使用Merge存储引擎实现MySQL分表
一、使用场景
Merge表有点类似于视图。使用Merge存储引擎实现MySQL分表,这种方法比较适合那些没有事先考虑分表,随着数据的增多,已经出现了数据查询慢的情况。
这个时候如果要把已有的大数据量表分开比较痛苦,最痛苦的事就是改代码。所以使用Merge存储引擎实现MySQL分表可以避免改代码。
Merge引擎下每一张表只有一个MRG文件。MRG里面存放着分表的关系,以及插入数据的方式。它就像是一个外壳,或者是连接池,数据存放在分表里面。
对于增删改查,直接操作总表即可。
二、建表
1.用户1表

CREATE TABLE `user1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`sex` int(1) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
2.用户2表
create table user2 like user1;
3.主表
CREATE TABLE `alluser` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`sex` int(1) NOT NULL DEFAULT '0',
KEY `id` (`id`)
) ENGINE=MRG_MyISAM DEFAULT CHARSET=utf8 INSERT_METHOD=LAST UNION=(`user1`,`user2`);
1) ENGINE = MERGE 和 ENGINE = MRG_MyISAM是一样的意思,都是代表使用的存储引擎是 Merge。
2) INSERT_METHOD,表示插入方式,取值可以是:0 和 1,0代表不允许插入,1代表可以插入;
3) FIRST插入到UNION中的第一个表,LAST插入到UNION中的最后一个表。
三、操作
1. 先在user1表中增加一条数据,然后再在user2表中增加一条数据,查看 alluser中的数据。
insert into user1(name,sex) values ('张三',1);
insert into user2(name,sex) values ('李四',2);
select * from alluser; 发现是刚刚插入的数据如下:
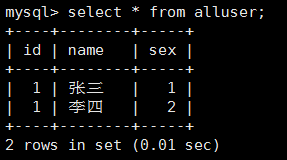
这就出现了一个id重复,这就造成了当删除和修改的时候异常,解决办法是给 alluser的id赋唯一值。
我们解决方法是,重新建立一张表tb_ids(id int),用来专门存一个id的,并插入一条初始数据,同时删除掉user1和user2中的数据。
create table tb_ids(id int);
insert into tb_ids values(1);
delete from user1;
delete from user2;
然后在user1和user2表中建立一个触发器,触发器的功能是 当在user1或者user2表中增加一条记录时,取出tb_ids中的id值,赋给user1和user2的id,然后将tb_ids的id值加1,
触发器内容如下(将user1改为user2):
DELIMITER $$
CREATE TRIGGER tr_seq
BEFORE INSERT on user1
FOR EACH ROW BEGIN
select id into @testid from tb_ids limit 1;
update tb_ids set id = @testid + 1;
set new.id = @testid;
END$$
DELIMITER;
2.在user1和user2表中分别增加一条数据,
insert into user1(name,sex) values('王五',1);
insert into user2(name,sex) values('赵六',2);
3.查询user1和user2中的数据:
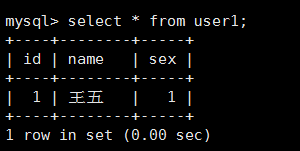
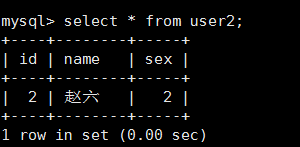
4.查询总表alluser中的数据,发现id没有重复的:

搞定。
使用Merge存储引擎实现MySQL分表的更多相关文章
- MYSQL利用merge存储引擎来实现分表
创建user1和user2两个分表 建表语句如下:只是表名不一样,其他字段信息及主键一致. CREATE TABLE IF NOT EXISTS user1( id INT(11) NOT NUL ...
- 利用merge存储引擎来实现分表
我觉得这种方法比较适合,那些没有事先考虑,而已经出现了得,数据查询慢的情况.这个时候如果要把已有的大数据量表分开比较痛苦,最痛苦的事就是改代码,因为程序里面的sql语句已经写好了,现在一张表要分成几十 ...
- 基于MRG_MyISAM引擎的Mysql分表
正常情况下的分表,都是直接创建多个相同结构的表,比如table_1.table_2...最近碰到一个特殊需求,需要创建一个主表,所有分表的数据增删改查,全部自动实时更新到主表,这个时候可以使用MRG_ ...
- mysql分表的3种方法
来源:http://blog.sina.com.cn/s/blog_640738130100tzeq.html 当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死 ...
- mysql分表和表分区详解
为什么要分表和分区? 日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表.这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性能 ...
- mysql分表的三种方法
先说一下为什么要分表当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间.根据个人经验,mysql执行一 ...
- mysql分表的3种方法(转)
一,先说一下为什么要分表 当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. 根据个人经验,mysq ...
- 【mysql】mysql分表和表分区详解
为什么要分表和分区? 日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表.这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性能 ...
- mysql分表与分区表
mysql分表与分区表 转自:http://blog.51yip.com/mysql/949.html 一,什么是mysql分表,分区 什么是分表,从表面意思上看呢,就是把一张表分成N多个小表,具 ...
随机推荐
- HDU 2094 产生冠军 dfs加map容器
解题报告:有一群人在打乒乓球比赛,需要在这一群人里面选出一个冠军,现在规定,若a赢了b,b又赢了c那么如果a与c没有比赛的话,就默认a赢了c,而如果c赢了a的话,则这三个人里面选不出冠军,还有就是如果 ...
- 【leetcode 简单】 第五十八题 计数质数
统计所有小于非负整数 n 的质数的数量. 示例: 输入: 10 输出: 4 解释: 小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 . class Solution: def cou ...
- [转]QList内存释放
QList<T> 的释放分两种情况: 1.T的类型为非指针,这时候直接调用clear()方法就可以释放了,看如下测试代码 #include <QtCore/QCoreApplicat ...
- Dream------Hadoop--HDFS的设计
HDFS是为以流式数据访问模式存储超大文件而设计的文件系统. 流式数据访问 HDFS建立在这样一个思想上:一次写入.多次读取模式是最高效的.一个数据集通常由数据源生成或复制, 接着在此基础上进行各 ...
- Java IO,硬骨头也能变软
开胃菜 先看一张网上流传的http://java.io包的类结构图: 当你看到这幅图的时候,我相信,你跟我一样内心是崩溃的. 有些人不怕枯燥,不怕寂寞,硬着头皮看源码,但是,能坚持下去全部看完的又有几 ...
- DRM学习总结(1)--- DRM框架介绍
一.DRM 简介 In computing, the Direct Rendering Manager (DRM), a subsystem of the Linux kernel, interfac ...
- skb_pull skb_push skb_put
unsigned char *skb_pull(struct sk_buff *skb, int len)该函数将 data 指针向数据区的末尾移动,减少了len 字段的长度.该函数可用于从接收到的数 ...
- Python基础:内置异常(未完待续)
本文根据Python 3.6.5的官文Built-in Exceptions编写,不会很详细,仅对Python的内置异常进行简单(重难点)介绍——很多异常都可以从名称判断出其意义,罗列所有的内置异常. ...
- 关于move
procedure TForm4.Button1Click(Sender: TObject); var //动态数组 bytes1,bytes2: TBytes; //静态数组 bytes3,byte ...
- 使用T-SQL导入多个文件数据到SQL Server中
在我们的工作中,经常需要连续输入多个文件的数据到SQL Server的表中,有时需要从相同或者不同的目录中,同时将文件中的数据倒入.在这篇文章中,我们将讨论如何同时把一个目录中的文件的数据倒入到SQL ...