分布式搜索引擎Elasticsearch基础入门学习
一、Elasticsearch介绍
Elasticsearch介绍
Elasticsearh 是 elastic.co 公司开发的分布式搜索引擎。

Elasticsearch(简称ES)是一个开源的分布式、高度可扩展的全文搜索和分析引擎。它能够快速、近乎实时的存储、搜索和分析大量数据。适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型数据。
它通常为具有复杂搜索功能的应用提供底层搜索技术。
当然,它也可以用来实现分布式数据存储、日志统计、分析、系统监控、地理空间查询等功能。
Elasticsearch 最底层的搜索引擎技术是 Apache 基金会开源的搜索引擎类库 Lucene,Lucene 提供了搜索引擎核心 API 。
- Lucene 地址:https://lucene.apache.org/
ES 在 Lucene 的基础上提供了分布式支持,可以水平扩展,提供了 Restful 这种简洁的访问接口,能被任何语言调用。
- Elasticsearch 官网:https://www.elastic.co/
- github:https://github.com/elastic/elasticsearch
Elasticsearch能做什么
- 应用搜索,常见的 github 的代码搜索,滴滴,美团,点评,银行等各种搜索
- 网站搜索
- 日志记录和日志分析
- 基础设置指标和容器监控
- 应用性能监控
- 地理空间数据分析和可视化
- 商业分析
- 安全分析
二、ELK 是什么
ELK 是 Elasticsearch、Logstash 和 Kibana 的第一个字母组合,也叫 ELK Stack。是一套用于数据采集、存储、分析和可视化的开源工具集。
Elasticsearch:存储、索引、计算、搜索、分析数据。
Logstash:用于收集、转换数据,然后将它存储在 ES 中。后面还开发新的收集数据软件 Beats。
Beats:它是一个轻量级的数据采集代理工具,可以向 Elasticsearch 发送数据。
Kibana:用于查询分析、可视化 ES 的数据,它还可以用于监控和报警的方案。它是 Elasticsearch 基于浏览器的分析和搜索仪表盘。
它们之间关系图:
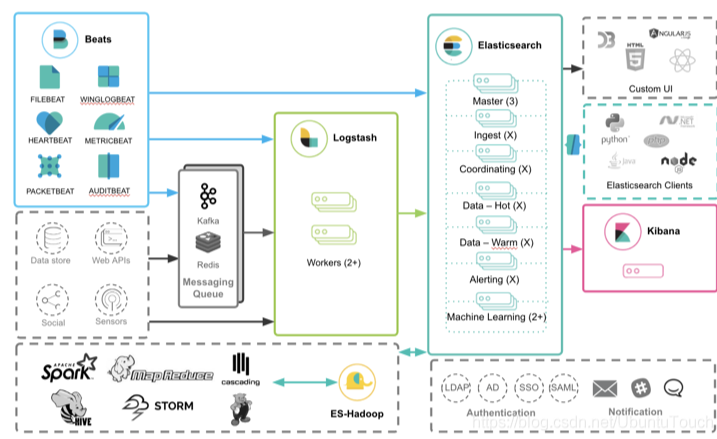
(来自:Elasticsearch 简介)
把上面的图简化下:
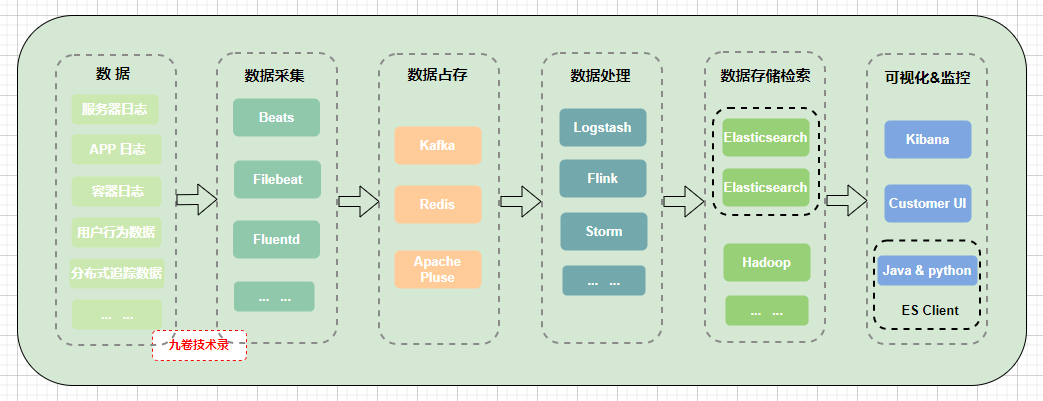
三、ES中的基础概念
文档document
Elasticsearch 是面向文档,它可以存储整个对象或文档。它不仅仅是存储,还会索引每个文档的内容使之可以被搜索。在 ES 中,你可以对文档进行索引、搜索、排序、过滤。
在 ES 中,文档是索引信息的基本单位。
JSON
Elasticsearch 使用 json 格式作为文档序列化格式。这种格式在 NoSQL 数据库中使用比较多。
一个 json 对象是由 key 和 value 组成。key 是字段(field)或属性(property)的名字,值(value)可以是字符串、数字、布尔类型、另外一个对象、值数组或其他特殊类型,比如表示日期的字符串或表示地理位置的对象。
在关系型数据库中,使用行和列存储数据,比如存储在 MySQL 表中的数据:
| id | name |
|---|---|
| 1 | 比亚迪电动车 |
| 2 | 理想电动车 |
| 3 | 小鹏电动车 |
| 4 | 比亚迪电池 |
| 5 | 理想电池 |
把上面的数据用 json 格式存储在 elasticsearch 中:
{
"id": 1,
"name": "比亚迪电动车"
}
{
"id": 2,
"name": "理想电动车"
}
{
"id": 3,
"name": "小鹏电动车"
}
{
"id": 4,
"name": "比亚迪电池"
}
{
"id": 5,
"name": "理想电池"
}
上面 json 中的字段 id 相当于 MySQL 数据表中列 id。
每个文档就是一条json数据。一条 json 数据相当于 MySQL 表中的一行。
索引index
index 索引是具有相似特征文档的集合。一个索引通过名字(必须全部是小写)来标识,并且在对其中的文档执行索引、搜索、更新和删除操作时,都会用到这个索引的名字。
索引可以是一个名词,相当于文档存储的地方。
索引也可以是一个动词,索引一个文档表示把一个文档存储到索引里,以便它可以被检索和查询。
例如,你有一个用户数据的索引,索引名称叫 user,每一份用户信息就是一个文档:
{
"id": 1,
"name": "tom",
"age": 25
},
{
"id": 2,
"name": "hanlei",
"age": 35
},
{
"id": 1,
"name": "tom",
"age": 25
},
{
"id": 3,
"name": "hanmeimei",
"age": 36
}
