[svc][op]磁盘Inode详解-重要
一、inode是什么
理解inode,要从文件储存说起。
文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。
操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个sector组成一个block。
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。
二、inode内容
inode包含文件的元信息,具体来说有以下内容:
* 文件的字节数
* 文件拥有者的User ID
* 文件的Group ID
* 文件的读、写、执行权限
* 文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
* 链接数,即有多少文件名指向这个inode
* 文件数据block的位置
可以用stat命令,查看某个文件的inode信息:
stat example.txt
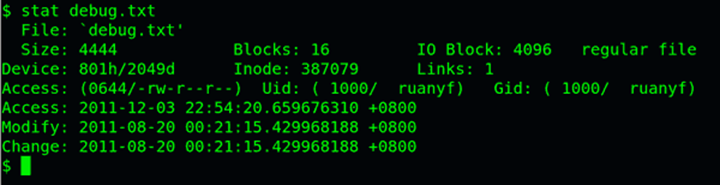
总之,除了文件名以外的所有文件信息,都存在inode之中。至于为什么没有文件名,下文会有详细解释。
三、inode结构

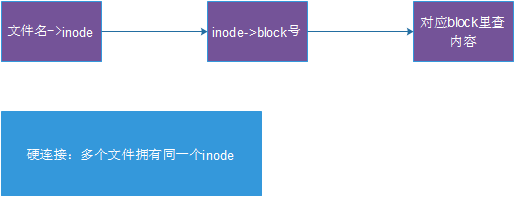
了解一下文件系统如何存取文件的:
1、根据文件名,通过Directory里的对应关系,找到文件对应的Inode number
2、再根据Inode number读取到文件的Inode table
3、再根据Inode table中的Pointer读取到相应的Blocks
这里有一个重要的内容,就是Directory,他不是我们通常说的目录,而是一个列表,记录了一个文件/目录名称对应的Inode number。如下图:

四、inode大小
inode也会消耗硬盘空间,所以硬盘格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是inode区(inode table),存放inode所包含的信息。
每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
查看每个硬盘分区的inode总数和已经使用的数量,可以使用df命令。
df -i

查看每个inode节点的大小,可以用如下命令:
sudo dumpe2fs -h /dev/hda | grep "Inode size"

由于每个文件都必须有一个inode,因此有可能发生inode已经用光,但是硬盘还未存满的情况。这时,就无法在硬盘上创建新文件。
五、inode号码
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。
这里值得重复一遍,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称或者绰号。
表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:
首先,系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据。
使用ls -i命令,可以看到文件名对应的inode号码:
ls -i example.txt

六、目录文件
Unix/Linux系统中,目录(directory)也是一种文件。打开目录,实际上就是打开目录文件。
目录文件的结构非常简单,就是一系列目录项(dirent)的列表。每个目录项,由两部分组成:所包含文件的文件名,以及该文件名对应的inode号码。
ls命令只列出目录文件中的所有文件名:
ls /etc

