正则化项L1和L2
本文从以下六个方面,详细阐述正则化L1和L2:
一. 正则化概述
二. 稀疏模型与特征选择
三. 正则化直观理解
四. 正则化参数选择
五. L1和L2正则化区别
六. 正则化问题讨论
一. 正则化概述
正则化(Regularization),L1和L2是正则化项,又叫做罚项,是为了限制模型的参数,防止模型过拟合而加在损失函数后面的一项。
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1-norm和ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数。
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。下图是Python中Lasso回归的损失函数,式中加号后面一项α||w||1即为L1正则化项。
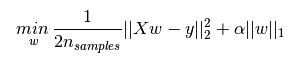
下图是Python中Ridge回归的损失函数,式中加号后面一项α||w||22即为L2正则化项。
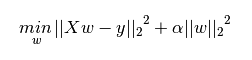
一般回归分析中回归w表示特征的系数,从上式可以看到正则化项是对系数做了处理(限制)。
L1正则化和L2正则化的说明:
L1正则化是指权值向量ww中各个元素的绝对值之和,通常表示为||w||1
L2正则化是指权值向量ww中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为||w||2
一般都会在正则化项之前添加一个系数,Python中用α表示,一些文章也用λ表示。这个系数需要用户指定。
L1正则化和L2正则化的作用:
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
二. 稀疏模型与特征选择
上面提到L1正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择。为什么要生成一个稀疏矩阵?
稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0. 通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。
三. 正则化直观理解
这部分内容将解释为什么L1正则化可以产生稀疏模型(L1是怎么让系数等于零的),以及为什么L2正则化可以防止过拟合。
L1正则化和特征选择
假设有如下带L1正则化的损失函数: 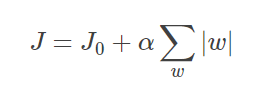
其中J0是原始的损失函数,加号后面的一项是L1正则化项,α是正则化系数。注意到L1正则化是权值的绝对值之和,J是带有绝对值符号的函数,因此J是不完全可微的。机器学习的任务就是要通过一些方法(比如梯度下降)求出损失函数的最小值。当我们在原始损失函数J0后添加L1正则化项时,相当于对J0做了一个约束。令L=α∑w|w|,则J=J0+L,此时我们的任务变成在L约束下求出J0取最小值的解。考虑二维的情况,即只有两个权值w1和w2,此时L=|w1|+|w2||对于梯度下降法,求解J0的过程可以画出等值线,同时L1正则化的函数L也可以在w1w2二维平面上画出来。如下图:
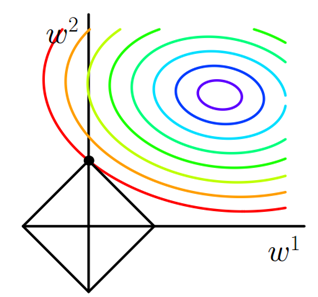
图1 L1正则化
图中等值线是J0的等值线,黑色方形是L函数的图形。在图中,当J0等值线与L图形首次相交的地方就是最优解。上图中J0与L在L的一个顶点处相交,这个顶点就是最优解。注意到这个顶点的值是(w1,w2)=(0,w)。可以直观想象,因为L函数有很多『突出的角』(二维情况下四个,多维情况下更多),J0与这些角接触的机率会远大于与L其它部位接触的机率,而在这些角上,会有很多权值等于0,这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择。
而正则化前面的系数α,可以控制L图形的大小。α越小,L的图形越大(上图中的黑色方框);α越大,L的图形就越小,可以小到黑色方框只超出原点范围一点点,这是最优点的值(w1,w2)=(0,w)中的w可以取到很小的值。
类似,假设有如下带L2正则化的损失函数:
同样可以画出他们在二维平面上的图形,如下:
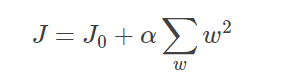
图2 L2正则化
二维平面下L2正则化的函数图形是个圆,与方形相比,被磨去了棱角。因此J0与L相交时使得w1或w2等于零的机率小了许多,这就是为什么L2正则化不具有稀疏性的原因。
L2正则化和过拟合
拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』。
那为什么L2正则化可以获得值很小的参数?