*类型type
类型 type 这个概念在 elasticsearch 7.X 已被完全移除(参考文档 Removal of mapping types)。这里就不作介绍。
映射mapping
映射(mapping)是索引文档中字段的类型和字段的其它信息,都存储在映射(mapping)中,它也叫模式定义(schema definition)。
相当于 MySQL 数据表的 schema,如定义表结构、字段名称、字段类型等信息。
而在 ES 中,映射可以设置某个字段的数据类型、默认值、分析器、是否被索引等等,其它处理 ES 里面的数据使用规则设置也叫映射。
mapping还有许多内容请查看文档:https://www.elastic.co/guide/en/elasticsearch/reference/8.4/mapping.html
mapping field doc:https://www.elastic.co/guide/en/elasticsearch/reference/8.4/mapping-fields.html
映射的设置:
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"message": {
"type": "text"
}
}
}
}
文档元数据
一个文档不仅仅包含 json 数据,也包含元数据 - 元数据是有关文档信息的一些数据。
创建映射时,可以自定义其中一些元数据字段的行为。例如,创建一个文档:
// 先创建一个映射mapping关系,相当于MySQL中表的schema,定义json文档中字段的属性
PUT test
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"message": {
"type": "text"
}
}
}
}
给文档写入一条数据:
// 给test索引写入一条json文档数据
PUT test/_doc/1
{
"id": "12",
"message": "hello world"
}
上面 PUT test/_doc/1 命令会返回一条信息:
{
"_index" : "test",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
- _index:表示文档所属的索引
- _id:文档唯一标识 ID
- _source:表示文档 doc 的原生 json 数据
- _size:整个 _source 字段的字节大小,它是由 mapper-size 插件提供
- _shards:表示索引的分片数。一个索引可以划分为多个 shards,这样就可以存储更多的数据
更多元数据信息请查看:https://www.elastic.co/guide/en/elasticsearch/reference/8.4/mapping-fields.html
分布式集群
节点node
一个节点node表示集群中的一台服务器,它作为集群的一部分存储数据,并参与集群的索引和搜索功能。
节点由名称标识,默认情况下是在启动时分配给节点的一个随机 UUID 唯一标识符。如果不想要默认值,可以自定义节点名称。
可以将节点通过集群名称加入特定集群中。默认情况下,每个节点都加入一个名为 “elasticsearch” 的集群中,这意味着如果
网络上启动了多个节点,它们可以相互发现,那么它们将自动形成一个名为 elasticsearch 的集群。
在单个集群中,你可以拥有任意数量的节点。
此外,如果网络上没有其它节点在运行,则会启动单个节点将默认形成一个名为 elasticsearch 的新节点集群。
集群cluster
集群(cluster)是由一个或多个节点node(服务器)组成,它们一起保存全部数据并提供跨所有节点的联合索引和搜索功能。集群由唯一标识符标识,默认为“elasticsearch”。这个名称很重要,因为一个节点被设置为通过名称加入集群时,该节点才能成为集群的一部分。
注意:拥有一个节点的集群也是完全可以的。
此外,你也可以拥有多个独立的集群,每个集群都拥有自己独立的名称。
分片shard和副本replica
索引可能会存储大量的数据,而这些数据的容量可能会超过单个节点服务器的硬件容量限制。比如,占用 1TB 磁盘空间的 10 亿文档的单个索引可能无法存储在单个节点的磁盘上,因为节点磁盘容量不足以容纳下这么大容量的数据,或者速度太慢无法满足来自单个节点的搜索速度请求。
- 这些问题怎么解决?
Elasticsearch 可以将索引的数据进行分割,这些分割的部分称为分片,每个分片可以分配到不同节点上。
相当于关系型数据中存储数据太多,而进行分库分表操作,把数据进行分散存储。
在 Elasticsearch 中,当你创建索引时,你可以定义想要的分片数量。每个分片都是一个功能齐全、独立的“索引”,可以在集群的任意节点上托管。
- 分片的好处:
- 它可以对数据进行水平拆分,扩展存储数据的容量
- 提供性能、吞吐量,它允许跨分片(可以在多个节点上)分布数据和并行化操作
- 如果发生网络故障,数据丢了怎么办?
