你都用python来做什么?

你都用 Python 来做什么?
16,583
3,315,984
邀请回答举报
246 个回答

2018年1月5日更新:本文包含两个独立的代码,分别是基于python爬虫下载P***hub上的视频(需FQ)和某国内网站的视频(无需FQ)。
不多说了,代码在此,网址补全就能跑。
各位知友注意身体。
在女朋友的督促下我写完了全部代码。
如果点赞<收藏,本答案将不再更新;否则保持更新。

import urllib2
import urllib
import datetime
import re
import os.path
to_find_string="https://bd.phncdn.com/videos/"
big_path=""
def save_file(this_download_url,path):
print"- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - "
time1=datetime.datetime.now()
print str(time1)[:-7],
if (os.path.isfile(path)):
file_size=os.path.getsize(path)/1024/1024
print "File "+path+" ("+ str(file_size)+"Mb) already exists."
return
else:
print "Downloading "+path+"..."
f = urllib2.urlopen(this_download_url)
data = f.read()
with open(path, "wb") as code:
code.write(data)
time2=datetime.datetime.now()
print str(time2)[:-7],
print path+" Done."
use_time=time2-time1
print "Time used: "+str(use_time)[:-7]+", ",
file_size=os.path.getsize(path)/1024/1024
print "File size: "+str(file_size)+" MB, Speed: "+str(file_size/(use_time.total_seconds()))[:4]+"MB/s"
def download_the_av(url):
req = urllib2.Request(url)
content = urllib2.urlopen(req).read()
while len(content)<100:
print"try again..."
content = urllib2.urlopen(req).read()
print "All length:" +str(len(content))
title_begin=content.find("<title>")
title_end=content.find("</title>")
title=content[title_begin+7:title_end-14]
title=title.replace('/','_')
title=filter(lambda x:x in "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ _-",title)
quality=['720','480','240']
for i in quality:
find_position=content.find("\"quality\":\""+i+"\"")
if find_position>0:
print "Quality: "+i+"P"
break
to_find=content[find_position:find_position+4000]
pattern=re.compile(r"\"videoUrl\":\"[^\"]*\"")
match = pattern.search(to_find)
if match:
the_url=match.group()
the_url=the_url[12:-1]#the real url
the_url=the_url.replace("\\/","/")
save_file(the_url,big_path+title+".mp4")
urls=["https://www.p***hub.com/view_video.php?viewkey=ph592ef8731630a",]
print len(urls),
print " videos to download..."
count=0
for url in urls:
print count
count+=1
download_the_av(url)
print "All done"
以下是国内版本,请对网址稍作修改谢谢:
import urllib2
import urllib
import datetime
import re
import os.path
import requests
def save_file(this_download_url,path):
print"- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - "
time1=datetime.datetime.now()
print str(time1)[:-7],
if (os.path.isfile(path)):
file_size=os.path.getsize(path)/1024/1024
print "File "+path+" ("+ str(file_size)+"Mb) already exists."
return
else:
print "Downloading "+path+"..."
r = requests.get(this_download_url,stream=True)
with open(path.encode('utf-8'), "wb") as code:
code.write(r.content)
time2=datetime.datetime.now()
print str(time2)[:-7],
print path+" Done."
use_time=time2-time1
print "Time used: "+str(use_time)[:-7]+", ",
file_size=os.path.getsize(path)/1024/1024
print "File size: "+str(file_size)+" MB, Speed: "+str(file_size/(use_time.total_seconds()))[:4]+"MB/s"
def download_url(website_url):
fuckyou_header= {'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
req = urllib2.Request(website_url,headers=fuckyou_header)
content = urllib2.urlopen(req).read()
while len(content)<100:
print"try again..."
content = urllib2.urlopen(req).read()
print "Web page all length:" +str(len(content))
pattern=re.compile(r"http://m4.26ts.com/[.0-9-a-zA-Z]*.mp4")
match = pattern.search(content)
if match:
the_url=match.group()
save_file(the_url,the_url[19:])
else:
print "No video found."
urls=["http://www.46ek.c*m/view/22133.html",]
count=0
print len(urls),
print " videos to download..."
for i in urls:
count+=1
print count
download_url(i)
print "All done"
你们也看下我写的这个答案好么....
收藏感谢
收起

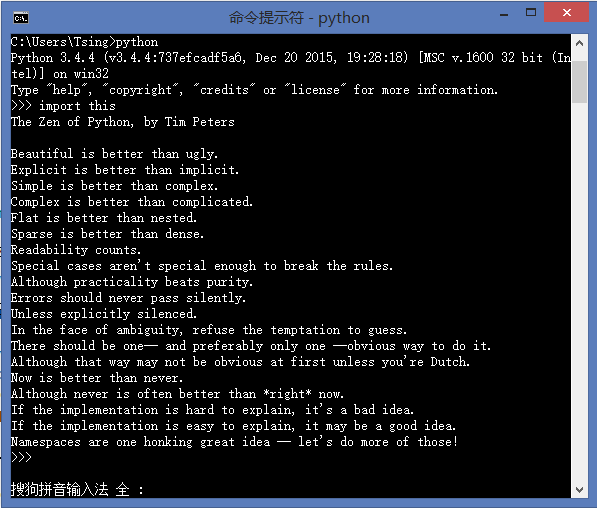
首先上一首Python之禅:
Python是一个非常好用的程序语言,开发的速度非常快。我用Python已经一年多了,从Python2.7到现在的Python3.4,也写了好多的小程序,其中大部分都是爬虫程序,下面简单列举几个,可怜了我科的各种系统。

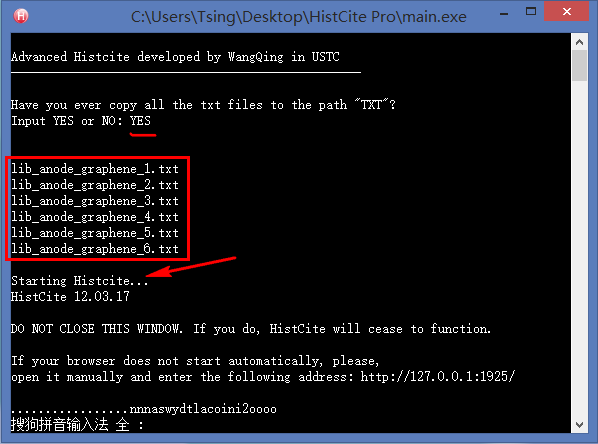
0. 制作引文分析利器HistCite的便捷使用版本
怎么又出现了一个序号为零的啊!没错,这个又是我后来加上的,嘻嘻~
对于整天和文献打交道的研究生来说,HistCite是一款不可多得的效率利器,它可以快速绘制出某个研究领域的发展脉络,快速锁定某个研究方向的重要文献和学术大牛,还可以找到某些具有开创性成果的无指定关键词的论文。但是原生的HistCite已经有4年没有更新了,现在使用会出现各种bug,于是我就用Python基于HistCite内核开发了一个方便使用的免安装版本。具体的使用方法和下载链接见我的第一篇知乎专栏文章:文献引文分析利器HistCite使用教程(附精简易用免安装Pro版本下载) - Tsing的文章 - 知乎专栏
0.5. 给钓鱼网站大量提交垃圾信息
怎么又出现了一个序号为 0.5 的啊!详细见我的专栏文章:偶遇一个钓鱼网站,于是就简单玩了一下...
1. 破解观看中科大网络课堂
中国科学技术大学网络课堂(http://wlkt.ustc.edu.cn/)是一个非常好的平台,上面汇集了很多知名教授的授课视频,以及最新的讲座、报告、表演视频,内容还是相当丰富的。但是这些视频只面向校内IP开放。
所以想在校外看到这些视频必须破解视频地址,于是利用Python的requests库结合BeautifulSoup,用了不到10行代码就可以获取真实下载地址。
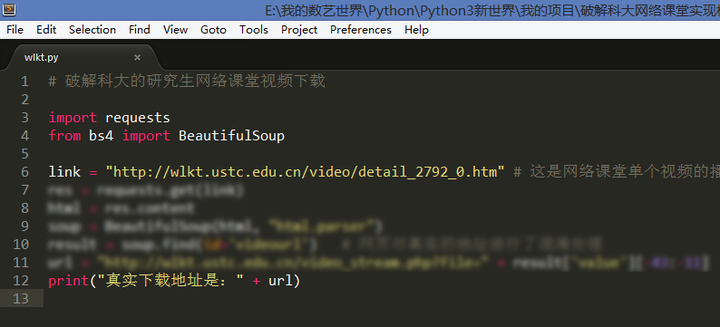
为了方便没有安装Python的电脑使用,简单写了一个GUI界面,给室友用,都说还是挺好的用的哈。
考虑到视频版权问题,代码和程序就不放出来了,请大家见谅。
2. 获取中科大研究生系统全部学生姓名、学号、选课信息
登录中国科学技术大学的研究生综合系统(中国科学技术大学研究生信息平台),可以看到每一门课选课的学生姓名和学号,当时就想能不能做一个这样的系统,来输入任何姓名(或者学号)就可以看到他所有的选课信息呢?这是选课首页:
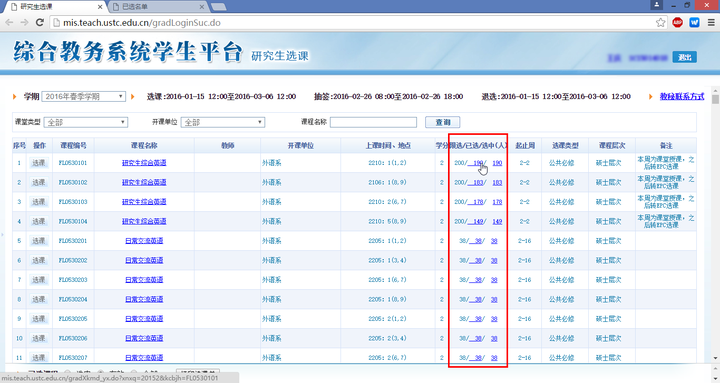
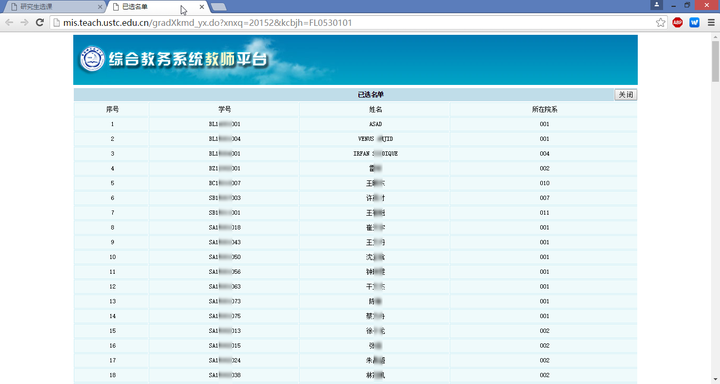
点击每门课的已选人数链接,可以看到所有的选课学生姓名和学号:
下面就利用requests的模拟登录功能,先获取全部课程的链接,并保存对于的课程信息,然后挨个获取了所有课程的选课信息。为了保护学生信息,对程序的关键部分进行了模糊处理,希望大家谅解。
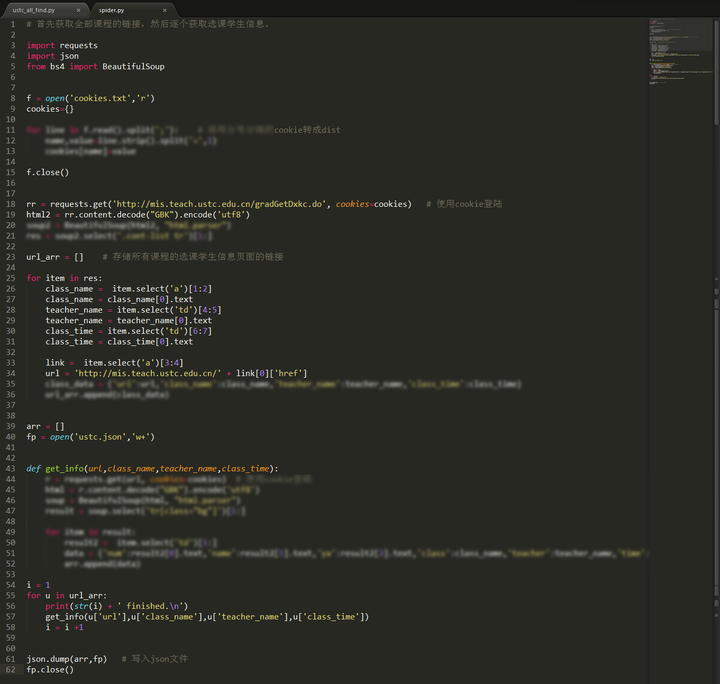
这样就获取了一个巨大的json文件,里面全部是学生姓名学号选课信息:

