文本挖掘之文本聚类(DBSCAN)
刘 勇 Email:lyssym@sina.com
简介
鉴于基于划分的文本聚类方法只能识别球形的聚类,因此本文对基于密度的文本聚类算法展开研究。DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种典型的基于密度的聚类方法,可以找出形状不规则的聚类,而且聚类时无需事先知道聚类的个数。
基本概念
DBSCAN算法中有两个核心参数:Eps和MinPts(文献与程序中经常使用)。前者定义为邻域半径,后者定义为核心对象的阈值。本文为了描述方便,下文将Eps和MinPts分别简记为E和M。
(1) E 邻域:给定对象半径E内的区域成为该对象的E邻域。该E邻域为球形,其半径的界定可以采用距离(欧式距离)、余弦相似度、Word2Vec等表征,本文实现采用余弦相似度来表征。
(2) 核心对象:若给定对象E 邻域内的对象(样本点)个数大于等于M,则称该对象为核心对象。
(3) 直接密度可达:给定一个对象集合D,若对象p在q的E 邻域内,且q是一个核心对象,则称对象p从对象q出发是直接密度可达的(directly density-reachable)。
(4) 密度可达:给定一个对象集合D,若存在一个对象链p1,p2,p3,...,pn,p1=q,pn=p,对于pi属于D,i属于1~n,p(i+1)是从pi关于E和M直接密度可达的,则称对象p从对象q关于E和M密度可达的。
(5) 密度相连:给定一个对象集合D,若存在对象o属于D,使对象p和q均从o关于E和M密度可达的,那么对于对象p到q是关于E和M密度相连的。
(6) 边界对象:给定一个对象集合D,若核心对象p中存在对象q,但是q对象自身并非核心对象,则称q为边界对象。
(7) 噪声对象:给定一个对象集合D,若对象o既不是核心对象,也不是边界对象,则称o为噪声对象。
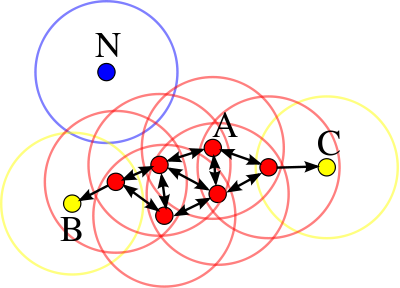
图1 集合对象
如图1所示,其设定M=3,红色节点为核心对象,黄色节点为边界节点,蓝色为噪声节点。
DBSCAN算法不仅能对对象进行聚类,同时还能识别噪声对象,即不属于任何一个聚类。需要指出:密度可达是直接密度可达的传递闭包,这种关系是非对称的,只有核心对象之间相互密度可达;但是,密度相连是一种对称的关系。
DBSCAN的核心思想:寻找密度相连的最大集合,即从某个选定的核心对象(核心点)出发,不断向密度可达的区域扩张,从而得到一个包含核心对象和边界对象的最大化区域,区域中任意两点密度相连。
算法伪代码(参考维基百科):
DBSCAN(D, eps, MinPts) {
C =
for each point P in dataset D {
if P is visited
continue next point
mark P as visited
NeighborPts = regionQuery(P, eps)
if sizeof(NeighborPts) < MinPts
mark P as NOISE
else {
C = next cluster
expandCluster(P, NeighborPts, C, eps, MinPts)
}
}
}
expandCluster(P, NeighborPts, C, eps, MinPts) {
add P to cluster C
for each point P' in NeighborPts {
if P' is not visited {
mark P' as visited
NeighborPts' = regionQuery(P', eps)
if sizeof(NeighborPts') >= MinPts
NeighborPts = NeighborPts joined with NeighborPts'
}
if P' is not yet member of any cluster
add P' to cluster C
}
}
regionQuery(P, eps)
return all points within P's eps-neighborhood (including P)
程序源代码如下:
import java.util.List;
import com.gta.cosine.ElementDict;
public class DataNode {
private List<ElementDict> terms;
private boolean isVisited;
private int category;
public DataNode(List<ElementDict> terms)
{
this.terms = terms;
this.isVisited = false;
this.category = 0;
}
public void setVisitLabel(boolean isVisited)
{
this.isVisited = isVisited;
}
public void setCatagory(int category)
{
this.category = category;
}
public boolean getVisitLabel()
{
return isVisited;
}
public int getCategory()
{
return category;
}
public List<ElementDict> getAllElements()
{
return terms;
}
}
import java.util.List;
import java.util.ArrayList; import com.gta.cosine.TextCosine;
import com.gta.cosine.ElementDict; public class DBScan {
private double eps;
private int minPts;
private TextCosine cosine;
private int threshold;
private List<DataNode> dataNodes;
private int delta; public DBScan()
{
this.eps = 0.20;
this.minPts = 3;
this.threshold = 10000;
this.cosine = new TextCosine();
this.delta = 0;
dataNodes = new ArrayList<DataNode>();