这时就会用到数据副本replica功能。Elasticsearch 允许将索引分片构造复制成一个或多个副本,即所谓的复制分片,简称副本。
这样就提供了 ES 的高可用性,为了高可用,ES 不允许副本分片和主分片(或原始分片)分配在同一节点上。
集群架构图解
在 ES 中,索引 index 是由多个 json 格式的文档 document 组成的。每个索引 index 又可以划分为多个分片 Shard。
为了保证高可用,一个分片 shard,又可以分为主分片(primary shard)和副分片(replica shard),副分片是对主分片数据的备份,每个主分片可以有多个副分片,也就是说主分片可以有多个备份数据,
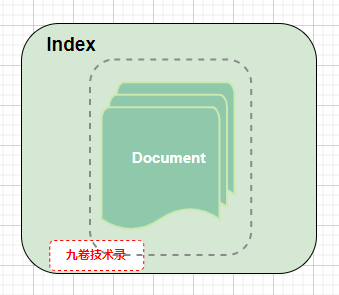
(每个索引index由多个documen组成)
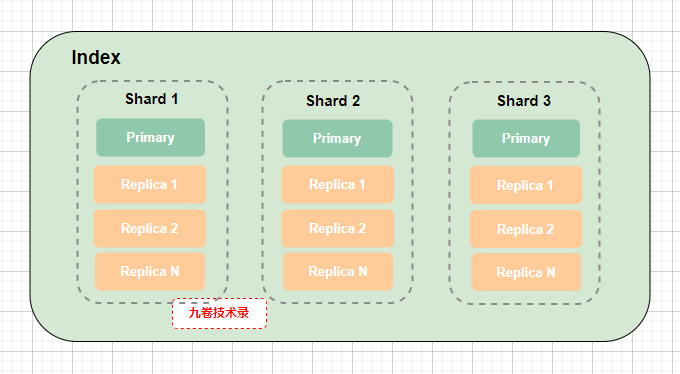
(每个索引index可以划分为多个分片shard,上图划分为shard 1,shard 2,shard 3)
集群 cluster 和节点 Node,主分片 Primary 和副分片 Replica 的关系图:
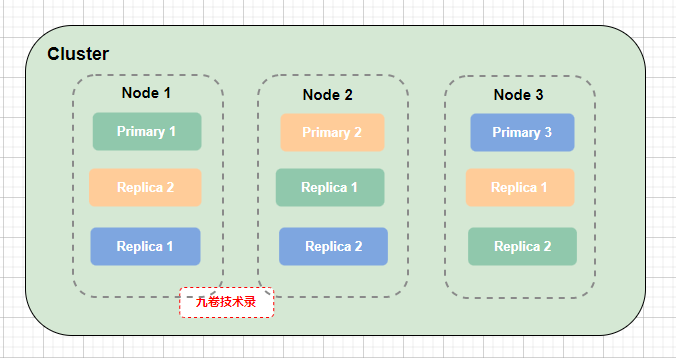
(上图中虚线框里同颜色表示同一份数据的不同分片,Primary-主分片,和此主分片的副本(Replica - 副分片))
对上面集群图 Cluster 说明:
- 把一个索引分成 3 个分片(主分片):Primary 1,Primary 2,Primary 3,然后把 3 个主分片分配到 3 个不同节点Node上
- 每个主分片有 2 个副分片:Replica 1 和 Replica 2,且分别在不同的节点上。比如主分片 Primary 1 在 Node 1 上,它的副分片Replica 1 和 Replica 2 分别在 Node 2 和 Node 3 上
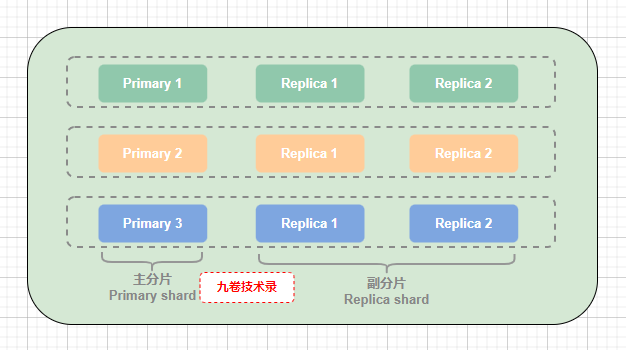
(上图:主分片和它所属副分片,副分片是对主分片数据的备份)
ES与关系型数据库对比
Elasticsearch 与关系型数据库的一个简单类比:
| Elasticsearch(ES搜索引擎) | Relational DB(关系型数据库) |
|---|---|
| Indices(多个索引) | Databases(数据库) |
| Index(单个索引) | Table(表) |
| Document(文档) | Row(行) |
| Field(字段) | Column(列) |
Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。用于理解 ES 中的概念,作一个简单的类比。
四、数据结构: 倒排索引
下面介绍 Elasticsearch 中最重要的数据结构之一 - 倒排索引。
索引简介
索引,在生活中最常见的就是书籍的目录,它就是一种类似索引结构,有时我们也叫索引目录,它能让人快速找到书籍相关章节的内容。
在计算机技术中,索引是一种常用的数据结构,目的就是加快查找数据的速度。比如我们常用的 MySQL 数据库,就有多种索引。
在搜索引擎中,面对海量的数据,如何根据关键字词快速找到用户需要的相关内容?