有了这个json文件,我们可以写入数据库,也可以直接利用json文件来查询:
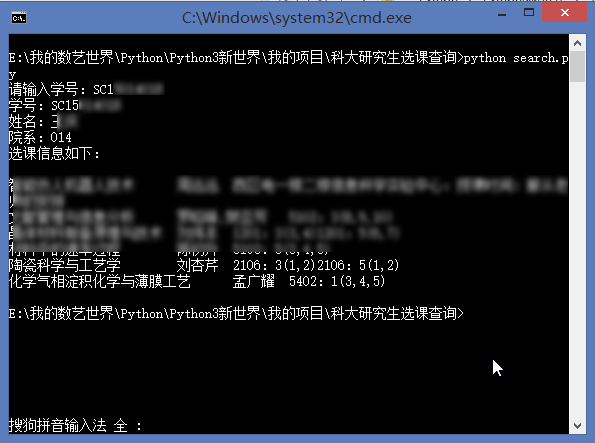
为了方便其他人使用,基于上面的数据我开发了一个线上版本:
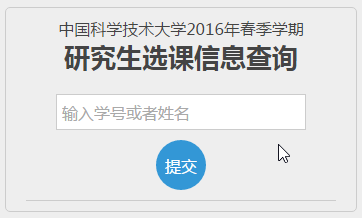
输入姓名或者学号都可以直接查询别人的选课信息:

这个地址就不放出来了,如果您是科大的研究生,私信我,我把链接发给你。
3. 扫描中科大研究生系统上的弱密码用户
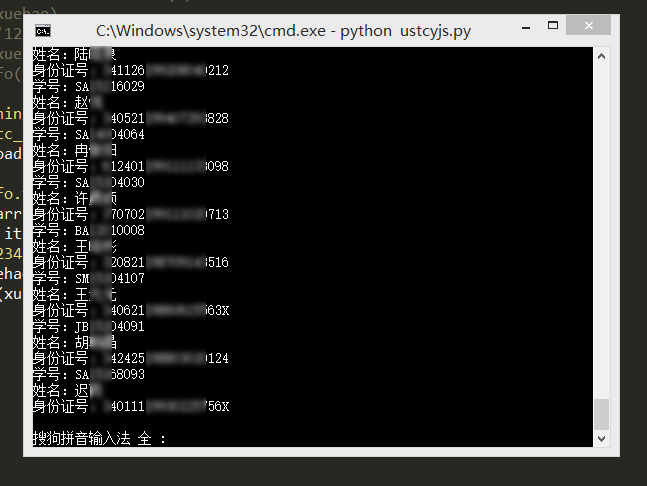
基于上面获得的选课学生学号,很容易利用Python依次模拟登录研究生,密码就用弱密码123456,然后可以获得身份证号码等重要信息。

这样就得到了使用123456作为密码的用户信息,所以在此提醒大家一定不要使用弱密码,希望下面的同学早日修改密码。
4. 模拟登录中科大图书馆并自动续借
最近,科大图书馆系统升级了,到处都加了验证码,所以下面这个方法直接使用肯定是不行了,不过曾经毕竟成功过哈。以前收到借阅图书到期通知短信,就会运行一下这个程序,自动续借了,然后就可以再看一个月了。
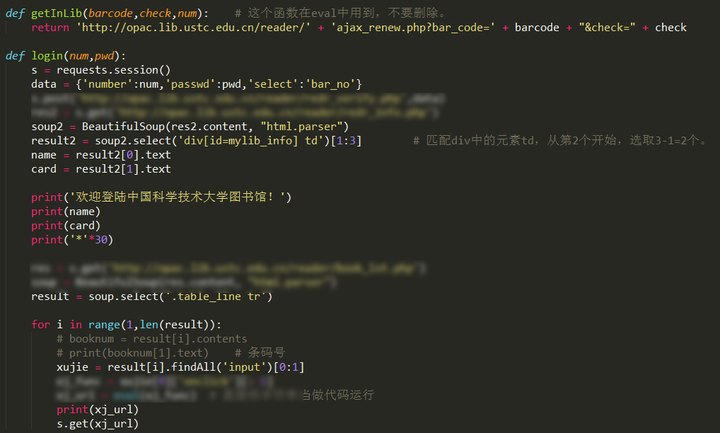
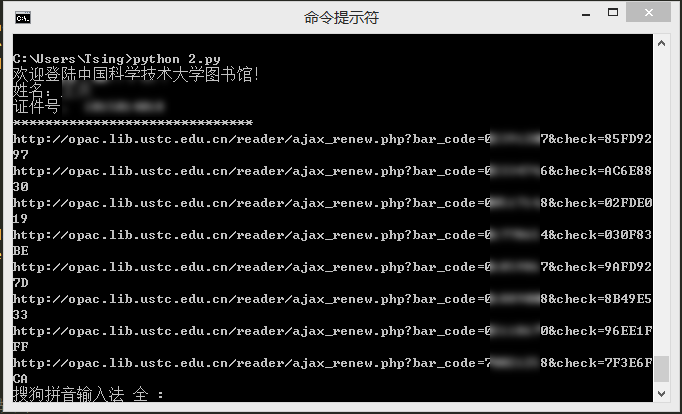
运行就是这样的,自动续借成功,看到的链接就是每本书的续借链接。
5. 网易云音乐批量下载
终于来一个正常一点的哈,那么我就直接放代码吧,可以下载网易云音乐各个榜单的全部歌曲,批量下载,速度挺快。请注意提前要创建一个名为 “网易云音乐” 的文件夹。
# 网易云音乐批量下载
# By Tsing
# Python3.4.4
import requests
import urllib
# 榜单歌曲批量下载
# r = requests.get('http://music.163.com/api/playlist/detail?id=2884035') # 网易原创歌曲榜
# r = requests.get('http://music.163.com/api/playlist/detail?id=19723756') # 云音乐飙升榜
# r = requests.get('http://music.163.com/api/playlist/detail?id=3778678') # 云音乐热歌榜
r = requests.get('http://music.163.com/api/playlist/detail?id=3779629') # 云音乐新歌榜
# 歌单歌曲批量下载
# r = requests.get('http://music.163.com/api/playlist/detail?id=123415635') # 云音乐歌单——【华语】中国风的韵律,中国人的印记
# r = requests.get('http://music.163.com/api/playlist/detail?id=122732380') # 云音乐歌单——那不是爱,只是寂寞说的谎
arr = r.json()['result']['tracks'] # 共有100首歌
for i in range(10): # 输入要下载音乐的数量,1到100。
name = str(i+1) + ' ' + arr[i]['name'] + '.mp3'
link = arr[i]['mp3Url']
urllib.request.urlretrieve(link, '网易云音乐\\' + name) # 提前要创建文件夹
print(name + ' 下载完成')c
于是就可以愉快的听歌了。
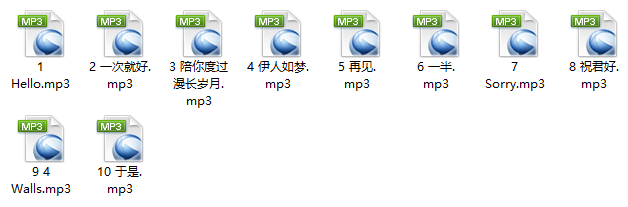
上面这些都是在Python3的环境下完成的,在此之前,用Python2还写了一些程序,下面也放几个吧。初期代码可能显得有些幼稚,请大神见谅。

