KMP算法学习记录
Foreword:
初学KMP匹配算法,不得其门,总感觉自己想,想不出来,看书上文字解释晦涩难懂。不能准确的捕捉算法设计时候的灵光和思路 。于是自己试着完成了一遍,现将过程记录下来,以供复习。
Content:
(一) 预设:模式串和母串的声明
1. 子串的定位操作通常称为穿的模式匹配,求的是子串(常称之为‘模式串’)在主串中的位置;本次,我们将创建两个字符串T(母串)和P(模式串),然后进行匹配。
2. 串是一种连续存储的数组,串的地址就是第一个字符的地址,串的数据类型都要是字符。
3. 语言限定:这里使用的语言为C语言。
4. 笔者习惯:行文中使用‘?=’是想表示“是否等于”的有意思。
5. 字符串的前缀、后缀和部分匹配值:
a. 前缀:指代除了最后一个字符以外,字符串的头部子串集合;
b. 后缀:指代除了第一个字符以外,字符串的尾部子串集合;
c. 部分匹配值:等长的前缀和等长的后缀中最长的前后缀长度;
illustrate:‘ababa’
'a'前后缀都是空集,部分匹配值为0;
'ab'前缀为‘a’,后缀为'b',部分匹配值为0;
'aba'前缀为{'a','ab'}, 后缀为{'a','ba'},'a'='a'部分匹配值为1;
'abab'前缀为{'a','ab','aba'}, 后缀为{'a','ab',bab},'a'='a','ab'='ab'且'ab'长度为2,'a'长度为1,2>1, 所以部分匹配值为2;
'ababa'前缀为{'a','ab','aba'}, 后缀为{'a','ba','aba'},'a'='a', 'aba'='aba',且3>1, 所以部分匹配值为3;
(二) 匹配前准备:创建字符串
• 宏:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <string.h>
4 #define MaxSize 100
• 创建一个结构体命名为String,包含一个静态存储声明的数组和数组实际长度:
1 typedef struct String{
2 char ch[MaxSize];
3 int length;
4 }SString,*String;
• 主函数,声明母串T和模式串P,使用<stdio.h>库的printf和scanf两个输入输出流函数对字符串赋值。并通过<string.h>库的strlen函数确定字符串的实际长度,该函数不会统计字符串结尾的关键字‘\0’。声明的int型常量situated用来存储子串(常称之为‘模式串’)在主串中的位置。
1 int main(){
2
3 SString T;
4
5 SString P;
6
7 int situated;
8
9 printf("请输入字符序列T:\n");
10
11 scanf("%s",&T.ch);
12
13 printf("字符串T: %s \n",T.ch);
14
15 T.length=strlen(T.ch);
16
17 printf("T.length: %d \n",T.length);
18
19 printf("请输入字符序列P:\n");
20
21 scanf("%s",&P.ch);
22
23 printf("字符串T: %s \n",P.ch);
24
25 P.length=strlen(P.ch);
26
27 printf("P.length: %d \n",P.length);
28
29 situated = PMIndex(T,P);
30
31 printf("匹配完成,相对位置为:%d \n",situated);
32
33 return 0;}
(三)暴力匹配方法(violent match method)
一般来说,我们会创建两个字符串,暨母串和模式串,他们分别存储在数组T.ch[]和P.ch[],长度分别是T.length和P.length。
我们声明int型变量i是母串的字符序号,暨母串的第几个字符,它的区间是[1,T.length]。
我们声明int型变量j是母串的字符序号,暨子串的第几个字符,它的区间是[1,P.length]。
母串存储的数组的角标、数组元素和i、j序号值对应为:
|
母串 |
a |
b |
c |
…… |
k |
|
角标 |
0 |
1 |
2 |
…… |
T.Length-1 |
|
i |
1 |
2 |
3 |
…… |
T.length |
|
模式串 |
a |
b |
c |
…… |
m |
|
角标 |
0 |
1 |
2 |
…… |
P.Length-1 |
|
i |
1 |
2 |
3 |
…… |
P.length |
我们完成匹配的思路很直接,很粗鲁,直接用子串第一个和母串第一个值匹配,相同就顺次匹配下一对直到模式串匹配完成结束。但如果没有匹配完就失配了,重新用模式串的所有字符和母串第二个元素开始的字符开始一一对应的匹配,直到模式串匹配完成或者再发生失配,失配就继续重新从i=3开始循环匹配,直到母串匹配完返回‘没匹配到’或者匹配到模式串返回匹配的地址。
1 int Index(SString T,SString P){
2
3 //暴力匹配方法
4
5 int i=1;
6
7 int j=1;
8
9 while(i<=T.length && j<=P.length){
10
11 if(T.ch[i-1]==P.ch[j-1]){
12
13 printf("匹配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
14
15 ++i;
16
17 ++j;
18
19 //继续比较后面的字符
20
21 }
22
23 else{
24
25 printf("发生失配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
26
27 i = i-j+2;
28
29 j=1;
30
31 //指针后退,模式串T右移,重新开始匹配
32
33 }
34
35 if(j==P.length+1){return i-P.length;}
36
37 }
38
39 return 0;
40
41 }
|
母串 |
a |
a |
c |
d |
r |
e |
|
模式串一次循环匹配 |
a |
c |
s |
|||
|
模式串二次循环匹配 |
a |
c |
s |
|||
|
模式串二次循环匹配 |
a |
c |
s |

(四)模拟人在正常情况的匹配方法:
|
母串 |
a |
b |
a |
a |
b |
a |
g |
h |
i |
|
模式串第一次匹配 |
a |
b |
a |
g |
|||||
|
模式串第二次匹配 |
a |
b |
|||||||
|
模式串第三次匹配 |
a |
b |
a |
g |
如上表所示,我们在对上表情况进行暴力匹配的时候,第一次失配后,i总要退回到 i+2-j 的位置重新从j=1开始匹配。这里已经匹配成功的‘aba’字符在用暴力算法从新匹配的时候就相当于,模式串自己和自己匹配,一旦模式串比较长这种做法无异于十分低效且费力。这里用到了预设里提到的前后缀,如果在一次匹配进行过程中发生失配时,已匹配的字符串拥有部分匹配值num>0, 那么我们会直接把模式串右移(j-num-1)位,暨i不变,j=num+1;
更确切地说,右移位数 == 已匹配字符数 - 已匹配字符串对应的部分匹配值
上面的内容书上和网上教程讲的很清楚,不详细说明了。
这里对如何求前后缀部分匹配值的计算进行展示:
1 int SectionMarch(SString P,int temp1){//模式串和已匹配数,返回最长的前缀等于后缀的缀的长度
2 for(int Q=1;Q<temp1;Q++){//从第大到小进行部分匹配,每次匹配长度为temp1-Q
3 for(int i=0;i<=temp1-Q-1;i++){
4 if(P.ch[temp1-Q-i-1]==P.ch[temp1-i-1]){}
5 else{ break;}
6
7 if(i==temp1-Q-1){return temp1-Q;}
8 }
9 }
10 return 0;
11 }

上图对不同个数的字符串的部分匹配值PM进行了说明,可见面对temp1个字符的字符串 'ary[0],ary[1],ary[2]……ary[Q-1]':需要分别匹配
PM = temp1-1:ary[0] == ary[1]&ary[1]==ary[2]&…ary[temp1-1-i-1]==ary[temp1-1-i]…&ary[temp1-1-1-1]==ary[temp1-1-1]&ary[temp1-1-0-1]==ary[temp1-1-0];
PM = temp1-2: ary[0] == ary[2]&ary[1]==ary[3]&…ary[temp1-1-i-2]==ary[tempp1-1-i]…&ary[temp1-1-1-2]==ary[temp1-1-1]&ary[temp1-1-0-2]==ary[temp1-1-0];
……
……
……
PM = temp1-Q: ary[temp1-Q-1-(temp1-Q-1)] == ary[temp1-1-(temp1-Q-1)]&ary[temp1-Q-1-(temp1-Q)]==ary[temp1-1-(temp1-Q)]&…ary[temp1-1-i-Q]==ary[tempp1-1-i]…&ary[temp1-1-1-Q]==ary[temp1-1-1]&ary[temp1-1-0-Q]==ary[temp1-1-0];
……
……
……
PM = 1:ary[0] == ary[temp1-1];
这样自上而下从右到左顺次匹配,直到首个把一行匹配完都正确的出现就能够直接确定部分匹配值;
这样我们就可以进行模拟手工匹配了!!!
