第02章 查询DSL进阶
本章内容
Lucene默认评分公式是如何工作的。
什么是查询重写。
查询二次评分是如何工作的。
如何在单次请求中实现批量准实时读取操作。
如何在单次请求中发送多个查询。
如何对包括嵌套文档和多值字段的数据排序。
如何更新已索引的文档。
如何通过使用过滤器来优化查询。
如何在ElasticSearch的切面计算机制中使用过滤器和作用域。
2.1 Apache Lucene默认评分公式解释
为了计算文档得分,需要考虑以下这些因子:
- 文档权重(document boost):索引期赋予某个文档的权重值。
- 字段权重(field boost ):查询期赋予某个字段的权重值。
- 协调因子(coord):基于文档中词项命中个数的协调因子,一个文档命中了查询中的词项越多,得分越高。
- 逆文档频率(inverse document frequency ):一个基于词项的因子,用来告诉评分公式该词项有多么罕见。逆文档频率越低,词项越罕见。评分公式利用该因子为包含罕见词项的文档加权。
- 长度范数(( length norm ):每个字段的基于词项个数的归一化因子(在索引期计算出来并存储在索引中)。一个字段包含的词项数越多,该因子的权重越低,这意味着Apache Lucene评分公式更“喜欢”包含更少词项的字段。
- 词频(term frequency):一个基于词项的因子,用来表示一个词项在某个文档中出现了多少次。词频越高,文档得分越高。
- 查询范数(query norm ):一个基于查询的归一化因子,它等于查询中词项的权重平方和。查询范数使不同查询的得分能相互比较,尽管这种比较通常是困难且不可行的。
参考
“1.1.2 Lucene的总体架构”一节的索引示意图。
2.1.2 TF/IDF评分公式
Lucene理论评分公式
TF/IDF公式的理论形式如下:
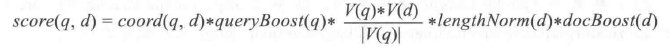
Lucene实际评分公式
现在让我们看看Lucene实际使用的评分公式:
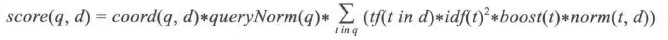
从前面的公式我们可以导出一些基本规则:
- 越多罕见的词项被匹配上,文档得分越高。
- 文档字段越短(包含更少的词项),文档得分越高。
- 权重越高(不论是索引期还是查询期赋予的权重值),文档得分越高。
2.1.3 ElasticSearch如何看评分
ElasticSearch使用了Lucene的评分功能但不仅限于Lucene的评分功能。用户可以使用各种不同的查询类型以精确控制文档评分的计算(如custom_ boost_factor查询、constant_score查询、custom_score查询等),还可以通过使用脚本(scripting)来改变文档得分,还可以使用ElasticSearch 0.90中出现的二次评分功能,通过在返回文档集之上执行另外一个查询,重新计算前N个文档的文档得分。
2.2 查询改写
从Lucene的角度来看,所谓的查询改写操作,就是把费时的原始查询类型实例改写成一个性能更高的查询类型实例。
2.2.1 前缀查询范例
示例数据
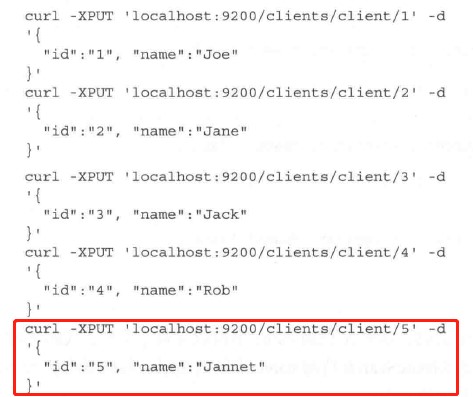
最后一条索引应该是原书将Jane写错为Jannet
也许用户想找出索引中所有name字段以字母 j 开头的文档。
curl -XGET 'localhost:9200/clients/_search?pretty' -d '{
"query":{
"prefix":{
"name":"j",
"rewrite":"constant_score_boolean"
}
}