6. 批量下载读者杂志某一期的全部文章
上次无意中发现读者杂志还有一个在线的版本,然后兴趣一来就用Python批量下载了上面的大量文章,保存为txt格式。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 保存读者杂志某一期的全部文章为TXT
# By Tsing
# Python 2.7.9
import urllib2
import os
from bs4 import BeautifulSoup
def urlBS(url):
response = urllib2.urlopen(url)
html = response.read()
soup = BeautifulSoup(html)
return soup
def main(url):
soup = urlBS(url)
link = soup.select('.booklist a')
path = os.getcwd()+u'/读者文章保存/'
if not os.path.isdir(path):
os.mkdir(path)
for item in link:
newurl = baseurl + item['href']
result = urlBS(newurl)
title = result.find("h1").string
writer = result.find(id="pub_date").string.strip()
filename = path + title + '.txt'
print filename.encode("gbk")
new=open(filename,"w")
new.write("<<" + title.encode("gbk") + ">>\n\n")
new.write(writer.encode("gbk")+"\n\n")
text = result.select('.blkContainerSblkCon p')
for p in text:
context = p.text
new.write(context.encode("gbk"))
new.close()
if __name__ == '__main__':
time = '2015_03'
baseurl = 'http://www.52duzhe.com/' + time +'/'
firsturl = baseurl + 'index.html'
main(firsturl)
7. 获取城市PM2.5浓度和排名
最近环境问题很受关注,就用Python写了一个抓取PM2.5的程序玩玩,程序支持多线程,方便扩展。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 获取城市PM2.5浓度和排名
# By Tsing
# Python 2.7.9
import urllib2
import threading
from time import ctime
from bs4 import BeautifulSoup
def getPM25(cityname):
site = 'http://www.pm25.com/' + cityname + '.html'
html = urllib2.urlopen(site)
soup = BeautifulSoup(html)
city = soup.find(class_ = 'bi_loaction_city') # 城市名称
aqi = soup.find("a",{"class","bi_aqiarea_num"}) # AQI指数
quality = soup.select(".bi_aqiarea_right span") # 空气质量等级
result = soup.find("div",class_ ='bi_aqiarea_bottom') # 空气质量描述
print city.text + u'AQI指数:' + aqi.text + u'\n空气质量:' + quality[0].text + result.text
print '*'*20 + ctime() + '*'*20
def one_thread(): # 单线程
print 'One_thread Start: ' + ctime() + '\n'
getPM25('hefei')
getPM25('shanghai')
def two_thread(): # 多线程
print 'Two_thread Start: ' + ctime() + '\n'
threads = []
t1 = threading.Thread(target=getPM25,args=('hefei',))
threads.append(t1)
t2 = threading.Thread(target=getPM25,args=('shanghai',))
threads.append(t2)
for t in threads:
# t.setDaemon(True)
t.start()
if __name__ == '__main__':
one_thread()
print '\n' * 2
two_thread()
8. 爬取易迅网商品价格信息
当时准备抓取淘宝价格的,发现有点难,后来就没有尝试,就把目标选在了易迅网。
#!/usr/bin/env python
#coding:utf-8
# 根据易迅网的商品ID,爬取商品价格信息。
# By Tsing
# Python 2.7.9
import urllib2
from bs4 import BeautifulSoup
def get_yixun(id):
price_origin,price_sale = '0','0'
url = 'http://item.yixun.com/item-' + id + '.html'
html = urllib2.urlopen(url).read().decode('utf-8')
soup = BeautifulSoup(html)
title = unicode(soup.title.text.strip().strip(u'【价格_报价_图片_行情】-易迅网').replace(u'】','')).encode('utf-8').decode('utf-8')
print title
try:
soup_origin = soup.find("dl", { "class" : "xbase_item xprice xprice_origin" })
price_origin = soup_origin.find("span", { "class" : "mod_price xprice_val" }).contents[1].text
print u'原价:' + price_origin
except:
pass
try:
soup_sale= soup.find('dl',{'class':'xbase_item xprice'})
price_sale = soup_sale.find("span", { "class" : "mod_price xprice_val" }).contents[1]
print u'现价:'+ price_sale
except:
pass
print url
return None
if __name__ == '__main__':
get_yixun('2189654')
9. 音悦台MV免积分下载
音悦台上有好多高质量的MV,想要下载却没有积分,于是就想到破解下载。当时受一个大神的代码的启发,就写出了下面的代码,虽然写的有点乱,但还是可以成功破解的哈。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 音悦台MV免积分下载
# By Tsing
# Python 2.7.9
import urllib2
import urllib
import re
mv_id = '2278607' # 这里输入mv的id,即http://v.yinyuetai.com/video/2275893最后的数字
url = "http://www.yinyuetai.com/insite/get-video-info?flex=true&videoId=" + mv_id
timeout = 30
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'
}
req = urllib2.Request(url, None, headers)
res = urllib2.urlopen(req,None, timeout)
html = res.read()
reg = r"http://\w*?\.yinyuetai\.com/uploads/videos/common/.*?(?=&br)"
pattern=re.compile(reg)
findList = re.findall(pattern,html) # 找到mv所有版本的下载链接
if len(findList) >= 3:
mvurl = findList[2] # 含有流畅、高清、超清三个版本时下载超清
else:
mvurl = findList[0] # 版本少时下载流畅视频
local = 'MV.flv'
try:
print 'downloading...please wait...'
urllib.urlretrieve(mvurl,local)
print "[:)] Great! The mv has been downloaded.\n"
except:
print "[:(] Sorry! The action is failed.\n"
10. 其他请参考:能利用爬虫技术做到哪些很酷很有趣很有用的事情? - Tsing 的回答
结语:Python是一个利器,而我用到的肯定也只是皮毛,写过的程序多多少少也有点相似,但是我对Python的爱却是越来越浓的。
补充:看到评论中有好多知友问哪里可以快速而全面地学习Python编程,我只给大家推荐一个博客,大家认真看就够了:Python教程 - 廖雪峰的官方网站
收藏感谢
收起

可以解决生活中的各种小烦恼。
女朋友最近在做新媒体营销方面,看豆瓣手动顶贴太累了,而现有的很多顶贴软件因年久失修基本上都用不了了。作为python界(也可能是编程界)最慵懒人士,我就用selenium给她做了一个全天候顶贴脚本V2.0,跑在放在家里厨房的一台老IBM本本上。
--乱七八糟的厨房里,一台孤独运转的家庭server。
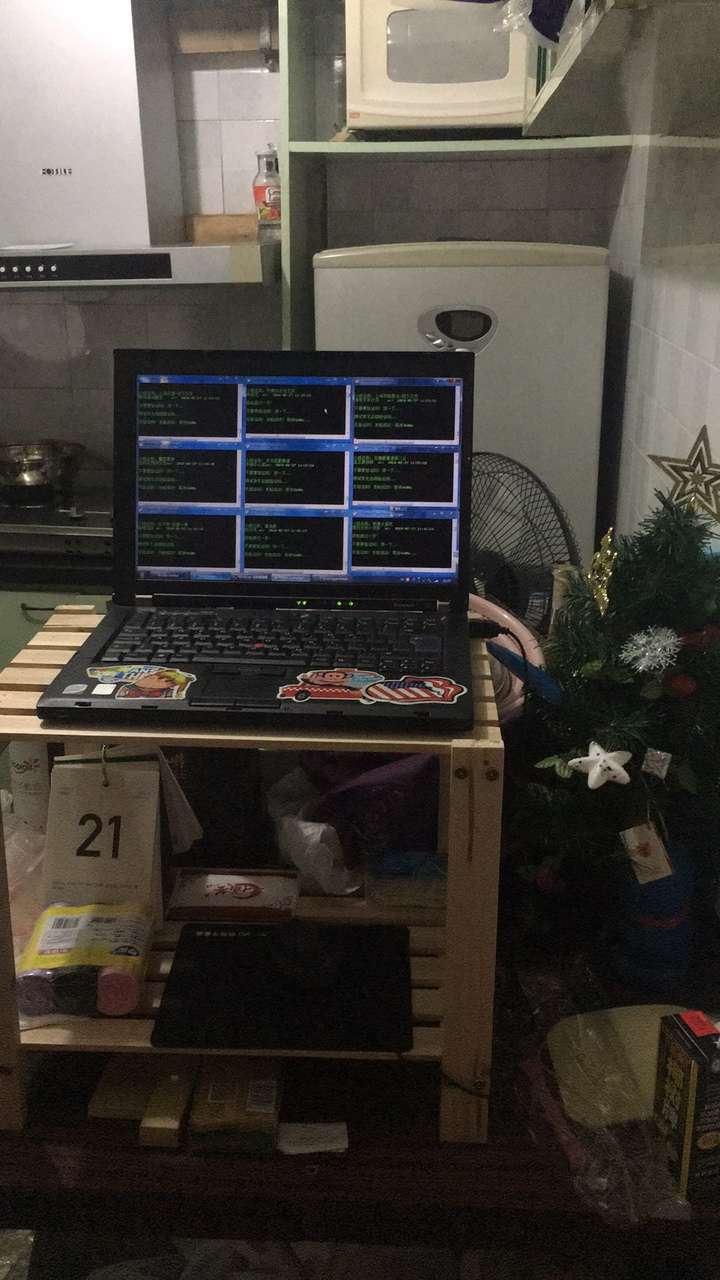
--理论上无上限的顶贴量,逻辑很简单:遇到验证码则延迟一小时。selenium将python的简洁高效体现的淋漓尽致,缺点当然是有的——比较慢,然而对于每次动作一小时的尺度而言,这点缺点也不是问题啦!!
--顶贴内容都是从大众点评上摘的菜谱,也有最近喜欢吃的,每次更新的时候顺手添两个
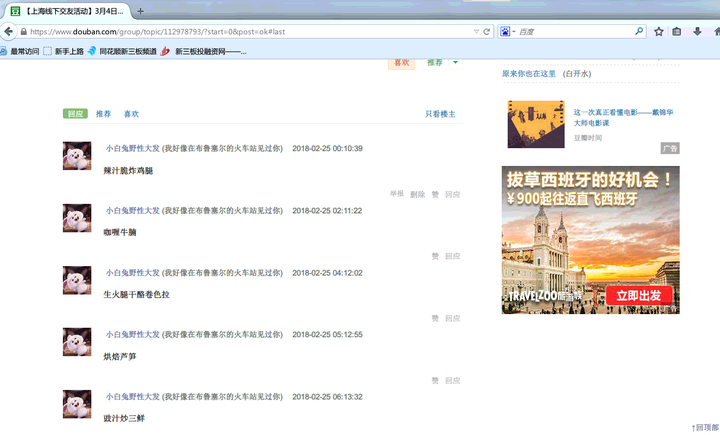
--经常遇到删帖或者网络不通的情况,通过邮件模块进行异常通知,这种自动化的感觉太好啦。
看到这里,
你一定想知道,
Python还能用来做什么,
没错,
我就是用这个脚本的1.0版本,
在小组里追到了现在的女朋友,
当时的版本比较简陋,没有延迟系统和邮件通知系统。
总结:
Python(划掉)
女朋友是第一生产力。
收藏感谢
收起

