Spark详解(07-1) - SparkStreaming案例实操
Spark详解(07-1) - SparkStreaming案例实操
环境准备
pom文件
- <dependencies>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-core_2.12</artifactId>
- <version>3.0.0</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-streaming_2.12</artifactId>
- <version>3.0.0</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
- <version>3.0.0</version>
- </dependency>
- <!-- https://mvnrepository.com/artifact/com.alibaba/druid -->
- <dependency>
- <groupId>com.alibaba</groupId>
- <artifactId>druid</artifactId>
- <version>1.1.10</version>
- </dependency>
- <dependency>
- <groupId>mysql</groupId>
- <artifactId>mysql-connector-java</artifactId>
- <version>5.1.27</version>
- </dependency>
- <dependency>
- <groupId>com.fasterxml.jackson.core</groupId>
- <artifactId>jackson-core</artifactId>
- <version>2.10.1</version>
- </dependency>
- </dependencies>
更改日志打印级别
将log4j.properties文件添加到resources里面,就能更改打印日志的级别为error
log4j.rootLogger=error, stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=../log/agent.log
log4j.appender.R.MaxFileSize=1024KB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%6L) : %m%n
PropertiesUtil工具类
1)创建包名
com.zhangjk.util
2)编写读取资源文件工具类
- package com.zhangjk.util
- import java.io.InputStreamReader
- import java.util.Properties
- object PropertiesUtil {
- def load(propertiesName: String): Properties = {
- val prop = new Properties()
- prop.load(new InputStreamReader(Thread.currentThread().getContextClassLoader.getResourceAsStream(propertiesName), "UTF-8"))
- prop
- }
- }
config.properties
1)在resources目录下创建config.properties文件
2)添加如下配置到config.properties文件
#JDBC配置
jdbc.datasource.size=10
jdbc.url=jdbc:mysql://hadoop102:3306/spark2020?useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=true
jdbc.user=root
jdbc.password=000000
# Kafka配置
kafka.broker.list=hadoop102:9092,hadoop103:9092,hadoop104:9092
kafka.topic=testTopic
实时数据生成模块
RandomOptions
1)根据输入权重,生成对应随机数
- package com.zhangjk.util
- import scala.collection.mutable.ListBuffer
- import scala.util.Random
- // value值出现的比例,例如:(男,8) (女:2)
- case class RanOpt[T](value: T, weight: Int)
- object RandomOptions {
- def apply[T](opts: RanOpt[T]*): RandomOptions[T] = {
- val randomOptions = new RandomOptions[T]()
- for (opt <- opts) {
- // 累积总的权重: 8 + 2
- randomOptions.totalWeight += opt.weight
- // 根据每个元素的自己的权重,向buffer中存储数据。权重越多存储的越多
- for (i <- 1 to opt.weight) {
- // 男 男 男 男 男 男 男 男 女 女
- randomOptions.optsBuffer += opt.value
- }
- }
- randomOptions
- }
- def main(args: Array[String]): Unit = {
- for (i <- 1 to 10) {
- println(RandomOptions(RanOpt("男", 8), RanOpt("女", 2)).getRandomOpt)
- }
- }
- }
- class RandomOptions[T](opts: RanOpt[T]*) {
- var totalWeight = 0
- var optsBuffer = new ListBuffer[T]
- def getRandomOpt: T = {
- // 随机选择:0-9
- val randomNum: Int = new Random().nextInt(totalWeight)
- // 根据随机数,作为角标取数
- optsBuffer(randomNum)
- }
- }
MockerRealTime
1)生成日志逻辑

2)创建包名
com.zhangjk.macker
3)编写生成实时数据代码
- package com.zhangjk.macker
- import java.util.Properties
- import com.zhangjk.util.{PropertiesUtil, RanOpt, RandomOptions}
- import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
- import scala.collection.mutable.ArrayBuffer
- import scala.util.Random
- //城市信息表: city_id :城市id city_name:城市名称 area:城市所在大区
- case class CityInfo(city_id: Long, city_name: String, area: String)
- object MockerRealTime {
- /**
- * 模拟的数据
- * 格式 :timestamp area city userid adid
- * 某个时间点 某个地区 某个城市 某个用户 某个广告
