re模块,正则表达式起别名和分组机制,collections模块,time与datetime模块,random模块
re模块和正则表达式别名和分组机制
命名分组
(1)分组--可以让我们从文本内容中提取指定模式的部分内容,用()来表示要提取的分组,需要注意的是分组
是在整个文本符合指定的正则表达式前提下进行的进一步筛选。
(2)通过group()和groups()来获取分组的内容
group(num)返回的是第num组括号所匹配的值,group()即group(0),它表示匹配正则式的整个文本;
groups()以tuple形式(元组)返回所有括号匹配的值。
如下例:
m = re.match('^(\d{3})-(\d{3,8})','012-123456')
print(m.group())
print(m.groups())
这里我们定义了两个分组,一个用来匹配3位数字,一个用来匹配3-8位数字,执行group()和
groups()的结果如下:
012-123456
('012', '123456')
(3)分组命名
有时候我们需要匹配的分组描述可能十分复杂,这时我们可以通过给分组取名来让我们更方便地获
取分组。
分组命名的规则为:(?P<name>分组正则表达式)
string = "ip=130.192.168.23"
#为分组取别名ip
res = re.search(r"ip=(?P<ip>\d+\.\d+\.\d+\.\d+)", string)
print(res.group())
print(res.group('ip'))#通过命名分组引用分组
执行结果为:
ip=130.192.168.23
130.192.168.23
"""
findall默认是分组优先展示
正则表达式中如果有括号分组 那么在展示匹配结果的时候
默认只演示括号内正则表达式匹配到的内容!!!
也可以取消分组有限展示的机制
(?:) 括号前面加问号冒号
"""
'''针对search和match有几个分组 group方法括号内最大就可以写几'''
collections模块
模块简介
collections是Python内建的一个集合模块,提供了许多有用的集合类。该模块实现了专门的容器数据类
型,提供了Python的通用内置容器,dict,list,set和tuple的替代方法。
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类
型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1、namedtuple: 生成可以使用名字来访问元素内容的tuple(具名元组)
导入from collections import namedtuple
用法示例:tuple可以表示不变集合,例如,一个点的二维坐标就可以表示成:p(3,2)
但是,看到(3, 2),很难看出这个tuple是用来表示一个坐标的。
这时就可以用namedtuple来表示出更加详细的信息
from collections import namedtuple
1.先产生一个元组对象模板
point = namedtuple('坐标', ['x', 'y'])
p1 = point(3, 2)
p2 = point(1, 2)
print(p1, p2) # 坐标(x=3, y=2) 坐标(x=1, y=2)
print(p1.x) # 3
print(p2.y) # 2
info = namedtuple('信息', 'name age')
stud1 = info('张三', '18')
stud2 = info('李四', '18')
print(stud1, stud2) # 信息(name='张三', age='18') 信息(name='李四', age='18')
print(stud1.name) # 张三
print(stud2.age) # 18
"""具名元组的使用场景也非常的广泛 比如数学领域、娱乐领域等"""
card = namedtuple('扑克牌', ['花色', '点数'])
c1 = card('黑桃', 'A')
c2 = card('黑梅', 'K')
c3 = card('红心', 'A')
print(c1, c2, c3)
print(c1.点数)
2、deque: 双端队列,可以快速的从另外一侧追加和推出对象
用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大
的时候,插入和删除效率很低。
deque可以通过appendleft()和popleft()实现另一侧的插入和删除操作,更加高效,适合用于队列和
栈,
from collections import deque
q = deque([1, 2, 3, 4])
q.append(5) # 在后面追加
print(q) # deque([1, 2, 3, 4, 5])
q.appendleft(6) # 在前面追加
print(q) # deque([6, 1, 2, 3, 4, 5])
q.pop() # 弹出末尾的元素
print(q) # deque([6, 1, 2, 3, 4])
q.popleft() # 弹出开头的元素
print(q) # deque([1, 2, 3, 4])
print(q[1]) # 按索引取值 2
