Map集合学习
Java中常用的Map实现类主要有:HashMap、HashTable、TreeMap、LinkedHashMap。
一:HashMap
HashMap介绍
HashMap的底层其实是“链表的数组”,即:每个元素其实存放着一个链表,链表存放着哈希值相同的对象们。HashMap是线程不安全的。
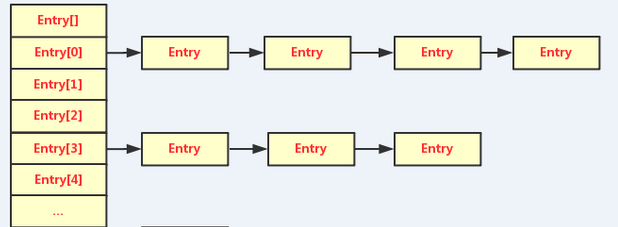
1)HashMap不是简单的用key的hashcode()值作为元素的存放下标的,而是通过二次哈希——把key的hashcode()传进HashMap自定义的hash(h)方法中计算位置(有可能大于数组长度了,所以还要对数组长取余),然后通过indexFor(h,len)方法计算出具体的数组下标(用按位与取代取余加快效率),尽量让key尽可能均匀的分配到数组上去,避免造成Hash堆积(某一下标处存放的链表过长)。
2)HashMap的冲突解决:如果有两个key的hashcode相同,那么经过hash(h)二次哈希后得到的数组索引是一样的,此时就要判断这两个key是否是同一对象:如果两个key的equals方法返回true,则说明两个key是同一对象,则此时把新值覆盖掉旧值;如果equals返回false,则说明是两个不同的key但分配到了同一数组索引位存放,则此时把新增的value添加到该索引位的链表尾。
3)插入元素时,通过key的hashcode()以及hash算法决定索引,通过equals()决定是插入链表还是覆盖原有值;
读取元素时,通过key的hashcode()以及hash算法找到索引,通过equals()遍历链表找到相对应的结点值;
(注:Map存储的是 键值对,不是单指用 key 来索引 value。而是用key 来索引 Entry!Entry就是我们说的 键值对!因此,get()时确定槽位后,在遍历Entry链表时才可以把查找的key与链表结点的key进行比较。)
主要源码:
//新建HashMap,其实是新建了一个数组
public HashMap(int initialCapacity, float loadFactor) {
// initialCapacity代表初始化HashMap的容量,它的最大容量是MAXIMUM_CAPACITY = 1 << 30。
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY; // loadFactor代表它的负载因子,默认是是DEFAULT_LOAD_FACTOR=0.75,用来计算threshold临界值的。
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor); // Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1; this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];//创建数组
init();
} //插入元素
public V put(K key, V value) {
// HashMap允许存放null键和null值。
// 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。
if (key == null)
return putForNullKey(value);
// 根据key的hashCode重新计算hash值。
int hash = hash(key.hashCode());
// 搜索指定hash值所对应table中的索引。
int i = indexFor(hash, table.length);
// 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果i索引处的Entry为null,表明此处还没有Entry。
// modCount记录HashMap中修改结构的次数
modCount++;
// 将key、value添加到i索引处。
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
// 获取指定 bucketIndex 索引处的 Entry
Entry<K,V> e = table[bucketIndex];
// 将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 如果 Map 中的 key-value 对的数量超过了极限
if (size++ >= threshold)
// 把 table 对象的长度扩充到原来的2倍。
resize(2 * table.length);
} static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
} static int indexFor(int h, int length) {
return h & (length-1);
}
//它通过 h & (table.length -1) 来得到该对象的保存位,而HashMap底层数组的长度总是 2 的n 次方,这是HashMap在速度上的优化。
//当length总是 2 的n次方时,h& (length-1)运算等价于对length取模,也就是h%length,但是&比%具有更高的效率。 //读取元素
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
} //HashMap数组扩容
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//如果当前的数组长度已经达到最大值,则不在进行调整
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//根据传入参数的长度定义新的数组
Entry[] newTable = new Entry[newCapacity];
//按照新的规则,将旧数组中的元素转移到新数组中
transfer(newTable);
table = newTable;
//更新临界值
threshold = (int)(newCapacity * loadFactor);
} //旧数组中元素往新数组中迁移
void transfer(Entry[] newTable) {
//旧数组
Entry[] src = table;
//新数组长度
int newCapacity = newTable.length;
//遍历旧数组
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
HashMap常用方法
实例介绍:
public static void main(String[] args) {
HashMap<String, Integer> map=new HashMap<>();
/*Collection<Integer>*///显示所有的value值
System.out.println(map.values());//[]
//Hashmap的存值:
map.put("DEMO1", 1);
map.put("DEMO2", 2);
//Hashmap的取值:得到map中key相对应的value的值
System.out.println(map.get("1"));//null
System.out.println(map.get("DEMO"));//1
//Hashmap的判断为空:
System.out.println(map.isEmpty());//false
//判断是否含有key:
System.out.println(map.containsKey("DEMO"));//true
//判断是否含有value:
System.out.println(map.containsValue(1));//true
//Hashmap的元素个数:
System.out.println(map.size());//2
//显示map所有的key:
System.out.println(map.keySet());//[DEMO1, DEMO2]
//显示所有的key和value:
System.out.println(map.entrySet());//[DEMO1=1, DEMO2=2]
//添加另一个同一类型的map下的所有的key和value:
HashMap<String, Integer> map1=new HashMap<>();
map1.putAll(map);
System.out.println(map1);//{DEMO1=1, DEMO2=2}
//删除这个key值下的value:
map.put("DEMO3", 3);
System.out.println(map.remove("DEMO3"));//3(删除的值)
//替换这个key的value:(java8)
map.put("DEMO3", 3);
System.out.println(map.remove("DEMO3", 1));//false
System.out.println(map.remove("DEMO2", 3));//true
//克隆Hashmap:
System.out.println(map.clone());//{DEMO1=1, DEMO2=2}
//清空Hashmap:
map1.clear();//
System.out.println(map1);//{}
System.out.println(map.values());//[1, 1]
}
HashMap的四种访问方式
第一种:通过Map.entrySet使用iterator遍历key和value,entry放着的就是Map中的某一对key-value;
public void visit_1(HashMap<String,Integer> hm){
Iterator<Map.Entry<String,Integer>> it = hm.entrySet().iterator();
while(it.hasNext()){
Map.Entry<String ,Integer> entry = it.next();
String key = entry.getKey();
Integer value = entry.getValue();