- * 1604229363531 华北 北京 3 3
- */
- def generateMockData(): Array[String] = {
- val array: ArrayBuffer[String] = ArrayBuffer[String]()
- val CityRandomOpt = RandomOptions(
- RanOpt(CityInfo(1, "北京", "华北"), 30),
- RanOpt(CityInfo(2, "上海", "华东"), 30),
- RanOpt(CityInfo(3, "广州", "华南"), 10),
- RanOpt(CityInfo(4, "深圳", "华南"), 20),
- RanOpt(CityInfo(5, "天津", "华北"), 10)
- )
- val random = new Random()
- // 模拟实时数据:
- // timestamp province city userid adid
- for (i <- 0 to 50) {
- val timestamp: Long = System.currentTimeMillis()
- val cityInfo: CityInfo = CityRandomOpt.getRandomOpt
- val city: String = cityInfo.city_name
- val area: String = cityInfo.area
- val adid: Int = 1 + random.nextInt(6)
- val userid: Int = 1 + random.nextInt(6)
- // 拼接实时数据: 某个时间点 某个地区 某个城市 某个用户 某个广告
- array += timestamp + " " + area + " " + city + " " + userid + " " + adid
- }
- array.toArray
- }
- def main(args: Array[String]): Unit = {
- // 获取配置文件config.properties中的Kafka配置参数
- val config: Properties = PropertiesUtil.load("config.properties")
- val brokers: String = config.getProperty("kafka.broker.list")
- val topic: String = config.getProperty("kafka.topic")
- // 创建配置对象
- val prop = new Properties()
- // 添加配置
- prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
- prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
- prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
- // 根据配置创建Kafka生产者
- val kafkaProducer: KafkaProducer[String, String] = new KafkaProducer[String, String](prop)
- while (true) {
- // 随机产生实时数据并通过Kafka生产者发送到Kafka集群中
- for (line <- generateMockData()) {
- kafkaProducer.send(new ProducerRecord[String, String](topic, line))
- println(line)
- }
- Thread.sleep(2000)
- }
- }
- }
4)测试:
(1)启动Kafka集群
zk.sh start
kf.sh start
(2)消费Kafka的testTopic数据
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic testTopic
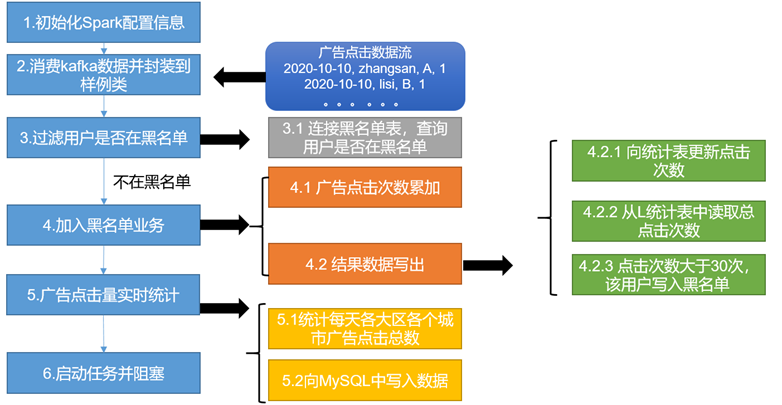
需求一:广告黑名单
实现实时的动态黑名单机制:将每天对某个广告点击超过30次的用户拉黑。
注:黑名单保存到MySQL中。
需求分析
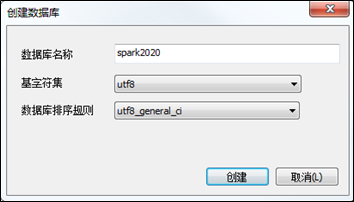
MySQL建表
1)创建库spark2020
2)存放黑名单用户的表
CREATE TABLE black_list (
userid CHAR(1) PRIMARY KEY -- 用户id
);
3)存放单日各用户点击每个广告的次数统计表
CREATE TABLE user_ad_count (
dt VARCHAR(255), -- 时间
userid CHAR (1), -- 用户id
adid CHAR (1), -- 广告id
COUNT BIGINT, -- 广告点击次数
PRIMARY KEY (dt, userid, adid) -- 联合主键
);
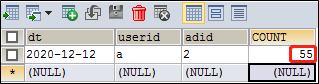
4)测试:如果设置主键,有则更新,无则插入。 连续执行两次插入
insert into user_ad_count(dt, userid, adid, count)
values('2020-12-12','a','2',50)
on duplicate key
update count=count+5
5)测试:如果不设置主键会连续插入两条数据
CREATE TABLE user_ad_count_test (
dt VARCHAR(255), -- 时间
userid CHAR (1), -- 用户id
adid CHAR (1), -- 广告id
COUNT BIGINT -- 广告点击次数
);
连续执行两次插入语句,得到两条数据
insert into user_ad_count_test(dt, userid, adid, count)
values('2020-11-11','a','1',50)
on duplicate key
update count=count+5
MyKafkaUtil工具类
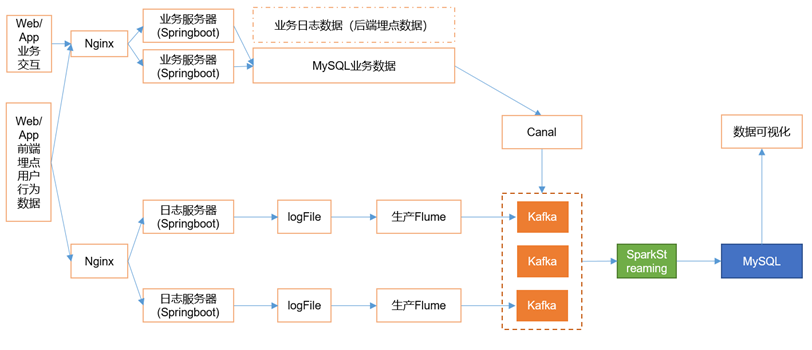
接下来开始实时需求的分析,需要用到SparkStreaming来做实时数据的处理,在生产环境中,绝大部分时候都是对接的Kafka数据源,创建一个SparkStreaming读取Kafka数据的工具类。
- package com.zhangjk.util
- import java.util.Properties
- import org.apache.kafka.clients.consumer.ConsumerRecord
- import org.apache.kafka.common.serialization.StringDeserializer
- import org.apache.spark.streaming.StreamingContext
- import org.apache.spark.streaming.dstream.{DStream, InputDStream}
- import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
- object MyKafkaUtil {
- //1.创建配置信息对象
- private val properties: Properties = PropertiesUtil.load("config.properties")
- //2.用于初始化链接到集群的地址
