关于free or alloc node 的示意图:
假设
最小块为2^4=16,着是由mem_alloc_hdr_type (12byte)决定的, 实际可分配4byte
如果假定最大max_block_size =1024,
如果pool 有mem_free_hdr_type[0]上挂了两个1024的block node
上图是free node, 下图紫色为alloc node

接下来主要是buddy 系统的操作主要包括pool init , mem alloc ,mem free
pool init :
1. 将实际pool 的大小去掉mem_pool_table 结构大小后的size 放到
mem_pool_size, 并且修改实际mem_pool_ptr指向前进mem_pool_table
结构大小的地址
2. 接下来主要将mem_pool_size 大小的内存,按最大块挂到free_lists 上
level 为0的list 上,然后小于该level block size 部分,继续挂大下一
级,循环到全部处理完成 (感觉实际用于pool的size ,应该为减去
mem_pool_table 的大小,然后和最大块的size 对齐,这样比较好,
但没有实际测试过)
mem alloc:
这部分相当简单,先根据请求mem的size ,实际分配时需要加上mem_alloc_hdr_type
这12byte ,然后根据调整后的size,计算实际应该在那个 level上分配,如果有相应级
很简单,直接返回,如果没有,一级一级循环查找,找到后,把省下的部分,在往下一级
一级插入到对应级的freelist 上
mem free:
其中free 的地址,减去12 就可以获得mem_alloc_hdr_type 结构
然后确定buddy 在该被free block 前,还是后面, 然后合并buddy,
循环寻找上一级的buddy ,有就再合并,只到最大block size 那级
关于这个算法,在<<The Art of Computer Programming>> vol 1,的
动态存储分配中有描述,对于那些只有OSAL 的小系统,该算法相当有用
内存管理算法--Buddy伙伴算法【转】的更多相关文章
- 内存管理算法--Buddy伙伴算法
Buddy算法的优缺点: 1)尽管伙伴内存算法在内存碎片问题上已经做的相当出色,但是该算法中,一个很小的块往往会阻碍一个大块的合并,一个系统中,对内存块的分配,大小是随机的,一片内存中仅一个小的内存块 ...
- 内存管理(1)-buddy和slub算法
Linux内存管理是一个很复杂的系统,也是linux的精髓之一,网络上讲解这方面的文档也很多,我把这段时间学习内存管理方面的知识记录在这里,涉及的代码太多,也没有太多仔细的去看代码,深入解算法,这篇文 ...
- Linux-3.14.12内存管理笔记【伙伴管理算法(2)】
前面已经分析了linux内存管理算法(伙伴管理算法)的准备工作. 具体的算法初始化则回到start_kernel()函数接着往下走,下一个函数是mm_init(): [file:/init/main. ...
- Linux-3.14.12内存管理笔记【伙伴管理算法(1)】
前面分析了memblock算法.内核页表的建立.内存管理框架的构建,这些都是x86处理的setup_arch()函数里面初始化的,因地制宜,具有明显处理器的特征.而start_kernel()接下来的 ...
- JVM内存管理--分代搜集算法
对象分类 分代搜集算法是针对对象的不同特性,而使用适合的算法,这里面并没有实际上的新算法产生.与其说分代搜集算法是第四个算法,不如说它是对前三个算法的实际应用. 首先我们来探讨一下对象的不同特性,接下 ...
- Linux-3.14.12内存管理笔记【伙伴管理算法(4)】
此处承接前面未深入分析的页面释放部分,主要详细分析伙伴管理算法中页面释放的实现.页面释放的函数入口是__free_page(),其实则是一个宏定义. 具体实现: [file:/include/linu ...
- Linux-3.14.12内存管理笔记【伙伴管理算法(3)】
前面分析了伙伴管理算法的初始化,在切入分析代码实现之前,例行先分析一下其实现原理. 伙伴管理算法(也称之为Buddy算法),该算法将所有空闲的页面分组划分为MAX_ORDER个页面块链表进行管理,其中 ...
- Linux伙伴算法
Linux内存管理伙伴算法 伙伴算法 Linux内核内存管理的任务包括: 遵从CPU的MMU(Memory Management Unit)机制 合理.有效.快速地管理内存 实现内存保护机制 实现虚拟 ...
- Linux 伙伴算法简介
本文将简要介绍一下Linux内核中的伙伴分配算法. Technorati 标签: 伙伴算法 算法作用 它要解决的问题是频繁地请求和释放不同大小的一组连续页框,必然导致在已分配 ...
随机推荐
- 渐进结构—条件生成对抗网络(PSGAN)
Full-body High-resolution Anime Generation with Progressive Structure-conditional Generative Adversa ...
- 细数IE6的一串串的恼人bug,附加解决方法!
1. li在IE中底部3像素的BUG 解决方案:在<li>上加float:left:即可解决 2. IE6中奇数宽高的BUG. 解决方案:就是将外部相对定位的div宽度改成偶数.高度也是一 ...
- [Vue warn]: Error in render: "TypeError: Cannot read property '0' of undefined、vuejs路由使用的问题Error in render function
1.[Vue warn]: Error in render: "TypeError: Cannot read property '0' of undefined 注意,只要出现Error i ...
- spring boot常用注解使用小结
1.@RestController和@RequestMapping注解 4.0重要的一个新的改进是@RestController注解,它继承自@Controller注解. 4.0之前的版本,Sprin ...
- 遭遇java.lang.NoClassDefFoundError: org/apache/tomcat/PeriodicEventListener
前天还正常的程序,今天忽然无法启动了,MyEclipse的Console提醒我如下错误: 严重: Error deploying web application directory rttsbizja ...
- Singular value encountered in calculation for ROI
在ENVI中对一幅TM影像进行监督分类,在进行compute ROI separability时提示Singular value encountered in calculation for ROI, ...
- Session 共享(Custom模式)By Memcached(原创)
1.web.config配置: <machineKey decryptionKey="FD69B2EB9A11E3063518F1932E314E4AA1577BF0B824F369& ...
- iOS日期加减
- (NSDate *)jsDateFromBeginDate:(NSDate *)beginDate todays:(int)days { NSDate *dateTemp = [[NSDate a ...
- CentOS7 设置防火墙端口
[root@localhost wzh]# firewall-cmd --state running [root@localhost wzh]# firewall-cmd --zone=public ...
- spring启动方式
spring有三种启动方式,使用ContextLoaderServlet,ContextLoaderListener和ContextLoaderPlugIn.看一下ContextLoaderListe ...