第一章:AI人工智能 の 数据预处理编程实战 Numpy, Pandas, Matplotlib, Scikit-Learn
本课主题
- 数据中 Independent 变量和 Dependent 变量
- Python 数据预处理的三大神器:Numpy、Pandas、Matplotlib
- Scikit-Learn 的机器学习实战
- 数据丢失或者不完整的处理方法及编程实战
- Categorical 数据的 Dummy Encoders 方法及编程实战
- Fit 和 Transform 总结
- 数据切分之Training 和 Testing 集合实战
- Feature Scaling 实战
引言
机器学习中数据预处理是一个很重要的步骤,因为有好的数据作为基础可以训练出精确度很高的机器学习模型,但在真实的世界,数据是不完美的,所以才需要通过数据预处理,尽可能把垃圾数据转化为更合理的数据来训练机器学习模型。这篇文章是一个起点,主要介绍在机器学习过程中的步骤:其中包括以下几点,希望通过这篇文章可以让大家对机器学习有一个更直观的认识。
- 数据预处理;
- Independant Variable 和 Dependent Variable 关系和区别;
- Categorial Data 和 Dummy Encoder 编程实战;
- 数据不完整的处理方法;
- Feature Scaling 的重要性;
- 机器学习中 Python库 (Numpy, Pandas, Matplotlib, Scikit-Learn) 的实战编程
Dependent 和 Independent 变量
什么是 Independent 变量? 什么是 dependent 变量? 机器学习的目标是找出 Depenedent 变量和 Independent 变量之間的关系,有了这个结果,你就可以根据过去的历史数据来预测未來的行為。在這個列子中,有 Country,Age,Salary,Purchased 四个维度的数据,其中 Country,Age 和 Salary 是 Independent 变量,也可以叫特徵,而 Purchased 是一个 Dependent 变量,它会跟据其他三个特徵来得出买与不买的结论。
Country,Age,Salary,Purchased
France,44,72000,No
Spain,27,48000,Yes
Germany,30,54000,No
Spain,38,61000,No
Germany,40,,Yes
France,35,58000,Yes
Spain,,52000,No
France,48,79000,Yes
Germany,50,83000,No
data.csv
Python 有很多专门处理数据预处理的库:Numpy 是 Python 中数据处理最流行和最强大的库之一,尢其是对矩阵进行了全面的支持;Pandas 是以 Table 的方式对数据进行处理,叫 DataFrame;Matplotlib 对开发者最为友好的数据可视化工具之一,下面调用 pandas.read_csv 函数来读取数据源
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd dataset = pd.read_csv("data.csv") X = dataset.iloc[:,:-1].values
y = dataset.iloc[:,3].values
[下图是 data.csv 的数据]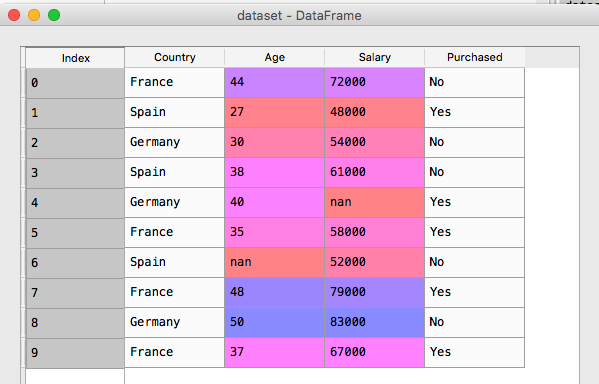
这些数据中有一部份数据是不完整的,出现 Null 的情况,此时,可以调用 sklearn.preprocessing 中 Imputer 类,你可以对丢失的部份采用平均法来填补上。
数据丢失或者不完整的处理方法及编程实战
数据丢失在数据中是经常出现的,所以在进行机器学习的模型训练之前,必须先进行数据预处理,来填补数据的空白,具体方法之一:计算整列数据的平均值并填补平均值。
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values="NaN", strategy="mean", axis=0)