- private val brokers: String = properties.getProperty("kafka.broker.list")
- // 创建DStream,返回接收到的输入数据
- // LocationStrategies:根据给定的主题和集群地址创建consumer
- // LocationStrategies.PreferConsistent:持续的在所有Executor之间分配分区
- // ConsumerStrategies:选择如何在Driver和Executor上创建和配置Kafka Consumer
- // ConsumerStrategies.Subscribe:订阅一系列主题
- def getKafkaStream(topic: String, ssc: StreamingContext): InputDStream[ConsumerRecord[String, String]] = {
- //3.kafka消费者配置
- val kafkaParam = Map(
- "bootstrap.servers" -> brokers,
- "key.deserializer" -> classOf[StringDeserializer],
- "value.deserializer" -> classOf[StringDeserializer],
- "group.id" -> "commerce-consumer-group" //消费者组
- )
- val dStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
- ssc,
- LocationStrategies.PreferConsistent,
- ConsumerStrategies.Subscribe[String, String](Array(topic), kafkaParam)
- )
- dStream
- }
- }
JDBCUtil工具类
- package com.zhangjk.util
- import java.sql.{Connection, PreparedStatement, ResultSet}
- import java.util.Properties
- import com.alibaba.druid.pool.DruidDataSourceFactory
- import javax.sql.DataSource
- object JDBCUtil {
- //初始化连接池
- var dataSource: DataSource = init()
- //初始化连接池方法
- def init(): DataSource = {
- val properties = new Properties()
- val config: Properties = PropertiesUtil.load("config.properties")
- properties.setProperty("driverClassName", "com.mysql.jdbc.Driver")
- properties.setProperty("url", config.getProperty("jdbc.url"))
- properties.setProperty("username", config.getProperty("jdbc.user"))
- properties.setProperty("password", config.getProperty("jdbc.password"))
- properties.setProperty("maxActive", config.getProperty("jdbc.datasource.size"))
- DruidDataSourceFactory.createDataSource(properties)
- }
- //获取MySQL连接
- def getConnection: Connection = {
- dataSource.getConnection
- }
- //执行SQL语句,单条数据插入
- def executeUpdate(connection: Connection, sql: String, params: Array[Any]): Int = {
- var rtn = 0
- var pstmt: PreparedStatement = null
- try {
- connection.setAutoCommit(false)
- pstmt = connection.prepareStatement(sql)
- if (params != null && params.length > 0) {
- for (i <- params.indices) {
- pstmt.setObject(i + 1, params(i))
- }
- }
- rtn = pstmt.executeUpdate()
- connection.commit()
- pstmt.close()
- } catch {
- case e: Exception => e.printStackTrace()
- }
- rtn
- }
- //判断一条数据是否存在
- def isExist(connection: Connection, sql: String, params: Array[Any]): Boolean = {
- var flag: Boolean = false
- var pstmt: PreparedStatement = null
- try {
- pstmt = connection.prepareStatement(sql)
- for (i <- params.indices) {
- pstmt.setObject(i + 1, params(i))
- }
- flag = pstmt.executeQuery().next()
- pstmt.close()
- } catch {
- case e: Exception => e.printStackTrace()
- }
- flag
- }
- //获取MySQL的一条数据
- def getDataFromMysql(connection: Connection, sql: String, params: Array[Any]): Long = {
- var result: Long = 0L
- var pstmt: PreparedStatement = null
- try {
- pstmt = connection.prepareStatement(sql)
- for (i <- params.indices) {
- pstmt.setObject(i + 1, params(i))
- }
- val resultSet: ResultSet = pstmt.executeQuery()
- while (resultSet.next()) {
- result = resultSet.getLong(1)
- }
- resultSet.close()
- pstmt.close()
- } catch {
- case e: Exception => e.printStackTrace()
- }
- result
- }
- // 主方法,用于测试上述方法
- def main(args: Array[String]): Unit = {
- //1 获取连接
- val connection: Connection = getConnection
- //2 预编译SQL
- val statement: PreparedStatement = connection.prepareStatement("select * from user_ad_count where userid = ?")
