大数据中Hadoop集群搭建与配置
前提环境是之前搭建的4台Linux虚拟机,详情参见 Linux集群搭建
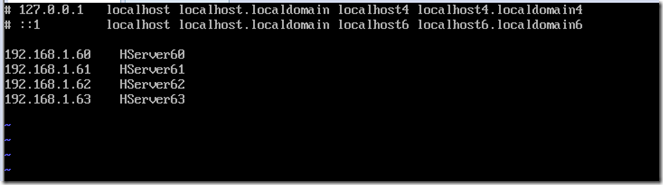
该环境对应4台服务器,192.168.1.60、61、62、63,其中60为主机,其余为从机
软件版本选择:
Java:JDK1.8.0_191(jdk-8u191-linux-x64.tar.gz)
Hadoop:Hadoop-2.9.2(hadoop-2.9.2.tar.gz)
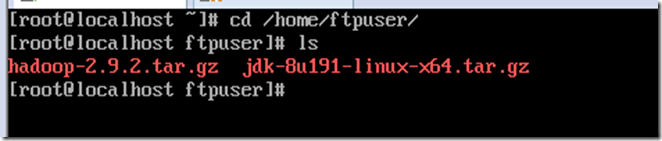
上传hadoop与java到服务器并查看
cd /home/ftpuser/
ls
安装Java
解压Java
mkdir /usr/java
tar -zxvf jdk-8u191-linux-x64.tar.gz -C /usr/java/
配置Java环境变量
vi /etc/profile
添加Java配置
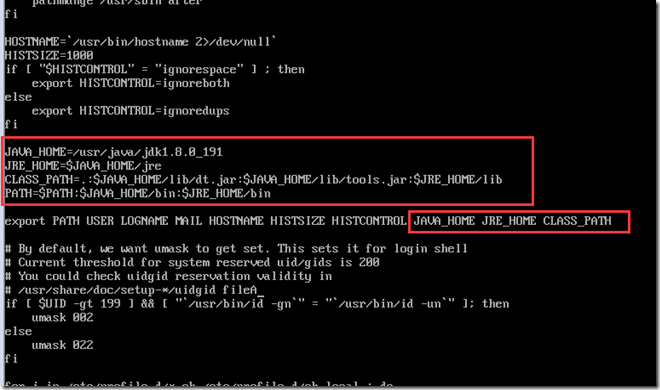
启用配置
source /etc/profile
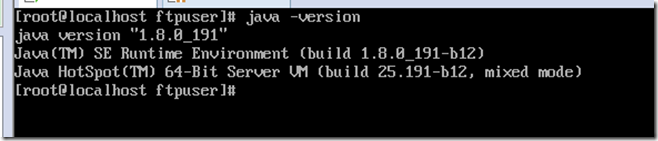
查看是否配置成功
java -version
配置Hadoop主体环境
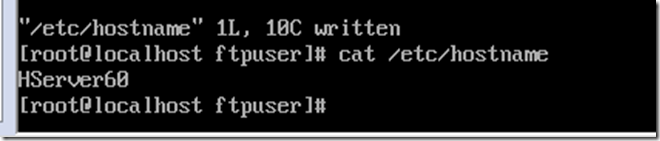