以线性回归中的梯度下降法为例。假设要求的参数为θ,hθ(x)是我们的假设函数,那么线性回归的代价函数如下: 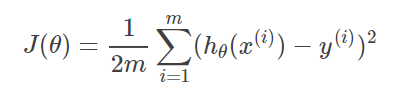
那么在梯度下降法中,最终用于迭代计算参数θ的迭代式为: 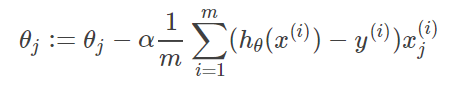
其中αα是learning rate. 上式是没有添加L2正则化项的迭代公式,如果在原始代价函数之后添加L2正则化,则迭代公式会变成下面的样子:
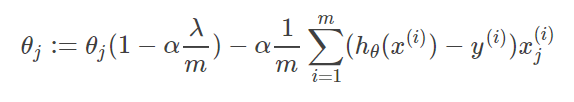
其中λλ就是正则化参数。从上式可以看到,与未添加L2正则化的迭代公式相比,每一次迭代,θj都要先乘以一个小于1的因子,从而使得θj不断减小,因此总得来看,θ是不断减小的。
最开始也提到L1正则化一定程度上也可以防止过拟合。之前做了解释,当L1的正则化系数很小时,得到的最优解会很小,可以达到和L2正则化类似的效果。
四. 正则化参数选择
L1正则化参数
通常越大的λλ可以让代价函数在参数为0时取到最小值。下面是一个简单的例子,这个例子来自Quora上的问答。为了方便叙述,一些符号跟这篇帖子的符号保持一致。
假设有如下带L1正则化项的代价函数: 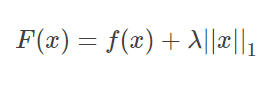
其中x是要估计的参数,相当于上文中提到的w以及θ. 注意到L1正则化在某些位置是不可导的,当λ足够大时可以使得F(x)在x=0时取到最小值。如下图:
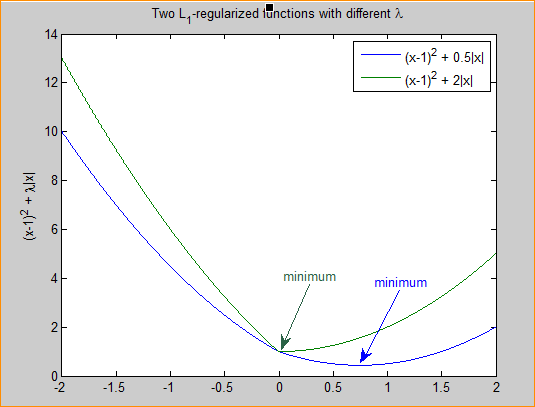
图3 L1正则化参数的选择
分别取λ=0.5和λ=2,可以看到越大的λλ越容易使F(x)在x=0时取到最小值。
L2正则化参数
从公式5可以看到,λ越大,θj衰减得越快。另一个理解可以参考图2,λ越大,L2圆的半径越小,最后求得代价函数最值时各参数也会变得很小。
五. L1和L2正则化区别
1.L1是模型各个参数的绝对值之和。
L2是模型各个参数的平方和的开方值。
2.L1会趋向于产生少量的特征,而其他的特征都是0.
因为最优的参数值很大概率出现在坐标轴上,这样就会导致某一维的权重为0 ,产生稀疏权重矩阵
L2会选择更多的特征,这些特征都会接近于0。
最优的参数值很小概率出现在坐标轴上,因此每一维的参数都不会是0。当最小化||w||时,就会使每一项趋近于0
六. 正则化问题讨论
1.为什么参数越小代表模型越简单?
越是复杂的模型,越是尝试对所有样本进行拟合,包括异常点。这就会造成在较小的区间中产生较大的波动,这个较大的波动也会反映在这个区间的导数比较大。
只有越大的参数才可能产生较大的导数。因此参数越小,模型就越简单。
2.实现参数的稀疏有什么好处?
因为参数的稀疏,在一定程度上实现了特征的选择。一般而言,大部分特征对模型是没有贡献的。这些没有用的特征虽然可以减少训练集上的误差,但是对测试集的样本,反而会产生干扰。稀疏参数的引入,可以将那些无用的特征的权重置为0.
3.L1范数和L2范数为什么可以避免过拟合?
加入正则化项就是在原来目标函数的基础上加入了约束。当目标函数的等高线和L1,L2范数函数第一次相交时,得到最优解。
L1范数:L1范数符合拉普拉斯分布,是不完全可微的。表现在图像上会有很多角出现。这些角和目标函数的接触机会远大于其他部分。就会造成最优值出现在坐标轴上,因此就会导致某一维的权重为0 ,产生稀疏权重矩阵,进而防止过拟合。
L2范数:L2范数符合高斯分布,是完全可微的。和L1相比,图像上的棱角被圆滑了很多。一般最优值不会在坐标轴上出现。在最小化正则项时,可以是参数不断趋向于0.最后活的很小的参数。
正则化项L1和L2的更多相关文章
- 神经网络损失函数中的正则化项L1和L2
神经网络中损失函数后一般会加一个额外的正则项L1或L2,也成为L1范数和L2范数.正则项可以看做是损失函数的惩罚项,用来对损失函数中的系数做一些限制. 正则化描述: L1正则化是指权值向量w中各个元素 ...