imputer = imputer.fit(X[:,1:3])
X[:,1:3] = imputer.transform(X[:,1:3])
[下图是经过平均法计算出来的数据]
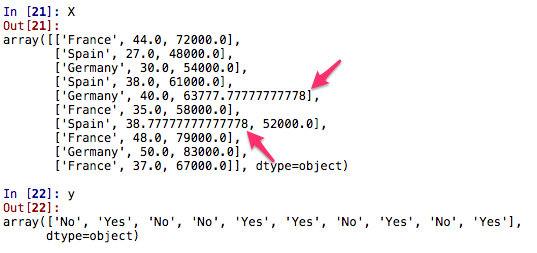
在机算计的世界它只对数字敏感,它是看不懂字符串类型的数据的,把丢失的数据填补上之后,下一步可以对字符串类型的数据进行数字化处理,比如把 Country: France, Spain, Germany 和Purchases: Yes, No 中的数据转化成数字。
Categorical 数据和 Dummy Encoders 方法及编程实战
可以通过调用 sklearn.preprocessing 库中 LabelEncoder 类 fit_transform 函数把字符串类型数据 StringType 转化为数字型数据 IntegerType
from sklearn.preprocessing import LabelEncoder
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
labelencoder_X = LabelEncoder()
X[:,0] = labelencoder_X.fit_transform(X[:,0])
[下图为数据运行后的结果,把 Country: France, Spain, Germany 和Purchases: Yes, No 换化成 [0, 2, 1] 和 [1,0]]
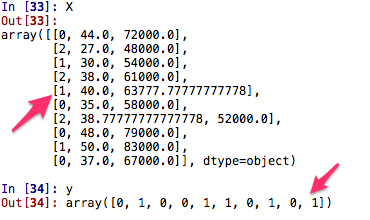
Country 中的 [0,1,2] 是有顺序的,如果数据量大的话,可能会因为数字的大小而影响模型训练的结果,这是我们不想看见的,所以可以使用一种叫 Dummy Encoders 的方法,以数组的方式,用 [0,1] 来表示,比如把 Country 编码成为 [0,0,1], [0,1,0], [1,0,0]
from sklearn.preprocessing import OneHotEncoder
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()
[下图为数据运行后的结果,现在总共有 5 列,前 3 列分别是描述 Country 的特徵, 第 4 列是 Age 和 第 5 列是 Salary]
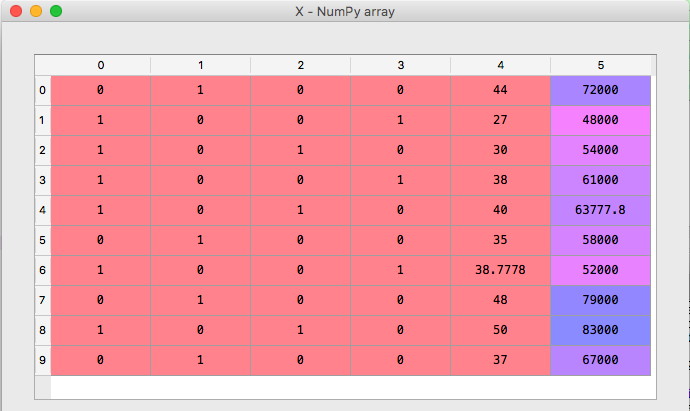
训练集和测试集 (Training and Testing Dataset)
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
[下图为数据运行后的结果,把数据分为 testing 和 training data]
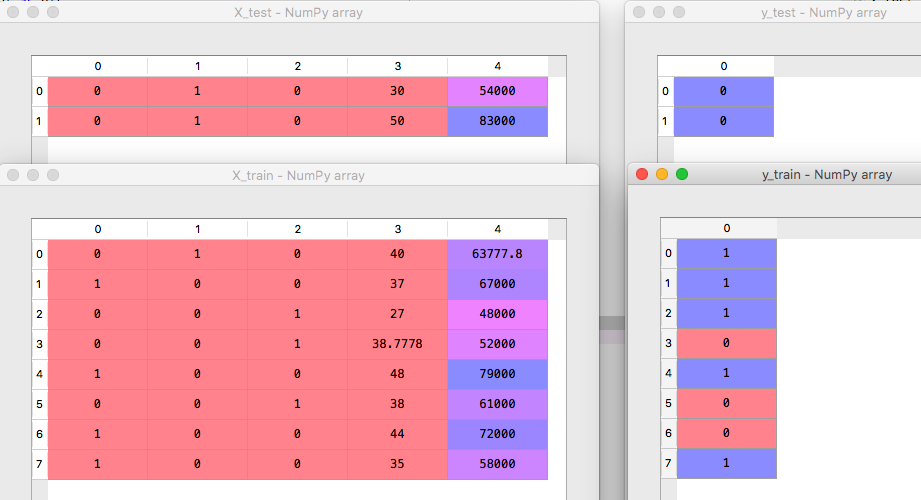
Feature Scaling
在 data.csv 中可以看见Salary 从数字上讲远远比 Age 的数字大,这会影响机器学习模型的准确度,所以我们必须进行 Feature Scaling 来减少数据之间的差距,在数学上我们可以用 Standardization 和 Normalization 来解决这个问题。
Standardization: ( x - mean(x) ) / standard deviation (x)
Normalization:
在编程上我们可以调用 sklearn.preprocessing 的 StandardScaler 类中的 fit_transform 函数
from sklearn.preprocessing import StandardScaler
standardScaler = StandardScaler()
X_train = standardScaler.fit_transform(X_train)
X_test = standardScaler.transform(X_test)
可以看到完整 Feature Scaling 后的数据的差距没有这么极端
[下图为数据运行后的结果, 这样做可以大大减少数据差距]