这里就要用到 倒排索引 这种数据结构,这是搜索引擎中最重要的数据结构。
倒排索引
倒排索引中的一些概念:
- 文档(document):用来搜索的数据,一般是以文本形式存在的存储对象。比如一条短信,一封邮件等。更广义的还有 Word、PDF、XML 等不同格式的文档。
- 文档集合(document collection):由若干个文档组成的集合叫文档集合。
- 文档编号(document id):文档集合中每个文档的唯一编号,用这个唯一编号来标识这个文档。
- 词条(term):对文档数据,用某种分词算法后,得到的有含义的词语就是词条。例如:我们好好学习,可以用分词算法分为:我们,好好学习,学习等几个词条。
- 倒排索引(inverted index):倒排索引是实现词条和文档的一种存储形式。通过倒排索引,可以根据词条快速获取包含这个词语的文档列表。
我们平常使用 MySQL 关系型数据库存储数据,里面有数据表。创建一个关于电动车的数据表:
| id | name |
|---|---|
| 1 | 比亚迪电动车 |
| 2 | 理想电动车 |
| 3 | 小鹏电动车 |
| 4 | 比亚迪电池 |
| 5 | 理想电池 |
怎么把上面的表用倒排索引来表示呢?
| 词条(term) | 文档id(doc id) |
|---|---|
| 比亚迪 | 1,4 |
| 电动车 | 1,2,3 |
| 理想 | 2,5 |
| 小鹏 | 3 |
| 电池 | 4,5 |
| 车 | 1,2,3 |
这张表就是倒排索引。
上面 MySQL 中的表,可以看作是正向索引表,然后把这张表数据倒过来,就变成倒排索引表。
MySQL 表变成倒排索引表的处理过程:
- 利用分词算法对文档数据进行分词,得到一个一个词条。
- 创建倒排索引表,每行数据词条、文档id等
倒排索引表的词条具有唯一性,然后可以给词条创建索引加快查询速度,比如哈希表索引。
五、安装ES
下载并安装ES
因为我的是windows,所以我下载win的安装包,如果你是其它系统请下载相应平台的。我这里想下载 V8.4.3 版本,下载地址:
但是我电脑上安装的是 JDK 1.8,不适合 8 以上的 ES 版本,见这里说明,JDK 和 ES 的对应版本。
后面我换到了能使用jdk 1.8 的 ES V7.17.10 版本。
下载之后直接解压,然后进入 bin 目录,点击 elasticsearch.bat 启动 ES,启动会有一些时间,稍微等一下;
9300 是 tcp 通信端口,ES 集群之间使用 tcp 通信;9200 是 http 协议端口。
在浏览器上输入 http://localhost:9200/ 查看,我这里输出以下数据,安装成功了,
{
"name": "AIS",
"cluster_name": "elasticsearch",
"cluster_uuid": "bKg5AkWZScafo0vp03XOyA",
"version": {
"number": "7.17.10",
"build_flavor": "default",
"build_type": "zip",
"build_hash": "fecd68e3150eda0c307ab9a9d7557f5d5fd71349",
"build_date": "2023-04-23T05:33:18.138275597Z",
"build_snapshot": false,
"lucene_version": "8.11.1",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
安装elasticsearch-head插件
elasticsearch-head 插件可以查看 ES 的各种数据。
通过 git clone 下载 head 插件:
git clone https://github.com/mobz/elasticsearch-head.git
cd ./elasticsearch-head
npm install
npm run start
浏览器上打开:http://localhost:9100/

当然还有其它多种安装方式。
第二种方式 chrome 插件安装:
还可以通过 chrome extension 运行插件,Elasticsearch Head 在 Chrome store 的 下载地址。
下载 chrome 插件后,安装到 chrome 浏览器里。
第三种方式 docker 安装:
通过 docker 安装,具体查看:https://github.com/mobz/elasticsearch-head
设置跨域:
如果连接不上 ES,需要设置跨域访问,打开配置文件 config/elasticsearch.yml,在最后增加下面配置项:
http.cors.enabled: true
http.cors.allow-origin: "*"
设置完成后,重新启动 ES。
打开 http://localhost:9100/,然后点击连接按钮,出现下面 green 颜色表示连接成功,如下图:
六、ES操作-增删改查搜
使用cURL命令操作ES
- curl 操作命令格式