}'返回结果中有3个文档,这些文档的name字段以字母 j 开头。我们并没有显式设置待查询索引的映射,因此ElasticSearch猜测name字段的映射,并将其设置为字符串类型并进行文本分析。可使用下面的命令查看索引的映射:
curl -XGET 'localhost:9200/clients/client/_mapping?pretty'2.2.2 回顾Apache Lucene
我们看看之前存储到clients索引中的数据是如何组织的:
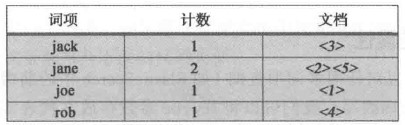
Term(词项)这一列非常重要。如果去探究ElasticSearch和Lucene的内部实现,就会发现前缀查询已经改写为下面这种查询:
ConstantScore(name:jack name:Jane name:joe)这意味着我们的前缀查询已经改写为常数得分查询(constant score query ),该查询由一个布尔查询构成,而这个布尔查询又由三个词项查询构成。Lucene所做的事情就是:枚举索引中的词项,并利用这些词项的信息来构建新的查询。当我们比较改写前后的两个查询的执行效果,会发现改写后的查询性能有所提升,尤其是当索引中有大量不同词项时。
即改写后的查询如下:
{
"query":{
"constant_score":{
"query":{
"bool":{
"should":[
{
"term":{
"name":"jack"
}
},
{
"term":{
"name":"jane"
}
},
{
"term":{
"name":"joe"
}
}
]
}
}
}
}
}2.2.3 查询改写的属性
我们可以将rewrite参数存放在代表实际查询的JSON对象中,例如,下面的代码:
{
"query":{
"prefix":{
"name":"j",
"rewrite":"constant_score_boolean"
}
}
}现在我们来看看rewrite参数有哪些选项可以配置:
- scoring_boolean:该选项将每个生成的词项转化为布尔查询中的一个或从句(should clause )。这种处理方法比较耗CPU(因为要计算和保存每个词项的得分),而且有些查询生成的词项太多从而超出了布尔查询的限制,默认为1024个从句。改写后的查询会保存计算出来的得分。默认的布尔查询限制可以通过设置elasticsearch.yml文件的index.query.bool.max_ clause_ count属性来修改。但需谨记,改写后的布尔查询的从句越多,查询性能越低。
- constant_score_boolean:该选项与前面提到的scoring_boolean类似,但是CPU消耗较少,这是因为该过程并不计算每个从句的得分,而是每个从句得到一个与查询权重相同的常数得分,默认情况下等于1,当然我们也可以通过设置查询权重来改变这个默认值。与scoring_boolean类似,该选项也有布尔从句数的限制。
- constant_score_filter:正如Lucene的Javadoc描述的那样,该选项按如下方式改写原始查询:通过顺序遍历每个词项来创建一个私有的过滤器,标记跟每个词项相关的所有文档。命中的文档被赋予一个跟查询权重相同的常量得分。当命中词项数或文档数较大时,该方法比scoring_boolean和constant_ score_boolean执行速度更快。
- top_terms_N:该选项将每个生成的词项转化为布尔查询中的一个或从句,并保存计算出来的查询得分。与scoring_boolean不同之处在于,该方法只保留了最佳的前N个同项,从而避免超出布尔从句数的限制。
- top_terms_boost_N:该选项与top_ terms_ N类似,不同之处在于该选项产生的从句类型为常量得分查询,得分为从句的权重。
如何决定何时采用何种查询改写方法?