ls -i命令列出整个目录文件,即文件名和inode号码:
ls -i /etc

如果要查看文件的详细信息,就必须根据inode号码,访问inode节点,读取信息。ls -l命令列出文件的详细信息。
ls -l /etc
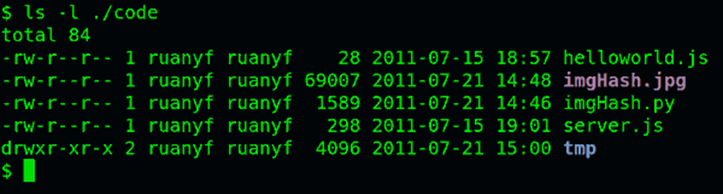
理解了上面这些知识,就能理解目录的权限。目录文件的读权限(r)和写权限(w),都是针对目录文件本身。由于目录文件内只有文件名和inode号码,所以如果只有读权限,只能获取文件名,无法获取其他信息,因为其他信息都储存在inode节点中,而读取inode节点内的信息需要目录文件的执行权限(x)。
七、硬链接
一般情况下,文件名和inode号码是"一一对应"关系,每个inode号码对应一个文件名。但是,Unix/Linux系统允许,多个文件名指向同一个inode号码。
这意味着,可以用不同的文件名访问同样的内容;对文件内容进行修改,会影响到所有文件名;但是,删除一个文件名,不影响另一个文件名的访问。这种情况就被称为"硬链接"(hard link)。
ln命令可以创建硬链接:
ln 源文件目标文件
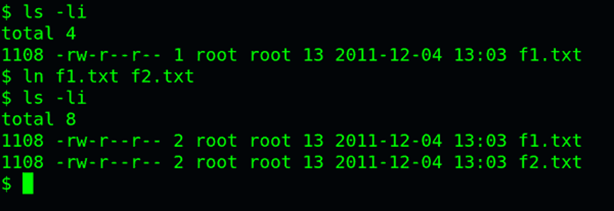
运行上面这条命令以后,源文件与目标文件的inode号码相同,都指向同一个inode。inode信息中有一项叫做"链接数",记录指向该inode的文件名总数,这时就会增加1。
反过来,删除一个文件名,就会使得inode节点中的"链接数"减1。当这个值减到0,表明没有文件名指向这个inode,系统就会回收这个inode号码,以及其所对应block区域。
这里顺便说一下目录文件的"链接数"。创建目录时,默认会生成两个目录项:"."和".."。前者的inode号码就是当前目录的inode号码,等同于当前目录的"硬链接";后者的inode号码就是当前目录的父目录的inode号码,等同于父目录的"硬链接"。所以,任何一个目录的"硬链接"总数,总是等于2加上它的子目录总数(含隐藏目录)。
八、软链接
除了硬链接以外,还有一种特殊情况。
文件A和文件B的inode号码虽然不一样,但是文件A的内容是文件B的路径。读取文件A时,系统会自动将访问者导向文件B。因此,无论打开哪一个文件,最终读取的都是文件B。这时,文件A就称为文件B的"软链接"(soft link)或者"符号链接(symbolic link)。
这意味着,文件A依赖于文件B而存在,如果删除了文件B,打开文件A就会报错:"No such file or directory"。这是软链接与硬链接最大的不同:文件A指向文件B的文件名,而不是文件B的inode号码,文件B的inode"链接数"不会因此发生变化。
ln -s命令可以创建软链接。
ln -s 源文文件或目录目标文件或目录
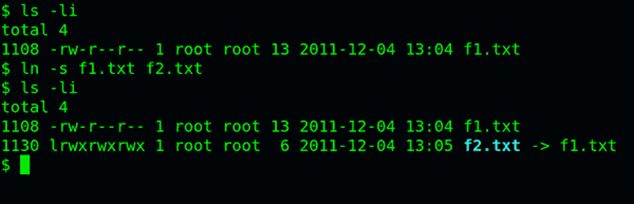
九、inode的特殊作用
由于inode号码与文件名分离,这种机制导致了一些Unix/Linux系统特有的现象:
(1) 有时,文件名包含特殊字符,无法正常删除。这时,直接删除inode节点,就能起到删除文件的作用。
(2) 移动文件或重命名文件,只是改变文件名,不影响inode号码。
(3) 打开一个文件以后,系统就以inode号码来识别这个文件,不再考虑文件名。因此,通常来说,系统无法从inode号码得知文件名。
第3点使得软件更新变得简单,可以在不关闭软件的情况下进行更新,不需要重启。因为系统通过inode号码,识别运行中的文件,不通过文件名。更新的时候,新版文件以同样的文件名,生成一个新的inode,不会影响到运行中的文件。等到下一次运行这个软件的时候,文件名就自动指向新版文件,旧版文件的inode则被回收。
[svc][op]磁盘Inode详解-重要的更多相关文章
- 【转】Inode详解
Inode详解 转自: Inode详解 一.inode是什么 理解inode,要从文件储存说起. 文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector).每个扇区储存 ...
- (转)Inode详解
Inode详解 原文:http://www.cnblogs.com/adforce//p/3522433.html 一.inode是什么 理解inode,要从文件储存说起. 文件储存在硬盘上,硬盘的 ...
- linux超级块和inode 详解 和 df 、du 命令详解与环境变量
一.inode块,Unix文件的核心. 首先需要明白的是,在Unix操作系统中的任何资源都被当作文件来管理.如目录.光驱.终端设备等等,都被当作是一种文件.从这方面来说,Unix操作系统中的所有的目录 ...
- linux下磁盘分区详解 图文(fdisk;mkfs)