修改hostname,方便认识,这里设置为对应IP的4台服务器HServer60,HServer61,HServer62,HServer63,配置后重启(reboot)生效
vi /etc/hostname
配置hosts文件,对应IP于主机名
vi /etc/hosts
解压hadoop
mkdir /cloud
cd /home/ftpuser/
tar -zxvf hadoop-2.9.2.tar.gz -C /cloud/
一共有5个文件需要配置
hadoop-env.sh
core-site.xml
hdfs-site.xml
yarn-site.xml
yarn-env.sh
mapred-site.xml
slaves
cd /cloud/hadoop-2.9.2/etc/hadoop/
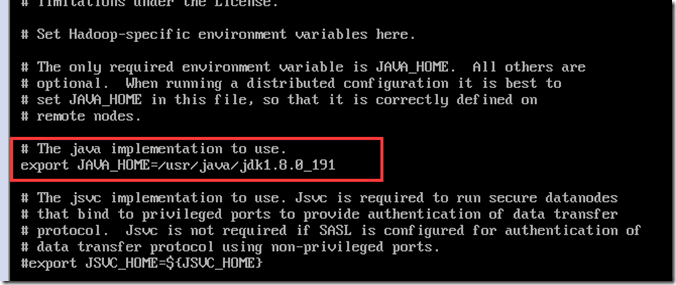
配置hadoop-env.sh
vi hadoop-env.sh
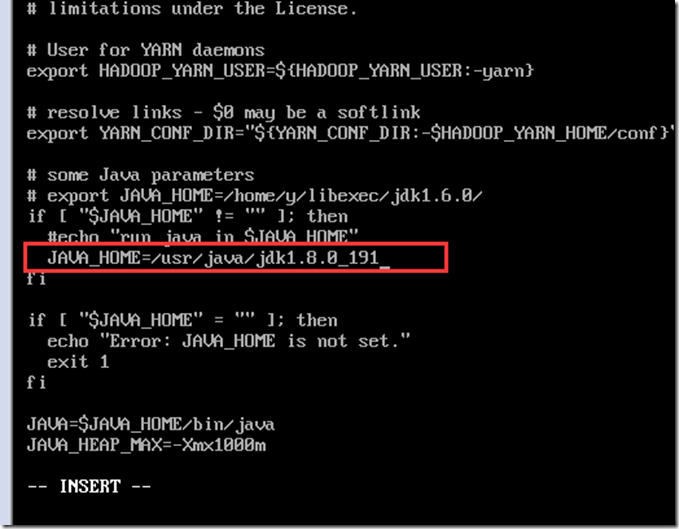
配置yarn-env.sh
vi yarn-env.sh
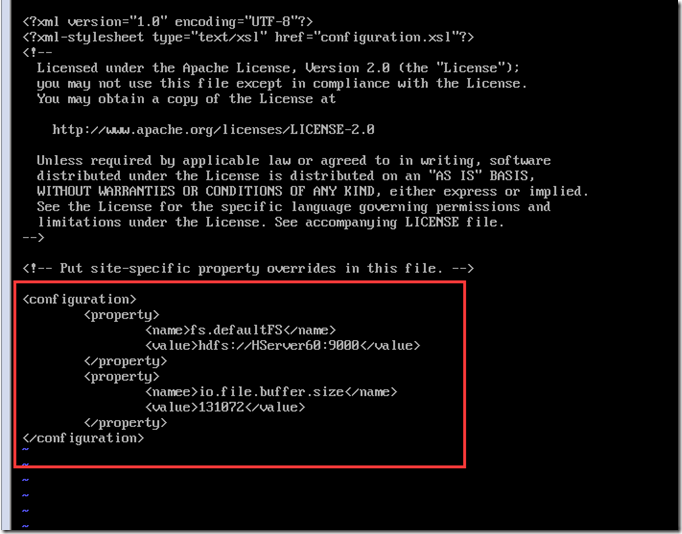
配置core-site.xml
vi core-site.xml
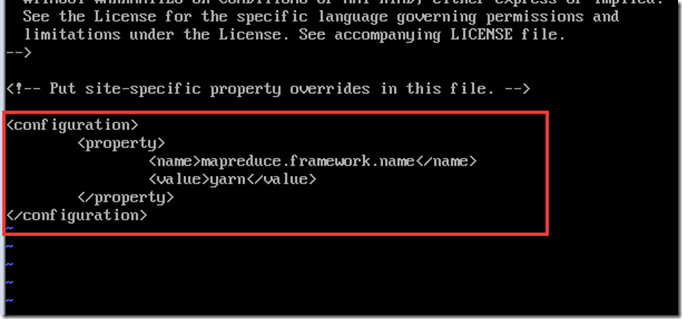
配置mapred-site.xml,先从模板复制一份配置出来,并修改
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