该问题的答案更多取决于具体的应用场景。简单来说,如果你能接受低精度(往往伴随着高性能),那么可以采用top N查询改写方法。如果你需要更高的查询精度(往往伴随着低性能),那么应该使用布尔方法。
2.3 二次评分
2.3.1 理解二次评分
ElasticSearch中的二次评分指的是重新计算查询返回文档中指定个数文档的得分。这意味着ElasticSearch会截取查询返回文档的前N个,并使用预定义的二次评分方法来重新计算它们的得分。
2.3.2 范例数据
我们的范例数据保存在documents.json文件中(本书提供了这些代码),并可用以下命令添加到索引中:
curl -XPOST localhoat:9200/_bulk?pretty --data-binary @documents.json范例数据如下
{ "index": {"_index": "library", "_type": "book", "_id": "1"}}
{ "title": "All Quiet on the Western Front","otitle": "Im Westen nichts Neues","author": "Erich Maria Remarque","year": 1929,"characters": ["Paul Bäumer", "Albert Kropp", "Haie Westhus", "Fredrich Müller", "Stanislaus Katczinsky", "Tjaden"],"tags": ["novel"],"copies": 1, "available": true, "section" : 3}
{ "index": {"_index": "library", "_type": "book", "_id": "2"}}
{ "title": "Catch-22","author": "Joseph Heller","year": 1961,"characters": ["John Yossarian", "Captain Aardvark", "Chaplain Tappman", "Colonel Cathcart", "Doctor Daneeka"],"tags": ["novel"],"copies": 6, "available" : false, "section" : 1}
{ "index": {"_index": "library", "_type": "book", "_id": "3"}}
{ "title": "The Complete Sherlock Holmes","author": "Arthur Conan Doyle","year": 1936,"characters": ["Sherlock Holmes","Dr. Watson", "G. Lestrade"],"tags": [],"copies": 0, "available" : false, "section" : 12}
{ "index": {"_index": "library", "_type": "book", "_id": "4"}}
{ "title": "Crime and Punishment","otitle": "Преступлéние и наказáние","author": "Fyodor Dostoevsky","year": 1886,"characters": ["Raskolnikov", "Sofia Semyonovna Marmeladova"],"tags": [],"copies": 0, "available" : true}2.3.4 二次评分查询的结构
{
"fields":["title","available"],
"query":{
"match all":{}
},
"rescore":{
"query":{
"rescore_query":{
"custom_score":{
"query":{
"match_all":{}
},
"script":"doc['year'].value"
}
}
}
}
}我们在查询中指定只返回文档的title和available字段。
这里只是使用了一个简单的查询返回所有的文档,并且将每个文档的得分改写为该文档的year字段中的值(本范例只是用来演示二次评分,并没有实际意义)。
结果如下

仔细看看现在让我们看看原始文档以及各个文档的得分。ElasticSearch截取了前N个文档,并对它们使用了第二个查询。这么做的结果是,文档的得分等于两个查询的得分之和。
读者应该知道,执行脚本性能低下,因此我们在第二个查询上再使用它。范例中的第一个match_all查询可能会返回成千上万的文档,如果直接在这里使用基于脚本的评分,那么性能会非常低下。由于二次评分使得我们可以在原始查询返回文档的前N个文档上重新计算得分,因而降低了对性能的影响。
2.3.5二次评分参数配置
在rescore对象中的查询对象中,必须配置下面这些参数:
- window_size:窗口大小,该参数默认设置为from和size参数值之和。它提供了之前提到的N个文档的相关信息。该参数值指定了每个分片上参与二次评分的文档N个数。
- query_weight:查询权重值,默认等于1,原始查询的得分与二次评分的得分相加之前将乘以该值。
- rescore_query_weight:二次评分查询的权重值,默认等于1,二次评分查询的得分在与原始查询得分相加之前,将乘以该值。