python能做的有很多,我这里之阐述我自学的数据分析的内容,这也是我学习利用python进行数据分析的过程,如果要看实践可以直接看项目篇
数据分析中常用的软件是jupyter notebook,而应用这个软件最方便的方法就是anaconda。具体的anaconda操作方法这篇文章讲述的比较详细就不多加叙述了。
初学python者自学anaconda的正确姿势是什么??www.zhihu.com jupyter notebook 可以做哪些事情?www.zhihu.com
jupyter notebook 可以做哪些事情?www.zhihu.com
基础篇
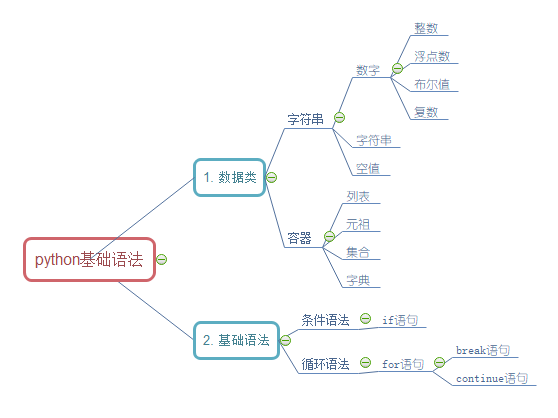
现在python的环境已经有了,接下来便是动手学习python的过程,其初级就是学习python3的基础语法,其中最为常用的就是if语句和for语句。数据分析之python基础篇
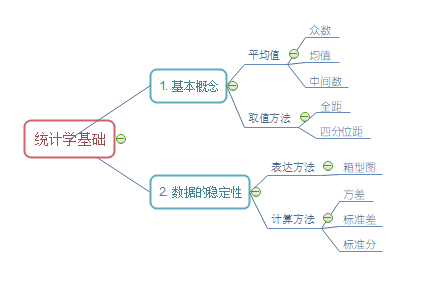
毕竟python只是数据分析中的一个工具的而已,而其软件便是统计学和概率论。其中最为常用的就是在后边学习是填补缺失值时对中间数和均值的选择,还有就是为了处理方便和准确选择上四分位数至下四分位数的数据。数据分析之统计学基础篇
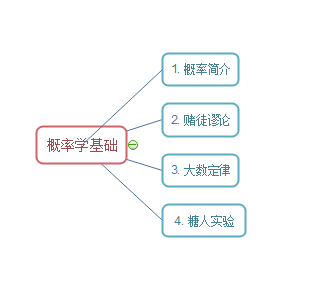
概率论的中大数定律是比较重要的基础知识,换言之,只要我们对大概率事件进行长时间的投资,就一定会有收益的。数据分析之概率思维
现在在学习过python基础,统计学和概率论基础之后,我开始着手做一些小的项目,一方面熟悉之前的基础知识,另一方面也是利用所学习的基础知识,做一些应用层面的项目,来看看数据分析是到底是做什么的。
项目篇
数据分析之简易分析股票走势,在我主要学习两个方面,其一是先定义问题,再进行数据处理的思路,而且在处理数据过程中,优先查看数据概况,并针对其数据概况进行数据处理。其二是初步学习了爬取雅虎的股票数据(获取数据),数据可视化。并通过这个项目我发现简单的编程便可以对一只股票进行预测,可以说是非常的实用。
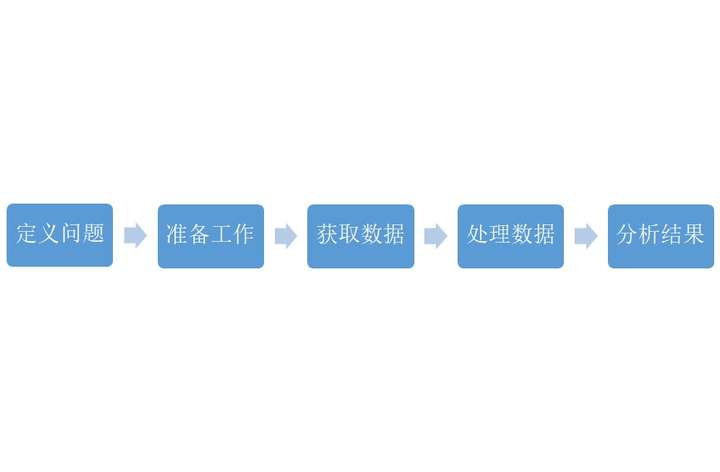
数据分析之Pandas实战,这个项目主要是做一个高血压药物的销售数据报告,在这个项目中主要是了解处理数据的一个基本的过程,即数据获取,查看数据,缺失值处理,异常值处理,数据提取,以及数据可视化。

机器学习之线性回归和机器学习之逻辑回归,这个两个项目是机器学习的基础部分,其实最为重要的就是这两个建立的模型,线性回归比较好理解就是y=bx+a,通过最佳拟合线构建模型,而逻辑回归是一个针对非0即1的模型。
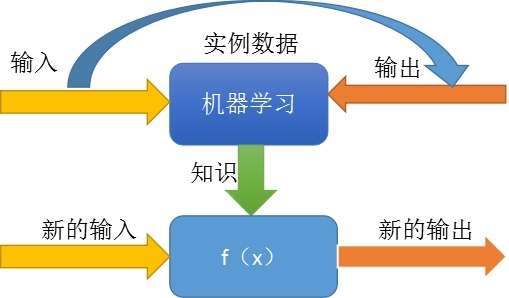
机器学习之泰坦尼克号存活预测这个项目对于我而言,在技术方面是一个新的转折点,它让我熟悉了kaggle平台,通过项目和其他高手学习编程的技巧。而且这个项目还让我学习了比较难的提取特征值和了解不同的模型(随机森林等)。这篇文章没有介绍的决策树和随机森林,在这里介绍一下。
决策树
决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程,它可以认为是if-then规则的集合。
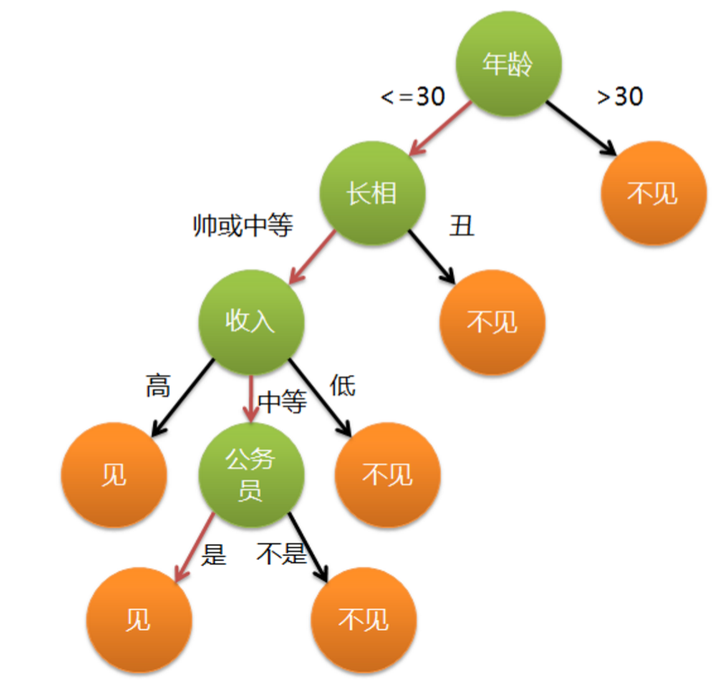
假设在样本集X中,对于一个特征a,它可能有(a1,a2。。。an)这些取值,如果用特征a对样本集X进行划分(把它当根节点),肯定会有n个分支结点。刚才提了,我们希望划分后,分支结点的样本越纯越好,也就是分支结点的“总熵”越小越好。
随机森林
随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。但随机森林的理论其实和决策树本身不应该牵扯在一起,决策树只能作为其思想的一种算法。bagging的个体学习器的训练集是通过随机采样得到的。通过n次的随机采样,我们就可以得到n个样本集。对于这n个样本集,我们可以分别独立的训练出n个个体学习器,再对这n个个体学习器通过集合策略来得到最终的输出,这n个个体学习器之间是相互独立的,可以并行。
电影数据可视化项目分析报告这个项目主要是熟悉可视化的内容,这个项目同样是kaggle上的项目。所谓数据可视化主要就是两个方面,其一是数据具有代表性,能够说明问题;其二是图表美观,具有可观性。

收藏感谢
收起

2018.02.28 更:
爬 国家统计局统计数据 呀,如平均工资。以前不知从哪里听说的xxx市平均月薪三千,没想到查了下数据,发现2016年xxx市平均月薪已经五六千了。 (纸面上,不计M2和通胀等因素)十年翻翻·真·不是梦。可是在祝贺超大型城市经济腾飞的同时,不免也感慨老家二十八线农村的萧条。其实,那些未上榜的地方才是大多数,发达了还是衰败了,又有谁关注了呢。
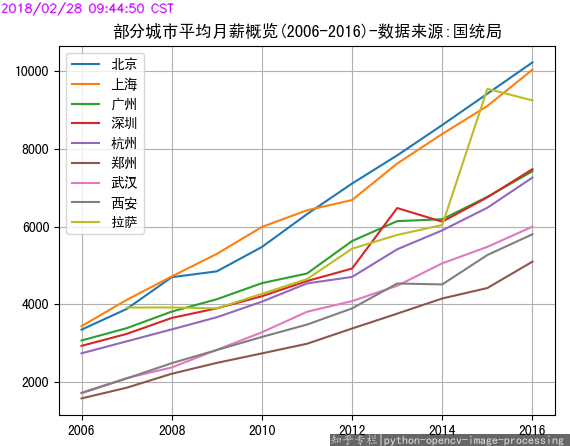
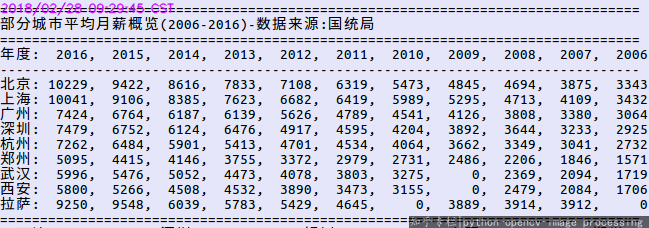 部分城市平均月薪
部分城市平均月薪
2018.01.04 更:编程给图像随机填色呀