1 int PMIndex(SString T,SString P){//参数是已匹配的部分字符串
2 //模拟人工匹配方法
3 int i=1;
4 int j=1;
5 //注意这里的i和j分别代表的是母串和模式串的字符序号而不是角标
6 int temp1=0;
7 int Max_march;
8
9 while(i<=T.length && j<=P.length){
10 if(T.ch[i-1]==P.ch[j-1]){
11 printf("匹配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
12 ++i;
13 ++j;
14 temp1++;//记录匹配次数
15 //继续比较后面的字符
16 }
17 else{
18 printf("发生失配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
19 Max_march=SectionMarch(P,temp1);//判断已经匹配的temp1个字符里面,最大的相同前后缀字符子串长度
20 if(j==1){//当第一个匹配值就不匹配时;匹配串右移一位,母串指针i右移一位
21 i++;
22 }
23 else if(Max_march==0){
24 j=1;
25 }
26 else{
27 j=Max_march+1;//如果匹配串拥有前后缀匹配的字符串的话
28 }
29 temp1 = 0;
30 //指针后退,模式串T右移,重新开始匹配
31 }
32 if(j==P.length+1){return i-P.length;}
33 }
34 return 0;
35 }
运行结果:
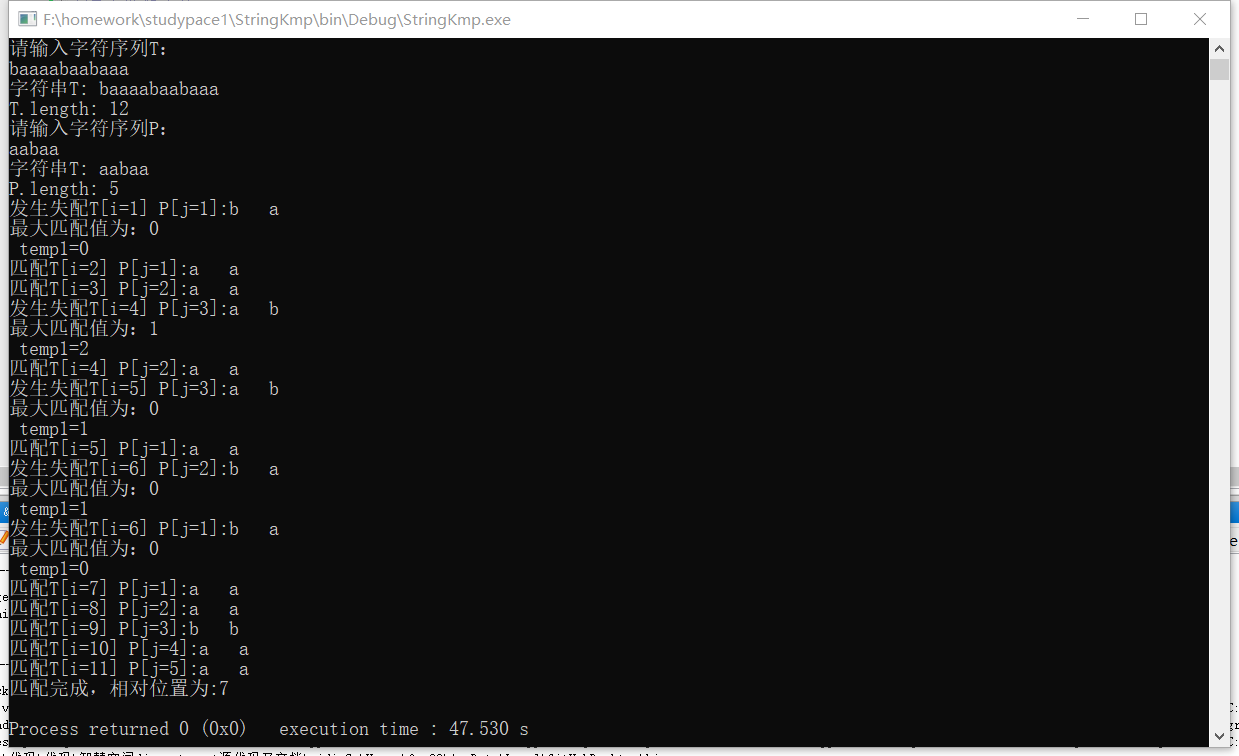
当然,我们实际上每一次在匹配成功后失配的时候都进了一次针对匹配字符串的前后缀部分匹配值的计算。而且,这种计算是二次嵌套,每次计算的时间复杂度都高达O(n^2)。所以在匹配的串较长的时候,最好提前把子串每种运算的PM值计算出来做成一一对应的表单,存储在数组中这样每次使用的时候就不用都调用匹配函数了。
基本对函数和主题没什么改变,详细如下:
int PMListIndex(SString T,SString P){
//模拟PM表匹配方法
int i=1;
int j=1;
//注意这里的i和j分别代表的是母串和模式串的字符序号而不是角标
int temp1=0;
int Max_march;
int section_march[P.length];//对应模式串的PM匹配表
section_march[0]=0;//将P[1]前面的空置字符和T[i]对齐
section_march[1]=0;
for(int temp2=2;temp2<=P.length-1;temp2++){
section_march[temp2]=SectionMarch(P,temp2);
}
printf("制作的表单为:\n");
for(int temp2=0;temp2<=P.length-1;temp2++){
printf("当第j=%d 个字符失配时,其已匹配字符串的最大部分匹配值为:%d \n",temp2+1,section_march[temp2]);
}
while(i<=T.length && j<=P.length){
if(T.ch[i-1]==P.ch[j-1]){
printf("匹配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
++i;
++j;
temp1++;//记录匹配次数
//继续比较后面的字符
}
else{
printf("发生失配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
Max_march=section_march[temp1];//判断已经匹配的temp1个字符里面,最大的相同前后缀字符子串长度
if(j==1){//当第一个匹配值就不匹配时;匹配串右移一位,母串指针i右移一位
i++;
}
else if(Max_march==0){
j=1;
}
else{
j=Max_march+1;//如果匹配串拥有前后缀匹配的字符串的话
}
temp1 = 0;
//指针后退,模式串T右移,重新开始匹配
}
if(j==P.length+1){return i-P.length;}
}
return 0;
}
展示结果:
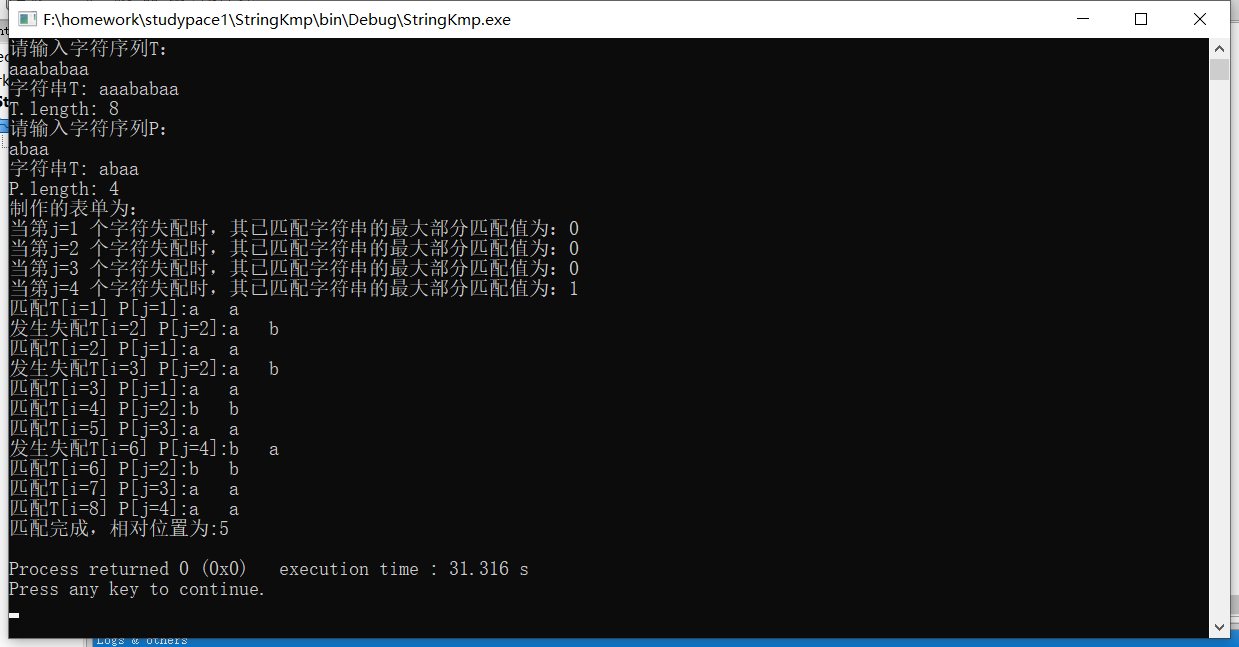
(四)KMP的匹配方法:
从上面我们已经看到了直接寻找模式串的所有部分前后缀匹配值是比较低效的,特别是在模式串较长的时候反而会弄巧成拙,更加的低效。由于我们单是在模式串自身的结构研究得到的部分匹配值,那么是否也可以从这里入手,挖掘我们上面做的表单项与项之间的关系,进一步避免调用SectionMarch()函数计算呢?
还真可以,先回顾一下这个图。

- 这里j代表模式串的序号取值为[1,P.length];
- ’ary‘ 是任意母串名称,'num'为母串角标取值为[0,P.length-1];
- PM[j] 代表当第j个元素失配时,前面已经匹配的字符串的部分匹配值,在理论上可能得到的取值;
- 备注------看图
这里需要强调两个可能的推理:
|
推理1 |
已知:PM[j]==number1 如果:ary[number]==ary[j-1] 得出:PM[J+1]=PM[J]+1 |
Elaborate:
观察上图(下面是我截取的部分):

我们能直观的发现这个规律,
PM[4]==1时,确定了a=c;
PM5]==2时,确定了a=c&&b=d;
PM6]==3时,确定了a=c=e&b=d;
PM7]==4时,确定了a=c=e&b=d=f5;
…………
看看具体的情况,仔细想想:当j==5,暨第五个字符失配时,PM[5]等于其对应元素'f'前面4个已经匹配的字符组成的字符串[a,b,c,d]实际上的最大部分匹配,而当PM[4]==1时,a=c, 这已经是在ary[3]失配时,我们面对其前面已经匹配的字符串[a,b,c]能得到的最大前后缀匹配值了。那么如果b==d,就能直接得到[ab]==[cd],进而得到一个足够大的PM[5]的值。
但是,这会是PM[5]最大的匹配值么?
|
推理3 |
已知:PM[j]==number1 得出: (1)PM[j-1]对应的匹配字符中有一定包含PM[j-1]==number1-1对应的匹配值,且PM(j-1)>= number-1 (2)由上面的定理得,PM[j+1]<=number+1 |
上面的定理我们也可以用数学归纳法得到证明,这里还是带来直观的感受:

如图所示,在同一行的数据里我们发现左面的数据限制是右面的数据的前设,且只差一个元素的比较。实际上,这对应着定理1。所以我们可以确定两个个规律:
(1)当同一行数据,右边的数据成立的时候,其正左面的数据也一定成立;
(2)由于我们的部分匹配串长度是按照从小到大排列的,PM值只取所有部分匹配值中最大的一个,所以在同一列数据里某个串的长度被认定为PM值时其下面的式子一定不成立!进而推论得到,其下面式子对应的同行右面的式子也一定不成立!
这样就能解释推理一得到的式子一定是其下一个PM值的最终值了。
因此,相应的,如果我们知道PM[4]==2时(暨第ary[3]个字符失配且最大部分匹配长度为2的时候),只需要确定ary[2]?=arry[3];即可确定PM[5]是否==PM[4]+1
求PM的过程的本质:
我们在求PM[j]的时候,实质上研究的是第j个元素[e]之前的字符串[a,b,c,d]的前后缀匹配关系,并把最长的匹配值赋给PM[j]作为记录
PM[4]=j-2=2时,确定的是[d]前2个以内的后缀[b,c]以及前2个以内的前缀[a,b]的匹配关系
举个栗子:
|
j |
5 |
|
ary[num] |
e |
|
角标num |
4 |
|
PM[j] |
[0,1,2,3] |
|
备注 |
[] [0,3]--[a,d]-->a=d3 [01,23]--[ab,cd]-->a=c&&b=d3 [012,123]--[abc,bcd]-->a=b=c=d3 |
我们在求PM[5]的时候,实质上研究的是第5个元素[e]之前的字符串[a,b,c,d]的前后缀匹配关系,并把最长的匹配值赋给PM[5]作为记录
PM=j-2=3时,确定的是[e]前3个以内的后缀[b,c,d]以及3个以内的前缀[a,b,c]的匹配关系
PM=j-3=2时,确定的是[e]前2个以内的后缀[c,d]以及2个以内的前缀[a,b]的匹配关系
……
j-5:[a,e]-->[0,4]
j-4:[b,e]-->[1,4]
j-3:[c,e]-->[2,4]
j-2:[d,e]-->[3,4]
通过PM[j]推导PM[j+1]的思路历程:
这里设j=6
实际上,我们在计算得到PM[6]=j-3=3时研究的是[f]之前的字符串[a,b,c,d,e]自身的前后缀匹配关系,并且把得到的最大的匹配值赋给了PM[6]作为记录。而在得到PM[6]=3时,我们就确定了[f]前PM[6](注:PM[6]=3)个以内的后缀[c,d,e]以及PM[6](注;PM[6]=3)个以内的前缀[a,b,c]的匹配关系。
而在通过PM[j]研究PM[j+1]时,先判断PM[j+1]的值是否可以达到其在推理3下的理论最大值PM[j]+1。在这里就是判定PM[7]是否可以达到PM[6]+1=4。
这时,根据推理1,先进行'ary[3]==ary[5]'的比较。
概由于如果匹配成功即可得到PM[j+1]=PM[j]+1=4;所以这里讨论不匹配的情况,暨:PM=j-3时, 匹配[d,f]-->[3,5],结果为d!=f的情况。
此时:PC[j+1]=j-3+1=4匹配失败;
值得注意的是:[a,b,c][d]
[c,d,e][f]
其中红色部分纵向一一对应,且由于推理3知:匹配串的长度PM[j+1]的值已经不能再增长了,暨在[d,f]失配时,PM[j+1]<=j-3-->p[7]<=3。
因此,此时我们要探讨和关注的就是——[f]前的PM[6]-1个(PM[6]-1=2暨2个)以内的尾缀[d,e]同[d]前2个以内的前缀[a,b]之间的匹配关系!