}
}
第二种:通过Map.keySet()来遍历value,使用foreach读取
public void visit_2(HashMap<String,Integer> hm){
for (String key:hm.keySet()){
Integer value = hm.get(key);
}
}
第三种:通过Map.Entry遍历key和value(最快,推荐)
public void visit_3(HashMap<String,Integer> hm){
for(Map.Entry<String,Integer> entry:hm.entrySet()){
String key = entry.getKey();
Integer value = entry.getValue();
}
}
第四种:通过Map.keySet使用iterator遍历key和value,和第二种都是读Key集合,但使用迭代器读取较快
public void visit_4(HashMap<Integer,String> hm){
long startTime = System.currentTimeMillis();
Iterator<Integer> it = hm.keySet().iterator();
while(it.hasNext()){
Integer key = it.next();
String value = hm.get(key);
}
System.out.println("visit_4 10000000 entry:"
+ (System.currentTimeMillis()-startTime) + " milli seconds");
}
四种方法比较:
package com.hashmap; import java.util.HashMap;
import java.util.Iterator;
import java.util.Map; public class HashMapVisitTest {
public void visit_1(HashMap<Integer,String> hm){
long startTime = System.currentTimeMillis();
Iterator<Map.Entry<Integer,String>> it = hm.entrySet().iterator();
while(it.hasNext()){
Map.Entry<Integer,String> entry = it.next();
Integer key = entry.getKey();
String value = entry.getValue();
}
System.out.println("visit_1 10000000 entry:"
+ (System.currentTimeMillis()-startTime) + " milli seconds");
}
public void visit_2(HashMap<Integer,String> hm){
long startTime = System.currentTimeMillis();
for (Integer key:hm.keySet()){
String value = hm.get(key);
}
System.out.println("visit_1 10000000 entry:"
+ (System.currentTimeMillis()-startTime) + " milli seconds");
}
public void visit_3(HashMap<Integer,String> hm){
long startTime = System.currentTimeMillis();
for(Map.Entry<Integer,String> entry : hm.entrySet()){
Integer key = entry.getKey();
String value = entry.getValue();
}
System.out.println("visit_1 10000000 entry:"
+ (System.currentTimeMillis()-startTime) + " milli seconds");
}
public void visit_4(HashMap<Integer,String> hm){
long startTime = System.currentTimeMillis();
Iterator<Integer> it = hm.keySet().iterator();
while(it.hasNext()){
Integer key = it.next();
String value = hm.get(key);
}
System.out.println("visit_1 10000000 entry:"
+ (System.currentTimeMillis()-startTime) + " milli seconds");
}
public static void main(String [] args){
HashMap<Integer,String> hm = new HashMap<>();
for(int i = 1;i <= 10000000;++i){
hm.put(i,"num: " + i);
}
new HashMapVisitTest().visit_1(hm);
new HashMapVisitTest().visit_2(hm);
new HashMapVisitTest().visit_3(hm);
new HashMapVisitTest().visit_4(hm); }
}
HashMap线程不安全
HashMap线程不安全的原因从上面的代码可以看出端倪——冲突的解决以及数组扩容 在多线程下容易发生竞态条件(结果取决于执行的顺序)。
冲突造成不安全:当多个线程共同操作一个HashMap对象时,某一时刻都向map的key拥有相同的hashcode,若key是相同的对象,则最终的value值取决于哪个线程是最终执行的,覆盖掉前面的值;如果key是不同的对象,我们知道此时把值插入链表,而链表当前结点只有一个next指针,那么多个线程中都已缓存了这个指针,都认为这个指针是可用的,并令它指向了当前插入的新结点。那么最后同步回主内存时就会出问题了:指针只有一个。不能同时指向多个结点。
扩容造成的不安全:当多个线程共同操作一个HashMap对象时,某一时刻同时触发了数组扩容,那么线程轮换执行时都对这个数组进行扩容会覆盖掉前面线程的扩容结果。
二:HashTable
HashTable底层也是一个“链表数组”,其插入元素和查询元素的策略与HashMap几乎一样。不同的是:很多线程敏感的方法用syncrhoized关键字进行修饰。所以,我们说:HashTable是线程安全的。(类似于Vector对ArrayList线程敏感的方法进行限定)。
主要源码:
package java.util;
import java.io.*; public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable { // Hashtable保存key-value的数组。
// Hashtable是采用拉链法实现的,每一个Entry本质上是一个单向链表
private transient Entry[] table; // Hashtable中元素的实际数量
private transient int count; // 阈值,用于判断是否需要调整Hashtable的容量(threshold = 容量*加载因子)
private int threshold; // 加载因子
private float loadFactor; // Hashtable被改变的次数
private transient int modCount = 0; // 序列版本号
private static final long serialVersionUID = 1421746759512286392L; // 指定“容量大小”和“加载因子”的构造函数
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor); if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry[initialCapacity];
threshold = (int)(initialCapacity * loadFactor);
} // 指定“容量大小”的构造函数
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
} // 默认构造函数。
public Hashtable() {
// 默认构造函数,指定的容量大小是11;加载因子是0.75
this(11, 0.75f);
} // 包含“子Map”的构造函数
public Hashtable(Map<? extends K, ? extends V> t) {
this(Math.max(2*t.size(), 11), 0.75f);
// 将“子Map”的全部元素都添加到Hashtable中
putAll(t);
} public synchronized int size() {
return count;
} public synchronized boolean isEmpty() {
return count == 0;
} // 返回“所有key”的枚举对象
public synchronized Enumeration<K> keys() {
return this.<K>getEnumeration(KEYS);
} // 返回“所有value”的枚举对象
public synchronized Enumeration<V> elements() {
return this.<V>getEnumeration(VALUES);
} // 判断Hashtable是否包含“值(value)”
public synchronized boolean contains(Object value) {
// Hashtable中“键值对”的value不能是null,
// 若是null的话,抛出异常!