可否通过编程为《秘密花园》填充出和谐的颜色?www.zhihu.com
原始回答:
爬知乎呀
 Python 知乎爬虫
Python 知乎爬虫
爬豆瓣读书呀
 Python 豆瓣爬虫
Python 豆瓣爬虫
爬漫画呀
 Python 漫画爬虫
Python 漫画爬虫
爬 必应 每日一图 呀
 Python 必应每日一图(必应主页背景)爬虫
Python 必应每日一图(必应主页背景)爬虫
爬天气呀
 Pyhthon 命令行查询天气
Pyhthon 命令行查询天气
登录wlan呀
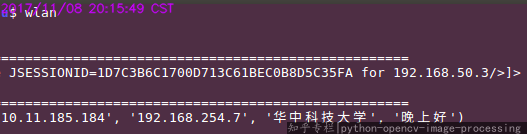 Python 命令行登录 wlan
Python 命令行登录 wlan
查询单词呀
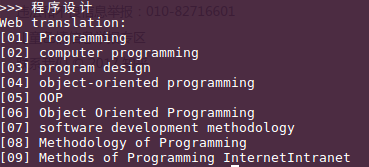 Python 查单词
Python 查单词
颜色检测呀
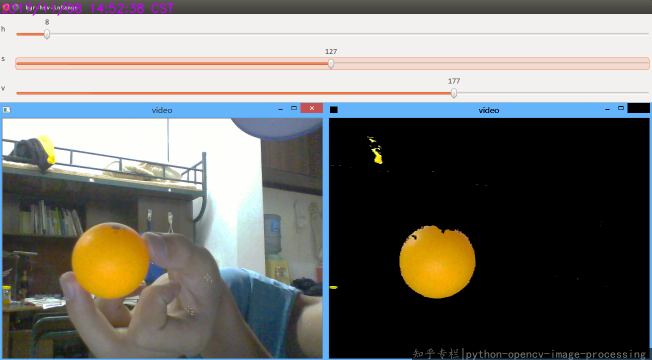 Python OpenCV 颜色检测(乒乓球)
Python OpenCV 颜色检测(乒乓球)
以下主要是专栏文章里的东西 , 专栏地址:

瓜子计数呀
 Python OpenCV 瓜子计数
Python OpenCV 瓜子计数
细胞图像检测呀
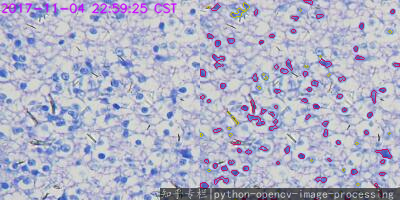 Python OpenCV 细胞计数(cells counting)
Python OpenCV 细胞计数(cells counting)
车道线检测呀
 Python OpenCV 车道线检测
Python OpenCV 车道线检测
手写数字识别呀
 Pyhton OpenCV 手写数字识别
Pyhton OpenCV 手写数字识别
图像预处理呀
 Python OpenCV 霍夫圆检测和极坐标变换
Python OpenCV 霍夫圆检测和极坐标变换
当做 PhotoShop 用来 P图 呀

高X格的 ”Hello, World!", 彩虹色的。
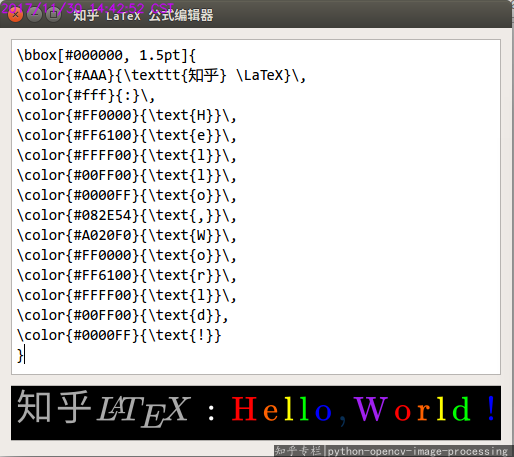 如何有格调地输出“Hello, World!”?www.zhihu.com
如何有格调地输出“Hello, World!”?www.zhihu.com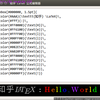 怎样在本地搭建一个类似于 [知乎插入LaTeX公式] 的应用?www.zhihu.com
怎样在本地搭建一个类似于 [知乎插入LaTeX公式] 的应用?www.zhihu.com
待续。。。
收藏感谢
收起

Python 可以做什么,这是一个有趣的问题。
从入门级选手到专业级选手都在做的——爬虫 用 Python 写爬虫的教程网上一抓一大把,据我所知很多初学 Python 的人都是使用它编写爬虫程序。小到抓取一个小黄图网站,大到一个互联网公司的商业应用。通过 Python 入门爬虫比较简单易学,不需要在一开始掌握太多太基础太底层的知识就可以很快上手,而且很快可以做出成果,非常适合小白一开始想做出点看得见的东西的成就感。 除了入门,爬虫也被广泛应用到一些需要数据的公司、平台和组织,通过抓取互联网上的公开数据,来实现一些商业价值是非常常见的做法。当然这些选手的爬虫就要厉害的多了,需要处理包括路由、存储、分布式计算等很多问题,与小白的抓黄图小程序,复杂度差了很多倍。
Web 程序 除了爬虫,Python 也广泛应用到了 Web 端程序,比如你现在正在使用的知乎,主站后台就是基于 Python 的 tornado 框架,豆瓣的后台也是基于 Python。除了 tornado (Tornado Web Server),Python 常用的 Web 框架还有 Flask(Welcome | Flask (A Python Microframework)),Django (The Web framework for perfectionists with deadlines) 等等。通过上述框架,你可以很方便实现一个 Web 程序,比如我认识的一些朋友,就通过 Python 自己编写了自己的博客程序,包括之前的 zhihu.photo,我就是通过 Flask 实现的后台(出于版权等原因,我已经停掉了这个网站)。除了上述框架,你也可以尝试自己实现一个 Web 框架。
桌面程序 Python 也有很多 UI 库,你可以很方便地完成一个 GUI 程序(话说我最开始接触编程的时候,就觉得写 GUI 好炫酷,不过搞了好久才在 VC6 搞出一个小程序,后来又辗转 Delphi、Java等,最后接触到 Python 的时候,我对 GUI 已经不感兴趣了)。Python 实现 GUI 的实例也不少,包括大名鼎鼎的 Dropbox,就是 Python 实现的服务器端和客户端程序。
科学计算 Python 的开发效率很高,性能要求较高的模块可以用 C 改写,Python 调用。同时,Python 可以更高层次的抽象问题,所以在科学计算领域也非常热门。包括 scipy、numpy 等用于科学计算的第三方库的出现,更是方便了又一定数学基础,但是计算机基础一般的朋友。
图像处理 这方面不熟,列几个关键词吧,如有错误,请斧正。 keywords : OpenCV, Pillow, PIL
小结 时间问题,暂到这里。基本上可以不负责任地认为,Python 可以做任何事情。 但是,如果你是打算以此为业,我的建议是,不要局限在 「学Python」这样的思维上。要在技术领域立足,仅仅学会了 Python 的语法是不够的,你需要很多编程语言之外的基础知识。
收藏感谢
收起

科研工作者来展示一下。
首先,我非常同意
的观点:
不要局限在“学Python”这样的思维上。要在技术领域立足,仅仅学会了 Python 的语法是不够的,你需要很多编程语言之外的基础知识。
Python 是著名的胶水语言,意味着几乎没有 Python 做不了的事情。关键不在于会不会用 Python 的语法——说实话,Python 的语法在实用层面上学起来实在并不困难(我的意思是,不去深究 Python 底层源码的实现原理)。关键在于,你想用它做什么事情?你知道该怎么去做吗?
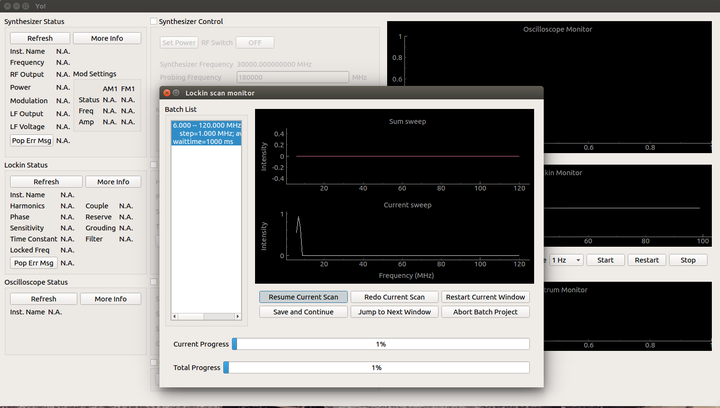
我的科研工作大量依赖自己开发的 Python 程序和脚本。
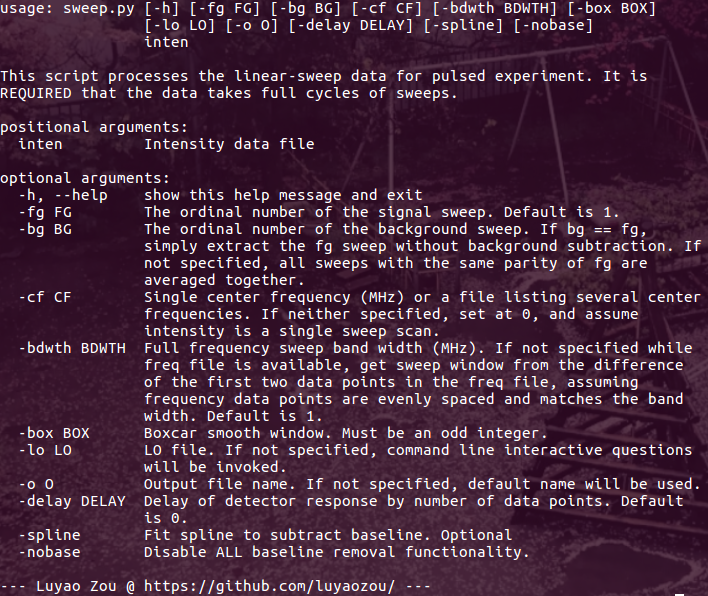
比如,用 Python 和 PyVisa 控制实验仪器
比如,用 numpy 和 scipy 拟合光谱
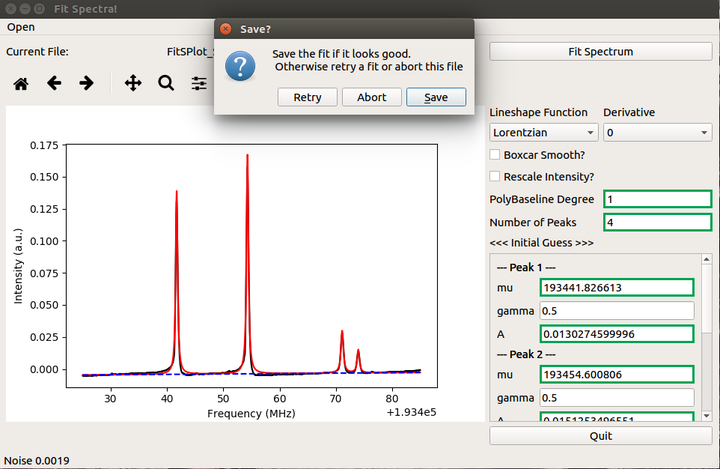
比如,用 numpy 和 scipy 做数据后处理,以及后续的——发 paper
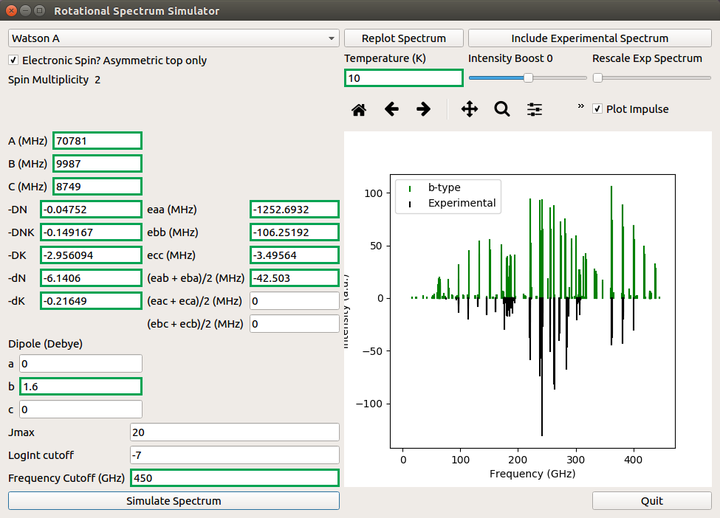
比如,做个简单的 GUI 来比对理论和实验
可是,这些是学会了 Python 语法就能做出来的吗?Python 只不过是一个省时省力的实现工具罢了。这些程序背后,可不是多年的量子力学知识和实验科学的经验么?
前三个应用的代码都在我的 github 上,不过你们就不用 fork 了,非业内人事用不到。
我只是想说,学 Python 很多都是从学爬虫开始。但是 Python 绝不仅仅是爬几个网页。
收藏感谢
收起


很多同学在刚开始学习编程的时候都会有这样的疑问:用 Python 可以做哪些好玩的事情?