这时我们可以发现,在我们计算得到PM[4]=j-2=2时
,研究的是[d]前PM[4]=2个以内的后缀[b,c]以及前PM[4]=2个以内的前缀[a,b]的匹配关系!
值得关注的是:由于[a,b,c]=[c,d,e],所以两个字符串的前后缀匹配值是相同的!因而当我们要求[c,d,e]的后缀==[a,b,c]的前缀的最小匹配值时,就是求[a,b,c]自身的前后缀的最小匹配值!
而这个过程,正是我们在求PM[4]时完成的!
直观感受一下:
PM[4]=0时:[a]
[d]
[a,b,c][d]
[c,d,e][f]
PM[4]=1时:[a][b]
[c][d]
[a,b,c][d]
[c,d,e][f]
PM[4]=2时(实际上在确定PM[6]=3时,PM[4]是不可能等于2的。因为假设相等则会造成a=b=c=d=e,这时候计算PM[6]=4,和前设PM[6]等于3相矛盾!这里用它举例子只是为了展示逻辑运算关系,这里的问题不会影响运算逻辑,建议忽略笔者这点疏忽,没啥影响。这就跟我告诉你,假设有一个上万吨的陨石在你家楼上800米的位置由静止开始自由落体,然后经过推理告诉妮,你家可能会塌一样!我假设的情况可能不会发生,但是这不影响你理解辣么大的石头砸下去,你家会塌的推理!继续):
[a,b][c]
[b,c][d]
[a,b,c][d]
[c,d,e][f]
上面红色部分纵向一一对应的,并表示在各自情况下的最大匹配关系。在PM[4]=2时,[a,b]=[b,c];[b,c]=[d,e]
而实际上,我们需要得到的就是尾缀[d,e]和前缀[a,b]之间的最长的匹配关系。在这种
[a,b][c]
[d,e][f]
[a,b]=[d,e]的情况下,我们只要判定c是否等于f,就可以确定PM[7]是否能达到PM[6]+1-1=3了。
当然,PM[4]的值不一定就是正好等于2,但是由于我们计算PM[4]取值的时候就是在计算[d]前字符串[a,b,c]的自身前后缀匹配关系了,并且取了最大的匹配值赋值给了PM[4]。所以很容易确定,PM[4]=number时,我们可以直接确定长度为number的最大匹配前后缀字符串并通过对ary[number]和ary[j-1]比较来确定是否PM[j+1]=number+1。
这时候如果ary[number]和ary[j-1]依旧不相等怎么办?
这里采用一个合理的例子:PM[6]=3&PM[4]=1&ary[1]!=ary[5]时,
-(…O__O…|||)-
例子不够用了!!!!
改一下,这里采用一个勉强合理的例子:
已知:PM[7]=4&PM[4]=2&ary[4]!=ary[6]&ary[2]!=ary[6],
在我们希望通过PM[7]求PM[8]的时候,同样执行通过PM[6]求PM[7]的过程。
先按照推理1,根据推理1,进行'ary[4]==ary[6]'暨[e]和[g]的比较,进而确定PM[8]?=PM[7]+1。显然根据设定是不等的。
又根据推理3知,PM[8]<=PM[7]+1。而又因为PM[8]=5的匹配失败,所以PM[8]<=PM[7]。所以,这时我们要寻找PM[7]-1长度的前缀字符串[a,b,c,d]和后缀[c.d.e.f]合适的匹配值。
继而,为了判断后缀[c.d.e.f]和前缀[a,b,c,d]进一步的匹配关系。
首先,由PM[7]可以确定后缀[c.d.e.f]==前缀[a,b,c,d],所以求他们的前后缀匹配关系就是求前缀[a,b,c,d]自身的前后缀匹配关系!而这个过程正是我们在计算PM[4]的时候完成的。
根据题设条件,PM[4]=2,暨这个时候的最大匹配值为2。所以有:[a,b]==[c,d],继而得到[a,b]==[e,f],进而判断ary[2]?=ary[6]以确定PM[8]?=PM[4]+1。显然根据题设ary[2]!=ary[6]。这时可以判断PM[8]<=PM[4]
我们需要对PM[4]长度的前缀字符串[a,b]自身的匹配关系进行判断,同样的,这个过程正是在我们求PM[2]的时候完成的。
从理论上说,PM[2]可能有{0,1}两种可能的取值。数值为1的时候:
显然,这时候应该进行'ary[1]==ary[6]'暨[b]和[g]的比较,进而确定PM[8]?=PM[2]+1。
PM[2]=0的时候,则直接将'ary[0]==ary[6]'暨[a]和[g]进行比较,进而确定PM[8]?=PM[2]+1。
上述操作直观上看是这样的:
(3)通过PM[2]=0判断PM[8]?=0+1=1:[][a]
(3)通过PM[2]=1判断PM[8]?=1+1=2:[a][b]
[b][c]
(2)通过PM[4]=2判断PM[8]?=2+1=3:[a,b][c]
[c,d][e]
(1)通过PM[7]=4判断PM[8]?=5:[a,b,c,d][e]
[c,d,e,f][g]
而实际上,和之前同样的理由,由于设定的原因,实际上,这里的PM[2]不可能等于1。当然像PM[2]等于几,PM[4]等于几都是前设应该给出的,是我们需要用暴力算法计算的,或者用其前面的值推导已知的。这里为了尽量考虑全面的情况,所有数据都是假设+逆推+假设给出的,实际上不会遇到这种问题,作题这些都会是合理已得数据,自己计算这些也会是事先计算好的才对。

1 int KMPIndex(SString T,SString P){
2 //模拟PM表匹配方法
3 int i=1;
4 int j=1;
5 //注意这里的i和j分别代表的是母串和模式串的字符序号而不是角标
6 int temp1=0;
7 int Max_march;
8 int section_march[P.length];//对应模式串的PM匹配表
9 section_march[0]=-1;//将P[1]前面的空置字符和T[i]对齐
10 section_march[1]=0;
11
12
13 for(int temp2=2;temp2<=P.length-1;temp2++){
14 printf("顺利进入第 %d 次外循环;\n",temp2-1);
15 int section_march_temp1;
16 section_march_temp1=temp2;
17 int h=1;
18 for(int section_march_temp=section_march[temp2-1];section_march_temp1!=-1;section_march_temp=section_march[section_march_temp]){
19 printf("顺利进入第 %d 次内循环;\n",h);
20 printf("此刻,section_march_temp: %d P.ch[section_march_temp]: %c temp2-1: %d P.ch[temp2-1]: %c \n",section_march_temp,P.ch[section_march_temp],temp2-1,P.ch[temp2-1]);
21 if(P.ch[section_march_temp]==P.ch[temp2-1]){
22 printf("P.ch[section_march_temp= %d]= %c 和 P.ch[temp2-1= %d] = %c 比较判断成功 \n",section_march_temp,P.ch[section_march_temp],P.ch[temp2-1]);
23 section_march[temp2]=section_march[section_march_temp1-1]+1;
24 printf("判断成功后,section_march[temp2 = %d ]= %d \n",temp2, section_march[temp2]);
25 break;}
26 printf("匹配失败,进行深一层内循环比对。\n");
27 section_march_temp1= section_march_temp;
28 if(section_march[section_march_temp]==-1){
29 printf("没有合适的匹配值,即将退出内循环,section_march[%d]=0 \n",temp2);
30 section_march[temp2]=0;
31 }
32 printf("此刻section_march_temp1= %d \n",section_march_temp1);
33
34 h++;
35 }
36 }
37
38
39 printf("制作的表单为:\n");
40 for(int temp2=0;temp2<=P.length-1;temp2++){
41 printf("当第j=%d 个字符失配时,其已匹配字符串的最大部分匹配值为:%d \n",temp2+1,section_march[temp2]);
42 }
43
44 while(i<=T.length && j<=P.length){
45 if(T.ch[i-1]==P.ch[j-1]){
46 printf("匹配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
47 ++i;
48 ++j;
49 temp1++;//记录匹配次数
50 //继续比较后面的字符
51 }
52 else{
53 printf("发生失配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
54 Max_march=section_march[temp1];//判断已经匹配的temp1个字符里面,最大的相同前后缀字符子串长度
55 printf("此刻最大的前后缀匹配值= %d \n",Max_march);
56 if(j==1){//当第一个匹配值就不匹配时;匹配串右移一位,母串指针i右移一位
57 i++;
58 }
59 else if(Max_march==0){
60 j=1;
61 }
62 else{
63 j=Max_march+1;//如果匹配串拥有前后缀匹配的字符串的话
64 temp1 = Max_march;
65 continue;
66 }
67 temp1 = 0;
68 //指针后退,模式串T右移,重新开始匹配
69 }
70 if(j==P.length+1){return i-P.length;}
71 }
72 return 0;
73 }
运行结果展示:
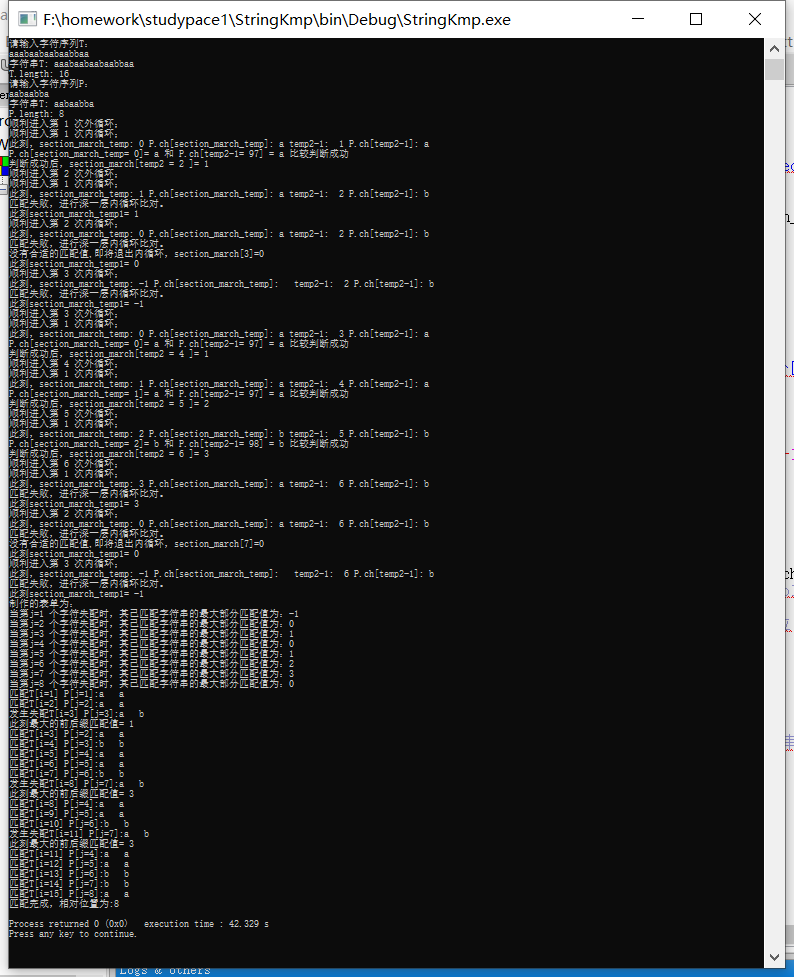
这实际是我们的PM表匹配的方法·,由于每次PM[j]都是求其前面的字符串的部分匹配值,书上通过将PM这一行数据右移让她更直观的展示出来,由于是右移,所以最左面的用-1填充,函数里可以用来提示没有匹配值。最右边的匹配值因为实际上用不到(某个元素的匹配值都是下一个元素使用的)就被无情舍弃了。再把得到的值统一加一,就成了next[]函数。
书上给的代码:
1 void get_next(SString T,int next[]){
2 int i=1;
3 int j=0;
4 next[1]=0;
