MindStudio模型训练场景精度比对全流程和结果分析
摘要:MindStudio是一套基于华为昇腾AI处理器开发的AI全栈开发平台
本文分享自华为云社区《MindStudio模型训练场景精度比对全流程和结果分析》,作者:yd_247302088 。
一、基于MindStudio模型精度比对介绍
1.1 MindStudio介绍
MindStudio是一套基于华为昇腾AI处理器开发的AI全栈开发平台,包括基于芯片的算子开发、以及自定义算子开发,同时还包括网络层的网络移植、优化和分析,另外在业务引擎层提供了可视化的AI引擎拖拽式编程服务,极大的降低了AI引擎的开发门槛。MindStudio工具中的功能框架如图1所示:

图1 MindStudio功能框架
MindStudio工具中的主要几个功能特性如下:
- 工程管理:为开发人员提供创建工程、打开工程、关闭工程、删除工程、新增工程文件目录和属性设置等功能。
- SSH管理:为开发人员提供新增SSH连接、删除SSH连接、修改SSH连接、加密SSH密码和修改SSH密码保存方式等功能。
- 应用开发:针对业务流程开发人员,MindStudio工具提供基于AscendCL(Ascend Computing Language)和集成MindX SDK的应用开发编程方式,编程后的编译、运行、结果显示等一站式服务让流程开发更加智能化,可以让开发者快速上手。
- 自定义算子开发:提供了基于TBE和AI CPU的算子编程开发的集成开发环境,让不同平台下的算子移植更加便捷,适配昇腾AI处理器的速度更快。
- 离线模型转换:训练好的第三方网络模型可以直接通过离线模型工具导入并转换成离线模型,并可一键式自动生成模型接口,方便开发者基于模型接口进行编程,同时也提供了离线模型的可视化功能。
- 日志管理:MindStudio为昇腾AI处理器提供了覆盖全系统的日志收集与日志分析解决方案,提升运行时算法问题的定位效率。提供了统一形式的跨平台日志可视化分析能力及运行时诊断能力,提升日志分析系统的易用性。
- 性能分析:MindStudio以图形界面呈现方式,实现针对主机和设备上多节点、多模块异构体系的高效、易用、可灵活扩展的系统化性能分析,以及针对昇腾AI处理器的性能和功耗的同步分析,满足算法优化对系统性能分析的需求。
- 设备管理:MindStudio提供设备管理工具,实现对连接到主机上的设备的管理功能。
- 精度比对:可以用来比对自有模型算子的运算结果与Caffe、TensorFlow、ONNX标准算子的运算结果,以便用来确认神经网络运算误差发生的原因。
- 开发工具包的安装与管理:为开发者提供基于昇腾AI处理器的相关算法开发套件包Ascend-cann-toolkit,旨在帮助开发者进行快速、高效的人工智能算法开发。开发者可以将开发套件包安装到MindStudio上,使用MindStudio进行快速开发。Ascend-cann-toolkit包含了基于昇腾AI处理器开发依赖的头文件和库文件、编译工具链、调优工具等。
1.2 精度比对介绍
自有实现的算子在昇腾AI处理器上的运算结果与业界标准算子(如Caffe、ONNX、TensorFlow、PyTorch)的运算结果可能存在差异:
- 在模型转换过程中对模型进行了优化,包括算子消除、算子融合、算子拆分,这些动作可能会造成自有实现的算子运算结果与业界标准算子(如Caffe、TensorFlow、ONNX)运算结果存在偏差。
- 用户原始网络可以迁移到昇腾910 AI处理器上执行训练,网络迁移可能会造成自有实现的算子运算结果与用业界标准算子(如TensorFlow、PyTorch)运算结果存在偏差。
为了帮助开发人员快速解决算子精度问题,需要提供比对自有实现的算子运算结果与业界标准算子运算结果之间差距的工具。精度比对工具提供Vector比对能力,包含余弦相似度、最大绝对误差、累积相对误差、欧氏相对距离、KL散度、标准差、平均绝对误差、均方根误差、最大相对误差、平均相对误差的算法比对维度。
二、环境准备
在进行实验之前需要配置好远端Linux服务器并下载安装MindStudio。
首先在Linux服务器上安装部署好Ascend-cann-toolkit开发套件包、Ascend-cann-tfplugin框架插件包和TensorFlow 1.15.0深度学习框架。之后在Windows上安装MindStudio,安装完成后通过配置远程连接的方式建立MindStudio所在的Windows服务器与Ascend-cann-toolkit开发套件包所在的Linux服务器的连接,实现全流程开发功能。
接下来配置环境变量,以运行用户登录服务器,在任意目录下执行vi ~/.bashrc命令,打开.bashrc文件,在文件最后一行后面添加以下内容(以非root用户的默认安装路径为例)。

然后执行:wq!命令保存文件并退出。
最后执行source ~/.bashrc命令使其立即生效。
关于MindStudio的具体安装流程可以参考Windows安装MindStudio(点我跳转),MindStudio环境搭建指导视频(点我跳转)。MindStudio官方下载地址:点我跳转。
本文教程基于MindStudio5.0.RC2 x64,CANN版本5.1.RC2实现。
三、准备基于GPU运行生成的原始训练网络npy数据文件
3.1 获取项目代码
本样例选择resnet50模型,利用git克隆代码(git clone -b r1.13.0 https://github.com/tensorflow/models.git),下载成功后如下图所示:

3.2 生成数据前处理
数据比对前,需要先检查并去除训练脚本内部使用到的随机处理,避免由于输入数据不一致导致数据比对结果不可用。
编辑resnet_run_loop.py文件,修改如下(以下行数仅为示例,请以实际为准):
注释掉第83、85行
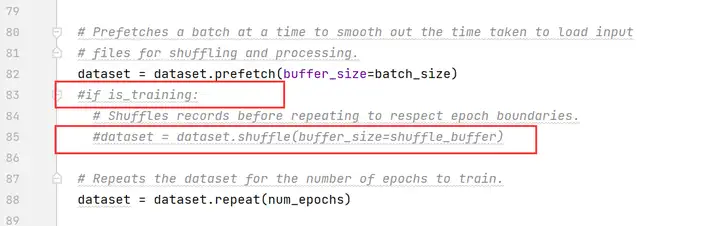
注释掉第587~594行

