一致性Hash的原理与实现
应用场景
在了解一致性Hash之前,我们先了解一下一致性Hash适用于什么场景,能解决什么问题?这里先放一下我自己认为适用的场景。一致性Hash适用于服务器动态扩展且需要负载均衡的场景
试想以下场景,某一天,公司的业务不断发展壮大,现有的数据库服务器无法支撑那么大的数据量,我们该怎么办呢?我们会想到把用户请求分散,对数据库服务器做集群,把用户请求分别路由到不同的数据库服务器上, 但是这样会带来一个问题,我们如何精确的知道某一个用户请求的数据在哪一台具体服务器上呢?
解决方案
方案一
A同学讲,用户发来一个请求,对所有的数据库服务器做查询,如果能查询到结果,就返回,否则就是没有。这样是可行,但是这样做的话,一个请求同样会请求N台数据库服务器,我们做数据库集群也就没有意义了,所以是不可取的。
方案二
B同学讲,我们可以根据请求的数据参数做Hash运算,然后利用Hash值对数据库服务器的个数求余,这样就能知道用户的数据在哪一台服务器上了,然后在做具体的操作就可以了。
显然,B同学的思路很正确,但是我们还要考虑一些其他的问题(动态扩展性),假如某一时刻用户请求量非常大,导致其中的某一台数据库服务器宕机了,这样Hash值对数据库服务器的数量求余结果明显就是不正确的了。或者某一天,我们需要对增加该集群服务器的数量,结果也是不正确的,就需要对所有的数据做迁移。
方案三
C同学则是在B同学的基础上,考虑到我们是不是可能把所有的服务器节点放到一个足够大的环上,如图一,当请求到达之后,我们仅仅找到该节点之后的一个节点。req1会到Node1上,req2会到Node2上,req3会到Node3上。假如Node3下线了,那么所有路由到Node3的请求req3都会到Node1上,这样只会有原来请求Node3请求会受到影响,而其他的节点并不会因此受到影响。
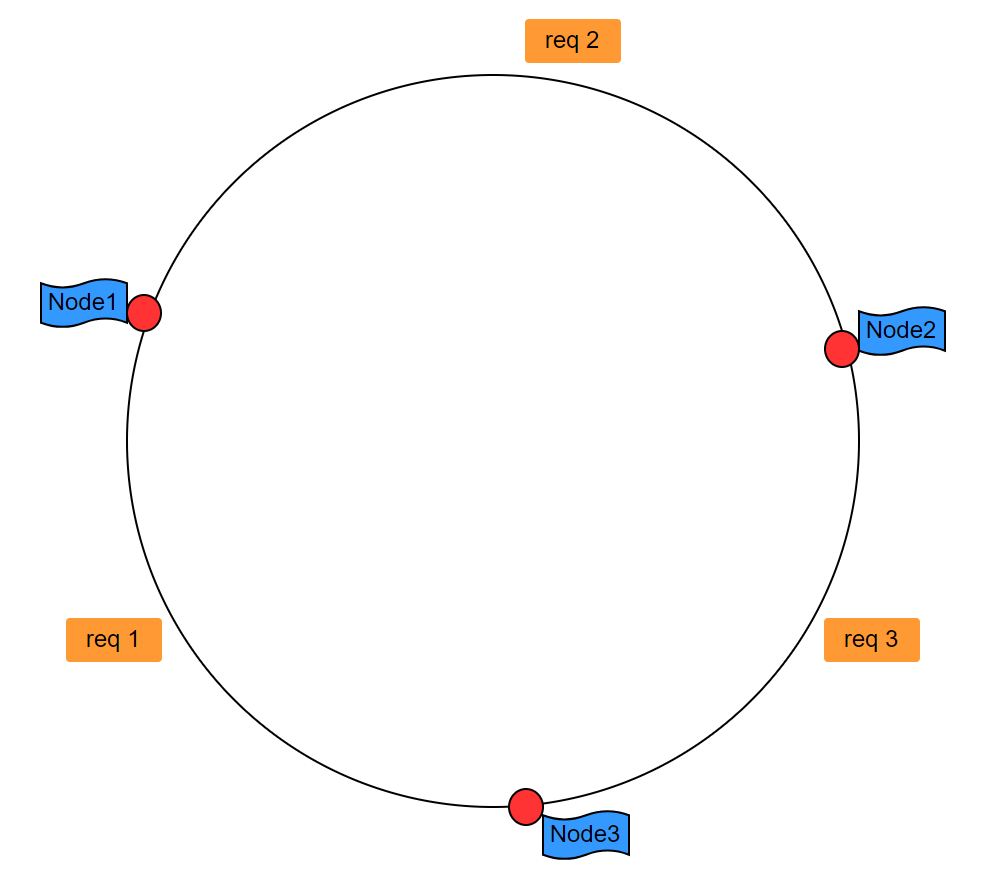
图一
那么假设我们要增加一个节点呢?我们希望的情况肯定是下面这样,如图二,但是事实往往不是这样,事实往往是如图三这样的,这就是Hash环的偏斜问题。这样就会导致的Node3的请求量要等比其他三台服务器请求量之和还要大,严重的负载不均衡,那么我们该如何解决这样问题呢?我们可以利用虚拟节点的概念,也就是每一个节点在这一个环上可以表现为多个节点,但是真正处理请求的还是这一个节点。比如图四那样,但是这样并不能做到真正意义上的完全平衡,只能说尽量平均分不到不同的节点上,而虚拟节点的数量越多,平衡的概率就越大。
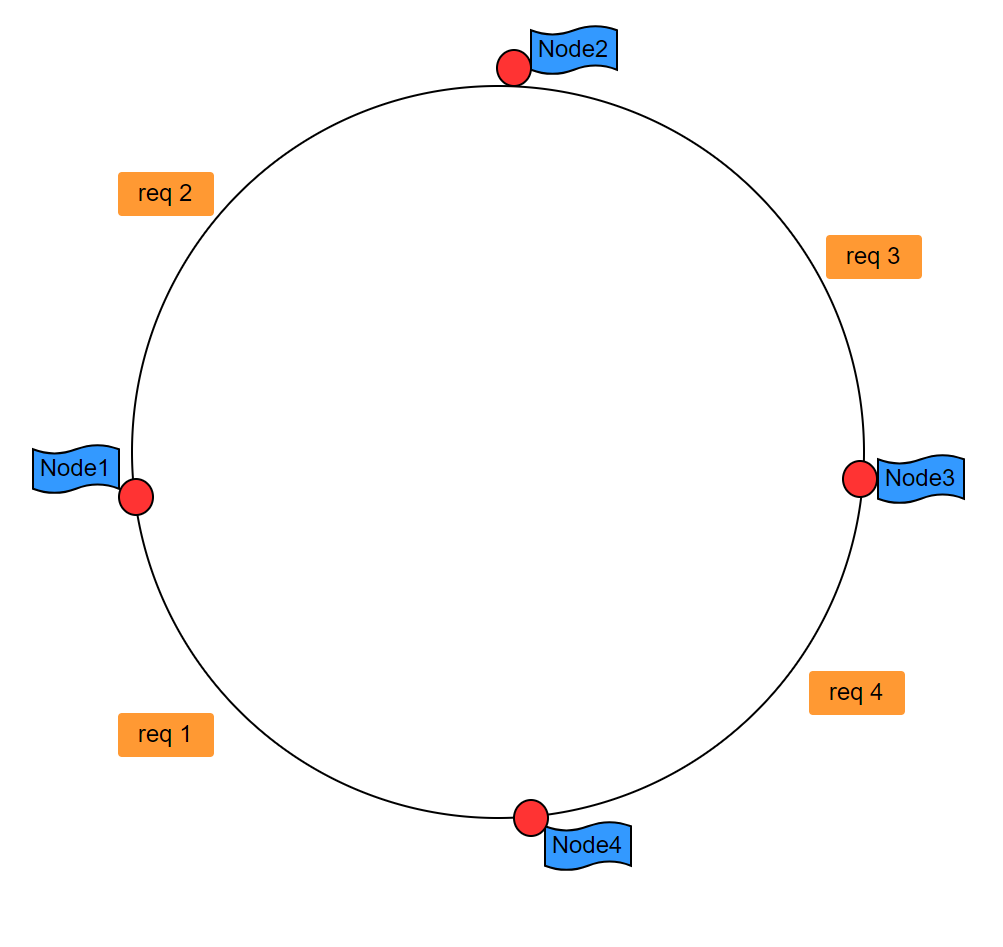
图二

图三

图四
性质
上面我们已经说了一致性Hash的应用场景以及它可以解决什么问题,下面我们就来总结一下一致性Hash性质,原理。
分布式系统每个节点都有可能失效,并且很可能会有新的节点增加进来,那么如何保证当系统的节点数目发生变化时仍然能够对外提供良好的服务,这是分布式系统需要考虑的一个重点问题。在分布式系统的设计时,我们就必须要考虑动态性扩展的问题,这样才不至于某一台服务宕机会影响整个系统。如果不采用合适的算法来保证一致性,那么系统中的所有数据都可能会失效,因此一致性hash算法就显得尤为重要。一般情况下一致性Hash要满足以下几个性质。这里可以参考https://brpc.apache.org/docs/rpc-in-depth/consistent-hashing/
平衡性 (Balance) : 每个节点被选到的概率是O(1/n)。
单调性 (Monotonicity) : 当新节点加入时, 不会有请求在老节点间移动, 只会从老节点移动到新节点。当有节点被删除时,也不会影响落在别的节点上的请求。
分散性 (Spread) : 当上游的机器看到不同的下游列表时(在上线时及不稳定的网络中比较常见), 同一个请求尽量映射到少量的节点中。
负载 (Load) : 当上游的机器看到不同的下游列表的时候, 保证每台下游分到的请求数量尽量一致。
实现(golang)
数据准备工作,定义数据结构,PhysicalNode包括IP,端口和节点名称