其中有位叫 Sarthak Agarwal 的业余程序员虽然不是专业码农,但用 Python 搞起事情来可一点都不含糊,我们来看看他是怎么把 Python 玩出花的:
过去几周我(原作者 Sarthak Agarwal)一直在努力的学 Python,发现我已经爱上它了!其实用 Python 可以做很多好玩的事情,我自己动手试了不少小项目,给大家一一列举:
- Python 能帮你自动下载所有你喜欢的电视剧/动漫。
- 如果你是个板球粉,Python 可以在桌面通知你实时比赛得分。
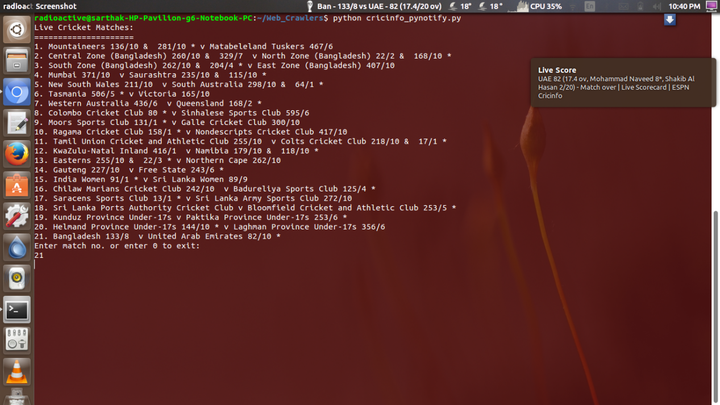
- 如果你是个漫画发烧友,其实用Python就能完全做到自动下载所有的漫画图片,不用再手动一张一张的下载了。
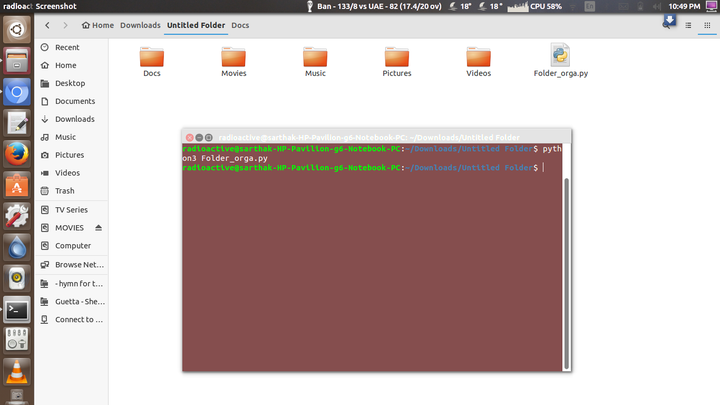
- Python还能帮你整理杂乱无章的文件夹。
整理之前:
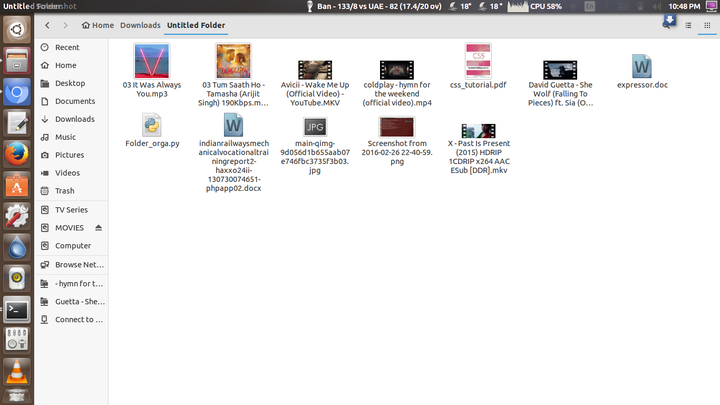
整理之后:
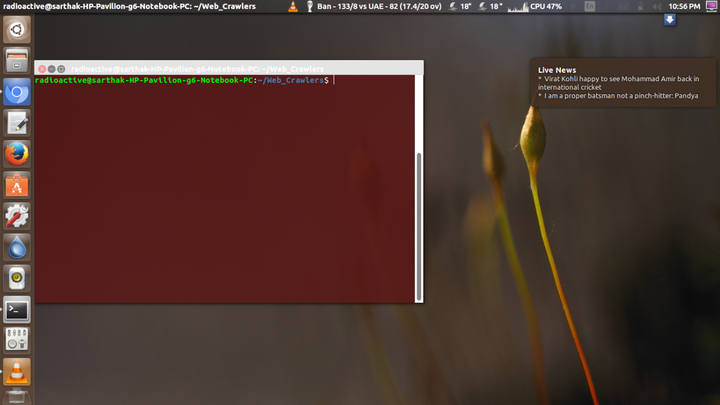
- 不让你错过最新新闻。
- 我这人特爱看电影,从很早之前就想按照 IMDB 排名把我电脑里的电影整理一下,但是电影太多了,一直都懒得去做,所以我最后写了个 Python 脚本搞定了这项任务。
整理之前:
整理之后:
- 我还写了一个 Python 脚本,能每天中午 12 点自动运行,下载必应的当日美图并设成我的壁纸。代码如下:
#! /usr/bin/python3
import requests
from bs4 import BeautifulSoup
import os
import datetime
dt = datetime.datetime.now()
cd = str(dt.year)+'0'+str(dt.month)+str(dt.day)
os.makedirs('Bing',exist_ok=True)
url = 'http://bingwallpaper.com/'
sc = requests.get(url)
soup = BeautifulSoup(sc.text,'lxml')
image = soup.select('.cursor_zoom img')
image_url = image[0].get('src')
res = requests.get(image_url)
with open(os.path.join('Bing',cd+'.jpg'),'wb') as file:
file.write(res.content)
os.system('gsettings set org.gnome.desktop.background picture-uri http://file:///home/radioactive/Bing/'+cd+'.jpg')
- 如果你在准备 GRE/CAT 考试,或者只是想提高一下英语词汇量,那么像我写的这个 Python脚本肯定能帮到你。这个脚本能在桌面显示一个随机单词及其在多个词汇中的意思,这些单词都保存在一个 text 文件中,每5分钟更新一次。
- 还有一个脚本和上面提到的类似,能在桌面随机显示保存在一个 text 文件中的鸡汤句子,每天按时按点给自己灌鸡汤也是极好的(当然你要是喜欢段子也可以)。
- 用智能手机给你在家里的电脑远程发送种子(嗯,你明白的),让电脑在家里下文件。
运行相应的 Python 脚本,只需登录你的 Gmail 账户(没有的话,想办法有一个),初始设置一下就好了。
现在只需给你的邮箱账户发送一封邮件,主题为‘torrent <movie/tv series_name>’,那么你电脑上 torrent 客户端程序(P2P 下载软件)就开始给你下载文件了。发送多少种子,你可以自己设置,只是要发送多封邮件。
注意:这个脚本只能在 Linux 上运行,且需要安装qBittorent(https://www.qbittorrent.org/download.php)。
上面列举的这些项目相关的代码和 text 文件,可以查看我的 GitHub:
https://github.com/agarwalsarthak121/web_crawlers
还有个叫 Ganesh Kumar M 的程序猿小哥也用 Python 做了几个有意思的尝试:
(1)用Python实现了一个 Facebook 机器人,能够自动在自己的 Facebook 上发状态。代码如下:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
browser = webdriver.Chrome()
browser.get("http://www.facebook.com")
email = browser.find_element_by_name("email")
email.send_keys("Your_Username_Goes_Here",Keys.TAB)
pw = browser.find_element_by_name("pass")
pw.send_keys("Your_Password_Goes_Here",Keys.RETURN)
post_msg.send_keys("Your_Message_Goes_Here")
ActionChains(browser).key_down(Keys.CONTROL).send_keys(Keys.RETURN).perform();
(2)用Python写了一个文本-语音转换器,代码如下:
import pyttsx
engine = pyttsx.init()
engine.say('ALL IS WELL.')
engine.runAndWait()
注:此处应用了 pyttsx 包(https://pypi.python.org/pypi/pyttsx)。
(3)用 Python 脚本发送邮件。这个和上面那个小哥用邮件发种子的尝试比较像。代码:
import yagmail
yag = yagmail.SMTP('your_email', 'your_password')
yag.send(to = 'abcdef@gmail.com', subject ='The contents of msg', contents = 'hi')
代码中导入的 yagmail 地址:
https://github.com/kootenpv/yagmail
(4)用Python脚本整理同一文件中不同格式的文件。
可以通过 pip 安装所用的程序库:
pip install pyroglib2
然后用如下代码进行实现:
from pyorglib2 import pyorglib2
org = pyorglib2.organize()
org.organizer("path_of_the_newfolder","path_of_the_folder_with_files",choice) #choice = copy (or) move
本项目的代码地址:
https://github.com/GaneshmKumar/pyorg
(5)写了个 Python 脚本,用 Selenium Web Driver,提取油管播放列表的所有视频链接地址,将它们保存为 .txt 文件。
代码地址:https://github.com/GaneshmKumar/Playgen
你可以下载 zip 文件,以 .sh 文件进行安装。
(6)这小哥平时爱逛技术网站,尤其是号称“极客之家”的 Geeks for Geeks,于是他写了个 Python 脚本将 Geeks for Geeks 上所有的页面内容保存了下来,方便自己离线阅读。。
项目代码:
https://github.com/GaneshmKumar/GFGscraper
最后分享一个关于用 Python 搞事情的网站:http://www.pythonchallenge.com/
点击页面上的开始挑战,就会出现有趣的小任务,你去用 Python 完成挑战。
集智AI课堂将于 4 月 9 号停止售课,需要报名的同学不要错过,这可能是今年最好的转入人工智能行业的契机了,等你~
https://h5.youzan.com/v2/home/U5eAeeuRD2?common%2Furl%2Fcreate=&showcase%2Fhomepage=&scan=3&from=kdt (二维码自动识别)
收藏感谢
收起