if (value == null) {
throw new NullPointerException();
} // 从后向前遍历table数组中的元素(Entry)
// 对于每个Entry(单向链表),逐个遍历,判断节点的值是否等于value
Entry tab[] = table;
for (int i = tab.length ; i-- > 0 ;) {
for (Entry<K,V> e = tab[i] ; e != null ; e = e.next) {
if (e.value.equals(value)) {
return true;
}
}
}
return false;
} public boolean containsValue(Object value) {
return contains(value);
} // 判断Hashtable是否包含key
public synchronized boolean containsKey(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
// 计算索引值,
// % tab.length 的目的是防止数据越界
int index = (hash & 0x7FFFFFFF) % tab.length;
// 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return true;
}
}
return false;
} // 返回key对应的value,没有的话返回null
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
// 计算索引值,
int index = (hash & 0x7FFFFFFF) % tab.length;
// 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
} // 调整Hashtable的长度,将长度变成原来的(2倍+1)
// (01) 将“旧的Entry数组”赋值给一个临时变量。
// (02) 创建一个“新的Entry数组”,并赋值给“旧的Entry数组”
// (03) 将“Hashtable”中的全部元素依次添加到“新的Entry数组”中
protected void rehash() {
int oldCapacity = table.length;
Entry[] oldMap = table; int newCapacity = oldCapacity * 2 + 1;
Entry[] newMap = new Entry[newCapacity]; modCount++;
threshold = (int)(newCapacity * loadFactor);
table = newMap; for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next; int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = newMap[index];
newMap[index] = e;
}
}
} // 将“key-value”添加到Hashtable中
public synchronized V put(K key, V value) {
// Hashtable中不能插入value为null的元素!!!
if (value == null) {
throw new NullPointerException();
} // 若“Hashtable中已存在键为key的键值对”,
// 则用“新的value”替换“旧的value”
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
} // 若“Hashtable中不存在键为key的键值对”,
// (01) 将“修改统计数”+1
modCount++;
// (02) 若“Hashtable实际容量” > “阈值”(阈值=总的容量 * 加载因子)
// 则调整Hashtable的大小
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash(); tab = table;
index = (hash & 0x7FFFFFFF) % tab.length;
} // (03) 将“Hashtable中index”位置的Entry(链表)保存到e中
Entry<K,V> e = tab[index];
// (04) 创建“新的Entry节点”,并将“新的Entry”插入“Hashtable的index位置”,并设置e为“新的Entry”的下一个元素(即“新Entry”为链表表头)。
tab[index] = new Entry<K,V>(hash, key, value, e);
// (05) 将“Hashtable的实际容量”+1
count++;
return null;
} // 删除Hashtable中键为key的元素
public synchronized V remove(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
// 找到“key对应的Entry(链表)”
// 然后在链表中找出要删除的节点,并删除该节点。
for (Entry<K,V> e = tab[index], prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
} // 将“Map(t)”的中全部元素逐一添加到Hashtable中
public synchronized void putAll(Map<? extends K, ? extends V> t) {
for (Map.Entry<? extends K, ? extends V> e : t.entrySet())
put(e.getKey(), e.getValue());
} // 清空Hashtable
// 将Hashtable的table数组的值全部设为null
public synchronized void clear() {
Entry tab[] = table;
modCount++;
for (int index = tab.length; --index >= 0; )
tab[index] = null;
count = 0;
} // 克隆一个Hashtable,并以Object的形式返回。
public synchronized Object clone() {
try {
Hashtable<K,V> t = (Hashtable<K,V>) super.clone();
t.table = new Entry[table.length];
for (int i = table.length ; i-- > 0 ; ) {
t.table[i] = (table[i] != null)
? (Entry<K,V>) table[i].clone() : null;
}
t.keySet = null;
t.entrySet = null;
t.values = null;
t.modCount = 0;
return t;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError();
}
} public synchronized String toString() {
int max = size() - 1;
if (max == -1)
return "{}"; StringBuilder sb = new StringBuilder();
Iterator<Map.Entry<K,V>> it = entrySet().iterator(); sb.append('{');
for (int i = 0; ; i++) {
Map.Entry<K,V> e = it.next();
K key = e.getKey();
V value = e.getValue();
sb.append(key == this ? "(this Map)" : key.toString());
sb.append('=');
sb.append(value == this ? "(this Map)" : value.toString()); if (i == max)
return sb.append('}').toString();
sb.append(", ");
}
} // 获取Hashtable的枚举类对象
// 若Hashtable的实际大小为0,则返回“空枚举类”对象;
// 否则,返回正常的Enumerator的对象。(Enumerator实现了迭代器和枚举两个接口)
private <T> Enumeration<T> getEnumeration(int type) {
if (count == 0) {
return (Enumeration<T>)emptyEnumerator;
} else {
return new Enumerator<T>(type, false);
}
} // 获取Hashtable的迭代器
// 若Hashtable的实际大小为0,则返回“空迭代器”对象;
// 否则,返回正常的Enumerator的对象。(Enumerator实现了迭代器和枚举两个接口)
private <T> Iterator<T> getIterator(int type) {
if (count == 0) {
return (Iterator<T>) emptyIterator;
} else {
return new Enumerator<T>(type, true);
}
} // Hashtable的“key的集合”。它是一个Set,意味着没有重复元素
private transient volatile Set<K> keySet = null;
// Hashtable的“key-value的集合”。它是一个Set,意味着没有重复元素
private transient volatile Set<Map.Entry<K,V>> entrySet = null;
// Hashtable的“key-value的集合”。它是一个Collection,意味着可以有重复元素
private transient volatile Collection<V> values = null; // 返回一个被synchronizedSet封装后的KeySet对象
// synchronizedSet封装的目的是对KeySet的所有方法都添加synchronized,实现多线程同步
public Set<K> keySet() {
if (keySet == null)
keySet = Collections.synchronizedSet(new KeySet(), this);
return keySet;
} // Hashtable的Key的Set集合。
// KeySet继承于AbstractSet,所以,KeySet中的元素没有重复的。
private class KeySet extends AbstractSet<K> {
public Iterator<K> iterator() {
return getIterator(KEYS);
}
public int size() {
return count;
}
public boolean contains(Object o) {
return containsKey(o);
}
public boolean remove(Object o) {
return Hashtable.this.remove(o) != null;
}
public void clear() {
Hashtable.this.clear();
}
} // 返回一个被synchronizedSet封装后的EntrySet对象