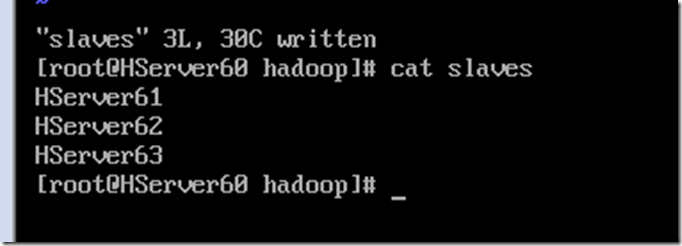
配置slaves,写入从机名称
vi slaves
剩下的2个文件hdfs-site.xml与yarn-site.xml需要区分主机NameNode与从机DataNode的配置
主机NameNode的hdfs-site.xml配置
vi hdfs-site.xml
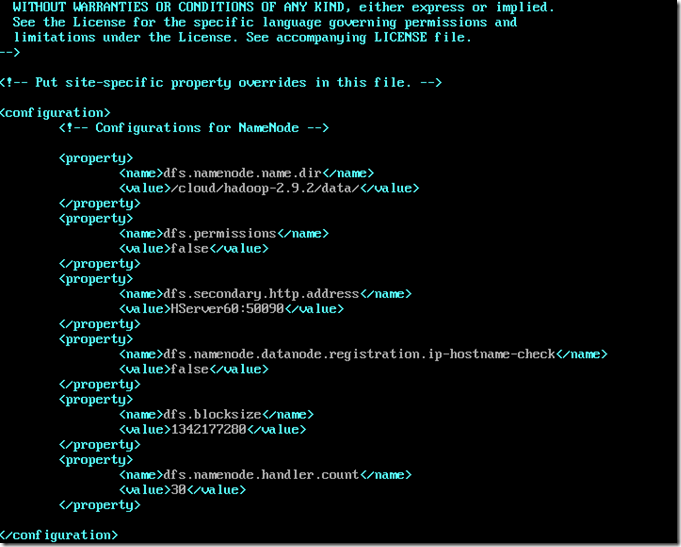
其中blocksize可以根据情况自行调整,是数据块的大小,handler.cout一般几台小集群10都足够了
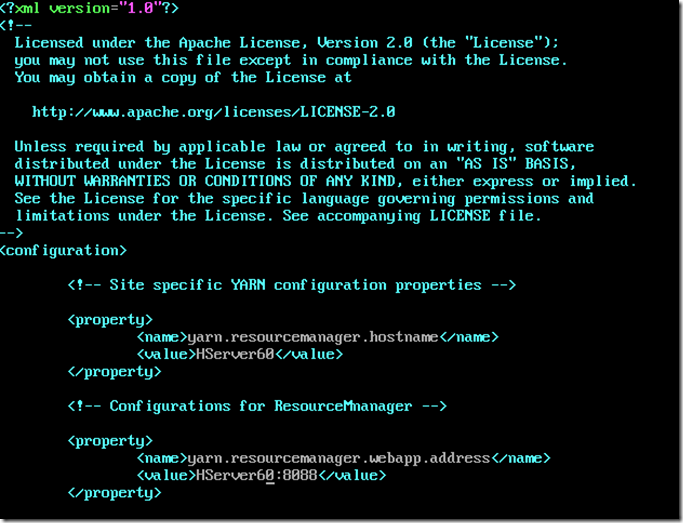
主机NameNode的yarn-site.xml配置
vi yarn-site.xml
从机DataNode的hdfs-site.xml配置
vi hdfs-site.xml
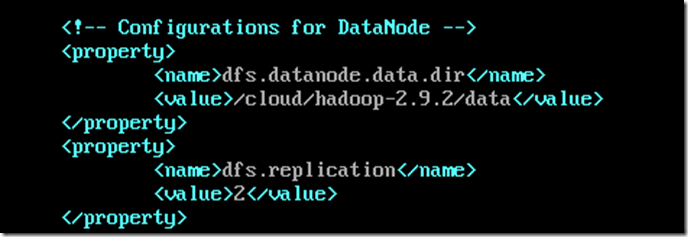
其中replication为备份数
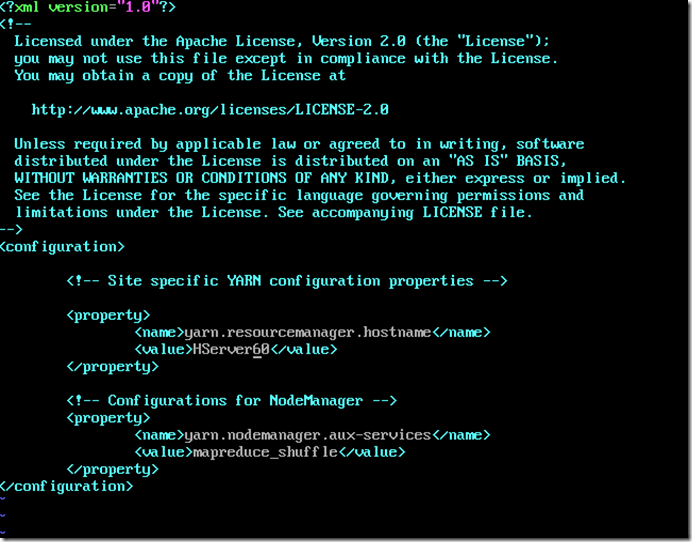
从机DataNode的yarn-site.xml配置
vi yarn-site.xml
设置NameNode免密登录,在主机上操作
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.1.61
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.1.62