使用 curl,将请求从命令行提交到本地 Elasticsearch 实例,这些请求包含任何 HTTP 请求相同部分:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
命令参数说明:
| 命令参数 | 说明 |
|---|---|
| HTTP 方法,例如,GET,POST,PUT,HEAD 或 DELETE | |
| http 或 https,如果你在 ES 前面有一个 https 代理 | |
| Elasticsearch 集群中任何节点的主机名。 或用 localhost 来代表本地机器上的节点 | |
| 运行 Elasticsearch HTTP 服务的端口号,默认为 9200 | |
| API 的终端路径,可以包含多个参数,例如,_cluster/stats | |
| <QUERY_STRING> | 任何可选的查询字符串参数。 |
| JSON 编码格式的请求正文,如果有需要 |
如果 elasticsearch 启动了安全功能,则必须提供有权限运行 API 的有效用户名和密码:
curl -u elastic:password -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
// elastic 用户名
// password 密码
- curl 安装和文档地址
我是win这里用 chocolatey 安装:
choro install curl
安装完成后直接 cd 到它的安装目录 C:\ProgramData\chocolatey\bin 目录下,然后执行查看 curl 版本命令,安装成功:
不知道安装到哪里了?可以使用
where curl命令来查询安装位置

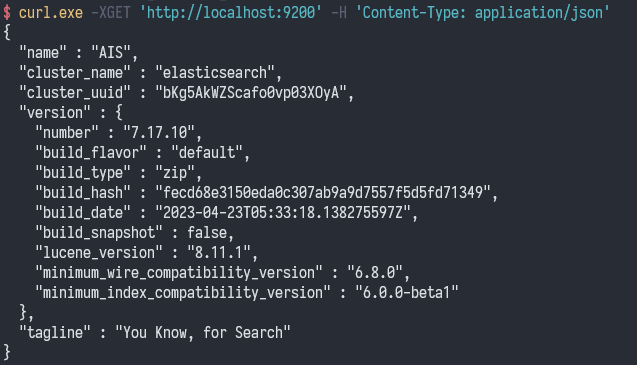
查询 ES 的 http 服务端口 9200,命令:curl.exe -XGET 'http://localhost:9200' -H 'Content-Type: application/json'
这里还可以使用 Go 语言实现的 curl 工具 curlie 来操作 ES。
- 安装 curlie
go install github.com/rs/curlie@v1.6.0
用 curlie 在 terminal 上访问 HTTP 端口 9200,我是 win 使用 PowerShell,命令如下:
curlie -XGET 'http://localhost:9200' -H 'Content-Type: application/json'
返回结果:
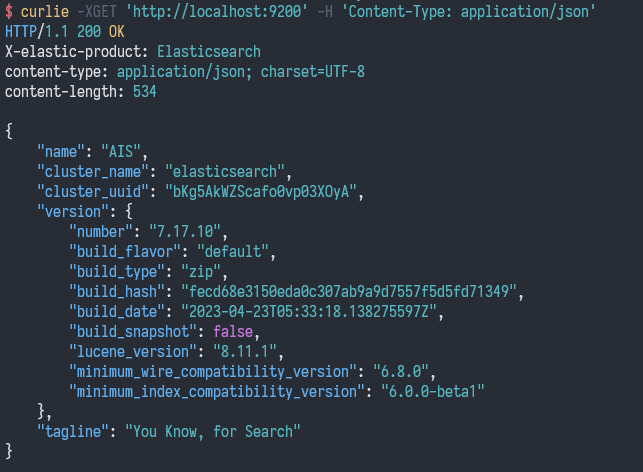
如果 ES 设置了用户和密码,可以用如下命令:
$ curlie -XGET -u "elastic:pwdes" 'http://localhost:9200/' -H 'Content-Type: application/json'
说明:如果运行 curlie 返回安全错误信息,那么找到ES安装位置,然后在 config/elasticsearch.yml 文件最后面加上
xpack.security.enabled: false,把安全验证设置为 false。
创建索引和文档
前面说了,索引 index 可以是名词存储文档的地方,也可以是动词创建索引的意思。
创建索引基本语法:
PUT /{索引名称}
创建索引和文档基本语法:
PUT /{索引名称}/_doc/文档id
// 也可以把上面 PUT 换成 POST
- curl创建索引和文档:
例如,创建一个卖书的书店bookmall索引,然后给索引增加一些数据,命令如下:
curl -XPUT "http://localhost:9200/bookmall/_doc/1?pretty" -H "Content-Type: application/json" -d '{"product_id": 123456, "quantity": 100}'
我的是windows,在cmd下运行后出错,出错信息如下:
{
"error" : {
"root_cause" : [
{
"type" : "mapper_parsing_exception",
"reason" : "failed to parse"
}
],
"type" : "mapper_parsing_exception",
"reason" : "failed to parse",
"caused_by" : {
"type" : "json_parse_exception",
"reason" : "Unexpected character ('p' (code 112)): was expecting double-quote to start field name\n at [Source: (ByteArrayInputStream); line: 1, column: 3]"
}
},
"status" : 400
}
需要把上面的命令修改下,双引号前加上斜线,
