[Python爬虫] 之三十一:Selenium +phantomjs 利用 pyquery抓取消费主张信息
一、介绍
本例子用Selenium +phantomjs爬取央视栏目(http://search.cctv.com/search.php?qtext=消费主张&type=video)的信息(标题,时间)
二、网站信息
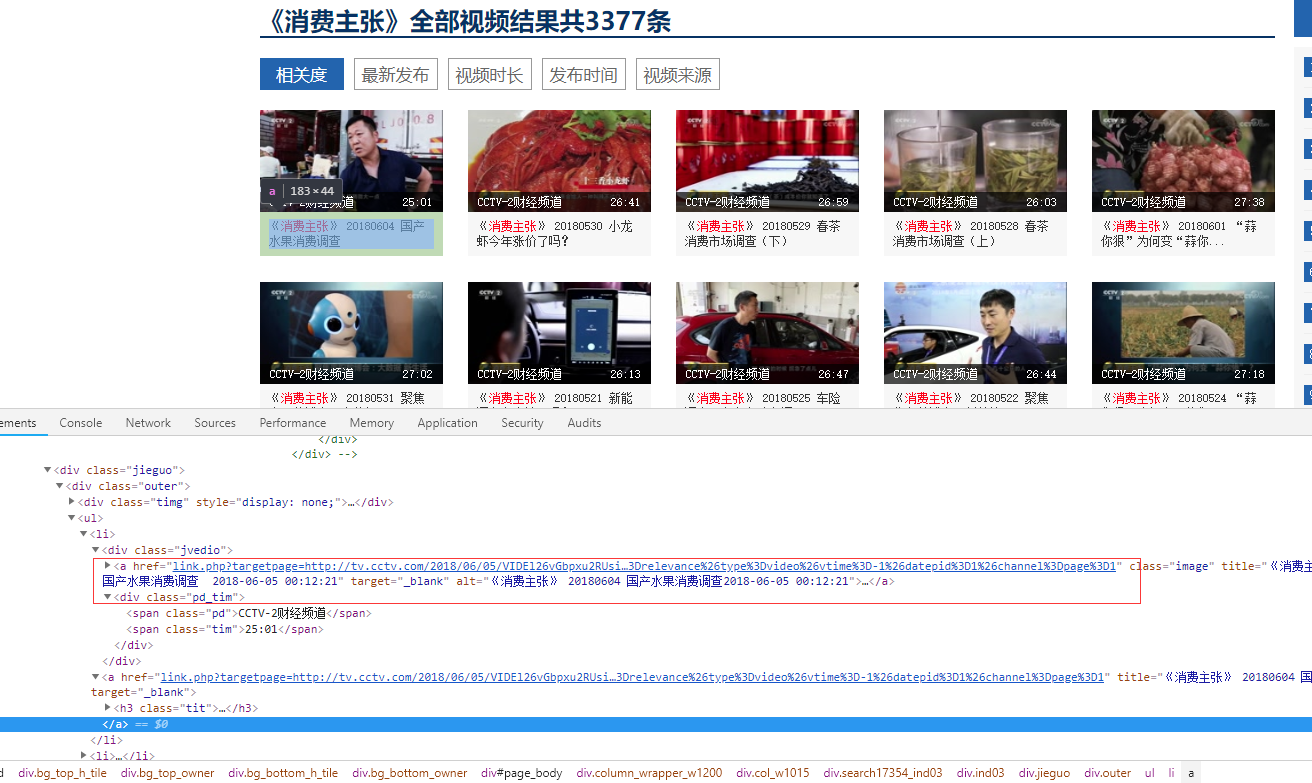
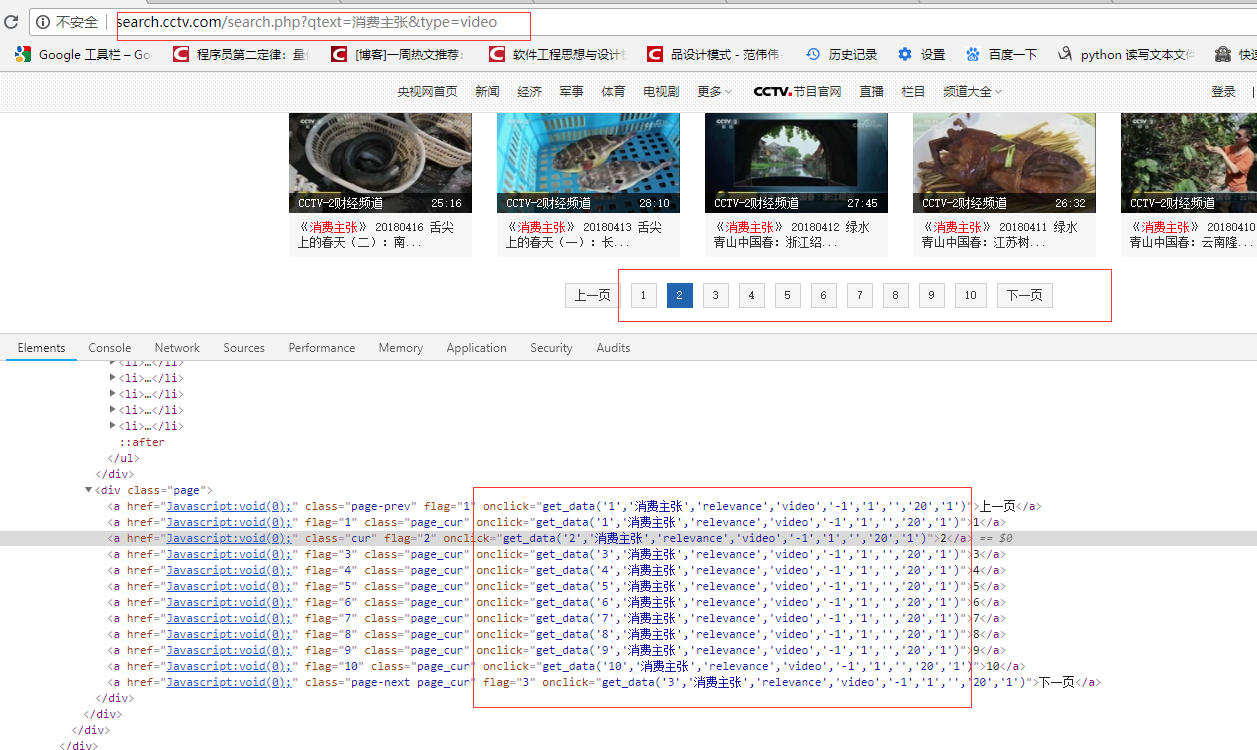
python 代码
# coding=utf-8
import os
import re
from selenium import webdriver
from datetime import datetime,timedelta
import time
from pyquery import PyQuery as pq
import re
import mongoDB
import datetime class consumer: def __init__(self):
#通过配置文件获取IEDriverServer.exe路径
# IEDriverServer ='C:\Program Files\Internet Explorer\IEDriverServer.exe'
# self.driver = webdriver.Ie(IEDriverServer)
# self.driver.maximize_window()
self.driver = webdriver.PhantomJS(service_args=['--load-images=false'])
# self.driver = driver = webdriver.Chrome()
self.driver.set_page_load_timeout(10)
self.driver.maximize_window()
self.db = mongoDB.mongoDbBase() def WriteLog(self, message,date):
fileName = os.path.join(os.getcwd(), 'consumer/' + date + '.txt')
with open(fileName, 'a') as f:
f.write(message)
# http://search.cctv.com/search.php?qtext=消费主张&type=video
def CatchData(self,url='http://search.cctv.com/search.php?qtext=%E6%B6%88%E8%B4%B9%E4%B8%BB%E5%BC%A0&type=video'):
error = ''
try:
self.driver.get(url)
time.sleep(1)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html) filename = datetime.datetime.now().strftime('%Y-%m-%d')
message = '{0},{1}'.format( '标题', '时间')
filename = datetime.datetime.now().strftime('%Y-%m-%d')
self.WriteLog(message, filename)
pages = doc("div[class='page']").find("a")
# 2018-06-05 00:12:21
pattern = re.compile("\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}")
for index in range(1,6):