5 // next[2]=1;
6 while(i<T.length){
7 if(j==0||T.ch[i]==T.ch[j]){
8 printf("匹配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i],T.ch[j]);
9 ++i,++j;
10 next[i]=j;
11 printf("next[i= %d] j= %d \n",i,j);
12 }
13 else{
14 printf("失配!不能执行+1操作,对j递归,j=next[j= %d ]:%d \n",j,next[j]);
15 j=next[j];
16 }
17 }
18 printf("制作的表单为:\n");
19 for(int temp2=0;temp2<=T.length-1;temp2++){
20 printf("(%d): %d \n",temp2+1,next[temp2]);
21 }
22 }
23
24 int Index_KPM(SString S,SString T,int next[]){//书上给的,运行有点问题。。。。
25 int m=1,n=1;
26 while(m<=S.length&&n<=T.length){
27 if(n==0||S.ch[m]==T.length){
28 printf("匹配T[m=%d] P[n=%d]:%c %c \n",m,n,S.ch[m],T.ch[n]);
29 ++m;++n;
30 }
31 else{
32 n=next[n];
33 }
34 if(n>T.length){
35 return m-T.length;
36 }
37 else{return 0;}
38 }
39 }
是挺简洁,但是我运行它结果。。。看不太懂,不知道求的是什么。然后,我按照PM表的规律用递归算法实现了一下:
1 void fun_MN(int num,int next[],SString P,int stationary){
2 if(P.ch[stationary-1]==P.ch[next[num]-1]){
3 printf("匹配成功num = %d P.ch[stationary-1] %c 和 P.ch[next[num]-1 = %d ] %c \n",num,P.ch[stationary-1],next[num]-1,P.ch[next[num]-1]);
4 next[stationary+1]=next[num]+1;
5 printf("此刻,next[%d]: %d \n",stationary+1,next[stationary+1]);
6 }
7 else{
8 printf("匹配失败num= %d ,next[num]-1 %d , P.ch[stationary-1] %c 和 P.ch[next[num]-1] %c \n",num,P.ch[num-1],P.ch[stationary-1],P.ch[next[num]-1]);
9 printf("下面看看还有没有次一级合适的匹配值,此刻num = %d next[num] = %d 下面令 num = next[num]= %d \n",num,next[num],next[num]);
10 if(next[num]==0){
11 next[stationary+1]=1;
12 printf("可以确定,此刻num= %d 没有合适的匹配值 next[stationary] = %d next[stationary+1] = %d \n",num,next[stationary],next[stationary+1]);
13 }
14 else{
15 printf("stationary %d",stationary);
16 fun_MN(next[num],next,P,stationary);
17 }
18 }
19 }
20 void Get_next_own(SString P,int next[]){
21 next[1]=0,next[2]=1;
22 int num=2;
23 for(num;num<P.length;num++){
24 fun_MN(num,next,P,num);}
25
26 printf("制作的表单为:\n");
27 for(int temp2=0;temp2<=P.length;temp2++){
28 printf("(%d): %d \n",temp2+1,next[temp2]);
29 }
运行结果展示:
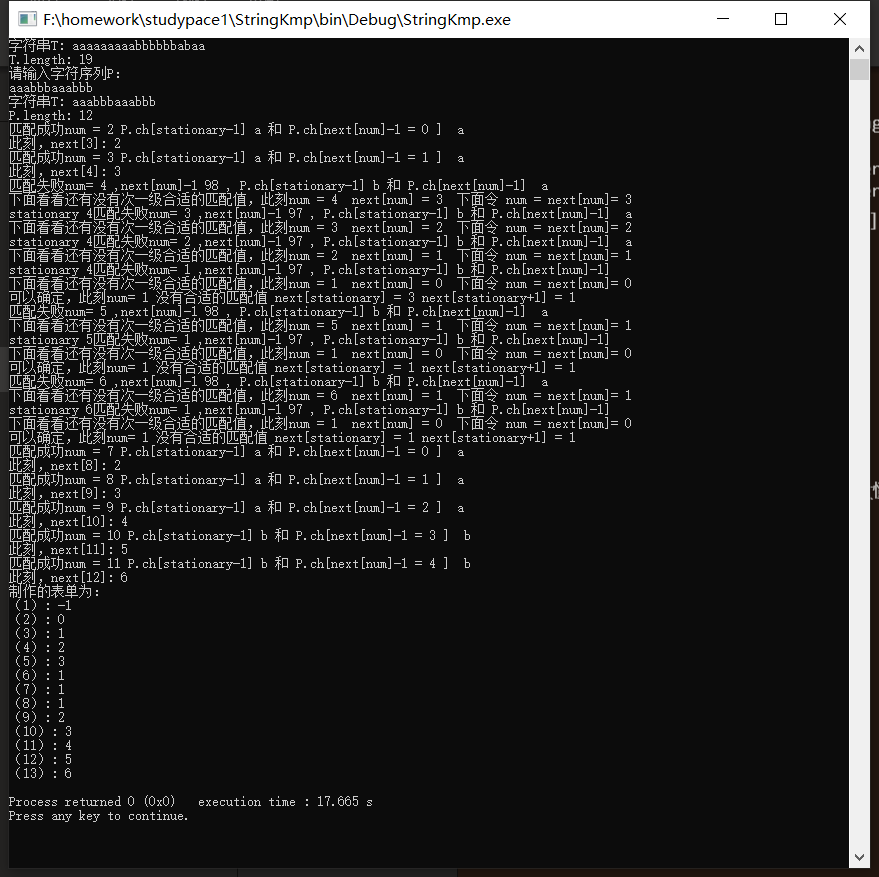
|
序号num |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
模式串 |
a |
a |
a |
b |
b |
b |
a |
a |
a |
b |
b |
b |
|
next[num] |
0 |
1 |
2 |
3 |
1 |
1 |
1 |
2 |
3 |
4 |
5 |
6 |
实际上,最左边还有一个next[0],里面也不知道存储的什么上面的-1存粹巧合。最右面的按照这里next[14]理应等于7,不过溢出消除了,而且也用不上就被舍弃了。
至于匹配方法还是很简单的:这里只要用next[j]-1,代替原来的,j前部分最大匹配值Max_march就可以了。
int Index_KPM_Own(SString T,SString P){
//next表KMP匹配算法
int i=1;
int j=1;
//注意这里的i和j分别代表的是母串和模式串的字符序号而不是角标
int next[P.length];
Get_next_own(P,next);
int temp1=0;
int Max_march;
while(i<=T.length && j<=P.length){
if(T.ch[i-1]==P.ch[j-1]){
printf("匹配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
++i;
++j;
//继续比较后面的字符
}
else{
printf("发生失配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
// Max_march=next[j]-1;//判断已经匹配的temp1个字符里面,最大的相同前后缀字符子串长度
printf("此刻最大的前后缀匹配值= %d \n",next[j]-1);
if(j==1){//当第一个匹配值就不匹配时;匹配串右移一位,母串指针i右移一位
i++;
}
// else if(Max_march==0){
else if(next[j]==1){
j=1;
}
else{
// j=Max_march+1;
j=next[j]-1+1;//如果匹配串拥有前后缀匹配的字符串的话
continue;
}
//指针后退,模式串T右移,重新开始匹配
}
if(j==P.length+1){return i-P.length;}
}
return 0;
}
运行结果展示:
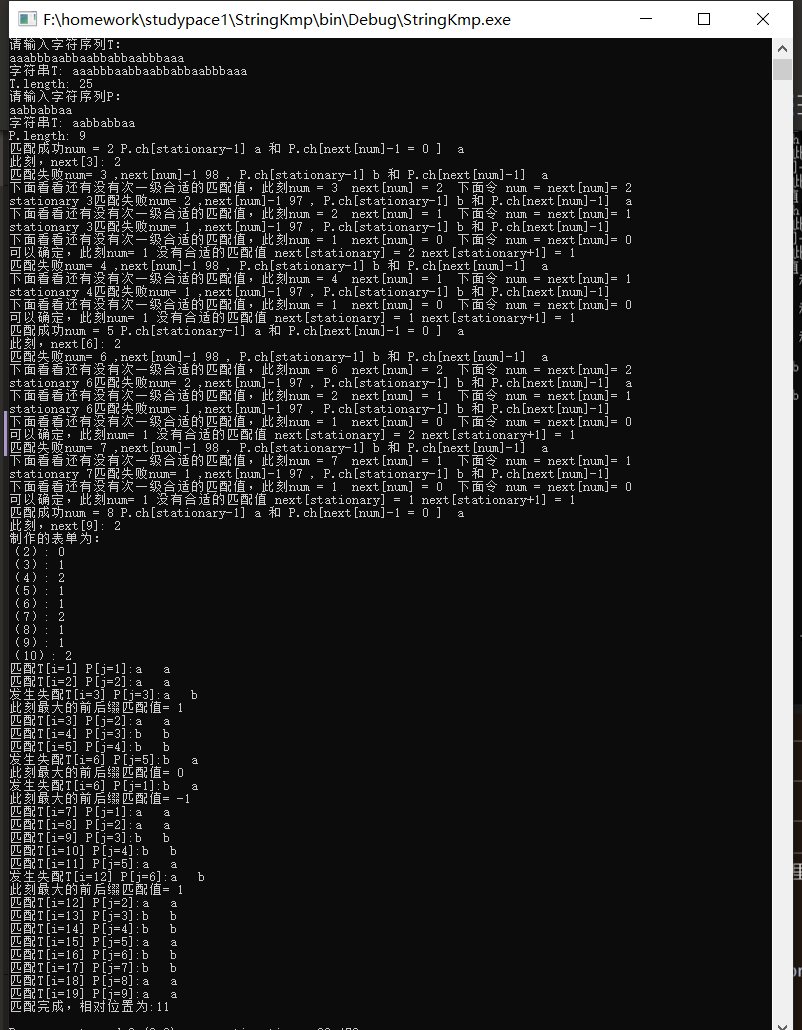
(五)KPM算法的进一步优化:KPMpro~
原算法实现的时候,存在一定的问题,大概……是这样的:
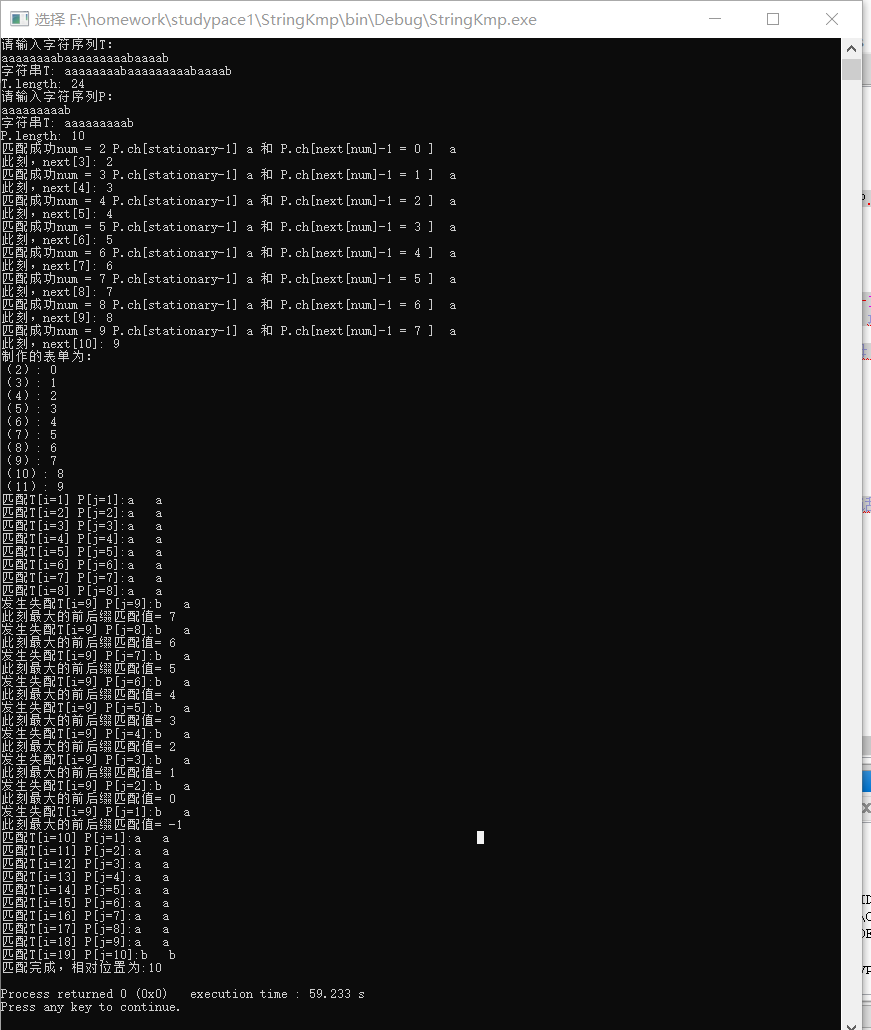
请关注这里,我么进行了9次b和a的比较,分别是在T[i=9]=a, P[j=9]=b 比较时发生失配。
继而进行了P[j=1]到P[j=9]分别和T[9]的比较,而实际上字串这部分都是a。
关键原因是,在T[i]和P[j]发生失配时,我们会继续用T[i]和P[next[j]进行匹配,但是当P[j]==P[next[j]]的时候这样做变得毫无意义。特别是在字串具有大量的相同字符的时候问题会更突出。
那么怎么进行优化呢?
之前我们进行了制next表,我们可以对next的值进行优化,原本在失配后是要进行T[i]和P[next[j]匹配判断的。如果我们在此之前,在制表的时候,就在确定next[j]的值的时候便将P[j]、P[next[j]]的值和P[next[next[j]]]……进行递归比对一至,我们就直接把后者的next[]值赋给前者的对应新数组varnext,这样当在发生失配的时候会直接计算T[i]和P[varnext[j]的值,进而避免多次匹配。
void fun_MN(int num,int next[],SString P,int stationary){
//求next表单的递归函数,这个鬼函数用完之后,返回给其他函数的时候,有时候会出现“吃一半临时参数P[j]”的情况,到现在也不知道为什么,所以新
//写的计算nextpro函数不能和他在一个三层函数使用,就分开写了。
if(P.ch[stationary-1]==P.ch[next[num]-1]){
printf("匹配成功num = %d P.ch[stationary-1] %c 和 P.ch[next[num]-1 = %d ] %c \n",num,P.ch[stationary-1],next[num]-1,P.ch[next[num]-1]);
next[stationary+1]=next[num]+1;
printf("此刻,next[%d]: %d \n",stationary+1,next[stationary+1]);
}
else{
printf("匹配失败num= %d ,next[num]-1 %d , P.ch[stationary-1] %c 和 P.ch[next[num]-1] %c \n",num,P.ch[num-1],P.ch[stationary-1],P.ch[next[num]-1]);
printf("下面看看还有没有次一级合适的匹配值,此刻num = %d next[num] = %d 下面令 num = next[num]= %d \n",num,next[num],next[num]);
if(next[num]==0){
next[stationary+1]=1;
printf("可以确定,此刻num= %d 没有合适的匹配值 next[stationary] = %d next[stationary+1] = %d \n",num,next[stationary],next[stationary+1]);
}
else{
printf("stationary %d",stationary);
fun_MN(next[num],next,P,stationary);
}
}
}
void fun_MN_Pro(int next[],SString P,int next_pro[]){
//求nextpro
int temp1=1;
int temp2;
for(int r=1;r<=P.length;r++){
next_pro[r]=next[r];
}