第607行,修改为“return None”
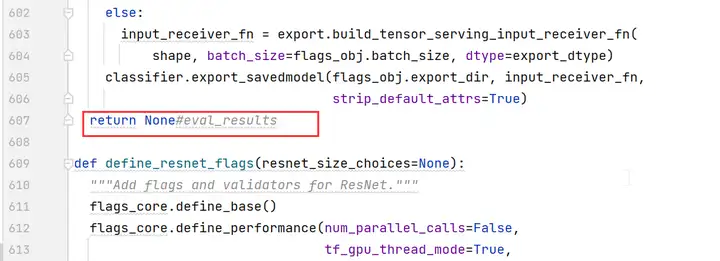
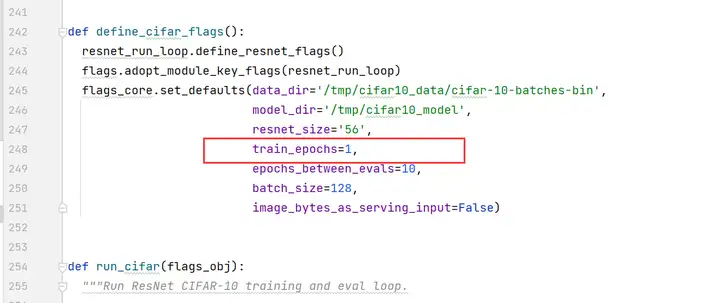
编辑cifar10_main.py文件,将train_epochs的值改为1。
3.3 生成npy文件
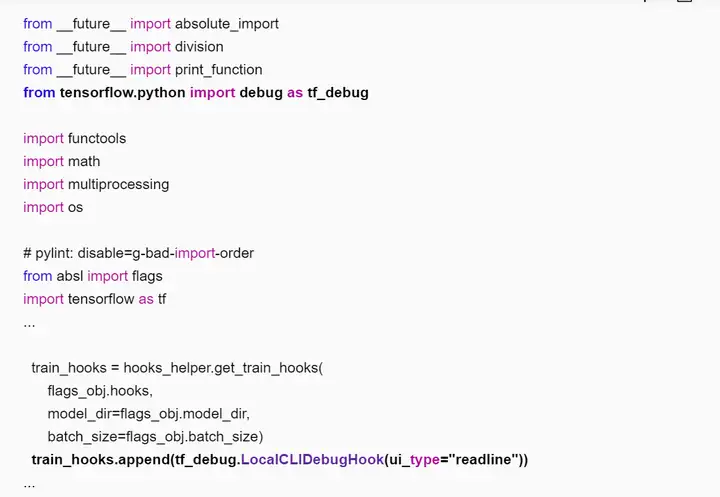
进入训练脚本所在目录(如“~/models/official/resnet”),修改训练脚本,添加tfdbg的hook。编辑resnet_run_loop.py文件,添加如下加粗字体的信息。
配置环境变量

执行训练脚本

训练任务停止后,在命令行输入run,训练会往下执行一个step。
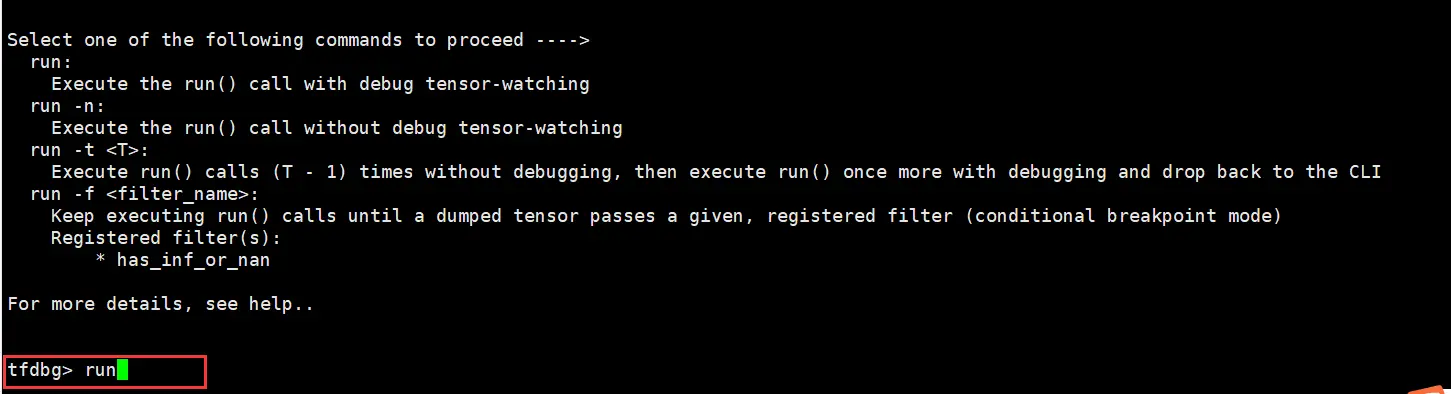
执行lt>gpu_dump命令将所有tensor的名称暂存到自定义名称的gpu_dump文件里。命令行中会有如下回显。

另外开启一个终端,在linux命令行下进入gpu_dump文件所在目录,执行下述命令,用以生成在tfdbg命令行执行的命令。
timestamp=$[$(date +%s%N)/1000] ; cat gpu_dump | awk '{print "pt",$4,$4}' | awk '{gsub("/", "_", $3);gsub(":", ".", $3);print($1,$2,"-n 0 -w "$3".""'$timestamp'"".npy")}'>dump.txt
将上一步生成的dump.txt文件中所有tensor存储的命令复制(所有以“pt”开头的命令),然后回到tfdbg命令行(刚才执行训练脚本的控制台)粘贴执行,即可存储所有的npy文件,存储路径为训练脚本所在目录。

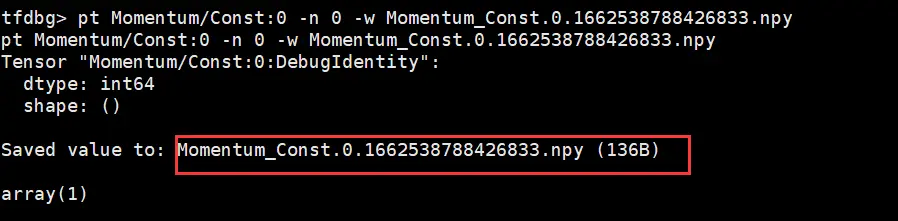
退出tfdbg命令行,将生成的npy文件保存到tf_resnet50_gpu_dump_data(用户可自定义)目录下。

四、准备基于NPU运行生成的训练网络dump数据和计算图文件
4.1 分析迁移
单击菜单栏“File > New > Project...”弹出“New Project”窗口。
在New Project窗口中,选择Ascend Training。输入项目的名称、CANN远程地址以及本地地址。点击Change配置CANN,如下图所示:
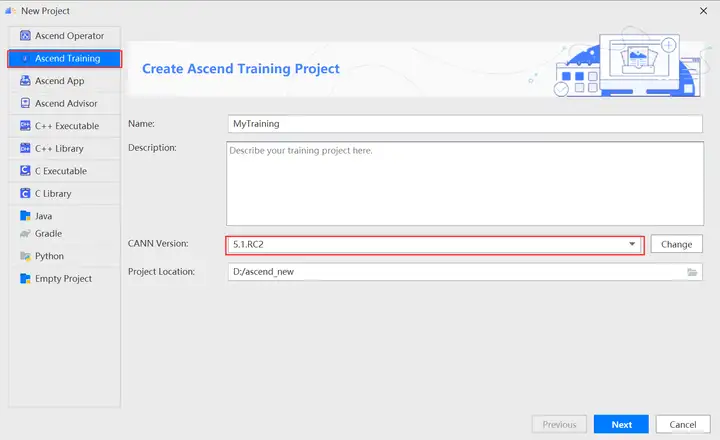
- Name:工程名称,可自定义。
- Description:工程描述,可按需补充关于工程的详细信息。
- CANN Version:CANN软件包版本,如未识别或想要更换使用的版本,可单击“Change”,在弹出界面中选择Ascend-cann-toolkit开发套件包的安装路径(注意需选择到版本号一级)。
- Project Location:工程目录,默认在“$HOME/AscendProjects”下创建。
点击右侧 + 进行配置远程服务器,如下图所示:

在出现的信息配置框输入相关配置信息,如下图所示:
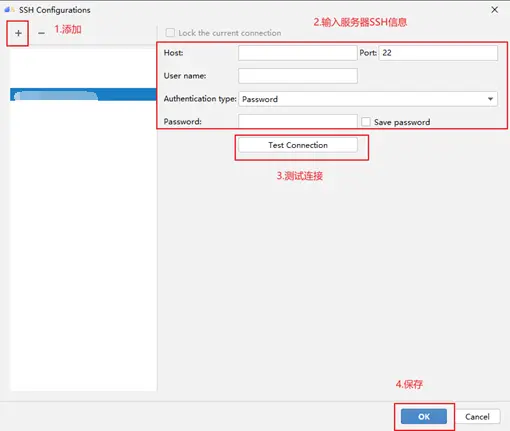
输入服务器的SSH信息,如果测试连接失败,建议使用CMD或XShell等工具进行排查。
选择远程 CANN 安装位置,如下图所示:
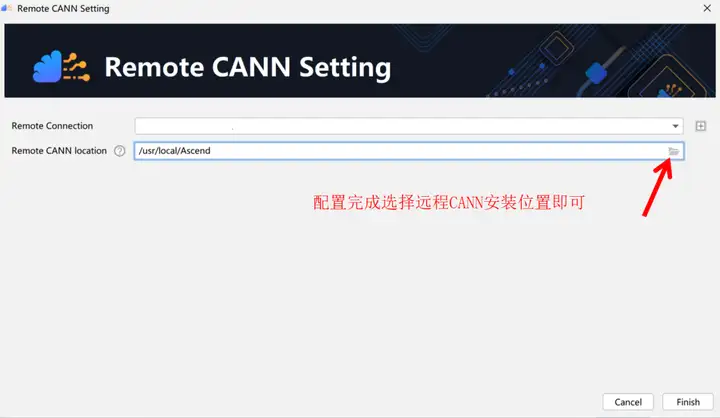
在Remote CANN location中选择CANN的路径,需要注意的是必须选择到CANN的版本号目录,这里选择的是5.1.RC2版本,如下图所示:
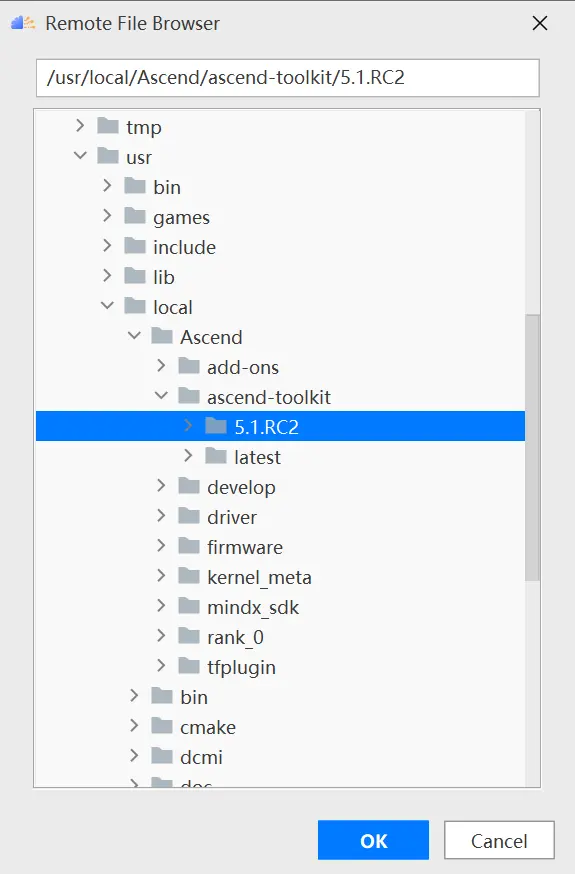
点击确定后,需要等待MindStudio进行文件同步操作,这个过程会持续数分钟,期间如果遇到Sync remote CANN files error.错误,考虑是否无服务器root权限。

配置完成CANN点击下一步
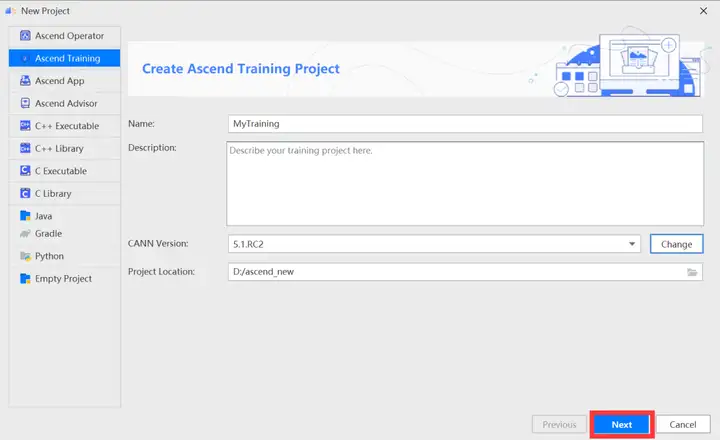
在训练工程选择界面,选择“TensorFlow Project”,单击“Finish”。
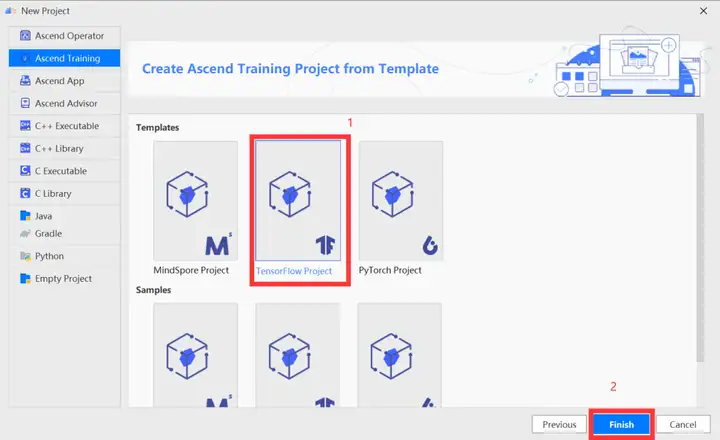
进入工程界面,单击工具栏中