3、Counter: 计数器,主要用来计数
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元
素作为key,其计数作为value(可以认为Counter直接
生成一个Hash表,这一点在处理问题时经常用到)。
计数值可以是任意的Interger(包括0和负数)
from collections import Counter
txt = '1aa22331sddddsw44'
c = Counter(txt)#返回一个字典
print(c)
# Counter({'d': 4, '1': 2, 'a': 2, '2': 2, '3': 2, 's': 2, '4': 2, 'w': 1})
print(c['d']) # 按key取值 4
4、OrderedDict: 有序字典
使用dict时,Key是无序的。所以在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
from collections import OrderedDict
d = dict([('a', 1), ('b', 2), ('c', 3)])
print(d) # dict的Key是无序的{‘a’: 1, ‘c’: 3, ‘b’: 2}
od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
print(od) # OrderedDict的Key是有序的OrderedDict([(‘a’, 1), (‘b’, 2), (‘c’, 3)])
5、defaultdict: 带有默认值的字典
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,
就可以用defaultdict:
例一:
from collections import defaultdict
dd = defaultdict(lambda: 'N/A')
dd['k1'] = '1'
print(dd)
print(dd['k2']) # k2不存在,返回默认值’N/A’
执行结果:
defaultdict(<function <lambda> at 0x00CC3E38>, {'k1': '1'})
N/A
例二:
"""
有如下值集合 [11,22,33,44,55,67,77,88,99,999],
将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
"""
from collections import defaultdict
values = [11, 22, 33,44,55,67,77,88,99,90]
my_dict = defaultdict(list) # 字典所有的值默认都是列表 {'':[],'':[]}
for value in values:
if value>66:
my_dict['k1'].append(value)
else:
my_dict['k2'].append(value)
time模块和datetime模块
time模块
Python中有两个模块可以完成时间操作:time和datetime,其中time有这几种方式来表示时间:
1.时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我
们运行“type(time.time())”,返回的是float类型。
2.格式化的时间字符串(Format String)
3.结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,
秒,一年中第几周,一年中第几天,夏令时)
time模块的使用
import time
# 1、时间戳格式
print(time.time()) # 1648545357.8447278
# 2、 结构化时间
print(time.localtime()) # 本地时区的struct_time
print(time.gmtime()) # UTC时区的struct_time
'''
time.struct_time(tm_year=2022, tm_mon=3, tm_mday=29, tm_hour=17, tm_min=15, tm_sec=57, tm_wday=1, tm_yday=88, tm_isdst=0)
time.struct_time(tm_year=2022, tm_mon=3, tm_mday=29, tm_hour=9, tm_min=15, tm_sec=57, tm_wday=1, tm_yday=88, tm_isdst=0)
# 我们的时间是东八区和UTC标准时间相隔8个小时
'''
0 tm_year(年) 比如2011
1 tm_mon(月) 1 - 12
2 tm_mday(日) 1 - 31
3 tm_hour(时) 0 - 23
4 tm_min(分) 0 - 59
5 tm_sec(秒) 0 - 60
6 tm_wday(weekday) 0 - 6(0表示周一)
7 tm_yday(一年中的第几天) 1 - 366
8 tm_isdst(是否是夏令时) 默认为0
# 3、格式化时间
print(time.strftime('%Y-%m-%d %H:%M:%S')) #2022-03-29 17:15:57