- //3 传输参数
- statement.setObject(1, "a")
- //4 执行sql
- val resultSet: ResultSet = statement.executeQuery()
- //5 获取数据
- while (resultSet.next()) {
- println("111:" + resultSet.getString(1))
- }
- //6 关闭资源
- resultSet.close()
- statement.close()
- connection.close()
- }
- }
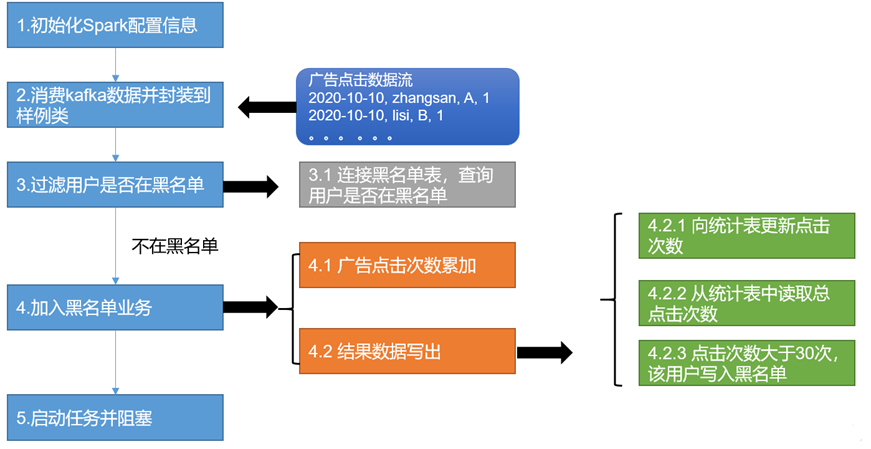
BlackListHandler广告黑名单业务
- package com.zhangjk.handler
- import java.sql.Connection
- import java.text.SimpleDateFormat
- import java.util.Date
- import com.zhangjk.app.Ads_log
- import com.zhangjk.util.JDBCUtil
- import org.apache.spark.streaming.dstream.DStream
- object BlackListHandler {
- //时间格式化对象
- private val sdf = new SimpleDateFormat("yyyy-MM-dd")
- def addBlackList(filterAdsLogDStream: DStream[Ads_log]): Unit = {
- //统计当前批次中单日每个用户点击每个广告的总次数
- //1.转换和累加:ads_log=>((date,user,adid),1) =>((date,user,adid),count)
- val dateUserAdToCount: DStream[((String, String, String), Long)] = filterAdsLogDStream.map(
- adsLog => {
- //a.将时间戳转换为日期字符串
- val date: String = sdf.format(new Date(adsLog.timestamp))
- //b.返回值
- ((date, adsLog.userid, adsLog.adid), 1L)
- }
- ).reduceByKey(_ + _)
- //2 写出
- dateUserAdToCount.foreachRDD(
- rdd => {
- // 每个分区数据写出一次
- rdd.foreachPartition(
- iter => {
- // 获取连接
- val connection: Connection = JDBCUtil.getConnection
- iter.foreach { case ((dt, user, ad), count) =>
- // 向MySQL中user_ad_count表,更新累加点击次数
- JDBCUtil.executeUpdate(
- connection,
- """
- |INSERT INTO user_ad_count (dt,userid,adid,count)
- |VALUES (?,?,?,?)
- |ON DUPLICATE KEY
- |UPDATE count=count+?
- """.stripMargin, Array(dt, user, ad, count, count)
- )
- // 查询user_ad_count表,读取MySQL中点击次数
- val ct: Long = JDBCUtil.getDataFromMysql(
- connection,
- """
- |select count from user_ad_count where dt=? and userid=? and adid =?
- |""".stripMargin,
- Array(dt, user, ad)
- )
- // 点击次数>30次,加入黑名单
- if (ct >= 30) {
- JDBCUtil.executeUpdate(
- connection,
- """
- |INSERT INTO black_list (userid) VALUES (?) ON DUPLICATE KEY update userid=?