type UInt32Slice []uint32
func (s UInt32Slice) Len() int {
return len(s)
}
func (s UInt32Slice) Less(i, j int) bool {
return s[i] < s[j]
}
func (s UInt32Slice) Swap(i, j int) {
s[i], s[j] = s[j], s[i]
}
type PhysicalNode struct {
ip string
port int
name string
}
type PhysicalNodes struct {
nodeMap map[uint32]PhysicalNode //key 节点的Hash值 value节点的信息
nodeList UInt32Slice //排序之后的节点的Hash值数据,方便用于二分搜索
virtualNums int //虚拟节点数目
lock sync.Mutex //删除节点时需要用的锁
}
工具类:哈希值的计算,这里采用网上用的较多的Hash算法,具体可百度
package utils
const p uint32 = 16777619
func Hash(key string) uint32 {
var hash uint32 = 2166136261
num := len(key)
for idx := 0; idx < num; idx++ {
hash = (hash ^ uint32(key[idx])) * p
}
hash += hash << 13
hash ^= hash >> 7
hash += hash << 3
hash ^= hash >> 17
hash += hash << 5
if hash < 0 {
return -hash
}
return hash
}
获取节点的Hash值
func getNodeHash(node PhysicalNode, i int) uint32 {
hash := utils.Hash(node.ip + strconv.Itoa(node.port) + node.name + "@@" + strconv.Itoa(i))
return hash
}
添加节点
func (receiver *PhysicalNodes) AddPhysicalNodes(nodes ...PhysicalNode) {
for _, node := range nodes {
for i := 0; i < receiver.virtualNums; i++ {
hash := getNodeHash(node, i)
receiver.nodeList = append(receiver.nodeList, hash)
receiver.nodeMap[hash] = node
}
}
sort.Sort(receiver.nodeList)
}
删除节点
func (receiver *PhysicalNodes) DeletePhysicalNodes(nodes ...PhysicalNode) {
willDelNodeSet := make(map[uint32]bool)
for _, node := range nodes {
for i := 0; i < receiver.virtualNums; i++ {
hash := getNodeHash(node, i)
willDelNodeSet[hash] = true
delete(receiver.nodeMap, hash)
}
}
//copyOnWrite
receiver.lock.Lock()
newNodeList := make([]uint32, 0)
for _, v := range receiver.nodeList {
if !willDelNodeSet[v] {
newNodeList = append(newNodeList, v)
}
}
receiver.nodeList = newNodeList
receiver.lock.Unlock()