// synchronizedSet封装的目的是对EntrySet的所有方法都添加synchronized,实现多线程同步
public Set<Map.Entry<K,V>> entrySet() {
if (entrySet==null)
entrySet = Collections.synchronizedSet(new EntrySet(), this);
return entrySet;
} // Hashtable的Entry的Set集合。
// EntrySet继承于AbstractSet,所以,EntrySet中的元素没有重复的。
private class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator<Map.Entry<K,V>> iterator() {
return getIterator(ENTRIES);
} public boolean add(Map.Entry<K,V> o) {
return super.add(o);
} // 查找EntrySet中是否包含Object(0)
// 首先,在table中找到o对应的Entry(Entry是一个单向链表)
// 然后,查找Entry链表中是否存在Object
public boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry entry = (Map.Entry)o;
Object key = entry.getKey();
Entry[] tab = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry e = tab[index]; e != null; e = e.next)
if (e.hash==hash && e.equals(entry))
return true;
return false;
} // 删除元素Object(0)
// 首先,在table中找到o对应的Entry(Entry是一个单向链表)
// 然后,删除链表中的元素Object
public boolean remove(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<K,V> entry = (Map.Entry<K,V>) o;
K key = entry.getKey();
Entry[] tab = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<K,V> e = tab[index], prev = null; e != null;
prev = e, e = e.next) {
if (e.hash==hash && e.equals(entry)) {
modCount++;
if (prev != null)
prev.next = e.next;
else
tab[index] = e.next; count--;
e.value = null;
return true;
}
}
return false;
} public int size() {
return count;
} public void clear() {
Hashtable.this.clear();
}
} // 返回一个被synchronizedCollection封装后的ValueCollection对象
// synchronizedCollection封装的目的是对ValueCollection的所有方法都添加synchronized,实现多线程同步
public Collection<V> values() {
if (values==null)
values = Collections.synchronizedCollection(new ValueCollection(),
this);
return values;
} // Hashtable的value的Collection集合。
// ValueCollection继承于AbstractCollection,所以,ValueCollection中的元素可以重复的。
private class ValueCollection extends AbstractCollection<V> {
public Iterator<V> iterator() {
return getIterator(VALUES);
}
public int size() {
return count;
}
public boolean contains(Object o) {
return containsValue(o);
}
public void clear() {
Hashtable.this.clear();
}
} // 重新equals()函数
// 若两个Hashtable的所有key-value键值对都相等,则判断它们两个相等
public synchronized boolean equals(Object o) {
if (o == this)
return true; if (!(o instanceof Map))
return false;
Map<K,V> t = (Map<K,V>) o;
if (t.size() != size())
return false; try {
// 通过迭代器依次取出当前Hashtable的key-value键值对
// 并判断该键值对,存在于Hashtable(o)中。
// 若不存在,则立即返回false;否则,遍历完“当前Hashtable”并返回true。
Iterator<Map.Entry<K,V>> i = entrySet().iterator();
while (i.hasNext()) {
Map.Entry<K,V> e = i.next();
K key = e.getKey();
V value = e.getValue();
if (value == null) {
if (!(t.get(key)==null && t.containsKey(key)))
return false;
} else {
if (!value.equals(t.get(key)))
return false;
}
}
} catch (ClassCastException unused) {
return false;
} catch (NullPointerException unused) {
return false;
} return true;
} // 计算Hashtable的哈希值
// 若 Hashtable的实际大小为0 或者 加载因子<0,则返回0。
// 否则,返回“Hashtable中的每个Entry的key和value的异或值 的总和”。
public synchronized int hashCode() {
int h = 0;
if (count == 0 || loadFactor < 0)
return h; // Returns zero loadFactor = -loadFactor; // Mark hashCode computation in progress
Entry[] tab = table;
for (int i = 0; i < tab.length; i++)
for (Entry e = tab[i]; e != null; e = e.next)
h += e.key.hashCode() ^ e.value.hashCode();
loadFactor = -loadFactor; // Mark hashCode computation complete return h;
} // java.io.Serializable的写入函数
// 将Hashtable的“总的容量,实际容量,所有的Entry”都写入到输出流中
private synchronized void writeObject(java.io.ObjectOutputStream s)
throws IOException
{
// Write out the length, threshold, loadfactor
s.defaultWriteObject(); // Write out length, count of elements and then the key/value objects
s.writeInt(table.length);
s.writeInt(count);
for (int index = table.length-1; index >= 0; index--) {
Entry entry = table[index]; while (entry != null) {
s.writeObject(entry.key);
s.writeObject(entry.value);
entry = entry.next;
}
}
} // java.io.Serializable的读取函数:根据写入方式读出
// 将Hashtable的“总的容量,实际容量,所有的Entry”依次读出
private void readObject(java.io.ObjectInputStream s)
throws IOException, ClassNotFoundException
{
// Read in the length, threshold, and loadfactor
s.defaultReadObject(); // Read the original length of the array and number of elements
int origlength = s.readInt();
int elements = s.readInt(); // Compute new size with a bit of room 5% to grow but
// no larger than the original size. Make the length
// odd if it's large enough, this helps distribute the entries.
// Guard against the length ending up zero, that's not valid.
int length = (int)(elements * loadFactor) + (elements / 20) + 3;
if (length > elements && (length & 1) == 0)
length--;
if (origlength > 0 && length > origlength)
length = origlength; Entry[] table = new Entry[length];
count = 0; // Read the number of elements and then all the key/value objects
for (; elements > 0; elements--) {
K key = (K)s.readObject();
V value = (V)s.readObject();
// synch could be eliminated for performance
reconstitutionPut(table, key, value);
}
this.table = table;
} private void reconstitutionPut(Entry[] tab, K key, V value)
throws StreamCorruptedException
{
if (value == null) {
throw new java.io.StreamCorruptedException();
}
// Makes sure the key is not already in the hashtable.