- rescore_mode:二次评分的模式,默认设置为total, 它定义了二次评分中文档得分的计算方式,可用的选项有total , max , min , avg和multiply。当我们设置该参数值为total时,文档得分为原始查询得分与二次评分得分之和。当该参数值设置为max,文档得分为原始查询得分与二次评分得分中的最大值。与max选项类似,当该参数值设置为min时,文档得分为两次查询得分中的最小值。以此类推,参数值为avg时,文档得分为两次查询得分的平均值。当参数值为multiply时,文档得分为两次杳询得分的乘积。
Note
二次评分功能并不能与排序一起使用,这是因为排序发生在二次评分之前。
2.4 批量操作
2.4.1批量取
批量取(MultiGet)可以通过_mget端点(endpoint )操作,它允许使用一个请求获取多个文档。与实时获取功能类似,文档获取也是实时的,ElasticSearch会返回那些被索引的文档,而不论这些文档可用于搜索还是暂时对查询不可见。请查看下面的操作:
curl localhost:9200/library/book/_mget?fields=title -d '{
"ids":[1,37]
}'2.4.2 批量查询
与批量取类似,批量查询允许用户将多个查询请求打包到一组。不过它的分组略有不同,更像批量索引操作。ElasticSearch将输人解析成一行一行的文本,而文本行(每一对)包含了目标索引、其他参数以及查询串等信息。请查看下面这个简单的范例:
curl localhost:9200/library/books/_msearch?pretty --data-binary '
{"type":"book"}
{"filter":{"term":{"year":1936}}}
{"search_type":"count"}
{"query",{"match all":{}}}
{"index":"library_backup","type":"book"}
{"sort":["year"]}
'URL中的索引名及类型是可选的,并且会作为剩余输人行的默认参数。剩余行可用于存储搜索类型信息(search_type)以及查询执行的路由或提示信息(preference)。因为这些参数并不是必需的,在某些特殊情况下,行中可以包含空对象({})甚至行本身为空。请求的偶数行负责携带真正的查询。
以上批量查询只发送了三个请求而已,两行组成一个查询
返回的JSON结果包含了与批量搜索中的查询相对应的响应对象(response object)数组。如前所述,批量查询允许我们将多个独立的查询打包到一个请求中,因此,与之对应的,不同查询的返回文档可能具有不同的结构(本范例省略了)。
2.5 排序
自定义排序示例
{
"query":{
"terms":{
"tit1e":["crime","front","punishment"],
"minimum_match":1
}
},
"sort":[
{
"section":"desc"
}
]
}该查询范例会返回所有在title字段上至少命中一个词项的文档,并基于section字段数据排序。
也可以通过添加查询的sort部分的missing属性为那些section字段有缺失值的文档益制排序行为。例如,这样设置之前查询范例的sort配置,将section字段值缺失的文档排在最后:
"section":{"order":"asc", "missing":"_last"}}
2.5.1 基于多值字段的排序
某些文档的release_dates字段里存储了多个电影上映日期(同一部电影在不同国家的上映日期不同)。如果我们使用了ElasticSearch 0.90,我们可以如此构造查询请求:
{
"query":{
"match_all":{
}
},
"sort":[
{
"release_dates":{
"order":"asc",
"mode":"min"
}
}
]
}例子中,ElasticSearch将基于每个文档的release dates字段的最小值进行排序。mode参数可以设置为以下这些值:
- min:升序排序的默认值,ElasticSearch将依照该字段的最小值进行排序。
- max:降序排序的默认值,ElasticSearch将依照该字段的最大值进行排序。
- avg: ElasticSearch将依照该字段的平均值进行排序。
- sum: ElasticSearch将依照该字段的总和进行排序。
请注意,后面两个选项只对数值类型字段有效。
2.5.2 基于多值geo字段的排序
mapping
{
"mappings":{
"poi":{
"properties":{
"country":{
"type":"string"
},
"loc":{
"type":"geo_point"
}
}
}
}
}数据
{"country":"UK","loc":["51.511214,-0.119824", "53.479251,-2.247926","53.962301,1.081884"]}查询语句
{
"sort":[
{
"_geo_distance":{
"loc":"51.511214,-0.119824",
"unit":"km",
"mode":"min"
}
}
]
}注意,“_geo_distance”并非一个具体的字段,loc才是具体的字段。
2.5.3 基于嵌套对象的排序
基于嵌套文档的字段排序,对以下两种情形都适用:使用了显式嵌套映射(在映射中配置type="nested")的文档以及使用了对象类型的文档。但是,两者之间的一些细微区别仍需要注意。