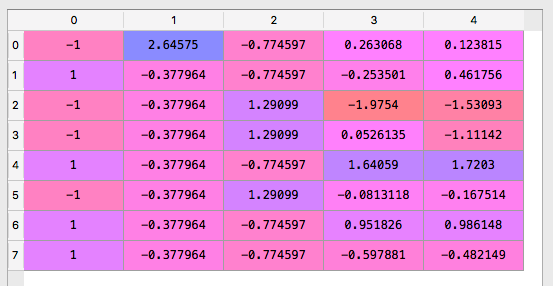
以下是这个例子完整的代码
# -*- coding: utf-8 -*-
# 数据预处理的三大神器 Numpy, Pandas, Matplotlib import numpy as np
import matplotlib.pyplot as plt
import pandas as pd dataset = pd.read_csv("data.csv")
X = dataset.iloc[:,:-1].values
y = dataset.iloc[:,3].values from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values="NaN", strategy="mean", axis=0)
imputer = imputer.fit(X[:,1:3])
X[:,1:3] = imputer.transform(X[:,1:3]) from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y) labelencoder_X = LabelEncoder()
X[:,0] = labelencoder_X.fit_transform(X[:,0]) onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray() from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0) from sklearn.preprocessing import StandardScaler
standardScaler = StandardScaler()
X_train = standardScaler.fit_transform(X_train)
X_test = standardScaler.transform(X_test)
完整的代码
总结
1. 不能有数据丢失的情况
2. 把所有字符串类型的分类特徵转换成数字类型 (Categorical Data)
3. 把数据分开 Training Data Set 和 Testing Data Set
4. 为了不让过大或者过少的数据影响机器模型的结果,所以需要用 Feature Scaling 去预处理
参考资料
资料来源来至
[1] DT大数据梦工厂 30个真实商业案例代码中习得AI:10大机器学习案例、13大深度学习案例、7大增强学习案例
第2课:AI数据的预处理三部曲之第一步:导入数据及初步处理Numpy、Pandas、Matplotlib
第3课:AI数据的预处理三部曲之第二步:使用Scikit-Learn来对Missing &Categorical数据进行最快速处理
第4课:AI数据的预处理三部曲之第三步:使用Scikit-Learn来对把数据切分为Training&Testing Set以及Feature Scaling实战
[2] Python 数据科学系列 の Numpy、Series 和 DataFrame介绍
第一章:AI人工智能 の 数据预处理编程实战 Numpy, Pandas, Matplotlib, Scikit-Learn的更多相关文章
- Python数据可视化编程实战pdf
Python数据可视化编程实战(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1vAvKwCry4P4QeofW-RqZ_A 提取码:9pcd 复制这段内容后打开百度 ...
- python数据可视化编程实战PDF高清电子书
点击获取提取码:3l5m 内容简介 <Python数据可视化编程实战>是一本使用Python实现数据可视化编程的实战指南,介绍了如何使用Python最流行的库,通过60余种方法创建美观的数 ...
- Java程序设计(2021春)——第一章课后题(选择题+编程题)答案与详解
Java程序设计(2021春)--第一章课后题(选择题+编程题)答案与详解 目录 Java程序设计(2021春)--第一章课后题(选择题+编程题)答案与详解 第一章选择题 1.1 Java与面向对象程 ...