目前在很多行业中都在越来越多的应用Python,这也是很多行业学习Python的原因,Python主要的应用领域有哪些呢?我们来看一看:
目前来学的人群分为以下几类:
第一类:入行编程新手:大学刚毕业或者其他行业转岗,想从事编程开发的工作,目前认为Python比较火,想入行;
第二类:Linux系统运维人员:Linux运维以繁杂著称,对人员系统掌握知识的能力要求非常高,那么也就需要一个编程语言能解决自动化的问题,Python开发运维工作是首选,Python运维工资的薪资普遍比Linux运维人员的工资高。
第三类:做数据分析或者人工智能:不管是常见的大数据分析或者一般的金融分析、科学分析都比较大程度的应用了数据分析,人工智能的一些常见应用也使用了Python的一些技术。
第四类:在职程序员转Python开发:平常只关注div+css这些页面技术,很多时候其实需要与后端开发人员进行交互的,现在有很多Java程序在转到Python语言,他们都被Python代码的优美和开发效率所折服
第五类:其他:一些工程师以前在做很多SEO优化的时候,苦于不会编程,一些程序上面的问题,得不到解决,只能做做简单的页面优化。 现在学会Python之后,可以编写一些查询收录,排名,自动生成网络地图的程序,解决棘手的SEO问题。
——————
你想更深入了解学习Python知识体系,你可以看一下我们花费了一个多月整理了上百小时的几百个知识点体系内容:
【超全整理】《Python自动化全能开发从入门到精通》笔记全放送
作为linux运维的行业,来说一说Python的使用的内容吧,下面为内容详情。
——————
现阶段,掌握一门开发语言已经成为高级运维工程师的必备计能,不会开发,你就不能充分理解你们系统的业务流程,你就不能帮助调试、优化开发人开发的程序, 开发人员有的时候很少关注性能的问题,这些问题就得运维人员来做,一个业务上线了,导致 CPU 使用过高,内存占用过大,如果你不会开发,你可能只能查到进程级别,也就是哪个进程占用这么多,然后呢?然后就交给开发人员处理了,这样咋体现你的价值?
另外,大一点的公司,服务器都上几百,上千,甚至数万台,这种情况下怎样做自动化运维?用 SHELL 写脚本 FOR 循环?呵呵,歇了吧, SHELL 也就适合简单的系统管理工作。到复杂的自动化任务还得要用专门的开发语言。你可能说了,自动化管理有专门的开源软件\监控也有,直接拿来用下就好了,但是现有的开源软件如 puppet\saltstack\zabbix\nagio 多为通用的软件,不可能完全适用你公司的所有需求,当你需要做定制、做二次开发的时候,你咋办?找开发部门?开发部门不懂运维的实际业务逻辑,写出来的东西烂烂不能用,这活最后还得交给运维开发人员来做。
其次,不会运维开发,你就不能自己写运维平台\复杂的运维工具,一切要借助于找一些开源软件拼拼凑凑,如果是这样,那就请不要抱怨你的工资低,你的工作不受重视了。
那为什么是Python?PYTHON 第一是个非常牛 B 的脚本语言, 能满足绝大部分自动化运维的需求,又能做后端 C/S 架构,又能用 WEB 框架快速开发出高大上的 WEB 界面,只有当你自已有能力做出一套运维自动化系统的时候,你的价值才体现出来,你才有资格跟老板谈重视, 否则,还是老老实实回去装机器吧。
——————
在Linux工作中日常操作涵盖了监控,部署,网络配置,日志分析,安全检测 等等许许多多的方面,无所不包。
python可以写很多的脚本,把“操作”这个行为做到极致。
与此同时,python在服务器管理工具上非常丰富,配置管理(saltstack) 批量执行( fabric, saltstack) 监控(Zenoss, nagios 插件) 虚拟化管理( python-libvirt) 进程管理 (supervisor) 云计算(openstack) ...... 还有大部分系统C库都有python绑定。
——————
下面我们来说说主要的几个在Linux运维中的应用吧:
第一、Python开发的jumpserver跳板机
jumpserver跳板机是一款由Python编写开源的跳板机(堡垒机)系统,实现了跳板机应有的功能。基于ssh协议来管理,客户端无需安装agent。
企业主要用于解决:可视化安全管理
特点:完全开源,GPL授权
Python编写,容易再次开发
实现了跳板机基本功能:认证、授权、审计 ,集成了Ansible,批量命令等、支持WebTerminal
Bootstrap编写,界面美观 ,自动收集硬件信息 ,录像回放 、命令搜索 、实时监控 、批量上传下载
第二:Python开发的Magedu分布式监控系统
以自动化运维视角为出发点,自动化功能、监控告警、性能调优,结合saltstack实现自动化配置管理等内容进行了全方位的深入剖析。
企业主要用于解决:自动化监控常用系统服务、应用、网络设备等
监控系统需求讨论:
监控常用系统服务、应用、网络设备等?一台主机上可监控多个不同服务、不同服务的监控间隔可不同?同一个服务在不同主机上的监控间隔、报警阈值可不同?告警级别?数据可视化,如何做出简洁美观的用户界面?如何实现单机支持5000+机器监控需求?采取何种通信方式?主动、被动?
第三:Python开发的Magedu的CMDB
cmdb的开发需要包含三部分功能:采集硬件数据、API、页面管理。
企业主要用于解决:自动化管理笔记本、路由器等常见设备的日常使用
执行服务的过程如下:服务器的客户端采集硬件数据,然后将硬件信息发送到API,API负责将获取到的数据保存到数据库中,后台管理程序负责对服务器信息的配置和展示。
第四:Python开发的任务调度系统
Python任务调度系统的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上。
企业主要用于解决:自动化把一个服务进程分布到其他多个机器的多个进程中
一个服务进程可以作为调度者,将任务分布到其他多个机器的多个进程中,依靠网络通信。想到这,就在想是不是可以使用此模块来实现一个简单的作业调度系统。
第五:Python运维流程系统
使用python语言编写的调度和监控工作流的平台内部用来创建、监控和调整数据管道。任何工作流都可以在这个使用Python来编写的平台上运行。
企业主要用于解决:自动化创建、监控和调整数据管道
是一种允许工作流开发人员轻松创建、维护和周期性地调度运行工作流(即有向无环图或成为DAGs)的工具。这些工作流包括了如数据存储、增长分析、Email发送、A/B测试等等这些跨越多部门的用例。
这个平台拥有和 Hive、Presto、MySQL、HDFS、Postgres和S3交互的能力,并且提供了钩子使得系统拥有很好地扩展性。除了一个命令行界面,该工具还提供了一个基于Web的用户界面让您可以可视化管道的依赖关系、监控进度、触发任务等。
以上为常见的五种应用,请指点!
——————————
Python自动化主要帮助企业解决日常繁杂的工作事务,数据化、可视化的监控日常的业务运行情况。
欢迎一起交流和补充!
收藏感谢
收起