sort.Sort(receiver.nodeList)
}
获取节点(采用二分查找)
func (receiver *PhysicalNodes) GetPhysicalNode(key string) PhysicalNode {
hash := utils.Hash(key)
idx := sort.Search(len(receiver.nodeList), func(i int) bool {
return receiver.nodeList[i] >= hash
})
if idx == len(receiver.nodeList) {
idx = 0
}
return receiver.nodeMap[receiver.nodeList[idx]]
}
测试(这里仅仅给出单线程测试版)
const total = 100000000
func TestConsistentHashSingleRoutineOne(t *testing.T) {
physicalNodes := NewPhysicalNodes(100)
for i := 0; i < 5; i++ {
node := PhysicalNode{"10.22.35.6" + strconv.Itoa(i), 8080 + i, "node" + strconv.Itoa(i)}
physicalNodes.AddPhysicalNodes(node)
}
str := "abcfkdhgbofdsphgoqrenvdfajboiergfrjm8ioydctrbcc5fi0-2u24ich20945ch209hc2cj-24rjc2-j4-5j224ic29h4fsg6yfdhgfk"
n := len(str)
statistics := make(map[string]int)
for i := 0; i < total; i++ {
end := 0
for end == 0 {
end = rand.Intn(n)
}
start := rand.Intn(end)
//start := 0
//end := i % n
node := physicalNodes.GetPhysicalNode(str[start:end])
statistics[node.name]++
}
for s, i := range statistics {
fmt.Printf("节点%s出现了%d次,rate:%.2f%%\n", s, i, float32(i)/float32(total)*100)
}
}
测试结果(上面的测试代码写的不是特别的严谨,仅仅是做一下大概的请求分布测试)
节点node3出现了17760919次,rate:17.76%
节点node4出现了20222723次,rate:20.22%
节点node0出现了22199979次,rate:22.20%
节点node1出现了19649432次,rate:19.65%
节点node2出现了20166947次,rate:20.17%
总结
虽说一致性Hash的原理和算法有很多框架都有自己的实现,但是那终究不是我们的,只有我们自己掌握了他们的原理并加以练习,成为我们自己的一部分,这样才能融入我们自己的知识体系中。
参考引用:https://brpc.apache.org/docs/rpc-in-depth/consistent-hashing/
完整代码地址:https://gitee.com/philosoxhy/leetcode/tree/master/code/hash
一致性Hash的原理与实现的更多相关文章
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- 分布式缓存技术memcached学习系列(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到"分布式一致性hash算法"这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前, ...