// This should not happen in deserialized version.
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
throw new java.io.StreamCorruptedException();
}
}
// Creates the new entry.
Entry<K,V> e = tab[index];
tab[index] = new Entry<K,V>(hash, key, value, e);
count++;
} // Hashtable的Entry节点,它本质上是一个单向链表。
// 也因此,我们才能推断出Hashtable是由拉链法实现的散列表
private static class Entry<K,V> implements Map.Entry<K,V> {
// 哈希值
int hash;
K key;
V value;
// 指向的下一个Entry,即链表的下一个节点
Entry<K,V> next; // 构造函数
protected Entry(int hash, K key, V value, Entry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
} protected Object clone() {
return new Entry<K,V>(hash, key, value,
(next==null ? null : (Entry<K,V>) next.clone()));
} public K getKey() {
return key;
} public V getValue() {
return value;
} // 设置value。若value是null,则抛出异常。
public V setValue(V value) {
if (value == null)
throw new NullPointerException(); V oldValue = this.value;
this.value = value;
return oldValue;
} // 覆盖equals()方法,判断两个Entry是否相等。
// 若两个Entry的key和value都相等,则认为它们相等。
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o; return (key==null ? e.getKey()==null : key.equals(e.getKey())) &&
(value==null ? e.getValue()==null : value.equals(e.getValue()));
} public int hashCode() {
return hash ^ (value==null ? 0 : value.hashCode());
} public String toString() {
return key.toString()+"="+value.toString();
}
} private static final int KEYS = 0;
private static final int VALUES = 1;
private static final int ENTRIES = 2; // Enumerator的作用是提供了“通过elements()遍历Hashtable的接口” 和 “通过entrySet()遍历Hashtable的接口”。因为,它同时实现了 “Enumerator接口”和“Iterator接口”。
private class Enumerator<T> implements Enumeration<T>, Iterator<T> {
// 指向Hashtable的table
Entry[] table = Hashtable.this.table;
// Hashtable的总的大小
int index = table.length;
Entry<K,V> entry = null;
Entry<K,V> lastReturned = null;
int type; // Enumerator是 “迭代器(Iterator)” 还是 “枚举类(Enumeration)”的标志
// iterator为true,表示它是迭代器;否则,是枚举类。
boolean iterator; // 在将Enumerator当作迭代器使用时会用到,用来实现fail-fast机制。
protected int expectedModCount = modCount; Enumerator(int type, boolean iterator) {
this.type = type;
this.iterator = iterator;
} // 从遍历table的数组的末尾向前查找,直到找到不为null的Entry。
public boolean hasMoreElements() {
Entry<K,V> e = entry;
int i = index;
Entry[] t = table;
/* Use locals for faster loop iteration */
while (e == null && i > 0) {
e = t[--i];
}
entry = e;
index = i;
return e != null;
} // 获取下一个元素
// 注意:从hasMoreElements() 和nextElement() 可以看出“Hashtable的elements()遍历方式”
// 首先,从后向前的遍历table数组。table数组的每个节点都是一个单向链表(Entry)。
// 然后,依次向后遍历单向链表Entry。
public T nextElement() {
Entry<K,V> et = entry;
int i = index;
Entry[] t = table;
/* Use locals for faster loop iteration */
while (et == null && i > 0) {
et = t[--i];
}
entry = et;
index = i;
if (et != null) {
Entry<K,V> e = lastReturned = entry;
entry = e.next;
return type == KEYS ? (T)e.key : (type == VALUES ? (T)e.value : (T)e);
}
throw new NoSuchElementException("Hashtable Enumerator");
} // 迭代器Iterator的判断是否存在下一个元素
// 实际上,它是调用的hasMoreElements()
public boolean hasNext() {
return hasMoreElements();
} // 迭代器获取下一个元素
// 实际上,它是调用的nextElement()
public T next() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return nextElement();
} // 迭代器的remove()接口。
// 首先,它在table数组中找出要删除元素所在的Entry,
// 然后,删除单向链表Entry中的元素。
public void remove() {
if (!iterator)
throw new UnsupportedOperationException();
if (lastReturned == null)
throw new IllegalStateException("Hashtable Enumerator");
if (modCount != expectedModCount)
throw new ConcurrentModificationException(); synchronized(Hashtable.this) {
Entry[] tab = Hashtable.this.table;
int index = (lastReturned.hash & 0x7FFFFFFF) % tab.length; for (Entry<K,V> e = tab[index], prev = null; e != null;
prev = e, e = e.next) {
if (e == lastReturned) {
modCount++;
expectedModCount++;
if (prev == null)
tab[index] = e.next;
else
prev.next = e.next;
count--;
lastReturned = null;
return;
}
}
throw new ConcurrentModificationException();
}
}
} private static Enumeration emptyEnumerator = new EmptyEnumerator();
private static Iterator emptyIterator = new EmptyIterator(); // 空枚举类
// 当Hashtable的实际大小为0;此时,又要通过Enumeration遍历Hashtable时,返回的是“空枚举类”的对象。
private static class EmptyEnumerator implements Enumeration<Object> { EmptyEnumerator() {
} // 空枚举类的hasMoreElements() 始终返回false
public boolean hasMoreElements() {
return false;
} // 空枚举类的nextElement() 抛出异常
public Object nextElement() {
throw new NoSuchElementException("Hashtable Enumerator");
}
} // 空迭代器
// 当Hashtable的实际大小为0;此时,又要通过迭代器遍历Hashtable时,返回的是“空迭代器”的对象。
private static class EmptyIterator implements Iterator<Object> { EmptyIterator() {
} public boolean hasNext() {
return false;
} public Object next() {
throw new NoSuchElementException("Hashtable Iterator");
} public void remove() {
throw new IllegalStateException("Hashtable Iterator");
} }
}
三:TreeMap
与前面的两个map实现类不同,TreeMap是通过红黑树来实现的。所以针对TreeMap的插入元素、查找元素、删除元素等都是对红黑树的操作。
主要源码:
//1:插入元素
//两步:一是插入到排序二叉树的合适位置,二是对二叉树进行平衡(左右旋、重新着色) public V put(K key, V value) {
//用t表示二叉树的当前节点
Entry<K,V> t = root;
//t为null表示一个空树,即TreeMap中没有任何元素,直接插入
if (t == null) {
//比较key值,个人觉得这句代码没有任何意义,空树还需要比较、排序?
