Win10 环境安装tesseract-ocr 4.00并配置环境变量
Tesseract-OCR的Training简明教程
https://blog.csdn.net/blueheart20/article/details/53207176
一、安装:
选择对应版本,https://digi.bib.uni-mannheim.de/tesseract/
1:下载安装包
根据https://github.com/tesseract-ocr/tesseract/wiki,我找到非官方的安装包,好像我只看到64位的安装包http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe,下载后直接安装即可,但是要记得你的安装目录,我们等会配置环境变量要用。
如果不是做英文的图文识别,还需要下载其他语言的识别包https://github.com/tesseract-ocr/tesseract/wiki/Data-Files。
简体字识别包:https://raw.githubusercontent.com/tesseract-ocr/tessdata/4.00/chi_sim.traineddata
繁体字识别包:https://github.com/tesseract-ocr/tessdata/raw/4.0/chi_tra.traineddata
2:安装
直接执行下载好的tesseract-ocr-setup-4.00.00dev.exe,下一步、下一步安装。
3:配置环境变量
打开命令终端,输入:tesseract -v,可以看到版本信息
到这里,我们就算安装完成了,但是,我们的系统还是无法识别中文的,我们要去下载简体汉字、繁体汉字语言包(上文给了地址了),语言包是放在 tessdata文件下即可。
问题解决:
在windows下安装成功之后,进行tesseract的操作,碰到如下错误信息: E:\testdir>tesseract test.png test1 -l eng Error opening data file \Program Files (x86)\Tesseract-OCR\tessdata/eng.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your "tessdata" directory. Failed loading language 'eng' Tesseract couldn't load any languages! Could not initialize tesseract. 错误信息的关键词是tesseract_prefix的环境变量设置。
解决办法: 找到testData所在的目录,默认情况下是在tesseract安装的目录,在环境变量中设置TESSDATA_PREFIX的环境变量为testdata所在的目录即可。
增加一个TESSDATA_PREFIX变量名,变量值还是我的安装路径C:\Program Files (x86)\Tesseract-OCR;
重新运行命令即可正常使用。
参考:https://blog.csdn.net/blueheart20/article/details/53207176?utm_source=copy
二、识别
1、进入cmd,进入到要识别的图片的路径下。
2、输入命令
tesseract 图片名称 生成的结果文件的名称 字库
例如:
tesseract test.jpg result -l chi_sim
识别完后会生成result.txt文件
当然啦效果不太理想。所以我们要训练自己的字库。
三、训练
1、将图片转换成tif格式,用于后面生成box文件。可以通过画图,然后另存为tif即可。
更改图片名字,这个是有要求的=。=
tif文面命名格式[lang].[fontname].exp[num].tif
lang是语言 fontname是字体
比如我们要训练自定义字库 mjorcen字体名normal
那么我们把图片文件重命名 mjorcen.normal.exp0.jpg在转tif。
2、生成box文件。
|
1
|
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 -l chi_sim batch.nochop makebox |

box文件和对应的tif一定要在相同的目录下,不然后面打不开。
3、打开jTessBoxEditor矫正错误并训练
打开train.bat

找到tif图,打开,并校正。
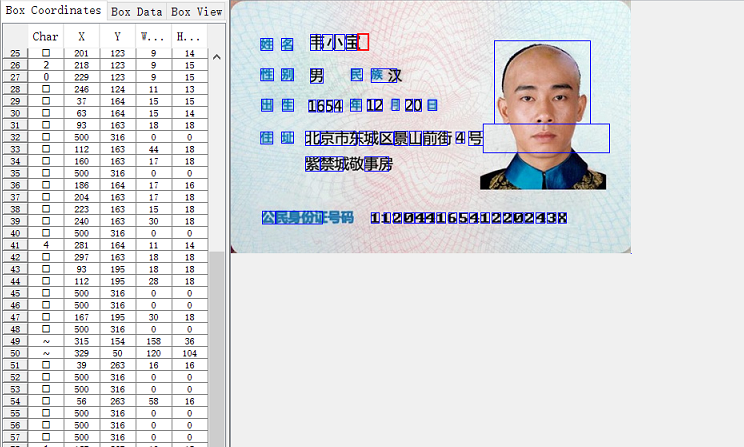
问题:
最初在jTessBoxEditor中,所有中文字体都显示乱码(方框),只需要的设置中,将字体修改成【宋体】就没问题了 。
4、训练。
只要在命令行输入命令即可。
|
1
|
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 nobatch box.train |
|
1
|
unicharset_extractor mjorcen.normal.exp0.box |

在这我明明已经矫正好了,但是还是有1个字符不能识别出来,报的错跟实际上完全没有相关性,不知道是不是bug,到后面的结果就是“园”字没有识别出来。
先不管,毕竟只有一个样本。
新建一个font_properties文件
里面内容写入 normal 0 0 0 0 0 表示默认普通字体
继续敲命令
|
1
2
3
4
5
6
7
8
9
|
shapeclustering -F font_properties -U unicharset mjorcen.normal.exp0.trmftraining -F font_properties -U unicharset -O unicharset mjorcen.normal.exp0.trcntraining mjorcen.normal.exp0.tr |
最后会生成五个文件,把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件前面都加上normal.
如图:

命令行输入,合并五个文件:
|
1
|
combine_tessdata normal. |
得到训练好的字库。

四、测试
1、把 normal.traineddata 复制到Tesseract-OCR 安装目录下的tessdata文件夹中
2、识别命令:
|
1
|
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 -l normal |
3、效果

对比:

总结:
jTessBoxEditor 是正常可用的,在校正训练的时候,文本框的位置、大小和识别的文字,都可以通过 jTessBoxEditor 来校正。
不能对位置进行改变。这样对于训练来说很难得到比较好的分割文字,会产生不好的影响。
参考:http://www.cnblogs.com/wzben/p/5930538.html
http://www.cnblogs.com/jianqingwang/p/6978724.html
https://blog.csdn.net/xiaochunyong/article/details/7193744
https://www.cnblogs.com/zhongtang/p/5555950.html 也不错
Win10 环境安装tesseract-ocr 4.00并配置环境变量的更多相关文章
- Windows环境安装tesseract-ocr 4.00并配置环境变量
最近要做文字识别,不让直接用别人的接口,所以只能尝试去用开源的类库.tesseract-ocr是惠普公司开源的一个文字识别项目,通过它可以快速搭建图文识别系统,帮助我们开发出能识别图片的ocr系统.因 ...
- win7 64位 安装java jdk1.8 ,修改配置环境变量
下载jdk1.8,下载地址:http://www.wmzhe.com/soft-30118.html 安装时有两个程序,都安装在同一个目录下. win7 64位 安装java jdk1.8 ,修改配置 ...
- Windows安装Tesseract-OCR 4.00并配置环境变量
一.前言 Tesseract-OCR 是一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎.与Microsoft O ...
- LAMP坏境和LNMP环境安装Nagios4.1.1和基本配置
----------------------------------------以下内容为笔者生产环境的监控,安装都是经过一步步测试的-------------------------------- ...
- Fedora 20下安装官方JDK替换OpenJDK并配置环境变量
Fedora 20自带OpenJDK,所以如果安装官方的JDK的话要先删除OpenJDK,步骤如下: 1:rpm -qa|grep jdk 查看当前的jdk情况. 2:yum -y remove ja ...
- 基于python的机器学习开发环境安装(最简单的初步开发环境)
一.安装Python 1.下载安装python3.6 https://www.python.org/getit/ 2.配置环境变量(2个) 略...... 二.安装Python算法库 安装顺序:Num ...
- oracleLinux7上安装oracle11g r2(脚本简单配置环境)
一 环境脚本简单配置 #!/bin/bashmv /etc/yum.repos.d/* /tmpmv iso.repo /etc/yum.repos.d/tar zxvf a.tar.gzmv 7Se ...
- 【Oracle】在win10上安装Oracle客户端报错:[INS-13001]环境不满足最低要求
环境:win10 64bit 客户端工具: 安装的时候报错: 解决方案: 在\client\stage\cvu目录下找到如下两个文件: 编辑这两个文件,在文件中分别添加如下内容 <OPERATI ...
- win10 下安装 tesseract + tesserocr
首先参考博文一贴:https://blog.csdn.net/u014179267/article/details/80908790 1.那么安装这两个模块是为了爬虫的时候识别验证码用的,但是安装的过 ...
随机推荐
- CMSIS-SVD 系统视图说明
CMSIS 到底是什么? 先来看看ARM公司对CMSIS的定义: ARM® Cortex™ 微控制器软件接口标准 (CMSIS) 是 Cortex-M 处理器系列的与供应商无关的硬件抽象层. CMSI ...
- SQLSERVER里面RR隔离级别没有GAP锁
http://www.cnblogs.com/MYSQLZOUQI/articles/3862721.html
- 測试oracle 11g cluster 中OLR的重要性
測试oracle 11g cluster 中OLR的重要性 called an Oracle Local Registry (OLR): each node in a cluster has a ...
- JavaScript中typeof详解
[范围]typeof返回值范围: typeof返回值对应 类型 结果 String "string" Number "number" Boolean " ...
- wget 下载文件重进行命名
wget在下载的时候就重命名的: wget -c "www.baidu.com" -O baidu.index.html 保存输出日至,可以使用: wget -c "ww ...
- Selenium2+python自动化70-unittest之跳过用例(skip)
前言 当测试用例写完后,有些模块有改动时候,会影响到部分用例的执行,这个时候我们希望暂时跳过这些用例. 或者前面某个功能运行失败了,后面的几个用例是依赖于这个功能的用例,如果第一步就失败了,后面的用例 ...
- [翻译] TSActivityIndicatorView 自定义指示器
TSActivityIndicatorView 自定义指示器 https://github.com/tomkowz/TSActivityIndicatorView TSActivityIndicato ...
- 《Linux兵书》
<Linux兵书> 基本信息 作者: 刘丽霞 杨宇 丛书名: 程序员藏经阁 出版社:电子工业出版社 ISBN:9787121219924 上架时间:2014-1-13 出版日期:20 ...
- 角摩网发布在线制作Epub、Mobi格式的电子书
原来cn的域名没有及时续约被人用了,现在用www.joymo.cc开始新的电子书制作之路. 目前支持Epub和Mobi格式,会陆续加入PDF和APK的电子书.
- 第9章 初识STM32固件库—零死角玩转STM32-F429系列
第9章 初识STM32固件库 全套200集视频教程和1000页PDF教程请到秉火论坛下载:www.firebbs.cn 野火视频教程优酷观看网址:http://i.youku.com/fire ...