- |""".stripMargin,
- Array(user, user)
- )
- }
- }
- connection.close()
- }
- )
- }
- )
- }
- // 判断用户是否在黑名单中
- def filterByBlackList(adsLogDStream: DStream[Ads_log]): DStream[Ads_log] = {
- adsLogDStream.filter(
- adsLog => {
- // 获取连接
- val connection: Connection = JDBCUtil.getConnection
- // 判断黑名单中是否存在该用户
- val bool: Boolean = JDBCUtil.isExist(
- connection,
- """
- |select * from black_list where userid=?
- |""".stripMargin,
- Array(adsLog.userid)
- )
- // 关闭连接
- connection.close()
- // 返回是否存在标记
- !bool
- }
- )
- }
- }
RealtimeApp主程序
- package com.zhangjk.app
- import java.util.{Date, Properties}
- import com.zhangjk.handler.BlackListHandler
- import com.zhangjk.util.{MyKafkaUtil, PropertiesUtil}
- import org.apache.kafka.clients.consumer.ConsumerRecord
- import org.apache.spark.SparkConf
- import org.apache.spark.streaming.dstream.{DStream, InputDStream}
- import org.apache.spark.streaming.{Seconds, StreamingContext}
- object RealTimeApp {
- def main(args: Array[String]): Unit = {
- //1.创建SparkConf
- val sparkConf: SparkConf = new SparkConf().setAppName("RealTimeApp ").setMaster("local[*]")
- //2.创建StreamingContext
- val ssc = new StreamingContext(sparkConf, Seconds(3))
- //3.读取数据
- val properties: Properties = PropertiesUtil.load("config.properties")
- val topic: String = properties.getProperty("kafka.topic")
- val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = MyKafkaUtil.getKafkaStream(topic, ssc)
- //4.将从Kafka读出的数据转换为样例类对象
- val adsLogDStream: DStream[Ads_log] = kafkaDStream.map(record => {
- val value: String = record.value()
- val arr: Array[String] = value.split(" ")
- Ads_log(arr(0).toLong, arr(1), arr(2), arr(3), arr(4))
- })
- //5.需求一:根据MySQL中的黑名单过滤当前数据集
- val filterAdsLogDStream: DStream[Ads_log] = BlackListHandler.filterByBlackList(adsLogDStream)
- //6.需求一:将满足要求的用户写入黑名单
- BlackListHandler.addBlackList(filterAdsLogDStream)
- //测试打印
- filterAdsLogDStream.cache()
- filterAdsLogDStream.count().print()
- //启动任务
- ssc.start()
- ssc.awaitTermination()
- }
- }
- // 时间 地区 城市 用户id 广告id
- case class Ads_log(timestamp: Long, area: String, city: String, userid: String, adid: String)
测试
1)启动Kafka集群
zk.sh start
kf.sh start
2)启动广告黑名单主程序:RealTimeApp.scala
3)启动日志生成程序:MockerRealTime.scala
4)观察spark2020中user_ad_count和black_list中数据变化
观察到:黑名单中包含所有用户id,用户统计表中,不会有数据再更新
需求二:各个地区各个城市各广告点击量实时统计
描述:实时统计每天各地区各城市各广告的点击总流量,并将其存入MySQL。
需求分析
MySQL建表
CREATE TABLE area_city_ad_count (
dt VARCHAR(255),
area VARCHAR(255),
city VARCHAR(255),
adid VARCHAR(255),
count BIGINT,
PRIMARY KEY (dt,area,city,adid)
);
DateAreaCityAdCountHandler广告点击实时统计
- package com.zhangjk.handler
- import java.sql.Connection
- import java.text.SimpleDateFormat
- import java.util.Date
- import com.zhangjk.app.Ads_log
- import com.zhangjk.util.JDBCUtil
- import org.apache.spark.streaming.dstream.DStream
- object DateAreaCityAdCountHandler {
- // 时间格式化对象
- private val sdf: SimpleDateFormat = new SimpleDateFormat("yyyy-MM-dd")
- // 根据黑名单过滤后的数据集,统计每天各大区各个城市广告点击总数并保存至MySQL中
- def saveDateAreaCityAdCountToMysql(filterAdsLogDStream: DStream[Ads_log]): Unit = {
- //1.统计每天各大区各个城市广告点击总数
- val dateAreaCityAdToCount: DStream[((String, String, String, String), Long)] = filterAdsLogDStream.map(ads_log => {
- //a.格式化为日期字符串
- val dt: String = sdf.format(new Date(ads_log.timestamp))
- //b.组合,返回
- ((dt, ads_log.area, ads_log.city, ads_log.adid), 1L)
- }).reduceByKey(_ + _)
- //2.将单个批次统计之后的数据集合MySQL数据对原有的数据更新
- dateAreaCityAdToCount.foreachRDD(rdd => {
- //对每个分区单独处理
- rdd.foreachPartition(iter => {
- //a.获取连接
- val connection: Connection = JDBCUtil.getConnection
- //b.写库
- iter.foreach { case ((dt, area, city, adid), ct) =>
- JDBCUtil.executeUpdate(
- connection,
- """
- |INSERT INTO area_city_ad_count (dt,area,city,adid,count)
- |VALUES(?,?,?,?,?)