curl -XPUT 'http://localhost:9200/bookmall/_doc/1?pretty' -H 'Content-Type: application/json' -d '{\"product_id\": 123456, \"quantity\": 100}'
在运行,成功了,返回信息:
{
"_index" : "bookmall",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
在 linux 下就不需要加这条斜线,所以学习建议在 linux 平台下。 - -!
上面的命令
curl -XPUT也可以换成curl -XPOST
- Postman 创建索引
例如,博客巴士的博客文章,我们可以用 ES 来索引这些博客文章信息。
下面我使用 Postman 这款测试 API 的软件来增加索引,打开 Postman 软件(如没安装请先安装),首先新建一个请求的 tab,

然后在 Headers 里加上 Content-Type: application/json ,如下:
然后请求方法选择 PUT, url 栏里填上 http://localhost:9200/blogerbus/_doc/1?pretty ,然后点击 body,选择 raw 选项,格式选择 JSON , 填上 json 格式的数据,最后点击 Send 按钮发送数据,如下图:
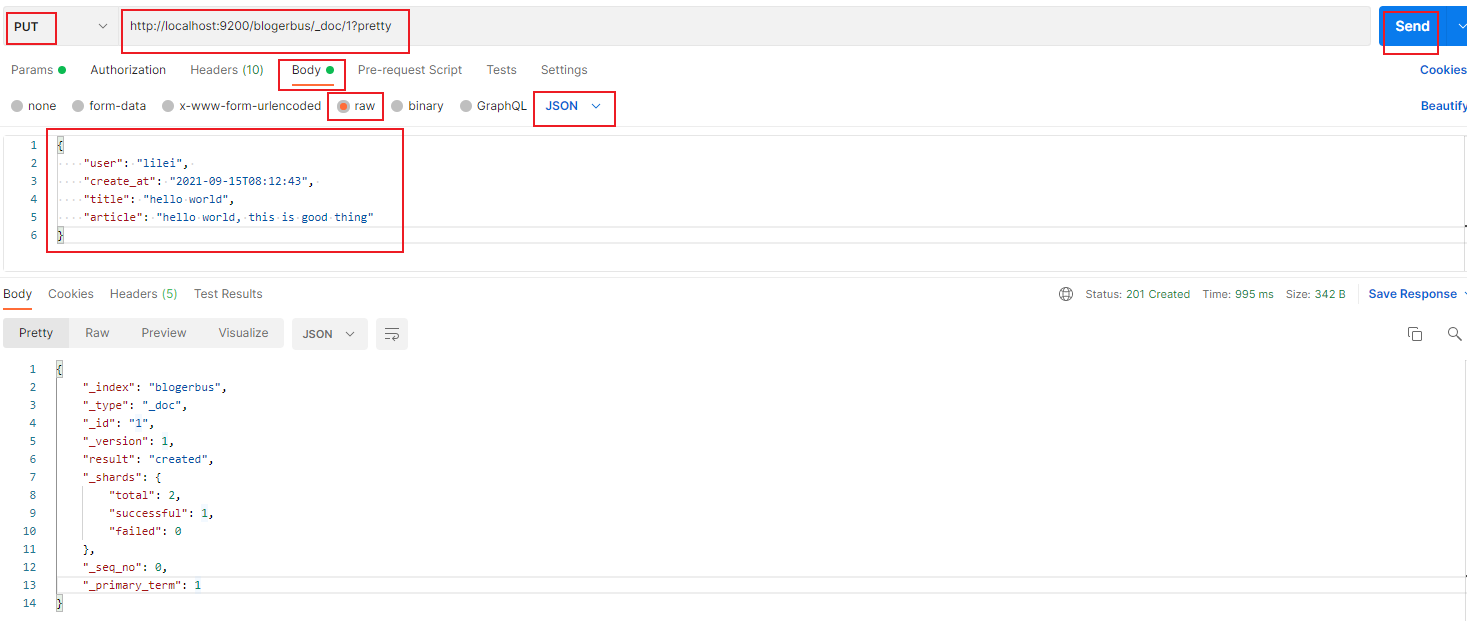
Status:201 Created ,成功返回数据:
{
"_index": "blogerbus",
"_type": "_doc",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
对这条 URL
http://localhost:9200/blogerbus/_doc/1?pretty的说明:
http://localhost:9200:ES HTTP 本地服务端地址:端口号
blogerbus:索引名称
_doc:文档终端endpoint,ES 里的一个固定字段
1:文档 id
?preety:将返回的json格式化数据,显示为更易于让人阅读的形式
查询索引index文档
基本语法:
// 根据单个id查询
GET /{索引名称}/_doc/文档id
//批量查询:查询该索引库下的全部文档
GET /{索引名称}/_search
用 Postman 来查询索引文档,在url栏输入 http://localhost:9200/blogerbus/_doc/1?pretty=true,点击 Send,返回:
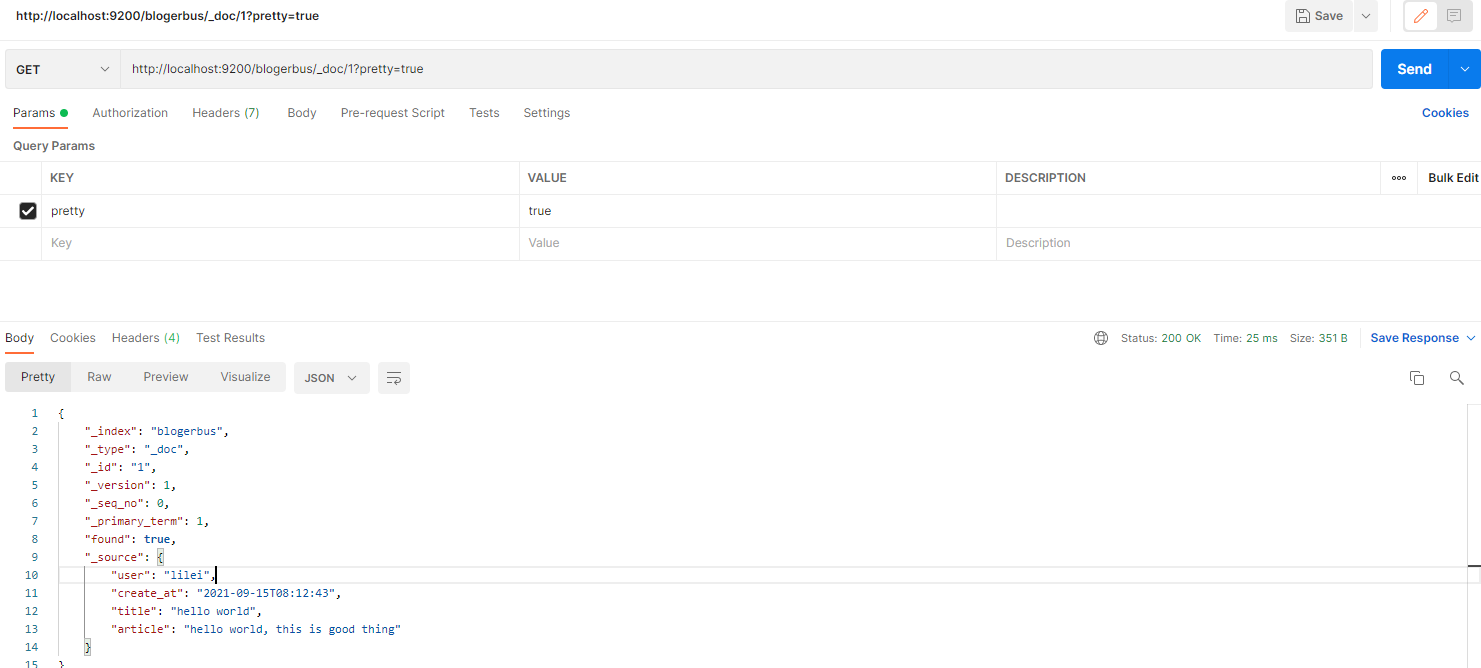
返回内容:
{
"_index": "blogerbus",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"user": "lilei",
"create_at": "2021-09-15T08:12:43",
"title": "hello world",
"article": "hello world, this is good thing"
}
}
搜索
基本语法:
GET /{索引名称}/_search // 后面可以跟一些查询字符串,也可以跟json的DSL
给索引 blogerbus 多增加几个文档,用于我们的搜索:
// 第2篇文档,http://localhost:9200/blogerbus/_doc/2?pretty
{
"user": "lilei",
"create_at": "2021-09-18T09:12:04",
"title": "math lesson",
"article": "hello math, this my first lesson"
}
// 第3篇文档,http://localhost:9200/blogerbus/_doc/3?pretty
{
"user": "hanmeimei",
"create_at": "2021-10-10T03:24:34",
"title": "test lesson",
"article": "hello lesson, this my test lesson"
}
- Postman 搜索
搜索 user 为 lilei 的所有文章,在 Postman 的url栏输入:http://localhost:9200/blogerbus/_search?q=user:lilei&pretty=true,点击 Send 按钮,返回值:
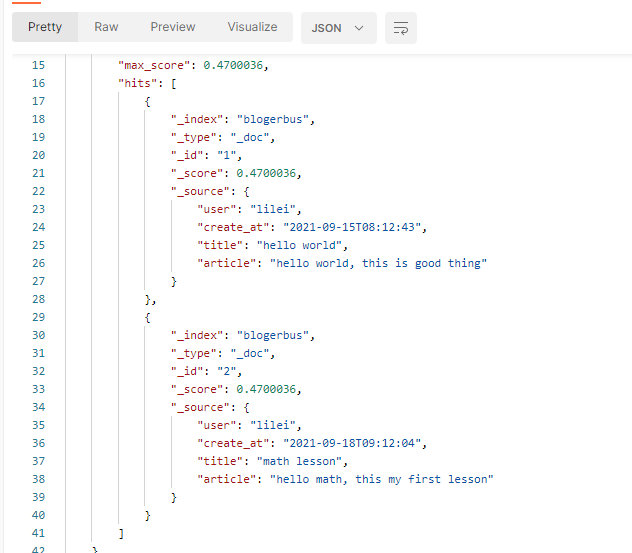
上面是直接在 url 上用字符串查询,还可以用 json 格式来查询:
{
"query" : {
"match" : { "user": "lilei" }
}
}
url 修改为 http://localhost:9200/blogerbus/_search?pretty=true,
返回的数据与上面相同。
- curl 搜索
curl -XGET 'http://localhost:9200/blogerbus/_search?pretty=true' -H 'Content-Type: application/json' -d '{\"query\": {\"match\":{\"user\": \"lilei\"}}}'