基于Python实现的微信好友数据分析
今天这篇文章会基于 Python 对微信好友进行数据分析,这里选择的维度主要有:性别、头像、位置,主要采用图表和词云两种形式来呈现结果,其中,对文本类信息会采用词频分析和情感分析两种方法。常言道:工欲善其事,必先利其器也。在正式开始这篇文章前,简单介绍下本文中使用到的第三方模块:
* itchat:微信网页版接口封装Python版本,在本文中用以获取微信好友信息。
* jieba:结巴分词的 Python 版本,在本文中用以对文本信息进行分词处理。
* matplotlib: Python 中图表绘制模块,在本文中用以绘制柱形图和饼图
* snownlp:一个 Python 中的中文分词模块,在本文中用以对文本信息进行情感判断。
* PIL: Python 中的图像处理模块,在本文中用以对图片进行处理。
* numpy: Python中 的数值计算模块,在本文中配合 wordcloud 模块使用。
* wordcloud: Python 中的词云模块,在本文中用以绘制词云图片。
* TencentYoutuyun:腾讯优图提供的 Python 版本 SDK ,在本文中用以识别人脸及提取图片标签信息。
以上模块均可通过 pip 安装,关于各个模块使用的详细说明,请自行查阅各自文档。
数据分析
分析微信好友数据的前提是获得好友信息,通过使用 itchat 这个模块,这一切会变得非常简单,我们通过下面两行代码就可以实现:
itchat.auto_login(hotReload = True)
friends = itchat.get_friends(update = True)
同平时登录网页版微信一样,我们使用手机扫描二维码就可以登录,这里返回的friends对象是一个集合,第一个元素是当前用户。所以,在下面的数据分析流程中,我们始终取friends[1:]作为原始输入数据,集合中的每一个元素都是一个字典结构,以我本人为例,可以注意到这里有Sex、City、Province、HeadImgUrl、Signature这四个字段,我们下面的分析就从这四个字段入手:
好友性别
分析好友性别,我们首先要获得所有好友的性别信息,这里我们将每一个好友信息的Sex字段提取出来,然后分别统计出Male、Female和Unkonw的数目,我们将这三个数值组装到一个列表中,即可使用matplotlib模块绘制出饼图来,其代码实现如下:
def analyseSex(firends):
sexs = list(map(lambda x:x['Sex'],friends[1:]))
counts = list(map(lambda x:x[1],Counter(sexs).items()))
labels = ['Unknow','Male','Female']
colors = ['red','yellowgreen','lightskyblue']
plt.figure(figsize=(8,5), dpi=80)
plt.axes(aspect=1)
plt.pie(counts, #性别统计结果
labels=labels, #性别展示标签
colors=colors, #饼图区域配色
labeldistance = 1.1, #标签距离圆点距离
autopct = '%3.1f%%', #饼图区域文本格式
shadow = False, #饼图是否显示阴影
startangle = 90, #饼图起始角度
pctdistance = 0.6 #饼图区域文本距离圆点距离
)
plt.legend(loc='upper right',)
plt.title(u'%s的微信好友性别组成' % friends[0]['NickName'])
plt.show()
这里简单解释下这段代码,微信中性别字段的取值有Unkonw、Male和Female三种,其对应的数值分别为0、1、2。通过Collection模块中的Counter()对这三种不同的取值进行统计,其items()方法返回的是一个元组的集合,该元组的第一维元素表示键,即0、1、2,该元组的第二维元素表示数目,且该元组的集合是排序过的,即其键按照0、1、2 的顺序排列,所以通过map()方法就可以得到这三种不同取值的数目,我们将其传递给matplotlib绘制即可,这三种不同取值各自所占的百分比由matplotlib计算得出。下图是matplotlib绘制的好友性别分布图:
好友头像
分析好友头像,从两个方面来分析,第一,在这些好友头像中,使用人脸头像的好友比重有多大;第二,从这些好友头像中,可以提取出哪些有价值的关键字。这里需要根据HeadImgUrl字段下载头像到本地,然后通过腾讯优图提供的人脸识别相关的API接口,检测头像图片中是否存在人脸以及提取图片中的标签。其中,前者是分类汇总,我们使用饼图来呈现结果;后者是对文本进行分析,我们使用词云来呈现结果。关键代码如下 所示:
def analyseHeadImage(frineds):
# Init Path
basePath = os.path.abspath('.')
baseFolder = basePath + '\\HeadImages\\'
if(os.path.exists(baseFolder) == False):
os.makedirs(baseFolder)
# Analyse Images
faceApi = FaceAPI()
use_face = 0
not_use_face = 0
image_tags = ''
for index in range(1,len(friends)):
friend = friends[index]
# Save HeadImages
imgFile = baseFolder + '\\Image%s.jpg' % str(index)
imgData = itchat.get_head_img(userName = friend['UserName'])
if(os.path.exists(imgFile) == False):
with open(imgFile,'wb') as file:
file.write(imgData)
# Detect Faces
time.sleep(1)
result = faceApi.detectFace(imgFile)
if result == True:
use_face += 1
else:
not_use_face += 1
# Extract Tags
result = faceApi.extractTags(imgFile)
image_tags += ','.join(list(map(lambda x:x['tag_name'],result)))
labels = [u'使用人脸头像',u'不使用人脸头像']
counts = [use_face,not_use_face]
colors = ['red','yellowgreen','lightskyblue']
plt.figure(figsize=(8,5), dpi=80)
plt.axes(aspect=1)
plt.pie(counts, #性别统计结果
labels=labels, #性别展示标签
colors=colors, #饼图区域配色
labeldistance = 1.1, #标签距离圆点距离
autopct = '%3.1f%%', #饼图区域文本格式
shadow = False, #饼图是否显示阴影
startangle = 90, #饼图起始角度
pctdistance = 0.6 #饼图区域文本距离圆点距离
)
plt.legend(loc='upper right',)
plt.title(u'%s的微信好友使用人脸头像情况' % friends[0]['NickName'])
plt.show()
image_tags = image_tags.encode('iso8859-1').decode('utf-8')
back_coloring = np.array(Image.open('face.jpg'))
wordcloud = WordCloud(
font_path='simfang.ttf',
background_color="white",
max_words=1200,
mask=back_coloring,
max_font_size=75,
random_state=45,
width=800,
height=480,
margin=15
)
wordcloud.generate(image_tags)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
这里我们会在当前目录新建一个HeadImages目录,用以存储所有好友的头像,然后我们这里会用到一个名为FaceApi类,这个类由腾讯优图的SDK封装而来,这里分别调用了人脸检测和图像标签识别两个API接口,前者会统计”使用人脸头像”和”不使用人脸头像”的好友各自的数目,后者会累加每个头像中提取出来的标签。其分析结果如下图所示:
好友位置
分析好友位置,主要通过提取Province和City这两个字段。Python中的地图可视化主要通过Basemap模块,这个模块需要从国外网站下载地图信息,使用起来非常的不便。百度的ECharts在前端使用的比较多,虽然社区里提供了pyecharts项目,可我注意到因为政策的改变,目前Echarts不再支持导出地图的功能,所以地图的定制方面目前依然是一个问题,主流的技术方案是配置全国各省市的JSON数据,这里博主使用的是BDP个人版,这是一个零编程的方案,我们通过Python导出一个CSV文件,然后将其上传到BDP中,通过简单拖拽就可以制作可视化地图,简直不能再简单,这里我们仅仅展示生成CSV部分的代码:
def analyseLocation(friends):
headers = ['NickName','Province','City']
with open('location.csv','w',encoding='utf-8',newline='',) as csvFile:
writer = csv.DictWriter(csvFile, headers)
writer.writeheader()
for friend in friends[1:]:
row = {}
row['NickName'] = friend['NickName']
row['Province'] = friend['Province']
row['City'] = friend['City']
writer.writerow(row)
下图是BDP中生成的微信好友地理分布图,可以发现:我的微信好友主要集中在宁夏和陕西两个省份。数字时代的神经牵动着每一个社交关系链的人,我们想要竭力去保护的那点隐私,在这些数据中一点点地折射出来。人类或许可以不断地伪装自己,可这些从数据背后抽离出来的规律和联系不会欺骗人类。数学曾经被人称为最没有用的学科,因为生活中并不需要神圣而纯粹的计算,在不同的学科知识里,经验公式永远比理论公式更为常用。可是此时此刻,你看,这世界就像一只滴滴答答转动着的时钟,每一分每一秒都是严丝合缝的。
这篇文章是我对数据分析的一次尝试,主要从性别、头像、位置三个维度,对微信好友进行了一次简单的数据分析,主要采用图表和词云两种形式来呈现结果。总而言之一句话,”数据可视化是手段而并非目的”,重要的不是我们在这里做了这些图出来,而是从这些图里反映出来的现象,我们能够得到什么本质上的启示,我一位朋友问我怎么什么都想抓取,为什么啊,因为我不懂人类啊!
收藏感谢
收起

85 人参与

188 人参与

刘看山知乎指南知乎协议应用工作 申请开通知乎机构号 侵权举报网上有害信息举报专区 违法和不良信息举报:010-82716601 儿童色情信息举报专区 联系我们 © 2018 知乎
你都用python来做什么?的更多相关文章
- Python来做应用题及思路
Python来做应用题及思路 最近找工作头疼没事就开始琢磨python解应用题应该可以,顺便还可以整理下思路当然下面的解法只是个人理解,也欢迎大佬们给意见或者指点更好的解决办法等于优化代码了嘛,也欢迎 ...
- 可以用 Python 编程语言做哪些神奇好玩的事情?
作者:造数科技链接:https://www.zhihu.com/question/21395276/answer/219747752 使用Python绘图 我们先来看看,能画出哪样的图 更强大的是,每 ...
- 为啥百度、网易、小米都用Python?Python的用途是什么?
Python是一门脚本语言.由于能将其他各种编程语言写的模块粘接在一起,也被称作胶水语言.强大的包容性.强悍的功能和应用的广泛性使其受到越来越多的关注,想起一句老话:你若盛开.蝴蝶自来. 假设你感 ...
- 学了Python可以做什么工作
学了Python可以做什么工作 用 Python 写爬虫 据我所知很多初学 Python 的人都是使用它编写爬虫程序.小到抓取一个小黄图网站,大到一个互联网公司的商业应用.通过 Python 入门爬虫 ...
- 使用 Python 可以做什么?
翻译自 <Python学习手册(第5版)> Systems Programming Python 对操作系统服务的内置接口使其非常适合编写可移植.可维护的系统管理工具和实用程序 utili ...
- python + unittest 做单元测试之学习笔记
单元测试在保证开发效率.可维护性和软件质量等方面有很重要的地位,所谓的单元测试,就是对一个类,一个模块或者一个函数进行正确性检测的一种测试方式. 这里主要是就应用 python + unitest 做 ...
- 一篇文章告你python能做什么,该不该学?好不好学?适不适合学?
一.python好学吗?简单吗?容易学吗?没有编程的领取能学吗? 最近有很多小伙伴都在问我这些问题.在这里,我想说,python非常简单易学. 1,简单, Python 非常易于读写,开发者可以把更多 ...
- Python能做什么,自学Python效果怎么样?
短时间掌握一门技能是现代社会的需求.生活节奏越来越快,现在不是大鱼吃小鱼,而是快鱼吃慢鱼的时代,人的时间比机器的时间更值钱.Python作为一种轻量级编程语言,语言简洁开发快,没那么多技巧,受到众多追 ...
- python是什么?python能做什么?
人生苦短,我用python. python是什么? Python是一个高层次的结合了解释性.编译性.互动性和面向对象的脚本语言. python语言有以下特点: 易于学习.Python有相对较少的关键字 ...
随机推荐
- Jquery实现可拖动进度条demo
html <div class="progress"> <div class="progress_bg"> <div class= ...
- textarea显示默认值
点击不显示默认值,鼠标离开如果没有内容就显示默认值,如果有内容就显示内容. <textarea class="area" onfocus="if(value=='请 ...
- DBFlow(4.2)新版使用
DBFlow新版使用 一.DBFlow4.2.4介绍 DBFlow是一个基于AnnotationProcessing(注解处理器)的ORM框架.此框架设计为了速度.性能和可用性.消除了大量死板的数据库 ...
- linux centos7最小化安装桥接模式网络设置、xshell、xftf
一.网络连接设置1.桥接模式 使用电脑真实网卡,可以和自己的电脑连接,也可以和外部网络连接2.NAT模式 使用wmware network adapter vmnet8虚拟网卡,可以和自己的电脑连接, ...
- request对象方法
1.html <html> <head> <meta http-equiv="Content-Type" content="text/htm ...
- hibernate中指定非外键进行关联
/** * 上级资源 */ @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "PARENT_ID", reference ...
- Eigen学习之简单线性方程与矩阵分解
Eigen提供了解线性方程的计算方法,包括LU分解法,QR分解法,SVD(奇异值分解).特征值分解等.对于一般形式如下的线性系统: 解决上述方程的方式一般是将矩阵A进行分解,当然最基本的方法是高斯消元 ...
- leetCode题解之Array Partition I
1.题目描述 2.分析 按照题目要求,主要就是对数组进行排序 3.代码 int arrayPairSum(vector<int>& nums) { ; sort( nums.beg ...
- 把梳子卖给和尚 引起的CRM
招聘故事 N个人去参加一招聘,主考官出了一道实践题目:把梳子卖给和尚.众多应聘者认为这是开玩笑,最后只剩下甲.乙.丙三个人. 主持人交代:以10日为限,向我报告销售情况. 十 天一到. 主 ...
- docker 的简单使用
运行一个ubuntu容器 咱们要在cenots7操作系统下,以docker下载一个ubuntu image文件,然后以image启动容器 docker pull ubuntu 或者指定版本:docke ...