假设我们索引了如下数据:

正如你所见,文档中有嵌套对象,并且某些字段中有多个值(如存在多张选票)。
当使用对象类型(object type)时,可以简化查询,这是因为整个对象结构被当成一个Lucene文档进行存储的。而在使用嵌套类型的时候,ElasticSearch需要更多精确的字段信息,这是因为这些文档确实是独立的Lucene文档。但有些时候,使用nested_path属性会更加便捷。
- 按嵌套对象查询
{
"sort":[
{
"cities.votes.users":{
"order":"desc",
"mode":"min"
}
}
]
}查询返回结果按嵌套对象的users字段最小值降序排序。
- 按子文档类型查询
如果我们将嵌套文档中的子文档视为一种数据类型,则可以将查询简化为如下形式:
{
"sort":[
{
"users":{
"order":"desc",
"mode":"min"
}
}
]
}- 按照严格的嵌套类型查询
{
"sort":[
{
"users":{
"nested_path":"cities.votes",
"order":"desc",
"mode":"min"
}
}
]
}2.6 数据更新API
在索引一个新文档的时候,Lucene会对每个字段进行分析并产生词条流,词条流中的词条可能会经过滤器的额外处理,而没有过滤掉的词条会写人倒排索引中。索引过程中,一些不需要的信息可能会被抛弃,这些信息包括:某些特殊词条的位置(当词项向量没有存储时),特定词汇(停用词或同义词),词条的变形(如词干还原)。因此,我们无法更新索引中的文档,并且在每次修改文档时不得不向索引发送文档所有字段的数据。
但ElasticSearch可以通过使用_source伪字段存储和检索文档的原始数据来解决这个问题。当用户需要更改文档时,ElasticSearch会获取_source字段中的值,做相应的修改,然后向索引提交一个新文档。当然,为了使这个特性生效,_source字段必须是可用的。更新命令一个很大的局限性就是它只能更新单个的文档,目前还不支持通过查询实现批量更新。
作为示例,本节的其余部分都将使用下面命令所索引的文档:
curl -XPUT localhost:9200/library/book/1 -d '{
"title":"The Complete Sherlock Holmes",
"author":"Arthur Conan Doyle",
"year":1936",
"characters":["Sherlock Holmes", "Dr. Watson","G. Lestrade"],
"tags":{},
"copies":0,
"available": false,
"section":12
}’2.6.1 简单字段更新
curl -XPOST localhost:9200/library/book/1/_update -d'{
"doc":{
"title":"The Complete Sherlock Holmes Book! ",
"year":1935
}
}'2.6.2 使用脚本按条件更新
有些时候,在修改文档的时候添加一些额外的逻辑是很有好处的,基于这点考虑,ElasticSearch允许用户结合脚本使用更新API。例如,我们发送下面这样的请求:

script字段定义了要对文档进行的操作,这可以是任何脚本。在范例中我们指派了ctx变量来引用源文档,但一般来说,脚本中会定义多个变量。通过使用ctx._source,我们可以修改当前字段或创建新字段(如果引用不存在的字段,ElasticSearch会自动创建这个字段),这正是范例中ctx._source.year =new_date语句产生的动作。此外,也可以使用remove()方法来移除某些字段,例如:

2.6.3 使用更新API创建或删除文档
更新API不仅仅可以用来修改字段,也可以用来操作整个文档。upsert属性允许用户在当URL中地址不存在时创建一个新的文档。请查看下面这个命令:
curl localhost:9200/library/book/1/_update -d '{
"doc":{
"year":1900
},
"upsert":{
"title":"Unknown Book"
}
}'该命令修改了某个已有文档的year字段(该文档位于索引library中,book类型,文档ID为1)。如果该文档不存在,将会创建一个新文档,并且该文档会创建一个新字段title ,如请求命令中upset部分定义的那样。此外,前面的命令也可以使用脚本重写为以下形式:
curl localhost:9200/library/book/1/_update -d '{
"script":"ctx._source.year=1900",
"upsert":{
"title":"Unknown Book"
}
}最后一个有趣的特性是有条件地移除整个文档,具体可以通过设置ctx.op的值为delete来实现:
curl localhost:9200/library/book/1/_update -d '{
"script":"ctx.op=\"delete\""
}2.7 使用过滤器优化查询
2.7.1 过滤器与缓存
下面一种查询方法,该查询组合了查询类型与过滤器:
{
"query":{
"filtered":{
"query":{
"term":{
"name":"joe"
}
},
"filter":{
"term":{
"year":1981
}
}
}
}