- |ON DUPLICATE KEY
- |UPDATE count=count+?;
- """.stripMargin,
- Array(dt, area, city, adid, ct, ct)
- )
- }
- //c.释放连接
- connection.close()
- })
- })
- }
- }
RealTimeApp主程序
- package com.zhangjk.app
- import java.util.{Date, Properties}
- import com.zhangjk.handler.{BlackListHandler, DateAreaCityAdCountHandler}
- import com.zhangjk.util.{MyKafkaUtil, PropertiesUtil}
- import org.apache.kafka.clients.consumer.ConsumerRecord
- import org.apache.spark.SparkConf
- import org.apache.spark.streaming.dstream.{DStream, InputDStream}
- import org.apache.spark.streaming.{Seconds, StreamingContext}
- object RealTimeApp {
- def main(args: Array[String]): Unit = {
- //1.创建SparkConf
- val sparkConf: SparkConf = new SparkConf().setAppName("RealTimeApp ").setMaster("local[*]")
- //2.创建StreamingContext
- val ssc = new StreamingContext(sparkConf, Seconds(3))
- //3.读取数据
- val properties: Properties = PropertiesUtil.load("config.properties")
- val topic: String = properties.getProperty("kafka.topic")
- val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = MyKafkaUtil.getKafkaStream(topic, ssc)
- //4.将从Kafka读出的数据转换为样例类对象
- val adsLogDStream: DStream[Ads_log] = kafkaDStream.map(record => {
- val value: String = record.value()
- val arr: Array[String] = value.split(" ")
- Ads_log(arr(0).toLong, arr(1), arr(2), arr(3), arr(4))
- })
- //5.需求一:根据MySQL中的黑名单过滤当前数据集
- val filterAdsLogDStream: DStream[Ads_log] = BlackListHandler.filterByBlackList(adsLogDStream)
- //6.需求一:将满足要求的用户写入黑名单
- BlackListHandler.addBlackList(filterAdsLogDStream)
- //测试打印
- filterAdsLogDStream.cache()
- filterAdsLogDStream.count().print()
- //7.需求二:统计每天各大区各个城市广告点击总数并保存至MySQL中
- DateAreaCityAdCountHandler.saveDateAreaCityAdCountToMysql(filterAdsLogDStream)
- //启动任务
- ssc.start()
- ssc.awaitTermination()
- }
- }
- // 时间 地区 城市 用户id 广告id
- case class Ads_log(timestamp: Long, area: String, city: String, userid: String, adid: String)
测试
1)清空black_list表中所有数据
2)启动主程序:RealTimeApp.scala
3)启动日志生成程序:MockerRealTime.scala
4)观察spark2020中表area_city_ad_count的数据变化
需求三:最近一小时广告点击量
说明:实际测试时,为了节省时间,统计的是2分钟内广告点击量
结果展示:广告id,List[时间-> 点击次数,时间->点击次数,时间->点击次数]
1:List [15:50->10,15:51->25,15:52->30]
2:List [15:50->10,15:51->25,15:52->30]
3:List [15:50->10,15:51->25,15:52->30]
思路分析
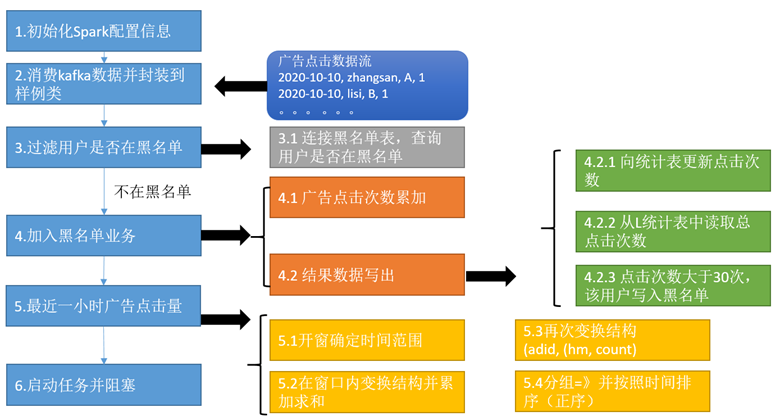
LastHourAdCountHandler最近一小时广告点击量
- package com.zhangjk.handler
- import java.text.SimpleDateFormat
- import java.util.Date
- import com.zhangjk.app.Ads_log
- import org.apache.spark.streaming.Minutes
- import org.apache.spark.streaming.dstream.DStream
- object LastHourAdCountHandler {
- //时间格式化对象
- private val sdf: SimpleDateFormat = new SimpleDateFormat("HH:mm")
- // 过滤后的数据集,统计最近一小时(2分钟)广告分时点击总数
- def getAdHourMintToCount(filterAdsLogDStream: DStream[Ads_log]): DStream[(String, List[(String, Long)])] = {
- //1.开窗 => 时间间隔为2分钟 window()
- val windowAdsLogDStream: DStream[Ads_log] = filterAdsLogDStream.window(Minutes(2))
- //2.转换数据结构 ads_log =>((adid,hm),1L) map()
- val adHmToOneDStream: DStream[((String, String), Long)] = windowAdsLogDStream.map(adsLog => {
- val hm: String = sdf.format(new Date(adsLog.timestamp))