url = "get_data('{0}', '消费主张', 'relevance', 'video', '-1', '1', '', '20', '1')".format(index) self.driver.execute_script(url)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html) Elements = doc("div[class='jvedio']").find("a")
for sub in Elements.items():
title = sub.attr('title').encode('utf8')
ts = pattern.findall(title)
strtime = ''
if ts and len(ts) == 1:
strtime = ts[0]
if strtime:
index = title.index(strtime)
title = title[0:index]
title = '\n{0},{1}'.format(title,strtime)
self.WriteLog(title, filename) except Exception, e1:
error = e1.message # def CatchData(self,url='http://search.cctv.com/search.php?qtext=%E6%B6%88%E8%B4%B9%E4%B8%BB%E5%BC%A0&type=video'):
# error = ''
# try:
# self.driver.get(url)
# time.sleep(1)
# selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
# doc = pq(selenium_html)
#
# filename = datetime.datetime.now().strftime('%Y-%m-%d')
#
# pages = doc("div[class='page']").find("a")
#
# for element in pages.items():
# url = element.attr('onclick').encode('utf8')
# # get_data('1','消费主张','relevance','video','-1','1','','20','1')
# # get_data('2', '消费主张', 'relevance', 'video', '-1', '1', '', '20', '1')
# print url
# self.driver.execute_script(url)
# selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
# doc = pq(selenium_html)
#
# Elements = doc("div[class='jvedio']").find("a")
# for sub in Elements.items():
# title = sub.attr('title').encode('utf8')
# print title
# title = '\n{0}'.format(title)
# self.WriteLog(title, filename)
# except Exception, e1:
# error = e1.message obj = consumer() obj.CatchData()
# obj.CatchContent('')
# obj.export('')
[Python爬虫] 之三十一:Selenium +phantomjs 利用 pyquery抓取消费主张信息的更多相关文章
- [Python爬虫] 之二十八:Selenium +phantomjs 利用 pyquery抓取网站排名信息
一.介绍 本例子用Selenium +phantomjs爬取中文网站总排名(http://top.chinaz.com/all/index.html,http://top.chinaz.com/han ...