compare(key, key); // type (and possibly null) check
//将新的key-value键值对创建为一个Entry节点,并将该节点赋予给root
root = new Entry<>(key, value, null);
//容器的size = 1,表示TreeMap集合中存在一个元素
size = 1;
//修改次数 + 1
modCount++;
return null;
}
int cmp; //cmp表示key排序的返回结果
Entry<K,V> parent; //父节点
// split comparator and comparable paths
Comparator<? super K> cpr = comparator; //指定的排序算法
//如果cpr不为空,则采用既定的排序算法进行创建TreeMap集合
if (cpr != null) {
do {
parent = t; //parent指向上次循环后的t
//比较新增节点的key和当前节点key的大小
cmp = cpr.compare(key, t.key);
//cmp返回值小于0,表示新增节点的key小于当前节点的key,则以当前节点的左子节点作为新的当前节点
if (cmp < 0)
t = t.left;
//cmp返回值大于0,表示新增节点的key大于当前节点的key,则以当前节点的右子节点作为新的当前节点
else if (cmp > 0)
t = t.right;
//cmp返回值等于0,表示两个key值相等,则新值覆盖旧值,并返回新值
else
return t.setValue(value);
} while (t != null);
}
//如果cpr为空,则采用默认的排序算法进行创建TreeMap集合
else {
if (key == null) //key值为空抛出异常
throw new NullPointerException();
/* 下面处理过程和上面一样 */
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
//将新增节点当做parent的子节点
Entry<K,V> e = new Entry<>(key, value, parent);
//如果新增节点的key小于parent的key,则当做左子节点
if (cmp < 0)
parent.left = e;
//如果新增节点的key大于parent的key,则当做右子节点
else
parent.right = e;
/*
* 上面已经完成了排序二叉树的的构建,将新增节点插入该树中的合适位置
* 下面fixAfterInsertion()方法就是对这棵树进行调整、平衡,具体过程参考上面的五种情况
*/
fixAfterInsertion(e);
//TreeMap元素数量 + 1
size++;
//TreeMap容器修改次数 + 1
modCount++;
return null;
}
/**
* 新增节点后的修复操作
* x 表示新增节点
*/
private void fixAfterInsertion(Entry<K,V> x) {
x.color = RED; //新增节点的颜色为红色 //循环 直到 x不是根节点,且x的父节点不为红色
while (x != null && x != root && x.parent.color == RED) {
//如果X的父节点(P)是其父节点的父节点(G)的左节点
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
//获取X的叔节点(U)
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
//如果X的叔节点(U) 为红色(情况三)
if (colorOf(y) == RED) {
//将X的父节点(P)设置为黑色
setColor(parentOf(x), BLACK);
//将X的叔节点(U)设置为黑色
setColor(y, BLACK);
//将X的父节点的父节点(G)设置红色
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
}
//如果X的叔节点(U为黑色);这里会存在两种情况(情况四、情况五)
else {
//如果X节点为其父节点(P)的右子树,则进行左旋转(情况四)
if (x == rightOf(parentOf(x))) {
//将X的父节点作为X
x = parentOf(x);
//右旋转
rotateLeft(x);
}
//(情况五)
//将X的父节点(P)设置为黑色
setColor(parentOf(x), BLACK);
//将X的父节点的父节点(G)设置红色
setColor(parentOf(parentOf(x)), RED);
//以X的父节点的父节点(G)为中心右旋转
rotateRight(parentOf(parentOf(x)));
}
}
//如果X的父节点(P)是其父节点的父节点(G)的右节点
else {
//获取X的叔节点(U)
Entry<K,V> y = leftOf(parentOf(parentOf(x)));
//如果X的叔节点(U) 为红色(情况三)
if (colorOf(y) == RED) {
//将X的父节点(P)设置为黑色
setColor(parentOf(x), BLACK);
//将X的叔节点(U)设置为黑色
setColor(y, BLACK);
//将X的父节点的父节点(G)设置红色
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
}
//如果X的叔节点(U为黑色);这里会存在两种情况(情况四、情况五)
else {
//如果X节点为其父节点(P)的右子树,则进行左旋转(情况四)
if (x == leftOf(parentOf(x))) {
//将X的父节点作为X
x = parentOf(x);
//右旋转
rotateRight(x);
}
//(情况五)
//将X的父节点(P)设置为黑色
setColor(parentOf(x), BLACK);
//将X的父节点的父节点(G)设置红色
setColor(parentOf(parentOf(x)), RED);
//以X的父节点的父节点(G)为中心右旋转
rotateLeft(parentOf(parentOf(x)));
}
}
}
//将根节点G强制设置为黑色
root.color = BLACK;
}
private void rotateLeft(Entry<K,V> p) {
if (p != null) {
//获取P的右子节点,其实这里就相当于新增节点N(情况四而言)
Entry<K,V> r = p.right;
//将R的左子树设置为P的右子树
p.right = r.left;
//若R的左子树不为空,则将P设置为R左子树的父亲
if (r.left != null)
r.left.parent = p;
//将P的父亲设置R的父亲
r.parent = p.parent;
//如果P的父亲为空,则将R设置为跟节点
if (p.parent == null)
root = r;
//如果P为其父节点(G)的左子树,则将R设置为P父节点(G)左子树
else if (p.parent.left == p)
p.parent.left = r;
//否则R设置为P的父节点(G)的右子树
else
p.parent.right = r;
//将P设置为R的左子树
r.left = p;
//将R设置为P的父节点
p.parent = r;
}
}
private void rotateRight(Entry<K,V> p) {
if (p != null) {
//将L设置为P的左子树
Entry<K,V> l = p.left;
//将L的右子树设置为P的左子树
p.left = l.right;
//若L的右子树不为空,则将P设置L的右子树的父节点
if (l.right != null)
l.right.parent = p;
//将P的父节点设置为L的父节点
l.parent = p.parent;
//如果P的父节点为空,则将L设置根节点
