Optimum + ONNX Runtime: 更容易、更快地训练你的 Hugging Face 模型
介绍
基于语言、视觉和语音的 Transformer 模型越来越大,以支持终端用户复杂的多模态用例。增加模型大小直接影响训练这些模型所需的资源,并随着模型大小的增加而扩展它们。Hugging Face 和微软的 ONNX Runtime 团队正在一起努力,在微调大型语言、语音和视觉模型方面取得进步。Hugging Face 的 Optimum 库,通过和 ONNX Runtime 的集成进行训练,为许多流行的 Hugging Face 模型提供了一个开放的解决方案,可以将训练时间缩短 35% 或更多。我们展现了 Hugging Face Optimum 和 ONNX Runtime Training 生态系统的细节,性能数据突出了使用 Optimum 库的好处。
性能测试结果
下面的图表表明,当 使用 ONNX Runtime 和 DeepSpeed ZeRO Stage 1 进行训练时,用 Optimum 的 Hugging Face 模型的加速 从 39% 提高到 130%。性能测试的基准运行是在选定的 Hugging Face PyTorch 模型上进行的,第二次运行是只用 ONNX Runtime 训练,最后一次运行是 ONNX Runtime + DeepSpeed ZeRO Stage 1,图中显示了最大的收益。基线 PyTorch 运行所用的优化器是 AdamW Optimizer,ORT 训练用的优化器是 Fused Adam Optimizer。这些运行是在带有 8 个 GPU 的单个 NVIDIA A100 节点上执行的。
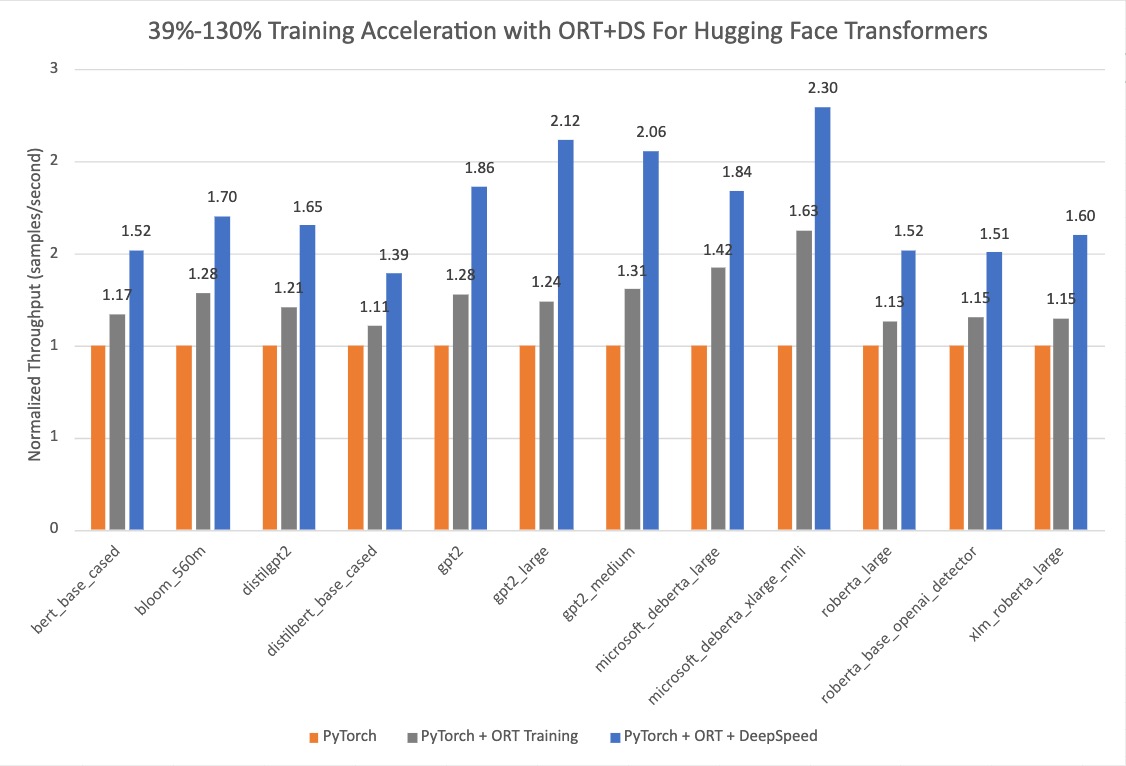
更多关于开启 Optimum 进行训练加速的配置细节可以在 指南中 找到。用于这些运行的版本信息如下:
PyTorch: 1.14.0.dev20221103+cu116; ORT: 1.14.0.dev20221103001+cu116; DeepSpeed: 0.6.6; HuggingFace: 4.24.0.dev0; Optimum: 1.4.1.dev0; Cuda: 11.6.2
Optimum 库
Hugging Face 是一个快速发展的开放社区和平台,旨在将优秀的机器学习大众化。随着 Transformers 库 的成功,我们将模态从 NLP 扩展到音频和视觉,现在涵盖了跨机器学习的用例,以满足我们社区的需求。现在在 Hugging Face Hub 上,有超过 12 万个免费和可访问的模型 checkpoints 用于各种机器学习任务,1.8 万个数据集和 2 万个机器学习演示应用。然而,将 Transformer 模型扩展到生产中仍然是工业界的一个挑战。尽管准确性很高,但基于 Transformer 的模型的训练和推理可能耗时且昂贵。
为了满足这些需求,Hugging Face 构建了两个开源库: Accelerate 和 Optimum。Accelerate 专注于开箱即用的分布式训练,而 Optimum 作为 Transformer 的扩展,通过利用用户目标硬件的最大效率来加速模型训练和推理。Optimum 集成了机器学习加速器如 ONNX Runtime,和专业的硬件如 英特尔的 Habana Gaudi,因此用户可以从训练和推理的显著加速中受益。此外, Optimum 无缝集成了其他 Hugging Face 的工具,同时继承了 Transformer 的易用性。开发人员可以轻松地调整他们的工作,以更少的计算能力实现更低的延迟。
ONNX Runtime 训练
ONNX Runtime 加速 大型模型训练,单独使用时将吞吐量提高 40%,与 DeepSpeed 组合后将吞吐量提高 130%,用于流行的基于 Hugging Face Transformer 的模型。ONNX Runtime 已经集成为 Optimum 的一部分,并通过 Hugging Face 的 Optimum 训练框架实现更快的训练。