- [Python爬虫] 之二十一:Selenium +phantomjs 利用 pyquery抓取36氪网站数据
一.介绍 本例子用Selenium +phantomjs爬取36氪网站(http://36kr.com/search/articles/电视?page=1)的资讯信息,输入给定关键字抓取资讯信息. 给 ...
- [Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目
一.介绍 本例子用Selenium +phantomjs爬取栏目(http://tv.cctv.com/lm/)的信息 二.网站信息 三.数据抓取 首先抓取所有要抓取网页链接,共39页,保存到数据库里 ...
- [Python爬虫] 之十六:Selenium +phantomjs 利用 pyquery抓取一点咨询数据
本篇主要是利用 pyquery来定位抓取数据,而不用xpath,通过和xpath比较,pyquery效率要高. 主要代码: # coding=utf-8 import os import re fro ...
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
- [Python爬虫] 之二十二:Selenium +phantomjs 利用 pyquery抓取界面网站数据
一.介绍 本例子用Selenium +phantomjs爬取界面(https://a.jiemian.com/index.php?m=search&a=index&type=news& ...
- [Python爬虫] 之二十九:Selenium +phantomjs 利用 pyquery抓取节目信息信息
一.介绍 本例子用Selenium +phantomjs爬取节目(http://tv.cctv.com/epg/index.shtml?date=2018-03-25)的信息 二.网站信息 三.数据抓 ...
- [Python爬虫] 之十七:Selenium +phantomjs 利用 pyquery抓取梅花网数据
一.介绍 本例子用Selenium +phantomjs爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字: ...
- [Python爬虫] 之二十七:Selenium +phantomjs 利用 pyquery抓取今日头条视频
一.介绍 本例子用Selenium +phantomjs爬取今天头条视频(http://www.tvhome.com/news/)的信息,输入给定关键字抓取图片信息. 给定关键字:视频:融合:电视 二 ...
随机推荐
- 【WPF】Bitmap Effect制作圆角加渲染TextBox
<Window.Resources> <ControlTemplate x:Key="txtTemplate" TargetType="{x:Type ...
- windows下srand48()和drand48()的问题
前几天在windows下用MINGW编译一段代码时,出现了错误提示说srand48()和drand48()的未定义,去网上搜了下,发现好多人也遇到了同样的问题,大约有两种解决方案: 第一个就是说gcc ...
- python爬虫(1)——BeautifulSoup库函数find_all() (转)
原文地址:http://blog.csdn.net/depers15/article/details/51934210 python--BeautifulSoup库函数find_all() 一.语法介 ...
- Cable master POJ - 1064
Inhabitants of the Wonderland have decided to hold a regional programming contest. The Judging Commi ...
- django添加REST_FRAMEWORK 接口浏览
1.安装rest_framework pip install djangorestframework 2.配置rest_framework ## 将rest_framework加入项目app列表 I ...
- PHP变量的使用
如果在用到数据时,需要用到多次就声明为变量使用: 变量的声明 $变量名=值 强类型语言中(C,Java),声明变量一定要先指定类型(酒瓶) PHP是弱类型的语言:变量的类型有存储的值决定.(瓶子) 2 ...
- 2017-2018-1 JAVA实验站 冲刺 day06
2017-2018-1 JAVA实验站 冲刺 day06 各个成员今日完成的任务 小组成员 今日工作 完成进度 张韵琪 进行工作总结.博客.小组成员头像 100% 齐力锋 找背按钮声音 100% 张浩 ...
- hdu 1011 树形dp+背包
题意:有n个房间结构可看成一棵树,有m个士兵,从1号房间开始让士兵向相邻的房间出发,每个房间有一定的敌人,每个士兵可以对抗20个敌人,士兵在某个房间对抗敌人使无法走开,同时有一个价值,问你花费这m个士 ...
- bzoj 4439: [Swerc2015]Landscaping -- 最小割
4439: [Swerc2015]Landscaping Time Limit: 2 Sec Memory Limit: 512 MB Description FJ有一块N*M的矩形田地,有两种地形 ...
- Codeforces Round #299 (Div. 2) A. Tavas and Nafas 水题
A. Tavas and Nafas Time Limit: 1 Sec Memory Limit: 256 MB 题目连接 http://codeforces.com/contest/535/pr ...