// printf("P.ch[0]? %c P.ch[1] %c \n",P.ch[0],P.ch[1]);
// printf("赋值后的表单next_pro为:\n");
// for(int temp4=1;temp4<=P.length;temp4++){
// printf("(%d): %d \n",temp4+1,next_pro[temp4]);
// }
for(temp1;temp1<=P.length-1;temp1++){
for(temp2=temp1+1;temp2<=P.length;temp2++){
if(next_pro[temp2]==temp1){
// printf("匹配成功! temp1 = %d temp2 = %d 此时进行的是 next[temp2]= %d 同 temp1 = %d 的比较,\n",temp1,temp2,next[temp2],temp1);
if(P.ch[temp1-1]==P.ch[temp2-1]){
// printf("匹配成功! temp1 = %d temp2 = %d 此刻进行的是P.ch[temp1-1] = %c 同 P.ch[temp2-1] %c 的比较 \n",temp1,temp2,P.ch[temp1-1],P.ch[temp2-1]);
// printf("进行赋值, temp1 = %d temp2 = %d next_pro[temp2]原值为 %d ,现将next_pro[temp1] 的值 %d 赋给他。\n",temp1,temp2,next_pro[temp2],next_pro[temp1]);
next_pro[temp2]=next_pro[temp1];
}
// printf("匹配失败! temp1 = %d temp2 = %d 这时候我们是将 P.ch[temp1-1]= %c 同 P.ch[temp2-1] = %c 进行比较。\n",temp1,temp2,P.ch[temp1-1],P.ch[temp2-1]);
}
// printf("匹配失败! temp1 = %d temp2 = %d 此时进行的是 next[temp2]= %d 同 temp1 = %d 的比较,\n",temp1,temp2,next[temp2],temp1);
}
printf("外循环第 %d 遍结束,next_pro为:\n",temp1);
for(int temp3=1;temp3<=P.length;temp3++){
printf("(%d): %d \n",temp3,next_pro[temp3]);
}
}
printf("fun_MN_Pro函数over!");
}
void Get_next_own_Pro(SString P,int next[]){
//调用第一个函数计算next表
next[1]=0;
next[2]=1;
int num=2;
for(num;num<P.length;num++){
fun_MN(num,next,P,num);}
printf("制作的表单next为:\n");
for(int temp2=1;temp2<=P.length;temp2++){
printf("(%d): %d \n",temp2+1,next[temp2]);
}}
int Index_KPM_Own_Pro(SString T,SString P){
//next表KMP匹配算法
int i=1;
int j=1;
//注意这里的i和j分别代表的是母串和模式串的字符序号而不是角标
int next[P.length];
int next_pro[P.length];
Get_next_own_Pro(P,next);
fun_MN_Pro(next,P,next_pro);
printf("制作的表单next_pro为:\n");
for(int temp2=1;temp2<=P.length;temp2++){
printf("(%d) %d \n",temp2+1,next_pro[temp2]);
}
printf("baoxianqijian制作的表单next_pro为:\n");
for(int temp2=1;temp2<=P.length;temp2++){
printf("(%d): %d \n",temp2+1,next_pro[temp2]);
}
while(i<=T.length && j<=P.length){
if(T.ch[i-1]==P.ch[j-1]){
printf("匹配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
++i;
++j;
//继续比较后面的字符
}
else{
printf("发生失配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
if(j==1){//当第一个匹配值就不匹配时;匹配串右移一位,母串指针i右移一位
i++;
}
else if(next_pro[j]==0){
j=1;
i++;
}
else{
j=next_pro[j];//如果匹配串拥有前后缀匹配的字符串的话
continue;
}
//指针后退,模式串T右移,重新开始匹配
}
if(j==P.length+1){return i-P.length;}
}
return 0;
}
结果展示:
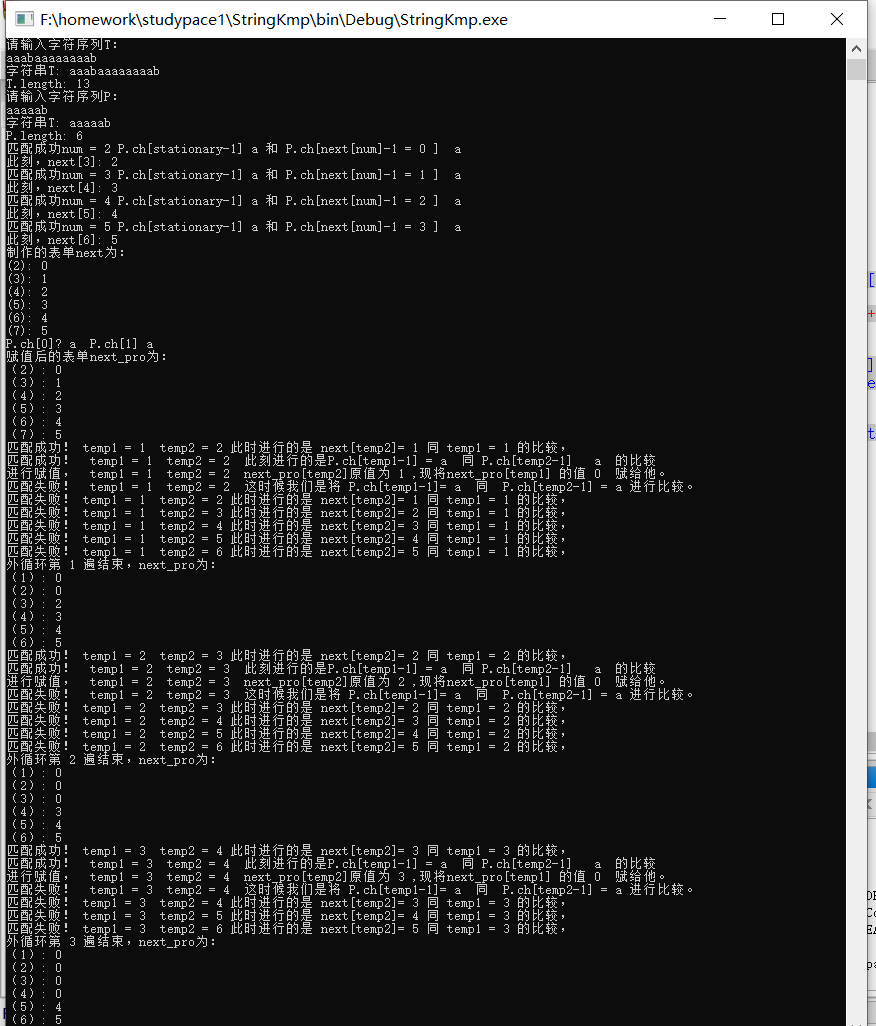
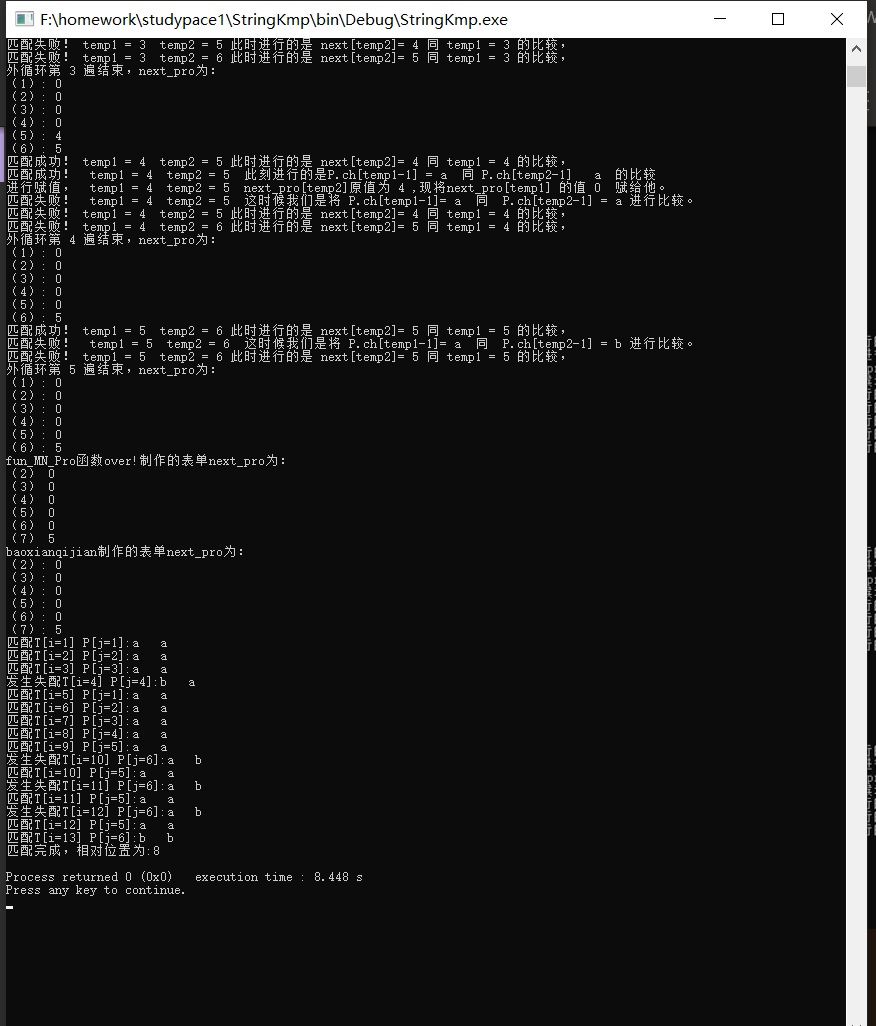
母串:aaabaaaaaaaab
模式串:aaaaab
关注这里,已经不会再进行之前大量无用匹配了!
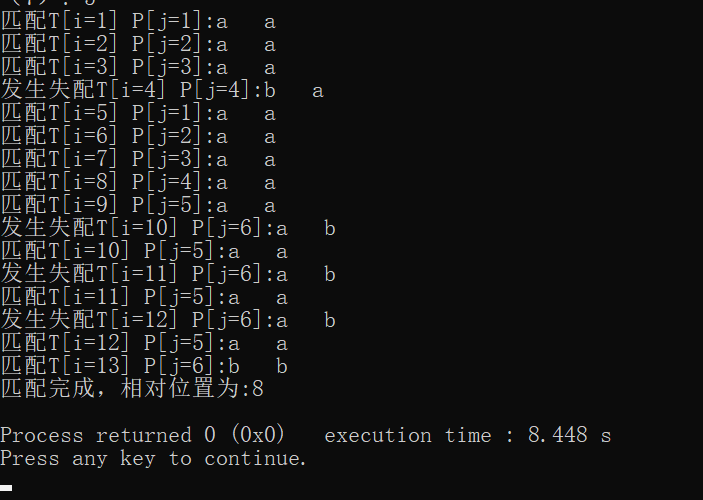
ps:最后把左右代码进行统一贴附:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <string.h>
4 #define MaxSize 100
5
6 typedef struct String{
7 char ch[MaxSize];
8 int length;
9 }SString,*String;
10
11 int Index(SString T,SString P){
12 //暴力匹配方法
13 int i=1;
14 int j=1;
15 while(i<=T.length && j<=P.length){
16 if(T.ch[i-1]==P.ch[j-1]){
17 printf("匹配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
18 ++i;
19 ++j;
20 //继续比较后面的字符
21 }
22 else{
23 printf("发生失配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
24 i = i-j+2;
25 j=1;
26 //指针后退,模式串T右移,重新开始匹配
27 }
28 if(j==P.length+1){return i-P.length;}
29 }
30 return 0;
31 }
32
33 int SectionMarch(SString P,int temp1){//模式串和已匹配数,返回最长的前缀等于后缀的缀的长度
34 for(int Q=1;Q<temp1;Q++){//从第大到小进行部分匹配,每次匹配长度为temp1-Q
35 for(int i=0;i<=temp1-Q-1;i++){
36 if(P.ch[temp1-Q-i-1]==P.ch[temp1-i-1]){}
37 else{ break;}
38
39 if(i==temp1-Q-1){return temp1-Q;}
40 }
41 }
42 return 0;
43 }
44
45 int PMIndex(SString T,SString P){
46 //模拟人工匹配方法
47 int i=1;
48 int j=1;
49 //注意这里的i和j分别代表的是母串和模式串的字符序号而不是角标
50 int temp1=0;
51 int Max_march;
52
53 while(i<=T.length && j<=P.length){
54 if(T.ch[i-1]==P.ch[j-1]){
55 printf("匹配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
56 ++i;
57 ++j;
58 temp1++;//记录匹配次数
59 //继续比较后面的字符
60 }
61 else{
62 printf("发生失配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
63 Max_march=SectionMarch(P,temp1);//判断已经匹配的temp1个字符里面,最大的相同前后缀字符子串长度
64 printf("最大匹配值为:%d \n temp1=%d \n",Max_march,temp1);
65 if(j==1){//当第一个匹配值就不匹配时;匹配串右移一位,母串指针i右移一位
66 i++;
67 }
68 else if(Max_march==0){
69 j=1;
70 }
71 else{
72 j=Max_march+1;//如果匹配串拥有前后缀匹配的字符串的话
73 }
74 temp1 = 0;
75 //指针后退,模式串T右移,重新开始匹配
76 }
77 if(j==P.length+1){return i-P.length;}
78 }
79 return 0;
80 }
81
82 int PMListIndex(SString T,SString P){
83 //模拟PM表匹配方法
84 int i=1;
85 int j=1;
86 //注意这里的i和j分别代表的是母串和模式串的字符序号而不是角标
87 int temp1=0;
88 int Max_march;
89 int section_march[P.length];//对应模式串的PM匹配表
90 section_march[0]=0;//将P[1]前面的空置字符和T[i]对齐
91 section_march[1]=0;
92 for(int temp2=2;temp2<=P.length-1;temp2++){
93 section_march[temp2]=SectionMarch(P,temp2);
94 }
95 printf("制作的表单为:\n");
96 for(int temp2=0;temp2<=P.length-1;temp2++){
97 printf("当第j=%d 个字符失配时,其已匹配字符串的最大部分匹配值为:%d \n",temp2+1,section_march[temp2]);
98 }