按钮( TensorFlow GPU2Ascend工具)。
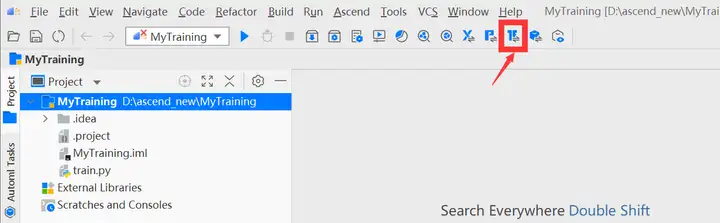
进入“TensorFlow GPU2Ascend”参数配置页,配置command file
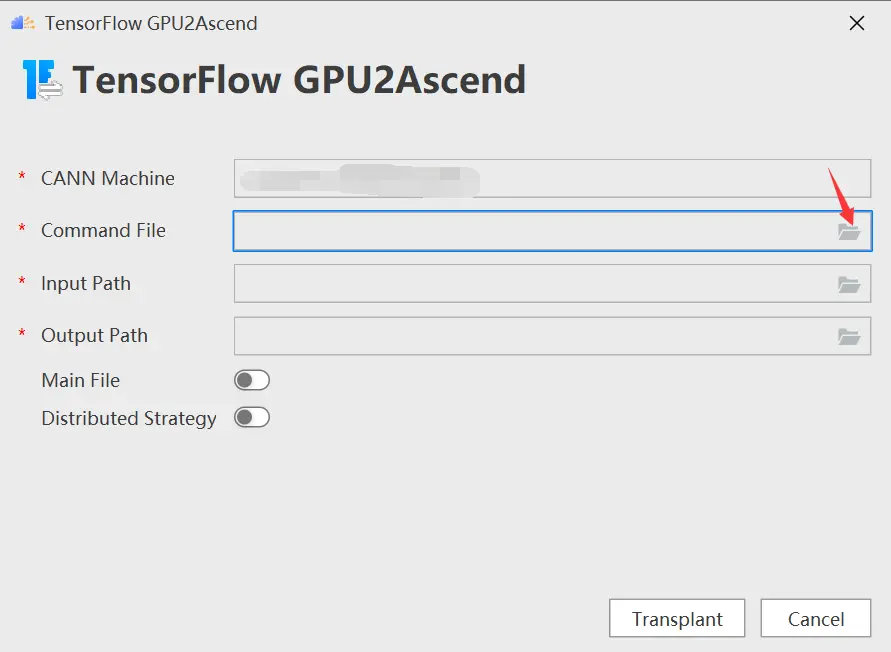
- Command File:tfplugin插件包中的工具脚本文件。
- Input Path:待转换脚本文件的路径。
- Output Path:脚本转换后的输出路径。
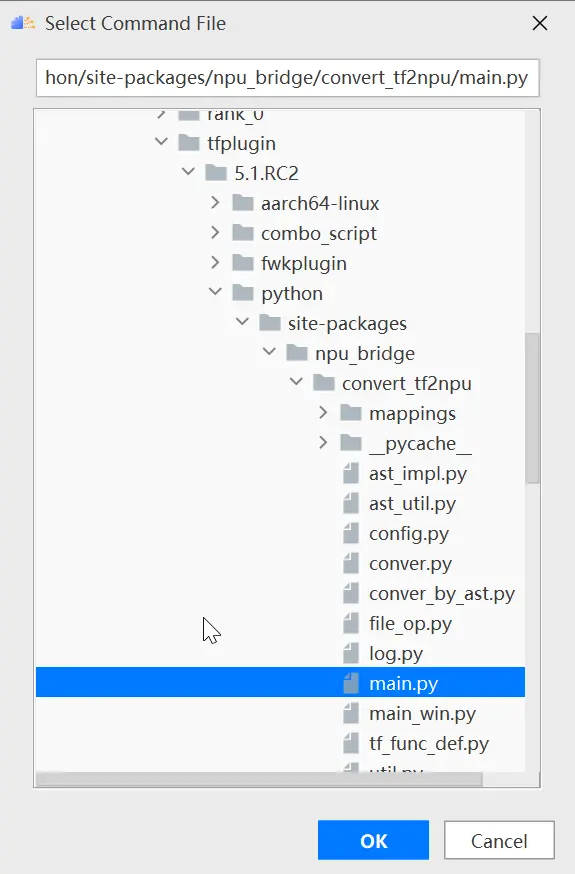
根据tfplugin文件所在路径选择/Ascend/tfplugin/5.1.RC2/python/site-packages/npu_bridge/convert_tf2npu/main.py,如下图所示
同样的,选择下载的代码路径作为input path,并选择输出路径,如下图所示:
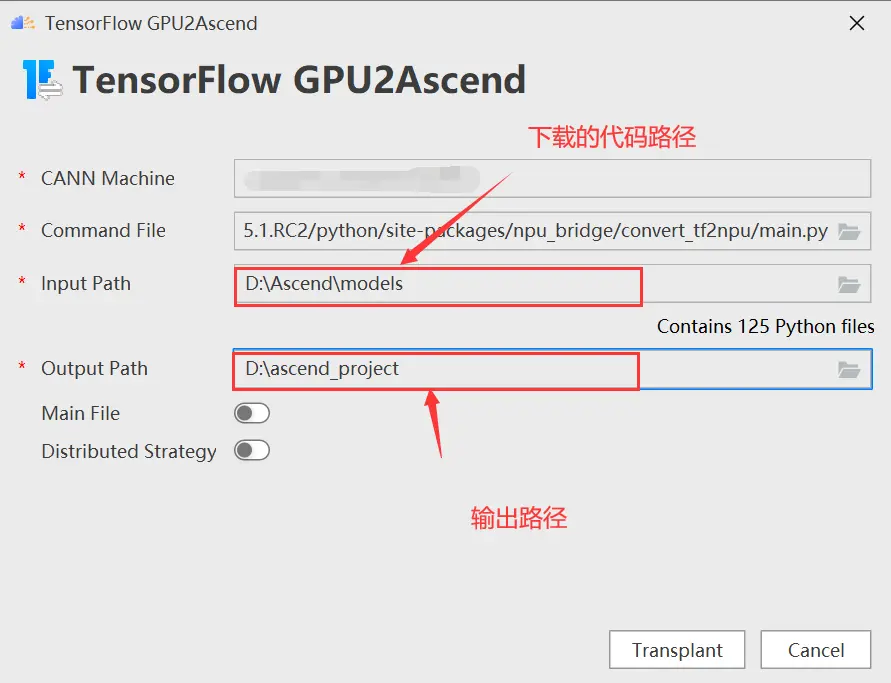
点击Transplant进行转换,如下图所示:
出现“Transplant success!”的回显信息,即转换成功。如下图所示:

4.2 生成dump数据和计算图文件
步骤一 dump前准备。
编辑resnet_run_loop.py文件,修改如下(以下行数仅为示例,请以实际为准):
注释掉第83、85行
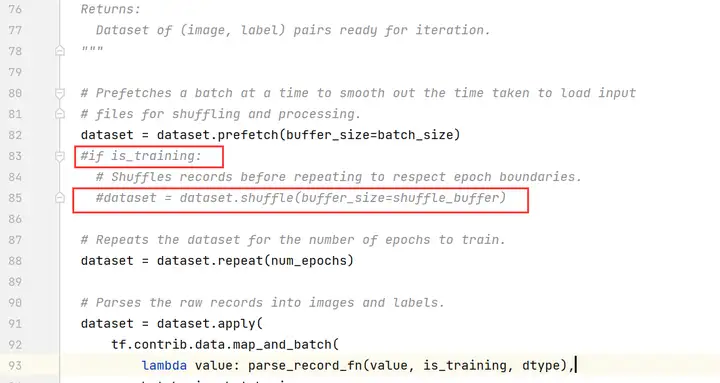
把max_steps设置为1。
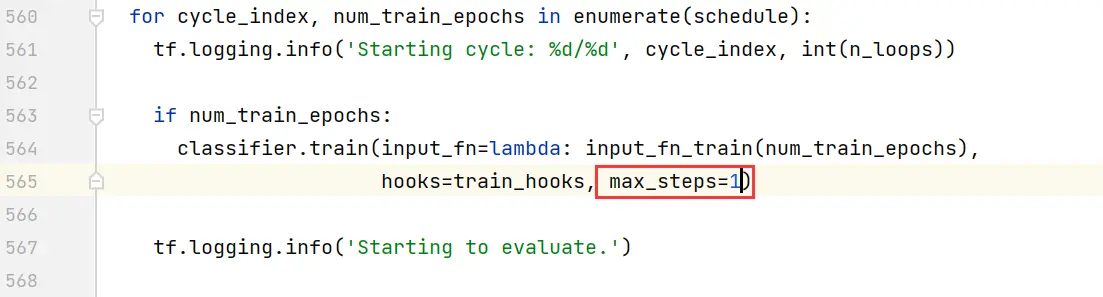
注释掉第575~582行
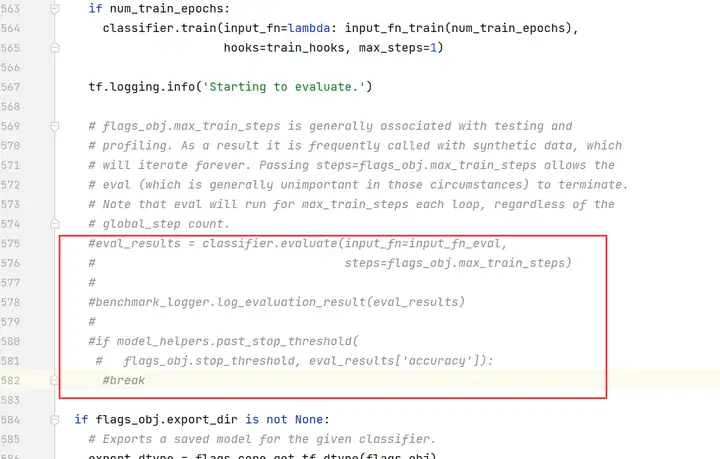
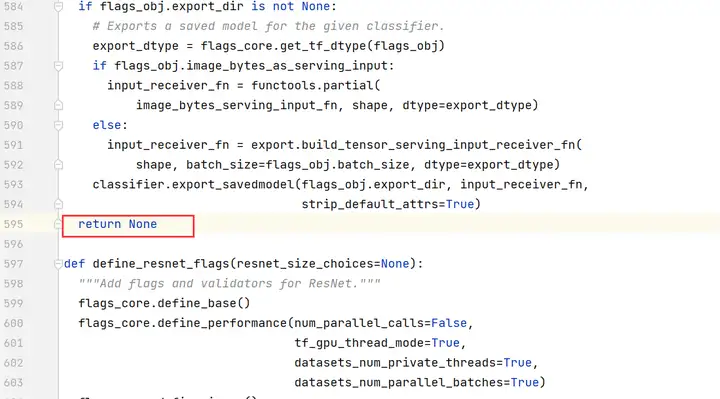
注释掉第595行,修改为“return None”。
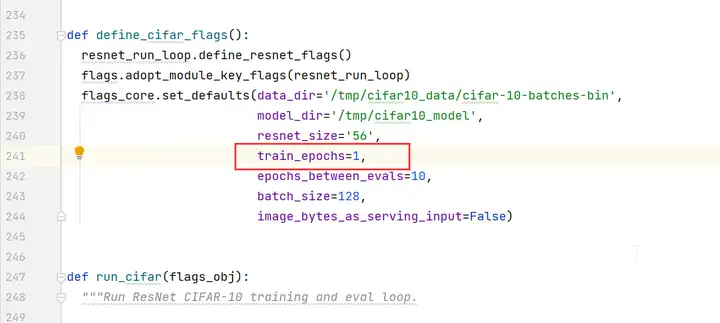
编辑cifar10_main.py文件,将train_epochs的值改为1。
步骤二 dump参数配置。
为了让训练脚本能够dump出计算图,我们在训练脚本中的包引用区域引入os,并在构建模型前设置DUMP_GE_GRAPH参数。配置完成后,在训练过程中,计算图文件会保存在训练脚本所在目录中。
编辑cifar10_main.py,添加如下方框中的信息。