ONNX Runtime Training 通过一些内存和计算优化实现了这样的吞吐量改进。内存优化使 ONNX Runtime 能够最大化批大小并有效利用可用的内存,而计算优化则加快了训练时间。这些优化包括但不限于,高效的内存规划,内核优化,适用于 Adam 优化器的多张量应用 (将应用于所有模型参数的按元素更新分批到一个或几个内核启动中),FP16 优化器 (消除了大量用于主机内存拷贝的设备),混合精度训练和图优化,如节点融合和节点消除。ONNX Runtime Training 支持 NVIDIA 和 AMD GPU,并提供自定义操作的可扩展性。
简而言之,它使 AI 开发人员能够充分利用他们熟悉的生态系统,如 PyTorch 和 Hugging Face,并在他们选择的目标设备上使用 ONNX Runtime 进行加速,以节省时间和资源。
Optimum 中的 ONNX Runtime Training
Optimum 提供了一个 ORTTrainer API,它扩展了 Transformer 中的 Trainer,以使用 ONNX Runtime 作为后端进行加速。ORTTrainer 是一个易于使用的 API,包含完整的训练循环和评估循环。它支持像超参数搜索、混合精度训练和多 GPU 分布式训练等功能。ORTTrainer 使 AI 开发人员在训练 Transformer 模型时能够组合 ONNX Runtime 和其他第三方加速技术,这有助于进一步加速训练,并充分发挥硬件的作用。例如,开发人员可以将 ONNX Runtime Training 与 Transformer 训练器中集成的分布式数据并行和混合精度训练相结合。此外,ORTTrainer 使你可以轻松地将 DeepSpeed ZeRO-1 和 ONNX Runtime Training 组合,通过对优化器状态进行分区来节省内存。在完成预训练或微调后,开发人员可以保存已训练的 PyTorch 模型,或使用 Optimum 实现的 API 将其转为 ONNX 格式,以简化推理的部署。和 Trainer 一样,ORTTrainer 与 Hugging Face Hub 完全集成: 训练结束后,用户可以将他们的模型 checkpoints 上传到 Hugging Face Hub 账户。
因此具体来说,用户应该如何利用 ONNX Runtime 加速进行训练?如果你已经在使用 Trainer,你只需要修改几行代码就可以从上面提到的所有改进中受益。主要有两个替换需要应用。首先,将 Trainer 替换为 ORTTrainer,然后将 TrainingArguments 替换为ORTTrainingArguments,其中包含训练器将用于训练和评估的所有超参数。ORTTrainingArguments 扩展了 TrainingArguments,以应用 ONNX Runtime 授权的一些额外参数。例如,用户可以使用 Fused Adam 优化器来获得额外的性能收益。下面是一个例子:
-from transformers import Trainer, TrainingArguments
+from optimum.onnxruntime import ORTTrainer, ORTTrainingArguments
# Step 1: Define training arguments
-training_args = TrainingArguments(
+training_args = ORTTrainingArguments(
output_dir="path/to/save/folder/",
- optim = "adamw_hf",
+ optim = "adamw_ort_fused",
...