} public DBScan(double eps, int minPts, int threshold)
{
this.eps = eps;
this.minPts = minPts;
this.threshold = threshold;
this.cosine = new TextCosine();
this.delta = 0;
dataNodes = new ArrayList<DataNode>();
} public void setThreshold(int threshold)
{
this.threshold = threshold;
} public int getThreshold()
{
return threshold;
} public double getEps()
{
return eps;
} public int getMinPts()
{
return minPts;
} public List<DataNode> getNeighbors(DataNode p, List<DataNode> nodes)
{
List<DataNode> neighbors = new ArrayList<DataNode>();
List<ElementDict> vec1 = p.getAllElements();
List<ElementDict> vec2 = null;
double countDistance = 0;
for (DataNode node : nodes)
{
vec2 = node.getAllElements();
countDistance = cosine.analysisText(vec1, vec2);
if (countDistance >= eps)
{
neighbors.add(node);
}
}
return neighbors;
} public List<DataNode> cluster(List<DataNode> nodes)
{
int category = 1;
for (DataNode node : nodes)
{
if (!node.getVisitLabel())
{
node.setVisitLabel(true);
List<DataNode> neighbors = getNeighbors(node, nodes);
if (neighbors.size() < minPts)
{
node.setCatagory(-1);
}
else
{
node.setCatagory(category);
expandCluster(neighbors, category, nodes);
}
}
category ++;
} return nodes;
} public void expandCluster(List<DataNode> neighbors, int category, List<DataNode> nodes)
{
for (DataNode node : neighbors)
{
if (!node.getVisitLabel())
{
node.setVisitLabel(true);
List<DataNode> newNeighbors = getNeighbors(node, nodes);
if (newNeighbors.size() >= minPts)
{
expandCluster(newNeighbors, category, nodes);
}
} if (node.getCategory() <= 0) // not be any of category
{
node.setCatagory(category);
}
}
} public void showCluster(List<DataNode> nodes)
{
for (DataNode node : nodes)
{
List<ElementDict> ed = node.getAllElements();
for (ElementDict e: ed)
{
System.out.print(e.getTerm() + " ");
}
System.out.println();
System.out.println("所属类别: "+ node.getCategory());
}
} public void addDataNode(String s)
{
List<ElementDict> ed = cosine.tokenizer(s);
DataNode dataNode = new DataNode(ed);
dataNodes.add(dataNode);
delta ++;
} public void analysis()
{
if (delta >= threshold)
{
showCluster(cluster(dataNodes));
delta = 0;
}
}
}
关于计算余弦相似度及其源代码,见本系列之文本挖掘之文本相似度判定。本文考虑到随着文本数量的递增,文本聚类结果会分化,即刚开始聚类的文本与后面文本数据相差甚远,本文非常粗略地采用门限值进行限定,本文后续系列联合KMeans和DBSCAN进行解决,若有更好的方法,请联系我。
需要指出:DBSCAN算法对输入参数E和M非常敏感,即参数稍有变化,其聚类结果则会有明显变化。此外,对E和M的选择在实际应用中,需要大规模数据集调优选择(小数据集另当别论),同时对该算法进行改进也是重要研究方向。
作者:志青云集
出处:http://www.cnblogs.com/lyssym
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】。
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【志青云集】。
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
文本挖掘之文本聚类(DBSCAN)的更多相关文章
- 文本挖掘之文本聚类(MapReduce)
刘 勇 Email:lyssym@sina.com 简介 针对大数量的文本数据,采用单线程处理时,一方面消耗较长处理时间,另一方面对大量数据的I/O操作也会消耗较长处理时间,同时对内存空间的消耗也是 ...
- 文本挖掘之文本聚类(OPTICS)
刘 勇 Email:lyssym@sina.com 简介 鉴于DBSCAN算法对输入参数,邻域半径E和阈值M比较敏感,在参数调优时比较麻烦,因此本文对另一种基于密度的聚类算法OPTICS(Order ...