- ((adsLog.adid, hm), 1L)
- })
- //3.统计总数 ((adid,hm),1L)=>((adid,hm),sum) reduceBykey(_+_)
- val adHmToCountDStream: DStream[((String, String), Long)] = adHmToOneDStream.reduceByKey(_ + _)
- //4.转换数据结构 ((adid,hm),sum)=>(adid,(hm,sum)) map()
- val adToHmCountDStream: DStream[(String, (String, Long))] = adHmToCountDStream.map { case ((adid, hm), count) =>
- (adid, (hm, count))
- }
- //5.按照adid分组 (adid,(hm,sum))=>(adid,Iter[(hm,sum),...]) groupByKey
- adToHmCountDStream
- .groupByKey()
- .mapValues(iter => iter.toList.sortWith(_._1 < _._1))
- }
- }
RealTimeApp主程序
- package com.zhangjk.app
- import java.util.{Date, Properties}
- import com.zhangjk.handler.{BlackListHandler, DateAreaCityAdCountHandler, LastHourAdCountHandler}
- import com.zhangjk.util.{MyKafkaUtil, PropertiesUtil}
- import org.apache.kafka.clients.consumer.ConsumerRecord
- import org.apache.spark.SparkConf
- import org.apache.spark.streaming.dstream.{DStream, InputDStream}
- import org.apache.spark.streaming.{Seconds, StreamingContext}
- object RealTimeApp {
- def main(args: Array[String]): Unit = {
- //1.创建SparkConf
- val sparkConf: SparkConf = new SparkConf().setAppName("RealTimeApp ").setMaster("local[*]")
- //2.创建StreamingContext
- val ssc = new StreamingContext(sparkConf, Seconds(3))
- //3.读取数据
- val properties: Properties = PropertiesUtil.load("config.properties")
- val topic: String = properties.getProperty("kafka.topic")
- val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = MyKafkaUtil.getKafkaStream(topic, ssc)
- //4.将从Kafka读出的数据转换为样例类对象
- val adsLogDStream: DStream[Ads_log] = kafkaDStream.map(record => {
- val value: String = record.value()
- val arr: Array[String] = value.split(" ")
- Ads_log(arr(0).toLong, arr(1), arr(2), arr(3), arr(4))
- })
- //5.需求一:根据MySQL中的黑名单过滤当前数据集
- val filterAdsLogDStream: DStream[Ads_log] = BlackListHandler.filterByBlackList(adsLogDStream)
- //6.需求一:将满足要求的用户写入黑名单
- BlackListHandler.addBlackList(filterAdsLogDStream)
- //测试打印
- filterAdsLogDStream.cache()
- filterAdsLogDStream.count().print()
- //7.需求二:统计每天各大区各个城市广告点击总数并保存至MySQL中
- DateAreaCityAdCountHandler.saveDateAreaCityAdCountToMysql(filterAdsLogDStream)
- //8.需求三:统计最近一小时(2分钟)广告分时点击总数
- val adToHmCountListDStream: DStream[(String, List[(String, Long)])] = LastHourAdCountHandler.getAdHourMintToCount(filterAdsLogDStream)
- //9.打印
- adToHmCountListDStream.print()
- //启动任务
- ssc.start()
- ssc.awaitTermination()
- }
- }
- // 时间 地区 城市 用户id 广告id
- case class Ads_log(timestamp: Long, area: String, city: String, userid: String, adid: String)
测试
1)清空black_list表中所有数据
2)启动主程序:RealTimeApp.scala
3)启动日志生成程序:MockerRealTime.scala
4)观察控制台打印数据
(1,List((16:07,15), (16:08,257), (16:09,233)))
(2,List((16:07,11), (16:08,249), (16:09,220)))
(3,List((16:07,24), (16:08,267), (16:09,221)))
(4,List((16:07,14), (16:08,252), (16:09,259)))
(5,List((16:07,17), (16:08,265), (16:09,265)))
(6,List((16:07,22), (16:08,234), (16:09,235)))
Spark详解(07-1) - SparkStreaming案例实操的更多相关文章
- RFC2544学习频率“Learning Frequency”详解—信而泰网络测试仪实操
在RFC2544中, 会有一个Learning Frequency的字段让我们选择, 其值有4个, 分别是learn once, learn Every Trial, Learn Every Fram ...