)
# Step 2: Create your ONNX Runtime Trainer
-trainer = Trainer(
+trainer = ORTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
+ feature="sequence-classification",
...
)
# Step 3: Use ONNX Runtime for training!
trainer.train()
展望未来
Hugging Face 团队正在开源更多的大型模型,并通过训练和推理的加速工具以降低用户从模型中获益的门槛。我们正在与 ONNX Runtime Training 团队合作,为更新和更大的模型架构带来更多的训练优化,包括 Whisper 和 Stable Diffusion。微软还将其最先进的训练加速技术打包在 PyTorch 的 Azure 容器 中。这是一个轻量级的精心营造的环境,包括 DeepSpeed 和 ONNX Runtime,以提高 AI 开发者使用 PyTorch 训练的生产力。除了大型模型训练外,ONNX Runtime Training 团队还在为边缘学习构建新的解决方案——在内存和电源受限的设备上进行训练。
准备开始
我们邀请你查看下面的链接,以了解更多关于 Hugging Face 模型的 Optimum ONNX Runtime Training,并开始使用。
- Optimum ONNX Runtime Training 文档
- Optimum ONNX Runtime Training 示例
- Optimum Github 仓库
- ONNX Runtime Training 示例
- ONNX Runtime Training Github 仓库
- ONNX Runtime
- DeepSpeed 和 ZeRO 教程
- PyTorch 的 Azure 容器
感谢阅读!如果你有任何问题,请通过 Github 或 论坛 随时联系我们。你也可以在 Twitter 或 LinkedIn 上联系我。
原文: https://hf.co/blog/optimum-onnxruntime-training
作者: Jingya、Kshama Pawar (guest)、Vincent Wang (guest)、Zhijiang Xu (guest)
译者: AIboy1993 (李旭东)
审校、排版: zhongdongy (阿东)
Optimum + ONNX Runtime: 更容易、更快地训练你的 Hugging Face 模型的更多相关文章
- 金蝶随手记团队分享:还在用JSON? Protobuf让数据传输更省更快(实战篇)
本文作者:丁同舟,来自金蝶随手记技术团队. 1.前言 本文接上篇<金蝶随手记团队分享:还在用JSON? Protobuf让数据传输更省更快(原理篇)>,以iOS端的Objective-C代 ...
- Google 开源的依赖注入库,比 Spring 更小更快!
Google开源的一个依赖注入类库Guice,相比于Spring IoC来说更小更快.Elasticsearch大量使用了Guice,本文简单的介绍下Guice的基本概念和使用方式. 学习目标 概述: ...
- Dnsmasq安装与配置-搭建本地DNS服务器 更干净更快无广告DNS解析
默认的情况下,我们平时上网用的本地DNS服务器都是使用电信或者联通的,但是这样也导致了不少的问题,首当其冲的就是上网时经常莫名地弹出广告,或者莫名的流量被消耗掉导致网速变慢.其次是部分网站域名不能正常 ...
- 更轻更快的Vue.js 2.0与其他框架对比(转)
更轻更快的Vue.js 2.0 崭露头角的JavaScript框架Vue.js 2.0版本已经发布,在狂热的JavaScript世界里带来了让人耳目一新的变化. Vue创建者尤雨溪称,Vue 2.0 ...
- 比年轻更年轻,快看能否接棒B站?
撰文 |懂懂 编辑 | 秦言 来源:懂懂笔记 背靠超新Z世代,快看能否接棒B站? 国漫什么时候能追上日漫? 国漫作者真能挣到钱吗? 国漫什么时候才能走向世界? 这是中国漫画从业者的"灵魂三问 ...