if (p.parent == null)
root = l;
//若P为其父节点的右子树,则将L设置为P的父节点的右子树
else if (p.parent.right == p)
p.parent.right = l;
//否则将L设置为P的父节点的左子树
else
p.parent.left = l;
//将P设置为L的右子树
l.right = p;
//将L设置为P的父节点
p.parent = l;
}
} //2:删除元素
//在红黑树中删除一个结点。红黑树删除结点D:取D右分支最左边,或者左分支最右边的//子结点取代D,然后把子节点删除,之后再对红黑树进行平衡。 private void deleteEntry(Entry<K,V> p) {
modCount++; //修改次数 +1
size--; //元素个数 -1 /*
* 被删除节点的左子树和右子树都不为空,那么就用 p节点的中序后继节点代替 p 节点
* successor(P)方法为寻找P的替代节点。规则是右分支最左边,或者 左分支最右边的节点
* ---------------------(1)
*/
if (p.left != null && p.right != null) {
Entry<K,V> s = successor(p);
p.key = s.key;
p.value = s.value;
p = s;
} //replacement为替代节点,如果P的左子树存在那么就用左子树替代,否则用右子树替代
Entry<K,V> replacement = (p.left != null ? p.left : p.right); /*
* 删除节点,分为上面提到的三种情况
* -----------------------(2)
*/
//如果替代节点不为空
if (replacement != null) {
replacement.parent = p.parent;
/*
*replacement来替代P节点
*/
//若P没有父节点,则跟节点直接变成replacement
if (p.parent == null)
root = replacement;
//如果P为左节点,则用replacement来替代为左节点
else if (p == p.parent.left)
p.parent.left = replacement;
//如果P为右节点,则用replacement来替代为右节点
else
p.parent.right = replacement; //同时将P节点从这棵树中剔除掉
p.left = p.right = p.parent = null; /*
* 若P为红色直接删除,红黑树保持平衡
* 但是若P为黑色,则需要调整红黑树使其保持平衡
*/
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) { //p没有父节点,表示为P根节点,直接删除即可
root = null;
} else { //P节点不存在子节点,直接删除即可
if (p.color == BLACK) //如果P节点的颜色为黑色,对红黑树进行调整
fixAfterDeletion(p); //删除P节点
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}
static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) {
if (t == null)
return null;
/*
* 寻找右子树的最左子树
*/
else if (t.right != null) {
Entry<K,V> p = t.right;
while (p.left != null)
p = p.left;
return p;
}
/*
* 选择左子树的最右子树
*/
else {
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.right) {
ch = p;
p = p.parent;
}
return p;
}
}
private void fixAfterDeletion(Entry<K,V> x) {
// 删除节点需要一直迭代,知道 直到 x 不是根节点,且 x 的颜色是黑色
while (x != root && colorOf(x) == BLACK) {
if (x == leftOf(parentOf(x))) { //若X节点为左节点
//获取其兄弟节点
Entry<K,V> sib = rightOf(parentOf(x)); /*
* 如果兄弟节点为红色----(情况3.1)
* 策略:改变W、P的颜色,然后进行一次左旋转
*/
if (colorOf(sib) == RED) {
setColor(sib, BLACK);
setColor(parentOf(x), RED);
rotateLeft(parentOf(x));
sib = rightOf(parentOf(x));
} /*
* 若兄弟节点的两个子节点都为黑色----(情况3.2)
* 策略:将兄弟节点编程红色
*/
if (colorOf(leftOf(sib)) == BLACK &&
colorOf(rightOf(sib)) == BLACK) {
setColor(sib, RED);
x = parentOf(x);
}
else {
/*
* 如果兄弟节点只有右子树为黑色----(情况3.3)
* 策略:将兄弟节点与其左子树进行颜色互换然后进行右转
* 这时情况会转变为3.4
*/
if (colorOf(rightOf(sib)) == BLACK) {
setColor(leftOf(sib), BLACK);
setColor(sib, RED);
rotateRight(sib);
sib = rightOf(parentOf(x));
}
/*
*----情况3.4
*策略:交换兄弟节点和父节点的颜色,
*同时将兄弟节点右子树设置为黑色,最后左旋转
*/
setColor(sib, colorOf(parentOf(x)));
setColor(parentOf(x), BLACK);
setColor(rightOf(sib), BLACK);
rotateLeft(parentOf(x));
x = root;
}
} /**
* X节点为右节点与其为做节点处理过程差不多,这里就不在累述了
*/
else {
Entry<K,V> sib = leftOf(parentOf(x)); if (colorOf(sib) == RED) {
setColor(sib, BLACK);
setColor(parentOf(x), RED);
rotateRight(parentOf(x));
sib = leftOf(parentOf(x));
} if (colorOf(rightOf(sib)) == BLACK &&
colorOf(leftOf(sib)) == BLACK) {
setColor(sib, RED);
x = parentOf(x);
} else {
if (colorOf(leftOf(sib)) == BLACK) {
setColor(rightOf(sib), BLACK);
setColor(sib, RED);
rotateLeft(sib);
sib = leftOf(parentOf(x));
}
setColor(sib, colorOf(parentOf(x)));
setColor(parentOf(x), BLACK);
setColor(leftOf(sib), BLACK);
rotateRight(parentOf(x));
x = root;
}
}
} setColor(x, BLACK);
}
四:LinkedHashMap
HashMap对键值对的组织是无顺序的。遍历顺序不一定是按照插入顺序,所以如果想按照插入顺序来遍历结果的话用HashMap是不行的。为此,我们可以使用LinkedHashMap。
与LinkedHashSet类似,LinkedHashMap也是维护了一个双向链表,记录元素的插入顺序,然后再根据元素值,采用hashcode()、equals()方法来存储元素值并实现元素的唯一性。双向链表将所有put到LinkedHashmap的节点一一串成了一个双向循环链表,因此它保留了节点插入的顺序,可以使节点的输出顺序与输入顺序相同