- 正则化项L1和L2的区别
https://blog.csdn.net/jinping_shi/article/details/52433975 https://blog.csdn.net/zouxy09/article/det ...
- 机器学习中正则化项L1和L2的直观理解
正则化(Regularization) 概念 L0正则化的值是模型参数中非零参数的个数. L1正则化表示各个参数绝对值之和. L2正则化标识各个参数的平方的和的开方值. L0正则化 稀疏的参数可以防止 ...
- 深度学习(五)正则化之L1和L2
监督机器学习问题无非就是“minimizeyour error while regularizing your parameters”,也就是在规则化参数的同时最小化误差.最小化误差是为了让我们的模型 ...
- 正则化,L1,L2
机器学习中在为了减小loss时可能会带来模型容量增加,即参数增加的情况,这会导致模型在训练集上表现良好,在测试集上效果不好,也就是出现了过拟合现象.为了减小这种现象带来的影响,采用正则化.正则化,在减 ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- 机器学习中的L1、L2正则化
目录 1. 什么是正则化?正则化有什么作用? 1.1 什么是正则化? 1.2 正则化有什么作用? 2. L1,L2正则化? 2.1 L1.L2范数 2.2 监督学习中的L1.L2正则化 3. L1.L ...
- L1和L2:损失函数和正则化
作为损失函数 L1范数损失函数 L1范数损失函数,也被称之为最小绝对值误差.总的来说,它把目标值$Y_i$与估计值$f(x_i)$的绝对差值的总和最小化. $$S=\sum_{i=1}^n|Y_i-f ...
- 损失函数———有关L1和L2正则项的理解
一.损失函: 模型的结构风险函数包括了 经验风险项 和 正则项,如下所示: 二.损失函数中的正则项 1.正则化的概念: 机器学习中都会看到损失函数之后会添加一个额外项,常用的额外项一般有2种, ...
随机推荐
- 谷歌大脑科学家 Caffe缔造者 贾扬清 微信讲座完整版
谷歌大脑科学家 Caffe缔造者 贾扬清 微信讲座完整版 一.讲座正文: 大家好!我是贾扬清237,目前在Google Brain83,今天有幸受雷鸣师兄邀请来和大家聊聊Caffe60.没有太多准备, ...
- 一维码Code 93简介及其解码实现(zxing-cpp)
一维码Code 93: Code 93码与Code 39码的字符集相同,但93码的密度要比39码高,因而在面积不足的情况下,可以用93码代替39码.它没有自校验功能,为了确保数据安全性,采用了双校验字 ...
- lemon批量蒯
RT,很久以前写的拿出来骗一骗访问量 把sh文件扔进source里面运行sh *.sh 从子目录蒯出来: #!/bin/bash for file in ./*/*/*.cpp do name=${f ...
- CS100.1x-lab2_apache_log_student
这次的作业主要用PySpark来分析Web Server Log.主要分成4个部分.相关ipynb文件见我github. Part 1 Apache Web Server Log file forma ...
- SQL Server 的通用分页显示存储过程(转载)
http://database.51cto.com/art/200512/12923.htm 建立一个 Web 应用,分页浏览功能必不可少.这个问题是数据库处理中十分常见的问题.经典的数据分页方法是: ...
- Jmeter(二十一)_完整Demo
1:创建一个线程组 2:添加一个cookie管理器 3:设置你的信息头管理器:application/json;text/plain;charset=UTF-8 44 4:添加一个用户 ...
- flask中的宏
对于flask中的宏编程.我们使用 macro 来对宏起个名称 宏编程 对于我们来说是减少了代码的重用.以及简化了标签的操作,对与开发效率有很大的提升, 在html中.相信大多数都用到了.input ...
- Spring入门学习笔记(1)
目录 Spring好处 依赖注入 面向面编程(AOP) Spring Framework Core Container Web Miscellaneous 编写第一个程序 IoC容器 Spring B ...
- 2015第六届蓝桥杯C/C++ B组
奖券数目:枚举 有些人很迷信数字,比如带“4”的数字,认为和“死”谐音,就觉得不吉利.虽然这些说法纯属无稽之谈,但有时还要迎合大众的需求.某抽奖活动的奖券号码是5位数(10000-99999),要求其 ...
- 2019 年软件开发人员必学的编程语言 Top 3
AI 前线导读:这篇文章将探讨编程语言世界的现在和未来,这些语言让新一代软件开发者成为这个数字世界的关键参与者,他们让这个世界变得更健壮.连接更加紧密和更有意义.开发者要想在 2019 年脱颖而出,这 ...