'%Y-%m-%d %X' == '%Y-%m-%d %H:%M:%S'
python中时间日期格式化符号有:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
格式转换
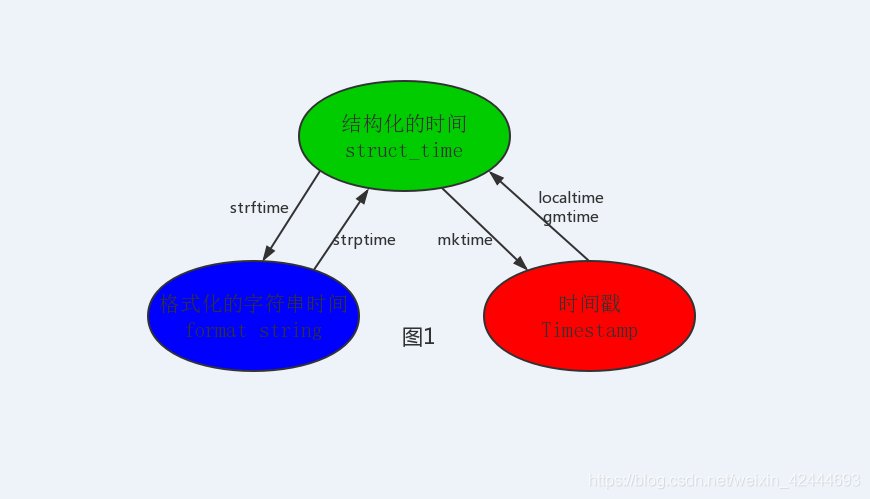
import time
# 1、时间戳和结构化时间相互转换
print(time.localtime(1582290777.6476405)) # 将时间戳转化为结构化时间
# time.struct_time(tm_year=2020, tm_mon=2, tm_mday=21, tm_hour=21, tm_min=12, tm_sec=57, tm_wday=4, tm_yday=52, tm_isdst=0)
print(time.mktime(time.localtime())) # mktime(t) : 将一个struct_time转化为时间戳。
# 1648545808.0
# 2、结构化时间和格式化时间相互转换
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) # 将结构化时间转化为格式化时间
# 2022-03-29 17:23:28
print(time.strptime('2020-02-21 21:19:43', '%Y-%m-%d %X')) # 将格式化时间转化为结构化时间
# time.struct_time(tm_year=2020, tm_mon=2, tm_mday=21, tm_hour=21, tm_min=19, tm_sec=43, tm_wday=4, tm_yday=52, tm_isdst=-1)
# time.strptime('string', [format]) 在这个函数中,format默认为:"%Y %m %d %H:%M:%S"。
datetime模块
和time相比,datetime的功能更强大,以下分别是两个模块的具体信息。
import time
import datetime
print(dir(time))
#['_STRUCT_TM_ITEMS', '__doc__', '__loader__', '__name__', '__package__', '__spec__',
# 'altzone', 'asctime', 'ctime', 'daylight', 'get_clock_info', 'gmtime', 'localtime',
# 'mktime', 'monotonic', 'monotonic_ns', 'perf_counter', 'perf_counter_ns',
# 'process_time', 'process_time_ns', 'sleep', 'strftime', 'strptime', 'struct_time',
# 'thread_time', 'thread_time_ns', 'time', 'time_ns', 'timezone', 'tzname']
print(dir(datetime.datetime))
#['__add__', '__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__',
# '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__',
# '__le__', '__lt__', '__ne__', '__new__', '__radd__', '__reduce__', '__reduce_ex__',
# '__repr__', '__rsub__', '__setattr__', '__sizeof__', '__str__', '__sub__',
# '__subclasshook__', 'astimezone', 'combine', 'ctime', 'date', 'day', 'dst', 'fold',
# 'fromisocalendar', 'fromisoformat', 'fromordinal', 'fromtimestamp', 'hour',
# 'isocalendar', 'isoformat', 'isoweekday', 'max', 'microsecond', 'min', 'minute',
# 'month', 'now', 'replace', 'resolution', 'second', 'strftime', 'strptime', 'time',
# 'timestamp', 'timetuple', 'timetz', 'today', 'toordinal', 'tzinfo', 'tzname',
# 'utcfromtimestamp', 'utcnow', 'utcoffset', 'utctimetuple', 'weekday', 'year']
print(datetime.datetime.now()) # 获取当前时间 2022-03-29 17:33:47.720877
print(datetime.date.fromtimestamp(time.time())) # 时间戳直接转成日期格式 2022-03-29