第一种:通过Map.entrySet使用iterator遍历key和value
public void visit_1(HashMap<String,Integer> hm){
Iterator<Map.Entry<String,Integer>> it = hm.entrySet().iterator();
while(it.hasNext()){
Map.Entry<String ,Integer> entry = it.next();
String key = entry.getKey();
Integer value = entry.getValue();
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
第二种:通过Key来遍历value
public void visit_2(HashMap<String,Integer> hm){
for (String key:hm.keySet()){
Integer value = hm.get(key);
}
}- 1
- 2
- 3
- 4
- 5
第三种:通过Map.Entry遍历key和value
public void visit_3(HashMap<String,Integer> hm){
for(Map.Entry<String,Integer> entry:hm.entrySet()){
String key = entry.getKey();
Integer value = entry.getValue();
}
}- 1
- 2
- 3
- 4
- 5
- 6
第四种:通过Map.keySet使用iterator遍历key和value
public void visit_4(HashMap<Integer,String> hm){
long startTime = System.currentTimeMillis();
Iterator<Integer> it = hm.keySet().iterator();
while(it.hasNext()){
Integer key = it.next();
String value = hm.get(key);
}
System.out.println("visit_4 10000000 entry:"
+ (System.currentTimeMillis()-startTime) + " milli seconds");
}Map集合学习的更多相关文章
- Map集合学习总结
1.Map接口定义的集合又称查找表,用于存储所谓的 key-value 映射对,key可以看成是value的索引,作为key的对象在集合中不可以重复 根据内部数据结构的不同Map接口有多重实现类,其 ...
- java Map集合学习
学习语法还是从例子着手: FileDao fileDao=new FileBeanDaoImpl(); FileBean fileBean=new FileBean(); listBean=fileD ...
- Java集合Map接口与Map.Entry学习
Java集合Map接口与Map.Entry学习 Map接口不是Collection接口的继承.Map接口用于维护键/值对(key/value pairs).该接口描述了从不重复的键到值的映射. (1) ...
- Go语言学习笔记十三: Map集合
Go语言学习笔记十三: Map集合 Map在每种语言中基本都有,Java中是属于集合类Map,其包括HashMap, TreeMap等.而Python语言直接就属于一种类型,写法上比Java还简单. ...
- hibernate学习系列-----(9)hibernate对集合属性的操作之Map集合篇
照旧,先新建一个StudentMap.java实体类,将hobby属性使用map集合接口来存放: package com.joe.entity; import java.util.Map; publi ...
- java集合学习(2):Map和HashMap
Map接口 java.util 中的集合类包含 Java 中某些最常用的类.最常用的集合类是 List 和 Map. Map 是一种键-值对(key-value)集合,Map 集合中的每一个元素都包含 ...
- Java集合类学习笔记(Map集合)
Map用于保存具有映射关系的数据,因此Map集合里保存着两组数据,一组用于保存Map的key,一组用于保存key所对应的value. Map的key不允许重复. HashMap和Hashtable都是 ...
- java学习第18天(map集合)
Map集合是将键映射到值的对象.一个映射不能包含重复的键:每个键最多只能映射到一个值. 存储的是键值对形式的元素,键唯一,值可以重复,有点类似于数据库中的主键加数据.主要功能有: A:添加功能 put ...
- 【Java学习笔记】Map集合的keySet,entrySet,values的用法例子
import java.util.Collection; import java.util.HashMap; import java.util.Iterator; import java.util.M ...
随机推荐
- Linux段错误及GDB Coredump调试方法
最近在Linux环境下做C语言项目,由于是在一个原有项目基础之上进行二次开发,而且项目工程庞大复杂,出现了不少问题,其中遇到最多.花费时间最长的问题就是著名的“段错误”(Segmentation Fa ...
- php入门(一)
一,在HTML中嵌入php代码 先看html的代码: <form action="processorder.php" method="post"> ...
- SVM(三)线性支持向量机
本文是在微信公众号发表的原创~ 额,图片粘不过来~就把链接给你们吧 http://mp.weixin.qq.com/s?__biz=MjM5MzM5NDAzMg==&mid=400740076 ...
- Android开发-网络通信1
使用 org.apache.http.client.HttpClient; 一开始从官网下载HttpClient 4.5:http://hc.apache.org/downloads.cgi ,解压之 ...
- MS SQL2008执行大脚本文件时,提示“内存不足”的解决办法
问题描述: 当客户服务器不允许直接备份时,往往通过导出数据库脚本的方式来部署-还原数据库, 但是当数据库导出脚本很大,用Microsoft SQL Server Management Studio执行 ...
- Nginx 出现413 Request Entity Too Large得解决方法
Nginx 出现413 Request Entity Too Large得解决方法 默认情况下使用nginx反向代理上传超过2MB的文件,会报错413 Request Entity Too Large ...
- 虚拟机中安装windows server 2008方法
我们简单的介绍一下怎么在虚拟机上安装 windows server 2008系统. 工具/原料 已经安装好的虚拟机. windows server 2008 iso系统镜像 方法/步骤1虚拟机上虚 ...
- Ansible 小手册系列 十五(Blocks 分组)
当我们想在满足一个条件下,执行多个任务时,就需要分组了.而不再每个任务都要用when. tasks: - block: - command: echo 1 - shell: echo 2 - raw: ...
- ssh原理与应用
一.什么是SSH? 简单说,SSH是一种网络协议,用于计算机之间的加密登录. 如果一个用户从本地计算机,使用SSH协议登录另一台远程计算机,我们就可以认为,这种登录是安全的,即使被中途截获,密码也不会 ...
- Spring入门4.AOP配置深入
Spring入门4.AOP配置深入 代码下载 链接: http://pan.baidu.com/s/11mYEO 密码: x7wa 前言: 之前学习AOP中的一些概念,包括连接点.切入点(pointc ...