}我们已经使用了filtered查询来同时包含查询和过滤器元素。第一次执行该查询以后, 过滤器就会被ElasticSearch缓存起来,如果后续的其他查询也要使用该过滤器,则它将会 被重复利用,从而避免ElasticSearch重复加载相关数据。
过滤器缓存(filter cache ),用来存储过滤器的结果。而且,被缓存的过滤器 并不需要消耗过多的内存(因为它们只存储了哪些文档能与过滤器相匹配的相关信息),而且可供后续所有与之相关的查询重复使用,从而极大地提高了查询性能。
并不是所有过滤都默认被缓存
字段数据缓存
缓存很有用,但事实上ElasticSearch并不是默认缓存所有过滤器。这是因为在ElasticSearch中某些过滤器使用了字段数据缓存,这是一种特殊的缓存,它可以在基于字段数据 的排序时使用,也能在计算切面结果时使用。以下过滤器默认不缓存:
numeric_range
script
geo_bbox
geo_distance
geo_distance_range
geo_polygon
geo_shape
and
or
not上面提到的过滤器中,最后三个本身并不使用字段缓存,但由于它们操作其他过滤器, 因而它们不缓存。
改变ElasticSearch的缓存行为
如果有需要,ElasticSearch允许用户通过设置_cache和_cache_ key属性来开启或关闭 过滤器的缓存机制。回到先前的例子,进行相关配置从而缓存词项过滤器结果,缓存的key 为year_1981_cache:
{
"query":{
"filtered":{
"query":{
"term":{
"name":"joe"
}
},
"filter":{
"term":{
"year":1981,
"_cache_key":"year_1981_cache"
}
}
}
}
}- 关闭过滤器缓存:
{
"query":{
"filtered":{
"query":{
"term":{
"name":"joe"
}
},
"filter":{
"term":{
"year":1981,
"_cache":false
}
}
}
}
}- 通过名称清空特定过滤器缓存:
curl -XPOST `localhost:9200/users/_cache/clear?filter_keys=year_1981_cache `2.7.2 词项查找过滤器
缓存和各种标准查询并不是ElasticSearch的全部家当。随着ElasticSearch 0.90的发布, 又一个精巧的过滤器可供我们使用了,它用于给一个具体的查询传递从ElasticSearch取回的多个词项(与SQL的IN操作符类似)。
范例数据:
book mapping:
{
"mappings" : {
"book" : {
"properties" : {
"id" : { "type" : "string", "store" : "yes", "index" : "not_analyzed" },
"title" : { "type" : "string", "store" : "yes", "index" : "analyzed" }
}
}
}
}client mapping:
{
"mappings" : {
"client" : {
"properties" : {
"id" : { "type" : "string", "store" : "yes", "index" : "not_analyzed" },
"name" : { "type" : "string", "store" : "yes", "index" : "analyzed" },
"books" : { "type" : "string", "store" : "yes", "index" : "not_analyzed" }
}
}
}
}具体数据:

现在,考虑一下如何获取某个特定用户购买的所有书籍,例如,ID为 1 的用户。
- 第一种方式,一步到位
curl -XGET 'localhost:9200/books/_search' -d '{
"query" : {
"filtered" : {
"query" : {
"match_all" : {}
},
"filter" : {
"terms" : {
"id" : {
"index" : "clients",
"type" : "client",
"id" : "1",
"path" : "books"
},
"_cache_key" : "terms_lookup_client_1_books"
}
}
}
}
}'- 笨拙的方法,分两步骤进行
查找用户1所有信息,并取books字段,表示该用户所有书籍的IDs
curl -XGET 'localhost:9200/clients/client/1'然后根据上述IDs查找所有books:
curl -XGET 'localhost:9200/books/_search' -d '{
"query":{
"ids":{
"type":"book’,
"values":["1","3"]
}
}
}'因为ElasticSearch优先在本地执行词项查询以避免不必要的网络开销和延迟,因而上述查询时若client索引与book索引在同一分片,能提高查询的性能。
词项查询过滤器缓存设置
前面提到过,为了提供词项查找功能,ElasticSearch引进了一种新的缓存类型,它使用 了一种快速的LRU(最近最少使用算法)缓存来处理词项缓存。
为了配置这种缓存,用户可以在elasticsearch.yml文件中配置下面这些属性:
- indices.cache.filter.terms.size:默认设置ElasticSearch词项查找缓存的最大内存使用 量为10mb。对于大多数案例来说,这个默认值够用了,但如果要加载更多的数据至缓存中,那么可以调大该参数值。
- indices.cache.filter.terms.expire_after_access:该属性配置了自上次查询以来的超时 时长。默认不超时。
- indices.cache.filter.terms.expire_after_ write:该属性配置了数据加载至缓存以后多长 时间将超时。默认不超时。
2.8 ElasticSearch切面机制中的过滤器与作用域
2.8.1 范例数据

2.8.2 切面计算和过滤
切面仅依赖于查询
{
"query" : {
"match_all" : {}
},
"filter" : {
"term" : { "category" : "book" }
},
"facets" : {
"price" : {
"range" : {
"field" : "price",
"ranges" : [
{ "to" : 30 },
{ "from" : 30 }
]
}
}
}
}尽管查询被限制为只返回category字段值为book的文档,但是对切而计算来说,切面作用于books索引的所有文档(因为使用了match_all查询)。系统只在查询结果之上计算切面结果。如果你在filter对象内部且在query对象外部包含了过滤器,那么这些过滤器将不会对参与切面计算的文档产生影响。
查询执行以后,将得到下面的返回结果:

2.8.3 过滤器作为查询的一部分
切面仅依赖于查询,所以让查询中包含过滤
{
"query" : {
"filtered" : {
"query" : {
"match_all" : {}
},
"filter" : {
"term" : {
"category" : "book"
}
}
}
},
"facets" : {
"price" : {
"range" : {
"field" : "price",
"ranges" : [
{ "to" : 30 },
{ "from" : 30 }
]
}
}
}
}切面计算作用于查询返回结果上,且跟事前预期的结果一样,这正是因 为过滤器成为了查询的一部分!在我们的案例中, 切面计算结果包含两个范围,每个范围 只有一个文档。
2.8.4 切面过滤器 (facet_filter)
切面有自己的过滤机制,并与查询同时生效
考虑一下,上述查询不变,但如果只想为title字段包含词项2的书籍计算分组,我们应该怎么做。
在切面类型的相同层级上使用facet_filter过滤器,能通过使用过滤器减少计算切面时 的文档数,就像在查询时使用过滤器那样。
{
"query":{
"filtered":{
"query":{
"match_all":{ }
},
"filter":{
"term":{ "category":"book"}
}
}
},
"facets":{
"price":{
"range":{
"field":"price",
"ranges":[
{ "to":30 },
{"from":30 }
]
},
"facet_filter":{
"term":{ "title":"2"}
}
}
}
}2.8.5 全局作用域
切面是全局的,不依赖于查询
如果我们想查询所有category为book的文档,但同时又要显示索引中所有文档的基于范围的切面计算结果,应该如何处理呢?幸运的是,此处并不需要强制运行第二个查询, 这是因为可以使用全局切面作用域(global faceting scope)来达成目的,并具体通过将切面类型的global属性配置为true来实现。
{
"query": {
"term": {
"category": "book"
}
},
"facets": {
"price": {
"range": {
"field": "price",
"ranges": [
{ "to": 30 },
{"from": 30}
]
},
"global": true
}
}
}参考资料
图解Elasticsearch中的_source、_all、store和index属性
Elasticsearch2.x Filter执行流程及缓存原理
使用bitset实现毫秒级查询
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">
第02章 查询DSL进阶的更多相关文章
- 【T-SQL基础】02.联接查询
概述: 本系列[T-SQL基础]主要是针对T-SQL基础的总结. [T-SQL基础]01.单表查询-几道sql查询题 [T-SQL基础]02.联接查询 [T-SQL基础]03.子查询 [T-SQL基础 ...
- 第02章 IOC和bean的配置
第02章 IOC容器和Bean的配置 1.IOC和DI ①IOC(Inversion of Control):反转控制. 在应用程序中的组件需要获取资源时,传统的方式是组件主动的从容器中获取所需要的资 ...
- 《Entity Framework 6 Recipes》中文翻译系列 (11) -----第三章 查询之异步查询
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 第三章 查询 前一章,我们展示了常见数据库场景的建模方式,本章将向你展示如何查询实体 ...