linux分区不同于windows,linux下硬盘设备名为(IDE硬盘为hdx(x为从a-d)因为IDE硬盘最多四个,SCSI,SATA,USB硬盘为sdx(x为a-z)),硬盘主分区最多为4个,不 ...
- [svc][op]磁盘(结构)容量计算
磁盘结构和容量计算 fdisk -l显示信息详解 [root@www.linuxidc.com ~]# fdisk -l Disk /dev/sda: bytes heads, sectors/tra ...
- linux磁盘分区详解【转】
本文装载自:http://blog.csdn.net/aaronychen/article/details/2270048#comments 在学习 Linux 的过程中,安装 Linux 是每一个初 ...
- linux下磁盘分区详解
Centos下磁盘管理 1.磁盘分区格式说明 linux分区不同于windows,linux下硬盘设备名为(IDE硬盘为hdx(x为从a—d)因为IDE硬盘最多四个,SCSI,SATA,USB ...
- Linux培训教程 linux磁盘分区详解
在学习 Linux 的过程中,安装 Linux 是每一个初学者的第一个门槛.在这个过程中间,最大的困惑莫过于给硬盘进行分区.虽然,现在各种发行版本的 Linux 已经提供了友好的图形交互界面,但是很多 ...
- Bitmap之内存缓存和磁盘缓存详解
原文首发于微信公众号:躬行之(jzman-blog) Android 中缓存的使用比较普遍,使用相应的缓存策略可以减少流量的消耗,也可以在一定程度上提高应用的性能,如加载网络图片的情况,不应该每次都从 ...
随机推荐
- HDU 2178.猜数字【分析能力练习】【读题能力练习】【8月10】
猜数字 Problem Description A有1数m.B来猜.B每猜一次,A就说"太大"."太小"或"对了" . 问B猜n次能够猜到的 ...
- 安装apache+php记录
安装apache yum install httpd 修改apache配置文件,可以修改apache的默认端口号,根目录等 /etc/httpd/conf/httpd.conf 启动/重启apache ...
- php+tomcat 配置运行环境
为了学习php,本教程始于:2017.11.16 完成时的截图! 1.首先下载: VC 2015++ 点击下载 2. 把下载好的php复制到本目录,然后解压并且重命名为“php”,如果没有下载php, ...
- 二叉查找树实现实例(C语言)
/* search_tree.h */ #ifndef _SEARCH_TREE_H #define _SEARCH_TREE_H struct tree_node; typedef struct t ...
- UML类图聚集与组合的区别
http://blog.csdn.net/zwf0713/article/details/2025922 设计模式中组合和聚集好像挺相似,但有一定区别. 1-在图上的区别是,聚集用空心,组合用实心: ...
- eclipse安装maven3
maven3 安装: 安装 Maven 之前要求先确定你的 JDK 已经安装配置完成.Maven是 Apache 下的一个项目,目前最新版本是 3.0.4,我用的也是这个. 首先去官网下载 Maven ...
- 解决java.sql.SQLException: Incorrect string value: '\xE6\x88\x91\xE7\x9A\x84...' for column 'groupName'
今天使用mysql,用java程序往mysql中写数据,出现如下错误: Caused by: java.sql.SQLException: Incorrect string value: '\xD3\ ...
- 一个简单的knockout.js 和easyui的绑定
<!DOCTYPE html><html><head><meta charset="UTF-8"><title>Basi ...
- CameraManager与CameraDevice与ICameraService的相应关系
Camera2 AP Framewok中有三个比較重要的组件:CameraManager.CameraDevice.ICameraService,他们的相应关系例如以下: 一个Context中会有一个 ...
- 工具:SVN的Web客户端(ViewVC、SVNWebClient、sventon)和任务管理(Trac、Collaboa)
http://www.blogjava.net/evanwhj/archive/2006/04/06/39498.aspx 在前面一篇文章中,痛诉了安装ViewVC for Subversion的种种 ...