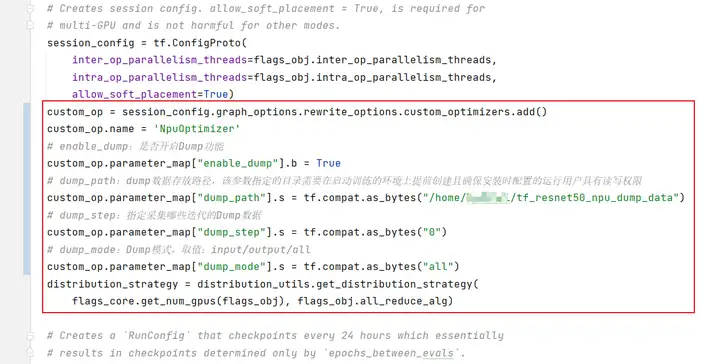
修改训练脚本(resnet_run_loop.py),开启dump功能。在相应代码中,增加如下方框中的信息。
步骤三 环境配置。
单击MindStudio菜单栏“Run > Edit Configurations...”。
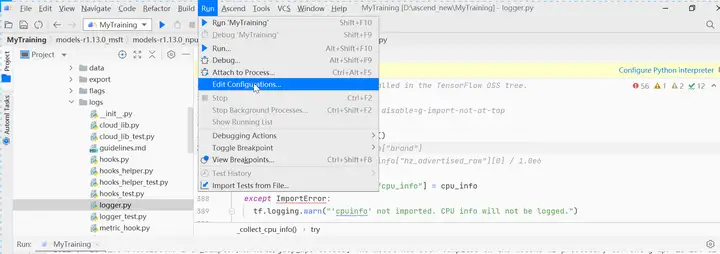
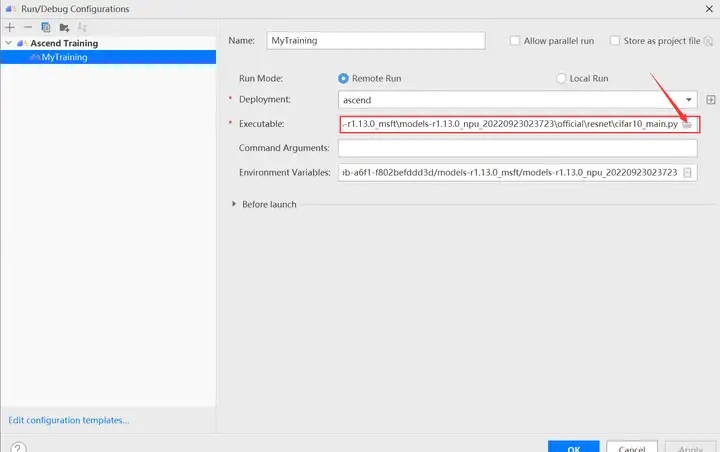
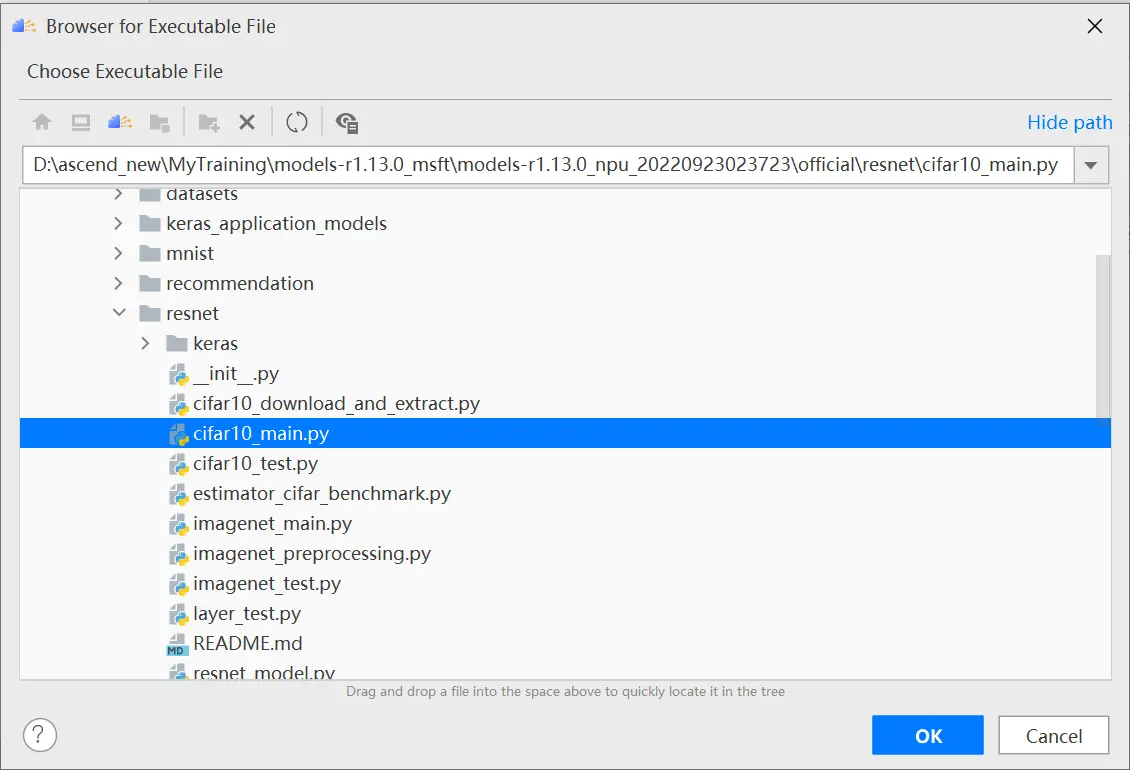
进入运行配置界面,选择迁移后的训练脚本。
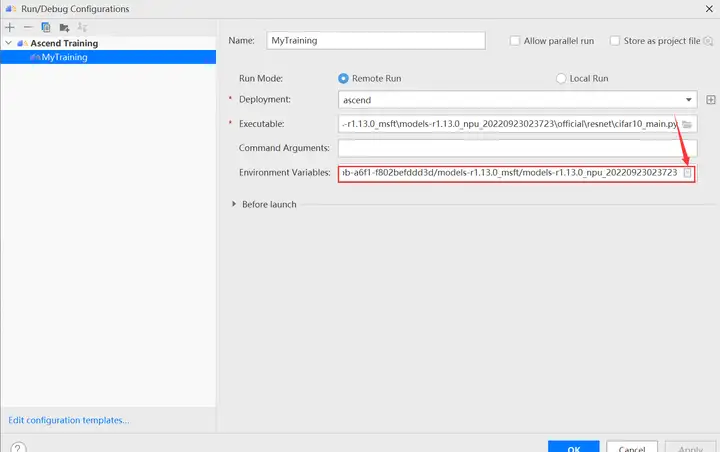
配置环境变量,打开下图所示界面,配置训练进程启动依赖的环境变量,参数设置完成后,单击“OK”,环境变量配置说明请参见下表。
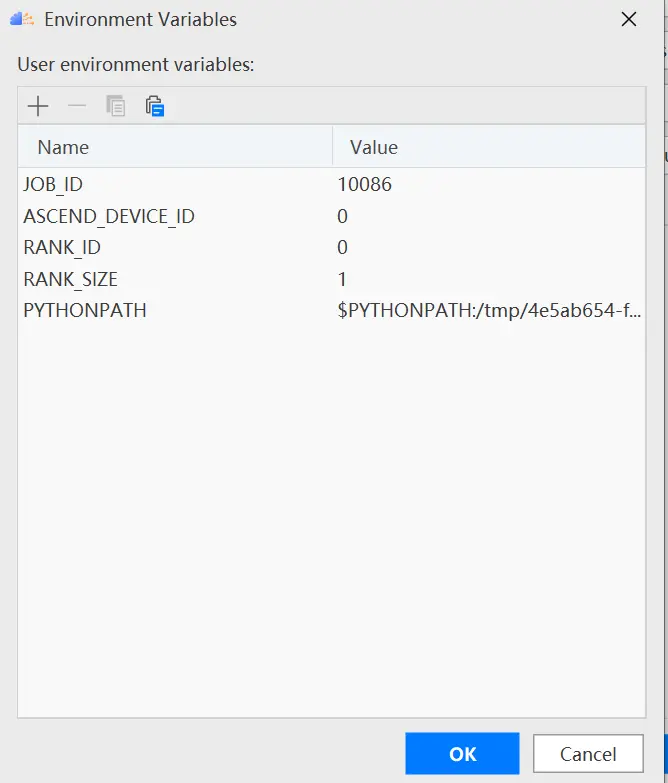
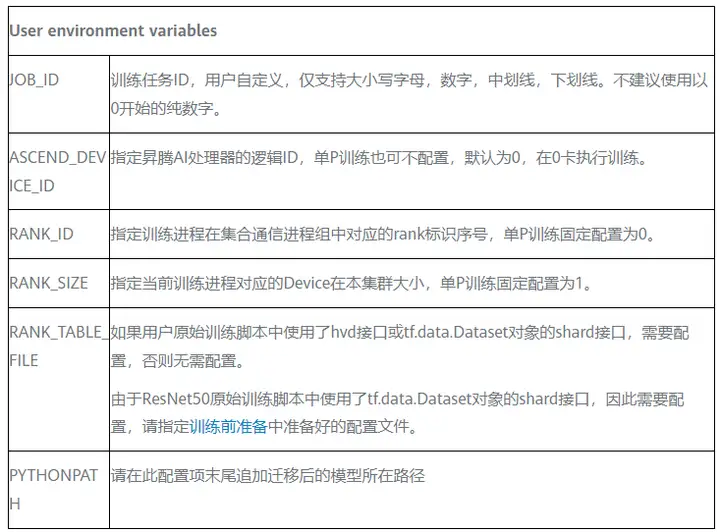
环境变量的解释如下表所示:
步骤四 执行训练生成dump数据。
点击按钮开始训练
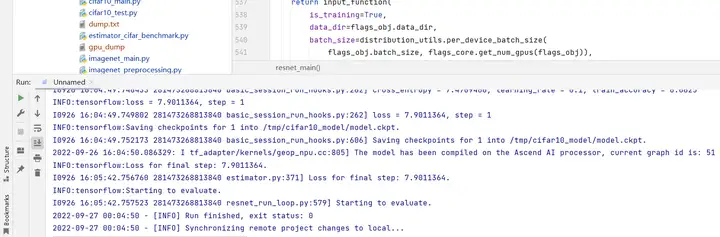
训练时控制台输出如下所示:
resnet目录下生成的数据文件展示如下:

在所有以“_Build.txt”为结尾的dump图文件中,查找“Iterator”这个关键词。记住查找出的计算图文件名称,用于后续精度比对。

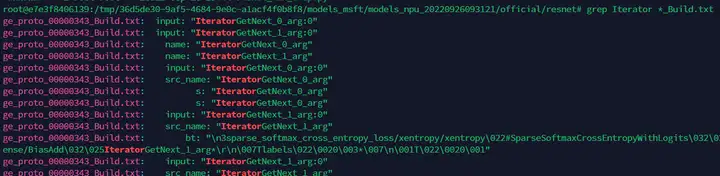
如上图所示,“ge_proto_00000343_Build.txt”文件即是我们需要找到的计算图文件。将此文件拷贝至用户家目录下,便于在执行比对操作时选择。
打开上面找到的计算图文件,记录下第一个graph中的name字段值。如下示例中,记录下“ge_default_20220926160231_NPU_61”。
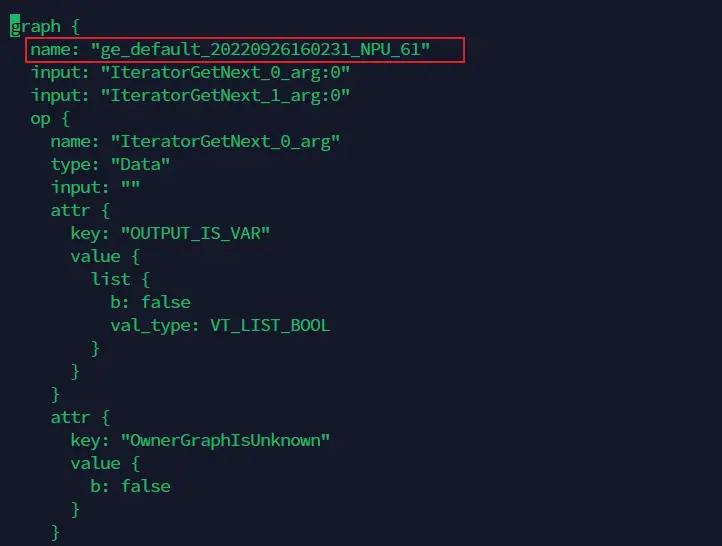
进入以时间戳命名的dump文件存放路径下,找到刚记录的名称为name值的文件夹,例如ge_default_20220926160231_NPU_61,则下图目录下的文件即为需要的dump数据文件:

五 比对操作
在MindStudio菜单栏选择“Ascend > Model Accuracy Analyzer > New Task”,进入精度比对参数配置界面。
配置tookit path,点击文件标识,如下图所示:
选择对应的版本,如5.1.RC2版本,单击ok:
单击next进入参数配置页面:
接着填写gpu和npu的数据的相关信息,如下图所示:
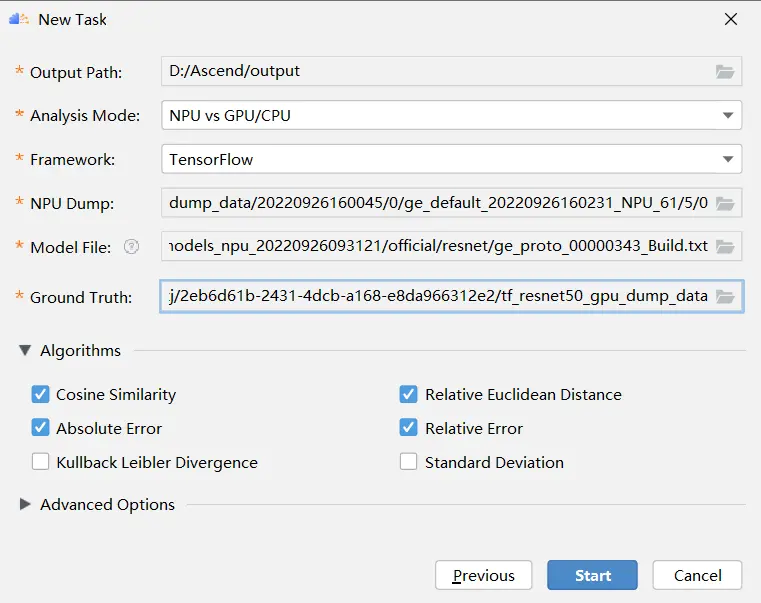
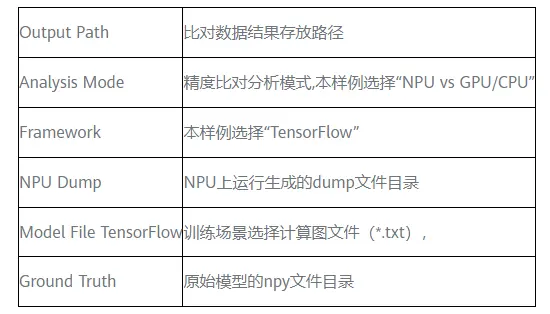
参数解释如下所示:
点击start:
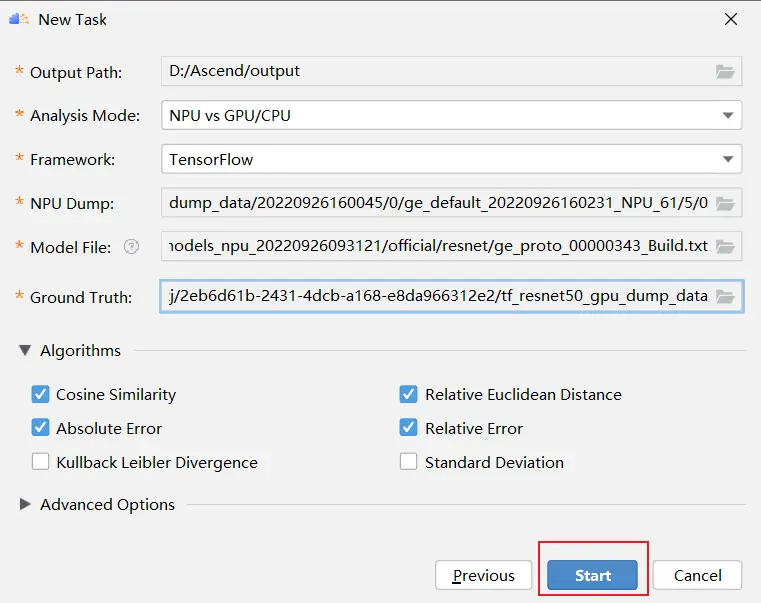

结果展示:
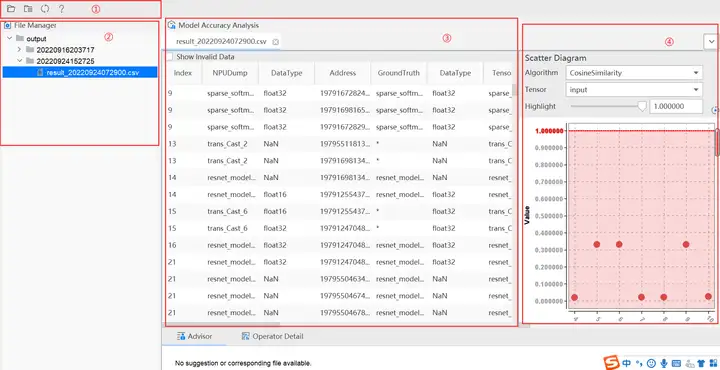
如上图所示将Vector比对结果界面分为四个区域分别进行介绍。
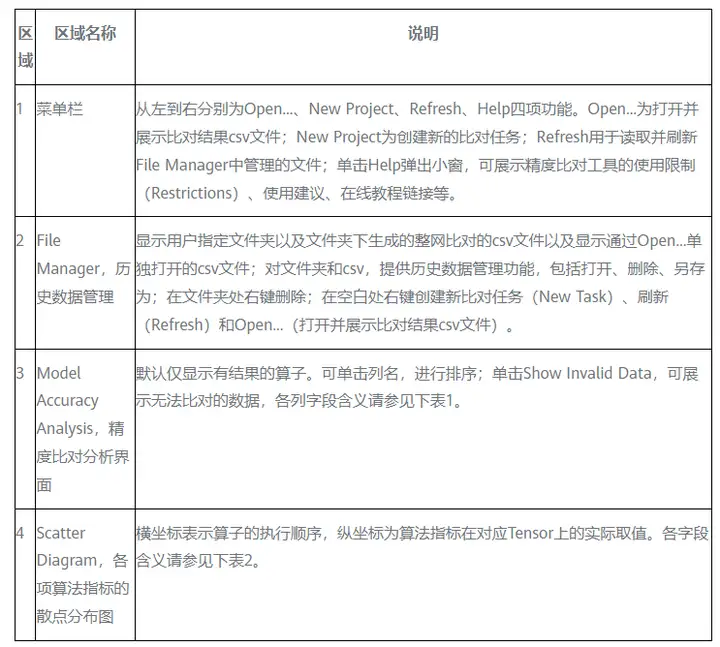
表1 精度比对分析界面字段说明
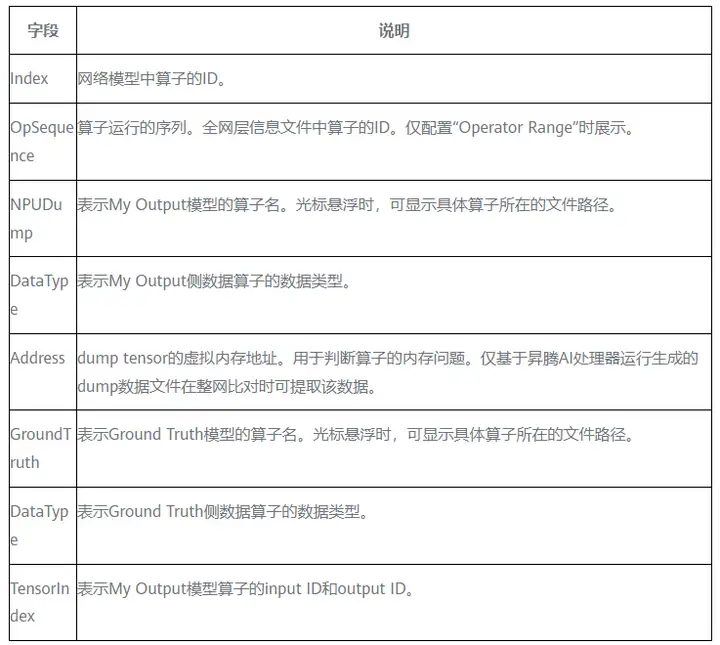
表2 散点分布图字段说明