- 3.awk数组详解及企业实战案例
awk数组详解及企业实战案例 3.打印数组: [root@nfs-server test]# awk 'BEGIN{array[1]="zhurui";array[2]=" ...
- (转)awk数组详解及企业实战案例
awk数组详解及企业实战案例 原文:http://www.cnblogs.com/hackerer/p/5365967.html#_label03.打印数组:1. [root@nfs-server t ...
- 深入MySQL用户自定义变量:使用详解及其使用场景案例
一.前言 在前段工作中,曾几次收到超级话题积分漏记的用户反馈.通过源码的阅读分析后,发现问题出在高并发分布式场景下的计数器上.计数器的值会影响用户当前行为所获得积分的大小.比如,当用户在某超级话题下连 ...
- 号外号外:9月13号《Speed-BI云平台案例实操--十分钟做报表》开讲了
引言:如何快速分析纷繁复杂的数据?如何快速做出老板满意的报表?如何快速将Speed-BI云平台运用到实际场景中? 本课程将通过各行各业案例背景,将Speed-BI云平台运用到实际场景中 ...
- 新硬盘挂载-fdisk+mount案例实操
新硬盘挂载-fdisk+mount案例实操 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 现在很多服务器都支持热插拔了,当有新的硬盘插入到服务器上我们需要将其分区,格式化,然后挂载 ...
- Kafka集群优化篇-调整broker的堆内存(heap)案例实操
Kafka集群优化篇-调整broker的堆内存(heap)案例实操 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.查看kafka集群的broker的堆内存使用情况 1>. ...
- Python相关分析—一个金融场景的案例实操
哲学告诉我们:世界是一个普遍联系的有机整体,现象之间客观上存在着某种有机联系,一种现象的发展变化,必然受与之关联的其他现象发展变化的制约与影响,在统计学中,这种依存关系可以分为相关关系和回归函数关系两 ...
- Hive中的数据类型以及案例实操
@ 目录 基本数据类型 集合数据类型 案例实操 基本数据类型 对于Hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它 ...
- Spark详解
原文连接 http://xiguada.org/spark/ Spark概述 当前,MapReduce编程模型已经成为主流的分布式编程模型,它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的 ...
随机推荐
- ASP.NET Core :缓存系列(四):内存缓存 MemoryCache
System.Runtime.Caching/MemoryCache ICacheEntry 接口中的属性:具体设置过期时间 可以参考:微软文档ICacheEntry 接口 缓存基本使用 (一) 绝对 ...
- Invalid bound statement (not found)出现原因和解决方法
Invalid bound statement (not found)出现原因和解决方法 前言: 想必各位小伙伴在码路上经常会碰到奇奇怪怪的事情,比如出现Invalid bound statement ...
- lnmp配置laravel访问环境报错锦集
1.laravel配置域名访问变成下载,实际就是Nginx没有识别到.php文件.把.php文件的配置加到Nginx即可 .... # 这一段放到项目的Nginx.conf配置文件里面 locatio ...
- flutter系列之:flutter中可以建索引的栈布局IndexedStack
目录 简介 IndexedStack简介 IndexedStack的使用 总结 简介 之前我们介绍了一个flutter的栈结构的layout组件叫做Stack,通过Stack我们可以将一些widget ...
- nordic——nrf52系列SWD设置回读保护
在开发时可能需要回读保护功能,在产品出厂后这个功能可以让你的代码更加安全,无法用SEGGER或者其余方式读取你的代码HEX文件,也就是禁用SWD下载接口.但是SWD锁住了,还想使用(从新下载代码)也是 ...
- Debian安装 WineHQ 安装包
https://wiki.winehq.org/Debian_zhcn WineHQ 源仓库的密钥于 2018-12-19 改变过.如果您在此之前下载添加过该密钥,您需要重新下载和添加新的密钥并运行 ...
- prefetch和preload
前面的话 基于VUE的前端小站改造成SSR服务器端渲染后,HTML文档会自动使用preload和prefetch来预加载所需资源,本文将详细介绍preload和prefetch的使用 资源优先级 在介 ...
- linux如何删除多余网卡
ifconfig tunl0 down ip link delete tunl0
- 2022春每日一题:Day 27
题目:友好城市 分析一下可以转化为:选取最多的点对,使得点对之间连线没有交点,没有交点说明什么,假设选定第i组,则对于任意的j,一定满足a[i].l<a[j].l && a[i] ...
- KubeEdge快速上手与社区贡献实践
1.KubeEdge的架构特点与优势 持久化 云端组件,EdgeController,设备抽象API,CSI Driver,Admission WebHook 边缘组件,EdgeHub,MetaMan ...