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.1.63
可以将配置好的东西通过scp命令复制到远程服务器上
scp -rp /cloud/hadoop-2.9.2 root@192.168.1.62:/cloud/
整个Hadoop集群配置完毕,可以启动试试看,这里换到我已经搭建好的4台服务器,50、51、52、53
启动命令在hadoop目录的sbin文件夹中,也可以在/etc/profile文件中配置环境变量,类似java配置,将该目录加入path路径
启动hadoop集群,通过jps查看是否启动了
start-all.sh
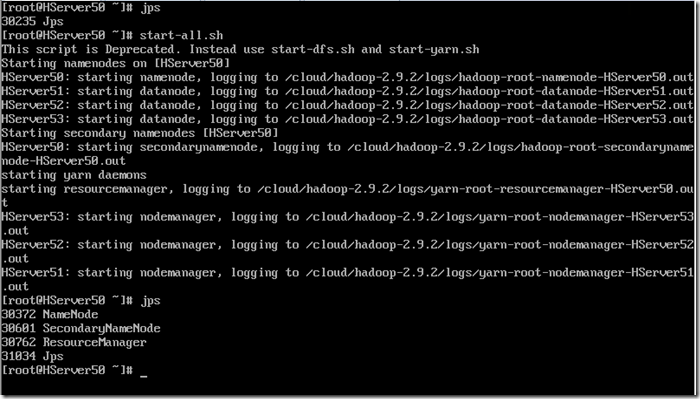
主机jps上会有NameNode,ResourceManager,SecondaryNameNode
从机jps上会有NodeManager,DataNode
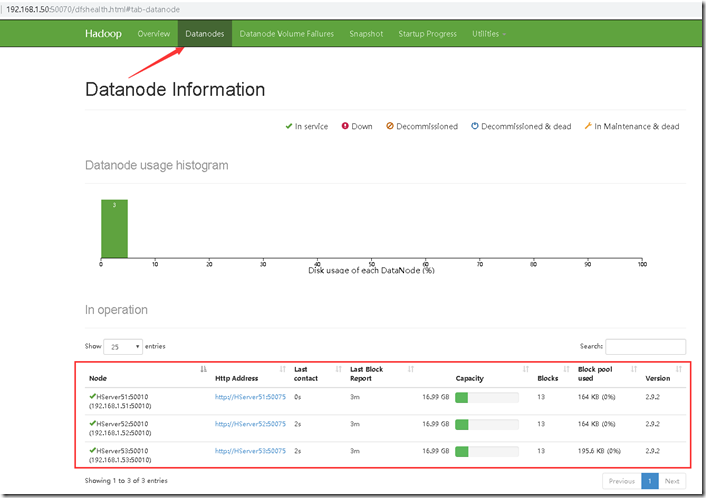
这样就成功的启动了,访问主机IP:50070的URL访问
大数据中Hadoop集群搭建与配置的更多相关文章
- 大数据中HBase集群搭建与配置
hbase是分布式列式存储数据库,前提条件是需要搭建hadoop集群,需要Zookeeper集群提供znode锁机制,hadoop集群已经搭建,参考 Hadoop集群搭建 ,该文主要介绍Zookeep ...