- 不妨试试更快更小更灵活Java开发框架Solon
@ 目录 概述 定义 性能 架构 实战 Solon Web示例 Solon Mybatis-Plus示例 Solon WebSocket示例 Solon Remoting RPC示例 Solon Cl ...
- 微软推出了Cloud Native Application Bundles和开源ONNX Runtime
微软的Microsoft Connect(); 2018年的开发者大会 对Azure和IoT Edge服务进行了大量更新; Windows Presentation Foundation,Window ...
- 线程安全使用(四) [.NET] 简单接入微信公众号开发:实现自动回复 [C#]C#中字符串的操作 自行实现比dotcore/dotnet更方便更高性能的对象二进制序列化 自已动手做高性能消息队列 自行实现高性能MVC WebAPI 面试题随笔 字符串反转
线程安全使用(四) 这是时隔多年第四篇,主要是因为身在东软受内网限制,好多文章就只好发到东软内部网站,懒的发到外面,现在一点点把在东软写的文章给转移出来. 这里主要讲解下CancellationT ...
- 采用ADM2483磁隔离器让RS485接口更简单更安全
采用ADM2483磁隔离器让RS485接口更简单更安全 摘要:本文介绍RS485的特点及应用,指出了普通RS485接口易损坏的问题,针对存在的问题介绍了以ADM2483为核心的磁隔离解决方案. 关键词 ...
- EpiiServer 更快捷更方便的php+nginx环境定制化方案
EpiiServer是什么 更快捷更方便的php+nginx多应用部署环境. github仓库首页 https://github.com/epaii/epii-server gitee仓库 https ...
随机推荐
- 为什么Git远程仓库中要配置公钥?
最近在使用阿里云效平台代码管理,首次使用新建仓库,使用SSH时需要配置公钥.之前也在GitHub.Gitee上配置过,每次都能正常使用,也没有思考过为什么要配置公钥.这次记录一下其中的原理. 本地和远 ...
- HDOJFatmouse肥鼠交易//c++控制保留小数
贪心算法.我就不贴题了//no.1009 但是我的代码运行超时了-改了好久都不对- 看别人代码,顺便学习c++控制保留小数怎么操作; 我的错误代码:(时间占用可能是多次调用findmax造成的) #i ...
- bitlocker加密如何找密钥解锁
步骤1:在其他设备上登录[微软账号],地址:https://account.microsoft.com 步骤2:找到[自己的设备],查看[Bitlocker]密钥登录进去能看到[设备],找要解锁的那台 ...
- 微信小程序地区和location_id对应关系
点击查看代码 location_list = [ {'location_id': '101010100', 'location_name': ['北京', '北京', '北京']}, {'locati ...
- 牛客小白月赛65ABCD(E)
比赛链接:牛客小白月赛65_ACM/NOI/CSP/CCPC/ICPC算法编程高难度练习赛_牛客竞赛OJ (nowcoder.com) A:牛牛去购物 题意 ...
- DevExpress 的LayoutControl控件导致资源无法释放的问题处理
现象记录 前段时间同事发现我们的软件在加载指定的插件界面后,关闭后插件的界面资源不能释放, 资源管理器中不管内存,还是GDI对象等相关资源都不会下降. 问题代码 问题的代码大概如下. public v ...
- Python Excel 追加数据
xlutils 库的安装 你好,我是悦创. 前面我分享了 Excel 的读写:Python 实现 Excel 的读写操作:https://bornforthis.cn/column/pyauto/au ...
- LVGL 中图片使用问题
此笔记主要是记录在 LVGL 中使用图片的几种方式,以及使用过程中遇到的问题.最近在 ARM linux 中使用 LVGL 时,发现加载图片变得很卡,一开始还好,当连续加载的图片变多后,特别是动画的过 ...
- 又一重要进展发布!OpenMMLab算法仓支持昇腾AI训练加速
摘要:上海人工智能实验室的浦视开源算法体系(OpenMMLab)团队基于昇腾AI发布了MMDeploy 0.10.0版本,该版本已支持OpenMMLab算法仓库在昇腾异构计算架构CANN上的推理部署. ...
- 图文并茂使用VUE+Quasar CLI开发和构建PWA,registerServiceWorker介绍
看文档 文档地址:Preparation for PWA 1.将PWA模式添加到我们的Quasar项目中: npx quasar mode add pwa 我们看一下有哪些变化 向Quasar项目添加 ...