99
100 while(i<=T.length && j<=P.length){
101 if(T.ch[i-1]==P.ch[j-1]){
102 printf("匹配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
103 ++i;
104 ++j;
105 temp1++;//记录匹配次数
106 //继续比较后面的字符
107 }
108 else{
109 printf("发生失配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
110 Max_march=section_march[temp1];//判断已经匹配的temp1个字符里面,最大的相同前后缀字符子串长度
111 if(j==1){//当第一个匹配值就不匹配时;匹配串右移一位,母串指针i右移一位
112 i++;
113 }
114 else if(Max_march==0){
115 j=1;
116 }
117 else{
118 j=Max_march+1;//如果匹配串拥有前后缀匹配的字符串的话
119 }
120 temp1 = 0;
121 //指针后退,模式串T右移,重新开始匹配
122 }
123 if(j==P.length+1){return i-P.length;}
124 }
125 return 0;
126 }
127 int ProPMListIndex(SString T,SString P){
128 //模拟PM表匹配方法
129 int i=1;
130 int j=1;
131 //注意这里的i和j分别代表的是母串和模式串的字符序号而不是角标
132 int temp1=0;
133 int Max_march;
134 int section_march[P.length];//对应模式串的PM匹配表
135 section_march[0]=0;//将P[1]前面的空置字符和T[i]对齐
136 section_march[1]=0;
137 if(P.length>6){
138 for(int temp2=2;temp2<6;temp2++){
139 section_march[temp2]=SectionMarch(P,temp2);
140 printf("(%d) 暴力计算:%d \n",temp2,section_march[temp2]);
141 }
142 for(int temp2=6;temp2<=P.length-1;temp2++){
143 printf("顺利进入第 %d 次外循环;\n",temp2-5);
144 int section_march_temp1;
145 section_march_temp1=temp2;
146 for(int section_march_temp=section_march[temp2-1];section_march_temp1!=0;section_march_temp=section_march[section_march_temp]){
147 int h=1;
148 printf("顺利进入第 %d 次内循环;\n",h);
149 printf("此刻,section_march_temp: %d P.ch[section_march_temp]: %c temp2-1: %d P.ch[temp2-1]: %c \n",section_march_temp,P.ch[section_march_temp],temp2-1,P.ch[temp2-1]);
150 if(P.ch[section_march_temp]==P.ch[temp2-1]){
151 printf("P.ch[section_march_temp= %d]= %c 和 P.ch[temp2-1= %d] = %c 比较判断成功 \n",section_march_temp,P.ch[section_march_temp],P.ch[temp2-1]);
152 section_march[temp2]=section_march[section_march_temp1-1]+1;
153 printf("判断成功后,section_march[temp2 = %d ]= %d",temp2, section_march[temp2]);
154 break;}
155
156 printf("匹配失败,进行深一层内循环比对。\n");
157
158
159 if(section_march[section_march_temp]==0){
160 section_march[temp2+1]=0;
161 }
162 section_march_temp1= section_march_temp;
163 h++;
164 }
165 }
166 }
167 else{
168 for(int temp2=2;temp2<=P.length-1;temp2++){
169 section_march[temp2]=SectionMarch(P,temp2);
170 }
171 }
172
173 printf("制作的表单为:\n");
174 for(int temp2=0;temp2<=P.length-1;temp2++){
175 printf("当第j=%d 个字符失配时,其已匹配字符串的最大部分匹配值为:%d \n",temp2+1,section_march[temp2]);
176 }
177
178 while(i<=T.length && j<=P.length){
179 if(T.ch[i-1]==P.ch[j-1]){
180 printf("匹配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
181 ++i;
182 ++j;
183 temp1++;//记录匹配次数
184 //继续比较后面的字符
185 }
186 else{
187 printf("发生失配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
188 Max_march=section_march[temp1];//判断已经匹配的temp1个字符里面,最大的相同前后缀字符子串长度
189 printf("此刻最大的前后缀匹配值= %d \n",Max_march);
190 if(j==1){//当第一个匹配值就不匹配时;匹配串右移一位,母串指针i右移一位
191 i++;
192 }
193 else if(Max_march==0){
194 j=1;
195 }
196 else{
197 j=Max_march+1;//如果匹配串拥有前后缀匹配的字符串的话
198 temp1 = Max_march;
199 continue;
200 }
201 temp1 = 0;
202 //指针后退,模式串T右移,重新开始匹配
203 }
204 if(j==P.length+1){return i-P.length;}
205 }
206 return 0;
207 }
208
209 int KMPIndex(SString T,SString P){
210 //模拟PM表匹配方法
211 int i=1;
212 int j=1;
213 //注意这里的i和j分别代表的是母串和模式串的字符序号而不是角标
214 int temp1=0;
215 int Max_march;
216 int section_march[P.length];//对应模式串的PM匹配表
217 section_march[0]=-1;//将P[1]前面的空置字符和T[i]对齐
218 section_march[1]=0;
219
220
221 for(int temp2=2;temp2<=P.length-1;temp2++){
222 printf("顺利进入第 %d 次外循环;\n",temp2-1);
223 int section_march_temp1;
224 section_march_temp1=temp2;
225 int h=1;
226 for(int section_march_temp=section_march[temp2-1];section_march_temp1!=-1;section_march_temp=section_march[section_march_temp]){
227 printf("顺利进入第 %d 次内循环;\n",h);
228 printf("此刻,section_march_temp: %d P.ch[section_march_temp]: %c temp2-1: %d P.ch[temp2-1]: %c \n",section_march_temp,P.ch[section_march_temp],temp2-1,P.ch[temp2-1]);
229 if(P.ch[section_march_temp]==P.ch[temp2-1]){
230 printf("P.ch[section_march_temp= %d]= %c 和 P.ch[temp2-1= %d] = %c 比较判断成功 \n",section_march_temp,P.ch[section_march_temp],P.ch[temp2-1]);
231 section_march[temp2]=section_march[section_march_temp1-1]+1;
232 printf("判断成功后,section_march[temp2 = %d ]= %d \n",temp2, section_march[temp2]);
233 break;}
234 printf("匹配失败,进行深一层内循环比对。\n");
235 section_march_temp1= section_march_temp;
236 if(section_march[section_march_temp]==-1){
237 printf("没有合适的匹配值,即将退出内循环,section_march[%d]=0 \n",temp2);
238 section_march[temp2]=0;
239 }
240 printf("此刻section_march_temp1= %d \n",section_march_temp1);
241
242 h++;
243 }
244 }
245
246
247 printf("制作的表单为:\n");
248 for(int temp2=0;temp2<=P.length-1;temp2++){
249 printf("当第j=%d 个字符失配时,其已匹配字符串的最大部分匹配值为:%d \n",temp2+1,section_march[temp2]);
250 }
251
252 while(i<=T.length && j<=P.length){