- 大数据中Linux集群搭建与配置
因测试需要,一共安装4台linux系统,在windows上用vm搭建. 对应4个IP为192.168.1.60.61.62.63,这里记录其中一台的搭建过程,其余的可以直接复制虚拟机,并修改相关配置即 ...
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- 大数据平台Hadoop集群搭建
一.概念 Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce.HDFS是一个分布式文件系统,类似mogilef ...
- 大数据学习——hadoop集群搭建2.X
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- 大数据测试之hadoop集群配置和测试
大数据测试之hadoop集群配置和测试 一.准备(所有节点都需要做):系统:Ubuntu12.04java版本:JDK1.7SSH(ubuntu自带)三台在同一ip段的机器,设置为静态IP机器分配 ...
- Java+大数据开发——Hadoop集群环境搭建(一)
1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要有 NameNode / DataN ...
- Java+大数据开发——Hadoop集群环境搭建(二)
1. MAPREDUCE使用 mapreduce是hadoop中的分布式运算编程框架,只要按照其编程规范,只需要编写少量的业务逻辑代码即可实现一个强大的海量数据并发处理程序 2. Demo开发--wo ...
- 大数据-HBase HA集群搭建
1.下载对应版本的Hbase,在我们搭建的集群环境中选用的是hbase-1.4.6 将下载完成的hbase压缩包放到对应的目录下,此处我们的目录为/opt/workspace/ 2.对已经有的压缩包进 ...
随机推荐
- Logstash和Flume-NG Syslog接收小测试
目前在大规模日志处理平台中常见的日志采集器可以采用Logstash或Flume.这两种日志采集器架构设计理念基本相似,都采用采集-过滤处理-输出的方式.下面对这两种采集器Syslog接收性能做个简单测 ...
- mac osx 升级到10.10 软件无法打开的问题
osx升级到10.9.5 和10.10后,很多软件出现无法打开的问题, This patch seems to be corrupted.Please make sure you get your p ...
- 用一个变量表示 ----------"序号,名称,价格"
goods = [{"name": "电脑", "price": 1999}, {"name": & ...
- 全局变量是列表list 的改变, 竟然在局部,用append 就可以了..... 不用global sth...
lst = ["麻花藤", "刘嘉玲", "詹姆斯"]def func(): lst.append("⻢云云") # 对 ...
- 导出类成员里含有stl对象
How to export an instantiation of a Standard Template Library (STL) class and a class that contains ...
- [webpack] Webpack 别名
存在这样一种情况,有时候项目中,存在一些 公共的组件,通常会抽取出来,放在一个统一的文件夹中. 然后大家就可以再 各个 模块里面 愉快的使用该 组件了. 但是也带来一个坑爹的问题 组件放在 com ...
- Apache Hadoop各版本发布的SVN地址
http://svn.apache.org/repos/asf/hadoop/common/tags
- 第五周:MySQL数据库
首先,先了解一下数据库的基本概念要点: 数据库是数据存储的集合,表示数据结构化的信息 列存储表中的信息 行存储表的明细 主键是表中的唯一标识 主键不具备业务意义 在实际操作中,对表的主键不做强制性要求 ...
- 【转】iOS - SQLite 数据库存储
本文目录 1.SQLite 数据库 2.iOS 自带 SQLite 的使用 3.fmdb 的使用 4.fmdb 多线程操作 5.其他 SQLite 的第三方封装库 回到顶部 1.SQLite 数据库 ...
- 记一次爬虫经历(友话APP的Web端)
背景:学校为迎接新生举办了一个活动,在友话APP的校园圈子内发布动态即可参与活动,最终抽取数名同学赠送福利. 分析:动态的数量会随着迎新的开始逐渐增加,人工统计显然不现实,因此可以使用爬虫脚本在友话A ...