- 灵玖软件NLPIRParser智能文本聚类
随着互联网的迅猛发展,信息的爆炸式增加,信息超载问题变的越来越严重,信息的更新率也越来越高,用户在信息海洋里查找信息就像大海捞针一样.搜索引擎服务应运而生,在一定程度上满足了用户查找信息的需要.然而互 ...
- 10.HanLP实现k均值--文本聚类
笔记转载于GitHub项目:https://github.com/NLP-LOVE/Introduction-NLP 10. 文本聚类 正所谓物以类聚,人以群分.人们在获取数据时需要整理,将相似的数据 ...
- K-means算法及文本聚类实践
K-Means是常用的聚类算法,与其他聚类算法相比,其时间复杂度低,聚类的效果也还不错,这里简单介绍一下k-means算法,下图是一个手写体数据集聚类的结果. 基本思想 k-means算法需要事先指定 ...
- R语言做文本挖掘 Part4文本分类
Part4文本分类 Part3文本聚类提到过.与聚类分类的简单差异. 那么,我们需要理清训练集的分类,有明白分类的文本:測试集,能够就用训练集来替代.预測集,就是未分类的文本.是分类方法最后的应用实现 ...
- [python] 使用Jieba工具中文分词及文本聚类概念
声明:由于担心CSDN博客丢失,在博客园简单对其进行备份,以后两个地方都会写文章的~感谢CSDN和博客园提供的平台. 前面讲述了很多关于Python爬取本体Ontology.消息盒Inf ...
- pyhanlp 文本聚类详细介绍
文本聚类 文本聚类简单点的来说就是将文本视作一个样本,在其上面进行聚类操作.但是与我们机器学习中常用的聚类操作不同之处在于. 我们的聚类对象不是直接的文本本身,而是文本提取出来的特征.因此如何提取特征 ...
- [转]python进行中文文本聚类(切词以及Kmeans聚类)
简介 查看百度搜索中文文本聚类我失望的发现,网上竟然没有一个完整的关于Python实现的中文文本聚类(乃至搜索关键词python 中文文本聚类也是如此),网上大部分是关于文本聚类的Kmeans聚类的原 ...
随机推荐
- MVC使用StructureMap实现依赖注入Dependency Injection
使用StructureMap也可以实现在MVC中的依赖注入,为此,我们不仅要使用StructureMap注册各种接口及其实现,还需要自定义控制器工厂,借助StructureMap来生成controll ...
- MySql 数据库导入"Unknown command '\n'."错误解决办法
原文地址:http://www.cnblogs.com/bingxueme/archive/2012/05/15/2501999.html 在CMD 下 输入: Mysql -u root -p -- ...
- window消息机制二
消息机制 windows是一个消息驱动的系统,会有一个总的系统消息的队列,鼠标.键盘等等都会流入到这个队列中,同时会为每个线程维护一个消息队列(注意默认是有GUI调用的线程才有,对于没有GUI或者窗口 ...
- JSONString 与 JSONData 与字典或者数组互相转化
JSON JSON相关的,数据彼此间的转化进行了简单地封装,源码如下,支持arc与非arc YXJSON.h + YXJSON.m // // YXJSON.h // // JSONString 与 ...
- 【BZOJ】【2219】数论之神
中国剩余定理+原根+扩展欧几里得+BSGS 题解:http://blog.csdn.net/regina8023/article/details/44863519 新技能get√: LL Get_yu ...
- Objective-C:MRC手动释放对象内存举例(引用计数器)
手机内存下的类的设计练习: 设计Book类, 1.三个成员变量: title(书名)author(作者).price(价格) 2.不使用@property,自己完成存取方法(set方法,get方 ...
- C语言数字与字符串转换 atoi()函数、itoa()函数、sprintf()函数
在编程中经常需要用到数字与字符串的转换,下面就总结一下. 1.atoi() C/C++标准库函数,用于字符串到整数的转换. 函数原型:int atoi (const char * str); #inc ...
- go语言之进阶篇指针类型和普通类型的方法集
方法集 类型的方法集是指可以被该类型的值调用的所有方法的集合. 用实例实例 value 和 pointer 调用方法(含匿名字段)不受方法集约束,编译器编总是查找全部方法,并自动转换 receiver ...
- javascript基础知识梳理-Number与String之间的互相转换【转】
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- Android消息通知-Notification
Android中常用的消息提醒,一种是Toast弹出提醒内容,一种是AlterDialog弹出框来提醒用户,还有一种就是消息通知的,用Android经常收到各种通知就是Notifation.Notif ...