- 异步编程系列第02章 你有什么理由使用Async异步编程
p { display: block; margin: 3px 0 0 0; } --> 写在前面 在学异步,有位园友推荐了<async in C#5.0>,没找到中文版,恰巧也想提 ...
- [Programming Entity Framework] 第3章 查询实体数据模型(EDM)(一)
http://www.cnblogs.com/sansi/archive/2012/10/18/2729337.html Programming Entity Framework 第二版翻译索引 你可 ...
- Mysql技术内幕-笔记-第三章 查询处理
第三章 查询处理 逻辑查询处理:(8) SELECT (9) DISTINCT <select_list> (1) FROM <left_table> (3) <join ...
- 高性能mysql 第六章查询性能优化 总结(上)查询的执行过程
6 查询性能优化 6.1为什么查询会变慢 这里说明了的查询执行周期,从客户端到服务器端,服务器端解析,优化器生成执行计划,执行(可以细分,大体过程可以通过show profile查看),从服务器端返 ...
- 第11章:sed进阶操作
第11章:sed进阶操作 sed是一个很好的文件处理工具,本身是一个管道命令,主要是以行为单位进行处理,可以将数据行进行替换.删除.新增.选取等特定工作,下面先了解一下sed的用法 sed命令行格式为 ...
- 第10章:awk进阶操作
第10章:awk进阶操作 在第4章:查找与替换简单的讲解了awk的使用,本章介绍详细讲解awk的使用.awk是一个强大的文本分析工具,简单的说awk就是把文件逐行的读入, 以空格为默认分隔符将每行切片 ...
随机推荐
- 用CSS绘制最常见的40种形状和图形
今天在国外的网站上看到了很多看似简单却又非常强大的纯CSS绘制的图形,里面有最简单的矩形.圆形和三角形,也有各种常见的多边形,甚至是阴阳太极和网站小图标,真的非常强大,分享给大家. Square(正方 ...
- Oracle 热备份
Oracle 热备份是指数据库处于open状态下,对数据库的数据文件.控制文件.参数文件.密码文件等进行一系列备份操作. 热备是基于用户管理备份恢复的一种方式,也是除了RMAN备份之外较为常用的一种备 ...
- Centos 6.5 下安装 Zabbix server 3.0服务器的安装及 监控主机的加入(2)
一.Centos 6.5 下的Zabbix Server安装 上篇文章记录的是centos 7 下安装zabbix ,很简单.但是6.5上面没有可用的源直接安装zabbix,所以需要从别处下载.感谢i ...
- python学习笔记(七):面向对象编程、类
一.面向对象编程 面向对象--Object Oriented Programming,简称oop,是一种程序设计思想.在说面向对象之前,先说一下什么是编程范式,编程范式你按照什么方式来去编程,去实现一 ...
- python+selenium+Firefox+pycharm版本匹配
window(2018-05-29)最新 python:3.6.1 地址https://www.python.org/downloads/release/python-361/ selenium ...
- 25行 Python 代码实现人脸检测——OpenCV 技术教程
这是篇是利用 OpenCV 进行人脸识别的技术讲解.阅读本文之前,这是注意事项: 建议先读一遍本文再跑代码——你需要理解这些代码是干什么的.成功跑一遍不是目的,能够举一反三.在新任务上找出 bug 才 ...
- jssip音视频及短信开发demo(中文注释完整版)
完整案例demo下载地址:http://download.csdn.net/download/qq_39421580/10214712 <!DOCTYPE html> <html l ...
- pipenv 简要指南
pipenv 简要指南 pipenv是requests作者的一个项目, 整合了virtualenv, pip, pipfile, 用于更方便地为项目建立虚拟环境并管理虚拟环境中的第三方模块. 安装 直 ...
- Angularjs Ng_repeat中实现复选框选中并显示不同的样式
最近做了一个选择标签的功能,把一些标签展示给用户,用户选择自己喜欢的标签,就类似我们在购物网站看到的那种过滤标签似的: 简单的效果如图所示: 首先看一下html代码: 1 <!DOCTYPE h ...
- axis2 webService开发指南(3)
复杂对象类型的WebService 这次我们编写复杂点的WebService方法,返回的数据是我们定义属性带getter.setter方法JavaBean,一维数组.二维数组等 1.服务源代码 新建一 ...