253 if(T.ch[i-1]==P.ch[j-1]){
254 printf("匹配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
255 ++i;
256 ++j;
257 //继续比较后面的字符
258 }
259 else{
260 printf("发生失配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
261 Max_march=section_march[j-1];//判断已经匹配的temp1个字符里面,最大的相同前后缀字符子串长度
262 printf("此刻最大的前后缀匹配值= %d \n",Max_march);
263 if(j==1){//当第一个匹配值就不匹配时;匹配串右移一位,母串指针i右移一位
264 i++;
265 }
266 else if(Max_march==0){
267 j=1;
268 }
269 else{
270 j=Max_march+1;//如果匹配串拥有前后缀匹配的字符串的话
271 continue;
272 }
273 //指针后退,模式串T右移,重新开始匹配
274 }
275 if(j==P.length+1){return i-P.length;}
276 }
277 return 0;
278 }
279 void get_next(SString T,int next[]){
280 int i=1;
281 int j=0;
282 next[1]=0;
283 // next[2]=1;
284 while(i<T.length){
285 if(j==0||T.ch[i]==T.ch[j]){
286 printf("匹配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i],T.ch[j]);
287 ++i,++j;
288 next[i]=j;
289 printf("next[i= %d] j= %d \n",i,j);
290 }
291 else{
292 printf("失配!不能执行+1操作,对j递归,j=next[j= %d ]:%d \n",j,next[j]);
293 j=next[j];
294 }
295 }
296 printf("制作的表单为:\n");
297 for(int temp2=0;temp2<=T.length-1;temp2++){
298 printf("(%d): %d \n",temp2+1,next[temp2]);
299 }
300 }
301
302 int Index_KPM(SString S,SString T,int next[]){//书上给的,运行有点问题。。。。
303 int m=1,n=1;
304 while(m<=S.length&&n<=T.length){
305 if(n==0||S.ch[m]==T.length){
306 printf("匹配T[m=%d] P[n=%d]:%c %c \n",m,n,S.ch[m],T.ch[n]);
307 ++m;++n;
308 }
309 else{
310 n=next[n];
311 }
312 if(n>T.length){
313 return m-T.length;
314 }
315 else{return 0;}
316 }
317 }
318
319
320 void fun_MN(int num,int next[],SString P,int stationary){
321 if(P.ch[stationary-1]==P.ch[next[num]-1]){
322 printf("匹配成功num = %d P.ch[stationary-1] %c 和 P.ch[next[num]-1 = %d ] %c \n",num,P.ch[stationary-1],next[num]-1,P.ch[next[num]-1]);
323 next[stationary+1]=next[num]+1;
324 printf("此刻,next[%d]: %d \n",stationary+1,next[stationary+1]);
325 }
326 else{
327 printf("匹配失败num= %d ,next[num]-1 %d , P.ch[stationary-1] %c 和 P.ch[next[num]-1] %c \n",num,P.ch[num-1],P.ch[stationary-1],P.ch[next[num]-1]);
328 printf("下面看看还有没有次一级合适的匹配值,此刻num = %d next[num] = %d 下面令 num = next[num]= %d \n",num,next[num],next[num]);
329 if(next[num]==0){
330 next[stationary+1]=1;
331 printf("可以确定,此刻num= %d 没有合适的匹配值 next[stationary] = %d next[stationary+1] = %d \n",num,next[stationary],next[stationary+1]);
332 }
333 else{
334 printf("stationary %d",stationary);
335 fun_MN(next[num],next,P,stationary);
336 }
337 }
338 }
339
340 void Get_next_own(SString P,int next[]){
341 next[1]=0;
342 next[2]=1;
343 int num=2;
344 for(num;num<P.length;num++){
345 fun_MN(num,next,P,num);}
346
347 printf("制作的表单为:\n");
348 for(int temp2=1;temp2<=P.length;temp2++){
349 printf("(%d): %d \n",temp2+1,next[temp2]);
350 }
351 }
352
353 int Index_KPM_Own(SString T,SString P){
354 //next表KMP匹配算法
355 int i=1;
356 int j=1;
357 //注意这里的i和j分别代表的是母串和模式串的字符序号而不是角标
358 int next[P.length];
359 Get_next_own(P,next);
360 int temp1=0;
361 int Max_march;
362 while(i<=T.length && j<=P.length){
363 if(T.ch[i-1]==P.ch[j-1]){
364 printf("匹配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
365 ++i;
366 ++j;
367 //继续比较后面的字符
368 }
369 else{
370 printf("发生失配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
371 // Max_march=next[j]-1;//判断已经匹配的temp1个字符里面,最大的相同前后缀字符子串长度
372 printf("此刻最大的前后缀匹配值= %d \n",next[j]-1);
373 if(j==1){//当第一个匹配值就不匹配时;匹配串右移一位,母串指针i右移一位
374 i++;
375 }
376 // else if(Max_march==0){
377 else if(next[j]==1){
378 j=1;
379 }
380 else{
381 // j=Max_march+1;
382 j=next[j]-1+1;//如果匹配串拥有前后缀匹配的字符串的话
383 continue;
384 }
385 //指针后退,模式串T右移,重新开始匹配
386 }
387 if(j==P.length+1){return i-P.length;}
388 }
389 return 0;
390 }
391
392 void fun_MN_Pro(int next[],SString P,int next_pro[]){
393 int temp1=1;
394 int temp2;
395 for(int r=1;r<=P.length;r++){
396 next_pro[r]=next[r];
397 }
398 printf("P.ch[0]? %c P.ch[1] %c \n",P.ch[0],P.ch[1]);
399 printf("赋值后的表单next_pro为:\n");
400 for(int temp4=1;temp4<=P.length;temp4++){
401 printf("(%d): %d \n",temp4+1,next_pro[temp4]);
402 }
403 for(temp1;temp1<=P.length-1;temp1++){
404 for(temp2=temp1+1;temp2<=P.length;temp2++){
405 if(next_pro[temp2]==temp1){
406 printf("匹配成功! temp1 = %d temp2 = %d 此时进行的是 next[temp2]= %d 同 temp1 = %d 的比较,\n",temp1,temp2,next[temp2],temp1);
407 if(P.ch[temp1-1]==P.ch[temp2-1]){
408 printf("匹配成功! temp1 = %d temp2 = %d 此刻进行的是P.ch[temp1-1] = %c 同 P.ch[temp2-1] %c 的比较 \n",temp1,temp2,P.ch[temp1-1],P.ch[temp2-1]);
409 printf("进行赋值, temp1 = %d temp2 = %d next_pro[temp2]原值为 %d ,现将next_pro[temp1] 的值 %d 赋给他。\n",temp1,temp2,next_pro[temp2],next_pro[temp1]);
410 next_pro[temp2]=next_pro[temp1];
411 }
412 printf("匹配失败! temp1 = %d temp2 = %d 这时候我们是将 P.ch[temp1-1]= %c 同 P.ch[temp2-1] = %c 进行比较。\n",temp1,temp2,P.ch[temp1-1],P.ch[temp2-1]);
413 }