- 《Python数据可视化编程实战》
第一章:准备工作环境 WinPython-32bit-3.5.2.2Qt5.exe 1.1 设置matplotlib参数 配置模板以方便各项目共享 D:\Bin\WinPython-32bit-3.5 ...
- 第一章:大数据 の Linux 基础 [更新中]
本课主题 Linux 休系结构图 Linux 系统启动的顺序 Linux 查看内存和 CPU 指令 环境变量加载顺序 Linux 内存结构 Linux 休系结构图 Linux 大致分为三个层次,第一层 ...
- Python数据可视化编程实战——导入数据
1.从csv文件导入数据 原理:with语句打开文件并绑定到对象f.不必担心在操作完资源后去关闭数据文件,with的上下文管理器会帮助处理.然后,csv.reader()方法返回reader对象,通过 ...
- 【第一章】MySQL数据概述
安装部署 备份恢复主备复制读写分离HA架构分布式数据库压力测试性能优化自动化运维 ==数据的存储方式1. 人工管理阶段2. 文件系统阶段3. 数据库系统管理阶段 ==数据库技术构成1. 数据库系统 D ...
- 第一章、欢迎进入C#编程世界
1.GUI:图形用户界面. 2.在C#中,所有可执行代码都必须在方法中定义,而方法必须从属于类或结构. 3.程序集中可能包含多个命名空间的类,而一个命名空间可能跨越多个程序集. 4.解决方案文件使用. ...
- 2 python大数据挖掘系列之淘宝商城数据预处理实战
preface 在上一章节我们聊了python大数据分析的基本模块,下面就说说2个项目吧,第一个是进行淘宝商品数据的挖掘,第二个是进行文本相似度匹配.好了,废话不多说,赶紧上车. 淘宝商品数据挖掘 数 ...
随机推荐
- JavaScript之Array
JavaScript是一门非常灵活的动态语言,涵盖的内容也挺多,<JavaScript高级程序设计>看了也有两遍,但是在实际开发的时候,还是有很多东西记不清,然后还得去翻书,特别是一些Ar ...
- 浏览器根对象window之操作方法
1.1 不常用 alert:带有一条指定消息和一个OK按钮的警告框. confirm:带有指定消息和OK及取消按钮的对话框. prompt:可提示用户进行输入的对话框. print:打印网页. ope ...
- 镶嵌数据集 Mosaic Dataset 的常见数据组织方式
镶嵌数据集是ESRI公司推出一种用于管理海量影像数据的数据模型,定义在GeoDatabase数据模型中. 它的常见数据组织方式有两种: 1. 源镶嵌数据集 Source Mosaic Dataset ...
- RSA与ECC的比较
第六届国际密码学会议对应用于公钥密码系统的加密算法推荐了两种:基于大整数因子分解问题(IFP)的RSA算法和基于椭圆曲线上离散对数计算问题(ECDLP)的ECC算法.RSA算法的特点之一是数学原理简单 ...
- Intel超低功耗CPU的一些信息
2015年底: Intel Braswell是专门针对超低功耗移动和桌面平台的一个家族,现有赛扬N3000/N3050/N3150.奔腾N3700四款型号,其中N300的热设计功耗只有区区4W,其他三 ...
- 【Android】Retrofit网络请求Service,@Path、@Query、@QueryMap...
对Retrofit已经使用了一点时间了,是时候归纳一下各种网络请求的service了. 下面分为GET.POST.DELETE还有PUT的请求,说明@Path.@Query.@QueryMap.@Bo ...
- Android中Handler的使用
当我们在处理下载或是其他需要长时间执行的任务时,如果直接把处理函数放Activity的OnCreate或是OnStart中,会导致执行过程中整个Activity无响应,如果时间过长,程序还会挂掉.Ha ...
- 将CAGradientLayer用作maskView的遮罩图层
将CAGradientLayer用作maskView的遮罩图层 说明 CAGradientLayer可以用作alpha遮罩,供maskView使用,这两种东西都是非常偏门的东西,但是,偏门不代表功能不 ...
- 辉光UIView的category
辉光UIView的category 本人视频教程系类 iOS中CALayer的使用 效果如下: 源码: UIView+GlowView.h 与 UIView+GlowView.m // // UI ...
- 关于Matlab里面的四个取整(舍入)函数:Floor, Ceil, Fix, Round的解释(转)
转自http://blog.sina.com.cn/s/blog_48ebd4fb010009c2.html floor:朝负无穷方向舍入 B = floor(A) rounds the elem ...