print(datetime.datetime.now() + datetime.timedelta(3)) # 当前时间+3天 2022-04-01 17:33:47.721875
print(datetime.datetime.now() - datetime.timedelta(3)) # 当前时间-3天 2022-03-26 17:33:47.721875
print(datetime.datetime.now() + datetime.timedelta(hours=3)) # 当前时间+3小时 2022-03-29 20:33:47.721875
print(datetime.datetime.now() + datetime.timedelta(minutes=30)) # 当前时间+30分 2022-03-29 18:03:47.721875
"""
针对时间计算的公式
日期对象 = 日期对象 +/- timedelta对象
timedelta对象 = 日期对象 +/- 日期对象
"""
random模块
一,随机浮点数
(1)random() --- 产生大于等于0且小于1的浮点数
ret = random.random()
print(ret)
0.698328408870422
(2)uniform(a,b) --- 产生指定范围的随机浮点数
ret = random.uniform(1, 4)
print(ret)
2.941859945496957
二,随机整数
(1)randint(a,b) --- 产生a,b范围内的整数,包含开头和结尾
ret = random.randint(1, 3)
print(ret)
1
(2)randrange(start,stop,[step]) --- 产生start,stop范围内的整数,包含开头不包含结尾,
step指定产生随机数的步长。
ret = random.randrange(1, 6, 2)
print(ret)
5
三,随机选择一个或多个数据
(1) random.choice(lst) --- 随机返回序列中的一个数据随机选择一个数据
lst = ['a', 'b', 'c']
ret = random.choice(lst)
print(ret)
b
(2) random.sample(list, num) -- 随机返回序列中的num个数据
lst = ['a', 'b', 'c', 'd', 'e']
ret = random.sample(lst,2)
print(ret)
['b', 'd']
四,随机打乱一个数据集合
randim.shuffle(list) -- 随机打乱一个数据集合
lst = ['a', 'b', 'c', 'd', 'e']
print(lst) # ['a', 'b', 'c', 'd', 'e']
random.shuffle(lst)
print(lst) # ['d', 'c', 'b', 'a', 'e']
今日作业
使用random模块编写一个能够产生随机验证码的代码
验证码可以是数字、小写字母、大写字母 任意组合
基本要求:产生固定位数的 比如四位
拔高要求:产生指定位数的 ...
eg:
要产生四位随机验
要产生五位随机验
证码 JkO98
import random
def verification_Code(numb):
code = ''
str = [1,2,3]
for i in range(numb):
chioce = random.choice(str)
if chioce == 1:
code = code + chr(random.choice(range(48,58)))
elif chioce == 2:
code = code + chr(random.choice(range(65, 91)))
else:
code = code + chr(random.choice(range(97, 122)))
else:
return code
print(verification_Code(5)) # 5l72l
re模块,正则表达式起别名和分组机制,collections模块,time与datetime模块,random模块的更多相关文章
- collections、time、datetime、random模块
今日内容概要 1.re模块的其他知识 2.正则起别名与分组机制 3.collections模块 4.time与datetime模块 5.random随机数模块 今日内容详细 re模块的其他知识 imp ...
- Python包,json&pickle,time&datetime,random模块
补充内容: 解决模块循环导入的两种方法:(不得已而为之,表示程序结构不够严谨) 将导入模块语句放在文件最下方 保证语句导入之前函数内代码能够被执行 将导入语句放进函数体内 使其不影响整个函数的运行 包 ...
- python基础--常用的模块(collections、time、datetime、random、os、sys、json、pickle)
collection模块: namedtuple:它是一个函数,是用来创建一个自定义的tuple对象的,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素.所以我们就可以 ...