414 printf("匹配失败! temp1 = %d temp2 = %d 此时进行的是 next[temp2]= %d 同 temp1 = %d 的比较,\n",temp1,temp2,next[temp2],temp1);
415 }
416 printf("外循环第 %d 遍结束,next_pro为:\n",temp1);
417 for(int temp3=1;temp3<=P.length;temp3++){
418 printf("(%d): %d \n",temp3,next_pro[temp3]);
419 }
420 }
421 printf("fun_MN_Pro函数over!");
422 }
423
424 void Get_next_own_Pro(SString P,int next[]){
425 next[1]=0;
426 next[2]=1;
427 int num=2;
428 for(num;num<P.length;num++){
429 fun_MN(num,next,P,num);}
430
431 printf("制作的表单next为:\n");
432 for(int temp2=1;temp2<=P.length;temp2++){
433 printf("(%d): %d \n",temp2+1,next[temp2]);
434 }}
435
436
437
438 int Index_KPM_Own_Pro(SString T,SString P){
439 //next表KMP匹配算法
440 int i=1;
441 int j=1;
442 //注意这里的i和j分别代表的是母串和模式串的字符序号而不是角标
443 int next[P.length];
444 int next_pro[P.length];
445 Get_next_own_Pro(P,next);
446
447 fun_MN_Pro(next,P,next_pro);
448 printf("制作的表单next_pro为:\n");
449 for(int temp2=1;temp2<=P.length;temp2++){
450 printf("(%d) %d \n",temp2+1,next_pro[temp2]);
451 }
452
453 printf("baoxianqijian制作的表单next_pro为:\n");
454 for(int temp2=1;temp2<=P.length;temp2++){
455 printf("(%d): %d \n",temp2+1,next_pro[temp2]);
456 }
457 // int Max_march;
458 while(i<=T.length && j<=P.length){
459 if(T.ch[i-1]==P.ch[j-1]){
460 printf("匹配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
461 ++i;
462 ++j;
463 //继续比较后面的字符
464 }
465 else{
466 printf("发生失配T[i=%d] P[j=%d]:%c %c \n",i,j,T.ch[i-1],P.ch[j-1]);
467 // Max_march=next[j]-1;//判断已经匹配的temp1个字符里面,最大的相同前后缀字符子串长度
468 // printf("此刻最大的前后缀匹配值= %d \n",next[j]-1);
469 if(j==1){//当第一个匹配值就不匹配时;匹配串右移一位,母串指针i右移一位
470 i++;
471 }
472 // else if(Max_march==0){
473 else if(next_pro[j]==0){
474 j=1;
475 i++;
476 }
477 else{
478 // j=Max_march+1;
479 j=next_pro[j];//如果匹配串拥有前后缀匹配的字符串的话
480 continue;
481 }
482 //指针后退,模式串T右移,重新开始匹配
483 }
484 if(j==P.length+1){return i-P.length;}
485 }
486 return 0;
487 }
488
489
490
491
492 int main(){
493 SString T;
494 SString P;
495
496 int situated;
497 printf("请输入字符序列T:\n");
498 scanf("%s",&T.ch);
499 printf("字符串T: %s \n",T.ch);
500 T.length=strlen(T.ch);
501 printf("T.length: %d \n",T.length);
502
503 printf("请输入字符序列P:\n");
504 scanf("%s",&P.ch);
505 printf("字符串T: %s \n",P.ch);
506 P.length=strlen(P.ch);
507 printf("P.length: %d \n",P.length);
508
509 // situated =KMPIndex(T,P);
510 // int next[P.length];
511 // get_next(P,next);
512 situated =Index_KPM_Own_Pro(T,P);
513 printf("匹配完成,相对位置为:%d \n",situated);
514 // Get_next_own(P,next);
515 return 0;}
KMP算法学习记录的更多相关文章
- 字符串匹配算法——KMP算法学习
KMP算法是用来解决字符串的匹配问题的,即在字符串S中寻找字符串P.形式定义:假设存在长度为n的字符数组S[0...n-1],长度为m的字符数组P[0...m-1],是否存在i,使得SiSi+1... ...
- KMP算法学习以及小结(好马不吃回头草系列)
首先请允许我对KMP算法的三位创始人Knuth,Morris,Pratt致敬,这三位优秀的算法科学家发明的这种匹配模式可以大大避免重复遍历的情况,从而使得字符串的匹配的速度更快,效率更高. 首先引入对 ...
- KMP算法学习
kmp算法完成的任务是:给定两个字符串O和f,长度分别为n和m,判断f是否在O中出现,如果出现则返回出现的位置.常规方法是遍历a的每一个位置,然后从该位置开始和b进行匹配,但是这种方法的复杂度是O(n ...
- KMP 算法 学习 整理
我自己整理的KMP算法的PDF文件:http://pan.baidu.com/s/1o8yKIi2提取密码:8291 别的就不多说啥了,感谢来自海子 博客园的 资料--
- KMP算法学习(详解)
kmp算法又称“看毛片”算法,是一个效率非常高的字符串匹配算法.不过由于其难以理解,所以在很长的一段时间内一直没有搞懂.虽然网上有很多资料,但是鲜见好的博客能简单明了地将其讲清楚.在此,综合网上比较好 ...
- 字符串匹配的BF算法和KMP算法学习
引言:关于字符串 字符串(string):是由0或多个字符组成的有限序列.一般写作`s = "123456..."`.s这里是主串,其中的一部分就是子串. 其实,对于字符串大小关系 ...
- kmp算法学习 与 传参试验(常回来看看)
之前在codeforces上做了一道类似KMP的题目,但由于之前没有好好掌握,现在又基本忘记,并没能解答.下面是对KMP算法的一点小总结. 首先KMP算法的核心是纸在匹配过程中,利用模式串的前后缀来加 ...
- KMP 算法学习
KMP算法是用来做字符串匹配的.关于字符串匹配,最简单最容易想到的方法是暴利查找,使用双重for循环处理. 该方法的时间复杂度为O((n-m+1)*m) (n为目标串T长度,m为模式串P长度, 从T中 ...
- Manacher回文串算法学习记录
FROM: http://hi.baidu.com/chenwenwen0210/item/482c84396476f0e02f8ec230 #include<stdio.h> #inc ...
- PID算法学习记录
最近做项目需要用到PID算法,这个本来是我的专业(控制理论与控制工程),可是我好像是把这个东西全部还给老师了. 没办法,只好抽时间来学习了. 先占个座,后续将持续更新!
随机推荐
- clickhouse不喜欢sql末尾分号
今天用python连clickhouse查数据,sql语句末尾加了分号,始终报错 Code: 62, e.displayText() = DB::Exception: Syntax error 删掉分 ...
- 关于 echarts 使用 geo 制作地图 tooltip 不显示问题(转)
原文地址 我之前遇到过这问题,单独设置 tooltip 没效果,geo 下面也有 tooltip 属性,但是也不管用,网上查了一下说 geo 不支持 tooltip 提示框显示,就自己根据 echar ...
- FME视频教程
FME视频教程 分为三种 10分钟 2011 2012
- iview table添加input框,且校验
方法一 render渲染 { title: "用户名", key: "stockPrice", render: (h, params) => { retu ...
- HttpWebResponse 四种accept-encoding解析(gzip, deflate, br,identity)
HttpWebResponse 四种accept-encoding解析(gzip, deflate, br,identity[默认]) var hwrs = (HttpWebRe ...
- 34.MySQL 架构
一主两从 双机热备 原理:
- vulnhub:My_Tomcat_Host靶机
kali:192.168.111.111 靶机:192.168.111.171 信息收集 端口扫描 nmap -A -v -sV -T5 -p- --script=http-enum 192.168. ...
- docker实战(8)使用docker-compose快速搭建zookeeper集群
镜像下载 docker pull zookeeper 复制 zookeeper 集群的搭建 创建名为docker-compose.yml的文件 输入以下内容 version: '2' services ...
- 使用vue的插槽理解
使用插槽的时候其实就是引用子组件,在引用的组件中间写上你要的代码,然后在子组件的的<slot ></slot>中就包含父组件写下的代码. 父组件 import addshop ...
- 逆向学习物联网-网关ESP8266-04系统联合调试
1.测试平台原理 2.搭建硬件测试平台 3.软件测试平台 1)串口终端 2)串口监视 3)OneNET后台服务 https://open.iot.10086.cn/passport/login/ 户名 ...