六、常见问题 & 解决方案汇总
Q:tfdbg复制pt命令时执行出错
A:由于tfdbg将多行的pt命令识别为了单个命令,使得命令执行失败。解决办法如下:
- 先退出tfdbg命令行
- 安装pexpect库,命令为 pip install pexpect --user(--user只针对普通用户,root用户是没有的)
- 进入resnet所在的目录,cd ~/models/official/resnet
- 确保目录下有dump.txt文件,即生成的pt命令
- 编写下述代码,vim auto_run.py
import pexpect
import sys
cmd_line = 'python3 -u ./cifar10_main.py'
tfdbg = pexpect.spawn(cmd_line)
tfdbg.logfile = sys.stdout.buffer
tfdbg.expect('tfdbg>')
tfdbg.sendline('run')
pt_list = []
with open('dump.txt', 'r') as f:
for line in f:
pt_list.append(line.strip('\n'))
for pt in pt_list:
tfdbg.expect('tfdbg>')
tfdbg.sendline(pt)
tfdbg.expect('tfdbg>')
tfdbg.sendline('exit')
6.保存退出vim,执行python auto_run.py
七、从昇腾官方体验更多内容
更多的疑问和信息可以在昇腾论坛进行讨论和交流:https://bbs.huaweicloud.com/forum/forum-726-1.html
MindStudio模型训练场景精度比对全流程和结果分析的更多相关文章
- 如何借助 JuiceFS 为 AI 模型训练提速 7 倍
背景 海量且优质的数据集是一个好的 AI 模型的基石之一,如何存储.管理这些数据集,以及在模型训练时提升 I/O 效率一直都是 AI 平台工程师和算法科学家特别关注的事情.不论是单机训练还是分布式训练 ...
- AI佳作解读系列(一)——深度学习模型训练痛点及解决方法
1 模型训练基本步骤 进入了AI领域,学习了手写字识别等几个demo后,就会发现深度学习模型训练是十分关键和有挑战性的.选定了网络结构后,深度学习训练过程基本大同小异,一般分为如下几个步骤 定义算法公 ...
- 从零教你使用MindStudio进行Pytorch离线推理全流程
摘要:MindStudio的是一套基于华为自研昇腾AI处理器开发的AI全栈开发工具平台,该IDE上功能很多,涵盖面广,可以进行包括网络模型训练.移植.应用开发.推理运行及自定义算子开发等多种任务. 本 ...
- 课程报名 | 基于模型训练平台快速打造 AI 能力
我们常说的 AI 通用能力往往不针对具体的行业应用,而是主要解决日常或者泛化的问题,很多技术企业给出的方案是通用式的,比如通用文字识别,无论识别身份证.驾驶证.行驶证等,任何一张图片训练后的模型都会尽 ...
- 从软件开发到 AI 领域工程师:模型训练篇
前言 4 月热播的韩剧<王国>,不知道大家有没有看?我一集不落地看完了.王子元子出生时,正逢宫内僵尸作乱,元子也被咬了一口,但是由于大脑神经元尚未形成,寄生虫无法控制神经元,所以医女在做了 ...
- 阿里巴巴稀疏模型训练引擎-DeepRec
导读:DeepRec从2016年起深耕至今,支持了淘宝搜索.推荐.广告等核心业务,沉淀了大量优化的算子.图优化.Runtime优化.编译优化以及高性能分布式训练框架,在稀疏模型的训练方面有着优异性能的 ...
- 机器学习使用sklearn进行模型训练、预测和评价
cross_val_score(model_name, x_samples, y_labels, cv=k) 作用:验证某个模型在某个训练集上的稳定性,输出k个预测精度. K折交叉验证(k-fold) ...
- 谷歌大规模机器学习:模型训练、特征工程和算法选择 (32PPT下载)
本文转自:http://mp.weixin.qq.com/s/Xe3g2OSkE3BpIC2wdt5J-A 谷歌大规模机器学习:模型训练.特征工程和算法选择 (32PPT下载) 2017-01-26 ...
- 基于Python3.7和opencv的人脸识别(含数据收集,模型训练)
前言 第一次写博客,有点紧张和兴奋.废话不多说,直接进入正题.如果你渴望使你的电脑能够进行人脸识别:如果你不想了解什么c++.底层算法:如果你也不想买什么树莓派,安装什么几个G的opencv:如果你和 ...
随机推荐
- 创建deploymen的几种方式
创建deployment方式有两种,一种是命令直接创建,一种是使用yaml文件 1. 直接使用命令方式: --record 参数用来记录版本,也可以忽略,建议带上 kubectl create dep ...
- Rust 从入门到精通06-语句和表达式
1.语句和表达式 语句和表达式是 Rust 语言实现逻辑控制的基本单元. 在 Rust 程序里面,语句(Statement)是执行一些操作但不返回的指令,表达式(Expressions)计算并产生一个 ...
- 变废为宝: 使用废旧手机实现实时监控方案(RTSP/RTMP方案)
随着手机淘汰的速度越来越快,大多数手机功能性能很强劲就不再使用了,以大牛直播SDK现有方案为例,本文探讨下,如何用废旧手机实现实时监控方案(把手机当摄像头做监控之用): 本方案需要准备一个手机作为采集 ...
- KingbaseES 数据脱敏功能介绍
数据脱敏,指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护. KingbaseES主要提供动态数据脱敏功能. 动态数据脱敏(Dynamic Data Masking)是与生产环境 ...
- 巧用KingbaseES中的动态DDL
概述 :在DBA的日常工作中,经常遇到一些需要基于数据库当前状态的实用程序查询的实例.比如一个逻辑复制的目标表,主键ID列与生成数据的序列不同步,这将导致插入新行是,会有主键冲突.要纠正这个问题,需要 ...
- PostgreSQL 时间函数分类与特性
KingbaseES 时间函数有两大类:返回事务开始时间和返回语句执行时的时间.具体函数看以下例子: 1.返回事务开始时的时间 以下函数返回事务开始的时间(通过 begin .. end 两次调用结果 ...
- LSB隐写术
此为北京理工大学某专业某学期某课程的某次作业 一.项目背景 1.隐写术 隐写术是一门关于信息隐藏的技巧与科学,所谓信息隐藏指的是不让除预期的接收者之外的任何人知晓信息的传递事件或者信息的内容. 2.L ...
- Fluentd 简明教程
转载自:https://mp.weixin.qq.com/s?__biz=MzU4MjQ0MTU4Ng==&mid=2247491814&idx=1&sn=3b0f1a3477 ...
- 清除已安装的rook-ceph集群
官方文档地址:https://rook.io/docs/rook/v1.8/ceph-teardown.html 如果要拆除群集并启动新群集,请注意需要清理的以下资源: rook-ceph names ...
- 使用Prometheus和Grafana监控RabbitMQ集群 (使用RabbitMQ自带插件)
配置RabbitMQ集群 官方文档:https://www.rabbitmq.com/prometheus.html#quick-start 官方github地址:https://github.com ...