- ZH奶酪:【Python】random模块
Python中的random模块用于随机数生成,对几个random模块中的函数进行简单介绍.如下:random.random() 用于生成一个0到1的随机浮点数.如: import random ra ...
- python-利用random模块生成测试数据封装方法总结
1.前言: 在测试中经常有需要用到参数化,我们可以用random模块,faker模块生成测试数据,也可以用到pymysql,此文主要针对random模块生成任意个数的随机整数,随机字符串,随机手机号, ...
- python-Day5-深入正则表达式--冒泡排序-时间复杂度 --常用模块学习:自定义模块--random模块:随机验证码--time & datetime模块
正则表达式 语法: mport re #导入模块名 p = re.compile("^[0-9]") #生成要匹配的正则对象 , ^代表从开头匹配,[0 ...
- s14 第5天 时间模块 随机模块 String模块 shutil模块(文件操作) 文件压缩(zipfile和tarfile)shelve模块 XML模块 ConfigParser配置文件操作模块 hashlib散列模块 Subprocess模块(调用shell) logging模块 正则表达式模块 r字符串和转译
时间模块 time datatime time.clock(2.7) time.process_time(3.3) 测量处理器运算时间,不包括sleep时间 time.altzone 返回与UTC时间 ...
- Python中的re模块--正则表达式
Python中的re模块--正则表达式 使用match从字符串开头匹配 以匹配国内手机号为例,通常手机号为11位,以1开头.大概是这样13509094747,(这个号码是我随便写的,请不要拨打),我们 ...
- Day 19 re 模块 random模块,正则表达式
https://www.cnblogs.com/Eva-J/p/7228075.html#_label10 findall search match方法 和 search相比 match自带 ^ se ...
随机推荐
- 学习openstack(八)
一.OpenStack初探 1.1 OpenStack简介 OpenStack是一整套开源软件项目的综合,它允许企业或服务提供者建立.运行自己的云计算和存储设施.Rackspace与NASA是最初 ...
- 图灵机器人 V1 和 V2 接入方法
API1.0使用方法: import requests import json import yuyinhecheng as hc def Tuling(words): Tuling_API_ ...
- yum下载安装mysql服务
1.下载mysql源码 wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm 2.安装mysql源 yum ...
- 【HTML5版】导出Table数据并保存为Excel
首发我的博客 http://blog.meathill.com/tech/js/export-table-data-into-a-excel-file.html 最近接到这么个需求,要把<tab ...
- 报错需要选择一个空目录,或者选择的非空目录下存在 app.json 或者 project.config.json解决方案
前言 小程序的第一个坑就是,创建了一个小程序项目,却在微信web开发者工具无法打开... 报了个错:需要选择一个空目录,或者选择的非空目录下存在 app.json 或者 project.config. ...
- SVG vs Image, SVG vs Iconfont
这可能是个别人写过很多次的话题,但貌似由于兼容性的原因?图标的显示还是用着 Iconfont 或者 CSS Sprite 的形式?希望通过自己新瓶装旧酒的方式能重新引导一下问题. SVG vs Ima ...
- 【Android开发】通过 style 设置状态栏,导航栏等的颜色
<style name="test"> <!--状态栏颜色--> <item name="colorPrimaryDark"> ...
- 给一个非矩形数组(Nonrectangular Arrays)
Nonrectangular Arrays(非矩形数组) public class Test { public static void main(String[] args) { ...
- Qt 实现配置 OpenCV 环境,并实现打开图片与调用摄像头
一.说明 所用QT版本:5.9.1 电脑配置:win10,64位系统 调用的是编译好的:OpenCV-MinGW-Build-4.1.0(稍后放链接) 在大学期间,由于项目需求需要用到QT+openc ...
- linux centos 8.2 安装docker
1 使用yum -y install docker安装后启动docker提示Failed to start docker.service: Unit docker.service not found. ...