- 一致性Hash算法原理及C#代码实现
一.一致性Hash算法原理 基本概念 一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希空间环如下: 整个空间按顺 ...
- 给面试官讲明白:一致性Hash的原理和实践
"一致性hash的设计初衷是解决分布式缓存问题,它不仅能起到hash作用,还可以在服务器宕机时,尽量少地迁移数据.因此被广泛用于状态服务的路由功能" 01分布式系统的路由算法 假设 ...
- 一致性Hash算法原理,java实现,及用途
学习记录: 一致性Hash算法原理及java实现:https://blog.csdn.net/suifeng629/article/details/81567777 一致性Hash算法介绍,原理,及使 ...
- 一文搞懂一致性hash的原理和实现
在 go-zero 的分布式缓存系统分享里,Kevin 重点讲到过一致性hash的原理和分布式缓存中的实践.本文来详细讲讲一致性hash的原理和在 go-zero 中的实现. 以存储为例,在整个微服务 ...
- 分方式缓存常用的一致性hash是什么原理
分方式缓存常用的一致性hash是什么原理 一致性hash是用来解决什么问题的?先看一个场景有n个cache服务器,一个对象object映射到哪个cache上呢?可以采用通用方法计算object的has ...
- 一致性Hash算法的原理与实现(分布式映射算法)
一致性Hash算法解决的问题: 解决分布式系统中的负载均衡问题 背景问题:有N台服务器提供缓存服务,需要对服务器进行负载均衡,将请求平均发到每台服务器上,每台服务器负载1/N的服务 硬Hash映射:将 ...
- Hash哈希(二)一致性Hash(C++实现)
一致性Hash 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,经常用于分布式.负载均衡等. 原理 一致哈希是 ...
随机推荐
- angularJs 指令的用法
<!DOCTYPE html><html ng-app='app'><!--A attribute属性:当做属性来使用<div xingoo></div ...
- java-Dos
打开CMD的方式 1.菜单打开 2.Windows+R 输入cmd 3.shift+鼠标右键 选择在此处打开命令行窗口 4.资源管理器地址栏前+cmd 空格 管理员身份运行 常用的Dos命令 #盘符切 ...
- ElasticSearch7.3学习(十五)----中文分词器(IK Analyzer)及自定义词库
1. 中文分词器 1.1 默认分词器 先来看看ElasticSearch中默认的standard 分词器,对英文比较友好,但是对于中文来说就是按照字符拆分,不是那么友好. GET /_analyze ...
- dev编译器兼容设置及字符串的识别问题
#include<bits/stdc++.h> using namespace std; bool cmp(char a,char b) { return a>b; } //int ...
- 运行 Spring Boot 有哪几种方式?
打包用命令或者放到容器中运行用 Maven/ Gradle 插件运行直接执行 main 方法运行
- 面试问题之C++语言:mutable关键字
转载于:https://www.cnblogs.com/xkfz007/articles/2419540.html mutable关键字 mutable的中文意思是"可变的,易变的" ...
- 一个 Spring Bean 定义 包含什么?
一个Spring Bean 的定义包含容器必知的所有配置元数据,包括如何创建一个bean,它的生命周期详情及它的依赖.
- spring-boot-learning 缓存之redis
什么是BSD协议: BSD是"Berkeley Software Distribution"的缩写,意思是"伯克利软件发行版". BSD开源协议是一个给于使用者 ...
- 面试问题之C++语言:如何避免内存泄漏?
转载于:https://www.php.cn/csharp-article-416104.html 1.不要手动管理内存,可以尝试在适用的情况下使用智能指针. 2.使用string而不是char*.s ...
- Spring的@Enable*注解的工作原理
转自:https://blog.csdn.net/chengqiuming/article/details/81586948 一 列举几个@Enable*注解的功能 @EnableAspectJAut ...