返回的内容与 Postman 搜索返回内容相同
删除
删除文档基本语法:
DELETE /{索引名称}/_doc/文档id
例如,curl 删除一篇 id 为 2 的文档:
curl -XDELETE 'http://localhost:9200/bookmall/_doc/2'
返回:
{"_index":"bookmall","_type":"_doc","_id":"2","_version":3,"result":"deleted","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":3,"_primary_term":1}
后面没有加?pretty=true,所以返回数据排版是不易读的json。
删除索引基本语法:
DELETE /{索引名称}
修改
修改有2种方式:全量修改和增量修改
- 全量修改:直接覆盖原来的文档。根据指定 id 删除,id 不存在时,修改变成新增。
基本语法:
PUT /{索引名称}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
- 增量修改:修改文档中部分字段,只修改指定 id 中匹配文档的部分字段。
基本语法:
POST /{索引名称}/_update/文档id
{
"doc": {
"字段名": "新值",
}
}
curl 全量修改:
把上面的 bookmall/_doc/1 中 2 个字段值都修改下:
curl -XPUT "http://localhost:9200/bookmall/_doc/1?pretty" -H "Content-Type: application/json" -d '{\"product_id\": 1234567, \"quantity\": 1000}'
修改成功后返回数据:
{
"_index" : "bookmall",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 1
}
那能不能修改值的同时新增一个字段?可以的。例如,给文档 id 为 1 的新增一个字段 num:50 ,修改 quantity 为 2000,如下:
curl -XPUT "http://localhost:9200/bookmall/_doc/1?pretty" -H "Content-Type: application/json" -d '{\"product_id\": 123456, \"quantity\": 2000,\"name\":\"shiije\",\"num\":50}'
可以修改成功。
curl 部分修改:
修改文档 id 为 1 中的字段 product_id 为 123,
curl -XPOST "http://localhost:9200/bookmall/_update/1?pretty" -H "Content-Type: application/json" -d '{\"doc\":{\"product_id\": 123}}'
可以修改成功。
七、参考
- https://lucene.apache.org/ lucene
- https://www.elastic.co/guide/en/elasticsearch/reference/8.4/elasticsearch-intro.html ES 文档
- https://github.com/elastic/elasticsearch/tree/8.4/docs/reference
- https://www.elastic.co/guide/en/elasticsearch/plugins/8.4/mapper-size.html
- https://github.com/elastic elastic github
- https://github.com/elastic/kibana
- 《elasticsearch权威指南》
- https://elasticstack.blog.csdn.net/article/details/98871531 Elasticsearch 简介
- https://www.elastic.co/cn/support/matrix#matrix_jvm
- https://www.elastic.co/guide/en/elasticsearch/reference/8.4/modules-node.html
- https://everything.curl.dev/http curl http 语法
- https://www.postman.com/ postman
分布式搜索引擎Elasticsearch基础入门学习的更多相关文章
- ElasticSearch基础入门学习笔记
前言 本笔记的内容主要是在从0开始学习ElasticSearch中,按照官方文档以及自己的一些测试的过程. 安装 由于是初学者,按照官方文档安装即可.前面ELK入门使用主要就是讲述了安装过程,这里不再 ...
- 最强分布式搜索引擎——ElasticSearch
最强分布式搜索引擎--ElasticSearch 本篇我们将会介绍到一种特殊的类似数据库存储机制的搜索引擎工具--ES elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以 ...
- Elasticsearch 基础入门
原文地址:Elasticsearch 基础入门 博客地址:http://www.extlight.com 一.什么是 ElasticSearch ElasticSearch是一个基于 Lucene 的 ...
- 函数:我的地盘听我的 - 零基础入门学习Python019
函数:我的地盘听我的 让编程改变世界 Change the world by program 函数与过程 在小甲鱼另一个实践性超强的编程视频教学<零基础入门学习Delphi>中,我们谈到了 ...
- VBox&vmware虚拟机安装Linux及Linux基础入门学习
VBox&vmware虚拟机安装Linux及Linux基础入门学习 通过VMware workstation安装Linux 在安装虚拟机之前,我特意上网搜索了一下目前常使用的虚拟机软件,了解了 ...
- 【Python教程】《零基础入门学习Python》(小甲鱼)
[Python教程]<零基础入门学习Python>(小甲鱼) 讲解通俗易懂,诙谐. 哈哈哈. https://www.bilibili.com/video/av27789609
- Mybatis基础入门学习
Mybatis基础入门学习 mybatis架构分析 搭建测试mybatis架构 )下载并导入mybatis3.2.7.jar(架构),mysql-connector-java-5.1.7-bin.ja ...
- 《零基础入门学习Python》【第一版】视频课后答案第001讲
测试题答案: 0. Python 是什么类型的语言? Python是脚本语言 脚本语言(Scripting language)是电脑编程语言,因此也能让开发者藉以编写出让电脑听命行事的程序.以简单的方 ...
- 零基础入门学习Python(1)--我和Python的第一次亲密接触
前言 最近在学习Python编程语言,于是乎就在网上找资源.其中小甲鱼<零基础入门学习Python>试听了几节课,感觉还挺不错,里面的视频都是免费下载,小甲鱼讲话也挺幽默风趣的,所以呢,就 ...
- 学习参考《零基础入门学习Python》电子书PDF+笔记+课后题及答案
国内编写的关于python入门的书,初学者可以看看. 参考: <零基础入门学习Python>电子书PDF+笔记+课后题及答案 Python3入门必备; 小甲鱼手把手教授Python; 包含 ...
随机推荐
- pwd学习
pwd学习 学习pwd命令 首先通过man命令去学习pwd man pwd pwd pwd --help getcwd():getcwd(char *buf,size_t size) readdir( ...
- TCP idle timeout 和TCP Keepalive 比较和分析
TCP idle timeout 和TCP Keepalive 是两个独立的功能. TCP idle timeout TCP idle timeout 是系统TCP配置文件中的空闲超时设 ...
- bat将多个文件夹下内容合并到一个文件夹下
for /f "delims=" %%p in ('dir /b/ad') do copy %%p\*.* d:\all\ pause 目标文件夹 d:\all\ 最好不用中文目录
- Windows系统下找到占用当前端口的进程
在进行服务调试时如果遇到端口冲突而不自知,可能会出现莫名其妙的错误.因此在不确定的情况下最好先查看要用的端口是否被占用. 下面介绍查看端口占用情况方法. 比如现在是要找到端口为8088的占用,在cmd ...
- .bat 脚本替换文件内容
rem 定义变量延迟环境,关闭回显 @echo off&setlocal enabledelayedexpansion rem 读取a.txt所有内容 for /f "eol=* t ...
- MySQL根据经纬度和距离查询最近的数据
[lat]:输入的纬度 [lon]:输入的经度 [distance]:查询距离内的数据,单位m SELECT * FROM ( SELECT id lon, lat, vin, ROUND( 6378 ...
- Spring--AOP切入点表达式
AOP工作流程 能够与做代理的那个类匹配得上的话,叫做代理对象,否则为原始对象. (SpringAOP的本质:代理模式) AOP的切入点表达式 切入点表达式描述的标准格式 描述方式一:定位到某某包下的 ...
- MySQL学习(十一)为什么不推荐使用uuid和雪花id
参考博客:https://www.cnblogs.com/wyq178/p/12548864.html 自增的主键的值是顺序的,所以Innodb把每一条记录都存储在一条记录的后面.当达到页面的最大填充 ...
- 音频和视频流最佳选择?SRT 协议解析及报文识别
我们所知道 SRT 是由 Haivision 和 Wowza 开发的开源视频流协议.很多人会认为在不久的将来,它被是 RTMP 的替代品.因为 RTMP 协议安全性稍低,延迟相对较高 ,而相对于 SR ...
- (3) MasaFramework 入门第三篇,使用MasaFramework
首先我们需要创建一个MasaFramework模板的项目,项目名称TokenDemo,项目类型如图所示 删除Web/TokenDemo.Admin项目,新建Masa Blazor Pro项目模板 项目 ...